
AI を理解する: コンピューターに自然言語をどのように教えたか
公開: 2023-11-28「人工知能」という言葉は 1950 年代からコンピューターに関連して使用されてきましたが、昨年までは、ほとんどの人が AI はテクノロジーの現実というよりはまだ SF だと考えていたでしょう。
2022 年 11 月に OpenAI の ChatGPT が登場したことで、機械学習の可能性に対する人々の認識が突然変わりました。しかし、ChatGPT の何が、世界を立ち上がらせ、人工知能が大々的に登場していることを認識させたのでしょうか?
一言で言えば、言語です。ChatGPT がこれほど顕著な進歩を遂げたと感じた理由は、これまでのチャットボットでは見られなかった方法で、ChatGPT が自然言語で流暢に表現されているように見えたからです。
これは、自然言語を解釈して説得力のある応答を出力するコンピューターの能力である「自然言語処理」(NLP) の注目すべき新しい段階を示しています。 ChatGPT は、コンテンツを処理および生成できる大規模なデータセットでトレーニングされた深層学習を使用するニューラル ネットワークの一種である「ラージ言語モデル」(LLM) に基づいて構築されています。
「コンピューター プログラムはどのようにしてこれほど流暢な言語を実現したのでしょうか?」
しかし、どうやってここにたどり着いたのでしょうか? コンピューター プログラムはどのようにしてこのような流暢な言語を実現したのでしょうか? どうしてこんなに間違いなく人間的に聞こえるのでしょうか?
ChatGPT は単独で作成されたわけではありません。ここ数十年にわたる無数のさまざまな革新と発見に基づいて構築されました。 ChatGPT につながった一連のブレークスルーはすべてコンピューター サイエンスのマイルストーンでしたが、それらは人間が言語を獲得する段階を模倣していると見ることもできます。
私たちはどうやって言語を学ぶのでしょうか?
AI がどのようにしてこの段階に到達したかを理解するには、言語学習自体の性質を考慮する価値があります。私たちは単一の単語から始めて、複雑な概念、アイデア、指示を伝達できるようになるまで、それらを組み合わせて長いシーケンスを作り始めます。
たとえば、子供の言語習得の一般的な段階は次のとおりです。
- ホロフラスティック段階: 9 ~ 18 か月の間、子供たちは自分の基本的なニーズや欲求を説明する単一の単語を使用することを学びます。 単一の単語でコミュニケーションを図るということは、概念的な完全性よりも明確さを重視することを意味します。 子どもはお腹が空いても「食べ物がほしい」とか「お腹が空いた」とは言わず、単に「食べ物」とか「牛乳」と言います。
- 2 単語段階: 生後 18 ~ 24 か月の間に、子供はコミュニケーション スキルを高めるために、単純な 2 単語のグループ化を使い始めます。 今では、「もっと食べ物」や「本を読んで」などの表現で自分の気持ちやニーズを伝えることができます。
- 電信段階: 24 ~ 30 か月の間に、子供たちは複数の単語をつなぎ合わせて、より複雑なフレーズや文を形成し始めます。 使用される単語の数はまだ少ないですが、正しい語順とより複雑さが現れ始めます。 子どもたちは、「ママに見せたい」などの基本的な文の構成を学び始めます。
