
Javascript:OncrawlでSSRやプレレンダリングの実装をテストする方法は?
公開: 2021-09-13サイトのJavaScript実装に関するSEOの問題を診断することは必ずしも簡単ではありません。 ボットのサーバー側レンダリングまたは事前レンダリングを選択すると、タスクがさらに複雑になる可能性があります。
Googleボットに提供されるバージョンが完全であり、すべてのjavascript要素がサーバー側で実行され、ボットによってクロールされたhtmlに存在することを確認する必要があります。
この記事では、Oncrawlを使用してすべてのページのJSレンダリングをすばやく簡単にテストする方法を説明します。
SEOとJS
練習を始める前に、サーバーサイドレンダリング(SSR)のSEOとサイトのJavaScript要素の事前レンダリングについて簡単に説明しましょう。
JSとGoogle:グッドプラクティス
デフォルトでは、javascriptのHTMLレンダリングは、クライアント、つまりWebブラウザによって実行されます。 JS要素を含むページをリクエストすると、このjavascriptコードを実行してページ全体を表示するのはブラウザです。 これは、クライアント側レンダリング(CSR)と呼ばれます。
グーグルにとって、これは多くの時間と特にリソースを必要とするので問題です。 1回目はコードを取得するために、2回目はJSのHTMLをレンダリングした後に、ページを2回通過するように強制します。
SEOのCSRの直接的な結果として、ページの完全なコンテンツがGoogleにすぐに表示されないため、ページのインデックス作成が遅れる可能性があります。 さらに、ページを2回クロールする必要があるため、サイトに付与されるクロール予算も影響を受けます。
SSR(サーバー側レンダリング)
SSRの場合、JavaScriptのHTMLレンダリングは、サイトのすべての訪問者、人間、およびボットに対してサーバー側で行われます。 結果として、Googleは、クロール時に完全なhtmlを直接取得するため、JSのコンテンツを管理する必要はありません。 これにより、SEOのjavascriptの欠陥が修正されます。
一方、サーバー側でこのレンダリングを実現するためのリソースのコストは重要になる可能性があります。 これが、3番目のオプションである事前レンダリングの出番です。
事前レンダリング
このハイブリッド構成では、JSの実行は、検索エンジンボットを除くすべての訪問者(CSR)のクライアント側で行われます。 SSRのSEOの利点だけでなく、CSRの経済的な利点も維持するために、事前にレンダリングされたHTMLコンテンツがGoogleボットに提供されます。
一見クローキング(ボットやWebページの訪問者にさまざまなバージョンを提供する)と見なすことができるこの方法は、実際にはGoogleのアイデアであり、強くお勧めします。 その理由は簡単に推測できます。
OncrawlでJavascriptレンダリングをテストする方法は?
JSの実装でSEOエラーを診断する方法はたくさんあります。 Oncrawlを使用すると、手動で比較することなく、すべてのページを自動的にテストできます。
Oncrawlは、クライアント側でjavascriptを実行することにより、サイトをクロールできます。 アイデアは、2つのクロールを起動し、次の間の比較を生成することです。
- JSレンダリングが有効になっているクロール
- JSレンダリングが無効になっているクロール
次に、これら2つのクロールの違いをいくつかのメトリックで測定するために、JavaScriptの一部がサーバー側で実行されていないことを示します。
事前レンダリングの場合、事前レンダリングされたバージョンのサイトをクロールするために、2番目のクロールはGoogleユーザーエージェントで実行する必要があることに注意してください。
このテストは、次の3つのステップで実行できます。
- クロールプロファイルを作成する
- 各プロファイルでサイトをクロールし、クロールオーバークロールを生成します
- 結果を分析する
クロールプロファイルを作成する
JSのプロファイル
プロジェクトページで、[ +新しいクロールを設定]をクリックします。
