
Pythonとサイトマップを使用したコンテンツ戦略の監査
公開: 2020-10-08Pythonライブラリを使用してSEOに代わって実行できることへの関心は、もはや秘密ではありません。 ただし、プログラミングの経験がほとんどないほとんどの人は、多数のライブラリをインポートして使用したり、プッシュしたりするのが困難であり、通常のクローラーやSEOツールで実行できる以上の結果が得られます。
これが、SEO、SEM、SMO、SERPチェック、およびコンテンツ分析のために特別に作成されたPythonライブラリがすべての人に役立つ理由です。
この記事では、EliasDabbasによって作成および開発されたAdvertoolsPython Library for SEOで実行できるいくつかのことを見ていきます。これらの機能については、SEO、PPC、およびコーディング機能に大きな可能性があります。非常に短い時間で。 また、教育的かつ適応的な方法で、カスタムPythonスクリプトを他のPythonライブラリと一緒に使用します。
XMLサイトマップのダウンロードと分析に役立つEliasDabbasのsitemap_to_df関数のおかげで、サイトマップからSEOについて何を学ぶことができるかを調べます(サイトマップは、クロール可能およびインデックス可能なURLを検索エンジンに報告するために使用されるXML形式のドキュメントです)。
この記事では、さまざまなWebサイトをさまざまな構造に従って分析するためのカスタムPythonコードを作成する方法、SEOの観点からデータを解釈する方法、コンテンツプロファイル、URL、サイト構造に関して検索エンジンのように考える方法について説明します。 。
サイトマップに基づいたWebサイトのコンテンツスケールと戦略の分析
サイトマップは、Webサイトがコンテンツを公開する頻度、コンテンツのカテゴリ、公開日、作成者情報、コンテンツの件名など、さまざまな種類のデータをキャプチャできるWebサイトのコンポーネントです。
通常の状態では、scrapyを使用してサイトマップをスクレイプし、Pandasを使用してDataFrameに変換し、必要に応じてさまざまな補助ライブラリを使用して解釈できます。
ただし、この記事では、Advertoolsと一部のPandasライブラリのメソッドと属性のみを使用します。 一部のライブラリは、取得したデータを視覚化するためにアクティブ化されます。
すぐに飛び込んで、サイトマップを使用していくつかの重要なSEOの洞察を結論付けるWebサイトを選択しましょう。
Advertoolsを使用してサイトマップからデータフレームを抽出および作成する
Advertoolsでは、1行のコードで、Webサイトのすべてのサイトマップを検出、参照、および組み合わせることができます。
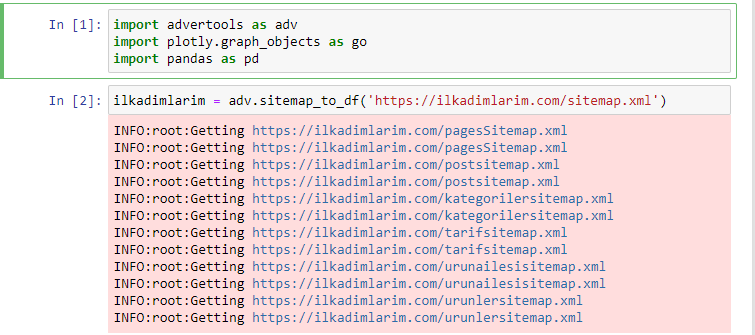
通常のコードエディタやIDEの代わりにJupyterNotebookを使用するのが大好きです。
最初のセルには、データを収集および整理するためのPandasとAdvertools、およびデータを視覚化するためのPlotly.graph_objectsをインポートしました。
adv.sitemap_to_df('sitemap address')コマンドは、単にすべてのサイトマップを収集し、それらをDataFrameとして統合します。
PandasとAdvertoolsを使用して同じことを行うと、どのサイトマップでどのURLが利用可能かを見つけることができます。
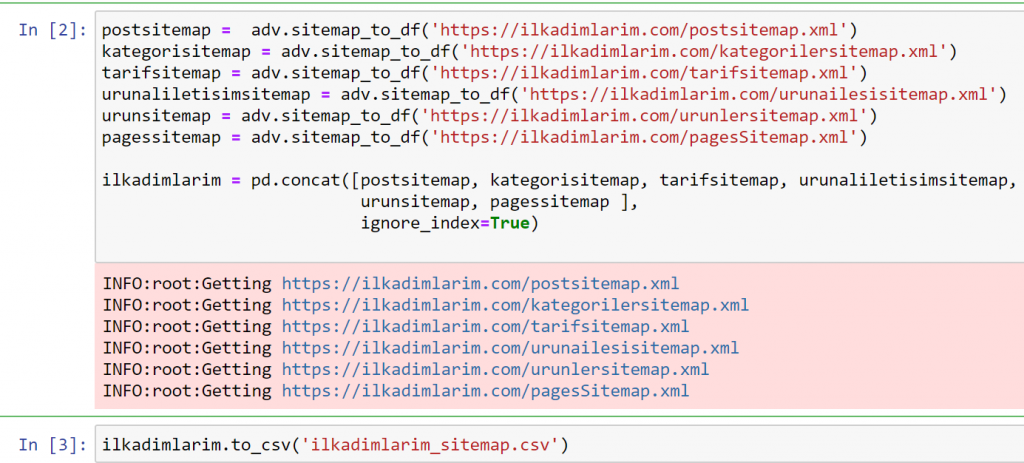
上記の例では、同じサイトマップを個別に取得してから、それらをpd.concatコマンドと組み合わせて、結果をCSVに転送しました。 前の例では、サイトマップインデックスファイルを使用しました。この場合、関数は他のすべてのサイトマップを取得します。 したがって、Webサイトの特定のセクションに関心がある場合は、ここで行ったように特定のサイトマップを選択するオプションがあります。
上記のサイトマップ名が異なる列が表示されます。 ignore_index = Trueセクションは、複数のDataFrameをマージした場合に、異なるDataFrameのインデックス番号を整理するためのものです。
オンクロールデータ³
 もっと詳しく知る
もっと詳しく知るPythonを使用したコンテンツ分析のためのサイトマップデータフレームのクリーニングと準備
サイトマップを通じてWebサイトのコンテンツプロファイルを理解するには、Advertoolsで取得したDataFrameを確認するためにWebサイトを準備する必要があります。
Pandasライブラリのいくつかの基本的なコマンドを使用して、データを形成します。
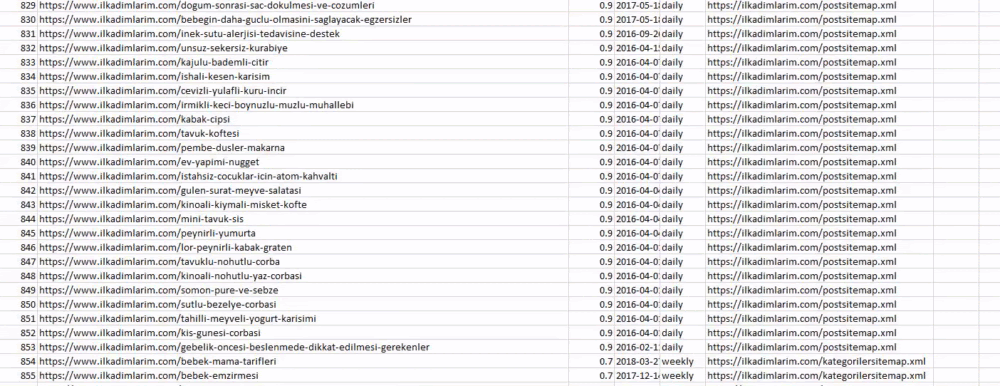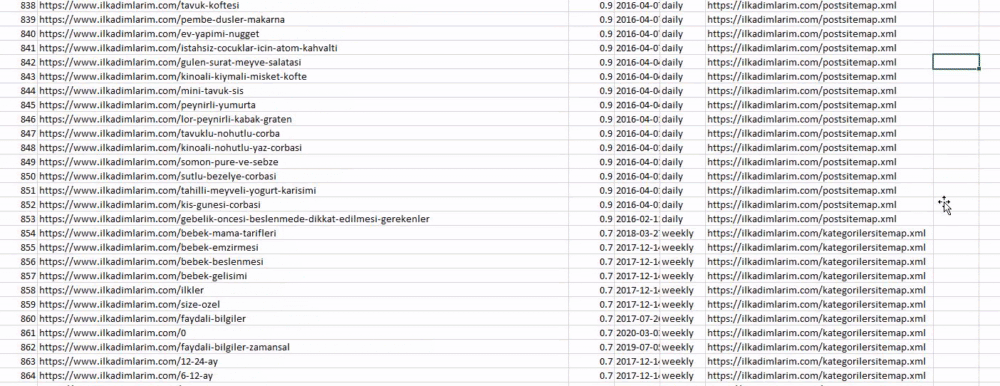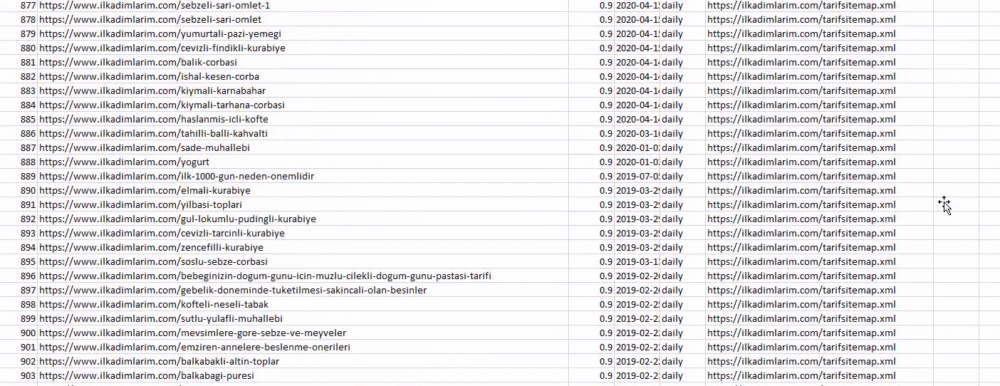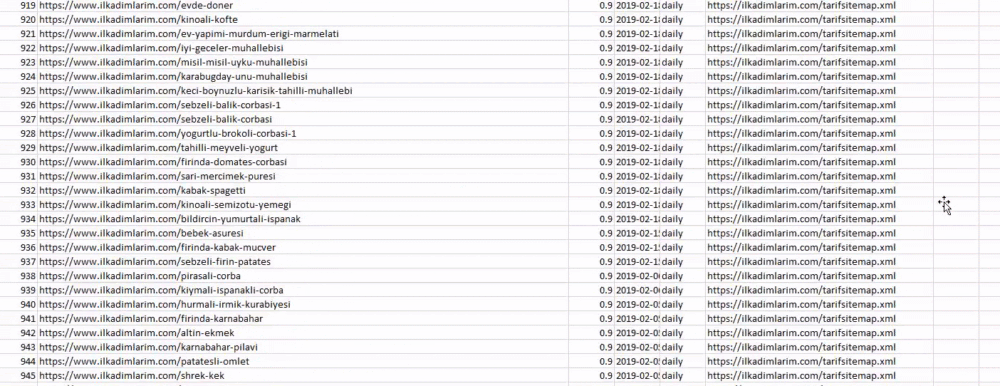
