
ウィキペディアとGoogle言語APIを使用したトピックグラフのハッキング
公開: 2019-08-27過去10年間の私のお気に入りのスライドデッキの1つは、彼がまだDistilledにいる間に、2014年にMarkJohnstoneによって作成されました。 このデッキは「より良いコンテンツのアイデアを生み出す方法」と呼ばれ、コンテンツプロモーションのハードワークを行うチームを構築する間、数年間聖書として使用しました。
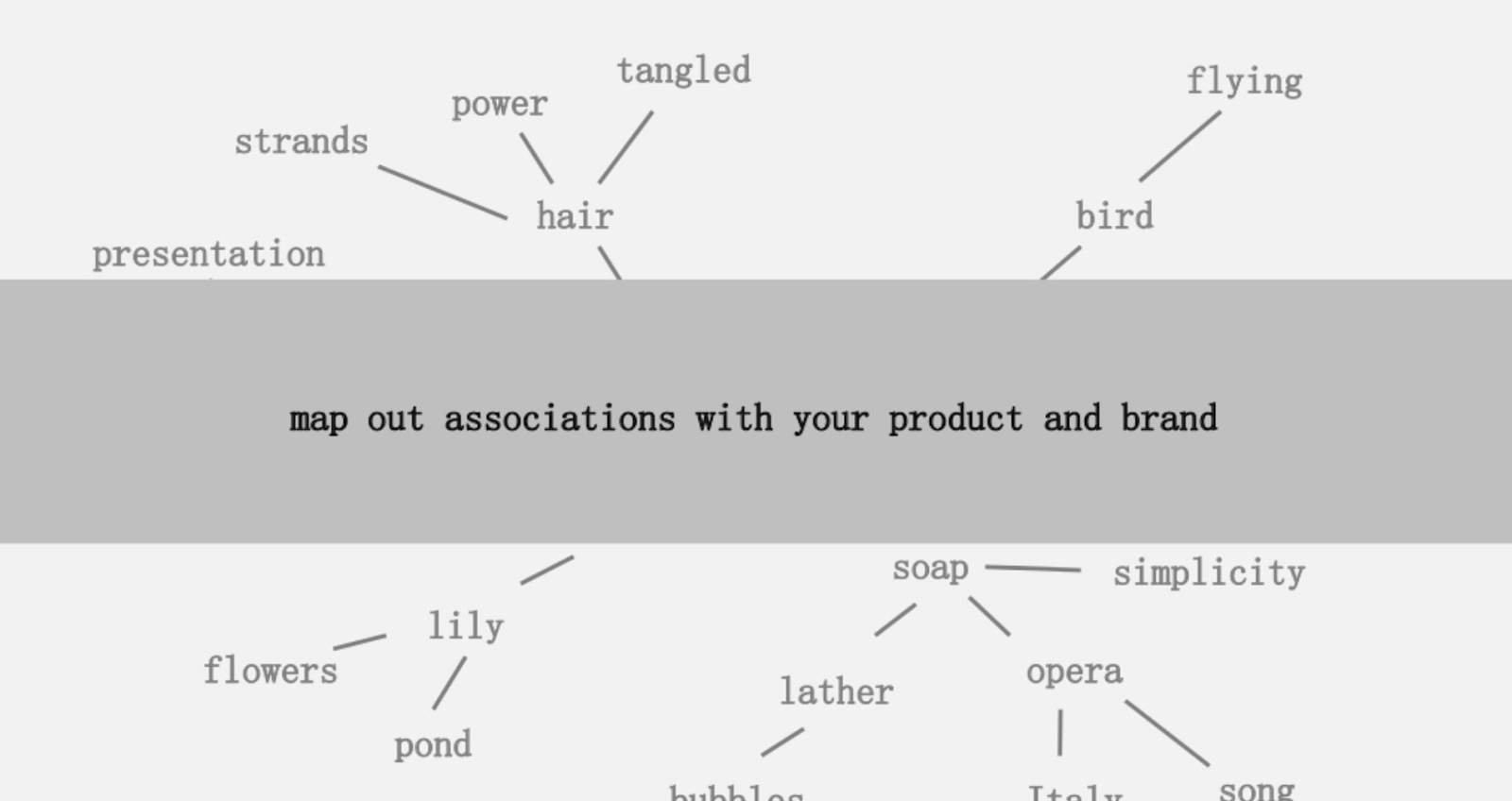
提供されたアイデアの1つは、製品またはブランドに関連付けられた単語の関連性の視覚的なマッピングを作成して、立ち止まり、関連付けを組み合わせて興味深いものにする方法を探すことでした。 目標はアイデアの生成であり、彼はそれを「価値を付加する方法で、以前は接続されていなかった要素の斬新な組み合わせ」と定義しています。
この記事では、Python、GoogleのLanguage API、およびWikipediaを使用して、シードトピックから存在するエンティティの関連付けを調査することにより、はるかに左脳的なアプローチを取ります。 目標は、トピックグラフに沿ったエンティティ関係の高レベルのビューです。 この記事は平均的な読者向けではありません。 Pythonに精通していて、少なくとも基本レベルのコーディング能力を持っている読者は、Pythonがはるかに有益であることに気付くでしょう。
アイデア
Mark Johnstoneのマッピングのアイデアに続いて、シードトピックまたはWebページから始まるトピック構造をGoogleとWikipediaに定義させるのは興味深いと思いました。 目標は、メイントピックへの関係のマッピングを視覚的に構築することです。ツリーのようなグラフで、接続を探し、場合によってはコンテンツのアイデアを生成するために確認できます。 次の画像は、初期の設計アイデアを表しています。
