
動作するRobots.txtを構築するための鍵
公開: 2020-02-18ボットは、クローラーまたはスパイダーとも呼ばれ、リンクを道路として使用して、Webサイト間を自動的に「移動」するプログラムです。 彼らは常に特定の好奇心を示してきましたが、robot.txtファイルは非常に効果的なツールになる可能性があります。 GoogleやBingなどの検索エンジンは、ボットを使用してWebのコンテンツをクロールします。 robots.txtファイルは、さまざまなボットに、サイトでクロールしてはならないページに関するガイダンスを提供します。 また、robots.txtからXMLサイトマップにリンクして、ボットがクロールする必要のあるすべてのページのマップを持つようにすることもできます。
robots.txtが役立つのはなぜですか?
robots.txtは、検索エンジンボットの場合にボットがクロールしてインデックスを作成する必要があるページの量を制限します。 Googleが管理ページをクロールしないようにしたい場合は、robots.txtでそれらをブロックして、Googleのサーバーからページを除外しようとすることができます。
robots.txtは、ページがインデックスに登録されないようにするだけでなく、クロール予算を最適化するのに最適です。 クロール予算は、Googleがサイトでクロールすると判断したページ数です。 通常、権限が多くページ数が多いWebサイトは、ページ数が少なく権限が少ないWebサイトよりもクロールバジェットが大きくなります。 サイトに割り当てられているクロール予算がわからないため、インデックスに登録したくないページをクロールするのではなく、Googlebotが最も重要なページにアクセスできるようにすることで、この時間を最大限に活用したいと考えています。
