
潜在的セマンティックインデックスとは何ですか?それはどのように機能しますか?
公開: 2020-04-02潜在意味索引付け(LSI)は、検索マーケターの間で長い間議論の原因となってきました。 グーグルは「潜在的意味索引付け」という用語を使用し、支持者と懐疑論者の両方に同等に遭遇します。 検索エンジンマーケティングの文脈でLSIを検討することの利点についての明確なコンセンサスはありません。 概念に慣れていない場合は、この記事でLSIに関する議論を要約するので、SEO戦略にとってそれが何を意味するのかを理解できれば幸いです。
潜在的セマンティックインデックスとは何ですか?
LSIは、自然言語処理(NLP)に見られるプロセスです。 NLPは言語学と情報工学のサブセットであり、機械が人間の言語をどのように解釈するかに焦点を当てています。 この研究の重要な部分は、分布セマンティクスです。 このモデルは、大規模なデータセット内で同様の文脈上の意味を持つ単語を理解して分類するのに役立ちます。
1980年代に開発されたLSIは、情報検索をより正確にする数学的手法を使用しています。 この方法は、単語間の隠されたコンテキスト関係を識別することによって機能します。 それはあなたがこのようにそれを分解するのを助けるかもしれません:
- 潜在→非表示
- セマンティック→単語間の関係
- 索引付け→情報検索
潜在意味索引付けはどのように機能しますか?
LSIは、特異値分解(SVD)の部分適用を使用して動作します。 SVDは、単純で効率的な計算のために行列をその構成部分に還元する数学演算です。
一連の単語を分析する場合、LSIは接続詞、代名詞、および一般的な動詞(ストップワードとも呼ばれます)を削除します。 これにより、フレーズの主要な「コンテンツ」を構成する単語が分離されます。 これがどのように見えるかの簡単な例を次に示します。
![]()
これらの単語は、用語ドキュメントマトリックス(TDM)に配置されます。 TDMは、データセット内のドキュメントで特定の各単語(または用語)が出現する頻度を一覧表示する2Dグリッドです。
次に、計量機能がTDMに適用されます。 簡単な例は、値が1の単語を含むすべてのドキュメントと、値が0の単語を含まないすべてのドキュメントを分類することです。これらのドキュメントで単語が同じ一般的な頻度で出現する場合、それは共起と呼ばれます。 以下に、TDMの基本的な例と、複数のフレーズにわたる共起を評価する方法を示します。
SVDを使用すると、すべてのドキュメントで単語の使用パターンを概算できます。 LSIによって生成されたSVDベクトルは、個々の用語を分析するよりも正確に意味を予測します。 最終的に、LSIは単語間の関係を使用して、特定のコンテキストでの単語の意味または意味をよりよく理解できます。
[ケーススタディ]ページ上のSEOで新しい市場の成長を促進する
 ケーススタディを読む
ケーススタディを読む潜在意味索引付けはどのようにしてSEOに関与するようになりましたか?
その形成期に、グーグルは検索エンジンが特定のキーワードの頻度に基づいてウェブサイトをランク付けしていることを発見しました。 ただし、これは最も関連性の高い検索結果を保証するものではありません。 Googleは代わりに、信頼できる情報の調停者と見なしたWebサイトのランク付けを開始しました。
時間の経過とともに、Googleのアルゴリズムは、低品質で無関係なWebサイトをより正確に除外します。 したがって、マーケターは、使用されている正確な単語に依存するのではなく、検索の背後にある意味を理解する必要があります。 これが、Roger Monttiが古いSEOの信念に関する記事で、LSIを「検索エンジンの補助輪」と説明した理由であり、LSIは「今日の検索エンジンがWebサイトをランク付けする方法とほとんどまたはまったく関連性がない」と付け加えました。
検索クエリの意味は、その背後にある意図と密接に関連しています。 Googleは、検索品質評価ガイドラインと呼ばれるドキュメントを管理しています。 これらのガイドラインでは、ユーザーの意図に役立つ4つのカテゴリを紹介しています。
- クエリを知る–これはトピックに関する情報を探すことを表します。 これの変形は、ユーザーが特定の答えを念頭に置いて検索しているときの「KnowSimple」クエリです。
- クエリを実行–これは、オンライン購入やダウンロードなどの特定のアクティビティに従事したいという願望を反映しています。 これらのクエリはすべて、「相互作用」の感覚で定義できます。
- ウェブサイトクエリ–これはユーザーが特定のウェブサイトまたはページを探しているときです。 これらの検索は、特定のWebサイトまたはブランドの事前の認識を示しています。
- 個人訪問クエリ–ユーザーは、実店舗やレストランなどの物理的な場所を検索しています。
LSIの背後にある理論(フレーズ内の単語の文脈上の意味を定義する)は、Googleに競争力を与えました。 しかし、「LSIキーワード」が突然SEOの成功への黄金の切符であるという考えが広まり始めました。

「LSIキーワード」は実際に存在しますか?
