
[ウェビナーダイジェスト]軌道上のSEO:重複コンテンツに関する新しい視点
公開: 2019-11-20ウェビナー重複コンテンツに関する新しい視点は、SEO in Orbitシリーズの最後のエピソードであり、2019年6月24日に放送されます。このエピソードでは、OnCrawlアンバサダーの近江シドとアレクシスサンダースが重複コンテンツの問題を探求します。 彼らは次のような質問に取り組んでいます。ランキング要素と進化する検索テクノロジーは、重複コンテンツの処理方法にどのように影響しますか? そして:ウェブ上の同様のコンテンツの将来はどうなるのでしょうか?
SEO in Orbitは、SEOを宇宙に送る最初のウェビナーシリーズです。 シリーズ全体を通して、私たちは技術的なSEOの現在と未来について、最高のSEOスペシャリストの何人かと話し合い、2019年6月27日に彼らの最高のヒントを宇宙に送りました。
ここでリプレイを見てください:
アレクシスサンダースのプレゼンテーション
Alexis Sandersは、MerkleでテクニカルSEOアカウントマネージャーとして働いています。 SEO技術チームは、すべての分野にわたる代理店の技術的推奨事項の正確性、実現可能性、および拡張性を保証します。 彼女はMozブログの寄稿者であり、TechnicalSEO.expertチャレンジとLabポッドキャストのSEOの作成者です。
このエピソードは近江シドが主催しました。 近江はベテランの国際的なスピーカーであり、彼のユーモアと聴衆がすぐに使い始めることができる実用的な洞察を提供する能力で業界で知られています。 世界最大の通信会社や旅行会社とのSEOコンサルティングから、HostelWorldやDaily Mailでの社内SEOの管理まで、近江は複雑なデータに飛び込んで明るい場所を見つけるのが大好きです。 現在、近江はキヤノンヨーロッパおよびオンクロールアンバサダーのシニアテクニカルSEOです。
重複コンテンツとは何ですか?
Omiは、重複コンテンツの次の定義を提供します。
同じ(または異なる)Webサイトの異なるURLに存在するコンテンツと類似またはほぼ類似している重複コンテンツ。
重複コンテンツペナルティの神話
重複コンテンツのペナルティはありません。
これはパフォーマンスの問題です。 ボットが2つの特定のURLを調べて、それらが互いに隣り合ってランク付けできる2つの異なるコンテンツであると考えてほしくないのです。
Alexisは、ボットによるWebサイトの理解を、私があなたについて嫌う10のことからのJoeyの写真と比較します。ボットが2つのバージョンの重要な違いを見つけることは不可能です。

あなたは、検索エンジンのランキング状況で互いに競合しなければならない2つのまったく同じものを持つことを避けたいと思っています。 代わりに、検索エンジンでランク付けして実行できる単一の統合されたエクスペリエンスが必要です。
ユーザーとボットが見るものの違い
ユーザーには説得力のある単一のURLが表示される場合がありますが、ボットには基本的に同じように見える複数のバージョンが表示される場合があります。
–非常に大規模なサイトのクロール予算への影響
ZillowやWalmartなどの非常に大規模なサイトの場合、クロールの予算はページごとに異なる可能性があります。
AlexisがSMXEastでのFredericDubutによるプレゼンテーションに基づく2018年の記事で説明したように、予算はさまざまなレベル、つまりサブドメインレベル、さまざまなサーバーレベルで設定されます。 GoogleであろうとBingであろうと、検索エンジンは丁寧なクローラーになりたいと思っています。 実際のユーザーのパフォーマンスを低下させたくないのです。 彼らがパフォーマンスの変化を感じるときはいつでも、彼らは後退します。 これは、サイトレベルだけでなく、さまざまなレベルで発生する可能性があります。
大規模なサイトがある場合は、ユーザーに関連する最も統合されたエクスペリエンスを提供していることを確認する必要があります。
重複コンテンツはコンテンツですか、それとも技術的な問題ですか?
