
ウェビナーダイジェスト:BillHartzerによるライブSEO監査とログファイル
公開: 2018-10-029月25日、OnCrawlは、ログファイル分析とSEO監査にとって重要である理由に関するウェビナーのためにBillHartzerをホストしました。 彼は自分のWebサイトを調べて、ボットのアクティビティとクロールの頻度に対する最適化の影響を示しました。
ビル・ハーツァーの紹介
Bill Hartzerは、20年以上の経験を持つSEOコンサルタントおよびドメイン名の専門家です。 ビルは彼の分野の専門家として国際的に認められており、最近、国内有数の検索専門家の1人としてCBSニュースでインタビューを受けました。
この1時間のウェビナーの過程で、ビルはログファイルを見て、サイト監査のコンテキストでそれらをどのように使用するかについて説明します。 彼は、自分のサイトでのサイトのパフォーマンスとボットの動作を検証するために使用するさまざまなツールを紹介しています。
最後に、ビルはOnCrawlを使用して意味のある結果を視覚化する方法に関する質問に答え、他のSEOにヒントを提供します。
WordPress用のcPanelプラグインを介してログファイルにアクセスする方法
WebサイトがWordPressで構築されており、プラグインcPanelを使用している場合は、サーバーログをWordPressインターフェイスで直接見つけることができます。
[メトリクス]、[RawAccess]の順に移動します。 そこで、ファイルマネージャから毎日のログファイルをダウンロードしたり、古いログファイルのzip形式のアーカイブをダウンロードしたりできます。 