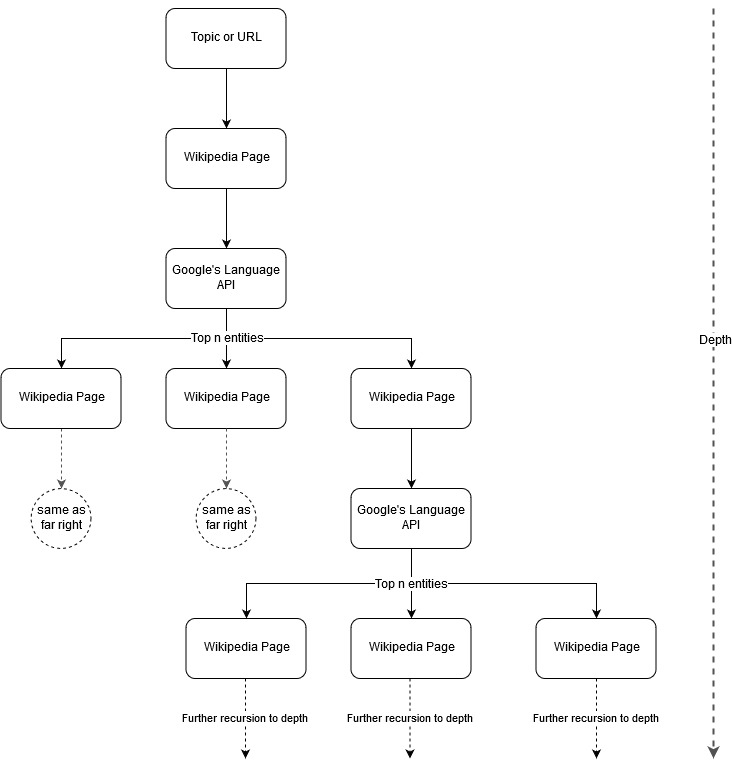
基本的に、ツールにトピックまたはURLを指定し、GoogleのLanguage APIに各エンティティページの上位n個(例では3個)のエンティティ(ウィキペディアのURLを含む)を選択させ、見つかった各エンティティのネットワークグラフを繰り返し作成します最大深度まで。
使用したツールの背景
Google言語API
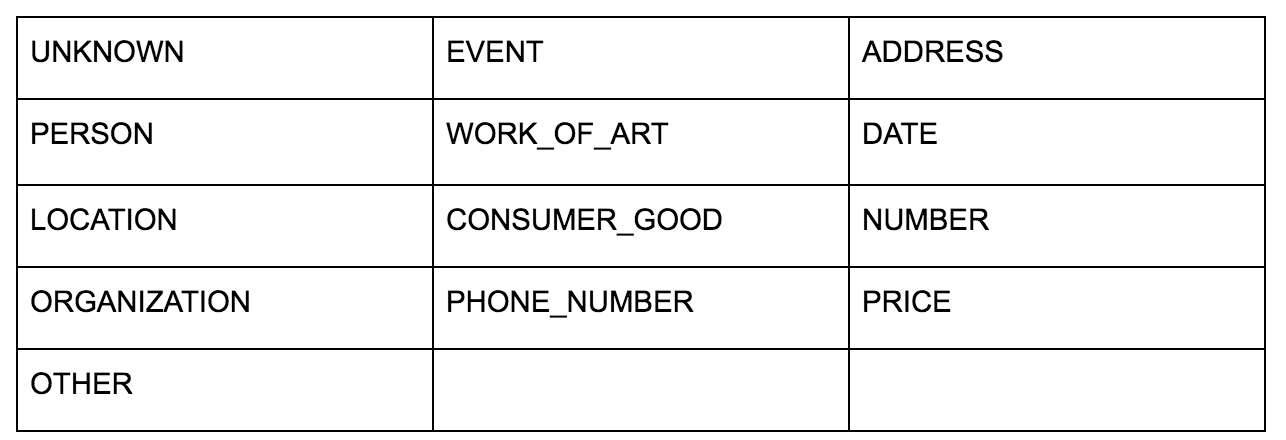
GoogleのLanguageAPIを使用すると、プレーンテキストまたはHTMLのいずれかを渡すことができ、コンテンツに関連付けられているさまざまなエンティティをすべて魔法のように返します。 APIはこれ以上のことを行いますが、この分析では、この部分のみに焦点を当てます。 返されるエンティティのタイプのリストは次のとおりです。
エンティティの識別は、長い間自然言語処理(NLP)の基本的な部分であり、タスクの正しい用語は、名前付きエンティティ認識(NER)です。 多くの単語は使用されるコンテキストに基づいて異なる意味を持つため、NERは難しい作業です。そのため、NLPツールまたはAPIは、用語を取り巻く完全なコンテキストを理解して、それらを特定のエンティティとして適切に識別できるようにする必要があります。
この記事を終える前にいくつかのコンテキストに追いつきたい場合は、opensource.comの記事で、このAPI、特にエンティティの非常に詳細な概要を説明しました。
GoogleのLanguageAPIの興味深い機能の1つは、関連するエンティティを見つけることに加えて、それらがドキュメント全体(顕著性)にどの程度関連しているかを示し、エンティティを表す関連するWikipedia(知識グラフ)の記事を提供することです。