「重複コンテンツ」の「コンテンツ」という言葉にもかかわらず、それは部分的に技術的な問題です。
–重複の原因– [07:50]
重複を引き起こす可能性のある多くの要因があります。 部分的なリストでさえ、永遠に続くように見えることがあります。
- 繰り返しページ
- ステージングサイト
- HTTPとHTTPSのURL
- 異なるサブドメイン
- さまざまなケース
- さまざまなファイル拡張子
- 末尾のスラッシュ
- インデックスページ
- URLパラメータ
- ファセット
- 並べ替え
- プリンター対応バージョン
- 誘導ページ
- 在庫
- シンジケートコンテンツ
- PRリリース
- コンテンツの再公開
- 盗用されたコンテンツ
- ローカライズされたコンテンツ
- 薄いコンテンツ
- のみ-画像
- 内部サイト検索
- 別のモバイルサイト
- ユニークでないコンテンツ
- …
–技術的なSEOとコンテンツ間の問題の配布
実際、これらの重複コンテンツのソースは、技術ソースと開発ソース、およびコンテンツベースのソースに分割でき、一部は2つの間の重複ゾーンに分類されます。
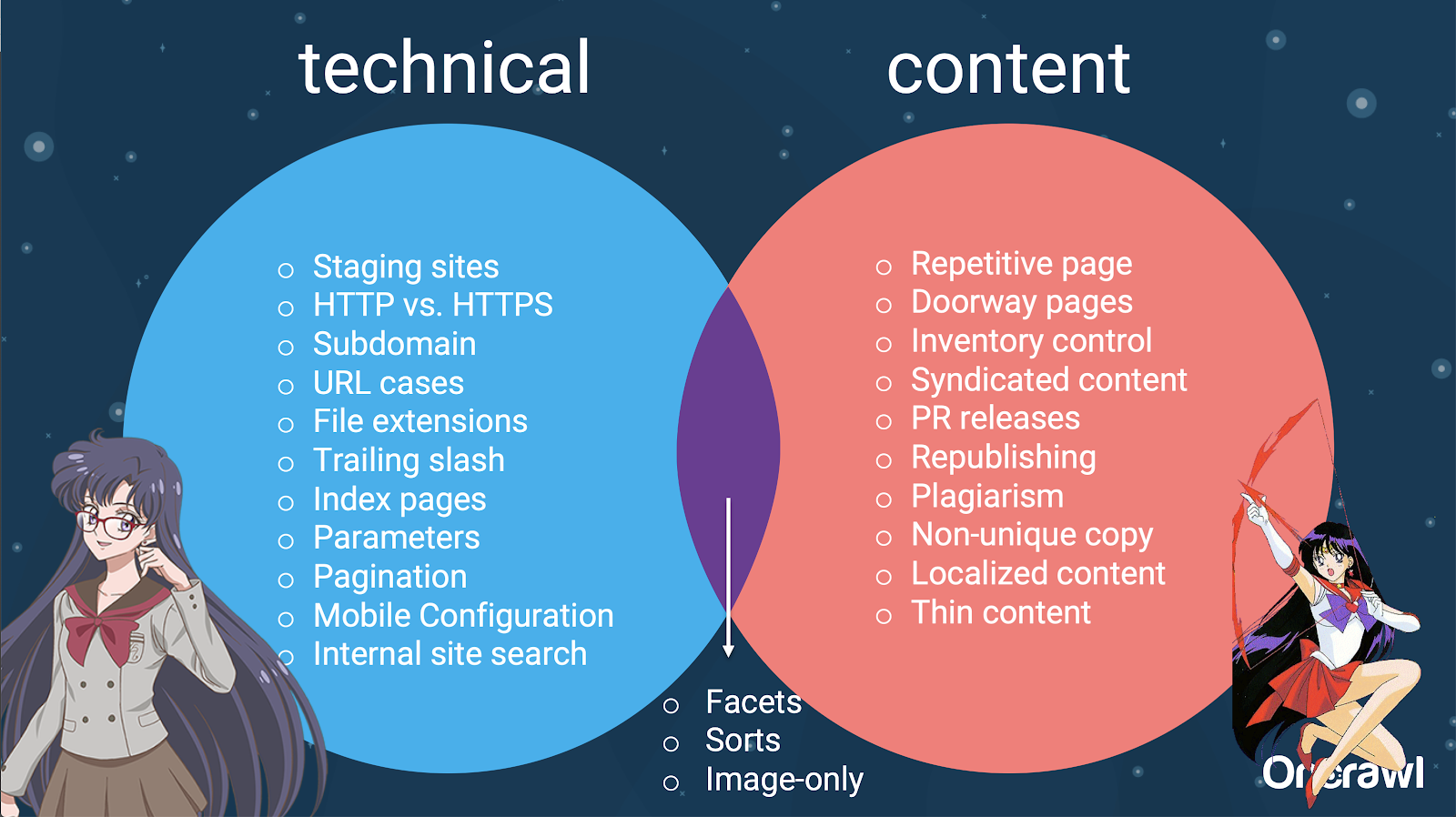
これにより、重複コンテンツがチーム間の問題になり、それが非常に興味深いものになっています。
重複するコンテンツを見つける方法
ほとんどの重複コンテンツは意図的ではありません。 Omiの場合、これは、重複するコンテンツを見つけて修正する責任がコンテンツチームと技術チームの間で共有されていることを示しています。
–近江のお気に入りのツール:Grammarly
Grammarlyは、重複コンテンツを見つけるための近江のお気に入りのツールであり、SEOツールでもありません。 彼は盗用チェッカーを使用しています。 彼は、コンテンツ発行者に、新しいコンテンツがすでに他の場所で発行されているかどうかを確認するように依頼します。
–意図しない重複コンテンツの量
意図しない重複コンテンツの問題は、エンジニアがよく知っている問題です。 明らかに時代遅れのIntroductiontoInformation Retrieval(2008)と呼ばれる本で、彼らは当時のWebの約40%が複製されたと推定しました。

