
CausalImpact予測の品質の評価
公開: 2022-02-15CausalImpactは、SEO実験で使用される最も人気のあるパッケージの1つです。 その人気は理解できます。
SEOの実験は、SEOが自分の仕事の価値について報告するための刺激的な洞察と方法を提供します。
ただし、機械学習モデルの精度は、提供される入力情報に依存します。
簡単に言えば、間違った入力は間違った推定を返す可能性があります。
この投稿では、CausalImpactがどれほど信頼できる(そして信頼できない)かを示します。 また、実験結果に自信を持つ方法についても学びます。
まず、CausalImpactがどのように機能するかについて簡単に説明します。 次に、CausalImpact推定の信頼性について説明します。 最後に、独自のSEO実験結果を推定するために使用できる方法論について学習します。
CausalImpactとは何ですか?それはどのように機能しますか?
CausalImpactは、ベイズ統計を使用して、実験がない場合のイベントの影響を推定するパッケージです。 この推定は因果推論と呼ばれます。
因果推論は、観察された変化が特定のイベントによって引き起こされたかどうかを推定します。
これは、SEO実験のパフォーマンスを評価するためによく使用されます。
たとえば、イベントの日付が指定された場合、CausalImpact(CI)は、介入前のデータポイントを使用して、介入後のデータポイントを予測します。 次に、予測を観測データと比較し、特定の信頼しきい値で差を推定します。
さらに、コントロールグループを使用して、予測をより正確にすることができます。
さまざまなパラメータも予測の精度に影響を与えます。
- テストデータのサイズ。
- 実験前の期間の長さ。
- 比較する対照群の選択。
- 季節性ハイパーパラメータ。
- 反復回数。
これらのパラメーターはすべて、モデルにより多くのコンテキストを提供し、モデルの信頼性を高めるのに役立ちます。
オンクロールBI
 発見する
発見するSEO実験の精度を評価することが重要なのはなぜですか?
過去数年間、私は多くのSEO実験を分析してきましたが、何かが印象的でした。
多くの場合、同一のテストセットと介入日に異なる対照群と時間枠を使用すると、異なる結果が得られました。
説明のために、以下は同じイベントからの2つの結果です。
最初のものは統計的に有意な減少を返しました。 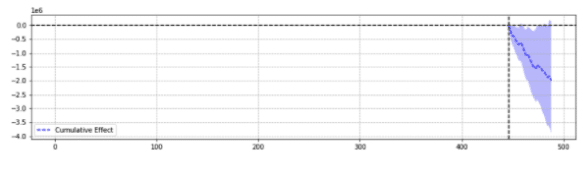
2番目は統計的に有意ではありませんでした。 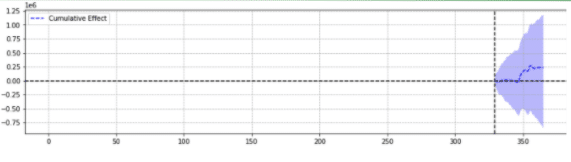
簡単に言えば、同じイベントに対して、選択したパラメーターに基づいて異なる結果が返されました。
どの予測が正確か疑問に思う必要があります。
結局、「統計的に有意」は、私たちの推定の信頼性を高めることになっているのではないでしょうか。
定義
SEO実験の世界をよりよく理解するには、読者はSEO実験の基本的な概念を知っておく必要があります。
- 実験:仮説をテストするために行われる手順。 因果推論の場合、特定の開始日があります。
- テストグループ:変更が適用されるデータのサブセット。 Webサイト全体またはサイトの一部にすることができます。
- コントロールグループ:変更が適用されなかったデータのサブセット。 1つまたは複数のコントロールグループを持つことができます。 これは、同じ業界の別のサイトでも、同じサイトの別の部分でもかまいません。
以下の例は、これらの概念を説明するのに役立ちます。
タイトル(実験)を変更すると、5つの都市(テストグループ)の製品ページのオーガニックCTRが1%(仮説)増加するはずです。 他のすべての都市(コントロールグループ)で変更されていないタイトルを使用して、見積もりが改善されます。