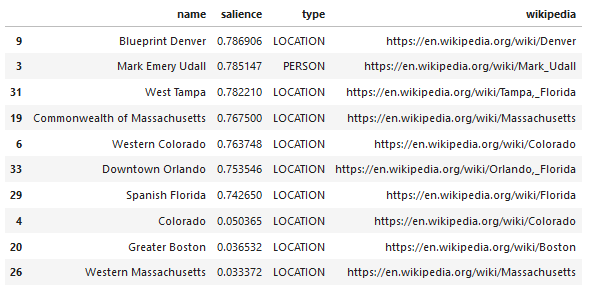
APIが返すものの出力例を次に示します(salienceでソート)。
オンクロール開発者
 もっと詳しく知る
もっと詳しく知るPython
Pythonは、大規模なデータセットの取り込み、クリーンアップ、操作、分析を容易にするライブラリの大規模で成長しているセットにより、データサイエンスの分野で普及しているソフトウェア言語です。 また、Jupyterノートブックと呼ばれるコラボレーション環境の恩恵を受けており、ユーザーは簡単にコードをテストして注釈を付けることができます。
このレビューでは、GoogleのNLPデータを使用していくつかの興味深いことを実行できるようにするいくつかの主要なライブラリを使用します。
- パンダ: Microsoft Excelをスクリプト化してスプレッドシートを読み取ったり、保存したり、解析したり、再配置したりできると考えてください。そうすれば、パンダが何をするのかがわかります。 パンダは素晴らしいです。 (リンク)
- Networkx: Networkxは、ノード間の関係を定義するノードとエッジのグラフを作成するためのツールです。 また、グラフを簡単に視覚化できるように、グラフをプロットするためのサポートが組み込まれています。 (リンク)
- Pywikibot: Pywikibotは、ウィキペディアと対話して、各ウィキペディアサイトのすべてのコンテンツを検索、編集、関係の検索などを行うことができるライブラリです。 (リンク)
プロセス
ここでは、フォローに使用できるGoogleColabノートブックを共有しています。 (記事とこのノートブックの健全性チェックをしてくれたTyler Reardonに特に感謝します。)
セットアップ