ログファイルの内容を調べます
ログファイルは、ボットを含むWebサイトへのすべての訪問者に関する情報を含む大きなテキストファイルです。 基本的なテキストエディタを使用して開くことができます。
ログファイルで自分自身を識別しているgooglebotまたはbingから潜在的なボットヒットを見つけることは難しくありませんが、IPルックアップを使用してボットの識別を確認することをお勧めします。
また、サイトをクロールする他のボットを見つけることもできますが、それは役に立たない可能性があります。 これらのボットがサイトにアクセスするのをブロックできます。
OnCrawlは、ログファイル内の生の分析を処理して、サイトにアクセスするボットを明確に表示します。

クロール統計の詳細については、ログファイルを使用する
クロール統計に関する情報は、古いバージョンのGoogle検索コンソールの[クロール]> [クロール統計]で、ログファイルの情報と比較して新しい意味を持ちます。
Google検索コンソールに表示されるデータはGoogleのSEOボットに限定されないため、ログファイルを分析して取得できるより正確な情報よりも有用性が低い可能性があることに注意してください。
異常なクロールアクティビティの最近のインスタンス
ビルは、Google検索コンソールのクロール統計に表示される最近の3つのスパイクを調べます。 これらは、クロールアクティビティの増加をトリガーする大きなイベントに対応します。
モバイルファーストインデックススパイク
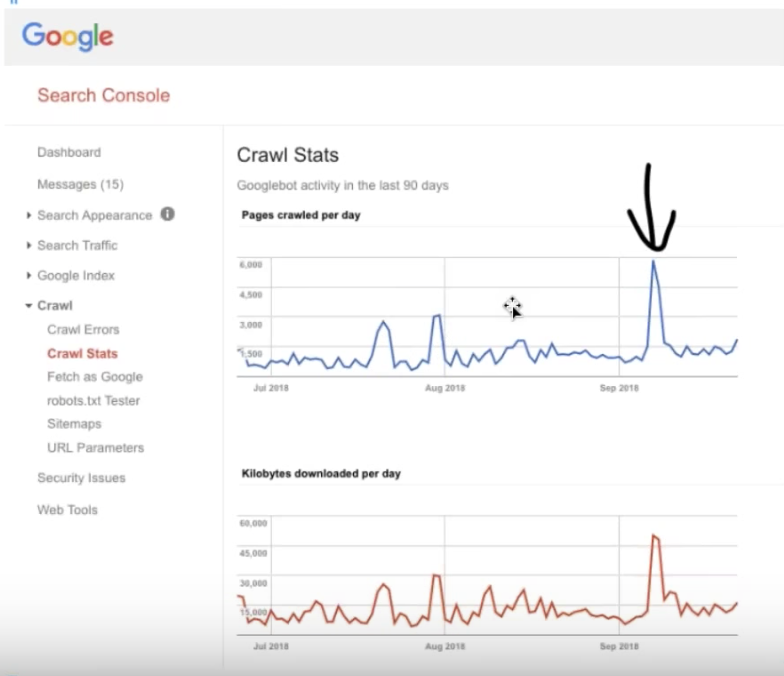