- 多語期: 30 か月後、子供は多語期に移行し始めます。 この段階では、子供たちはより文法的に正しく、複雑で複数の節からなる文を使い始めます。 これは言語習得の最終段階であり、子供たちは最終的には「雨が降ったら家にいてゲームをしたい」などの複雑な文でコミュニケーションをとるようになります。
言語習得における最初の重要な段階の 1 つは、非常に簡単な方法で 1 つの単語を使い始めることができるようになることです。 したがって、AI 研究者が克服する必要がある最初の障害は、単純な単語の関連付けを学習するようにモデルをトレーニングする方法でした。
モデル 1 – Word2Vec を使用した単一単語の学習 (論文 1 および論文 2)
この方法で単語の関連付けを学習しようとした初期のニューラル ネットワーク モデルの 1 つは、Tomaš Mikolov と Google の研究者のグループによって開発された Word2Vec です。 これは 2013 年に 2 つの論文で発表されました (この分野での発展がいかに速いかを示しています)。
これらのモデルは、一般的に一緒に使用される単語を関連付けることを学習することによってトレーニングされました。 このアプローチは、ジョン R. ファースなどの初期の言語学の先駆者の直観に基づいて構築されています。彼は、意味は単語の連想から導き出される可能性があると指摘しました。「単語は、それが保持している仲間によってわかるはずです。」
これは、同様の意味上の意味を共有する単語は、より頻繁に同時に出現する傾向があるという考えです。 一般に、「猫」と「犬」という単語は、「リンゴ」や「コンピュータ」などの単語よりも頻繁に一緒に出現します。 言い換えれば、「猫」という単語は「リンゴ」や「コンピュータ」に似ているよりも、「猫」という単語の方が「犬」という単語に似ているはずです。
Word2Vec の興味深い点は、これらの単語の関連付けを学習するために Word2Vec がどのようにトレーニングされたかということです。
- ターゲット単語を推測する: モデルには、ターゲット単語が欠落している固定数の単語が入力として与えられ、モデルは欠落しているターゲット単語を推測する必要がありました。 これは、Continuous Bag Of Words (CBOW) として知られています。
- 周囲の単語を推測する: モデルには 1 つの単語が与えられ、周囲の単語を推測するという課題が与えられます。 これはスキップグラムとして知られており、周囲の単語を予測するという点で CBOW とは逆のアプローチです。
これらのアプローチの利点の 1 つは、モデルをトレーニングするためにラベル付けされたデータが必要ないことです。たとえば、感情分析を教えるためにテキストを「ポジティブ」または「ネガティブ」と記述するデータのラベル付けは、結局のところ時間と労力のかかる作業です。
Word2Vec について最も驚くべきことの 1 つは、比較的単純なトレーニング アプローチで複雑な意味関係を捕捉したことです。 Word2Vec は、入力単語を表すベクトルを出力します。 これらのベクトルに対して数学的演算を実行することで、著者らは単語ベクトルが構文的に類似した要素だけでなく、複雑な意味関係も捉えていることを示すことができました。
これらの関係は、単語の使用方法に関連しています。 著者らが注目した例は、「王様」と「女王」、「男性」と「女性」などの単語の関係です。
しかし、これは一歩前進ではありましたが、Word2Vec には限界がありました。 単語ごとに定義は 1 つだけでした。たとえば、「堤防」という言葉は、堤防を持ち上げるつもりなのか、堤防から釣りをするつもりなのかによって意味が異なることは誰もが知っています。 Word2Vec は気にせず、「銀行」という単語の定義が 1 つだけあり、それをあらゆる文脈で使用していました。