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columns ='名前なし:0')
ilkadimlarim ['lastmod'] = pd.to_datetime(ilkadimlarim ['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
「Ilkadimlarim」はトルコ語で「私の最初のステップ」を意味し、ご想像のとおり、赤ちゃん、妊娠、母性のための場所です。
これらのラインで3つの操作を実行しました。
- 名前なし:DataFrameから0という名前の空の列を削除しました。 また、 pd.to_csv()関数で「index = False」を使用すると、この「名前のない0」列は最初に表示されません。
- [最終変更]列のデータを日時に変換しました。
- 「lastmod」列をインデックス位置に移動しました。
以下に、DataFrameの最終バージョンを示します。
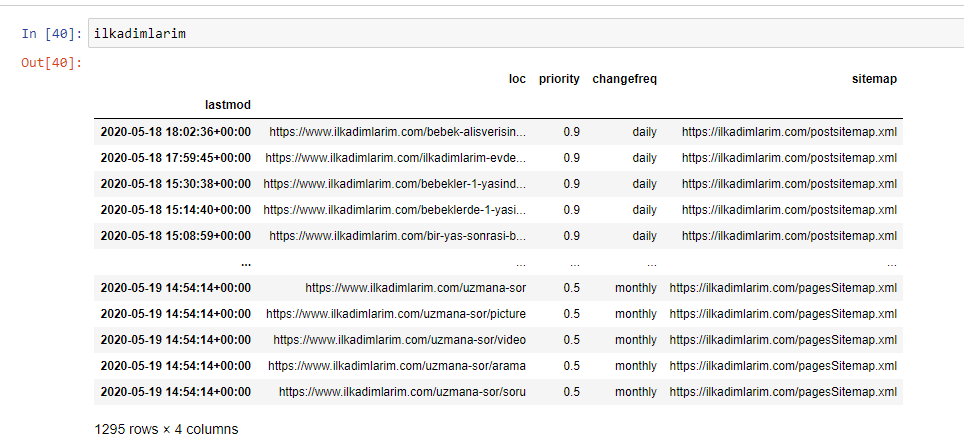
Googleは優先度を使用せず、サイトマップから頻度情報を変更しないことを私たちは知っています。 彼らはそれを「ノイズの袋」と呼んでいます。 ただし、他の検索エンジンでWebサイトのパフォーマンスを重視する場合は、それらを調べることも役立つ場合があります。 個人的には、このデータについてはあまり気にしませんが、DataFrameから削除する必要はありません。
別の列にサイトマップを分類するには、もう1行のコード行が必要です。
ilkadimlarim ['sitemap_cat'] = ilkadimlarim ['sitemap']。str.split('/').str [3]
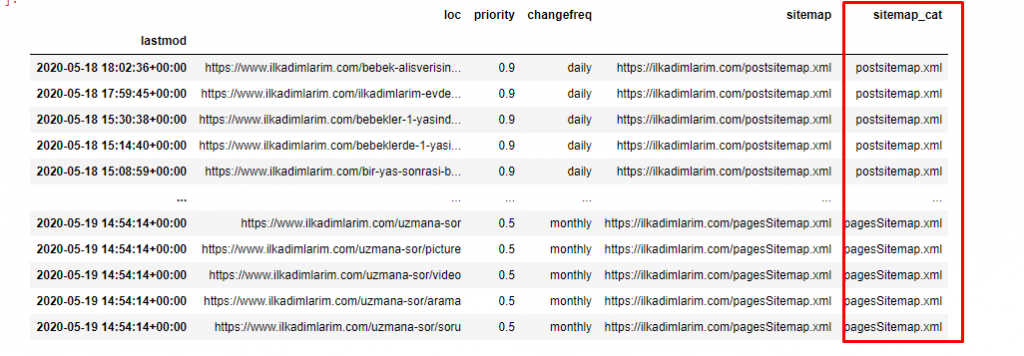
Pandasでは、DataFrameに新しい列または行を追加したり、それらを簡単に更新したりできます。 DataFrame['new_columns']コードスニペットを使用して新しい列を作成しました。 DataFrame ['column_name']。strを使用すると、列のデータ型を変更することでさまざまな操作を実行できます。 .split('/')に関連する列の文字列データを/文字で割り、リストに入れます。 .str [number]を使用して、そのリスト内の特定の要素を選択することにより、新しい列のコンテンツを作成します。
サイトマップの数と種類に応じたコンテンツプロファイル分析
サイトマップをタイプに応じて異なる列に配置した後、各サイトマップに含まれるコンテンツの割合を確認できます。 したがって、Webサイトのどの部分がより重要であるかを推測することもできます。
ilkadimlarim ['sitemap_cat']。value_counts(normalize = True)* 100
- DataFrame ['column_name']は、プロセスを作成する列を選択しています。
- value_counts()は、列の値の頻度をカウントします。
- normalize = Trueは、10進数の値の比率を取ります。
- * 100で10進数を大きくすることで、読みやすくします。
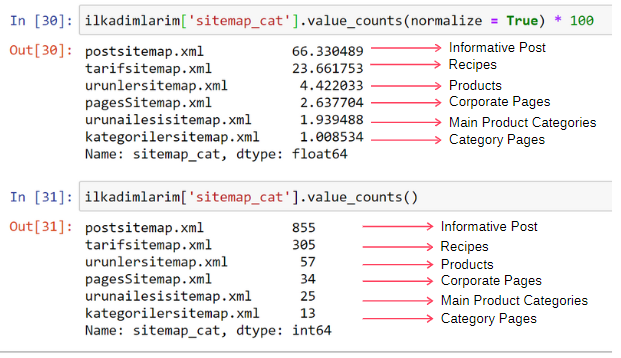
コンテンツの65%がポストサイトマップにあり、23%がレシピサイトマップにあることがわかります。 製品サイトマップには、コンテンツの2%しかありません。
これは、幅広いオーディエンスが自社製品を販売するための有益なコンテンツを作成する必要があるWebサイトがあることを示しています。 私たちの論文が正しいかどうかを確認しましょう。
先に進む前に、ilkadimlarim['sitemap_cat']列の名前を次のコードで'URL_Count'に変更する必要があります。
ilkadimlarim.rename(columns = {'sitemap_cat':'URL_Count'}、inplace = True)
- rename()関数は、データを接続するための列またはインデックスの名前と、より深いレベルでのその意味を変更するのに役立ちます。
- 'inplace = True'属性のおかげで、列名を永続的に変更しました。
- ilkadimlarim.rename(str.capitalize、axis ='columns'、inplace = True)を使用して、列とインデックスの文字スタイルを変更することもできます。 これは、Ilkadimlarimのすべての列の大文字として最初の文字のみを書き込みます。

さて、先に進むことができます。
この情報を1つのフレームで表示するには、次のコードを使用できます。
(ilkadimlarim ['sitemap_cat']
.value_counts()
。フレームへ移動()
.assign(percentage = lambda df:df ['sitemap_cat']。div(df ['sitemap_cat']。sum()))