ノートブックの最初のいくつかのセルは、いくつかのライブラリのインストール、それらのライブラリをPythonで利用できるようにすること、およびGoogleのLanguageAPIとPywikibotの資格情報と構成ファイルをそれぞれ提供することを扱います。 ツールを確実に実行するためにインストールする必要のあるすべてのライブラリは次のとおりです。
- パンダ
- リクエスト
- httplib2
- google-cloud-language
- pywikibot
- networkx
- バリデーター
- Bs4
注:このノートブックを実行できる最も難しい部分は、APIにアクセスするためにGoogleからクレデンシャルを取得することです。 これに不慣れな人にとって、これは理解するのに1時間かそこらかかるでしょう。 ノートブックの上部にあるサービスアカウントのクレデンシャルを取得するための手順をリンクしました。 以下は、私たちがどのように私たちを含めたかの例です。
勝利のための機能
「GoogleNLPのいくつかの関数を定義する」で示されるセルでは、Language APIのクエリ、Wikipediaとの対話、Webページのテキストの抽出、グラフの作成とプロットなどを処理する8つの関数を開発します。 関数は本質的に、いくつかの設定データを取り込んで、いくつかの作業を行い、何かを生成する小さなコード単位です。 すべての関数は、それらが取り込む変数とそれらが生成するものを伝えるためにコメント化されています。

APIのテスト
次の2つのセルは、URLを取得し、URLからテキストを抽出し、GoogleのLanguageAPIからエンティティをプルします。 1つはウィキペディアのURLを持つエンティティのみをプルし、もう1つはそのページからすべてのエンティティをプルします。
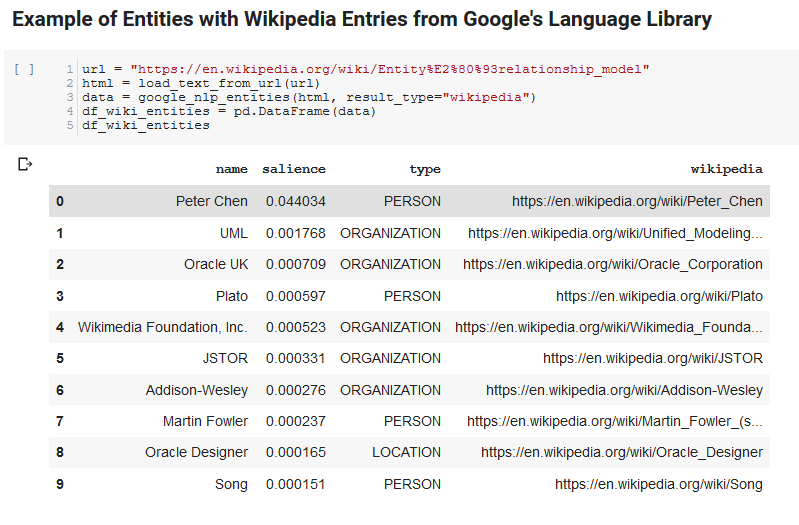
これは、コンテンツ抽出部分を正しくし、Language APIがどのように機能し、データを返すかを理解するための重要な最初のステップでした。