robots.txtについて知っておく必要のある非常に重要な詳細は、robots.txtによってブロックされているページをGoogleがクロールしない一方で、ページが別のウェブサイトからリンクされている場合でもインデックスに登録できることです。 ページがインデックスに登録されてGoogle検索結果に表示されないようにするには、サーバー上のファイルをパスワードで保護するか、noindexメタタグまたは応答ヘッダーを使用するか、ページを完全に削除する必要があります(404または410で応答します)。 クロールとインデックス作成の制御の詳細については、OnCrawlのrobots.txtガイドをご覧ください。
[ケーススタディ]Googleのボットクロールの管理
 ケーススタディを読む
ケーススタディを読むRobots.txtの構文を修正する
異なるクローラーは構文を異なる方法で解釈するため、robots.txt構文は少し注意が必要な場合があります。 また、評判の悪いクローラーの中には、robots.txtディレクティブを提案と見なし、従う必要のある明確なルールとは見なさないものもあります。 サイトに機密情報がある場合は、robots.txtを使用してクローラーをブロックするだけでなく、パスワード保護を使用することが重要です。
以下に、robots.txtで作業するときに覚えておく必要のあるいくつかの事項を示します。
- robots.txtファイルは、サブディレクトリではなく、ドメインの下に存在する必要があります。 クローラーは、サブディレクトリ内のrobots.txtファイルをチェックしません。
- 各サブドメインには、独自のrobots.txtファイルが必要です。
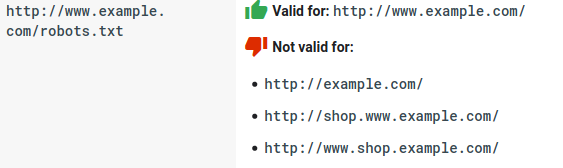