–重複コンテンツを処理するための戦略の優先順位付け
重複するコンテンツを処理するには、次のことを行う必要があります。
- ユーザージャーニーを知ることから始めます。これは、すべてのコンテンツがどこに適合するかを理解するのに役立ちます。 これを行うのは非常に難しい場合があります。特に、20年前にウェブサイトが作成された場合、ウェブサイトのサイズや規模がわからなかった場合はなおさらです。 ユーザーが旅のどの時点にいるかを知ることは、次のステップのいくつかで優先順位を付けるのに役立ちます。
- 各タイプのコンテンツの場所を提供するために、機能する階層が必要になります。 重複コンテンツを処理するためのステップでは、情報アーキテクチャを理解することが非常に重要です。
- パフォーマンスに影響を与える重複コンテンツに優先順位を付けます。 上記のソースの部分的なリストは長すぎて、現実的に一度に攻撃できるものにはなりません。
- 100%の重複に対処する
- 重複コンテンツを通知する
- 重複の処理方法について戦略的な選択を行います:統合、作成、削除、最適化
- 盗まれたコンテンツに対処する

–ツール:OnCrawlでのセグメンテーションの使用
Alexisは、OnCrawlでWebサイトをセグメント化する機能を非常に気に入っています。これにより、自分にとって意味のあることに飛び込むことができます。
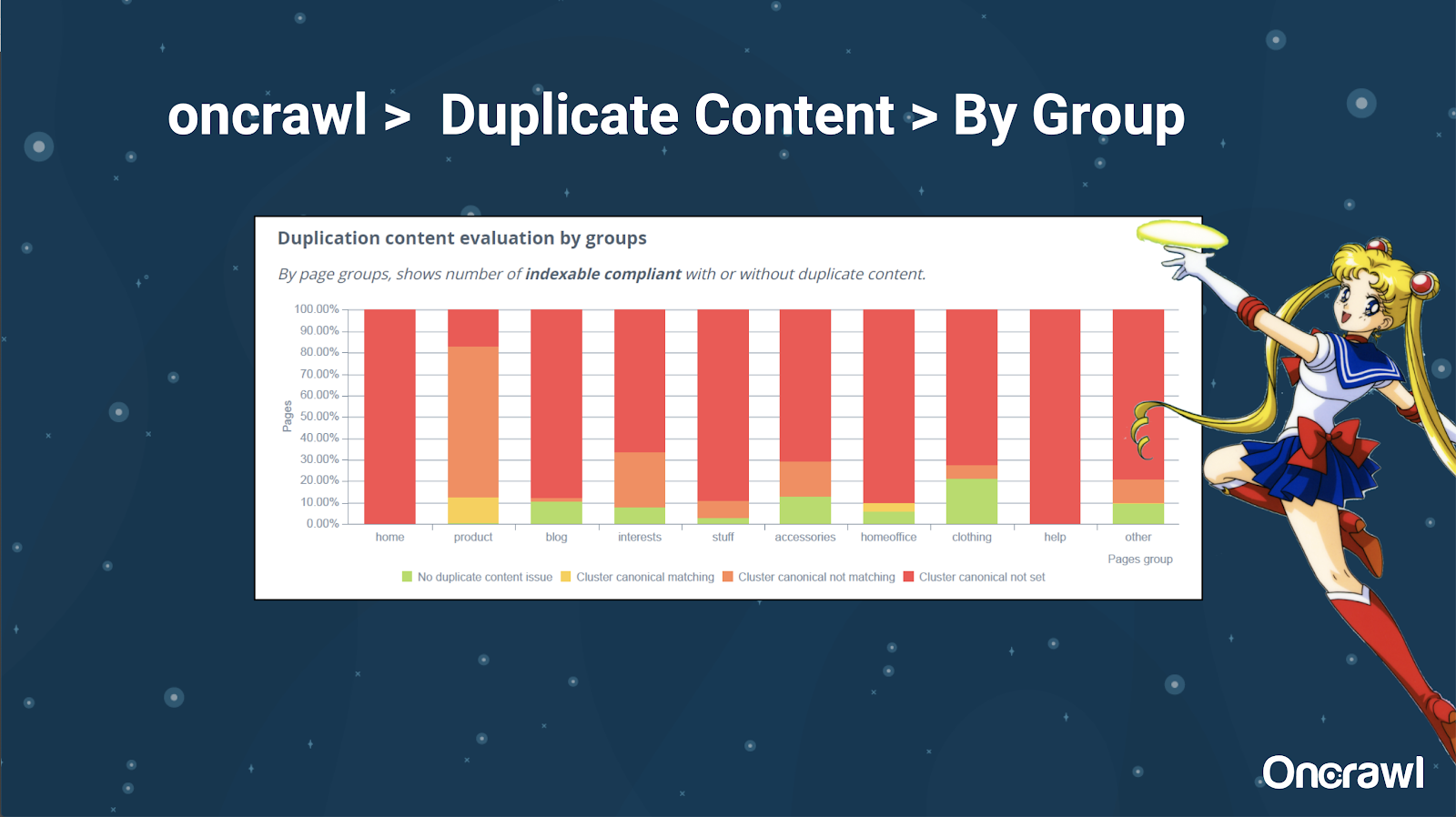
ページの種類が異なれば、重複の量も異なります。 これにより、最も問題のあるセクションを表示できます。 上記の例では、サイトに多くの注意が必要です。
–ツール:Google検索とGSC
検索エンジン自体を使用して、重複するコンテンツをチェックすることもできます。 Googleでは次のことができます。
- 直接引用符を使用する
- サイトを使用:検索
- inurl:、intitle:、filetypeなどの追加の演算子を使用する:

Google Search Consoleには、重複コンテンツレポートも追加されています。これは、Googleが重複コンテンツであるとGoogleが信じているものを特定するのに非常に役立ちます。
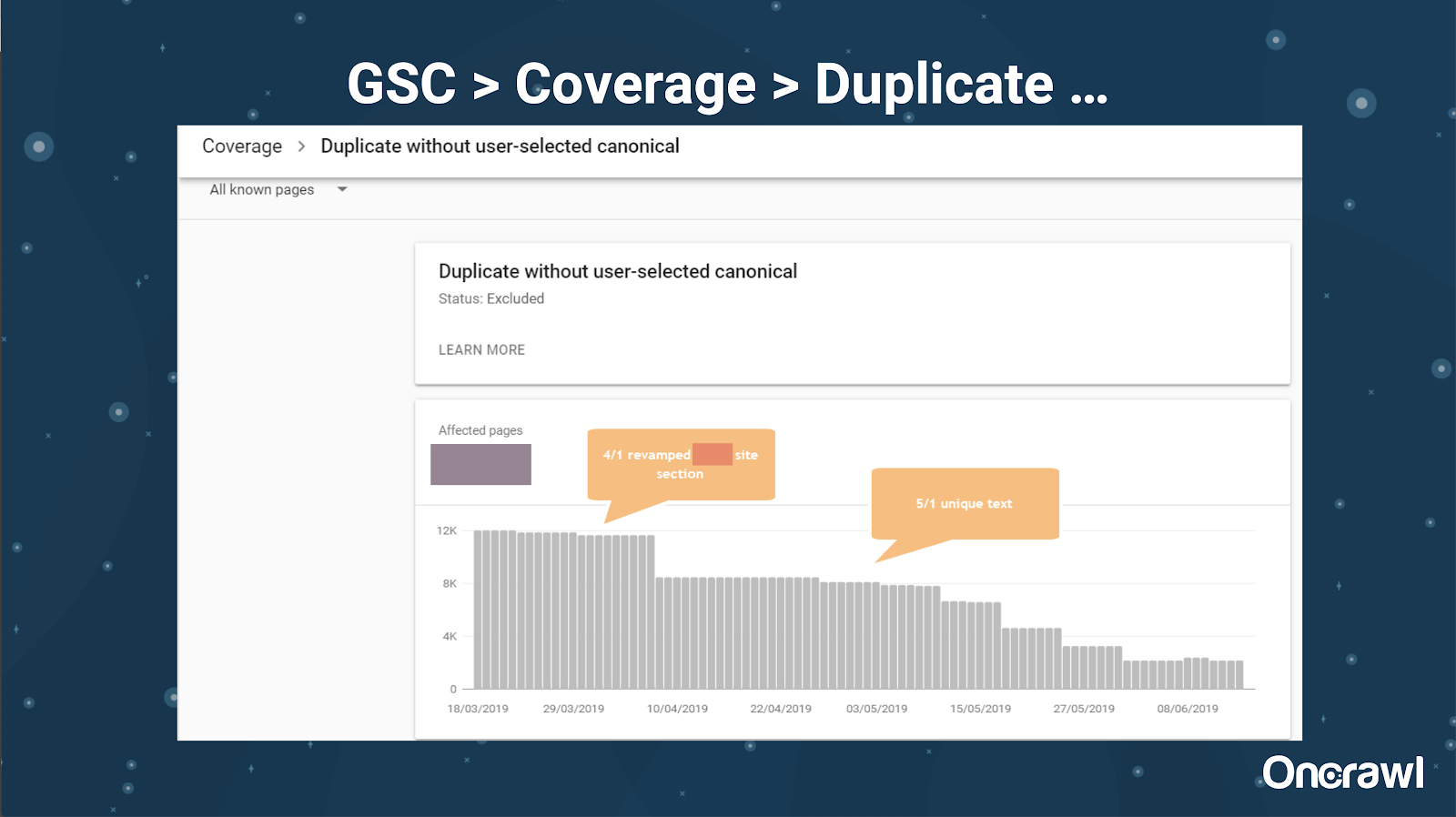
–ツール:盗用ツール
近江と同様に、Alexisもさまざまな盗用ツールを使用しています。
Quetext
Noplag
PaperRater
Grammarly
CopyScape
コンテンツがオリジナルであるだけでなく、ボットの観点からも、別のソースから引き出されたものとして認識されていないことを確認する必要があります。
これらは、インターネット上の他の場所のコンテンツに類似している可能性のある記事内のセグメントを見つけるのにも役立ちます。

Alexisは、私たちの誰もがロボットではないため、「検索エンジンボットに共感する」ことができるこれらのツールをどのように持っているかを気に入っています。 ツールがコンテンツがあまりにも類似しているというシグナルを私たちに与えるとき、たとえ違いがあることを知っていても、それはそこに掘り下げる何かがあるという良い兆候です。
–ツール:キーワード密度ツール
Alexisが使用するキーワード密度ツールの2つの例は次のとおりです。
TagCrowd
SEObook
サイトの種類に応じた問題
重複するコンテンツの解決は、公開しているコンテンツの種類と直面している問題の種類によって異なります。 たとえば、ブログはeコマースサイトと同じ重複コンテンツのケースに直面していません。
思い出に残るケース
Alexisは、記憶に残る重複コンテンツの問題を見つけた最近のクライアントの事例を共有しています。
–非常に大規模なサイト:独自のコンテンツを追加した後の結果
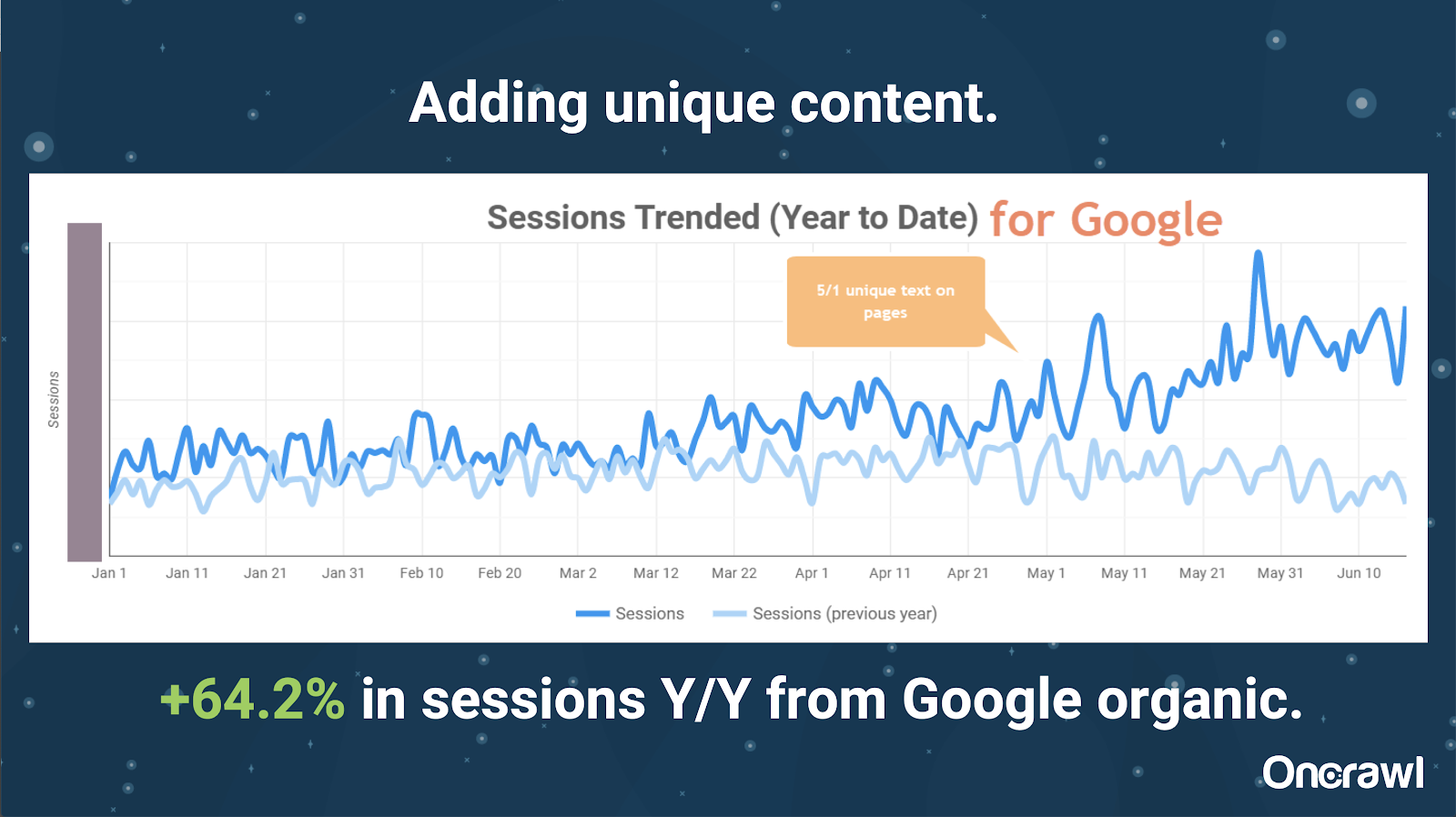
このサイトは非常に大きく、クロール予算の問題が発生しています。 まだインデックスに登録されていない8600万ページがあり、そのページの約1%しかインデックスに登録されていません。