何よりも、Word2Vec は命令や文章さえ処理できませんでした。 入力として単語を受け取り、その単語について学習した「単語の埋め込み」、つまりベクトル表現を出力することしかできませんでした。 この 1 つの単語の基礎を構築するために、研究者は 2 つ以上の単語をシーケンス内でつなぎ合わせる方法を見つける必要がありました。 これは言語習得の 2 単語段階に似ていると想像できます。
モデル 2 – RNN とテキストのシーケンスを使用した単語シーケンスの学習
子どもたちは、単一の単語の使い方をマスターし始めると、単語を組み合わせて、より複雑な考えや感情を表現しようとします。 同様に、NLP 開発の次のステップは、一連の単語を処理する能力を開発することでした。 テキストのシーケンスを処理する場合の問題は、テキストの長さが固定されていないことです。 文の長さは、数単語から長い段落までさまざまです。 シーケンスのすべてが全体的な意味や文脈にとって重要であるわけではありません。 ただし、どの部分が最も関連しているかを知るには、シーケンス全体を処理できる必要があります。
そこでリカレント ニューラル ネットワーク (RNN) が登場しました。
1990 年代に開発された RNN は、シーケンス内の各ステップを反復する際に、前のステップからの出力がネットワークを通じて伝達されるループ内で入力を処理することによって機能します。
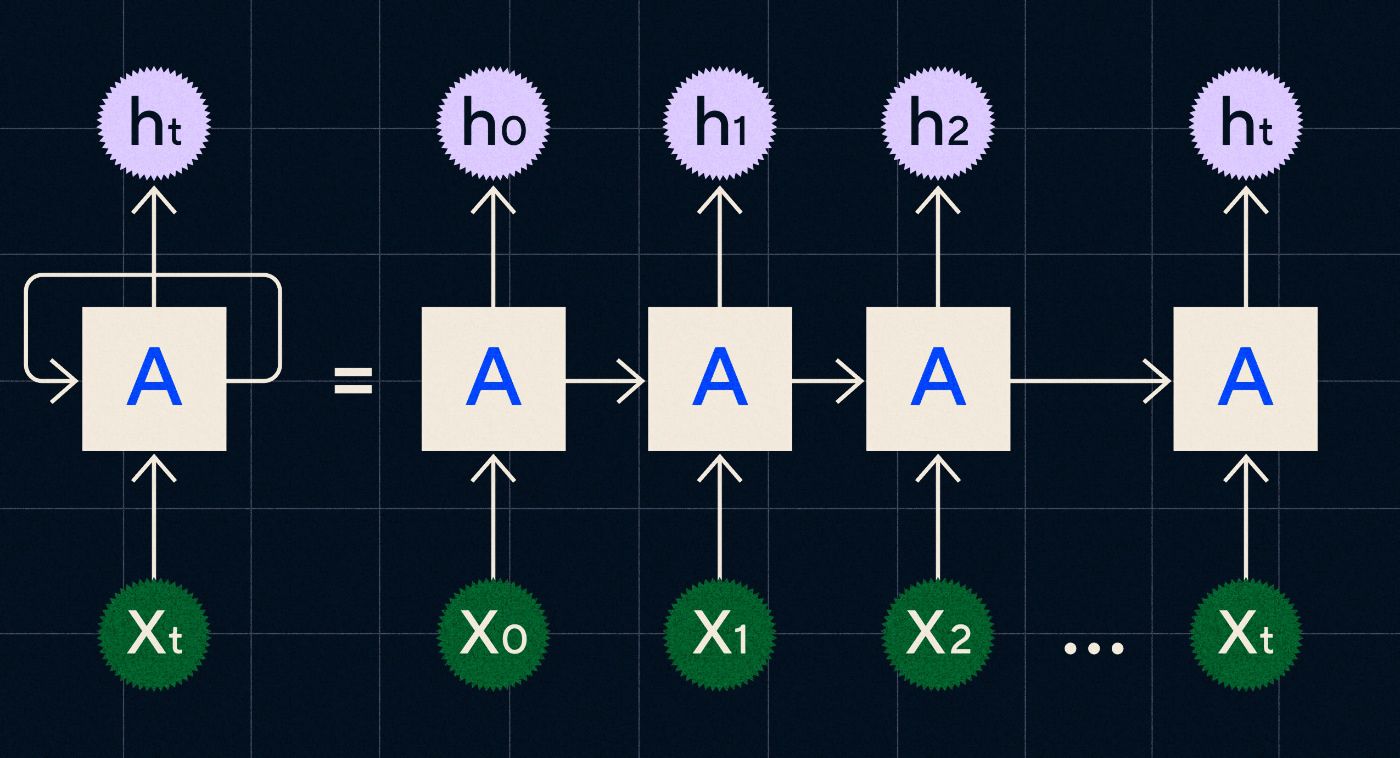
出典: RNN に関する Christopher Olah のブログ投稿
上の図は、前のステップの出力 (h0、h1、h2…ht) が次のステップに引き継がれる一連のニューラル ネットワーク (A) として RNN を描く方法を示しています。 各ステップでは、新しい入力 (X0、X1、X2 … Xt) もネットワークによって処理されます。
RNN (特に、1997 年に Sepp Hochreiter と Jurgen Schmidhuber によって導入された特別なタイプの RNN である Long Short Term Memory network (LSTM)) により、翻訳などのより複雑なタスクを実行できるニューラル ネットワーク アーキテクチャを作成できるようになりました。
2014 年に、Google の Ilya Sutskever (OpenAI の共同創設者)、Oriol Vinyals、Quoc V Le によって、Sequence to Sequence (Seq2Seq) モデルについて説明した論文が発表されました。 この論文では、入力テキストを受け取り、そのテキストの翻訳を返すようにニューラル ネットワークをトレーニングする方法を示しました。 これは、プロンプトを与えると応答を返す、生成ニューラル ネットワークの初期の例と考えることができます。 ただし、タスクは固定されているため、翻訳についてトレーニングされている場合は、他のことを行うようにタスクに「促す」ことはできません。
以前のモデル Word2Vec は単一の単語しか処理できなかったことを思い出してください。 したがって、「歯医者に歯を抜かれた」のような文を渡すと、単語ごとに無関係であるかのようにベクトルが生成されるだけです。
