
MMMデータフィードスプレッドシートを使用してマーケティングミックスモデリングを自動化する方法
公開: 2022-06-16マーケティングミックスモデリングまたはMMMは、一般的に使用されるようになってから60年以上にわたってルネッサンスを迎えています。 ほとんどのマーケティングアトリビューション方法とは異なり、MMMはユーザーレベルのデータを必要としません。マーケティングチャネルのアクションやイベントへの支出の急増と急降下を統計的にマッピングすることで、どのチャネルが売り上げに値するかをモデル化するのではありません。 単純な線形回帰からリッジ回帰やベイズ法などの手法にアップグレードすることで、マーケティングミックスモデリングが現代に向けて再発明されています。

MMMについてもっと知りたいですか?
マーケティングミックスモデリングとアトリビューションモデリングの長所と短所を読む
ただし、克服すべき大きなハードルがあります。 2021年10月からオープンソースのMMMライブラリに取り組んでいるMeta/Facebookによると、モデルの構築には3〜6か月かかる可能性があります。推定では、モデリングを開始する前にデータの収集とクリーニングに時間の約50%が費やされています。 。 これは、Recastでの私の経験(および以前のHarry's)と、データサイエンス時間の60%がデータのクリーニングと整理に費やされていることを発見したCrowdFlowerの調査結果と一致します。
早送り>>
- データクリーニング
- マーケティングミックスモデルの構築
- 自動モデリング
データクリーニングは仕事の60%であり、それを0%にする方法
正確なモデルを作成するには、特定の形式のデータが必要です。 データの準備には時間がかかるため、MMMプロジェクトには必要以上に時間がかかります。 これにより、MMMは専門的で高価なスキルになるため、ほとんどの企業は1年に1〜2つのモデルしか作成できません。 Supermetricsなどのツールを使用してプロセスを自動化してMMMデータフィードを作成できる場合は、モデルを定期的に更新して、マーケティング予算をより適切に最適化することができます。
表形式のデータ形式
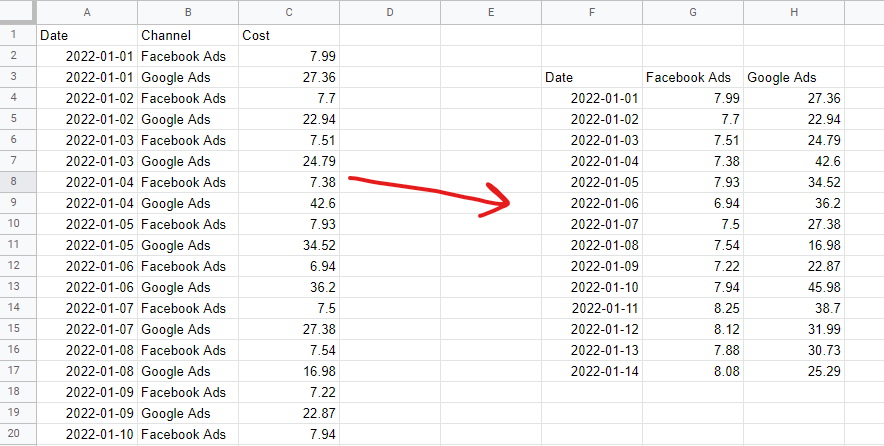