- Robots.txtでは大文字と小文字が区別されます。
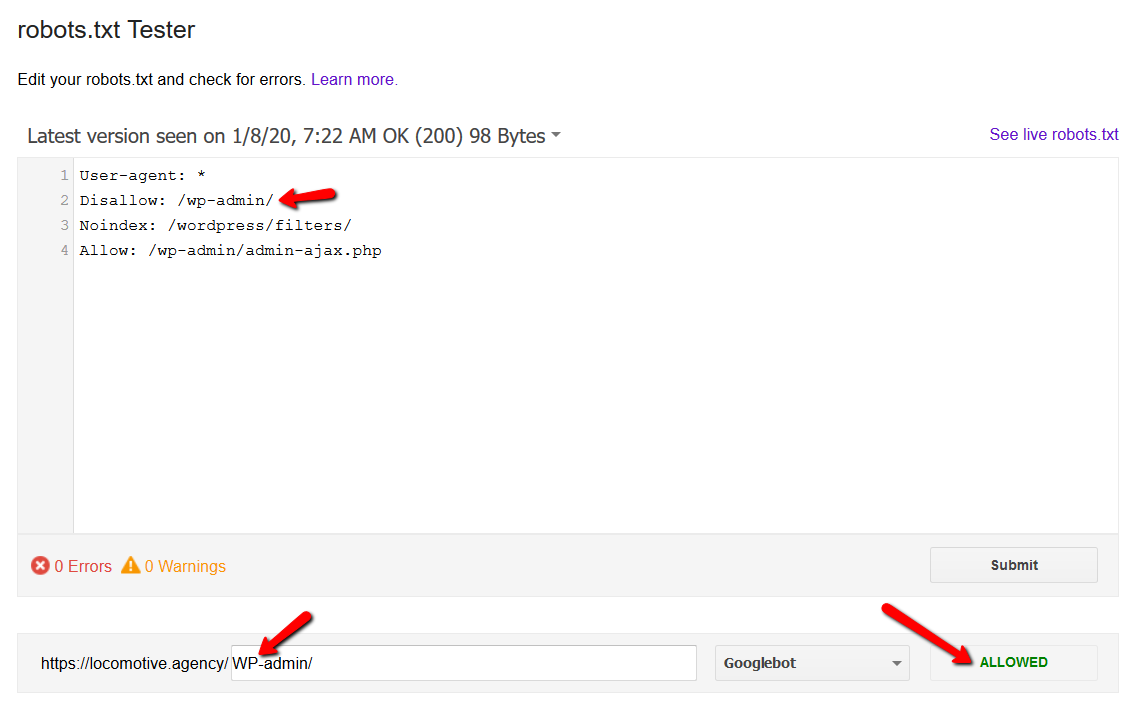
- noindexディレクティブ:robots.txtでnoindexを使用すると、disallowと同じように機能します。 Googleはページのクロールを停止しますが、インデックスには保持します。 @jroakesと私は、記事/ wordpress / filters /でNoindexディレクティブを使用して、Googleにページを送信するテストを作成しました。 以下のスクリーンショットで、URLがブロックされていることがわかります。
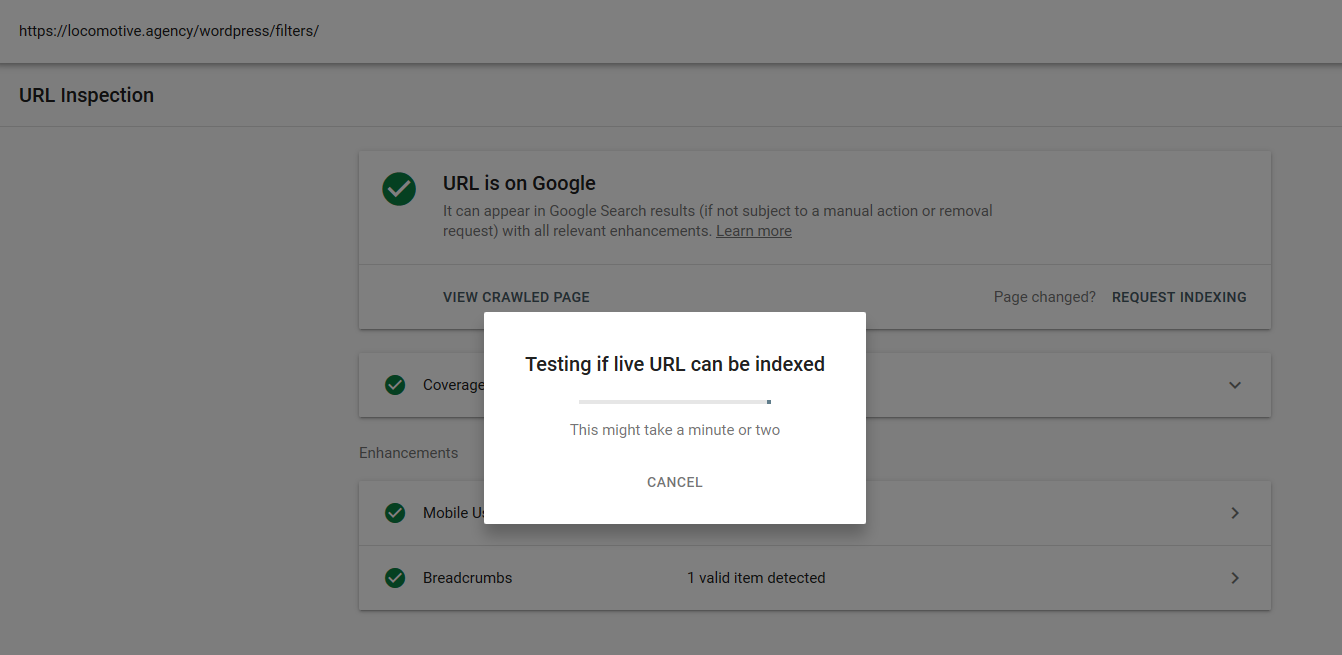
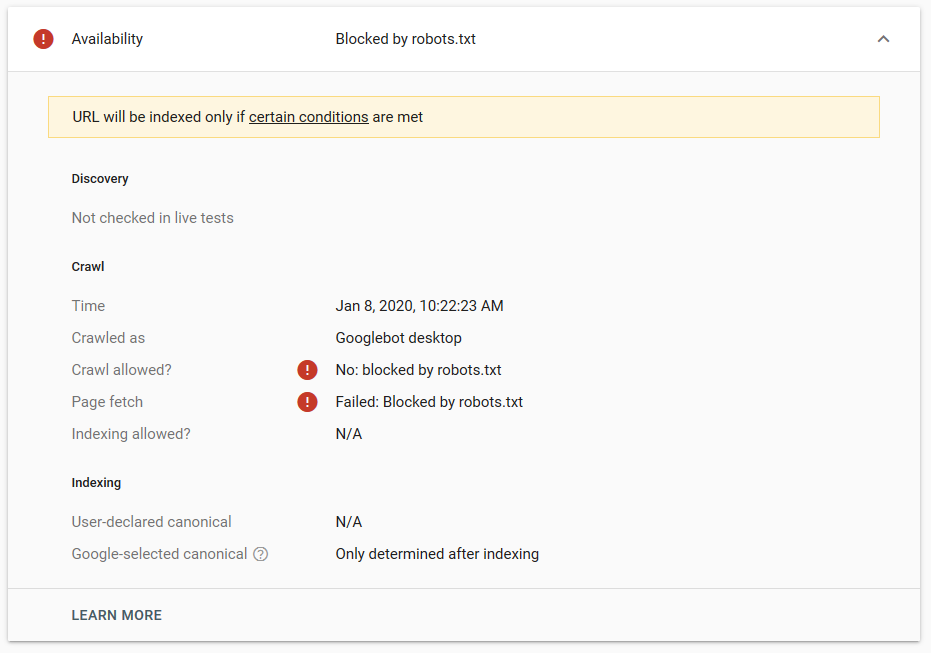
Googleでいくつかのテストを行いましたが、ページがインデックスから削除されることはありませんでした。

昨年、robots.txtで機能するnoindexディレクティブについて、Google以外のページを削除するという議論がありました。 これは、GaryIllyesがそれがなくなると述べたスレッドです。 このテストでは、noindexディレクティブが検索結果からページを削除しなかったため、Googleのソリューションが適切に機能していることがわかります。
最近、TwitterにChristian Oliveiraからの別の興味深いスレッドがあり、robots.txtで作業するときに考慮すべきいくつかの詳細を共有しました。
- 一般的なルールとGooglebot専用のルールが必要な場合は、User-agent:Googlebotのルールセットの下にあるすべての一般的なルールを複製する必要があります。 それらが含まれていない場合、Googlebotはすべてのルールを無視します。