Networkx
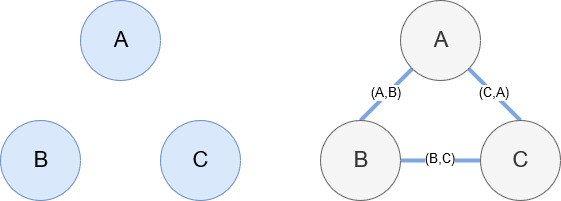
Networkxは、前述のように、かなり直感的に操作できる素晴らしいライブラリです。 基本的に、ノードとは何か、ノードがどのように接続されているかを伝える必要があります。 たとえば、次の画像では、Networkxに3つのノード(A、B、C)を指定しています。 次に、ノード間の関係を定義するエッジ(A、B)、(B、C)、(C、A)によって接続されていることをNetworkxに通知します。 私たちの使用法では、ウィキペディアのURLを持つエンティティがノードになり、エッジは現在のエンティティページで見つかった新しいエンティティによって定義されます。 したがって、エンティティAのウィキペディアページを確認していて、そのページでエンティティBが検出された場合、それはエンティティAとエンティティBの間のエッジです。
すべてを一緒に入れて
ノートブックの次のセクションは、 URLによるウィキペディアトピック分岐と呼ばれます。 ここで魔法が起こります。 Googleの言語APIによって定義された新しいエンティティに続いて、ウィキペディアのページを繰り返す特別な関数(recurse_entities)を以前に定義しました。 また、Stack Overflowから持ち上げた、非常にわかりにくい関数(hierarchy_pos)を追加しました。この関数は、多くのノードを持つツリーのようなグラフを適切に表示します。 以下のセルでは、入力を「検索エンジン最適化」として定義し、深さ3(再帰的に続くページ数)と制限3(ページごとにプルするエンティティ数)を指定します。
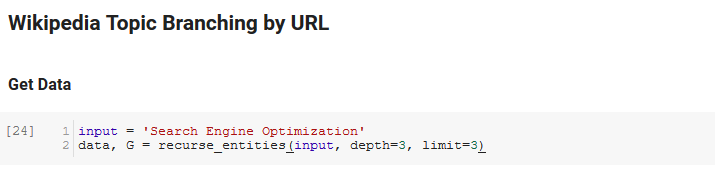
「検索エンジン最適化」という用語で実行すると、ウィキペディアの検索エンジン最適化ページ(レベル0)から始まり、指定された最大深度(3)までのページを再帰的にたどって、ツールがたどった次のパスを確認できます。

