
모든 SEO에 필요한 로그 파일 분석의 5가지 핵심
게시 됨: 2018-12-13로그 파일은 웹사이트의 수명을 정확하게 반영합니다. 사용자 또는 봇, 페이지 또는 리소스에 관계없이 웹사이트의 모든 활동은 로그에 저장됩니다.
IP 주소, 상태 코드, 사용자 에이전트, 참조자 및 기타 기술 데이터와 같은 정보를 포함하는 로그(서버 기반 데이터)의 모든 행은 일반적으로 주로 분석 데이터(사용자 지향 데이터).
로그에서 찾을 수 있는 데이터는 그 자체로 SEO 전략에 집중하는 데 도움이 될 수 있습니다.
1. 웹사이트의 상태
로그를 통해 얻을 수 있는 정보 중 상태 코드 , 응답 크기 및 응답 시간 은 웹사이트 상태를 나타내는 훌륭한 지표입니다.
실제로 그 이유를 제대로 이해하지 못한 채 트래픽이나 전환을 잃는 것이 일반적입니다. 설명이 때로는 기술적일 수 있기 때문입니다.
고려해야 할 리드 중에는 방금 언급한 3가지 필드와 직접적으로 관련된 몇 가지가 있습니다.
예 1: 서버 오류 수의 증가("5xx")는 단순히 페이지에서 페이지로 이동하는 경우 감지되지 않을 수 있는 기술적 문제를 나타낼 수 있습니다.
예 2: 여러 연구에서 전자 상거래 웹사이트의 전환율에 대한 로드 시간의 영향을 보여주었습니다. 판매 수익의 하락은 페이지 로드 시간의 증가와 관련될 수 있습니다.
또한 Google은 로드 시간과 수익 간의 관계를 시뮬레이션할 수 있는 계산기를 제공합니다.
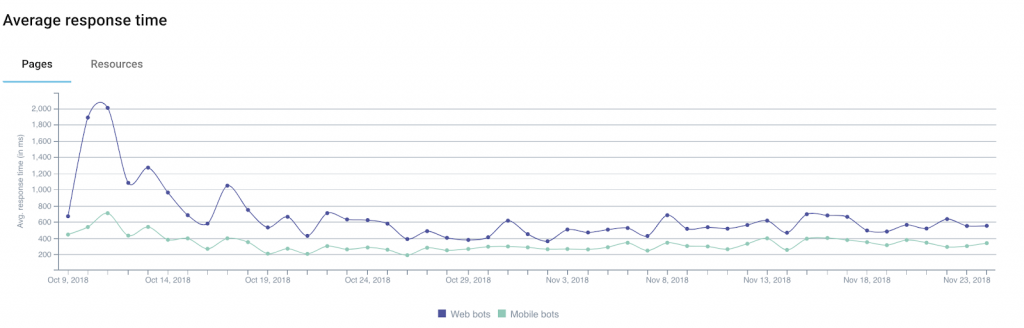
예 3: 다양한 기술적 문제에 따라 서버에서 빈 페이지를 반환하는 경우가 있습니다. 이 경우 상태 코드를 간단히 모니터링하는 것만으로는 경고가 표시되지 않습니다. 그렇기 때문에 모니터링하는 데이터에 응답 크기를 추가하는 것이 도움이 될 수 있습니다. 이러한 빈(또는 빈) 페이지는 일반적으로 평소보다 가볍습니다.
다양한 유형의 URL/페이지를 기반으로 웹사이트를 분할하면 기술 문제의 원인을 보다 쉽게 분리할 수 있으므로 문제를 더 쉽게 해결할 수 있습니다.
2. 봇 히트 빈도
SEO 커뮤니티의 구성원에게 로그는 검색 엔진 의 봇이 웹사이트를 "소비"하는 방법에 대한 유용한 정보를 많이 나타냅니다.
예를 들어 봇이 페이지를 처음 또는 마지막으로 방문한 시간을 알려줍니다.
새로운 콘텐츠를 빠르게 찾고 색인을 생성하기 위해 논리적으로 검색 엔진이 필요한 뉴스 웹사이트 의 예를 들어보겠습니다. 날짜와 시간 을 나타내는 로그 필드를 분석하면 기사 게시와 검색 엔진에 의한 검색 사이의 평균 시간 을 정의할 수 있습니다.
거기에서 웹사이트의 홈 페이지, 카테고리 페이지의 일일 봇 히트 수(또는 크롤링 빈도 )를 분석하는 것은 흥미로울 것입니다. 이렇게 하면 발견해야 하는 새로운 기사에 대한 링크를 배치할 위치를 쉽게 결정할 수 있습니다.
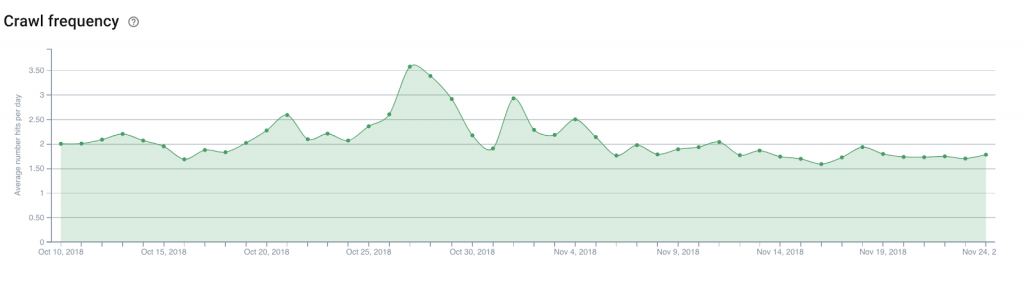
새로운 트렌드를 유지하기 위해 집중 조명하려는 제품과 같이 카탈로그에서 새로운 제품을 발견하기 위해 전자 상거래 웹 사이트 에도 동일한 이론을 적용할 수 있습니다.