これは不動産サイトであるため、コンテンツの多くは特にユニークではなく、ページの多くは非常によく似ています。 Alexisは、ページを区別するために場所固有の情報を追加するために、ページにコンテンツを追加することになりました。 これがどれほど迅速に結果を生み出したかは驚くべきことでした。 (これは単なるGoogleのオーガニックデータです。)
Alexisにとって、これはかなり一般的なケーススタディです。 今日私たちがEATや同様のことについて話しているのと同じように、これは検索エンジンがコンテンツをユニークで価値のあるものと見なすとすぐに、それはまだ報われていることを示しています。

このサイトでは、偶発的な正規タグの問題により、約250ページが間違ったプロトコルに送信されました。
これは、正規タグが間違ったプリンシパルページを示し、HTTPSページの代わりにHTTPページをプッシュする1つのケースです。
過去18か月の変化
Alexisは、このウェビナーの約18か月前に、非常に完全な記事「重複コンテンツと戦略的解決策」を作成しました。 SEOは急速に変化するため、知識を常に更新して再評価する必要があります。
Alexisの場合、rel = next / prevを除いて、記事に記載されている内容のほとんどは今日でも関連しています。 しかし、彼女はそれが今後5年から10年以内に関連性がなくなることを望んでいます。
開発者が扱う技術的な問題:手動すぎる
開発者によって処理される重複コンテンツに関連する問題の多くは、あまりにも手動です。 Alexisは、代わりにCMSとAdobeで処理する必要があると考えています。 たとえば、手動で実行して、すべてのカノニカルが設定され、一貫していることを確認する必要はありません。
–自動化/通知の機会
重複コンテンツに関する技術的な問題の分野では、自動化の機会がたくさんあります。 例を挙げると、HTTPSに接続する必要があるときに、HTTPに接続するリンクがあるかどうかをすぐに検出し、修正できるはずです。
–障害としてのサイトの時代とレガシーインフラストラクチャ
一部のバックエンドシステムは古すぎて、特定の変更や自動化をサポートできません。 古いCMSを新しいCMSに移行することは非常に困難です。 近江は、キヤノンのWebサイトを新しいカスタムビルドのCMSに移行する例を示しています。 高価なだけでなく、12ヶ月もかかりました。