マーケティングミックスモデルを構築するには、データをスタックされていない表形式でレイアウトする必要があります。 これは、観測ごとに1行(通常は数日または数週間)、モデルの「機能」ごとに1列(通常はメディア支出と有機変数または外部変数)を意味します。 カテゴリデータ(たとえば、祝日のリスト)は、ダミー変数にエンコードする必要があります。休日の場合は1、そうでない場合は0です。
参加したデータソース
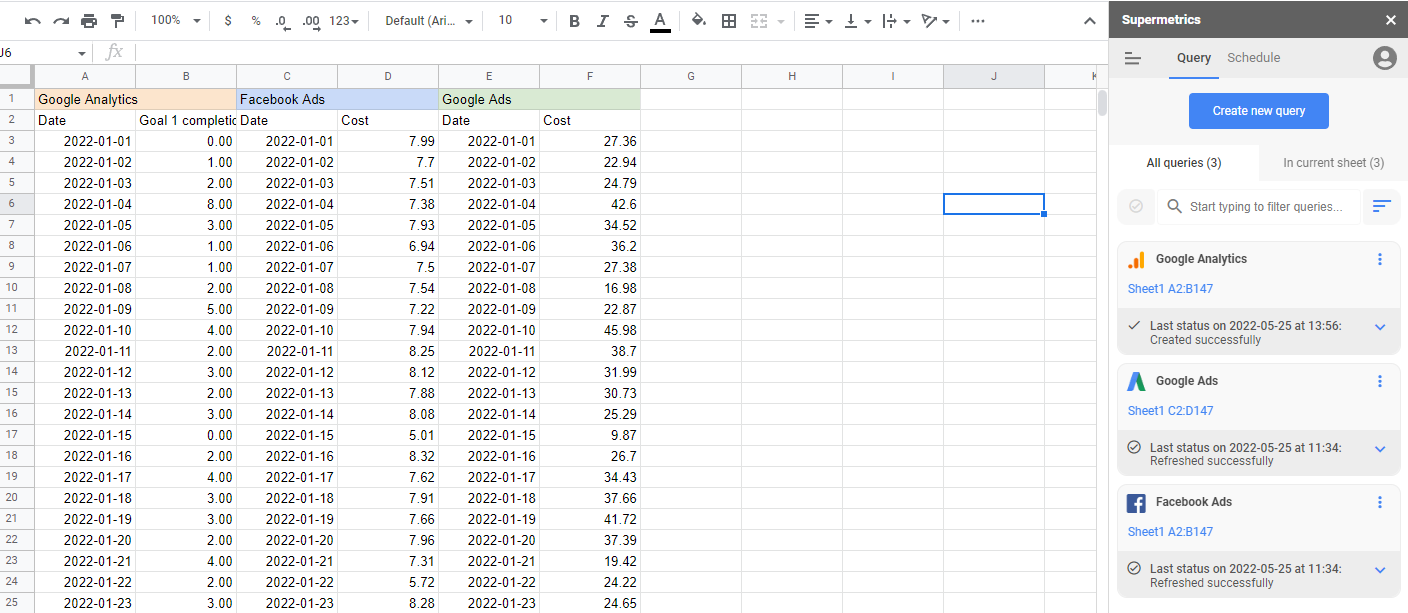
マーケティングアトリビューションモデルを構築するには、すべてのマーケティングデータを1か所にまとめる必要があります。 これは、Supermetricsが自動的に処理するものです。 90を超えるコネクタを使用すると、マーケティング費用、イベント、およびアクティビティをすべて1つの場所にまとめ、必要に応じて操作して、必要な形式と場所にエクスポートできます。
Googleスプレッドシートへのエクスポート
Supermetricsアカウントを取得したら、[拡張機能]>[アドオン]>[アドオンの取得]に移動してインストールするだけです。 SupermetricsアカウントにリンクされたGoogleアカウントで認証するように求められ、サイドバーが拡張機能メニューに表示されます。
これが完了したら、サイドバーを起動し(まだ起動されていない場合)、クリックして新しいクエリを作成できます。 クエリは、どのデータをどのアカウントから取得するかを決定する方法です。 Facebook広告やGoogle広告などの広告プラットフォームのいずれかを選択すると、認証してスーパーメトリクスへのアクセスを許可するように求められます。
次に、データを取得するアカウントと日付範囲を選択します。 最後に、指標(通常はMMMの費用またはインプレッション)とディメンションを選択します。表形式と一致するように日付のみを選択します。
オプションで、特定のキャンペーンセットを選択する必要がある場合は、フィルターを追加することをお勧めします。 たとえば、YouTubeキャンペーンの名前に「YT:」が含まれている場合は、それらを個別のソースとして選択し、クエリを複製して、他のキャンペーンタイプごとにフィルタリングすることができます。
クエリが終了したら、データを取り込むセルが選択されていることを確認し、[テーブルにデータを取得]をクリックします。 間違えた場合は、クエリを複製して適切な場所に配置し、もう一方を削除してください。