9月7日のGoogle検索コンソールの急増は、最初はWebサイトのイベントとは無関係に見えるかもしれません。 ただし、OnCrawlのログ分析を見ると、次のような手がかりが得られます。
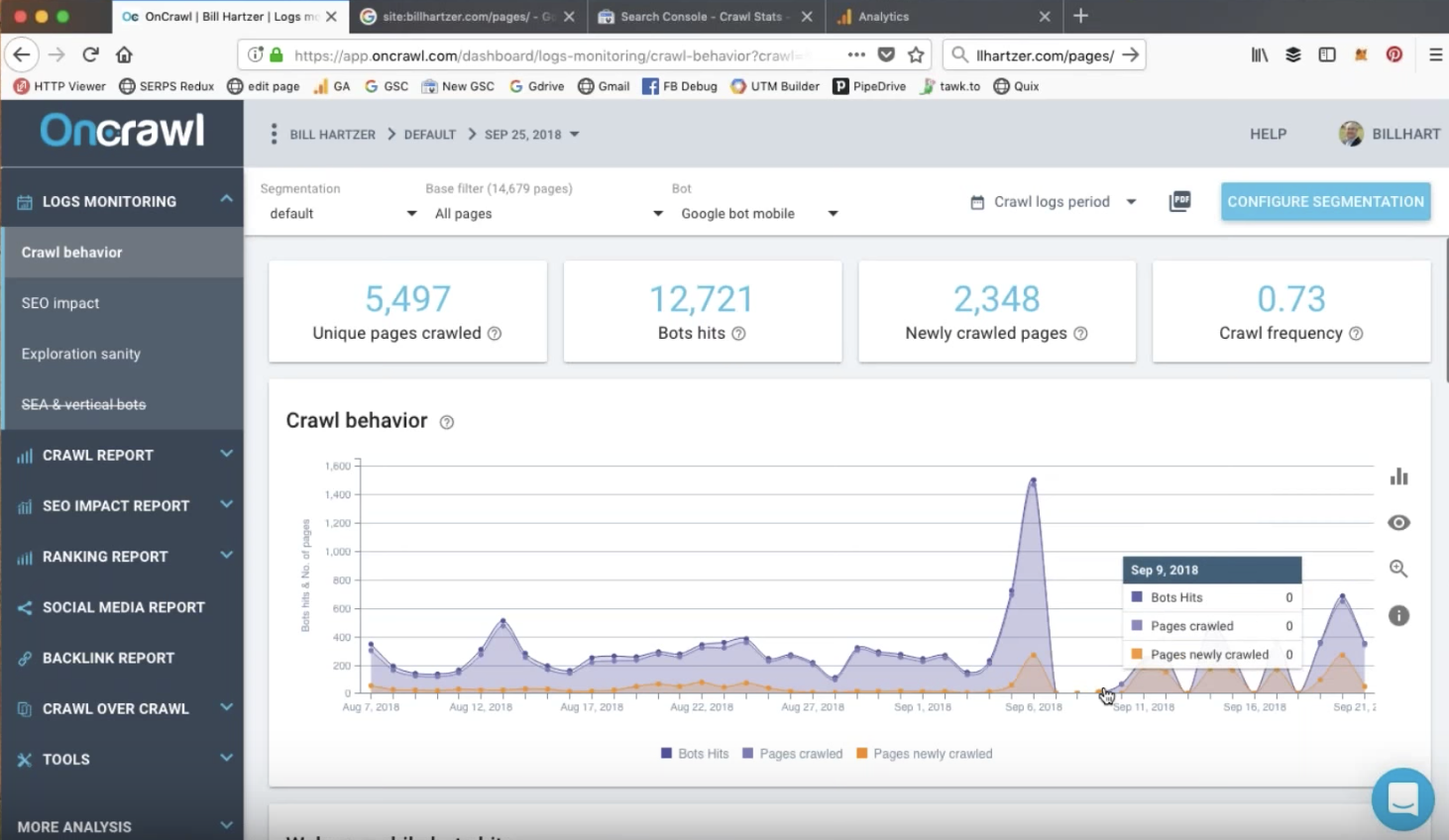
ログファイルの分析により、Googleがページをクロールするために使用するさまざまなボットの内訳を確認できます。 デスクトップのGooglebotのアクティビティはこの日付より前に急激に減少し、このスパイクは、以前の小さなスパイクとは異なり、モバイルGoogleボットによる一意のインデックス付きページのヒットでほぼ完全に構成されていたことが明らかになりました。
Google Analyticsによって記録されたオーガニックトラフィックの50%の増加は、この急上昇が、Googleからアラートが送信される数週間前の9月初旬のサイトのモバイルファーストインデックスに対応していることを確認しました。
サイトのURL構造の変更
8月中旬、ビルはURL構造を変更して、SEOに適したものにしました。
Google Search Consoleは、この変更の直後に2つの大きなスパイクを記録し、Googleが主要なサイトイベントを識別し、それらをWebサイトのURLを再クロールするためのシグナルとして使用することを確認しました。
OnCrawlでこれらのヒットの内訳を観察すると、2番目のスパイクはスパイクではないことが明らかになりますが、このWebサイトのページの高いクロール率は数日間にわたって継続します。 ビルが変更後の数日間のクロールアクティビティの違いを観察することで確認できるため、Googleが変更を取得したことは明らかです。