正確なSEO実験予測の柱
- 簡単にするために、実験の精度を向上させる方法を学ぶSEO専門家のためにいくつかの興味深い洞察をまとめました。
- CausalImpactの一部の入力は、統計的に有意な場合でも、誤った推定値を返します。 これは、私たちが「誤検知」および「誤検知」と呼んでいるものです。
- テストセットに対して使用するコントロールを管理する一般的なルールはありません。 特定のテストセットに使用するのに最適な制御データを定義するには、実験が必要です。
- CausalImpactを適切なコントロールと適切な長さのプレピリオドデータで使用すると、平均誤差が0.1%と低くなり、非常に正確になります。
- または、間違ったコントロールでCausalImpactを使用すると、エラー率が高くなる可能性があります。 個人的な実験では、実際には変化がなかったにもかかわらず、最大20%の統計的に有意な変動が示されました。
- すべてをテストできるわけではありません。 一部のテストグループは、正確な推定値を返すことはほとんどありません。
- コントロールグループがある場合とない場合の実験では、介入前に異なる長さのデータが必要です。
すべてのテストグループが正確な推定値を返すわけではありません
一部のテストグループは、常に不正確な予測を返します。 実験には使用しないでください。
異常なトラフィック変動が大きいテストグループは、信頼できない結果を返すことがよくあります。
たとえば、同じ年にWebサイトでサイトが移行され、パンデミックの影響を受け、技術的なエラーのためにサイトの一部が2週間「インデックスに登録されていません」でした。 そのサイトで実験を行うと、信頼できない結果が得られます。
上記のポイントは、以下に説明する方法論を使用して行われた一連の広範なテストを通じて収集されました。
コントロールグループを使用しない場合
- 単純な事前投稿の代わりにコントロールを使用すると、推定の精度が最大18倍向上する可能性があります。
- 16か月前のデータを使用することは、3年を使用するのと同じくらい正確でした。
コントロールグループを使用する場合
- 多くの場合、複数のコントロールを使用するよりも、適切なコントロールを使用する方が適切です。 ただし、単一のコントロールは、コントロールのトラフィックが大きく変動する場合に誤った予測のリスクを高めます。
- 適切なコントロールを選択すると、精度を10倍に高めることができます(たとえば、1つは+ 3.1%を報告し、もう1つは実際には+ 3%であったのに+ 4.1%を報告します)。
- テストデータとコントロールデータの間のほとんどの相関トラフィックパターンは、必ずしもより良い推定を意味するわけではありません。
- 16か月前のデータを使用することは、3年を使用することほど正確ではありませんでした。
実験前のデータの長さに注意してください
興味深いことに、対照群で実験する場合、16か月前のデータを使用すると、非常に高いエラー率が発生する可能性があります。
実際、実際の変更がなかった場合、エラーはトラフィックの3倍の増加を見積もるのと同じくらい大きくなる可能性があります。
ただし、3年間のデータを使用すると、そのエラー率が削除されました。これは、長さを16か月から36か月に増やしてもエラー率が増加しなかった単純な事後実験とは対照的です。
それは、コントロールの使用が悪いという意味ではありません。 それはまったく逆です。
これは、制御の追加が予測にどのように影響するかを示しています。
これは、対照群に大きな変動がある場合です。
この持ち帰りは、過去1年間に異常なトラフィック変動(重大な技術的エラー、COVIDパンデミックなど)があったWebサイトにとって特に重要です。

CausalImpact予測を評価する方法は?