テーブルの上のセルに各ソースの名前を入力すると、データをどこから取得しているかがわかるので便利です。 結果は次のようになります。
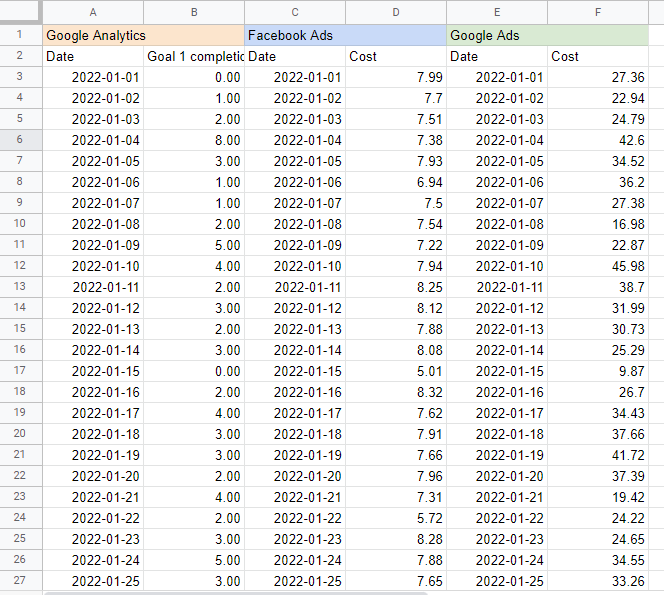
Googleスプレッドシートでのマーケティングミックスモデルの構築
マーケティングミックスモデリングはアトリビューションのための強力なツールですが、実際には想像以上にアクセスしやすくなっています。 ほとんどの開業医はカスタムコードと高度な統計を使用しますが、ExcelまたはGoogleスプレッドシートを使用するだけで、午後に基本を行うことができます。
LINEST関数による線形回帰
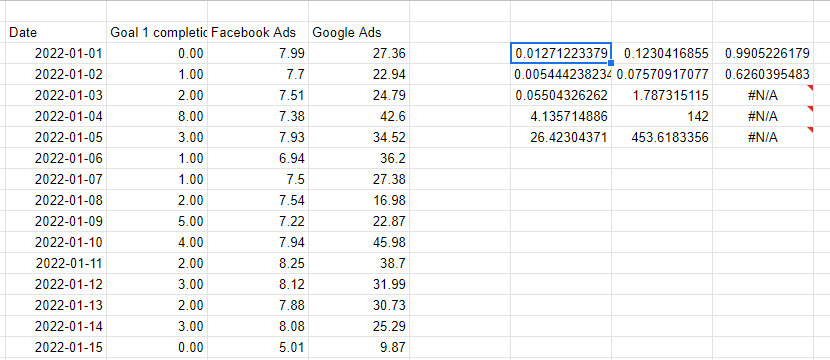
ExcelとGoogleスプレッドシートはどちらも、多変数線形回帰を実行するための簡単な方法であるLINEST関数を提供します。 LINESTは、予測しようとしている列を渡し、次に予測に使用している変数を表す複数の列を渡すことで機能します。 最後の2つのパラメーターは、係数だけでなく、モデルのすべての統計を含む切片線(通常はyesの場合は1)と出力を冗長にするかどうかです。
予測を行うために使用しているX変数は連続している必要があることに注意してください。そのため、左側の列を参照して、値を並べて繰り返しています。
モデル係数による再予測
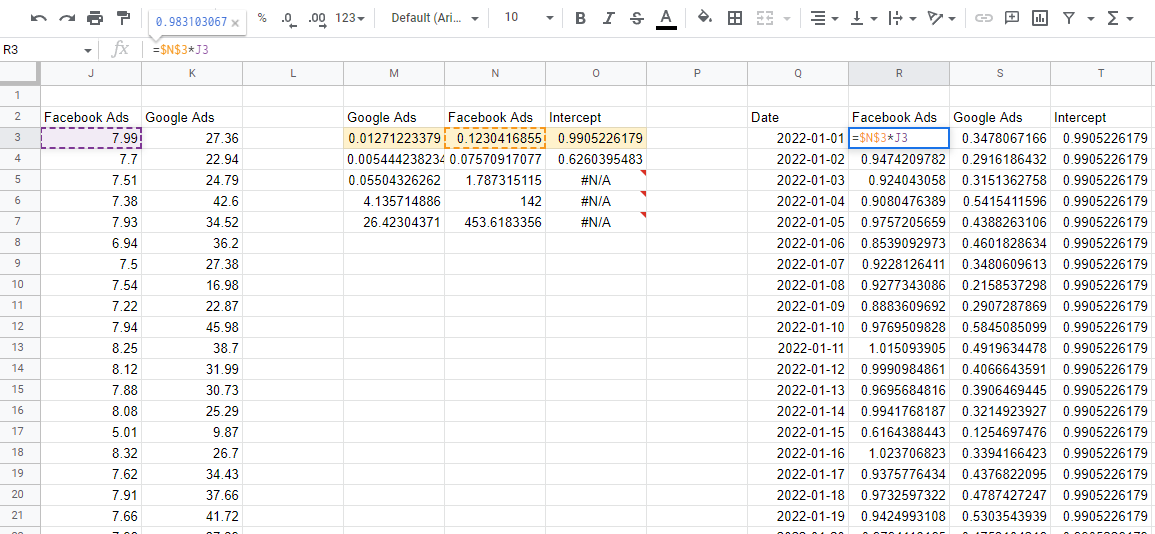
モデルができたので、係数を使用して各チャネルの影響を推定する必要があります。 一番上の行の数値を取得すると、それらは係数であり、データからの対応する入力値を掛けます。これにより、総売上高に対する各変数の寄与が得られます。
注意すべき点の1つは、LINESTが係数を逆方向に出力することです。 左から始まる最初の値は常に入力した最後の変数であり、最後の値(切片)に到達するまで逆の順序で続きます。 これらの寄与値をすべて合計すると、モデルからの予測が得られ、実際と比較してモデルが正確であることを確認できます。
モデルの精度メトリックを確認する
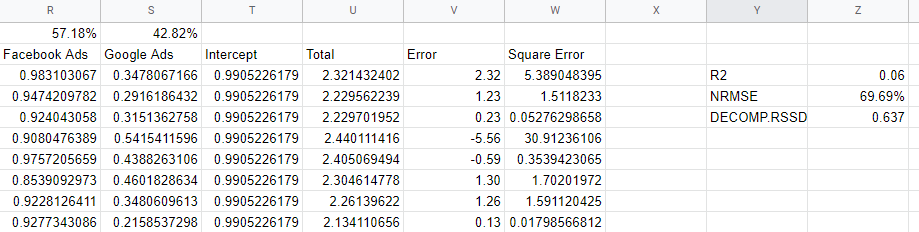