技術監査を実施するための便利なOnCrawlレポートと機能
SEO訪問とSEOアクティブページ
OnCrawlは、ログファイルデータを処理して、SEO訪問、またはGoogleSERPリストから到着した人間の訪問者に関する正確な情報を提供します。
訪問数を追跡したり、オーガニックトラフィックを受信するWebサイトの個々のページであるSEOアクティブページを確認したりできます。
監査の一環として調査したいことの1つは、一部のランキングページがオーガニックトラフィックを受信しない(つまり、SEOアクティブページではない)理由です。
フレッシュランク
OnCrawlのFreshRankなどの指標は、重要な情報を提供します。 この場合:Googleが最初にページをクロールしてから、ページが最初のSEOにアクセスするまでの平均遅延日数。
#FreshRankは、ページを初めてクロールする必要がある日数を把握し、最初の#SEOにアクセスするのに役立ちます。#oncrawlwebinar pic.twitter.com/WVojWXKStC
— OnCrawl(@OnCrawl)2018年9月25日
コンテンツプロモーション戦略とバックリンクの開発は、新しいページのトラフィックをより早く獲得するのに役立ちます。 ソーシャルネットワークを介して宣伝されたブログ投稿など、この監査のサイトの一部のページは、はるかに低いフレッシュランクを獲得しました。
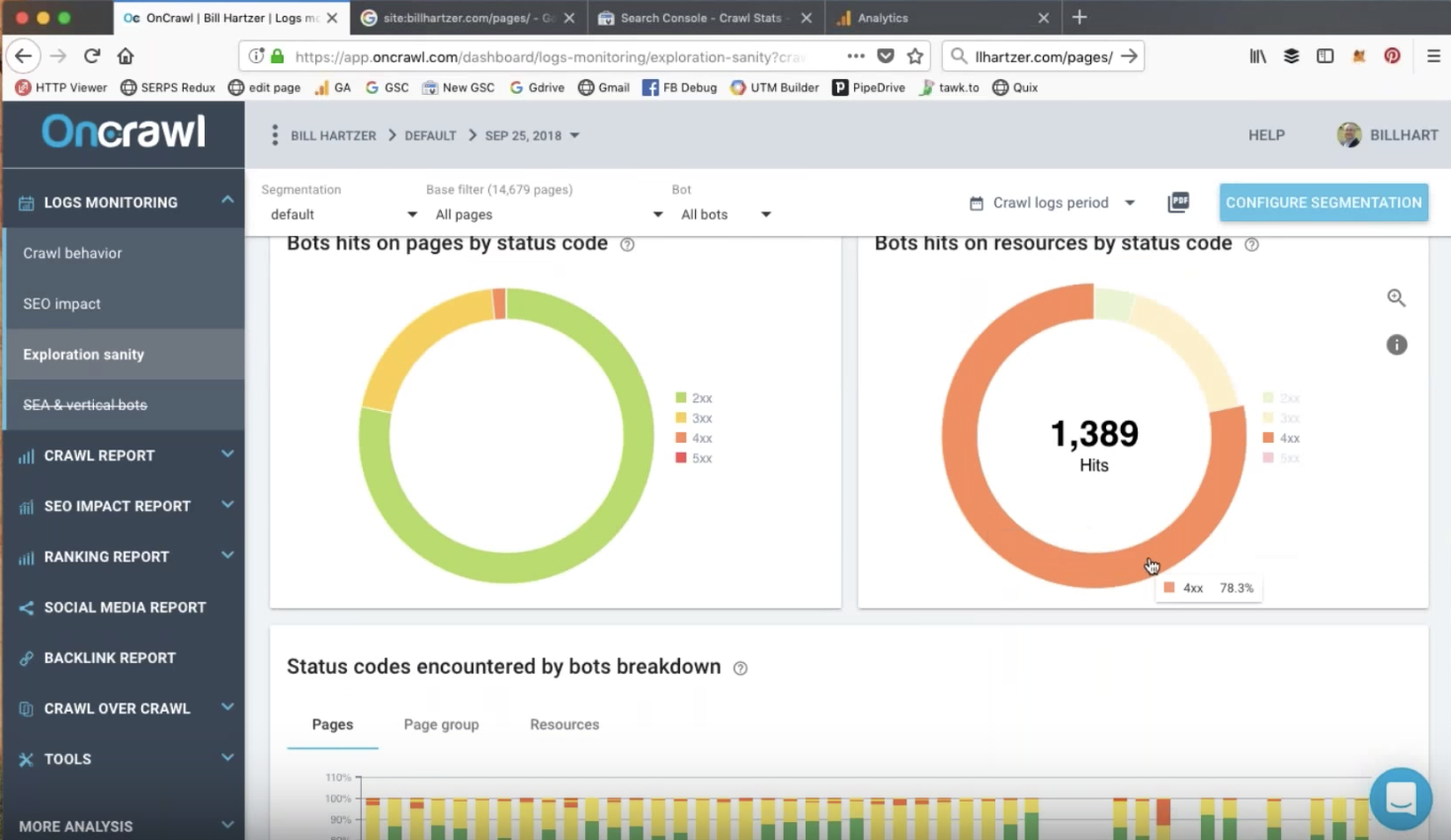