次に、見つかったすべてのエンティティを取得してPandas DataFrameに追加します。これにより、CSVとしての保存が非常に簡単になります。 このデータを顕著性(エンティティが見つかったページにとってどれほど重要か)で並べ替えますが、このスコアは、エンティティが元の用語にどの程度関連しているかを示していないため、このコンテキストでは少し誤解を招く可能性があります(「検索エンジン最適化")。 そのさらなる作業は読者に任せます。

最後に、ツールによって作成されたグラフをプロットして、すべてのエンティティの接続性を示します。 以下のセルで、関数に渡すことができるパラメーターは次のとおりです。( G :recurse_entities関数によって事前に作成されたグラフ、 w:プロットの幅、 h:プロットの高さ、 c:パーセント円形プロット、およびファイル名:画像フォルダに保存されるPNGファイル。)

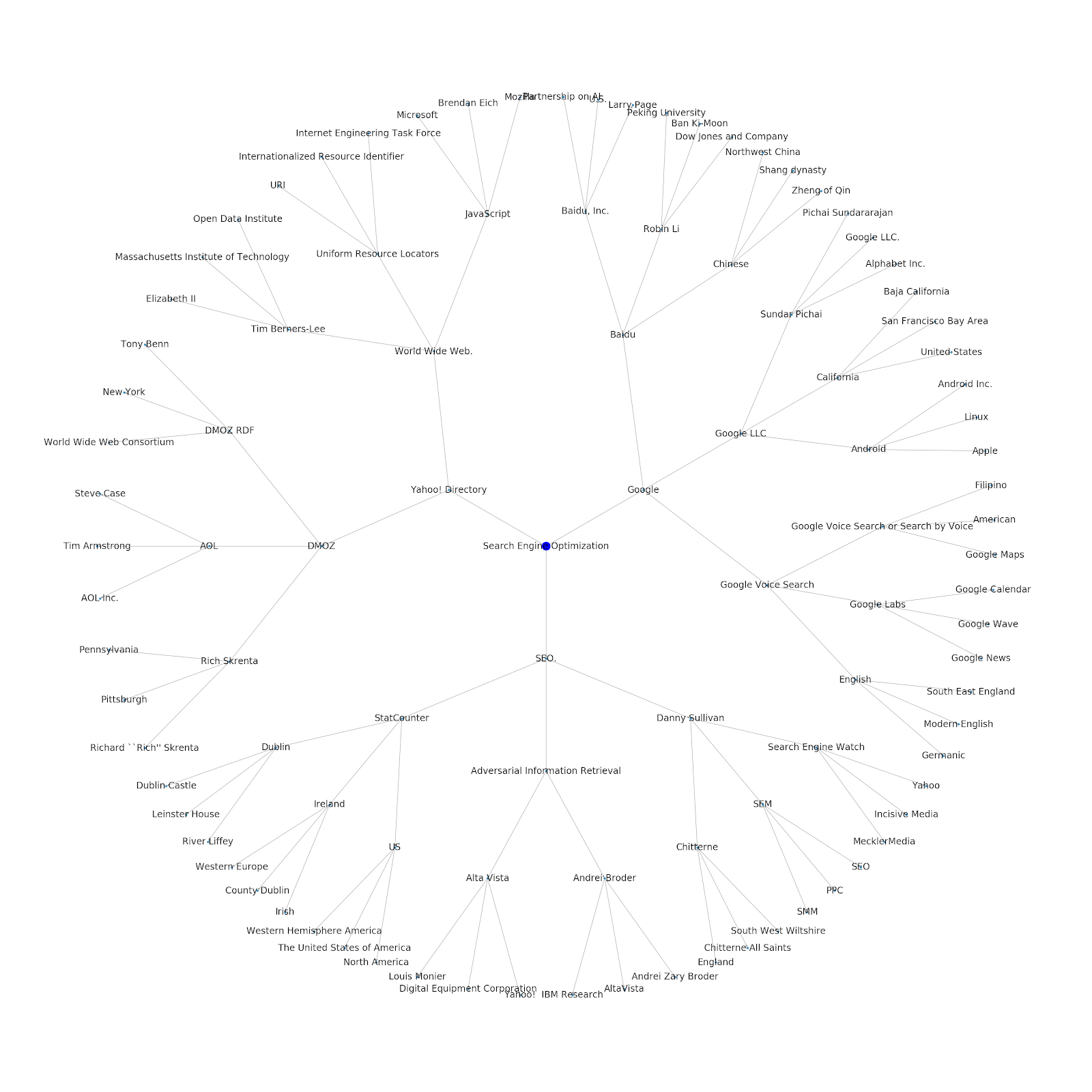
シードトピックまたはシードURLのいずれかを提供する機能を追加しました。 この場合、Googleのインデックス作成の問題は続くという記事に関連するエンティティを調べますが、これは異なります
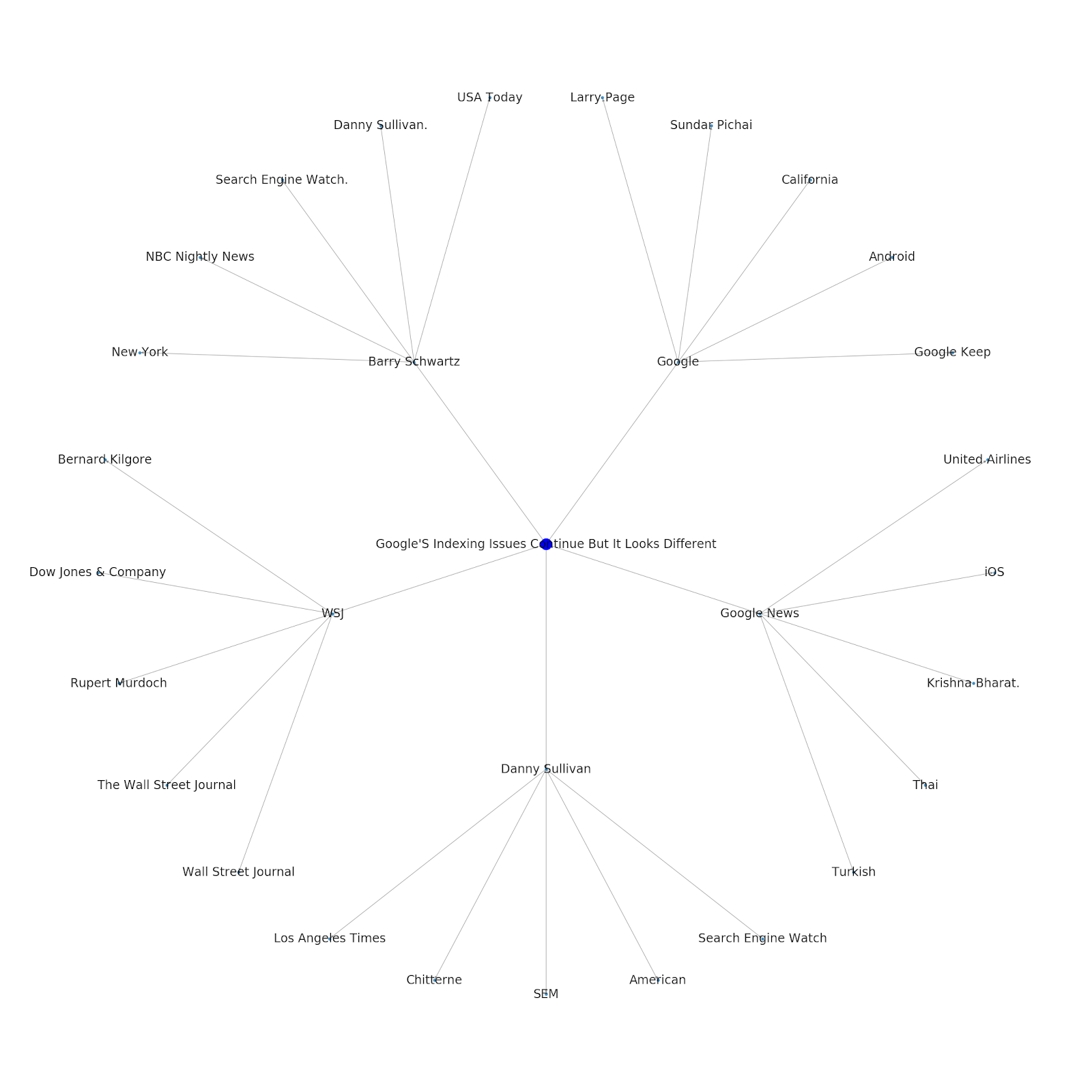
これがPythonのGoogle/Wikipediaエンティティグラフです。
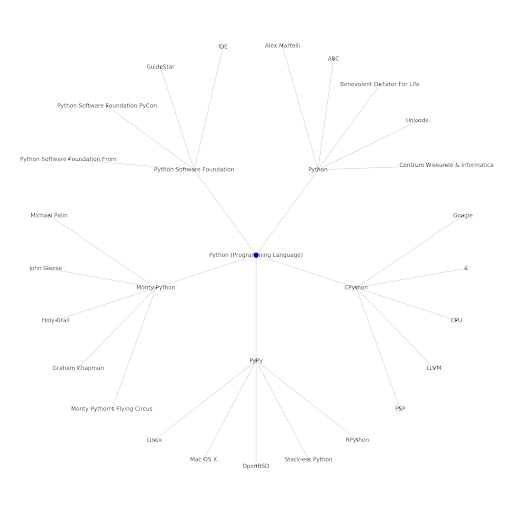
これが意味すること
インターネットのトピックレイヤーを理解することは、SEOの観点から興味深いものです。それは、個々のクエリだけでなく、物事がどのように接続されているかという観点から考える必要があるためです。 