ただし、翻訳などのタスクでは順序と文脈が重要です。 個々の単語を単に翻訳することはできず、一連の単語を解析して結果を出力する必要があります。 ここで、RNN によって Seq2Seq モデルがこの方法で単語を処理できるようになりました。
Seq2Seq モデルの鍵は、2 つの RNN を連続して使用するニューラル ネットワーク設計でした。 1 つはテキストからの入力をエンベディングに変換するエンコーダーで、もう 1 つはエンコーダーによって出力されたエンベディングを入力として受け取るデコーダーでした。
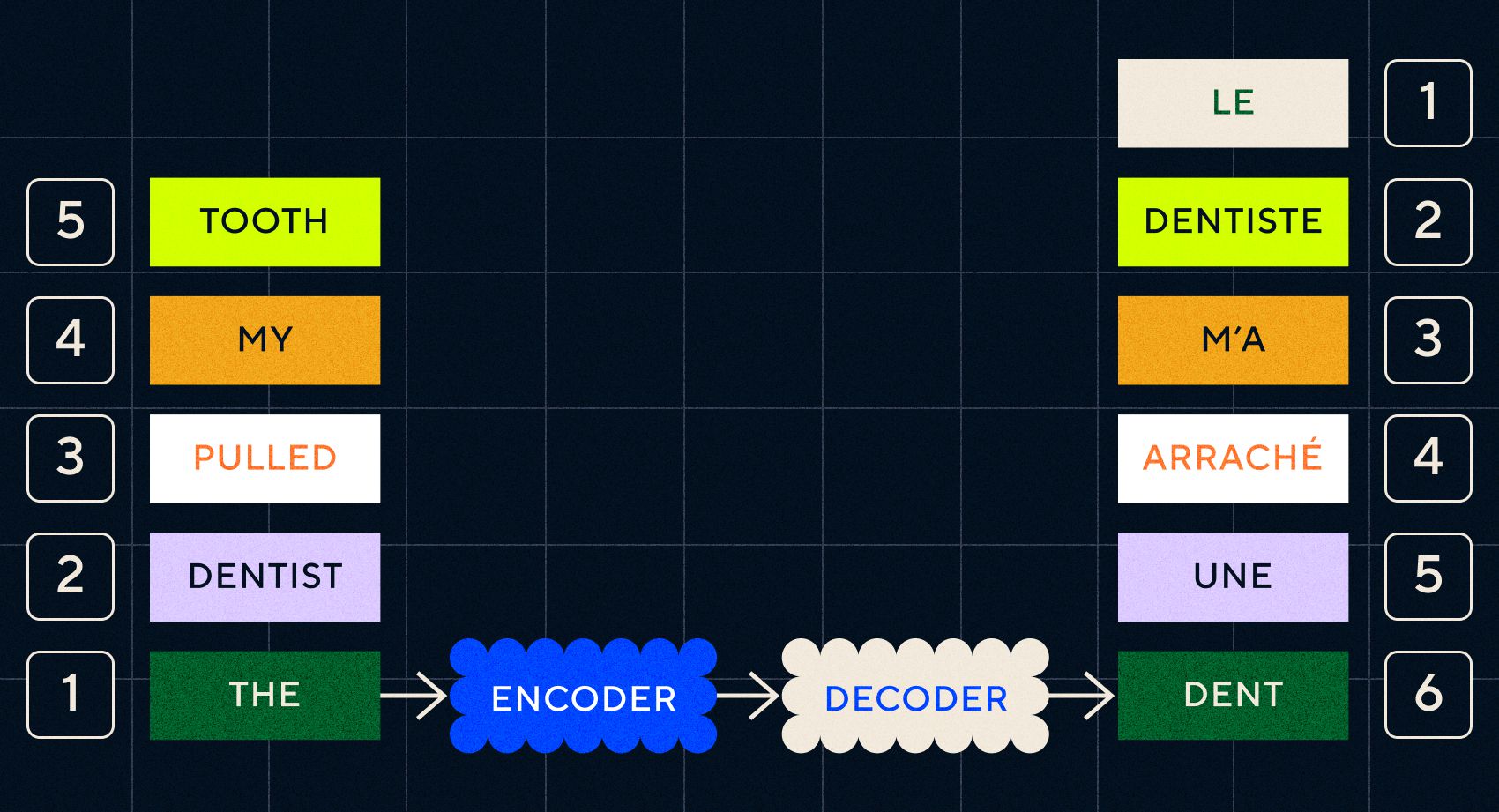
エンコーダーは各ステップで入力を処理すると、エンベディングを翻訳されたテキストに変換するデコーダーに出力を渡し始めます。
これらのモデルの進化を見ると、今日 ChatGPT で見られるものに、何らかの単純な形で似てきていることがわかります。 ただし、比較すると、これらのモデルがいかに制限されていたかがわかります。 私たち自身の言語発達と同様、言語能力を真に向上させるには、より複雑なフレーズや文章を作成するために何に注意を払うべきかを正確に知る必要があります。
モデル 3 – 注意による学習と Transformers によるスケーリング
電信段階では、子供たちが 2 つ以上の単語からなる短い文を作り始めると前述しました。 言語習得のこの段階の重要な側面の 1 つは、子供たちが適切な文の組み立て方を学び始めていることです。
RNN と Seq2Seq モデルは、言語モデルが複数の単語シーケンスを処理するのに役立ちましたが、処理できる文の長さには依然として制限がありました。 文の長さが長くなると、文中のほとんどのことに注意を払う必要があります。
たとえば、「部屋にはナイフで切れるほどの緊張感があった」という文を考えてみましょう。 そこではたくさんのことが起こっています。 ここで文字通りナイフで何かを切っているわけではないことを知るには、文の前半で「切る」と「張力」を結び付ける必要があります。
文の長さが長くなると、適切な意味を推測するためにどの単語がどれを指しているのかを知ることが難しくなります。 ここで RNN が限界に直面し始め、言語習得の次の段階に進むための新しいモデルが必要になりました。
「会話がどんどん長くなってきたら、決まった語数制限で会話を要約することを考えてみてください。 一歩を踏み出すごとに、ますます多くの情報が失われ始めます。」
2017 年、Google の研究者グループは、モデルがテキスト内の重要なコンテキストに注意を向けられるようにする手法を提案した論文を発表しました。
彼らが開発したのは、言語モデルがテキストの入力シーケンスを処理する際に必要なコンテキストをより簡単に検索する方法でした。 彼らはこのアプローチを「トランスフォーマー アーキテクチャ」と呼び、これは自然言語処理におけるこれまでで最大の進歩を表しました。
この検索メカニズムにより、モデルは、処理中の現在の単語に、前の単語のどれがより多くのコンテキストを提供したかを識別しやすくなります。 RNN は、各ステップですでに処理されたすべての単語の集約状態を渡すことによってコンテキストを提供しようとします。 会話がどんどん長くなってきたら、決まった語数制限で会話を要約することを考えてみましょう。 ステップが進むごとに、ますます多くの情報が失われ始めます。 代わりに、トランスフォーマーは、コンテキストの観点から現在の単語に対する重要性に基づいて、単語 (または単語全体ではなく単語の一部であるトークン) に重み付けを行いました。 これにより、RNN で見られるボトルネックを発生させることなく、ますます長い単語のシーケンスを処理することが容易になりました。 この新しいアテンション メカニズムにより、RNN のようにテキストを順次ではなく並行して処理することも可能になりました。

