
ウェブサイト全体のヒースのための迅速で汚い11ステップの技術的なSEO監査
公開: 2020-02-27技術的なSEOは、あらゆるプロジェクトの出発点であるため重要です。 SEOの専門家の観点からは、すべてのWebサイトは新しいプロジェクトです。 良い結果を得て、ランキングのようなSEOで最も重要なKPIに到達するために、Webサイトは強固な基盤を持っている必要があります。
私が新しいプロジェクトを始めるたびに、私が最初にすることは技術的なSEO監査です。 ほとんどの場合、技術的な問題を修正すると、Webサイトが再クロールされるとすぐに驚くべき結果が得られます。
人々がコンテンツやより多くのコンテンツについて話すのは私にとって面白いですが、彼らは技術的なSEOについて一言も言いません。 1つ確かなことは、ウェブサイトの健全性とテクニカルSEOは、2020年に重要になる2つの重要なことです。コンテンツが重要ではないと言っているわけではありません。 そうですが、ウェブサイトの技術的な問題を修正しなければ、コンテンツが結果をもたらすことはないと思います。
重要なページがrobots.txtファイルのディレクティブによってブロックされている場合や、最も重要なカテゴリまたはサービスのページがnoindex、nofollowなどのメタロボットによってブロックされている場合があります。 これらの問題を修正することで、優先順位を付けずに成功するにはどうすればよいでしょうか。
修正するWeb開発スペシャリストに報告する技術的な問題を特定する方法を知らないSEOの数を見ると驚くかもしれません。 私は、企業の分野で働いていたときに、チームが使用するTechSEO監査チェックリストシートを作成したことを思い出しました。 その時、このようなクイックフィックスシートを手元に用意しておくと、チームを大いに助け、クライアントに迅速な後押しをもたらすことができることに気づきました。 だからこそ、技術的なSEOの診断と推奨に役立つツール/ソフトウェアに投資することが最も重要だと私は考えています。
大きな違いを生むクイックテックSEO監査を実施する方法の実践的なプロセスを始めましょう。 これは、プロでなくても約1時間かかる簡単な演習です。 私にとって、OnCrawlのようなTech SEOツールを使用して、すべての手動作業を行うことなく5分ですべてを早送りすると、私の生活が楽になります。
テクニカルSEO監査を実施する際に確認すべき最も重要なことを確認します。 ページ上の問題をチェックできることは他にもありますが、インデックス作成の問題と予算の浪費を引き起こすものだけに焦点を当てたいと思います。 これに優先順位を付けることは、最も重要なページがGooglebotによってクロールされることを確認する方法です。
- 索引付け
- Robots.txtファイル
- メタロボットタグ
- 4xxエラー
- サイトマップ
- HTTP / HTTPS(Webサイトのセキュリティ、混合コンテンツ、重複コンテンツの問題)
