
内部リンク:リンクする最も重要なページを決定する方法は?
公開: 2021-05-03外部リンク(バックリンク)がSEOを改善するためによく言及される改善領域の1つである場合、内部リンクは見過ごされがちですが、重要でもあります。 実際、優れた内部リンク構造は、非常に競争の激しいセクターですべての違いを生む可能性があります。
小さなサイトの場合、最初にリンクする最も重要なページを定義するのが比較的簡単な作業である場合、数千または数百万のページがあるサイトはどうでしょうか。
今日の記事では、優先ページを決定するためにプロジェクトに適用できる方法論について説明します。
キーワードのNグラム分析
まず、当社の製品またはサービスを検索するために最も頻繁に使用されるキーワードを理解する必要があります。 Google検索コンソールのレポートを開いたことがあれば、多くのキーワード構造が存在する可能性があることに気付くでしょう。 たとえば、2つの異なる都市間のフライトを購入する場合、リヨンとバルセロナを考えてみましょう。検索は次のようになります。
- フライトリヨンバルセロナ
- フライトリヨンバルセロナ
- 格安航空券リヨンバルセロナ
- 等。
このような複数のキーワード構造を持つことは、旅行業界に固有のものではなく、おそらくあなた自身の業界でも同様の状況にあります。
ただし、分析を正しく実行するには、どの構造が最も使用されているかを知ることが不可欠です。 どうすればこれを行うことができますか? 独自のGoogle検索コンソールデータのn-gram分析(キーワードとして使用されるN語のシーケンス)を実行するだけです。
これを行う方法を説明する前に、1つのことを明確にしましょう。残念ながら、Google検索コンソールのデータは完全ではありません。
[ケーススタディ]ビジネス指向のSEOがトラフィックとコンバージョンをどのように増加させるか
 ケーススタディを読む
ケーススタディを読む制限事項
分析を開始する前に、「クエリ」ディメンションを含めたときにツールによって表示される指標は、たとえば、「ページ」ディメンション。
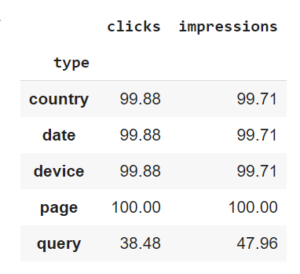
言い換えれば、ツールは次元サンプリングの影響を受けます。 これは、Google Search Consoleによって返されるメトリックが、分析対象(クエリ、ページなど)によって異なることを意味します。 また、APIを使用して、つまり、最大1000の要素しか分析できない、誰もが使い慣れているインターフェイスを介してではなく、利用可能なすべてのデータを操作することによって、このデータを取得したことも指摘しておく必要があります。
Pythonを使用している場合は、公式のGoogleドキュメントを読むことができます。さらに、このライブラリを使用すると、時間を大幅に節約できます。 普段は自分で使っています。
そうは言っても、Google Search Consoleは、最もよく知られているものだけを挙げれば、SEMrush、SEObserver、Ahrefs、Sistrixなどの他のサードパーティツールよりもさらに網羅的です。
n-gramを取得するための方法論
n-gramを取得するには、次の手順に従う必要があります。
Google検索コンソールのデータをダウンロードする
単一の業種のデータをダウンロードすることが重要です。 サイトのフライトセクションとトレインセクションのn-gramはおそらく異なるため、データを混合すると、最も検索された業種にのみ有効なn-gramが得られる可能性があります。
サイトが新しい場合、または最初のページにほとんど表示されない場合は、追加のデータソースを使用することをお勧めします。
変数を削除する
場合によっては、これらのキーワードの一部の要素を削除する必要があります。 たとえば、私のリストに4つのキーワードしか含まれていないとします。
- フライトパリローマ