- もう1つの紛らわしい動作は、(同じユーザーエージェントグループ内の)ルールの優先度が、ルールの順序ではなく、ルールの長さによって決定されることです。
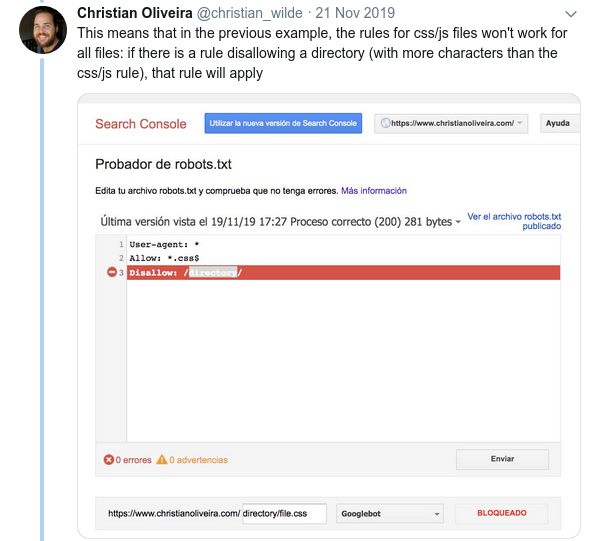
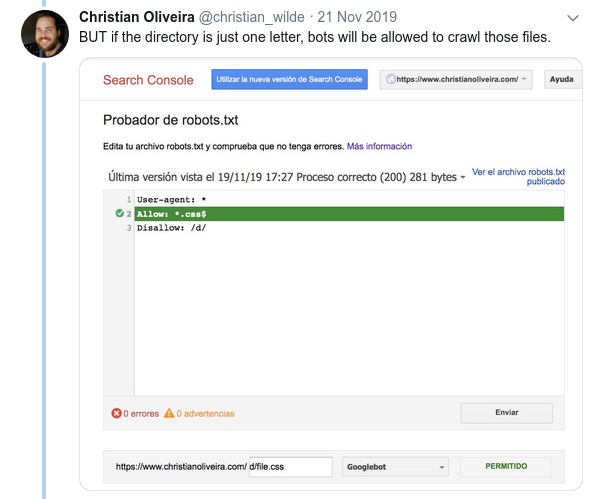
- これで、同じ長さと反対の動作(1つはクロールを許可し、もう1つはクロールを許可しない)の2つのルールがある場合、制限の少ないルールが適用されます。
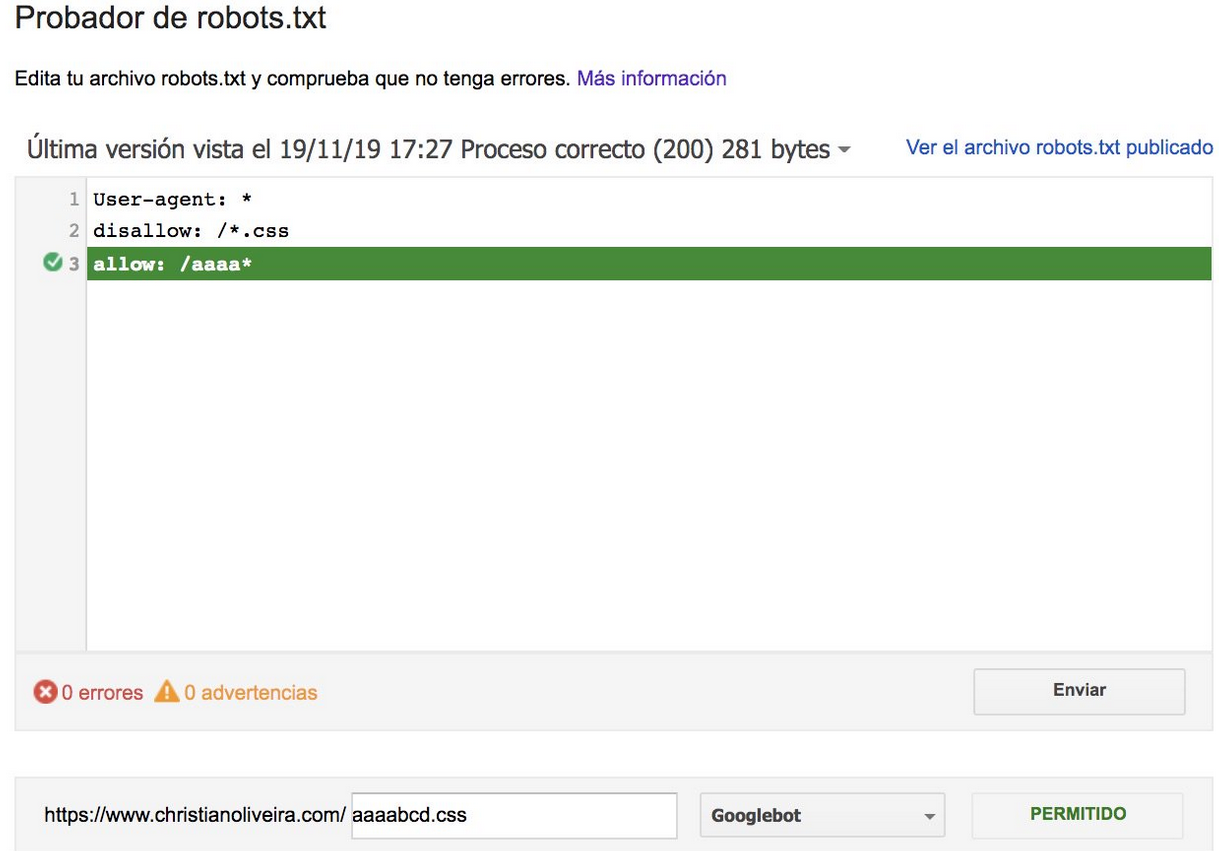
その他の例については、Googleが提供するrobots.txtの仕様をご覧ください。
Robots.txtをテストするためのツール
robots.txtファイルをテストする場合は、役立つツールがいくつかあります。また、独自のリポジトリを作成する場合は、いくつかのgithubリポジトリもあります。
- 蒸留
- Googleはrobots.txtテスターツールを古いGoogle検索コンソールからここに残しました
- Pythonの場合
- C++の場合
サンプル結果:eコマースのためのRobots.txtの効果的な使用
以下に、robots.txtファイルがないMagentoサイトで作業していたケースを示します。 Magentoやその他のCMSには、Googleにクロールさせたくないファイルを含む管理ページとディレクトリがあります。 以下に、robots.txtに含めたいくつかのディレクトリの例を示します。