- ページ付け
- 404ページ
- サイトの深さと構造
- 長いリダイレクトチェーン
- 正規タグの実装
1)索引付け
これが最初にチェックすることです。 多くの場合、インデックス作成はプラグインの構成や小さな間違いの影響を受ける可能性がありますが、今日では61.6億を超えるウェブページがインデックスに登録されているため、ファインダビリティへの影響は甚大です。 どの検索エンジンも努力していることを理解する必要があり、Googleでさえユーザーエクスペリエンスに最も関連性の高いページを優先する必要があります。 Googlebotの機能を簡単にすることを検討していない場合、競合他社はそれを実行し、健全なWebサイトに伴う信頼を大幅に高めます。
インデックス作成の問題がある場合、Webサイトのヘルスの問題はオーガニックトラフィックの損失に反映されます。 インデックス作成のプロセスは、検索エンジンがWebページをクロールし、後でSERPで提供する情報を整理することを意味します。 結果は、ユーザーの意図との関連性によって異なります。 Webページがクロールできない、またはクロールに問題がある場合、これは同じニッチの他のページに有利に働きます。
たとえば、検索演算子を使用します。
サイト:www.abc.com
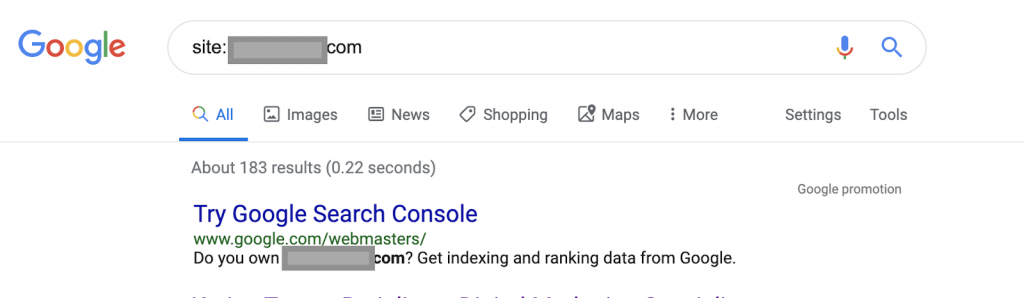
クエリは、Googleによってインデックス付けされた183ページを返します。 これは、Googleがインデックスに登録したページ数の概算です。 正確な数については、Google検索コンソールを確認できます。
また、OnCrawlなどのWebクローラーを使用して、Googleがアクセスできるすべてのページを一覧表示する必要があります。 以下に示すように、これは異なる番号を示しています。
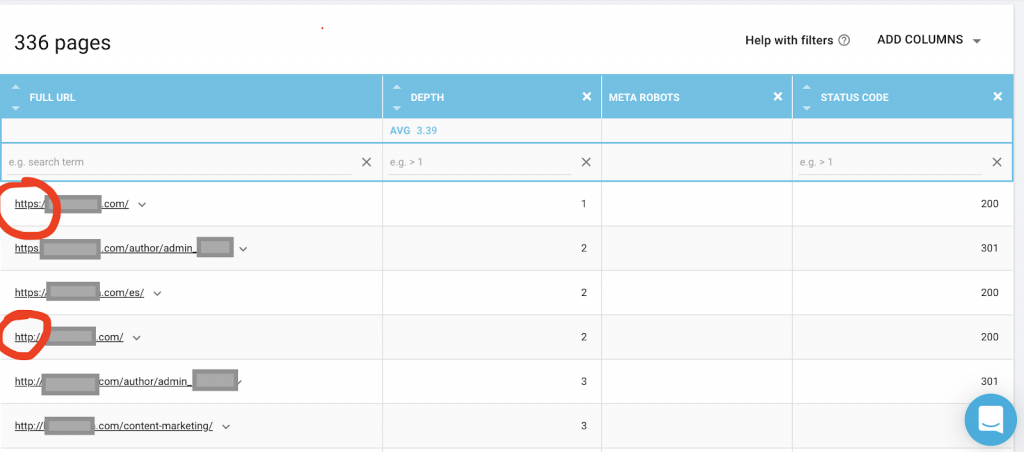
このWebサイトには、インデックスが作成されたページのほぼ2倍のクロール可能なページがあります。
これにより、コンテンツの重複の問題、またはHTTPとHTTPSの問題の間のWebサイトのセキュリティバージョンの問題が明らかになる可能性があります。 これについては、この記事の後半で説明します。
この場合、WebサイトはHTTPからHTTPSに移行されました。 OnCrawlで、HTTPページがリダイレクトされていることがわかります。 HTTPバージョンとHTTPSバージョンの両方に引き続きGooglebotがアクセスでき、所有者がランク付けしたい最も重要なページに優先順位を付ける代わりに、重複するすべてのページをクロールして、クロール予算を浪費する可能性があります。
無視されたウェブサイトやeコマースサイトのような大規模なウェブサイトに共通するもう1つの問題は、混合コンテンツの問題です。 簡単に言うと、セキュリティで保護されたページに、セキュリティで保護されていないバージョンからロードされたメディアファイル(ほとんどの場合:画像)などのリソースがある場合に問題が発生します。