- 格安航空券パリローマ
- フライトリヨンバルセロナ
- 格安航空券リヨンバルセロナ
変数を含む構造体の形式でn-gramを取得したいと思います。 ここでは、たとえば、都市なしで、フライト{{origin}}{{destination}}と格安フライト{{origin}}{{destination}}のみを保持したいと思います。 あなたの場合、あなたはあなたの製品の名前、サイズなどを取り替えなければならないかもしれません…それはあなたの業界に依存します。
n-gramを計算し、検索ボリュームを取得します
好みのシステムを使用できます。私の場合、Pythonを使用します。これは、シンプルであり、通常のコンピューターにあるデータ量を(クラッシュすることなく)処理できるという利点があります。
#importライブラリ コレクションをインポートする nltkをインポートする numpyをnpとしてインポートします パンダをpdとしてインポートします #一意のキーワードのリストを作成する list_of_keywords = report ['query']。tolist() #これらのキーワードに含まれる単語のリストを作成する list_of_words_in_keywords = [x.split( "")for x in list_of_keywords] #最も一般的なものを数える counts = collections.Counter() list_of_words_in_keywordsのフレーズの場合: counts.update(nltk.ngrams(phrase、1)) counts.update(nltk.ngrams(phrase、2))
Oncrawlのネイティブ機能を使用して、コンテンツを分析し、Google検索コンソールに(まだ)表示されないいくつかのn-gramを検出することもできます。
次に、以下のようなテーブルを取得するために、これらの各構造の検索ボリュームを取得する必要があります。 この表は、最も一般的な構造を示しています。つまり、業種のインプレッション数が最も多い構造です。
| クエリ | カウント | 印象 |
|---|---|---|
| フライト{出発地}{目的地} | 50 | 167000 |
| 格安航空券{出発地}{目的地} | 676 | 30000 |
| チケット{出発地}{目的地} | 300 | 97000 |
この段階に到達するための良い仕事。 この情報を何に使用するのか知りたいと言えます。 答えは次の部分にあります
[ケーススタディ]ビジネス指向のSEOがトラフィックとコンバージョンをどのように増加させるか
ケーススタディを読む
検索ボリュームの抽出
私たちの目標は、最初にリンクする最も重要なページを定義することであることを忘れないでください。
どのページが最も潜在的なトラフィックを持っているかを理解するために、ページごとに、さまざまな最も一般的なキーワード構造の検索ボリュームを取得する必要があります。 ここでは、検索ボリュームのみを考慮します。 クリック率の概念は後で来るでしょう!
前のステップが何のためにあったのか理解し始めていますか? 効率を上げるには、APIの使用が必須です。 多くのソリューションが存在し、そのほとんどは有料ソリューションです。 DataForSEOを使用する場合、350,000キーワードのボリュームを取得するには、40ユーロ未満の費用がかかるため、多額の投資についても話していません。
このステップの最後に、URLごとの潜在的なボリュームを含むファイルが作成されます。 これは、前のステップで計算された最も一般的なn-gramのボリュームの合計です。
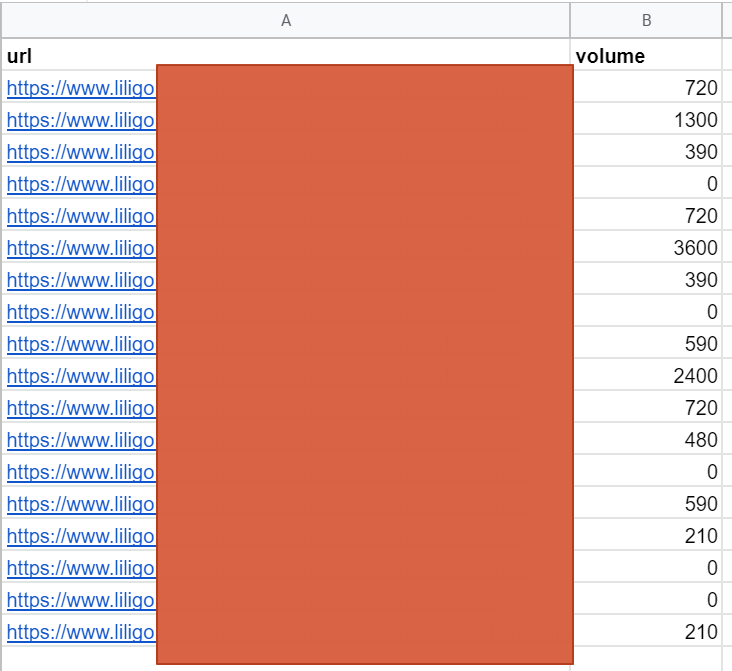
データのマージ
この段階では、明らかにこのデータを使用して、サイトの最も重要なページに優先順位を付けることはできません。 なぜだめですか?