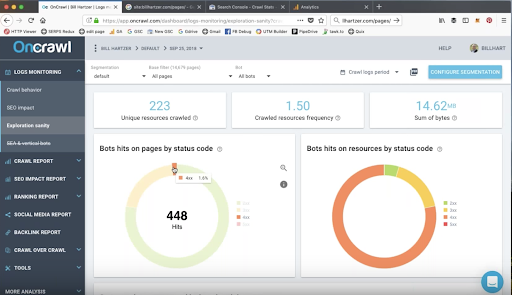
ステータスコードによるページとリソースのボットヒット
ボットは、404または410エラーを返すURLにアクセスしている可能性があります。 これは、CSS、JavaScript、PDF、画像ファイルなどのリソースに関係する可能性があります。
これらは、監査中に確実に調査したい要素です。 これらのURLをリダイレクトし、それらへの内部リンクを削除すると、すぐに成功する可能性があります。
監査中は、ステータスエラーをボットに返すURLなど、対処する必要のある要素をメモしておくと便利です。

データエクスプローラーレポート:カスタムレポート
OnCrawl Data Explorerは、興味のあるレポートを作成するためのクイックフィルターを提供しますが、興味のある基準に基づいて独自のレポートを取得することもできます。 たとえば、バウンスがあり読み込み時間が長いSEOアクティブページを調査したい場合があります。
データエクスプローラーレポート:アクティブな孤立ページ
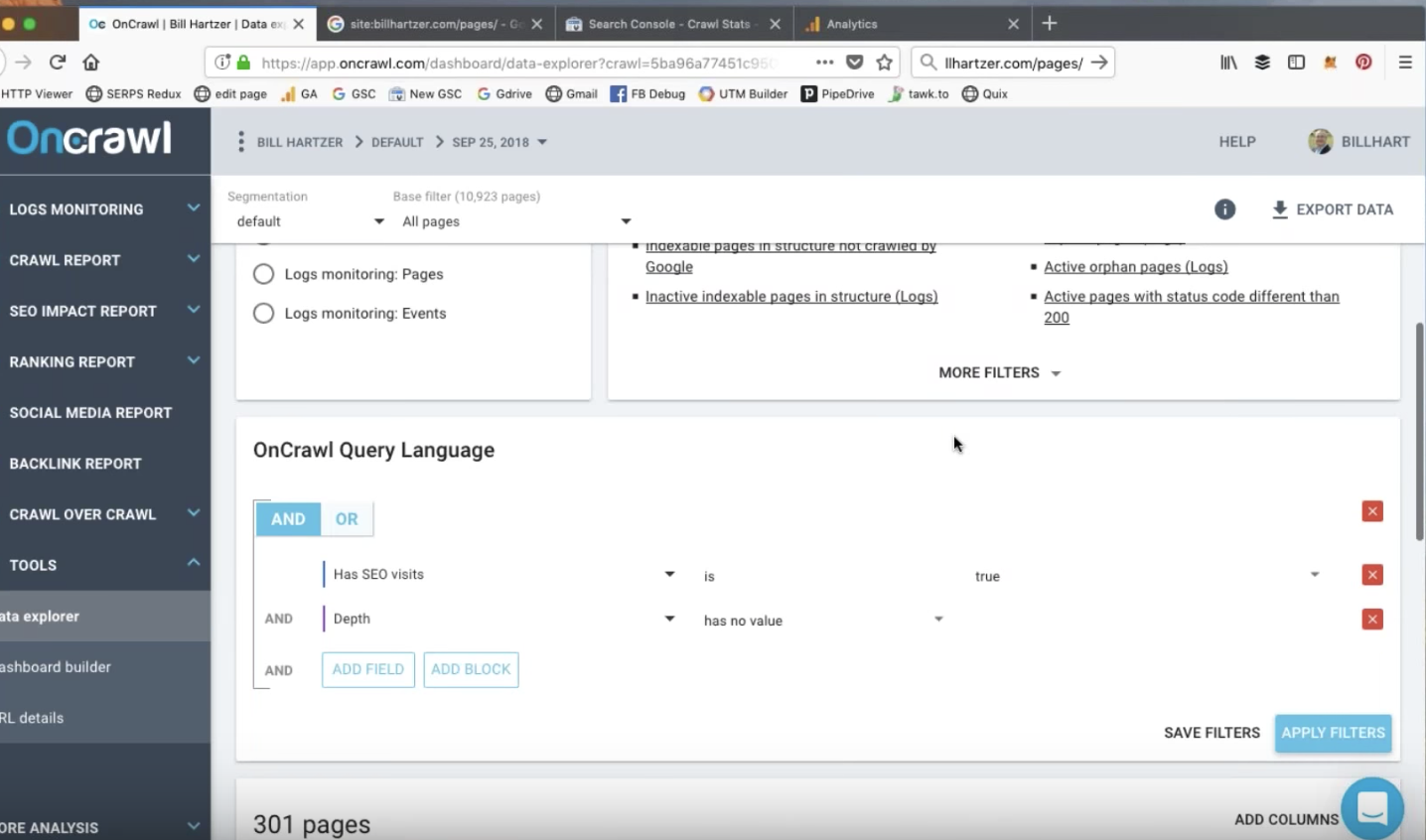
OnCrawlは、分析、クロール、ログファイルのデータを組み合わせることで、サイトに常に価値をもたらすとは限らない、有機的で人間的な訪問のあるページを見つけるのに役立ちます。 ログファイルのデータを使用する利点は、Google Analyticsコードが含まれていない可能性のあるページを含め、アクセスしたサイトのすべてのページを検出できることです。