そこで、「動物は疲れすぎていたので、通りを渡らなかった」のような文を想像してみてください。 RNN の場合、各ステップで前のすべての単語を表す必要があります。 「それ」と「動物」の間にある単語の数が増えると、RNN が適切なコンテキストを識別することが難しくなります。
変圧器アーキテクチャにより、モデルは「それ」を指す可能性が最も高い単語を検索できるようになりました。 以下の図は、トランスフォーマー モデルが文を処理しようとする際に、テキストの「動物」の部分にどのように焦点を当てることができるかを示しています。
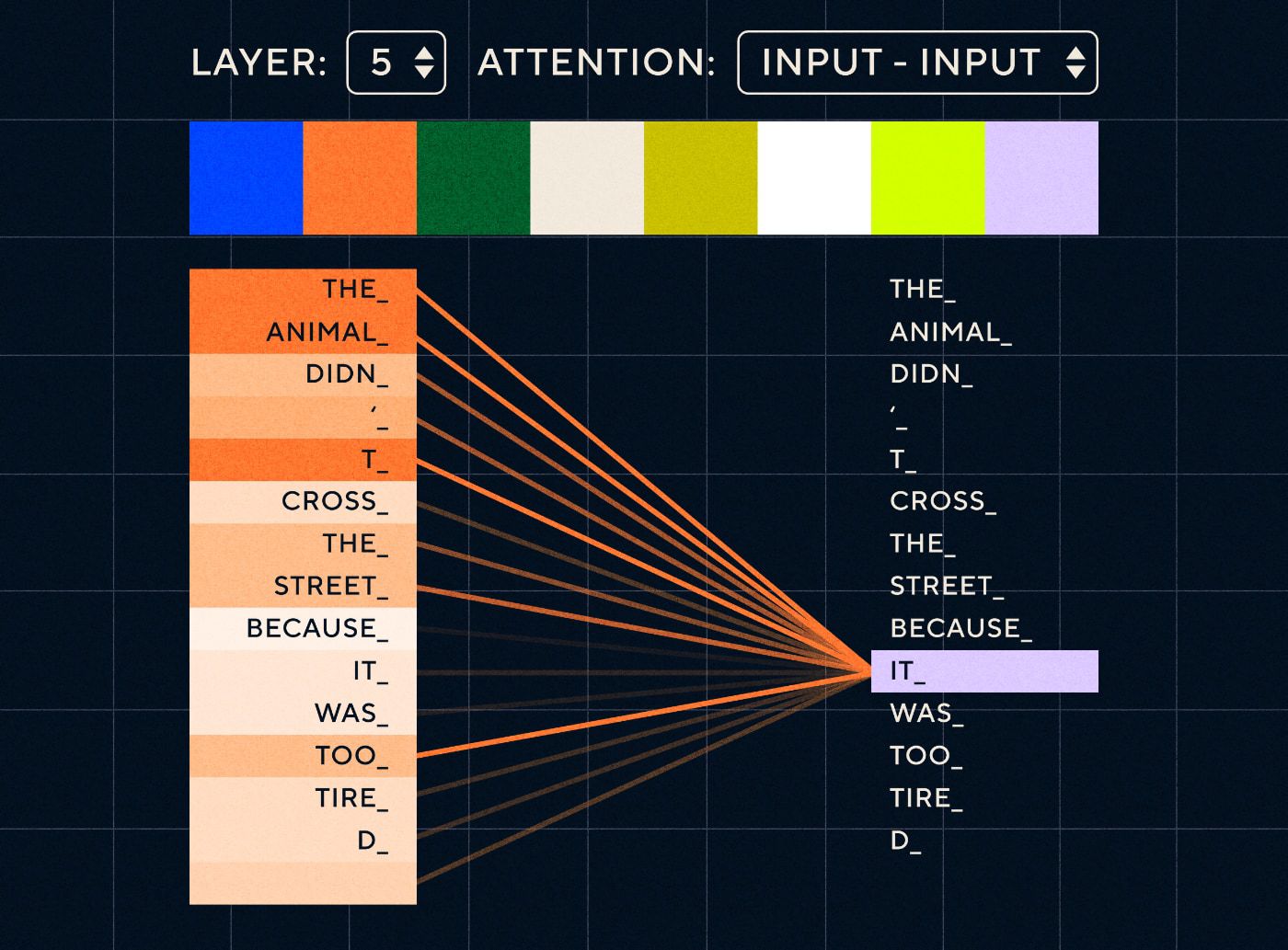
出典: 図解トランスフォーマー
上の図は、ネットワークのレイヤー 5 での注意を示しています。 各層で、モデルは文の理解を構築し、その時点で処理しているステップにより関連すると思われる入力の特定の部分に「注意を払っています」。つまり、「このレイヤーの「それ」は「animal」です。 出典: 図解されたトランスフォーマー
これは、「それ」に関連する可能性が最も高い、最高スコアの単語を検索できるデータベースのようなものだと考えてください。
この開発により、言語モデルは短いテキストシーケンスの解析に限定されなくなりました。 代わりに、長いテキスト シーケンスを入力として使用できます。 「熱心な会話」を通じて子どもたちがより多くの言葉に触れることは、言語発達の改善に役立つことがわかっています。
同様に、新しいアテンション メカニズムにより、言語モデルはより多くのさまざまな種類のテキスト トレーニング データを解析できるようになりました。 これには、Wikipedia の記事、オンライン フォーラム、Twitter、および解析できるその他のテキスト データが含まれます。 小児期の発達と同様に、これらすべての単語とさまざまな文脈でのその使用法に触れることは、言語モデルが新しく、より複雑な言語能力を開発するのに役立ちました。
何が学べるかを確認するために、人々がこれらのモデルにますます多くのデータを投げるスケーリング競争が見られ始めたのはこの段階でした。 このデータには人間がラベルを付ける必要はありません。研究者はインターネットをスクレイピングしてモデルに入力し、何が学習されたかを確認するだけで済みました。
「BERT のようなモデルは、利用可能な自然言語処理の記録をすべて破りました。 実際、これらのタスクに使用されたテスト データセットは、これらの変圧器モデルにはあまりにも単純すぎました。」
BERT (Bidirectional Encoder Representations from Transformers) モデルは、いくつかの理由から特別に言及する価値があります。 これは、Transformer アーキテクチャの中核であるアテンション機能を利用した最初のモデルの 1 つです。 まず、BERT は現在の入力の左と右の両方のテキストを参照できるという点で双方向でした。 これは、テキストを左から右に順次処理することしかできない RNN とは異なります。 第二に、BERT は「マスキング」と呼ばれる新しいトレーニング手法も使用しました。これは、モデルが「不正行為」できないようにするために、ランダムなトークンを「隠す」または「マスクする」ことで、ある意味、モデルにさまざまな入力の意味を強制的に学習させます。各反復で単一のトークンに焦点を当てます。 そして最後に、BERT を微調整して、さまざまな NLP タスクを実行できるようになります。 これらのタスクのためにゼロからトレーニングする必要はありませんでした。