Rel prev/nextとGoogleからのコミュニケーション
Googleからの通信が少し混乱することがあります。 近江は、rel = prev / nextを適用する際に、これらのタグが何年も使用されていないというGoogleの2019年の発表にもかかわらず、彼のクライアントが2018年にパフォーマンスの大幅な向上を見た例を引用しています。
–万能のソリューションの欠如
SEOの難しさは、ある人が自分のWebサイトで起こっていることを観察することは、別のSEOが自分のWebサイトで見ることと必ずしも同じではないということです。 万能のSEOはありません。
すべてのSEOに関連するアナウンスを行うGoogleの機能は、大きな偉業として認識されるべきです。rel= next / prevの場合のように、それらのステートメントの一部でさえミスです。
重複コンテンツ管理の将来への期待
アレクシスの将来への希望:
- 技術ベースの重複コンテンツが少ない(CMSが賢明であるため)。
- より多くの自動化(単体テストと外部テスト)。 たとえば、OnCrawlなどのツールは定期的にサイトをクロールし、特定のエラーに気付くとすぐに通知する場合があります。
- ライターとコンテンツマネージャーの類似性の高いページとページタイプを自動的に検出します。 これにより、Grammarlyなどのツールで現在手動で行われている検証の一部が自動化されます。誰かが公開しようとすると、CMSは「これは似たようなものです。これを公開してもよろしいですか?」と言う必要があります。 単一のWebサイトだけでなく、Webサイト間の比較にも多くの価値があります。
- Googleは、既存のシステムと検出を改善し続けています。
- おそらく、適切な正規を使用していないGoogleの問題をエスカレートするためのアラートシステム。 この問題についてGoogleに警告し、問題を解決できると便利です。
より優れたツール、より優れた内部ツールが必要ですが、Googleがシステムを開発するにつれて、少しでも役立つ要素が追加されることを願っています。