.style.format(dict(sitemap_cat ='{:,}'、percentage ='{:. 1%}')))
- to_frame()は、選択した列のvalue_counts()によって測定された値をフレーム化するために使用されます。
- Assign()は、フレームに特定の値を追加するために使用されます。
- lambdaは、Pythonの無名関数を指します。
- ここで、Lambda関数とサイトマップタイプは、Pandas div()メソッドによってサイトマップの総数で除算されます。
- style()は、指定された最終値がどのように書き込まれるかを決定します。
- ここでは、 format()メソッドを使用して、ピリオドの後に書き込まれる桁数を設定します。
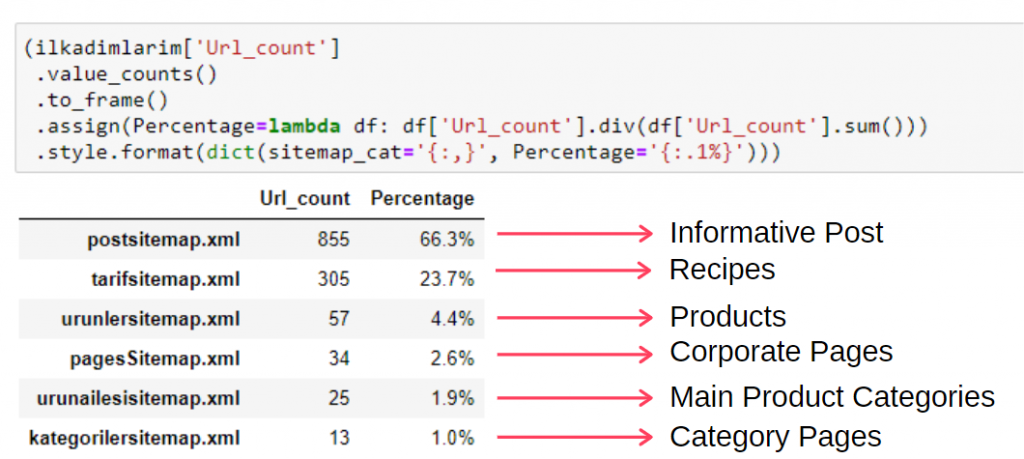
したがって、このWebサイトのコンテンツマーケティングの重要性を認識しています。 また、2行のコードで記事の発行傾向を年ごとに確認して、状況をより深く調べることもできます。
サイトマップとPythonを介した年ごとのコンテンツ発行トレンドの調査と視覚化
サイトマップのカテゴリに従って、調査したWebサイトのコンテンツとインテントのマッチングを行いましたが、時間ベースの分類はまだ行っていません。 これを実現するために、 resample()メソッドを使用します。
post_per_month = ilkadimlarim.resample('A')['loc']。count()
post_per_month.to_frame()
Resampleは、Pandasライブラリのメソッドです。 resample('A')は、データ系列の年次DataFrameをチェックします。 数週間は「W」を使用でき、数か月は「M」を使用できます。
ここの場所はインデックスを象徴しています。 countは、データ例の合計をカウントすることを意味します。
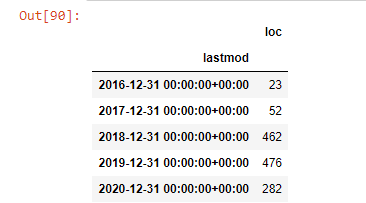
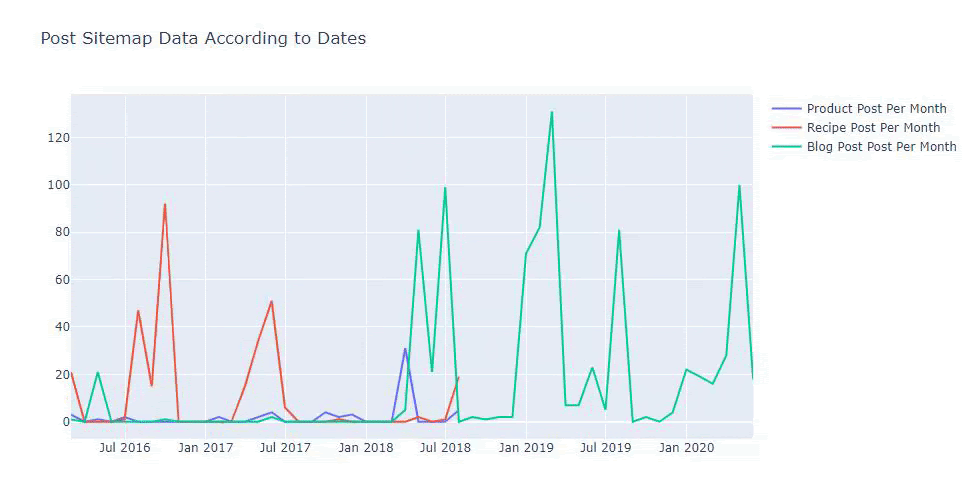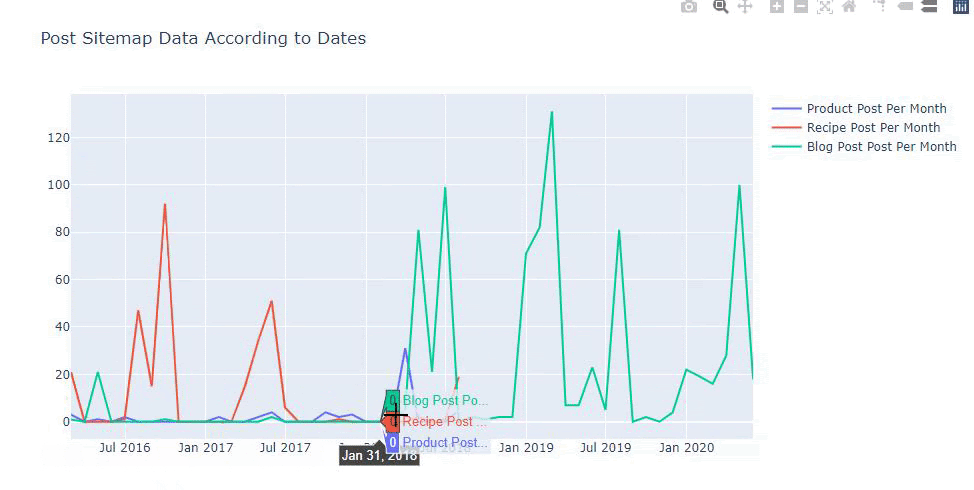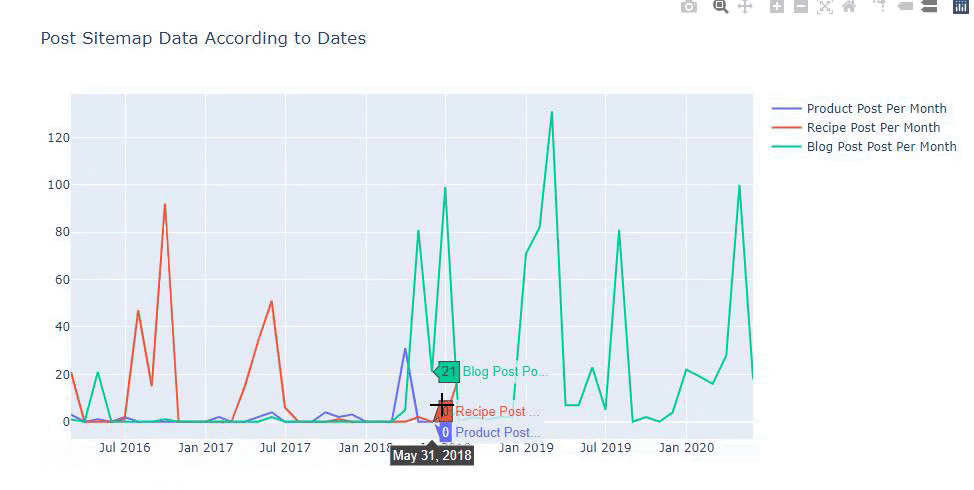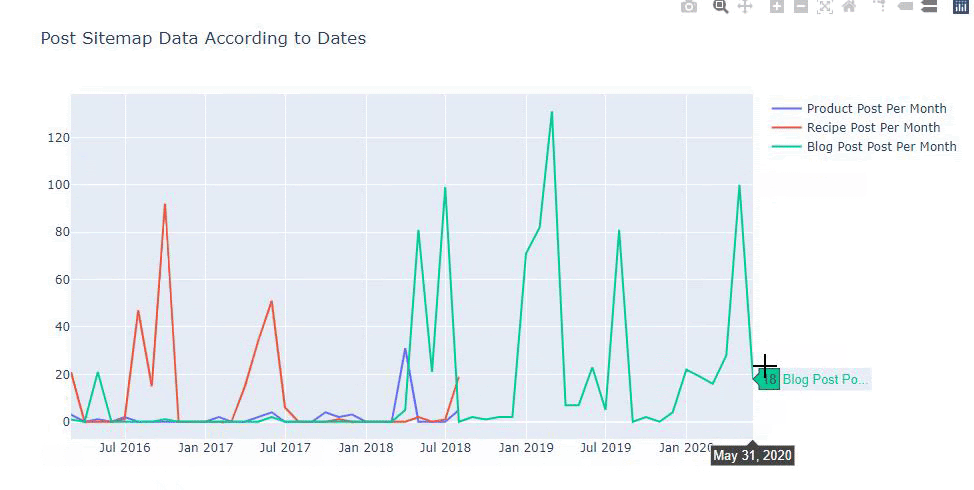
2016年に記事の公開を開始しましたが、2017年以降、主な公開傾向が高まっています。PlotlyGraph Objectsを使用して、これをグラフィックに組み込むこともできます。
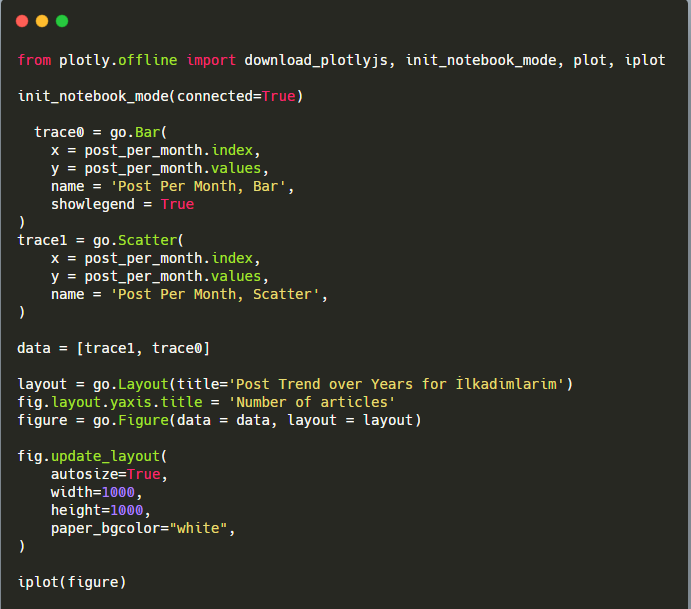
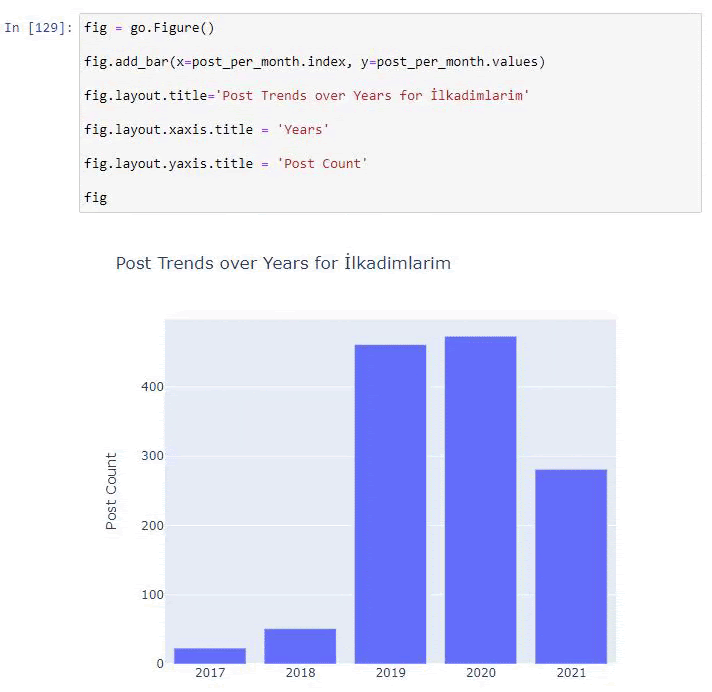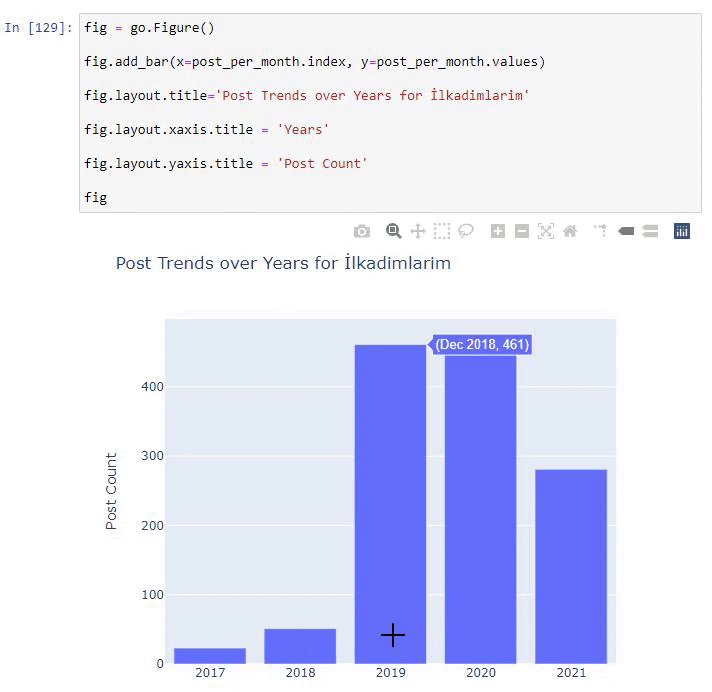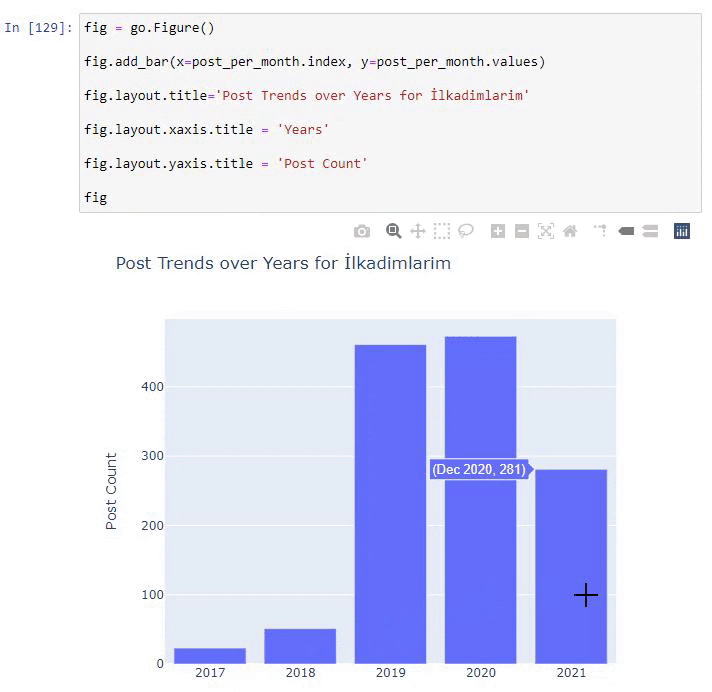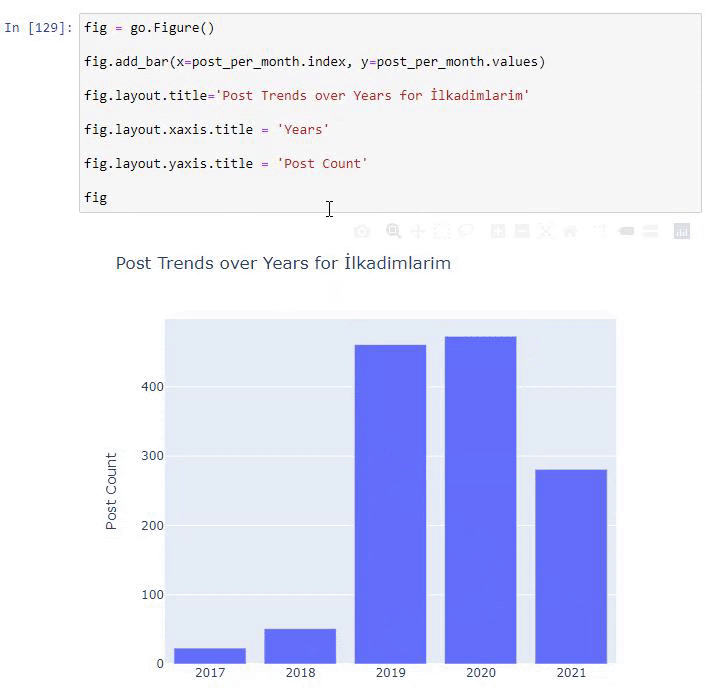
このプロット棒グラフのコードスニペットの説明:
- fig = go.Figure()は、フィギュアを作成するためのものです。
- fig.add_bar()は、図に棒グラフを追加するためのものです。 また、括弧内のX軸とY軸も決定します。
- Fig.layoutは、FigureとAxesの一般的なタイトルを作成するためのものです。
- 最後の行で、goと等しいfigコマンドで作成したプロットを呼び出しています。Figure()
以下に、散布図と棒グラフを使用した、月ごとの同じデータを示します。
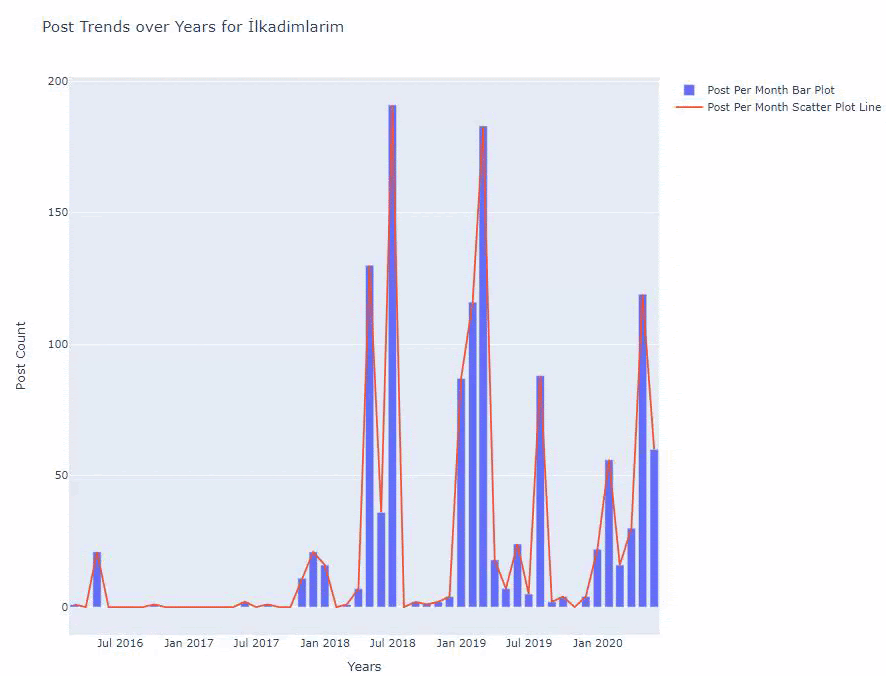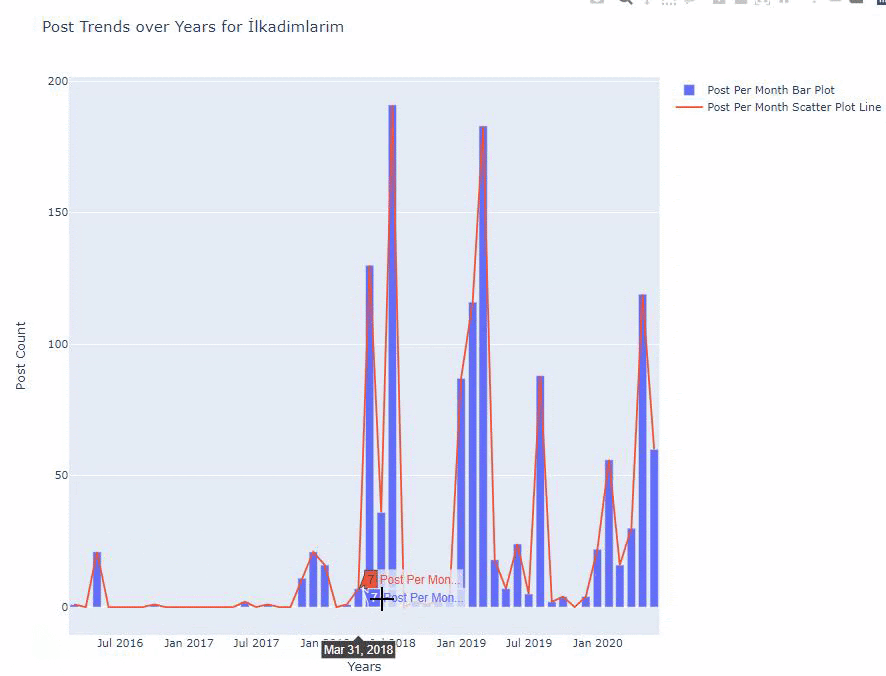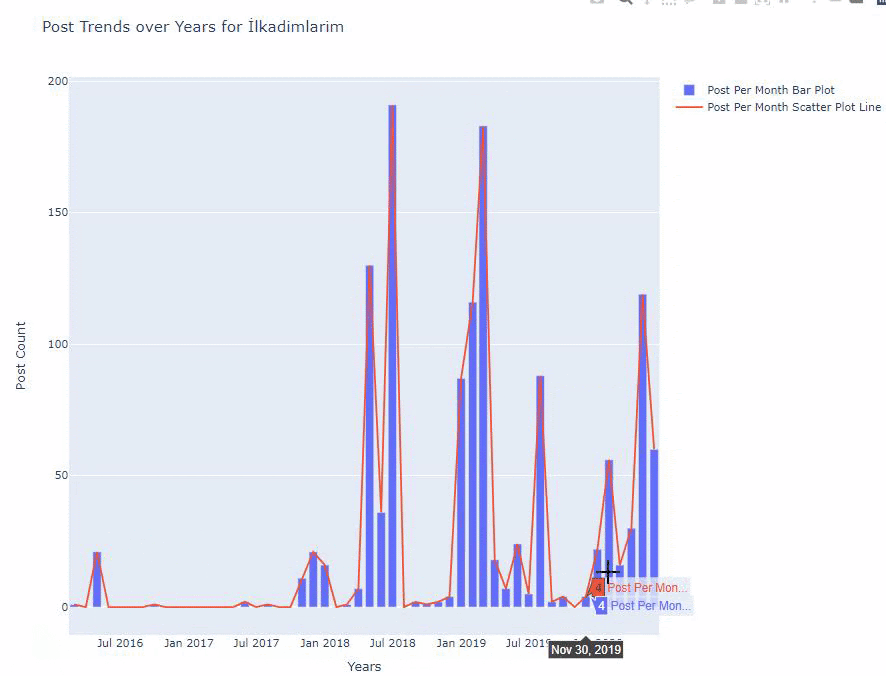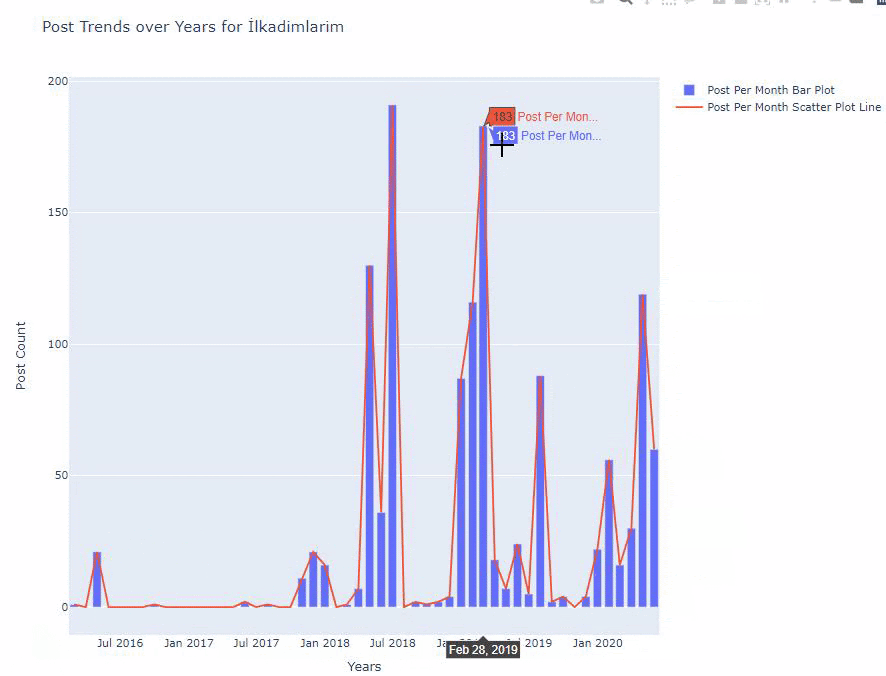
この図を作成するためのコードは次のとおりです。
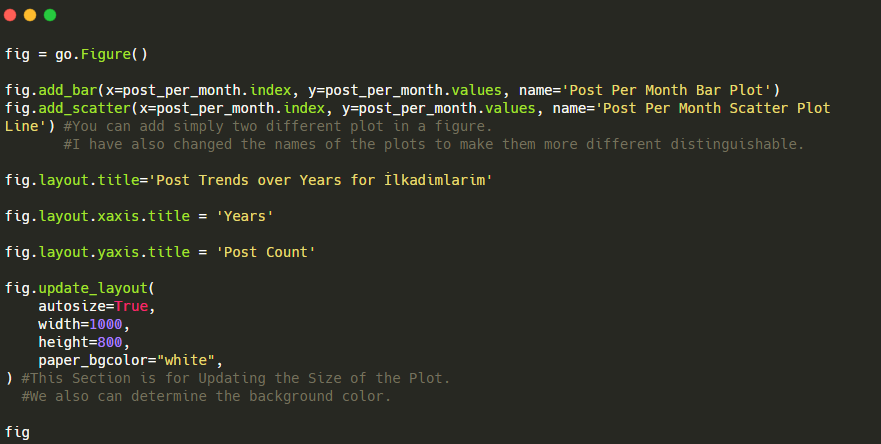
fig.add_scatter()を使用して2番目のプロットを追加し、name属性を使用して名前も変更しました。 fig.update_layout()は、プロットのサイズと背景色を変更するためのものです。
ホバーモード、バー間の距離などを変更することもできます。 ここで各コードを個別に説明すると、主要な主題から離れてしまう可能性があるため、コードを共有するだけで十分だと思います。
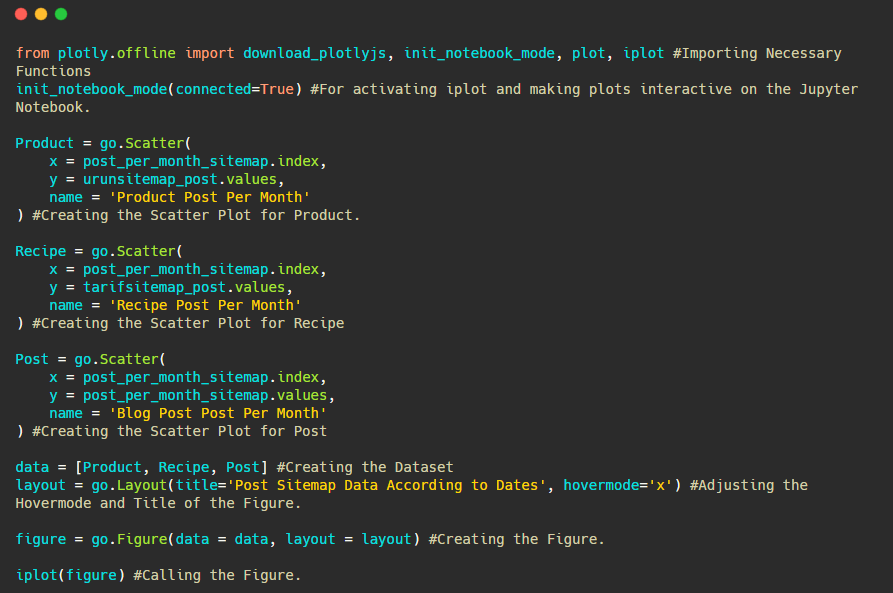
また、以下のようなカテゴリに従って、競合他社のコンテンツ公開の傾向を比較することもできます。
このグラフは2番目の方法で作成されています。違いはないかもしれませんが、そのうちの1つは非常に単純です。
3つの別々のサイトマップからコンテンツを公開する頻度と傾向をグラフ化するには、間隔が最も長いサイトマップをX軸に配置する必要があります。 したがって、調査しているWebサイトが、さまざまな検索目的でさまざまなタイプのコンテンツを公開する頻度を比較できます。