これにより、クロール設定ページが表示されます。 デフォルトのクロール設定が表示されます。 それらを変更するか、新しいクロール構成を作成することができます。
クロールプロファイルは、将来使用するために名前で保存された一連の設定です。
新しいクロールプロファイルを作成するには、右上隅にある青い[ +クロールプロファイルの作成]ボタンをクリックします。
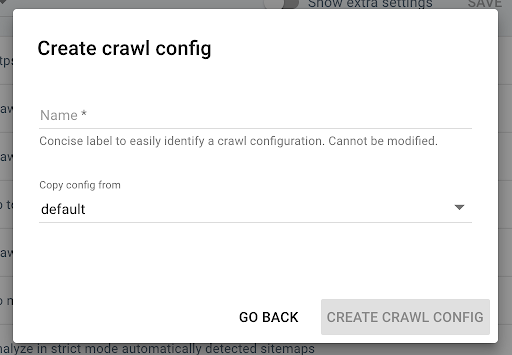
「JSでクロール」という名前を付けて、通常のクロールプロファイル(デフォルトなど)をコピーします。
この新しいプロファイルでJSをアクティブ化するには、デフォルトで非表示になっている追加のパラメーターを表示する必要があります。 それらにアクセスするには、ページの上部にある[追加の設定を表示]ボタンをクリックします。
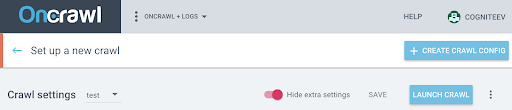
次に、[追加設定]に移動し、[JSのクロール]オプションで[有効にする]をクリックします。
注:Oncrawlは、Javascriptで要素を実行するために、URLごとにより多くの呼び出しを行うため、クロール速度をサイトのサーバーの容量に合わせて調整することを忘れないでください。 理想的な速度は、サーバーとサイトのアーキテクチャが最適にサポートできる速度です。 OnCrawlのクロール速度が速すぎると、サーバーが追いつかない可能性があります。
JSなしのプロファイル
この2番目のクロールプロファイルについては、同じ手順に従い、 JS有効化ボックスのチェックを外します。
注:比較を意味のあるものにするためには、同じスコープを持つ2つのプロファイルを用意することが重要です。
サイトがサーバー側レンダリングの場合は、次の手順に進みます。
サイトがGoogleボットに基づいて事前レンダリングされている場合は、クロール用にユーザーエージェントを変更するリクエストを送信する必要があります。 プロファイルが作成されたら、アプリケーションで直接Intercom経由でメッセージを送信して、OncrawlユーザーエージェントをGoogleボットユーザーエージェントに置き換えることができるようにします。
14日間の無料トライアルを開始する
 トライアルを開始する
トライアルを開始するクロールを起動し、クロールオーバークロールを生成します
2つのプロファイルが作成されたら、これら2つのプロファイルを順番に使用してサイトをクロールする必要があります。 簡単にするために、クロールプログラミング機能を使用できます。

クロールをスケジュールする
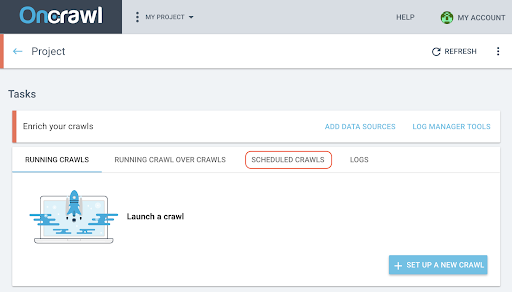
- プロジェクトページで、クロール追跡ボックスの上部にある[スケジュールされたクロール]タブをクリックします。
- 「+クロールのスケジュール」をクリックして、新しいクロールをスケジュールします。
- 次に、以下を選択する必要があります。
- 今後のクロールに使用するクロールプロファイル
- クロールを繰り返す頻度は、「1回だけ」を選択します。
- クロールを開始する日時(24時間形式)およびタイムゾーン(都市別)。
- 「クロールのスケジュール」をクリックします。
クロールの両方の分析が利用可能になったら、クロールオーバークロールを生成する必要があります。 
クロールオーバークロールを生成する
- プロジェクトのホームページから、クロールオーバークロールを起動します。
- 「タスク」の下で、 「クロールを介したクロールの実行」タブをクリックします。
- 「+クロールオーバークロールを開始」をクリックします。
- 比較する2つのクロールを選択します。
[ +クロールオーバークロールの実行]をクリックすると、Oncrawlは2つの既存のクロールの違いを分析し、2つのクロールの分析結果にクロールオーバークロールレポートを追加します。
このクロールオーバークロールの進行状況は、プロジェクトホームページの[クロールオーバークロールの開始]タブで確認できます。 クロールはすでに終了しているため、オーバークロールは「クロール」状態をスキップし、「分析」から直接開始します。
結果を分析する
次の3つのビューで、クロールオーバークロールレポートに移動します。
- 構造
- コンテンツ
- 内部リンク
カスタムダッシュボードをダウンロードすることもできます。
どのメトリックを確認しますか?