アレクシスのお気に入りの技術的なトリック
Alexisにはいくつかのお気に入りの技術的なトリックがあります。
- EC2リモートコンピューターインスタンス。 これは、非常に大規模なクロールや、多くの計算能力を必要とするもののために、実際のコンピューターにアクセスするための非常に優れた方法です。 一度設定すると非常に高速です。 お金がかかるので、終わったら必ず終了してください。
- モバイルファーストテストツールを確認してください。 グーグルは、これが彼らが見ているものの最も正確な絵であると述べました。 DOMを調べます。
- ユーザーエージェントをGooglebotに切り替えます。 これにより、Googlebotが実際に何を見ているのかがわかります。
- TechnicalSEO.comのrobots.txtツールを使用します。 これはMerkleのツールの1つですが、robots.txtは時々非常に混乱する可能性があるため、Alexisは本当にそれを気に入っています。
- ログアナライザーを使用します。
- Loveのhtaccessチェッカーで作られました。
- Google Data Studioを使用して変更をレポートします(シートを更新と同期し、関連する更新で各ページをフィルタリングします)。
技術的なSEOの難しさ:robots.txt
Robots.txtは本当に紛らわしいです。
これは、正規表現をサポートできるはずの古風なファイルですが、サポートしていません。
許可ルールと許可ルールには異なる優先順位ルールがあり、混乱を招く可能性があります。
ボットが異なれば、想定されていなくても、さまざまなことを無視できます。
何が正しいかについてのあなたの仮定は必ずしも正しいとは限りません。

Q&A
– HSTS:分割プロトコルが必要ですか?
HSTSを使用している場合は、重複するコンテンツに対してすべてのHTTPSを使用する必要があります。
–翻訳されたコンテンツは重複コンテンツですか?
