
話題の権威の重要性:セマンティックSEOのケーススタディ
公開: 2021-02-11トピックオーソリティとセマンティックSEOは、今後数年間で構造化検索エンジンの概念とより頻繁に議論されるでしょう。 この記事では、これらの手法を使用して、Interingilizce.comで月間オーガニックトラフィックをわずか5か月で10,000から200,000以上に増やす方法について説明します。
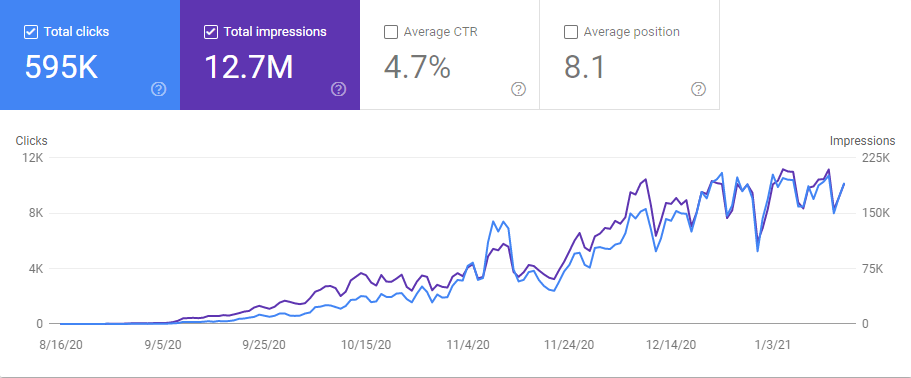
過去5か月。 GetWordly.comのグラフィック。 プロジェクトは6か月前に開始されました。
このSEOのケーススタディを読むと、少し異常なことがあるので、奇妙に思えるかもしれません。 したがって、セマンティックSEOのあまり馴染みのない概念を強調する必要があります。
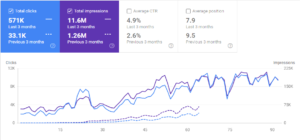
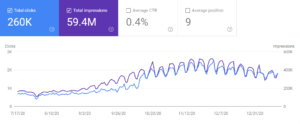
GetWordly.comのGSCオーガニックトラフィックパフォーマンスレポートの過去3か月と最初の3か月の比較。
セマンティックSEOのケーススタディとプロジェクトの背景
このSEOのケーススタディでは、次の方法はいずれも使用されておらず、以下の重要な目に見えるSEO要素はすべてプロジェクトから意図的に除外されています。
- ページスピードの最適化
- ブランド力とブランディング
- テクニカルSEO(そうです:私はそれを使用しませんでした。)
- 高品質のWebページのレイアウトとデザイン
- 健全なサーバー
- OnPage SEO
要約すると、私たちが通常言うことは、このWebサイトでは実行されなかった通常のSEOケーススタディでの優れた実践です。 したがって、私が成功したのはまぐれだと思われるかもしれません。 しかし、あなたは間違っているでしょう。同じ方法論で、私は過去5か月間に4つの別々のSEOケーススタディとサクセスストーリーを作成しました。
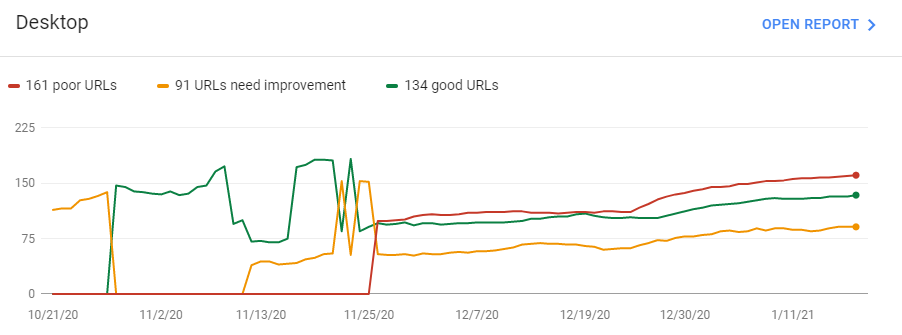
例として、「デスクトップに貧弱なURLがたくさんありました」。
この記事は私の方法論のエグゼクティブサマリーであり、セマンティックSEOのマニフェストと自由な分析的思考によるSEO理論の真の価値です。
これは、次のような関連するトピックや経験をカバーしないことにしたことを意味します。
- Googleのマイナーアップデート
- 注目のスニペットをすべて1日で失った理由
- 過剰なトラフィックによってサーバーがどのように崩壊したか
- 検索エンジンのアルゴリズムに対するサーバー障害の影響。
それを念頭に置いて、方法論を紹介しましょう。
4つの異なるSEOプロジェクト、同じ方法論、セマンティックSEOでの同じ成功
この記事では、簡単なセマンティックSEOエグゼクティブサマリーを使用してInteringilizce.comに焦点を当てます。 しかし、あなたが抱くかもしれない質問を減らし、 「SEO理論とGoogle特許」が具体的で実用的な価値を持っていることを保証するために(ビル・スラフスキーのおかげで)、4つの異なるSEOプロジェクトの旅をそれらの結果だけで要約したいと思います。