以下の関連コードを調べると、上記とそれほど変わらないことがわかります。
複数のY軸を持つ散布図を作成するには、以下のコードを使用できます。
さまざまなサイトマップを統合したり、列にforループを使用して散布図で複数のY軸を使用したりするなど、他の方法もありますが、このような小さなサイトでは必要ありません。 ほとんどの場合、数百のサイトマップがあるWebサイトでこの方法を使用する方が論理的です。
また、Webサイトが小さいため、グラフィックが浅く見える場合がありますが、数百万のURLを含むWebサイトの記事の後半で説明するように、このようなグラフィックは、さまざまなサイトを比較したり、さまざまなカテゴリのカテゴリを比較したりするのに最適な方法です。同じウェブサイト。
サイトマップとPythonを使用したコンテンツカテゴリ、インテント、公開トレンドの調査と視覚化
このセクションでは、記事の冒頭で述べたように、少数の製品を販売するために、特定の知識ドメインに多数のコンテンツを書き込んだことを確認します。 このおかげで、彼らが他のブランドとコンテンツパートナーシップを結んでいるかどうかを確認することができます。
サイトマップで他に何が見つかるかを示すために、もう少し掘り下げていきます。 他のサイトマップの「loc」部分からいくつかの情報を取得することもできます。
IlkadimlarimのURLにはカテゴリの内訳はありません。 WebサイトのURLにカテゴリの内訳がある場合、コンテンツの配布についてさらに多くのことを学ぶことができます。 そうでない場合は、追加のコードを記述して同じデータにアクセスできますが、確実性は低くなります。
この時点で、何十億ものサイトをクロールする検索エンジンがWebサイトを理解するために、URLの内訳がどれほど安価になるか想像できます。
a = ilkadimlarim ['loc']。str.contains(“ bebek | hamile | haftalik”)
ベベック:ベイビー
ハミール:妊娠中
Haftalik:毎週または「妊娠週」
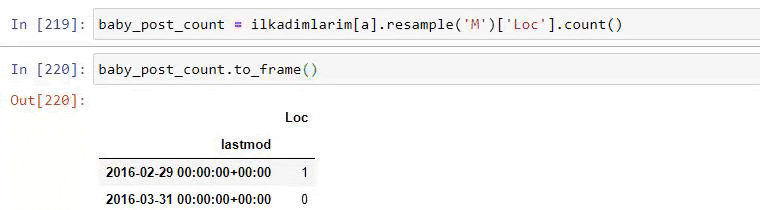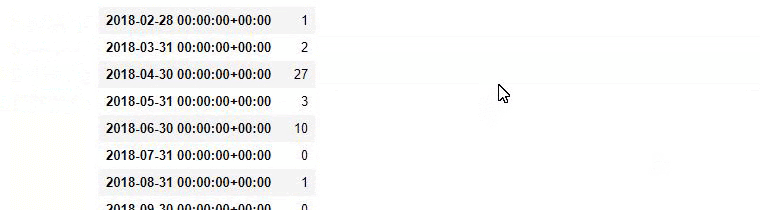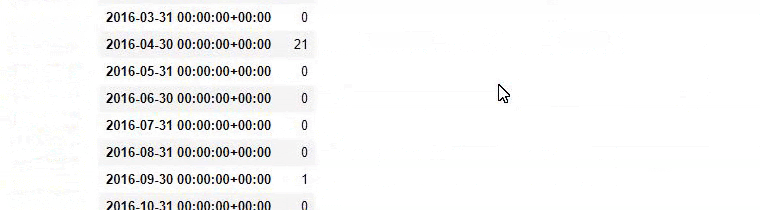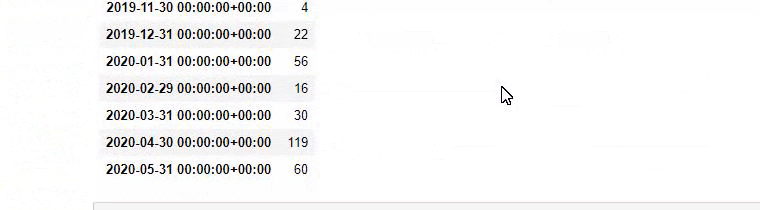
baby_post_count = ilkadimlarim [a] .resample('M')['loc']。count()
baby_post_count.to_frame()
ここでもstr()メソッドを使用すると、特定の操作を選択する列を設定できます。
contains()メソッドを使用して、データを判別し、文字列に変換されたデータに含まれているかどうかを確認します。
ここで、「|」 用語の間は「または」を意味します。
次に、フィルタリングしたデータを変数に割り当て、前に使用したresample()メソッドを使用します。
一方、 countメソッドは、どのデータが何回使用されたかを測定します。
count()で得られた結果は、再びto_frame()で囲まれます。
また、 str.contains()はデフォルトで正規表現値を取ります。これは、より少ないコードでより複雑なフィルタリング条件を作成できることを意味します。
つまり、この時点で、「baby」、「weekly」、「pregnant」という単語を含むURLをilkadimlarimの変数に割り当て、URLの公開日をこのフィルターの適切な条件に設定します。フレームで作成されます。
次に、「aptamil」という単語を含むURLに対しても同じことを行います。 アプタミルは、イルカディムラリムによって導入されたベビー栄養製品の名前です。 したがって、有益で商業的なコンテンツの放送密度にも注意を払うことができます。
また、2つの異なるコンテンツグループが、URLからのより確実で正確な情報を使用して、さまざまな検索インテントのスケジュールを何年にもわたって公開しているのを目にするかもしれません。
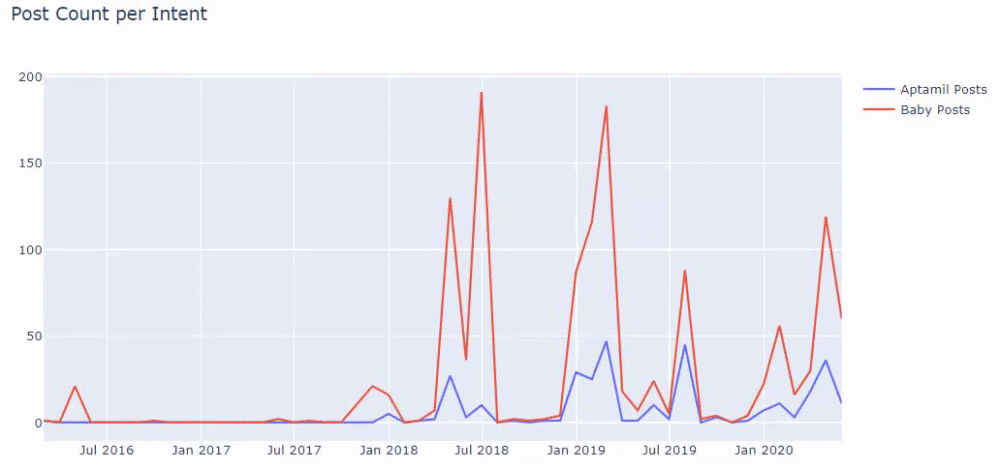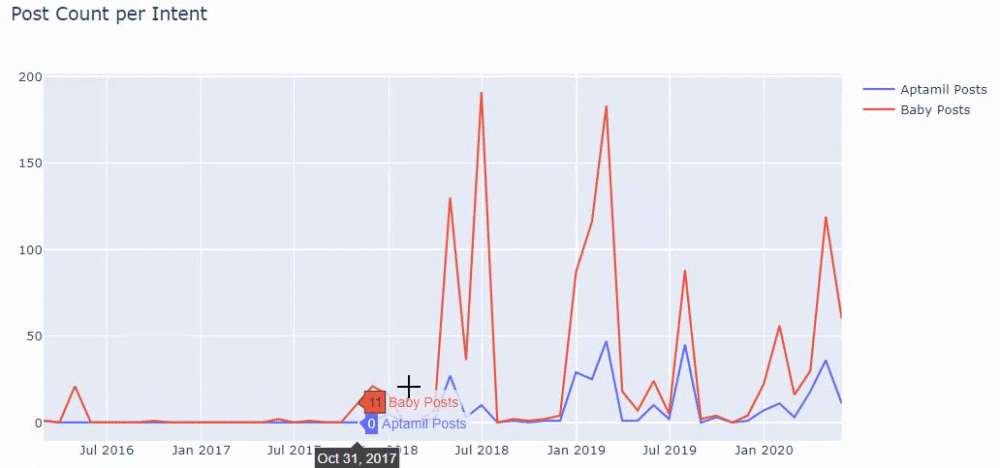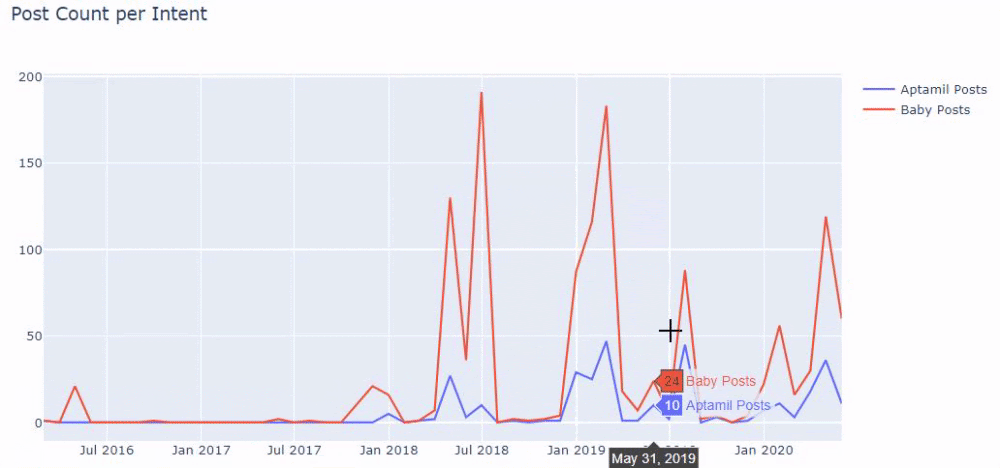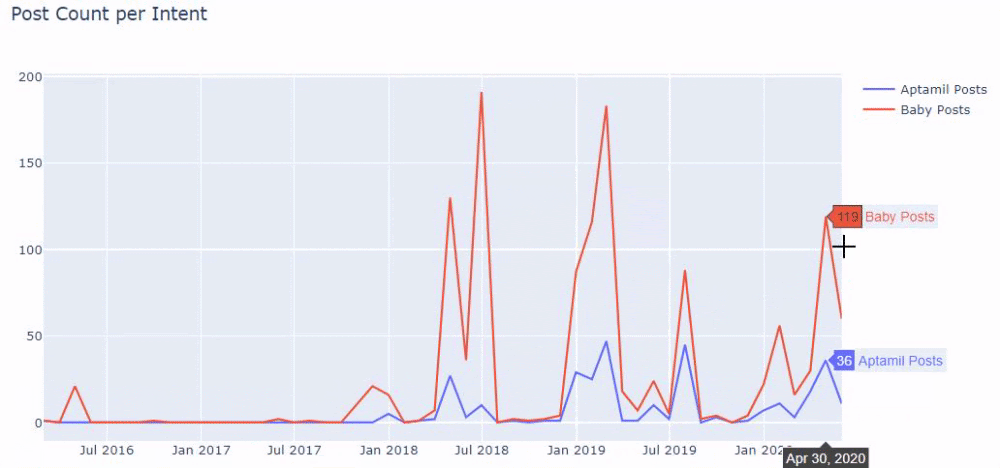
このチャートを作成するためのコードは、前のチャートで使用されたものと同じであるため、共有されませんでした
Googleの検索演算子の助けを借りて、Ilkadimlarim.comのアンカーテキストでAptamilという単語が使用されているページが必要な場合に38件の結果が得られます。 これらのページの重要な数は有益であり、商用コンテンツにリンクしています。

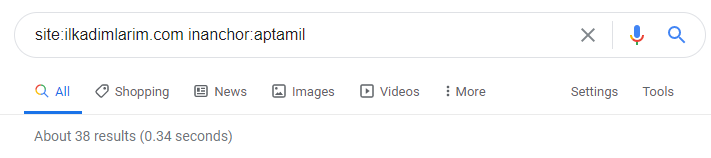
私たちの論文は証明されています。