ボリュームとトラフィックを混同しないようにしましょう!
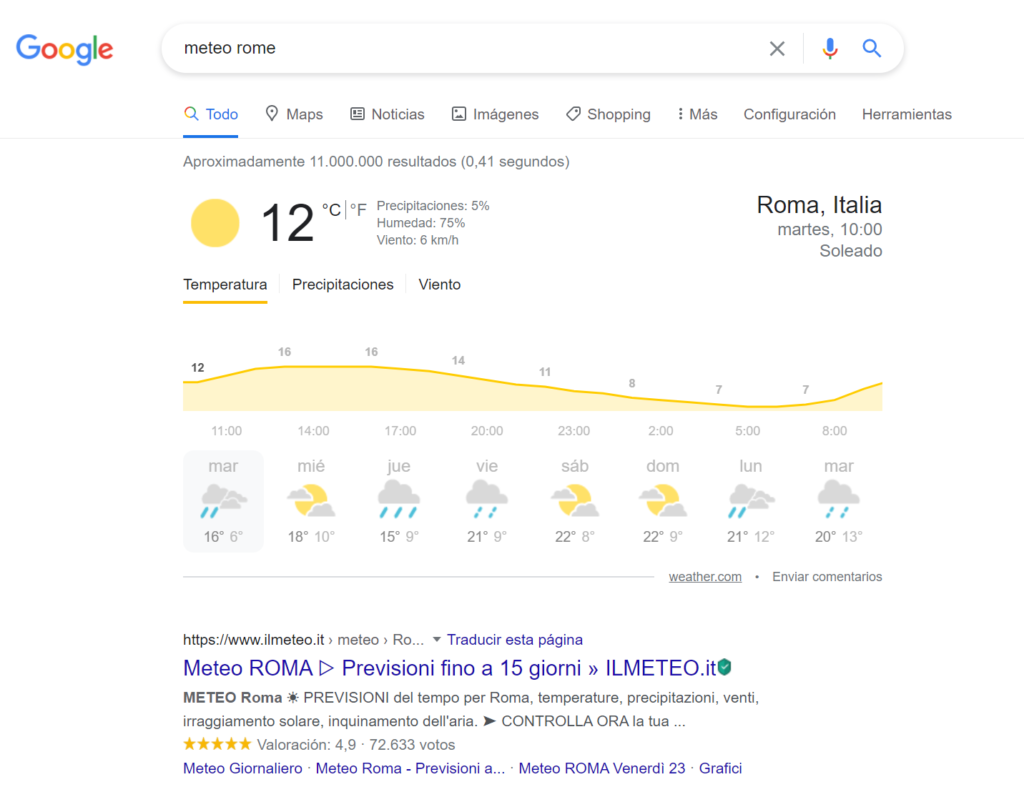
場合によっては、最初の位置にいても、クリック率が低いことがあります。 これは多くの場合、ページの上にGoogleが表示する広告とSERP機能の数が原因です。 これは、ユーザーが最初のオーガニック検索結果に到達するずっと前に、最初のGoogle要素がユーザーの注意を強く引き付ける天気クエリの例です。
nグラムの制限
ロングテールキーワードの重要性は、セクターによって異なります。 最初のステップでは保持されなかった(またはGoogle検索コンソールによって隠された)構造は、それでも可能性の興味深い部分を表す可能性があります。 したがって、それらを含める必要があります。
各ページの重要性
SEOの専門家としての私たちの目標は、トラフィックを生成することではなく、検索エンジンを介して売上を生成することです。 したがって、可能であれば、営業部門からのデータを使用してこの分析を完了することが重要です。 たとえば、販売マージンに関するデータは、優先するURLを決定するのに役立ちます。
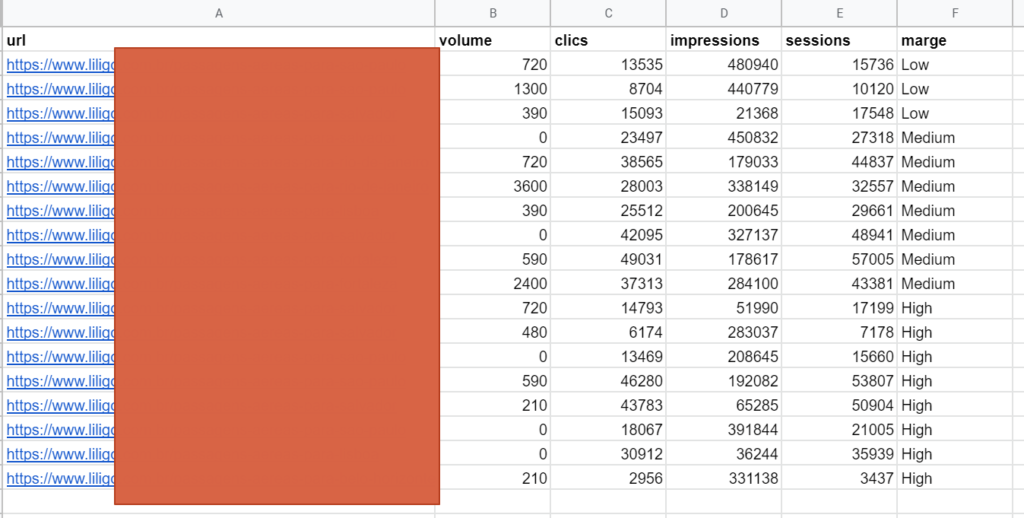
前のステップの最後から表を取り、測定に役立つ可能性のある他のデータを追加してみましょう。
- 潜在的な露出(ボリューム/インプレッション)
- 実際のトラフィック(セッション/クリック)
- 収益(コンバージョン率/マージン/収益)