結果は驚くべきものでした。 BERT のようなモデルは、利用可能な自然言語処理の記録をすべて破りました。 実際、これらのタスクに使用されたテスト データセットは、これらの変圧器モデルにとってはあまりにも単純すぎました。
これで、新しい自然言語処理タスクの基礎モデルとして機能する大規模な言語モデルをトレーニングできるようになりました。 以前はモデルをゼロからトレーニングすることがほとんどでした。 しかし、BERT や初期の GPT モデルのような事前トレーニング済みモデルは非常に優れているため、自分で行う意味がありませんでした。 実際、これらのモデルは、比較的少ない例で新しいタスクを実行できることを人々が発見した非常に優秀なモデルでした。ほとんどの人が新しい概念を理解するのにそれほど多くの例を必要としないのと同じように、これらのモデルは「数回の学習で学習できる人」と呼ばれていました。
これは、これらのモデルとその言語機能の開発における大きな転換点でした。 あとは、指示を作成する方法を改善するだけです。
モデル 4 – InstructGPT を使用した学習命令
子どもたちが言語習得の最終段階である多語段階で学ぶことの 1 つは、機能語を使用して文内の情報を伝える要素を接続する能力です。 機能語は、文内の異なる単語間の関係を教えてくれます。 命令を作成したい場合、ランガージュ モデルは、複雑な関係を捉える内容語と機能語を含む文を作成できる必要があります。 たとえば、次の命令では機能語が太字で強調表示されています。
- 「手紙を書いてほしいのですが…」
- 「上の文章についてどう思うか教えてください」
しかし、命令に従うように言語モデルをトレーニングする前に、言語モデルが命令についてすでに知っていることを正確に理解する必要がありました。
OpenAI の GPT-3 は 2020 年にリリースされました。これらのモデルの機能を垣間見ることができましたが、これらのモデルの基礎となる機能を解放する方法を理解する必要がありました。 これらのモデルと対話して、さまざまなタスクを実行させるにはどうすればよいでしょうか?
たとえば、GPT-3 は、モデルのサイズとトレーニング データを増やすことで、著者らが「メタ学習」と呼ぶものが可能になることを示しました。これは、言語モデルが広範な言語能力を開発する場所であり、その多くは予期せぬものであり、それらの能力を使用できるようになります。与えられたタスクを理解するスキル。
「モデルは単に次の単語を予測するのではなく、命令の意図を理解してタスクを実行できるでしょうか?」
GPT-3 およびそれ以前の言語モデルは、これらのスキルを開発するように設計されていないことを思い出してください。主に、一連のテキスト内の次の単語を予測するためだけに訓練されていました。 しかし、RNN、Seq2Seq、アテンション ネットワークの進歩により、これらのモデルはより多くのテキストをより長いシーケンスで処理し、関連するコンテキストにさらに焦点を当てることができるようになりました。