「MyFirstSteps」は、母性、赤ちゃんの世話、妊娠に関する何百もの有益なコンテンツを使用して、対象となる視聴者にリーチします。 「ilkadimlarim」は、このコンテンツのAptamil製品を含むページにリンクし、ユーザーをそこに誘導します。
Pythonを使用したサイトマップを介したコンテンツプロファイリングとコンテンツ戦略の分析の比較
さて、必要に応じて、同じ業界の企業に対して同じことを行い、この業界の一般的な側面とこれら2つのブランド間の戦略の違いを理解するために比較してみましょう。
2番目の例として、PampersであるPrima.com.trを選択しましたが、トルコではPrimaというブランド名を使用しています。 Primaには単一のサイトマップがあるため、サイトマップで分類することはできませんが、少なくともURLの区切りが異なります。 ですから、私たちは非常に幸運です。より少ないコードを書く必要があります。
あなたが理解しにくいサイトを作るとき、グーグルがあなたのために実行しなければならないアルゴリズムがどれほど高価であるか想像してみてください! これにより、URL構造に関しても、クロールコストの計算をより具体的にすることができます。
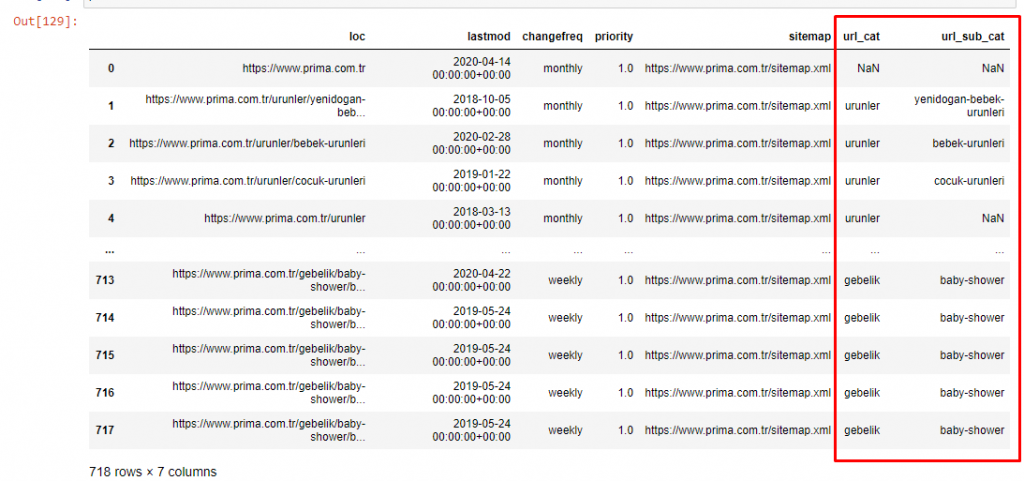
記事の量をさらに増やさないために、すでに行ったプロセスと同様のプロセスのコードは配置しません。
これで、URLカテゴリとURLサブカテゴリによるコンテンツカテゴリの分布を調べることができます。 企業のWebページが多すぎることがわかります。 これらの企業Webページは、「prima-hakkinda」(「Primaについて」)セクションに配置されています。 しかし、Pythonで確認すると、製品と企業のWebページが1つのカテゴリに統合されていることがわかります。 あなたはそれらのコンテンツの分布を以下で見ることができます:

次のサブカテゴリについても同じことができます。
Primaが「hamilelik」(アラビア語での妊娠)の変形である「gebelik」(トルコ語での妊娠)を使用していることに注目するのは興味深いことです。どちらも妊娠期間を意味します。

今では、それらのコンテンツがより深く分類されています。 内容の9.2%は健康な妊娠に関するもの、7.3%は赤ちゃんの成長過程に関するもの、8.3%は赤ちゃんと一緒にできる活動に関するもの、0.7%は赤ちゃんの睡眠順序に関するものです。 3.9%の歯が生える、1.9%の赤ちゃんの安全、1.4%の家族に妊娠を明らかにするなどのトピックもあります。 ご覧のとおり、URLとその配布率だけで業界を知ることができます。
これは完全な分類ではありませんが、少なくとも競合他社の考え方やコンテンツマーケティングの傾向、およびカテゴリ別のWebサイトのコンテンツを確認できます。 それでは、月ごとにコンテンツを公開する頻度を確認しましょう。
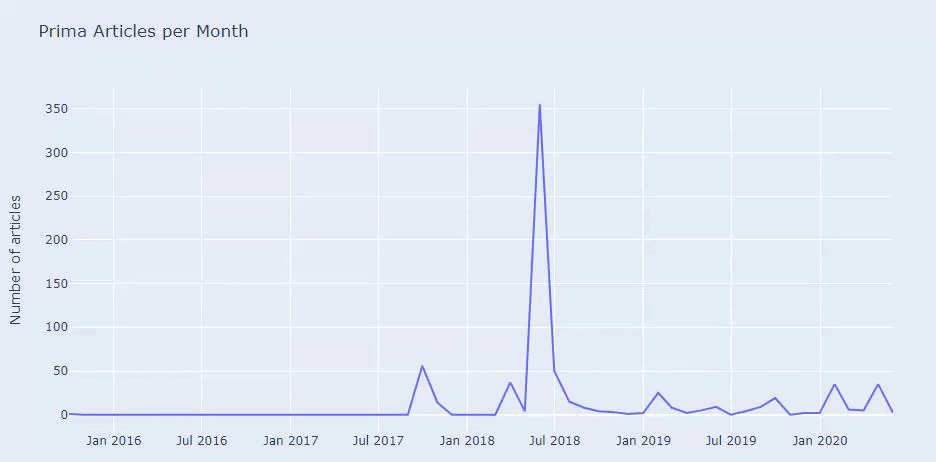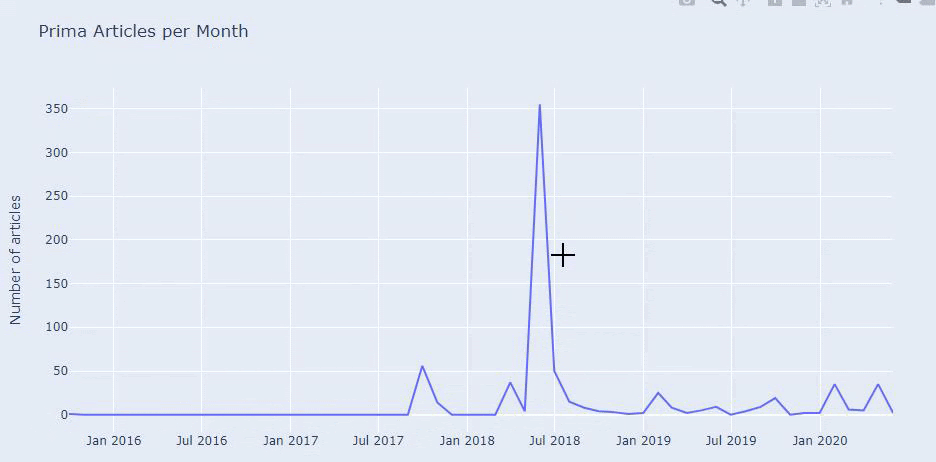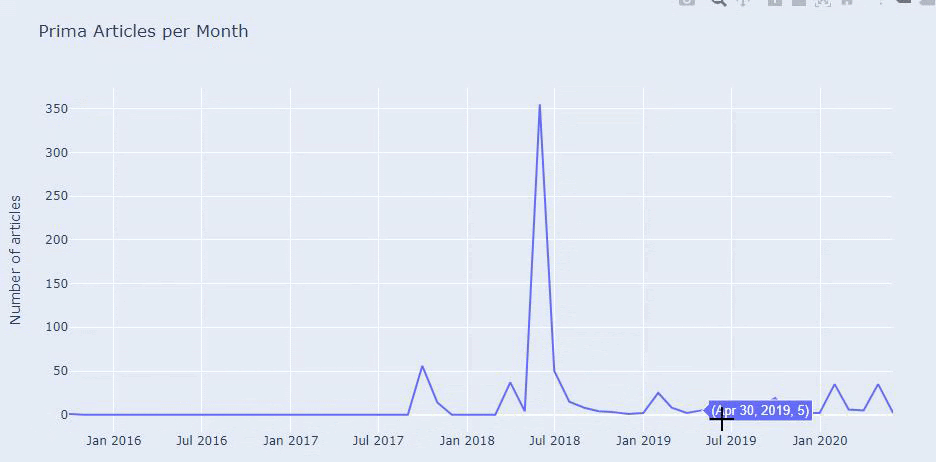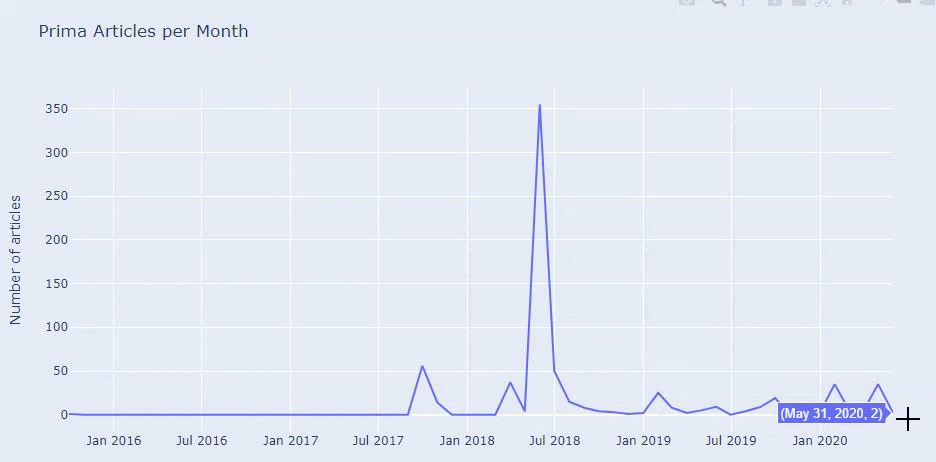
2018年7月に355件の記事が公開されており、サイトマップによると、それ以降、コンテンツは更新されていません。 また、長年にわたるカテゴリ別にコンテンツ公開の傾向を比較することもできます。 ご覧のとおり、コンテンツは主に4つの異なるカテゴリに分類されており、ほとんどが同じ月に公開されています。
先に進む前に、サイトマップデータが常に正しいとは限らないことを言わなければなりません。 たとえば、Lastmodデータは、この日にすべてのサイトマップを更新したため、すべてのURLで更新された可能性があります。 これを回避するために、Wayback Machineを使用して、コンテンツが変更されていないことを確認することもできます。
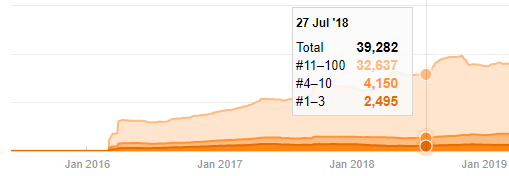
疑わしいように見えても、このデータは本物である可能性があります。 トルコの多くの企業は、少し前に大量の注文を出し、コンテンツを公開する傾向があります。 キーワード数を確認すると、この期間にジャンプが見られます。 したがって、比較コンテンツプロファイルと戦略分析を実行している場合は、これらの問題についても考慮する必要があります。
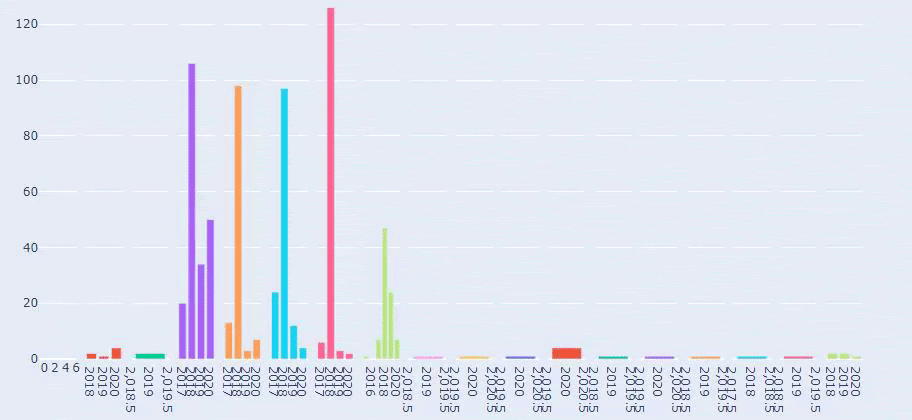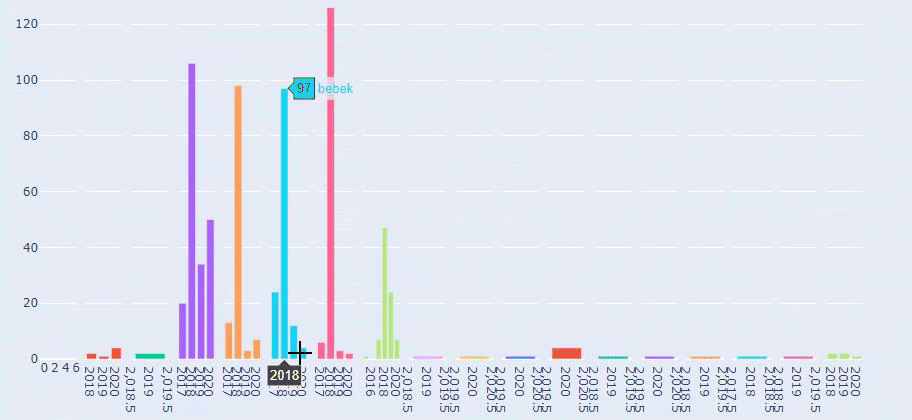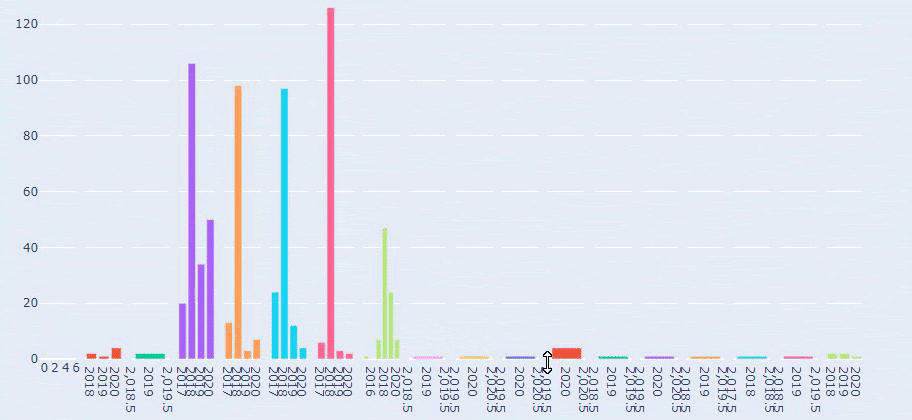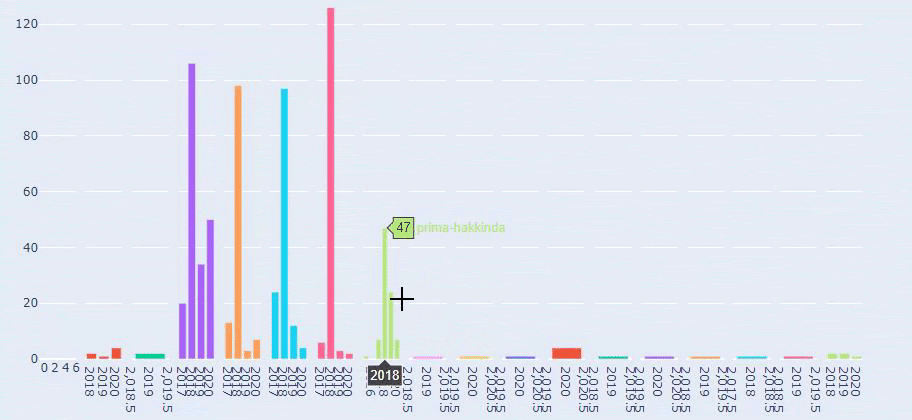
これは、Prima.com.trの長年にわたるすべてのカテゴリのコンテンツ公開トレンドの比較です。
これで、2つの異なるWebサイトのコンテンツカテゴリとそれらの公開傾向を比較できます。
Primaが赤ちゃんの成長、妊娠、母性に関する記事を公開する頻度を見ると、Ilkadimlarimと類似していることがわかります。