それを修正する方法:
Web開発者に、すべてのHTTPページをHTTPSバージョンに強制し、301ステータスコードを使用してHTTPアドレスをHTTPSにリダイレクトするように依頼できます。
混合コンテンツの問題については、ページのソースを手動で確認し、「src = http://example.com/media/images」としてロードされたリソースを検索できます。これは、特に大規模なWebサイトではほとんど問題ありません。 そのため、技術的なSEOツールを使用する必要があります。
2)Robots.txtファイル:
robots.txtファイルは、クロールエージェントにクロールしてはならないページを指示します。 Robots.txt仕様ガイドによると、ファイル形式は最大500KBのプレーンテキストである必要があります。
サイトマップをrobots.txt.fileに追加することをお勧めします。 誰もがこれを行うわけではありませんが、それは良い習慣だと思います。 robots.txtファイルは、ホストされているサーバーのpublic_htmlに配置する必要があり、ルートドメインの後にあります。
robots.txtファイルのディレクティブを使用して、検索エンジンが不要なページや、管理ページ、テンプレート、ショッピングカート(/ cart、/ checkout、/ login、ブログで使用される/ tagなどのフォルダー)などの機密情報を含むページをクロールしないようにすることができます。 、robots.txtファイルにこれらのページを追加します。
アドバイス:メディアファイルフォルダをブロックしないように注意してください。ブロックすると、画像、ビデオ、またはその他のセルフホストメディアがインデックスに登録されなくなります。 メディアは、ページの関連性だけでなく、画像や動画のオーガニックランキングやトラフィックにとっても非常に重要です。
3)メタロボットタグ
これは、ページ内のすべてのリンクを使用して、ページをクロールしてインデックスを作成するかどうかを検索エンジンに指示するHTMLコードです。 HTMLタグは、Webページの先頭に配置されます。 ロボットには4つの一般的なHTMLタグがあります。
- フォローしない
- 従う
- 索引
- インデックスなし
メタロボットタグが存在しない場合、検索エンジンはデフォルトでコンテンツを追跡してインデックスを作成します。
ニーズに最適な組み合わせを使用できます。 たとえば、OnCrawlを使用すると、このWebサイトの「作成者ページ」にメタロボットがないことがわかりました。 これは、デフォルトで方向が(“ follow、index”)であることを意味します
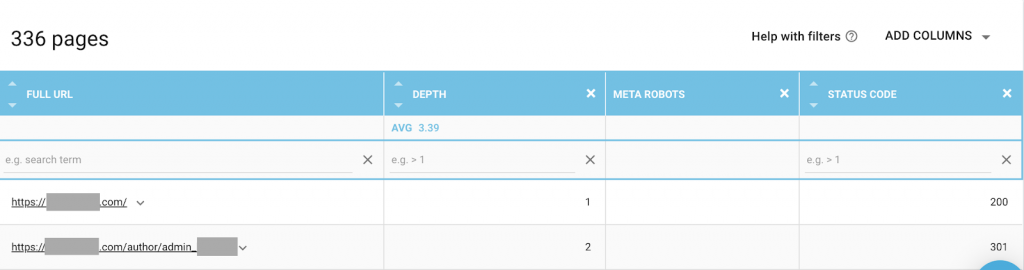
これは(「noindex、nofollow」)である必要があります。
なんで?