GPT-3 は、これをどこまで実現できるかを確認するためのテストと考えることができます。 モデルをどのくらいの大きさで作成でき、どのくらいの量のテキストをフィードできるでしょうか? その後、モデルを完了させるためにモデルに入力テキストを与えるだけでなく、入力テキストを命令として使用することができます。 モデルは単に次の単語を予測するのではなく、命令の意図を理解してタスクを実行できるでしょうか? ある意味、それはこれらのモデルが言語習得のどの段階に達しているかを理解しようとしているようなものでした。
今ではこれを「促す」と表現しますが、この論文が発表された 2020 年当時、これは非常に新しい概念でした。
幻覚と調整
今ではわかっているように、GPT-3 の問題は、入力テキストの指示に厳密に従うのが苦手だということでした。 GPT-3 は指示に従うことができますが、すぐに注意を失い、簡単な指示しか理解できず、でっちあげてしまう傾向があります。 言い換えれば、モデルは私たちの意図と「一致」していません。 したがって、現在の問題は、モデルの言語能力を向上させることではなく、指示に従う能力です。
GPT-3は実際には指示に従って訓練されていないことは注目に値します。 指示が何であるか、他のテキストとどう違うのか、指示にどのように従うべきなのかについては説明されていませんでした。 ある意味、他の一連のテキストと同様に、プロンプトを「完了」させることで、「だまされて」指示に従うことになります。 その結果、OpenAI は人間のように指示に従うことができるモデルをトレーニングする必要がありました。 そして彼らは、2022 年初めに出版された、「人間のフィードバックを伴う指示に従う言語モデルのトレーニング」という適切なタイトルの論文でそれを行いました。InstructGPT は、同じ年の後半に ChatGPT の前身であることが判明します。
この論文で概説されている手順は、ChatGPT のトレーニングにも使用されました。 指導トレーニングは 3 つの主なステップに従って行われました。
- ステップ 1 – GPT-3 を微調整する: GPT-3 は少数ショット学習で非常にうまく機能するように見えたので、高品質の命令例に基づいて微調整すればより良いのではないかと考えられました。 目標は、命令内の意図と生成された応答を簡単に一致させることでした。 これを行うために、OpenAI は、GPT-3 を使用してユーザーが送信したいくつかのプロンプトに対する応答を人間のラベル作成者に作成させました。 著者らは、実際の命令を使用することで、ユーザーが GPT-3 に実行させようとしているタスクの現実的な「分布」を把握することを望んでいました。これらの命令は、GPT-3 の即時応答能力を向上させるために GPT-3 を微調整するために使用されました。
- ステップ 2 – 新しく改良された GPT-3 を人間にランク付けしてもらう: 新しい命令の微調整された GPT-3 を評価するために、ラベル付け担当者は、事前定義された応答なしでさまざまなプロンプトでモデルのパフォーマンスを評価しました。 このランキングは、有益であること、真実であること、有害ではないこと、偏見や有害でないことなど、重要な調整要素に関連していました。 したがって、モデルにタスクを与え、これらのメトリクスに基づいてパフォーマンスを評価します。 次に、このランキング演習の出力を使用して別のモデルをトレーニングし、ラベラーがどの出力を好む可能性が高いかを予測しました。 このモデルは報酬モデル (RM) として知られています。