現在、CausalImpactライブラリには精度スコアが組み込まれていません。 したがって、それ以外の場合は推測する必要があります。
他の機械学習モデルが予測の精度をどのように推定するかを見て、二乗和誤差(SSE)が非常に一般的なメトリックであることがわかります。
二乗和誤差、または残差平方和は、期待値(yi)と実際の結果(f(xi))の間のすべての(n)差の合計を二乗して計算します。 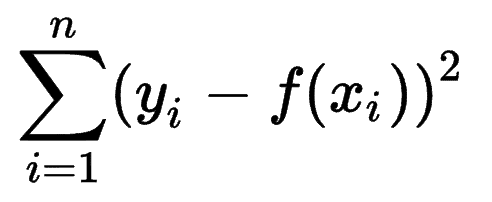
SSEが低いほど、結果は良くなります。
課題は、SEOトラフィックの事後実験では、実際の結果がないことです。
オンサイトで変更は行われていませんが、一部の変更が管理外で行われた可能性があります(たとえば、Googleアルゴリズムの更新、新しい競合他社など)。 SEOトラフィックも固定数で変化することはありませんが、上下に徐々に変化します。
SEOの専門家は、この課題をどのように克服するか疑問に思うかもしれません。
偽のバリエーションの紹介
イベントによって引き起こされる変動のサイズを確認するために、実験者はさまざまな時点で固定された変動を導入し、CausalImpactが変化を正常に推定したかどうかを確認できます。