モデルが信頼できるかどうかをどうやって知ることができますか? モデルはデータにうまく適合し、見たことのない新しいデータを予測でき、もっともらしい係数を持っている必要があります。 いくつかの検証メトリックは、これらの要件をキャプチャします。

テンプレートの関数をチェックして、これらのメトリックを計算する方法を確認してください。
テンプレートを使用するには、アドオンのリストから「ファイル」>「コピーを作成」>「スーパーメトリクスの起動」に移動し、このファイルを別のアカウントに複製してから、アカウントの選択に進みます。
R2またはR-Squaredは、データの分散のどれだけがモデルによって説明されるかの尺度であり、0から1の間です。適切なモデルは0.7を超えますが、1に近づくものはおそらく疑わしいものです。 モデルのように、0に近いということは、モデルに十分な変数が含まれておらず、有機チャネル、休日、マクロ経済的要因などを組み込む必要があることを示しています。
「正規化された二乗平均平方根誤差」は、精度を測定する方法であり、モデルの予測と実際の値の差を取り、実際の値のパーセンテージとして二乗値の根を見つけることによって求められます。 理想的には、これは目に見えないデータ(ホールドアウトグループ)に基づいて行われますが、単純なモデルでは、サンプル内のデータに対してエラーを計算しただけです。
ルートと二乗の手順は、負の値を処理し、非常に大きなエラーにペナルティを課すように機能します。 これは、特定の日にモデルのパーセンテージがオフになっていると解釈できるため、便利で直感的な測定値です。
妥当性は大きなトピックであり、通常、アナリストが最終決定を下す必要があります。 ただし、プログラムで計算できるメトリックを用意しておくと、現在のチャネルミックスからの結果に関して、モデルがどの程度逸脱しているかを理解できるので便利です。
Decomp RSSDは、FacebookのRobynチームによって発明された指標であり、モデルによって予測されたように、現在の支出配分と最大の効果をもたらしたチャネルとの差を測定しました。 モデルがあなたの最大のチャネルが実際にそれほど多くの売上を促進しなかったと言った場合、あなたは高いDecompRSSDを持っているでしょう。
私たちの場合、モデルがFacebookにあまりにも多くのクレジットを与えているため、0.6という高い値があります。これは、わずかな支出を表しています。
