
7 SEOは野生で見られない(そしてどのようにそれらを避けることができるか)
公開: 2022-06-12
なぜ自分のサイトがランキングされていないのか、なぜ検索エンジンによってインデックスに登録されていないのかと疑問に思う人からよく質問があります。
最近、所有者だけが見ることを知っていれば、簡単に修正できる大きなエラーのあるいくつかのサイトに出くわしました。 いくつかのSEOの間違いは非常に複雑ですが、ここでは見過ごされがちな「ヘッドスラミング」エラーのいくつかを紹介します。
だから、これらのSEOの失敗をチェックしてください—そしてあなたがそれらを自分で作るのを避ける方法。
SEOの失敗#1:Robots.txtの問題
robots.txtファイルには大きな力があります。 これは、検索エンジンボットにインデックスから何を除外するかを指示します。
これまで、サイトを再設計した後、サイトがそのファイルから1行のコードを削除するのを忘れ、サイト全体を検索結果に表示するのを見てきました。
そのため、花のサイトで問題が浮き彫りになったとき、私はサイトで常に行う最初のチェックの1つから始めました。robots.txtファイルを見てください。
サイトのrobots.txtが検索エンジンによるコンテンツのインデックス作成をブロックしているかどうかを知りたいと思いました。 しかし、予想されるテキストファイルの代わりに、Robots.Txtに花を配信することを提案しているページを見ました。
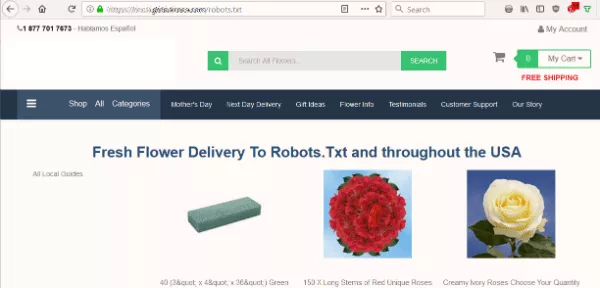
サイトにはrobots.txtがありませんでした。これは、ボットがサイトをクロールするときに最初に検索するものです。 それが彼らの最初の間違いでした。 しかし、そのファイルを宛先として使用するには…本当に?
SEOの失敗#2:自動生成がワイルドになりました
第二に、サイトは意味のないコンテンツを自動的に生成していました。 それはおそらくサンタクロースか私がURLに入れたどんなテキストにも届けるでしょう。
サーバーページのチェックツールを実行して、自動生成されたページに表示されているステータスを確認しました。 404(見つからない)の場合、ボットはページを無視します。 ただし、ページのサーバーヘッダーは200(OK)ステータスを示しました。 その結果、偽のページは検索エンジンにインデックスを付けるための青信号を与えていました。
検索エンジンは、ページごとにユニークで意味のあるコンテンツを見たいと思っています。 したがって、これらの非ページのインデックスを作成すると、SEOに悪影響を与える可能性があります。
SEO失敗#3:正規エラー
次に、検索エンジンがこのサイトをどう思っているかを確認しました。 彼らはページをクロールしてインデックスを作成できますか?
さまざまなページのソースコードを見ると、別の大きなエラーに気づきました。
すべてのページには、ホームページを指す正規リンク要素がありました。
<link rel =” canonical” href =” https://www.domain.com/” />
言い換えれば、検索エンジンは、すべてのページが実際にはホームページのコピーであると言われていました。 このタグに基づいて、ボットはそのドメインの残りのページを無視する必要があります。
幸いなことに、Googleは、これらのタグが誤って使用される可能性が高い時期を把握するのに十分賢いです。 そのため、サイトの一部のページのインデックスを作成していました。 しかし、その普遍的な標準的な要求は、サイトのSEOを助けていませんでした。
これらのSEOの失敗を回避する方法
花のサイトの複数の間違いについては、ここに修正があります:
- 有効なrobots.txtファイルを用意して、サイトをクロールしてインデックスを作成する方法を検索エンジンに指示します。 空白のファイルであっても、ドメインのルートに存在する必要があります。
- 各ページに適切な正規リンク要素を生成します。 また、インデックスを作成するページから離れないようにしてください。
- ページURLが存在しない場合に、カスタム404ページを表示します。 検索エンジンに明確なメッセージを与えるために、404サーバーコードが返されることを確認してください。
- 自動生成されたページには注意してください。 検索エンジンとユーザーのためにナンセンスまたは重複したページを作成することは避けてください。
サイトの問題が発生していない場合でも、安全のために、これらは定期的に確認することをお勧めします。
ああ、そしてあなたの404ページに正規のタグを決して付けないでください、特にあなたのホームページを指してはいけません…ただそうしないでください。
SEOの失敗#4:一晩のランキングフリーフォール
単純な変更は、コストのかかる間違いになる場合があります。 この話は、SEOクライアントの1人との経験から来ています。
ドメイン名の.org拡張子が利用可能になると、彼らはそれをすくい上げました。 ここまでは順調ですね。 しかし、彼らの次の動きは災害につながりました。
彼らはすぐに、新しく取得した.orgをメインの.comWebサイトに向ける301リダイレクトを設定しました。 彼らの推論は理にかなっています—間違った拡張子を入力するかもしれないわがままな訪問者を捕らえるために。
しかし翌日、彼らは私たちを必死に呼んだ。 彼らのサイトトラフィックは存在しませんでした。 彼らはその理由を知りませんでした。
いくつかの簡単なチェックは、彼らの検索ランキングが一晩でグーグルから消えたことを明らかにしました。 何が起こったのかを理解するのにそれほど多くのQ&Aは必要ありませんでした。