それぞれのケースは異なりますが、このウェブサイトは小さな個人的なブログです。 ブログに公開している作成者は1人だけで、ドメインは作成者の名前です。 この場合、「作成者」ページは、ブログプラットフォームによって生成されたものであっても、追加情報を提供しません。
別のシナリオは、ブログのカテゴリが重要なWebサイトである可能性があります。 所有者が自分のブログでカテゴリをランク付けする場合、メタロボットはカテゴリページで(「フォロー、インデックス」)またはデフォルトにする必要があります。
別のシナリオでは、主要なSEO専門家がコミュニティに続く記事を書く、大きくて有名なWebサイトの場合、Googleの著者名がブランドとして機能します。 この場合、おそらくいくつかの著者名に索引を付けたいと思うでしょう。
ご覧のとおり、メタロボットはさまざまな方法で使用できます。
それを修正する方法:
必要に応じてメタロボットタグを変更するようにWeb開発者に依頼してください。 上記の小さなWebサイトの場合、各ページに移動して手動で変更することで、自分で行うことができます。 WordPressを使用している場合は、RankMathまたはYoastの設定からこれを変更できます。
4)4xxエラー:
これらはクライアント側のエラーであり、401、403、および404の可能性があります。
- 404ページが見つかりません:
このエラーは、インデックスに登録されたURLアドレスでページが利用できない場合に発生します。 移動または削除された可能性があり、古いアドレスはWebサーバー機能301を使用して適切にリダイレクトされていません。404エラーはユーザーにとって悪い経験であり、対処する必要のある技術的なSEOの問題を表しています。 404を頻繁にチェックして修正し、予算を浪費しているクロールエージェントのために何度も試行されることのないようにすることは良いことです。
それを修正する方法:
コンテンツがまだ存在する場合は、404を返すアドレスを見つけて、301リダイレクトを使用して修正する必要があります。 または、画像の場合は、同じファイル名を保持する新しい画像に置き換えることができます。
- 401無許可
これは許可の問題です。 401エラーは通常、ユーザー名やパスワードなどの認証が必要な場合に発生します。
それを修正する方法:
2つのオプションがあります:1つ目はrobots.txtを使用して検索エンジンからページをブロックすることです。2つ目は認証要件を削除することです。
- 403禁止します
このエラーは401エラーに似ています。 403エラーは、ページに一般公開されていないリンクが含まれているために発生します。
それを修正する方法:
サーバーの要件を変更して、ページへのアクセスを許可します(これが間違いである場合のみ)。 このページにアクセスできないようにする必要がある場合は、ページからすべての内部リンクと外部リンクを削除してください。
- 400不正な要求
これは、ブラウザがWebサーバーと通信できない場合に発生します。 このエラーは通常、URL構文が正しくない場合に発生します。
それを修正する方法:
これらのURLへのリンクを見つけて、構文を修正してください。 これが修正できない場合は、Web開発者に連絡して修正する必要があります。
注:ツールまたはGoogleコンソールで400個のエラーを見つけることができます


5)サイトマップ
サイトマップは、Webサイトに含まれるすべてのURLのリストです。 サイトマップがあると、クローラーがコンテンツを見つけて理解するのに役立つため、検索のしやすさが向上します。
さまざまな種類のサイトマップがあり、それらすべてが良好な状態にあることを確認する必要があります。
必要なサイトマップは次のとおりです。
- HTMLサイトマップ:これはあなたのウェブサイトにあり、ユーザーがあなたのウェブサイト上のページをナビゲートして見つけるのに役立ちます
- XMLサイトマップ:これは、検索エンジンがWebサイトをクロールするのに役立つファイルです(ベストプラクティスとして、robots.txtファイルに含める必要があります)。
- ビデオXMLサイトマップ:上記と同じ。
- 画像XMLサイトマップ:これも上記と同じです。 画像、動画、コンテンツ用に個別のサイトマップを作成することをお勧めします。
大規模なWebサイトの場合、サイトマップに50.000を超えるURLを含めることはできないため、クロール性を高めるために複数のサイトマップを用意することをお勧めします。
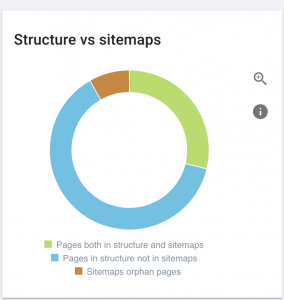
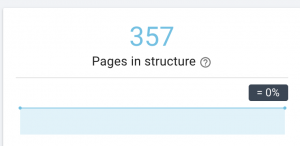
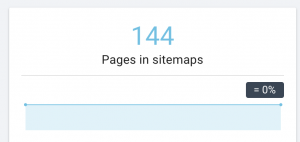