##一般的なMagentoディレクトリ 禁止:/ app / 禁止:/ダウンローダー/ 禁止:/エラー/ 禁止:/含む/ 禁止:/ lib / 禁止:/ pkginfo / 禁止:/シェル/ 禁止:/ var / ##検索ページと最適化されていないリンクカテゴリにインデックスを付けないでください 禁止:/ catalog / product_compare / 禁止:/ catalog / category / view / 禁止:/ catalog / product / view / 禁止:/ catalog / product / gallery / 禁止:/ catalogsearch /
クロールすることを意図していない膨大な量のページがクロール予算に影響を及ぼしており、Googlebotはサイト上のすべての製品ページをクロールできませんでした。
下の画像で、robots.txtが実装された10月25日以降にインデックス付きページがどのように増加したかを確認できます。
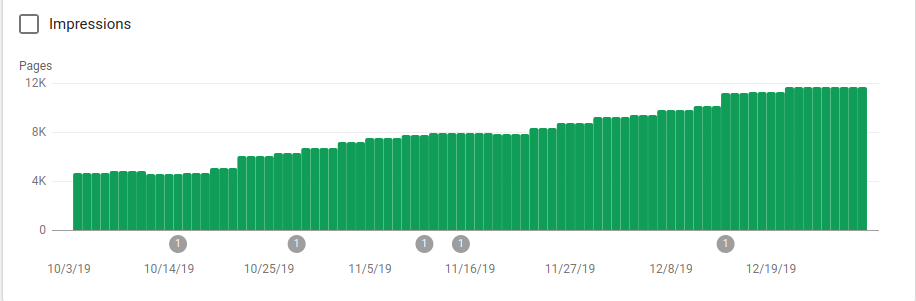
クロールされることを意図していないいくつかのディレクトリをブロックすることに加えて、ロボットにはサイトマップへのリンクが含まれていました。 以下のスクリーンショットでは、除外されたページと比較して、インデックスに登録されたページの数がどのように増加したかを確認できます。
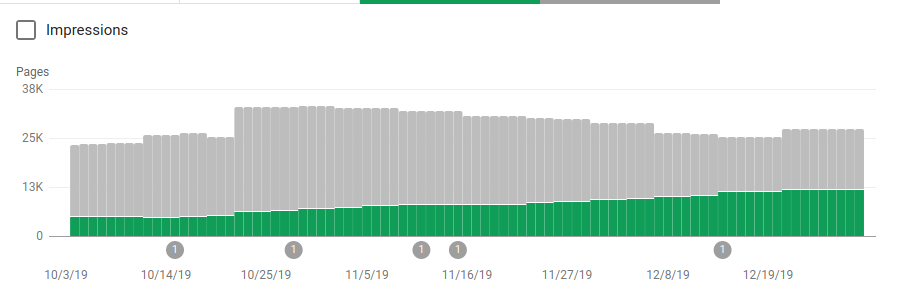
緑色のバーで示されているように、インデックス付けされた有効なページにはプラスの傾向があり、灰色のバーで示されている除外されたページにはマイナスの傾向があります。
まとめ
robots.txtの重要性が過小評価されることがあります。この投稿からわかるように、robots.txtを作成する際に考慮する必要のある詳細がたくさんあります。 しかし、作業は成果を上げています。robots.txtを正しく設定することで得られる肯定的な結果のいくつかを示しました。