MMMを自動的かつ大規模に配信
マーケティングミックスモデリングは、無限にスケーラブルなアクティビティの1つです。 ここで行ったように、ExcelまたはGoogle Sheets and Supermetricsを使用すると、午後に適切な結果を得ることができますが、ベイジアンMCMCなどの高度なアルゴリズムを使用してカスタムコードを作成する6人のデータサイエンティストのチームと3か月を費やして、さらに何かを構築することもできます。堅牢で正確。
高度なモデルの構築に使用される機能のチェックリストがあり、その一部には高度な統計知識が必要です。 Supermetricsを使用してその部分を自動化しない場合は、データパイプラインを構築するための高価なデータエンジニアを何人か追加してください。
ミックスの自動化のモデリングについてもっと知りたいですか?
自動化されたマーケティングミックスモデリングの記事をご覧ください
警告:MMMは難しいです。 モデリングに500ドル、5,000ドル、または5万ドルを費やすと、精度と堅牢性において大きく異なる結果を確認できます。 本当に重要なのは、マーケティング費用の配分を間違えることによる機会費用です。
月に1万ドルを費やす場合は、四半期に1回のスプレッドシートモデルで十分です。 ただし、1か月あたり10万ドル以上を費やしている場合は、5%オフでも、1年間で数万ドルの費用がかかる可能性があります。
MMMフィードに必要なデータアクセスモデルがわかりませんか?
私たちの記事をチェックして、あなたのビジネスに適したものを選択してください
そのとき、より高度なモデリングに投資するのが理にかなっています。 ビルドと購入の分析を行って、FacebookのRobynなどのオープンソースライブラリで構築されたカスタムソリューションと、Recastで構築したような高度なアトリビューションソフトウェアのどちらかを決定します。
著者について
Michael Kaminskyは、ヘルスケアと環境経済学のバックグラウンドを持つ訓練を受けた経済学者です。 彼は以前、Recastを共同設立する前に、男性用グルーミングブランドのHarry'sでマーケティングサイエンスチームを構築していました。

業績を向上させる
データウェアハウスでマーケティングとビジネスインテリジェンスを組み合わせることにより