このテーブルを表示する方法の例を次に示します。
データの重み付け
潜在的な露出、潜在的なトラフィック、および収益に従って各コンテンツを分類するには、これらの各要素にどの程度の重みを付けるかを決定する必要があります。
標準のパーセンテージを提案することはできません。 あなた自身の状況に合うパーセンテージを定義するのはあなた次第です。
標準化
各ページの重要性はまだ定義できていないことに注意してください。 以前に取得したデータを重み付けして取得した結果は、まだ有効ではありません。
説明:定義上、インプレッションはクリック数やセッション数よりも高くなります。 これは、CTRが低い業界で特に当てはまります。 データを事前に処理しないと、インプレッションを過大評価(およびセッションを過小評価)するリスクがあります。
この問題をどのように解決しますか? データを標準化することで! このプロセスにより、数値変数のサイズを変更して、共通のスケール(ソース)で比較できるようにすることができます。 数学的操作により、定量的データ分布の平均値は0、標準偏差は1になります。
興味のある方は、数式は次のとおりです。
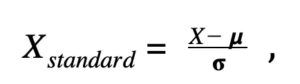
X_standard=標準化された値
X=初期値
μ=分布の平均(平均)
σ=分布の標準偏差
この式をデータに適用するのは非常に簡単です。
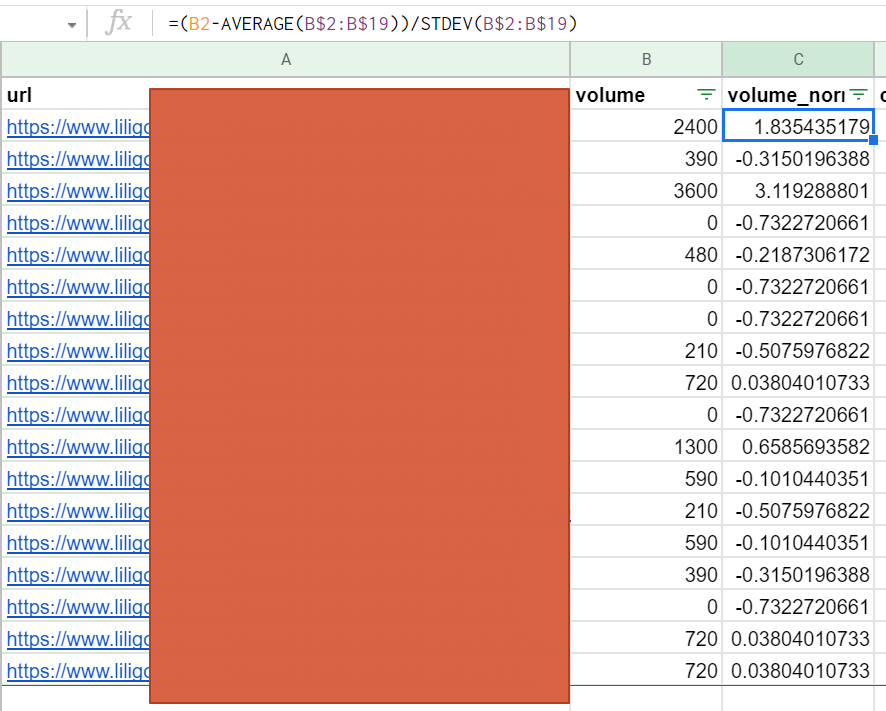
この式を、計算で検討するすべてのデータに適用します。 これにより、メトリックのオーバーウェイトの問題が確実に解消されます。