クロールされたページ、ページあたりの平均単語数、平均テキスト対コード比
2つのプロファイルが同じページ数をクロールしたかどうかは、最初のインジケーター[ページがクロールされました]にすぐに表示されます。
違いが重要でない場合は、ページのインジケーターで2つ確認できます。
- 1ページあたりの平均単語数
- テキストとコードの平均比率
これらの2つのメトリックは、クライアント側でJavaScriptを実行する場合としない場合のhtmlコンテンツの違いを明らかにします。
1ページあたりの単語数が平均して少ない場合は、ページコンテンツの一部がJSレンダリングなしでは利用できないことを意味します。
同様に、テキストと比率の比率が低い場合は、JSレンダリングなしでは一部のページコンテンツを利用できないことを意味します。
テキストとコードの比率は、ページのコンテンツの表示量(テキスト)とエンコードされたコンテンツの量(コード)を測定します。 報告される割合が高いほど、コードの量と比較してページに含まれるテキストが多くなります。
深さ、ランク付け、リンク
次に、より感度の高い内部メッシュに関連するメトリックを確認できます。 ページコンテンツのごく一部がJSレンダリングなしでは利用できないということは、SEOにとって必ずしも問題ではありませんが、それが内部メッシュに影響を与える場合は、サイトのクロール可能性とクロール予算への影響がより重要になります。
平均深度、平均インランク、平均インリンク数、および内部アウトリンクを比較します。
平均深度の増加、平均インランクの減少、およびインリンクとアウトリンクの平均数の減少は、サーバー側で事前にレンダリングされていないJSで管理されているメッシュブロックの存在を示しています。 その結果、一部のリンクはGoogleボットですぐに利用できなくなります。
これは、サイトの全部または一部に影響を与える可能性があります。 次に、ページのグループごとにこれらの変更を調べて、一部のタイプのページがこのjavascriptメッシュによって不利になるかどうかを特定する必要があります。
データエクスプローラーを使用すると、フィルターを操作してこれらの要素を強調表示できます。
データエクスプローラーとURLの詳細をさらに進めます
データエクスプローラーで
データエクスプローラーでクロールオーバークロールデータを見ると、URLの2つの列が表示されます。1つはクロール1のURL用で、もう1つはクロール2のURL用です。
次に、上記の各指標(クロールされたページ、単語数、テキストとコードの比率、深度、ランク付け、リンクなし)をそれぞれ2回追加して、クロール1とクロール2の値を並べて表示できます。
フィルタを使用することで、最も大きな違いがあるURLを特定できます。
URLの詳細
SSRおよび/または事前レンダリングバージョンとクライアント側レンダリングバージョンの違いを特定した場合は、どのJS要素がSEOに最適化されていないかを理解するために、より詳細に調べる必要があります。
データエクスプローラーのページをクリックすると、URLの詳細に切り替わり、[ソースの表示]タブをクリックして、Oncrawに表示されるソースコードを表示できます。
次に、[HTMLソースのコピー]をクリックしてHTMLコードを取得できます。
左上で、あるクロールから別のクロールに切り替えて、コードの他のバージョンを取得できます。
HTMLコード比較ツールを使用すると、クライアント側でJSを実行した場合と実行しない場合の2つのバージョンのページを比較できます。 残りはあなた次第です!