- ほとんどの記事は特定の時期に発行されました。
- それらは長い間更新されていませんでした。
- 製品とページの数は、有益なコンテンツのページの数と比較して非常に少なかった。
- 最近、彼らは彼らのサイトに新製品を追加したばかりです。
これらの4つの機能は業界のデフォルトの考え方であると見なすことができ、キャンペーンを支持するためにこれらの弱点を使用する可能性があります。 結局のところ、品質には鮮度が必要です(GoogleフェローのAmit Singhalが述べています)。
この時点で、業界はGooglebotの動作に精通していないこともわかります。 1日に250個のコンテンツをアップロードしてから1年間変更を加えないのではなく、定期的に新しいコンテンツを追加し、古いコンテンツを定期的に更新することをお勧めします。 したがって、コンテンツの品質を維持でき、Googlebotはサイトをより簡単に理解でき、クロール需要の頻度の値は競合他社よりも高くなります。
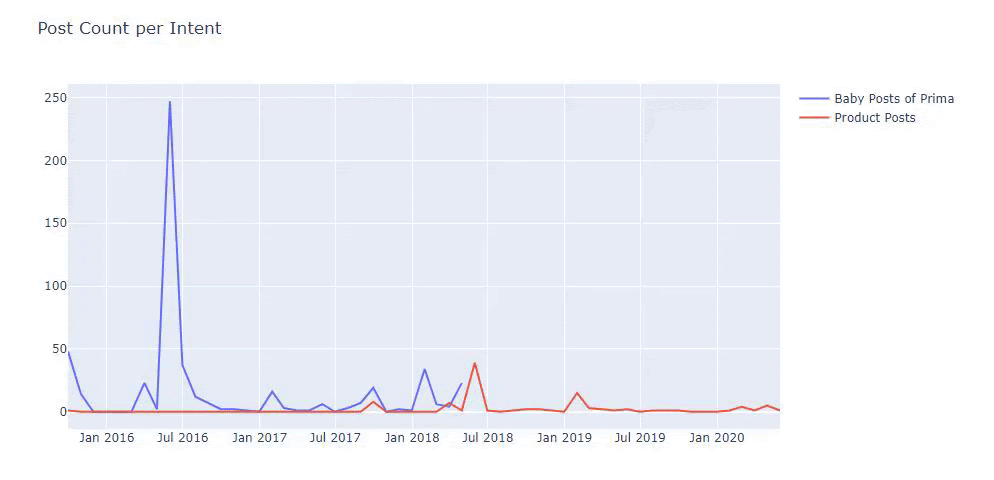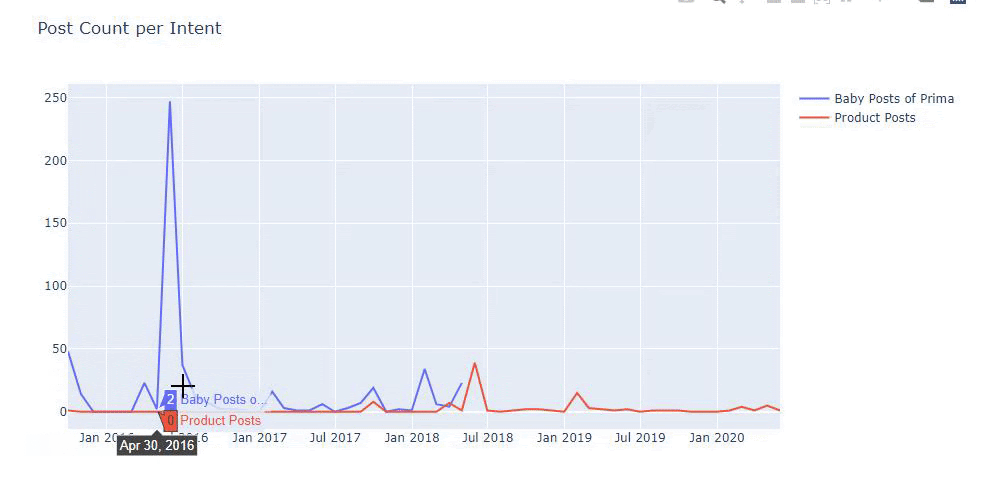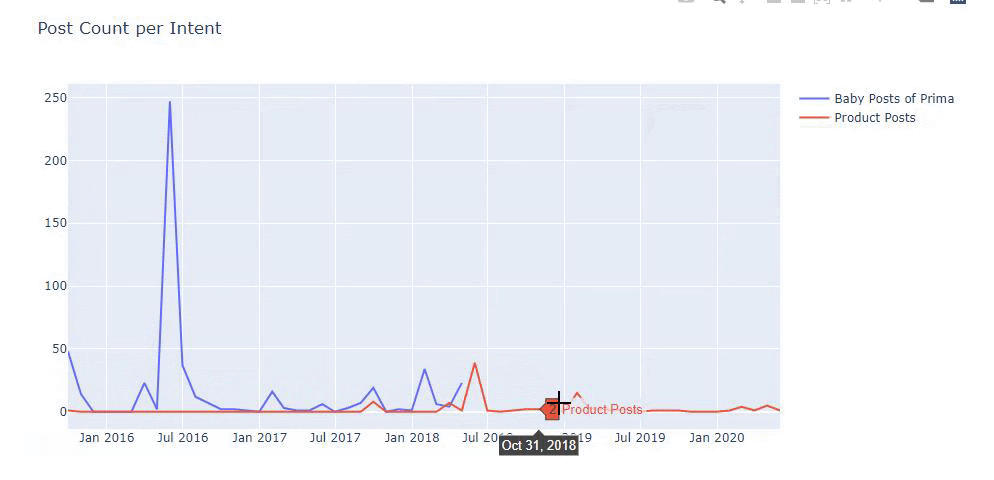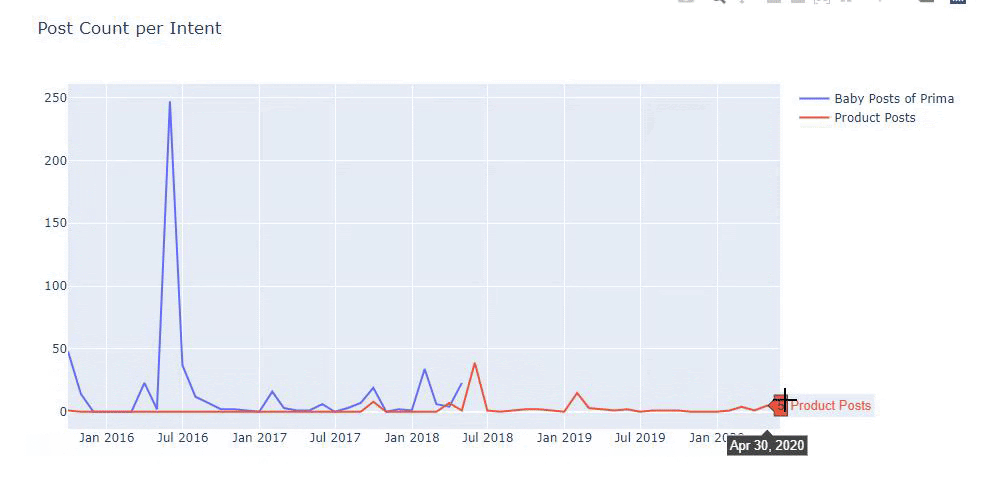
以前の方法を使用して、製品と有益なコンテンツページを区別し、URLで最もよく使用される単語のプロファイルを作成しました。 ここでの赤ちゃんの投稿は、これらが有益なコンテンツであることを意味します。
ご覧のとおり、1日に247のコンテンツが追加されました。 また、1年以上にわたって有益なコンテンツを公開または更新せず、たまに新しい製品ページを追加するだけでした。
それでは、出版の傾向を1つの図で比較しますが、2つの異なるプロットを使用します。 この図を作成するために、以下のコードを使用しました。
このグラフィックは前のグラフィックとは異なるため、コードを示したいと思います。 ここでは、2つの別々のプロットが同じ図に配置されています。 このため、make_subplotsメソッドは、plotly.subplotsimportmake_subplotsからのコマンドで呼び出されました。
これは、 make_subplots(2,1)を使用して2行1列の図として作成されました。
したがって、colとrowはトレースの最後に書き込まれ、それらの位置が指定されます。 CSSのグリッドシステムに精通している人なら誰でも簡単に認識できるシステムです。
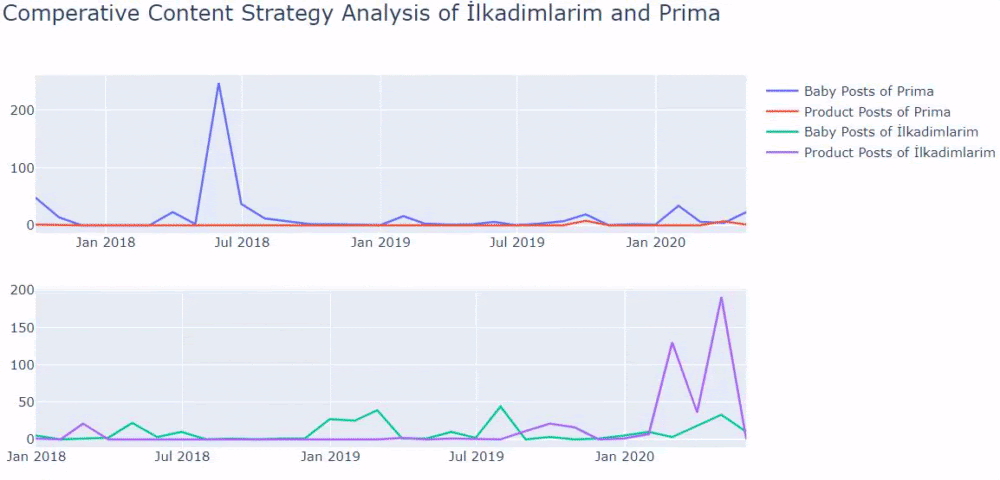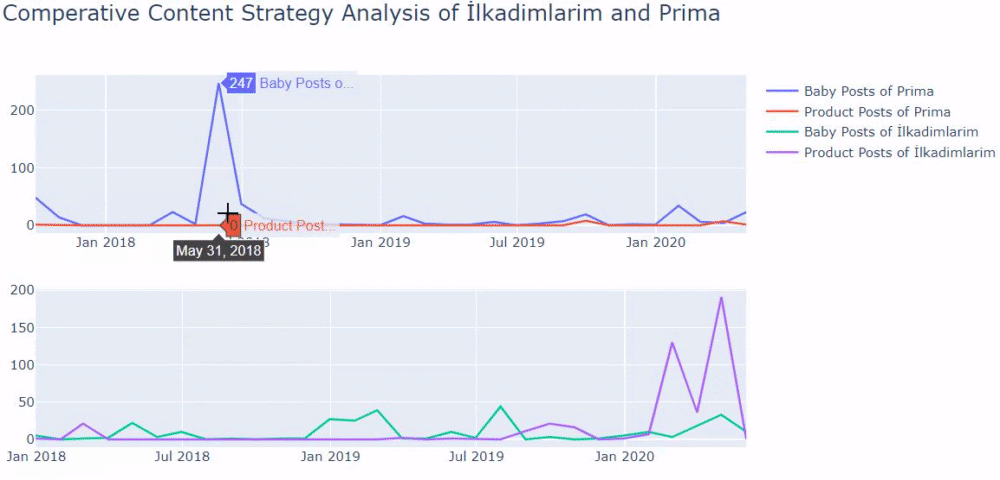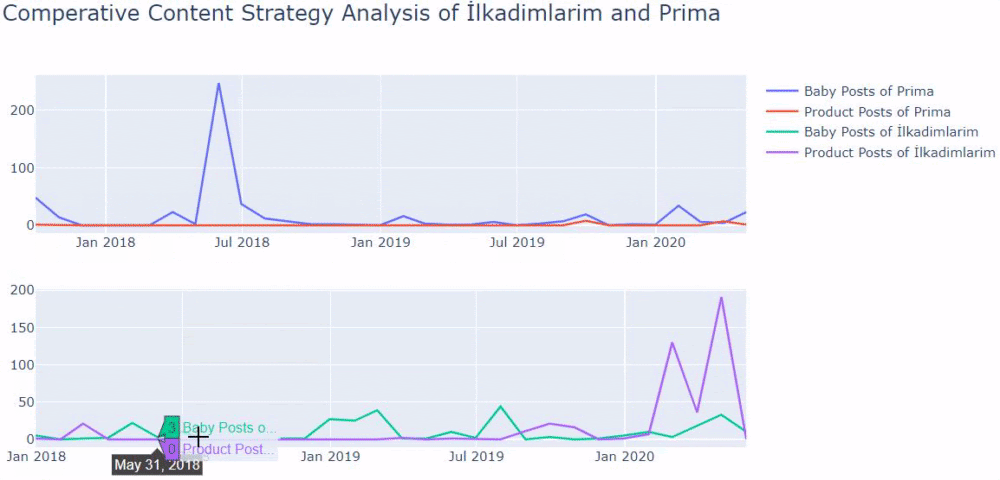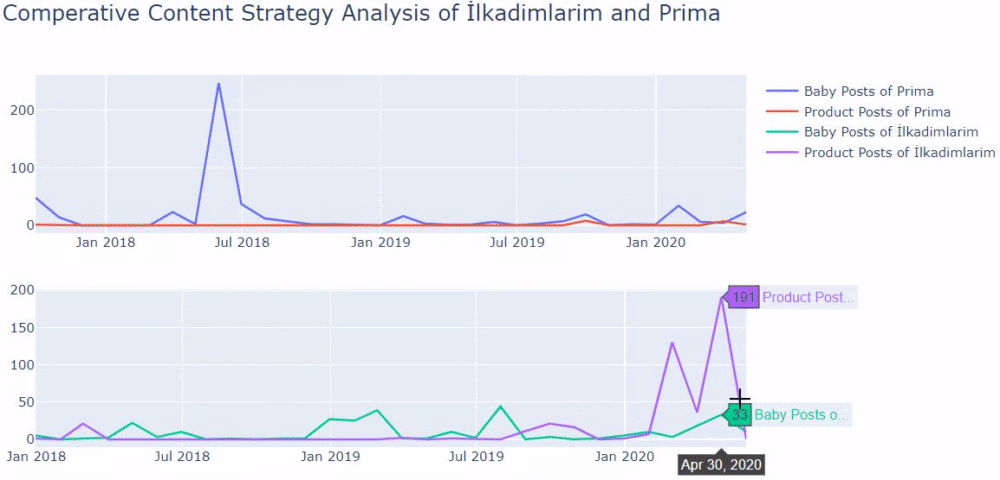
同じセクターに顧客がいる場合は、このデータを使用してコンテンツ戦略を作成し、競合他社の弱点とSERPを介したクエリ/ランディングページネットワークを確認できます。 また、同じナレッジドメインまたは同じユーザーインテントで公開する必要のあるコンテンツの量を理解できます。
コンテンツ戦略分析の一環としてサイトマップから学べることをまとめる前に、別の業界のURL数がはるかに多い最後のWebサイトを調べることができます。
Pythonとサイトマップを使用した通貨でのニュースWebエンティティのコンテンツ戦略分析
このセクションでは、Seabornのヒートマッププロットと、より洗練されたフレーミングおよびデータ抽出方法を使用します。

エリアス・ダバスは、データサイエンスとSEOの観点から、興味深く、本当に役立つKaggleアーカイブを持っています。 今月、彼は私が必要なコードを記述し、サイトマップを介してAdvertoolsでコンテンツ戦略分析を実行するために、トルコのニュースサイト用の新しいKaggleデータセットセクションを開設しました。
Kaggleでこれらの手法を使い始める前に、この記事では、より大きなWebエンティティで同じ手法を使用するとどうなるかについていくつかの例を示したいと思います。
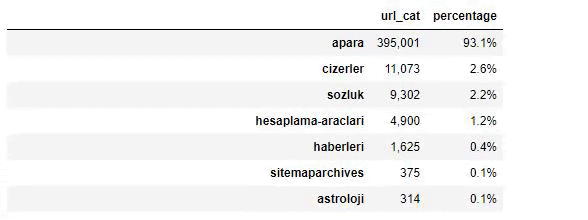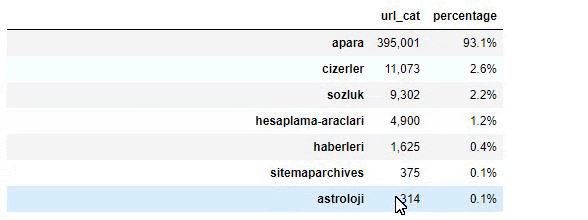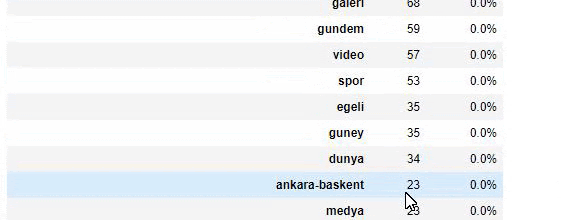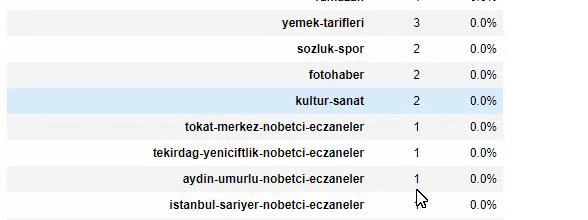
Sabah Newspaperの内容を分析すると、その内容のかなりの部分(81%)が「apara」と呼ばれるカテゴリーに含まれていることがわかります。 また、占星術、計算、辞書、天気、世界のニュースのいくつかの大きなカテゴリがあります。 (パラはトルコ語でお金を意味します)
Sabah Newspaperの場合、Advertoolsでのみ収集したサイトマップを使用してコンテンツを分析することもできますが、問題の新聞は非常に大きいため、サイトマップの数が多く、同じURLを含む異なるサイトマップのコンテンツであるため、私はそれを好みませんでした。カテゴリー。