さらに良いことに、SEOの専門家は、さまざまなテストグループとコントロールグループに対してこのプロセスを繰り返すことができます。
Pythonを使用して、ポスト期間のさまざまな介入日のデータに固定バリエーションが導入されました。
次に、CausalImpactによって報告された変動と導入された変動の間で、二乗和誤差が推定されました。
アイデアは次のようになります。
- テストおよび制御データを選択します。
- さまざまな日付で実際のデータに偽の介入を導入します(たとえば、5%の増加)。
- CausalImpactの推定値を、導入された各バリエーションと比較します。
- 二乗和誤差(SSE)を計算します。
- 複数のコントロールを使用して手順1を繰り返します。
- 実際の実験では、SSEが最小のコントロールを選択してください
方法論
以下の方法論を使用して、さまざまな時点でエラー率が最高および最低のコントロールを特定するために使用できるテーブルを作成しました。
まず、テストおよび制御データを選択し、-50%から50%までの変動を導入します。
次に、CausalImpact(CI)を実行し、CIによって報告された変動を実際に導入した変動から差し引きます。
その後、これらの差の2乗を計算し、すべての値を合計します。
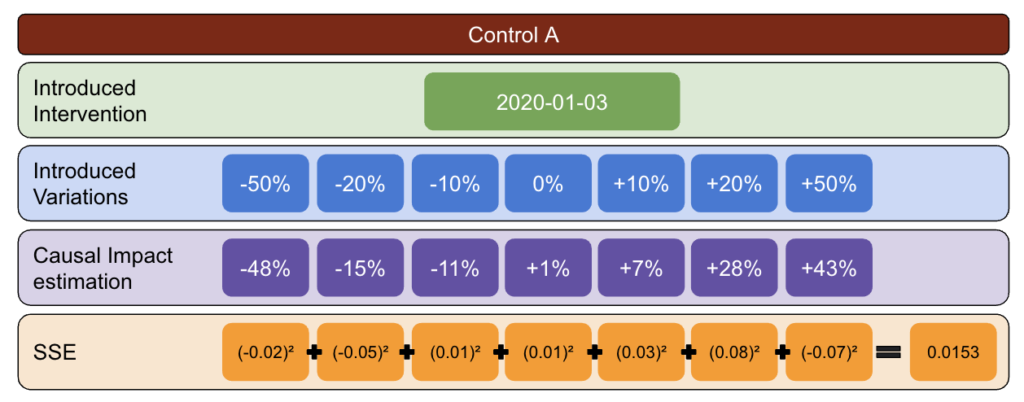
次に、同じプロセスを異なる日付で繰り返して、特定の日付での実際の変動によって引き起こされるバイアスのリスクを減らします。
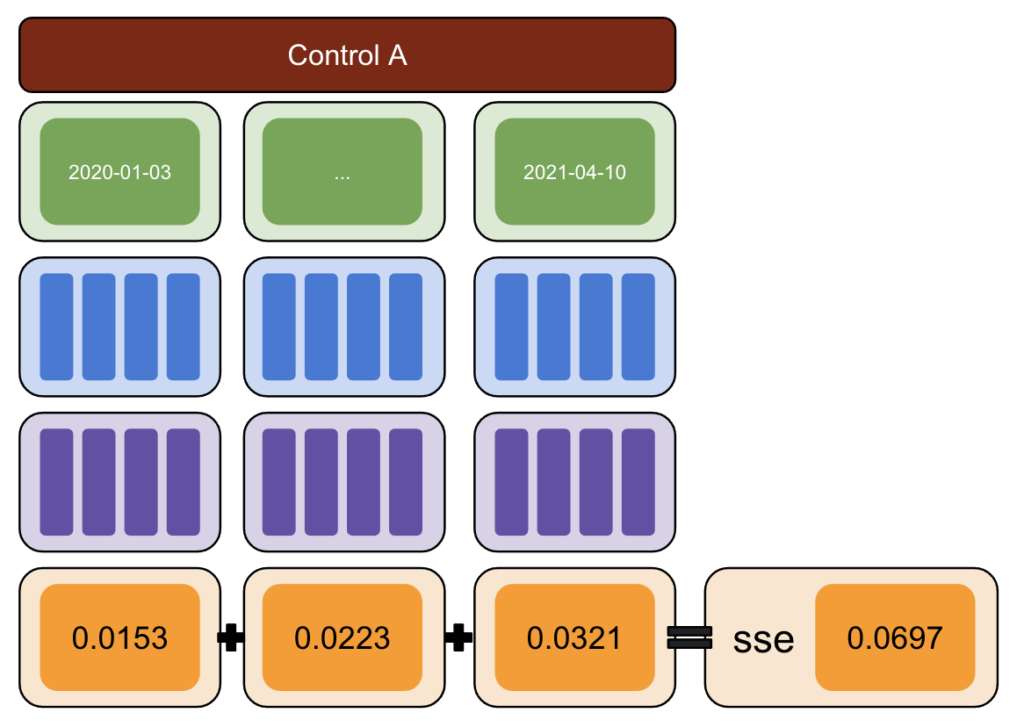
繰り返しますが、複数の対照群で繰り返します。
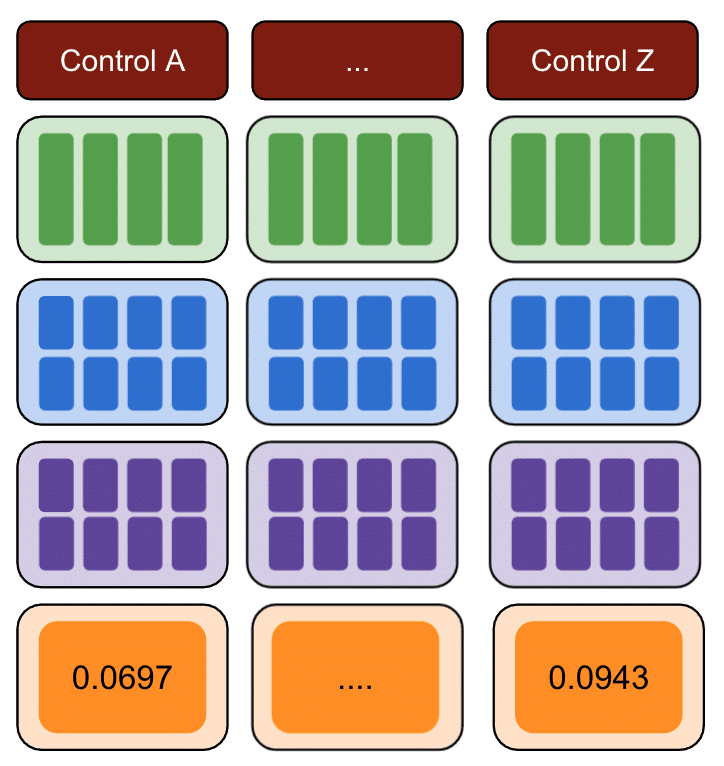
最後に、二乗和誤差が最小のコントロールは、テストデータに使用するのに最適なコントロールグループです。
テストデータごとに各手順を繰り返すと、結果は異なります。
結果のテーブルでは、各行はコントロールグループを表し、各列はテストグループを表します。 内部のデータはSSEです。
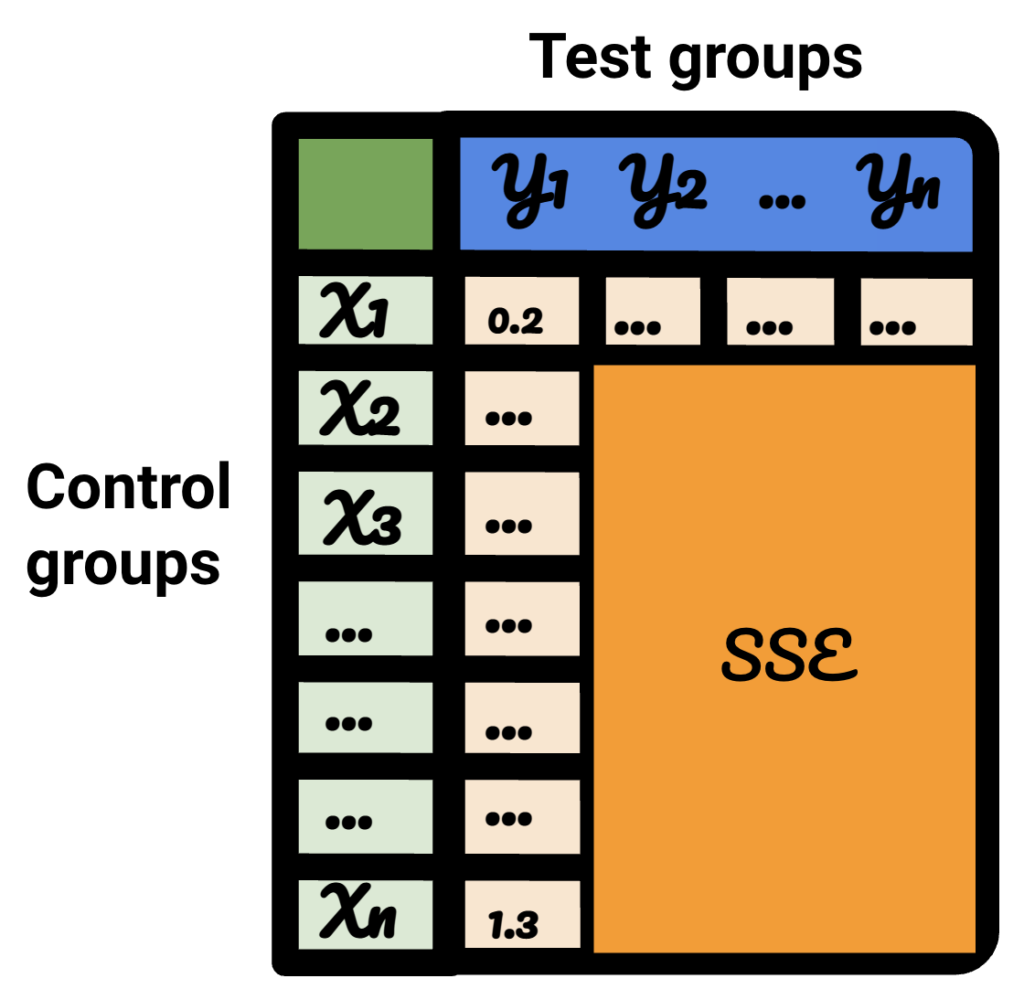
そのテーブルを並べ替えると、テストグループごとに、それに最適なコントロールグループを選択できると確信しています。
コントロールグループを使用する必要がありますか?