Google Discoverの再導入で述べたように、Googleはこのレイヤーを使用して個々のユーザーの親和性をトピックに一致させるため、データに焦点を当てたSEOにとってより重要なワークフローになる可能性があります。 上記の「Python」グラフでは、シードトピックに関連するトピックにユーザーが精通していることが、シードトピックに関する専門知識のレベルの妥当な尺度であると推測される場合があります。
以下の例は、2人のユーザーを示しており、緑色のハイライトは、関連するトピックに対する過去の関心または親和性を示しています。 左側のユーザーは、IDEとは何かを理解し、PyPyとCPythonの意味を理解しているので、Pythonが言語であることを知っている人よりも、Pythonの経験が豊富なユーザーですが、それ以外のユーザーはそれほど多くありません。 これは、ユーザーごとに、トピックごとの数値スコアに簡単に変換できます。

結論
今日の私の目標は、JupyterNotebookを使用してさまざまなツールやAPIの有効性をテストおよびレビューするために実行するかなり標準的なプロセスを共有することでした。 トピックグラフの探索は非常に興味深いものであり、共有されているツールを使用して、自分で探索を開始するために必要な最初の一歩を踏み出すことができれば幸いです。 これらのツールを使用すると、GoogleのLanguage APIの割り当て(1日あたり800,000)の範囲に限定されて、多くの関係レベルを調査するトピックグラフを作成できます。 (更新:価格はAPIに送信される1,000個のUnicode文字の単位に基づいており、最大5k単位まで無料です。ウィキペディアの記事は長くなる可能性があるため、支出を監視する必要があります。これを指摘するためのJohn Murchへのヒント。)ノートブックを強化したり、興味深い事例を見つけたりした場合は、お知らせいただければ幸いです。 Twitterの@jroakesで私を見つけることができます。