以下に、Advertoolsを使用した過剰なサイトマップも表示されます。
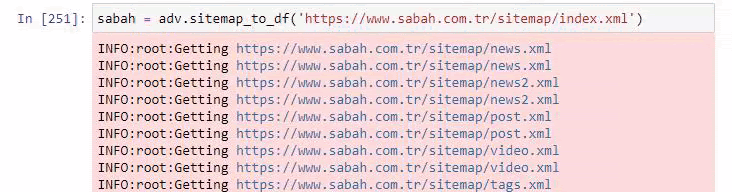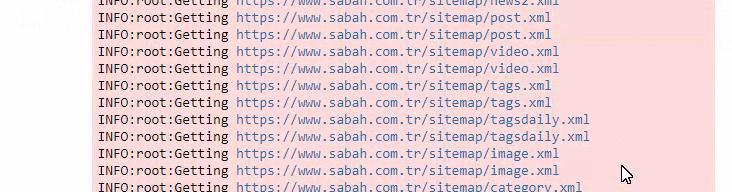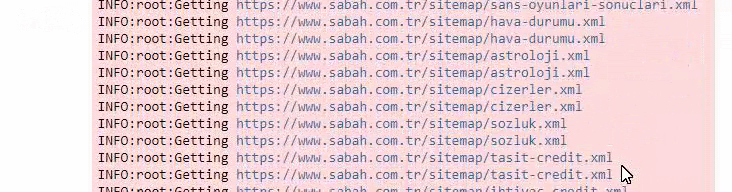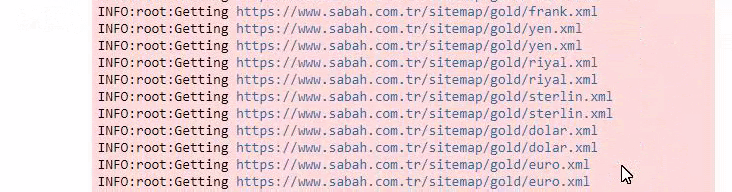
ゴールド、クレジット、通貨、タグ、祈りの時間、薬局の勤務時間など、同じURLカテゴリに対して異なるサイトマップがあることがわかります。
つまり、URLのサブカテゴリに焦点を当てることで、これらの詳細を実現できます。 変数を介して異なるサイトマップを統合する代わりに。 そのため、記事の冒頭のように、すべてのサイトマップをAdvertoolsのsitemap_to_df()メソッドで統合しました。
Elias Dabbasによって作成された別の関数セットを使用して、より優れたデータフレームを作成することもできます。 dataset_utitilites関数を確認すると、いくつかの例を見ることができます。 以下のコードは、指定されたURL正規表現の合計とパーセンテージ、およびスタイル設定による累積合計を示します。
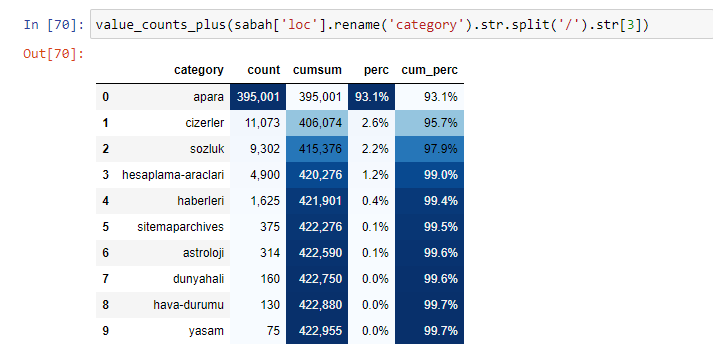
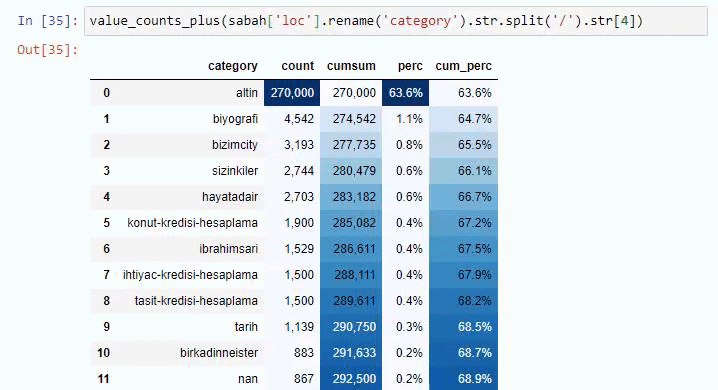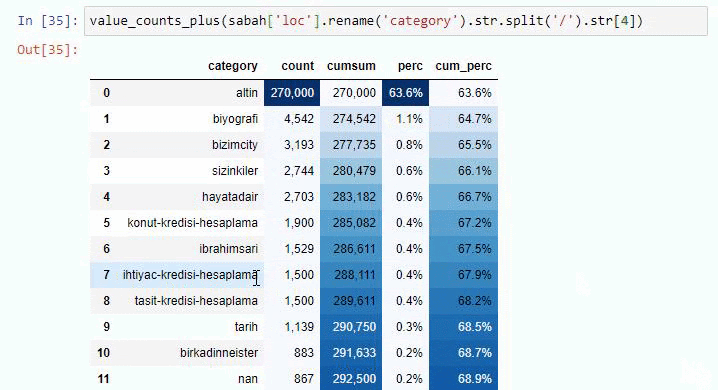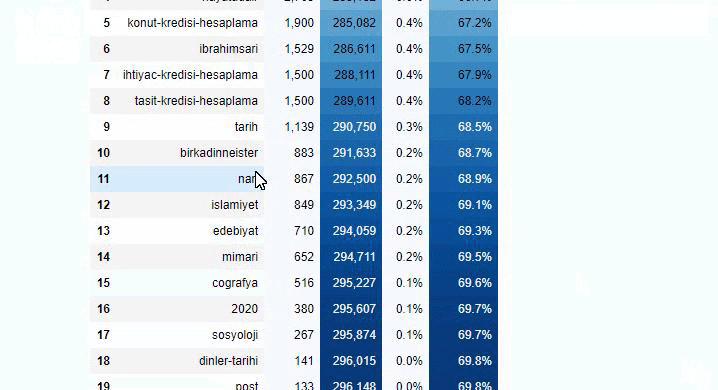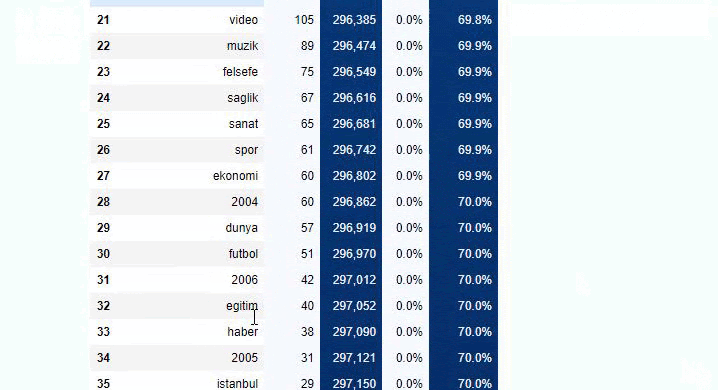
Sabah NewspaperのサブURL内訳に対して同じことを行うと、次の結果が得られます。
以下の行を変更することで、問題の関数が出力する行数を増やすことができます。 また、関数の内容を調べると、以前に使用したものと類似していることがわかります。
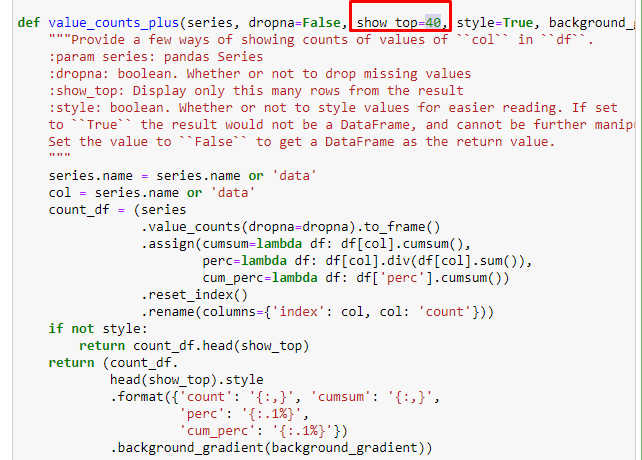
サブブレイクでは、「宗教の歴史」、「伝記」、「都市名」、「サッカー」、「Bizimcity(似顔絵)」、「住宅ローンのクレジット」など、さまざまな内訳が表示されます。 最大の内訳は「ゴールド」カテゴリーです。
では、新聞はどのようにして金価格の295,000のURLを持つことができるのでしょうか。
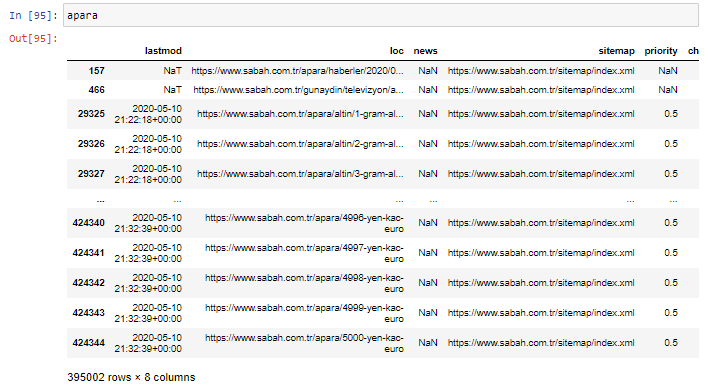
まず、SabahNewspaperの最初のURL内訳の「apara」を含むすべてのURLを変数に入れます。
apara = sabah [sabah ['loc']。str.contains('apara')]
結果は次のとおりです。
.filter()メソッドを使用して列をフィルタリングすることもできます。
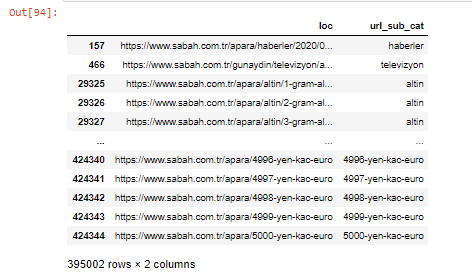
これで、DataFrameの下部に、SabahNewspaperが5000ユーロ、4999ユーロ、4998ユーロなど、通貨計算の量ごとに異なるWebページを開いたために過剰な量のAparaURLが含まれている理由がわかります。
ただし、結論を出す前に、これらのURLの250,000以上が「altin(ゴールド)」カテゴリに属していることを確認する必要があります。
apara.filter(['loc'、'url_sub_cat'])。tail(60)は、このデータフレームの最後の60行を表示します。

Aparaグループ内のゴールドURLの内訳についても同じことができます。
gold = apara [apara ['loc']。str.contains('altin')]
gold.filter(['loc'、'url_sub_cat'])。tail(85)
gold.filter(['loc'、'url_sub_cat'])。head(85)
この時点で、Sabah Newspaperが5000の異なるページを開いて、各通貨をドル、ユーロ、ゴールド、およびTL(トルコリラ)に変換していることがわかります。 1から5000までの金額の単位ごとに個別の計算ページがあります。以下のゴールドグループの最初の85行と最後の85行の例を示します。 金価格1グラムごとに個別のページが開かれています。


これらのページは不要であり、重複コンテンツが多く、非常に大きいことは間違いありませんが、Sabah Newspaperは非常に強力なウェブサイトであるため、Googleはほぼすべてのクエリでトップランクに表示し続けています。
この時点で、権限の高い古いニュースサイトのクロールコスト許容度が高いこともわかります。
ただし、これは、ゴールドカテゴリに他のカテゴリよりも多くのURLがある理由を説明していません。
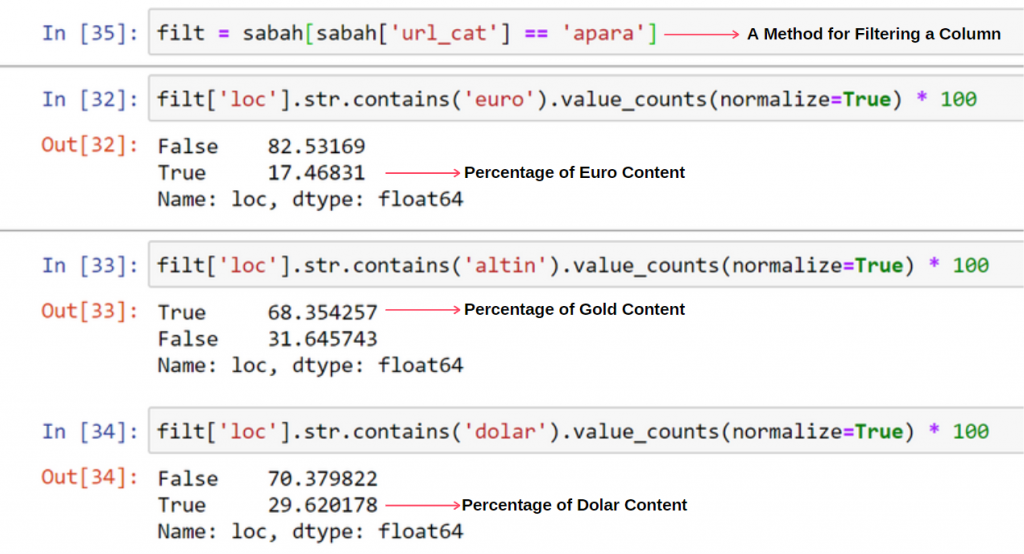
重複する値の合計が100%を超えることについて、奇妙なことは何も見られません。
私が何かを逃していない限り?