3. 크롤링 예산
크롤링 예산( Google 과 동료들이 사이트에 할당하는 일종의 크롤링 대역폭 크레딧)은 SEO 전문가가 가장 좋아하는 주제이며 최적화는 필수 과제가 되었습니다.
로그 외에는 Google Search Console(현재는 이전 버전)만 검색 엔진이 웹사이트에 부여하는 예산에 대한 기본 아이디어를 제공합니다. 그러나 Search Console의 정확도 수준은 노력을 집중해야 할 위치를 파악하는 데 실제로 도움이 되지 않습니다. 특히 보고된 데이터는 실제로 모든 Googlebot에서 누적된 집계 데이터이기 때문입니다.
그러나 사용자 에이전트 및 URL 필드 분석 덕분에 로그는 봇이 방문하는 페이지(또는 리소스)와 속도로 식별할 수 있습니다.
이 정보는 Googlebot이 SEO에 중요하지 않은 웹사이트 부분을 과도하게 탐색하여 다른 페이지에 유용할 수 있는 예산을 낭비하는지 알려줍니다.
이러한 유형의 분석은 내부 연결 전략, robots.txt 파일 관리, 봇을 대상으로 하는 메타 태그 사용 등을 구성하는 데 사용할 수 있습니다.

4. 모바일 우선 및 마이그레이션
기다리지 못하는 사람도 있고 두려워하는 사람도 있습니다. 하지만 Google에서 귀하의 웹사이트가 유명한 모바일 우선 색인으로 전환되었음을 알리는 이메일을 받게 될 날은 분명히 올 것입니다.
Googlebot-데스크톱 조회수 와 Googlebot-모바일 조회수 간의 비율 변화에 따라 전환이 발생할 시기를 예측할 수 있습니다.
모바일 Googlebot이 크롤링하는 부분은 일반적으로 증가하므로 전환을 예측하고 계획할 수 있습니다.
반면에 이 비율의 변화를 보지 못한다는 것은 색인 전환에 대한 Google의 기준에 웹사이트가 적합하다는 중요한 표시일 수도 있습니다.
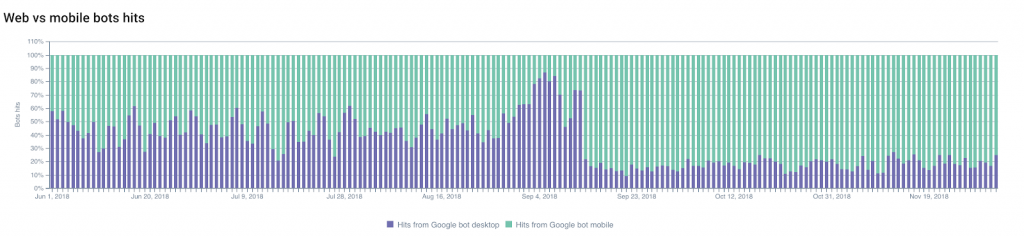
다른 변경 사항도 모니터링할 수 있습니다. 마이그레이션(예: HTTP 에서 HTTPS 로) 또는 웹사이트 구조 수정 .
첫 번째 예(사용된 프로토콜 수정)에 집중하면 보안 URL 및 리디렉션의 인덱싱과 이전 URL의 점진적인 "감소"를 로그 덕분에 쉽게 모니터링할 수 있습니다.
상태 코드 의 변경 사항을 모니터링하는 것이 가장 좋은 동맹이 될 것입니다!
5. 시끄러운 이웃
당신은 훌륭한 SEO이고 당신의 노력이 결실을 맺었습니다!
이것은 당신이 그것을 끌어낸 방법과 당신의 전체 웹사이트를 크롤링하기로 결정한 당신의 경쟁자(그리고 다른 코가 많은 사람들)의 호기심을 불러일으켰습니다.
이것은 나쁘다. 그러나 이상하지 않습니다(정반대로).
이제 당신의 임무는 스누퍼를 찾는 것입니다.
그들 중 가장 교활한 것은 Google user-agents 를 사용하여 봇을 Googlebot으로 가장하려는 것입니다. 그리고 이것은 로그에 저장된 IP 주소 가 매우 유용할 수 있는 곳입니다.
그러나 실제로 공식 Googlebot은 잘 문서화된 IP 주소 범위만 사용합니다. Google은 웹마스터에게 봇 출처를 확인하기 위해 역 DNS 조회를 수행할 것을 권고합니다.
이 테스트가 실패하면 결과(또는 IP 지리 추적 결과)가 수행할 작업을 결정하는 데 도움이 될 수 있습니다.
참고로 Imperva Incapsula의 디지털 보안 전문가는 2016년에 발표된 연구에 따르면 분석된 대역폭의 28.9%가 "나쁜 봇"에 의해 소비되었음을 보여줍니다("좋은 봇"은 22.9%, 사용자는 48.2%). ). 로그를 살펴보면 원치 않는 봇을 감지하여 리소스가 과도하게 소모되는 것을 방지할 수 있습니다.