ビルは、おそらく外部ソースからのリンクを介して、RSSフィードページでSEOのオーガニック訪問を特定することができました。 これらのページは彼のサイトの孤立したページです。 それらにリンクする「親」ページはありません。 これらのページは、彼のSEO戦略に特別な価値をもたらすものではありませんが、それでもオーガニックトラフィックから数回の訪問を受けています。
これらのページは、最適化を開始するのに最適な候補です。
キーワードランキングの分析を検索
ランキングのデータは、Google検索コンソールから取得できます。 古いバージョンのGoogle検索コンソールでは、[トラフィックの検索]、[アナリティクスの検索]の順に移動して、過去90日間のクリック数、表示回数、クリック率、掲載順位を表示できます。
OnCrawlは、この情報がサイト全体にどのように関連しているかについて明確なレポートを提供し、サイトの総ページ数、ランキングページ数、およびクリックを受け取ったページ数を比較できるようにします。
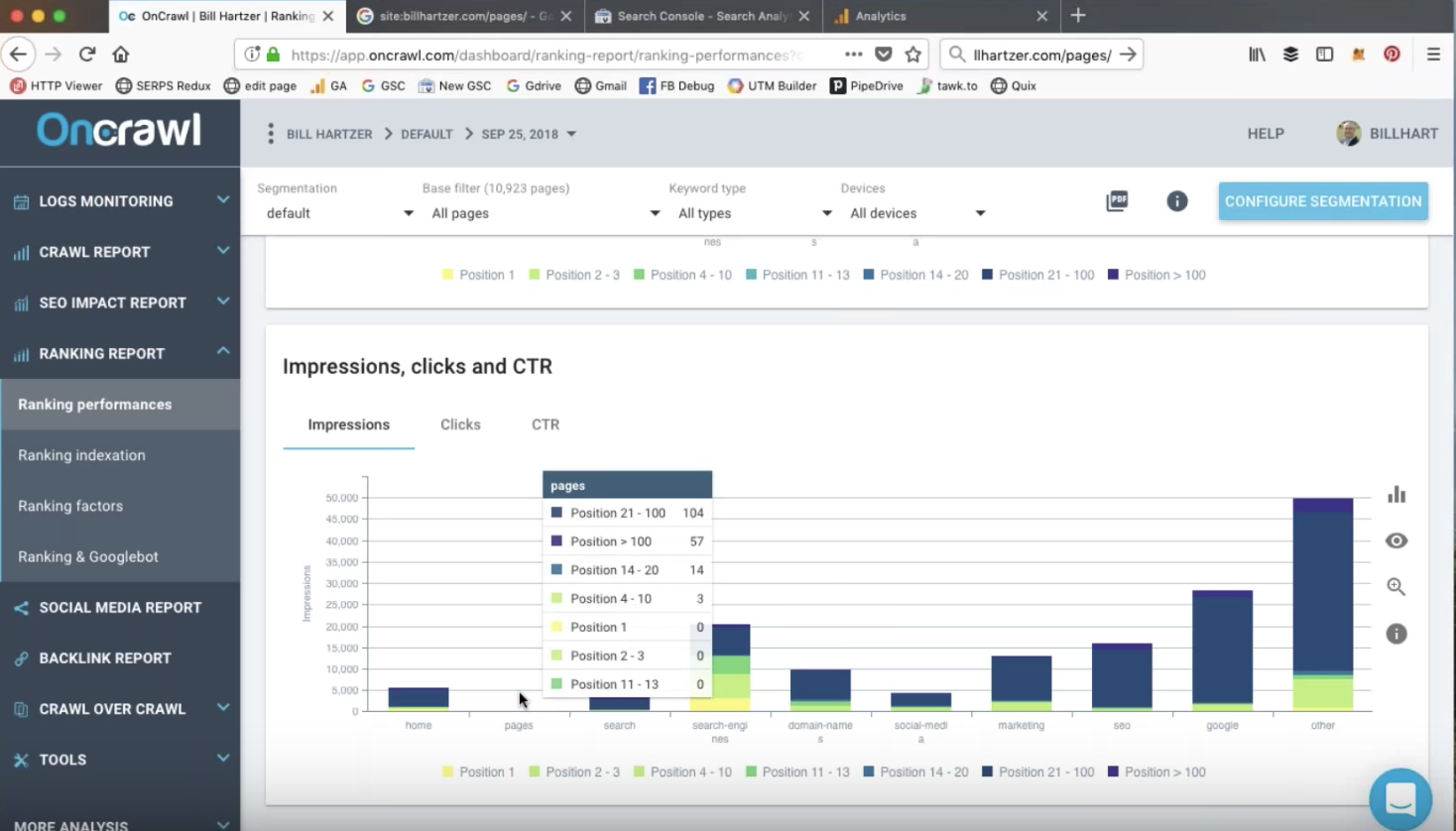
表示回数、クリック率、クリック数
サイトセグメンテーションを使用すると、サイトのどのタイプまたはグループのページがランク付けされているか、および結果のどのページにランク付けされているかを一目で確認できます。
この監査では、BillはOnCrawlのメトリックを使用して、ランクが高くなる傾向のあるページのタイプを見つけることができます。 これらは、ウェブサイトへのトラフィックを増やすために彼が作成し続ける必要があることを彼が知っているタイプのページです。