お気づきのように、すべての真の値を追加すると、115.16%の結果が得られます。 その理由は以下のとおりです。
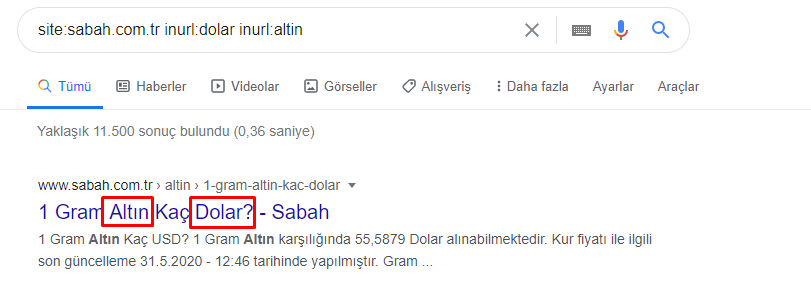
メイングループでさえ、このように互いに交差しています。 これらの交差点を分析することもできますが、別の記事の主題になる可能性があります。
Apara URLグループのコンテンツの68%がGOLDに関連していることがわかります。
この状況をよりよく理解するために、最初に行う必要があるのは、ゴールド屈折のURLをスキャンすることです。
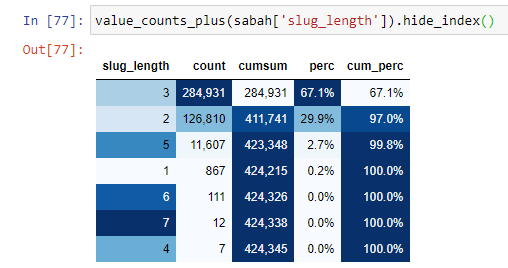
ルートセクション以降の「/」の量に従ってURLを分類すると、最大3つのブレークを持つURLの数が多いことがわかります。 これらのURLを分析すると、3つのslug_lengthURLのうち270.000がゴールドカテゴリに含まれていることがわかります。
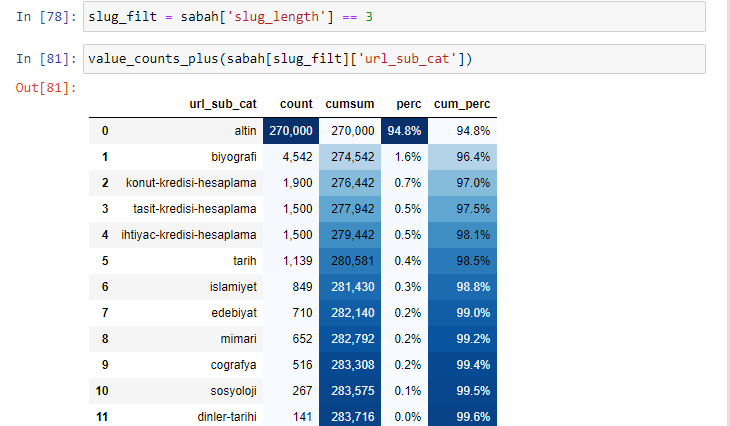
morning_filt = morning ['slug_length'] == 3これは、特定のデータフレームの特定の列にあるintデータ型のデータグループから3に等しいものだけを取得することを意味します。 次に、この情報に基づいて、条件に便利なURLをカウント、合計、および累積合計で集計率で構成します。
ゴールドURLで最も一般的に使用される単語を抽出すると、「full」、「republic」、「quarter」、「gram」、「half」、「ancestor」を表す単語に出くわします。 AtaとRepublicのゴールドタイプはトルコ独自のものです。 そのうちの1人はトルコの主権を代表しており、もう1人は共和国の創設者であるケマルアタチュルクです。 そのため、クエリ検索ボリュームが多くなっています。
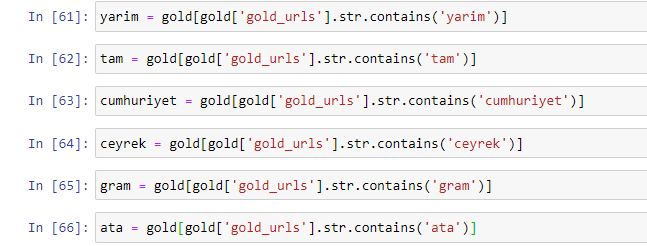
まず、URLで見つかった一般的な単語を削除し、それらを別々の変数に割り当てました。 次に、Gold DataFrameでこれらの変数を使用して、それらのタイプに固有の列を作成します。
変数を使用して新しい列を作成した後、ブール値でそれらをフィルター処理する必要があります。
ご覧のとおり、270,000行6列のすべてのゴールドURLを分類することができました。 ゴールド固有のページ数が多い主な理由は、ドルまたはユーロには個別のタイプがないのに対し、ゴールドには個別のタイプがあるためです。 同時に、トルコの人々に対する伝統的な信頼のため、金と異なる通貨の間でページをまたぐ多様性は他の通貨よりも高くなっています。
私の意見では、すべての種類のゴールドページを均等に配布する必要がありますよね?
Seabornのヒートマップ機能を使用してこれを簡単にテストできます。
Seabornをsnsとしてインポートする
matplotlib.pyplotをpltとしてインポートします
plt.figure(figsize =(10,8))
sns.heatmap(a、yticklabels = False、cbar = False、cmap =” viridis”)
plt.show()
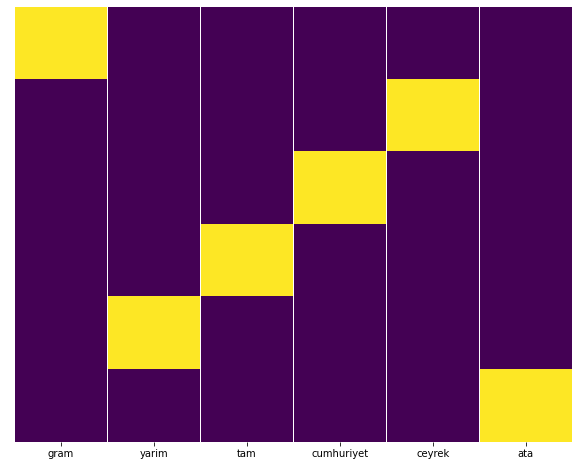
ここヒートマップでは、各列のTrueが単純にマークされています。 ご覧のとおり、それぞれのサイズは互いに対称であり、マップ上にきれいに配置されています。
このように、私たちは通貨と通貨計算に関するSabah.com.tr新聞のコンテンツポリシーについて広い視野を持っています。
将来的には、EliasDabbasが立ち上げたSitemapsKaggleに基づいて、トルコのニュースWebサイトとそのコンテンツ戦略を作成しますが、この記事では、サイトマップを使用して大小のWebサイトで何を発見できるかについて十分に説明しました。 。
結論とポイント
スムーズでセマンティックなURL構造のおかげで、ウェブサイトを理解するのがいかに簡単かを見てきました。 また、適切なURL構造がGoogleにとってどれほど価値があるかを覚えておく必要があります。
将来的には、データサイエンス、データの視覚化、フロントエンドプログラミングなどにますます精通している多くのSEOが見られるでしょう…このプロセスは避けられない変化の始まりだと思います。SEOと開発者の間のギャップは完全に埋められます。数年で。
Pythonを使用すると、この種の分析をさらに進めることができます。ニュースサイトの政治的見解を理解することから、誰が何について、どのくらいの頻度で、どのような感情で書いているかについてのデータを取得できます。 これらのプロセスはSEOよりも純粋なデータサイエンスに関するものであるため、ここでは詳しく説明しません(この記事はすでにかなり長いです)。
ただし、興味がある場合は、サイトマップ内のURLのステータスコードを確認するなど、サイトマップやPythonを介して実行できる他の多くの種類の監査があります。
PythonとAdvertoolsで実行できる他のSEOタスクを実験して共有することを楽しみにしています。