スコアの計算
重みを定義し、標準化された値を計算したら、各URLにスコアを割り当てて、その重要性を判断できます。 この例では、4つのメトリックがあり、それぞれが25%で均等に重み付けされていますが、他の数値を使用することもできます。
したがって、この方法では、客観的に最適なURLを最初に配置できます。つまり、検索ボリュームは少なくなりますが、インプレッション数は多くなり、とりわけCTRは印象的です。
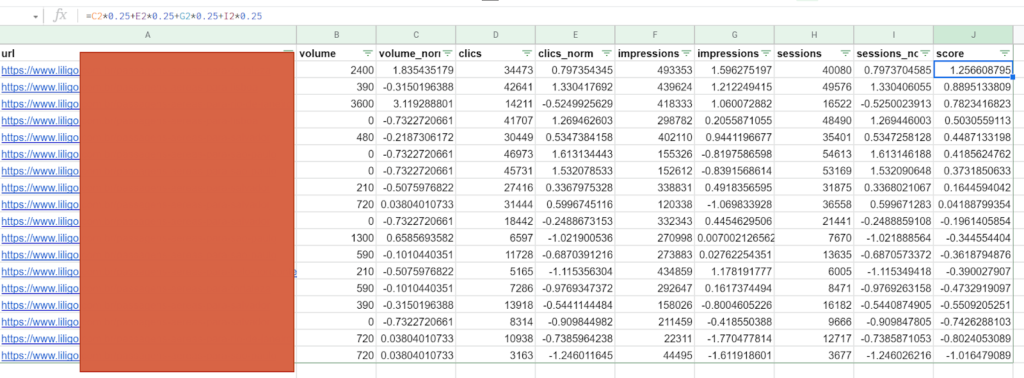
この情報を使用すると、検索ボリュームなどの単一の基準に基づく場合よりもはるかに包括的で関連性の高い方法で内部リンク構造を定義できます。 リンクするのはあなた次第です:
- ホームページから:最も重要なページ
- カテゴリから:問題のカテゴリの最も重要なページ
- 等々。
結論
n-gram方法論は効率的であり、多くのプロジェクトに適用できるという利点があります。 業界で最も重要なデータを使用して、それを適応させる必要があります。 一部の人にとっては新しいかもしれない数学的概念(標準化)を使用しているにもかかわらず、自由に使用できるツールを使用して説明し、実践することも簡単です。
それはあなたのページの可能性と結果に基づいてあなたの内部メッシュを構築するために必要な情報をあなたに提供します。 大規模なサイトでは取得が複雑な場合があるタスク。
あなたがしなければならないのはそれを適用することだけです!