このWebサイトにはサイトマップの問題があります。
修正方法:
コンテンツ、画像、動画のさまざまなサイトマップを生成することで、これを修正します。 次に、Google検索コンソールを介してそれらを送信し、WebサイトのHTMLサイトマップも作成します。 このためにWeb開発者は必要ありません。 無料のオンラインツールを使用してサイトマップを生成できます。
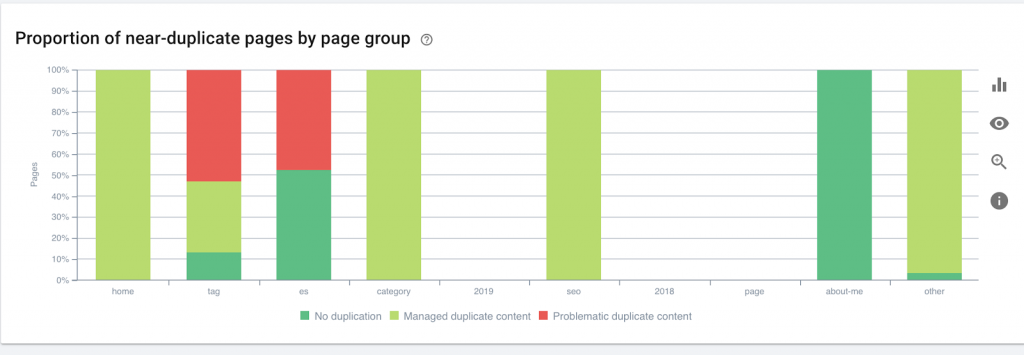
6)HTTP / HTTPS(重複コンテンツ)
HTTPからHTTPSへの移行の結果として、多くのWebサイトでこれらの問題が発生します。 この場合、Webサイトには検索エンジンにHTTPバージョンとHTTPSバージョンが表示されます。 この一般的な技術的問題の結果として、ランキングは希薄になります。 これらの問題は、重複コンテンツの問題も生成します。
![]()

それを修正する方法:
すべてのHTTPをHTTPSに強制することにより、この問題を修正するようにWeb開発者に依頼してください。
注:ソフト404エラーが生成されるため、すべてのHTTPをHTTPSホームページにリダイレクトしないでください。 (これはWeb開発者に伝える必要があります。SEOではないことを忘れないでください。)
7)ページ付け
これは、ページ間の関係を確立するHTMLタグ(「rel=prev」および「rel=next」)の使用であり、異なるページに表示されるコンテンツを識別または単一のページに関連付ける必要があることを検索エンジンに示します。 ページ付けは、UXのコンテンツと技術的な部分のページの重みを制限し、3MB未満に保つために使用されます。 無料のツールを使用してページネーションを確認できます。
ページネーションには自己標準的な参照があり、「rel=prev」と「rel=next」を示す必要があります。 重複する情報はメタタイトルとメタディスクリプションのみですが、開発者はこれを変更して小さなアルゴリズムを作成し、すべてのページにメタタイトルとメタディスクリプションが生成されるようにすることができます。
それを修正する方法:
Web開発者に、自己正規タグを使用してページ付けHTMLタグを実装するように依頼します。
オンクロールSEOクローラー
 Decouvrir
Decouvrir8)カスタム404が見つかりませんページ