彼らはリスクを考慮せずにリダイレクトを実施しました。 掘り下げてみたところ、.orgにはひどい過去があったことがわかりました。
.orgサイトの前の所有者は、それをスパムに使用していました。 リダイレクトにより、Googleはそのすべての毒を会社のメインサイトに割り当てていました! Googleでのサイトの地位を回復するのにたった2日しかかかりませんでした。
このSEOの失敗を回避する方法
登録したドメイン名のリンクプロファイルと履歴を常に調べてください。
資格のあるSEOコンサルタントがこれを行うことができます。 サイトのクローゼットにどのスケルトンが横たわっているのかを確認するために実行できるツールもあります。
新しいドメインを取得するときはいつでも、少なくとも6か月から1年は休止させてから、何かを作成しようとします。 私は検索エンジンが私のサイトの新しい化身をその過去の生活から明確に区別することを望んでいます。 それはあなたの投資を保護するための特別な予防策です。
SEOの失敗#5:消えないページ
サイトで別の問題が発生する場合があります。検索インデックスのページが多すぎます。
検索エンジンは、無効になったページを保持することがあります。 ユーザーが検索結果からエラーページにアクセスした場合、それはユーザーエクスペリエンスに悪影響を及ぼします。
一部のサイト所有者は、不満から、robots.txtファイルに個々のURLをリストしています。 彼らはグーグルがヒントを取り、それらの索引付けをやめることを望んでいる。
しかし、このアプローチは失敗します! Googleがrobots.txtを尊重している場合、それらのページはクロールされません。 したがって、Googleは404ステータスを確認することはなく、ページが無効であることを確認することもありません。
このSEOの間違いを回避する方法
修正の最初の部分は、robots.txtでこれらのURLを禁止しないことです。 ボットがクロールして、検索インデックスから削除するURLを把握する必要があります。
その後、古いURLに301リダイレクトを設定します。 訪問者(および検索エンジン)をサイトの最も近い代替ページに送ります。 これにより、訪問者が検索から来た場合でも、直接リンクから来た場合でも、訪問者の面倒を見ることができます。
SEOの失敗#6:リンクの公平性の欠如
大学のウェブサイトからのリンクをたどると、404(見つかりません)エラーが表示されました。
これは、リンクが/home.html(サイトの以前のホームページのURL)へのリンクであったことを除いて、珍しいことではありません。
ある時点で、Webサイトのアーキテクチャを変更し、古いスタイルの/home.htmlを削除して、シャッフルでリダイレクトを失ったに違いありません。
皮肉なことに、彼らの404ページには、ホームページからやり直すことができると書かれています。これは、私が最初に到達しようとしていたことです。
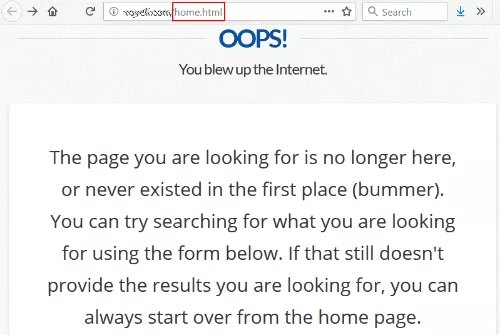
このサイトが尊敬されている大学から彼らのホームページに行く素敵なリンクを持っていることを望んでいることはかなり安全な賭けです。 そして、これを達成することは完全に彼らのコントロールの範囲内です。 リンク先のサイトに連絡する必要もありません。
この失敗を修正する方法
このリンクを修正するには、/home.htmlを指す301リダイレクトを現在のホームページに配置する必要があります。 (手順については、301リダイレクトの設定方法に関する記事を参照してください。)
追加のクレジットについては、Google検索コンソールにアクセスしてインデックスカバレッジステータスレポートを確認してください。 404エラーを返すと報告されているすべてのページを確認し、ここでできるだけ多くのエラーを修正してください。
SEOの失敗#7:コピー/貼り付けの失敗
サイトの再設計が開始され、正規のタグが配置され、新しいGoogleタグマネージャーがインストールされます。 それでも、ランキングの問題はまだあります。 実際、1つの新しいランディングページには、GoogleAnalyticsの訪問者が表示されていません。
開発チームは、本ですべてを行い、手紙の例に従ったと答えます。
彼らは正確に正しいです。 彼らは例に従いました—サンプルコードを残すことを含みます! コピーアンドペーストした後、開発者は自分のターゲットサイト情報を入力するのを忘れました。
アナリストがウェブサイトのコードで遭遇した3つの例を次に示します。
- <link rel =” canonical” href =” http://example.com/”>
- 'analyticsAccountNumber':'UA-123456-1'
- _gaq.push(['_ setAccount'、'UA-000000-1']);
このSEOの失敗を回避する方法
うまくいかない場合は、「この要素はソースコードに含まれていますか?」だけではありません。 適切な検証コード、アカウント番号、およびURLがHTMLコードで指定されていない可能性があります。
間違いが起こり、人は人間だけです。 これらの例があなた自身の同様のSEOの失敗を避けるのに役立つことを願っています。 お客様の利益のために、SEOのヒントとベストプラクティスを概説した詳細なSEOガイドを作成しました。
しかし、いくつかのSEOの問題は、あなたが思っているよりも複雑です。 インデックス作成に問題がある場合は、私たちがお手伝いします。 お電話またはリクエストフォームにご記入ください。ご連絡いたします。
この投稿が好きですか? 新しい投稿が受信トレイに配信されるようにするには、ブログを購読してください。