ランキングページのクリック数はランキングの位置と強く相関しています。10を超える位置は検索結果の最初のページに表示されなくなり、その時点でほとんどのキーワードのクリック数が急激に減少します。
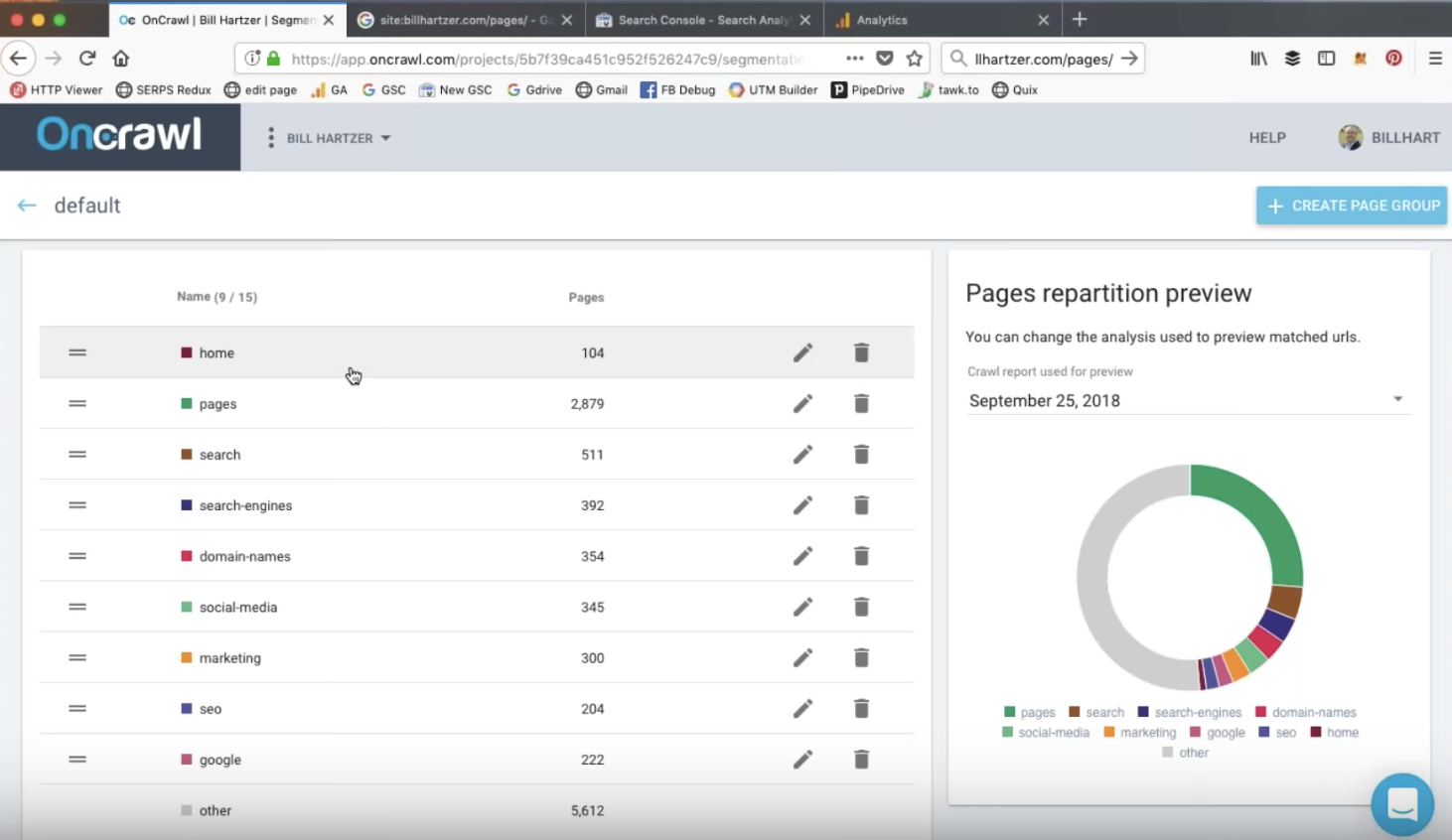
ウェブサイトのセグメンテーション
OnCrawlのセグメンテーションは、ページを意味のあるセットにグループ化する方法です。 自動セグメンテーションが提供されている間、フィルターを編集したり、独自のセグメンテーションを最初から作成したりできます。 OnCrawlクエリ言語フィルターを使用すると、さまざまな基準に基づいてグループ内のページを含めたり除外したりできます。
ビルがウェビナーで見ているサイトでは、セグメンテーションはWebサイトのさまざまなディレクトリに基づいています。
構造内のページ>クロール>ランク付け>アクティブ
OnCrawlランキングレポートでは、「構造内のページ>クロール>ランク付け>アクティブ」チャートで、ページのランク付けとアクセスの問題を警告できます。
このチャートはあなたを示しています:
- 構造内のページ:サイトのさまざまなリンクからアクセスできるページ数
- クロール:Googleがクロールしたページ
- ランク付け:GoogleSERPに表示されたページ
- アクティブ:オーガニック訪問を受けたページ
監査では、このグラフのバー間の違いの理由を確認する必要があります。
ただし、構造内のページ数とクロールされるページ数の違いは、たとえば、robots.txtファイルでロボットを禁止することでGoogleが特定のページをクロールできないようにする場合など、意図的なものである可能性があります。 これは、監査中に確認したいものです。