多くの注目すべき出版物は、LSIキーワードの確固たる支持者であり続けています。 しかし、Googleのウェブマスタートレンドアナリストであるジョンミューラーなどのいくつかの情報源は、それらは神話であると述べています。 これらの情報源は、次の点を提起し始めました。
- LSIは、ワールドワイドウェブの前に開発されたものであり、このような大規模で動的なデータセットに適用することを目的としたものではありません。
- 1989年にBellCommunicationsResearch Inc.という組織に付与された潜在意味索引に関する米国特許は、2008年に失効することになります。したがって、Bill Slawskiによれば、LSIを使用するGoogleは、スマート電信デバイスを使用して接続することに似ています。モバイルウェブ。」
- GoogleはRankBrainを使用しています。これは、大量のテキストを「ベクトル」に変換する機械学習手法です。これは、コンピューターが書かれた言語を理解するのに役立つ数学的エンティティです。 RankBrainは、絶えず拡大するデータセットとしてWebに対応し、LSIとは異なり、Googleで使用できるようにします。
最終的に、LSIは、マーケターが従うべき真実を明らかにします。単語の固有のコンテキストを調査することは、コンテンツに詰め込まれたキーワードよりもユーザーの意図をよりよく理解するのに役立ちます。 ただし、これは必ずしもGoogleがLSIに基づいてランク付けされていることを確認するものではありません。 したがって、LSIは正確な科学ではなく哲学としてSEOで機能すると言っても過言ではありませんか?
「検索エンジンの補助輪」としてのLSIについてのRogerMonttiの引用に戻りましょう。 自転車に乗ることを学ぶと、補助輪を外す傾向があります。 2020年に、Googleは補助輪を使用しなくなったと想定できますか?
Googleの最近のアルゴリズムの更新を検討することができます。 2019年10月、検索担当副社長のPandu Nayakは、GoogleがBERT(トランスフォーマーからの双方向エンコーダー表現)という名前のAIシステムの使用を開始したことを発表しました。 すべての検索クエリの10%以上に影響を及ぼし、これは近年の最大のGoogleアップデートの1つです。
検索クエリを分析するとき、BERTはその特定のフレーズのすべての単語に関連して1つの単語を考慮します。 この分析は、特定の単語の前後のすべての単語を考慮するという点で双方向です。 1つの単語を削除すると、BERTがフレーズの固有のコンテキストを理解する方法に大きな影響を与える可能性があります。
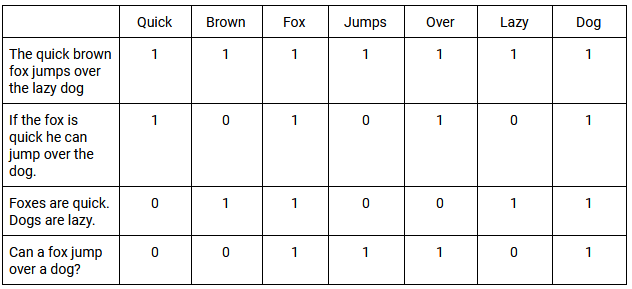
これは、分析からストップワードを省略しているLSIとは対照的です。 次の例は、ストップワードを削除すると、フレーズの理解方法がどのように変わるかを示しています。
![]()
ストップワードであるにもかかわらず、「find」は検索の核心であり、「visit-in-person」クエリとして定義します。
では、マーケターは何をすべきでしょうか?
当初、LSIは、Googleがコンテンツを関連するクエリと照合するのに役立つと考えられていました。 しかし、LSIの使用をめぐるマーケティングの議論はまだ単一の結論に達していないようです。 それにもかかわらず、マーケターは自分たちの仕事が戦略的に適切であり続けることを確実にするためにまだ多くのステップを踏むことができます。
まず、記事、Webコピー、および有料キャンペーンを最適化して、同義語とバリアントを含める必要があります。 これは、同じような意図を持つ人々が言語を異なる方法で使用する方法を説明しています。
マーケターは権威と明快さをもって書き続ける必要があります。 コンテンツで特定の問題を解決したい場合、これは絶対に必要です。 この問題は、情報の不足または特定の製品やサービスの必要性である可能性があります。 マーケターがこれを行うと、それは彼らがユーザーの意図を本当に理解していることを示しています。
最後に、構造化データも頻繁に使用する必要があります。 ウェブサイト、レシピ、FAQのいずれであっても、構造化データは、Googleがクロールしているものを理解するためのコンテキストを提供します。