404応答は、前に説明したように、ユーザーにリンク切れまたは存在しないページを表示する「見つかりません」エラーです。 これは、ユーザーを適切な場所にリダイレクトする機会です。 カスタム404ページの優れた例があります。 これは必需品です。
優れた404カスタムページの例を次に示します。

それを修正する方法:
カスタム404ページを作成します。それに追加する素晴らしいものについて考えてください。 このエラーをあなたのビジネスのチャンスにしてください。
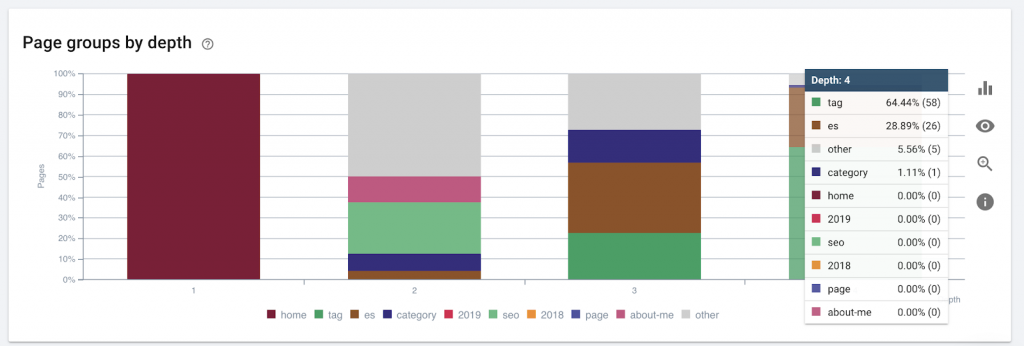
9)サイトの深さ/構造
ページ深度は、ルートドメインからページが検索されたクリック数です。 GoogleのJohnMuellerは、「ホームページに近いページほど重みが大きい」と述べています。 たとえば、ここのページにアクセスするには、次のナビゲーションが必要であると想像してください。

ページ「ラグ」はホームページから4クリック離れています。 検索エンジンはより深いページをクロールするのが難しいため、ホームから4クリック以上離れた場所にページを配置しないことをお勧めします。
この図は、ページグループを深度別に示しています。 Webサイトの構造を作り直す必要があるかどうかを理解するのに役立ちます。
それを修正する方法:
最も重要なページは、ユーザーが簡単にアクセスできるように、またWebサイトの構造を改善するために、UXのホームページに最も近いものにする必要があります。 ウェブサイトの構造を作成したり、ウェブサイトを再構築したりする際には、これを考慮することが非常に重要です。
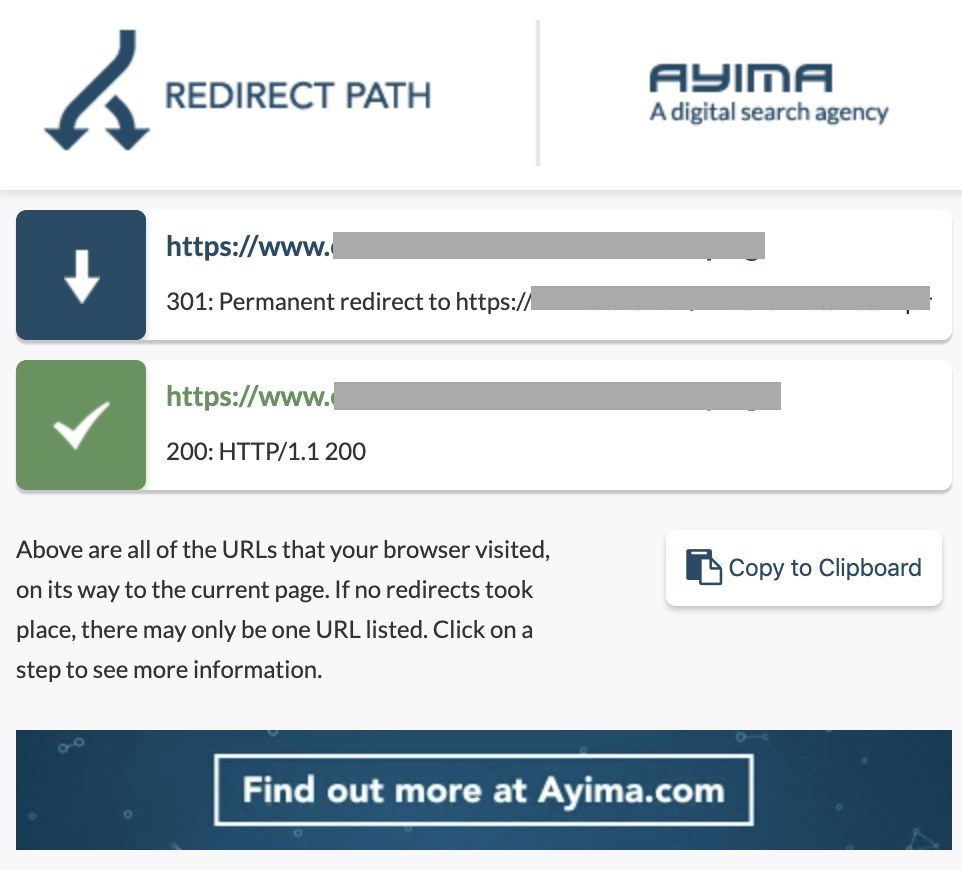
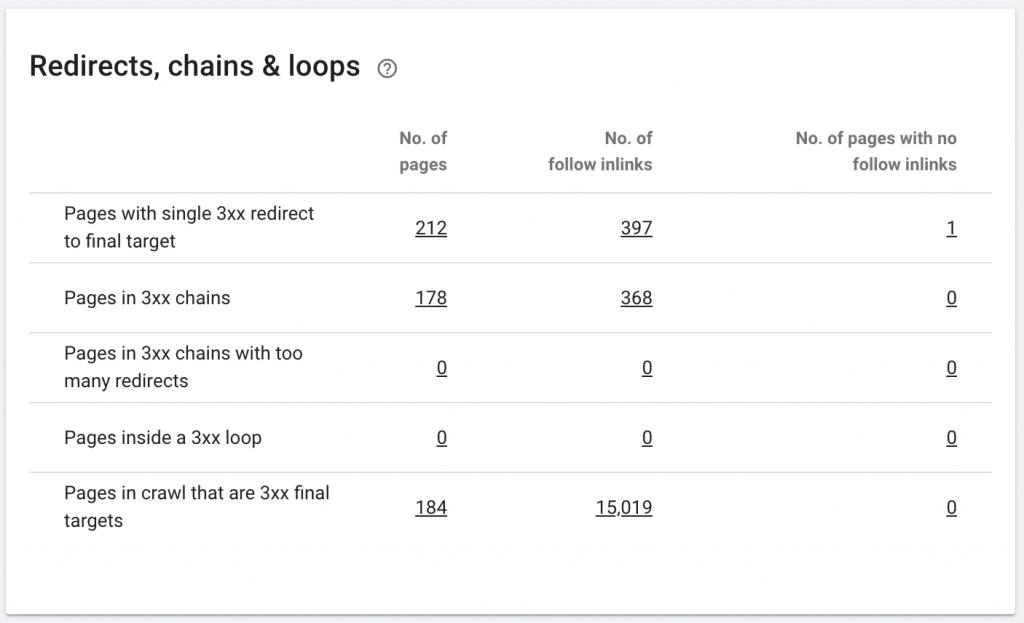
10.チェーンのリダイレクト
リダイレクトチェーンは、一連のリダイレクトがURL間で発生する場合です。 これらのリダイレクトのチェーンもループを作成する可能性があります。 また、Googlebotに問題を引き起こし、クロール予算を浪費します。
Chrome拡張機能のリダイレクトパスを使用するか、OnCrawlを使用して、リダイレクトのチェーンを識別できます。
それを修正する方法:
WordPress Webサイトで作業している場合、これを修正するのは本当に簡単です。 リダイレクトに移動してチェーンを探します。これらの変更が2〜3か月以上前に発生した場合は、チェーンに含まれるすべてのリンクを削除し、最後のリダイレクトを現在のURLに残します。 Web開発者は、必要に応じて.htaccesファイルに必要なすべての変更を加えることでこれを支援することもできます。 SEOプラグインで長いリダイレクトチェーンを確認および変更できます。
11)カノニカル
正規タグは、URLが別のページのコピーであることを検索エンジンに通知します。 これは多くのウェブサイトに存在する大きな問題です。 カノニカルを正しい方法で実装しない、またはまったく実装しないと、重複コンテンツの問題が発生します。
カノニカルは、サイズ、色などのさまざまなカテゴリで製品が複数回見つかるeコマースWebサイトで一般的に使用されます。

OnCrawlを使用して、ページに正規のタグがあるかどうか、およびそれらが正しく実装されているかどうかを確認できます。 その後、問題を調査して修正できます。
修正方法:
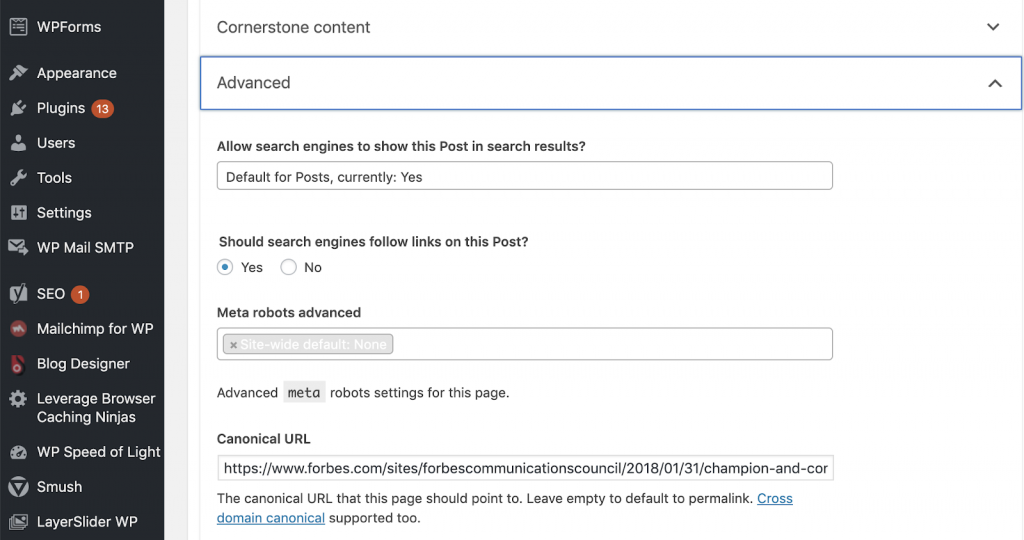
WordPressで作業している場合は、YoastSEOを使用して正規の問題を修正できます。 WordPressダッシュボードに移動し、次にYoast設定–詳細に移動します。
独自の監査の実行
技術的なSEOに飛び込み始めたいSEOは、SEOの健康を改善するために従うべきクイックステップのガイドを必要とします。 2019年10月にニューヨークで開催されたグローバルマーケティングデーで、コンデナストのオーディエンスグローのバイスプレジデントであり、NewzDashの創設者であるジョンシェハタとテクニカルSEOについて話します。
これが彼が私に言ったことです:
「SEO業界の多くの人々は技術的ではありません。 現在、すべてのSEOがコーディング方法を理解しているわけではなく、人々にこれを行うように依頼することは困難です。 一部の企業は、開発者を雇い、技術的なSEOギャップを埋めるためにSEOになるようにトレーニングしています。」
私の意見では、完全なコード知識を持たないSEOは、監査の実行方法を知り、重要な要素を特定し、レポートを作成し、Web開発者に実装を依頼し、最後に変更をテストすることで、TechSEOで優れた成果を上げることができます。
始める準備はできましたか? これらの主要な問題のチェックリストをダウンロードしてください。