多くの場合、hreflangを使用しているときは、米国とアイルランドの英語のページなど、同じ言語内のローカライズされたバージョンを明確にするために使用しています。 Alexisはこの重複コンテンツを考慮しませんが、これが同じエクスペリエンスであり、さまざまなオーディエンス向けに最適化されていることを示すために、hreflangタグが正しく設定されていることを確認することを強くお勧めします。
– HTTP / HTTPS移行に301リダイレクトの代わりに正規タグを使用できますか?
SERPで実際に何が起こっているかを確認すると便利です。 アレクシスの本能は、これは大丈夫だと言うことですが、それはグーグルが実際にどのように振る舞うかに依存します。 理想的には、これらがまったく同じページである場合は、301を使用することをお勧めしますが、彼女は過去にこのタイプの移行で正規タグが機能することを確認しました。 彼女は実際にこれが偶然に起こるのを見たことがあります。
近江の経験では、問題を回避するために301を使用することを強くお勧めします。Webサイトを移行する場合は、現在および将来のエラーを回避するために正しく移行することをお勧めします。
–重複するページタイトルの影響
場所によってタイトルが非常に似ているが、内容が非常に異なるとします。 これはAlexisと重複するコンテンツではありませんが、検索エンジンはこれを「全体的な」タイプのものとして扱っていると彼女は考えています。タイトルは、問題が発生する可能性のある領域を特定するために使用できるものです。
ここで、[site:+ intitle:]検索を使用できます。
ただし、同じタイトルタグを使用しているからといって、重複コンテンツの問題が発生することはありません。
ページ付けされたページや他の非常に類似したページであっても、独自のタイトルとメタディスクリプションを目指す必要があります。 これはコンテンツの重複によるものではなく、SERPでのページの表示方法を最適化する方法に関係しています。
トップチップ
「重複コンテンツは、技術的およびコンテンツマーケティングの課題です。」
軌道上のSEOは宇宙に行きました
6月27日に宇宙への航海を逃した場合は、ここでそれをキャッチして、宇宙に送ったすべてのヒントを見つけてください。