グラフをクリックすると、OnCrawlでこの種のデータを調べることができます。
重要なポイント
ログファイル分析は、ボットヒットの急増を検出し、ボットのアクティビティを毎日監視するのに役立ちます#oncrawlwebinar
@bhartzerによる本日のウェビナーpic.twitter.com/3DAC5d36j9— OnCrawl(@OnCrawl)2018年9月25日
このウェビナーの重要なポイントは次のとおりです。
- Webサイトの構造に大きな変更を加えると、クロールアクティビティに大きな変更が生じる可能性があります。
- Googleの無料ツールは、不正確に見える可能性のある方法で集計、平均化、または丸められたデータを報告します。
- ログファイルを使用すると、実際のボットの動作と有機的な訪問を確認できます。 クロールデータと毎日の監視を組み合わせることで、スパイクを検出するための強力なツールになります。
- 何が起こったのかを理解するには正確なデータが必要です。これは、分析、クロール、ランキング、特にOnCrawlなどのツールでのログファイルデータの相互分析によってのみ達成できます。
OnCrawlを無料でお試しください
実用的な監査の洞察を得るために、これらの手法をサイトに適用することに興味がありますか?
ライブを逃した? リプレイを見てください!
ライブウェビナーを作成できなかった場合、または完全なセッションにとどまることができなかった場合でも、完全なバージョンを表示できます。