証拠は、対照群を使用すると、単純な事前投稿よりも優れた推定値を得るのに役立つことを示しています。
ただし、これは、適切なコントロールグループを選択した場合にのみ当てはまります。
見積もり期間はどのくらいにする必要がありますか?
その答えは、選択しているコントロールによって異なります。
コントロールを使用しない場合は、16か月前の実験で十分と思われます。
コントロールを使用する場合、16か月だけを使用すると、エラー率が高くなる可能性があります。 3年を使用すると、誤解のリスクを減らすのに役立ちます。
1つのコントロールを使用する必要がありますか、それとも複数のコントロールを使用する必要がありますか?
その質問に対する答えは、テストデータによって異なります。
非常に安定したテストデータは、複数のコントロールと比較した場合に良好に機能します。 この場合、多くのコントロールを使用すると、コントロールの1つで予期しない変動によるモデルへの影響が少なくなるため、これは適切です。
他のデータセットでは、複数のコントロールを使用すると、単一のコントロールを使用する場合よりもモデルの精度が10〜20倍低くなる可能性があります。
SEOコミュニティでの興味深い仕事
CausalImpactは、SEOテストに使用できる唯一のライブラリではありません。また、上記の方法論は、その精度をテストするための唯一のソリューションではありません。
代替ソリューションを学ぶために、SEOコミュニティの人々によって共有された信じられないほどの記事のいくつかを読んでください。
まず、Andrea Volpiniが、CausalImpactAnalysisを使用したSEOの有効性の測定に関する興味深い記事を書きました。
次に、Daniel Herediaが、ProphetとPythonを使用してSEOトラフィックを予測するためのFacebookのProphetパッケージについて説明しました。
Prophetライブラリは実験よりも予測に適していますが、予測の世界をしっかりと把握するには、さまざまなライブラリを学ぶ価値があります。
最後に、ブライトンSEOでのSandy Leeのプレゼンテーションに非常に満足しました。そこでは、SEOテストのためのデータサイエンスの洞察を共有し、SEOテストの落とし穴のいくつかを提起しました。
SEO実験を行う際に考慮すべきこと
- サードパーティのSEO分割テストツールは優れていますが、不正確になる可能性もあります。 ソリューションを選択するときは徹底してください。
- 過去に書いたのですが、サーバー側でない限り、GoogleTagManagerでSEO分割テストの実験を行うことはできません。 最善の方法は、CDNを介して展開することです。
- テストするときは大胆にしてください。 小さな変更は通常、CausalImpactによって検出されません。
- SEOテストが常に最初の選択肢であるとは限りません。
- タイトルタグのような小さな変更をテストする代わりの方法があります。 GoogleAdsのA/Bテストまたはプラットフォーム上のA/Bテスト。 実際のA/Bテストは、SEO分割テストよりも正確であり、通常、タイトルの品質に関するより多くの洞察を提供します。
再現性のある結果
このチュートリアルでは、コーディング方法を知らなくても、SEO実験の精度を向上させる方法に焦点を当てたいと思いました。 さらに、データのソースはさまざまであり、サイトごとに異なります。
したがって、このコンテンツを作成するために使用したPythonコードは、この記事の範囲の一部ではありませんでした。
ただし、ロジックを使用すると、上記の実験を再現できます。
結論
この記事から得られるポイントが1つしかない場合、CausalImpact分析は非常に正確である可能性がありますが、常に離れている可能性があります。
このパッケージを使用したいSEOにとって、彼らが何を扱っているかを理解することは非常に重要です。 私自身の旅の結果は、最初に入力データでモデルの精度をテストしない限り、CausalImpactを信頼できないということです。