- ステップ 3 – RM を使用して他の例でトレーニングする:最後に、RM を使用して新しい命令モデルをトレーニングし、人間の好みに合わせた応答をより適切に生成しました。
ヒューマン フィードバックからの強化学習 (RLHF)、報酬モデル、ポリシーの更新などで何が起こっているのかを完全に理解するのは困難です。
簡単に考えると、これは人間が指示に従う方法のより良い例を生成できるようにするための単なる方法であるということです。 たとえば、子供に感謝の言葉をどのように教えるかを考えてみましょう。
- 親:「誰かがXをくれたら、ありがとうと言います。」 これはステップ 1 であり、プロンプトと適切な応答のデータセットの例です。
- 親:「さて、ここでYさんに何と言いますか?」 これはステップ 2 で、子供に応答を生成するように依頼し、親がそれを評価します。 「はい、それはいいですね。」
- 最後に、その後の遭遇では、親は将来の同様のシナリオでの反応の良い例または悪い例に基づいて子供に報酬を与えます。 これはステップ 3 であり、強化行動が行われます。
一方、OpenAIは、論文が述べているように、GPT-3などのモデルにすでに存在していたが、「迅速なエンジニアリングだけでは引き出すのが難しかった」機能を単に解除するだけだと主張している。
言い換えれば、ChatGPT は実際には「新しい」機能を学習しているのではなく、単にそれらを利用するためのより優れた言語的な「インターフェース」を学習しているだけなのです。
言語の魔法
ChatGPT は魔法のような飛躍のように感じられますが、実際には数十年にわたる骨の折れる技術進歩の結果です。
過去 10 年間の AI と NLP の分野における主要な発展のいくつかを見ると、ChatGPT がいかに「巨人の肩の上に立っている」かがわかります。 以前のモデルは、まず単語の意味を識別することを学習しました。 その後、後続のモデルがこれらの単語を組み合わせて、翻訳などのタスクを実行するようにトレーニングできるようになりました。 文を処理できるようになると、これらの言語モデルがより多くのテキストを処理し、学習したことを新しい予期せぬタスクに適用する能力を開発できるようにする技術を開発しました。 そして、ChatGPT を使用して、自然言語形式で命令を指定することで、これらのモデルとより適切に対話できる機能を最終的に開発しました。
「言語は私たちの思考の手段であるため、コンピュータに言語の全能力を教えれば、独立した人工知能が実現するでしょうか?」
しかし、NLP の進化は、私たちが普段は気づいていない、より深い魔法、つまり言語そのものの魔法と、私たちが人間としてそれをどのように習得するかということを明らかにします。
そもそも子供たちがどのようにして言語を学ぶのかについては、まだ多くの未解決の疑問や論争が残っています。 すべての言語に共通の基礎構造があるかどうかについても疑問があります。 人間は言語を使用するように進化したのでしょうか、それともその逆なのでしょうか?
興味深いのは、ChatGPT とその子孫が言語発達を改善するにつれて、これらのモデルがこれらの重要な質問のいくつかに答えるのに役立つ可能性があるということです。
最後に、言語は私たちの思考の媒体であるため、コンピュータに言語のフルパワーを教えることは、独立した人工知能につながるでしょうか? 人生においていつもそうであるように、学ぶべきことはたくさん残っています。