これらのSEOのケーススタディとプロジェクトに関するすべての重いSEO用語、理論、特許、および実用的な詳細を読みたい場合は、SEOのトピック権限、カバレッジ、およびコンテキスト階層の記事を読むことをお勧めします。 (長いもので、14,000語以上あります。)
「私たちは、新しいプロジェクトで迅速な効果を発揮して、短期間での成功を目指していました。 そして、新しいプロジェクトで目標を上回りました。」
Rustem Ersoyleyen
KonusarakOgren、マーケティング責任者
最初のプロジェクト:5か月で1100%のオーガニックトラフィックの増加、Interingilizce.com
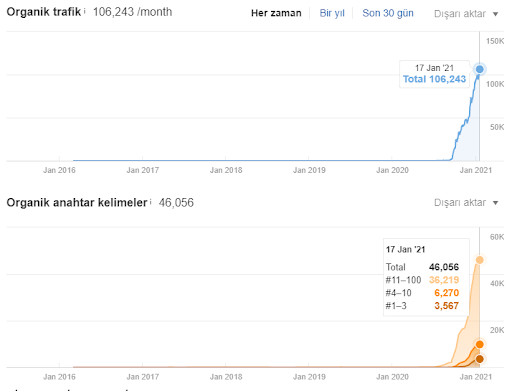
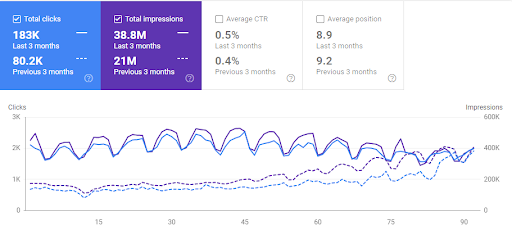
Interingilizce.comは実際には2年前のものですが、Webサイトのコンテンツもオーガニックトラフィックもありませんでした。 組織を増やしました。 145日間で1100%のトラフィック。 10,000〜200,000クリック。 イントロセクションで「過去6か月のオーガニックトラフィック」の結果をすでに確認しているので、以下の「2020年5月」と「2020年11月」の比較を確認できます。
実際には、1100%のオーガニックトラフィックの増加だけではありませんが、この種の増加に「%」記号を使用して、何か具体的なことを想像させることはできません。
以下に、Interingilizce.comの過去3か月間のオーガニックトラフィックの比較グラフィックを示します。
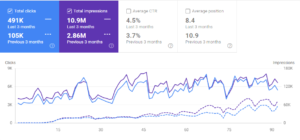
そして、Interingilizce.comの過去6か月のオーガニックトラフィックグラフィック。
GetWordly.comのGSCレポートと混同するかもしれませんが、それらは異なります。 私は同じ方法論を使用しているので、Googleのアルゴリズムと更新に対して同じ反射神経を持っていました。
2番目のプロジェクト:月間オーガニックトラフィックが0〜330,000、1日あたりのクリック数が10,000以上:GetWordly.com
GetWordly.comは2番目のサイトであり、このWebサイトは有機的な可視性と履歴の点で純粋でした。 GetWordly.comでは、わずか6か月で1日あたり11,000回のオーガニッククリック、1か月あたり330,000回のオーガニッククリックのレベルに達しました。
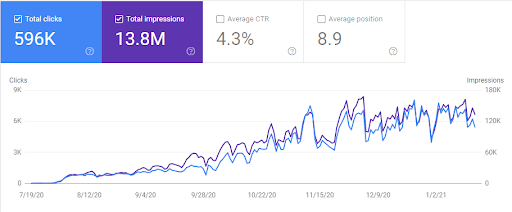
以下のGoogle検索コンソールからGetWordly.comの過去6か月のオーガニックトラフィックのグラフィックが表示されます。
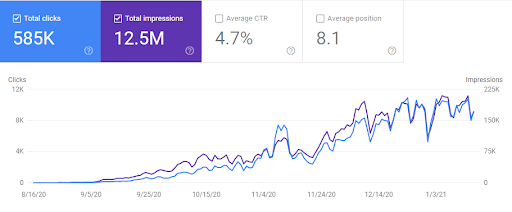
以下に、GetWordly.comのAhrefsグラフィックを示します。
そして、以下に、GetWordly.comのSEMRushグラフィックが表示されます。
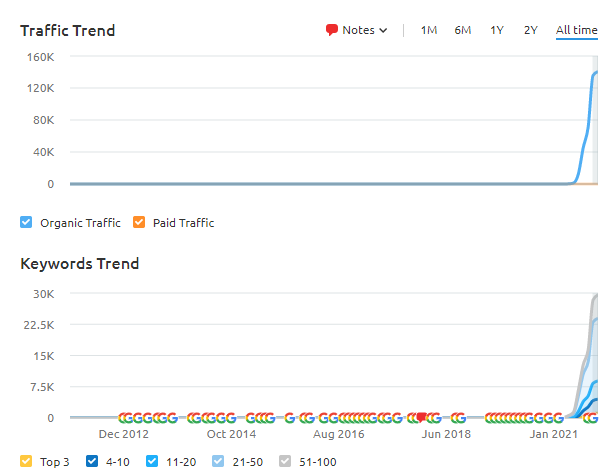
3番目のプロジェクト:5か月で600%のオーガニックトラフィックの増加:アゼルバイジャンに焦点を当てる
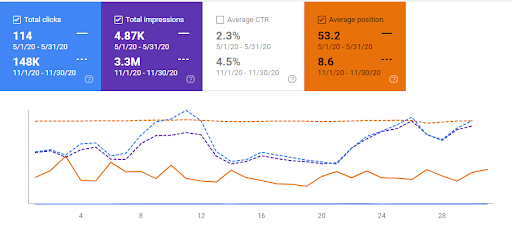
3番目のWebサイト(名前はまだ公開されていません)では、600%の成長が達成されました。 5か月以内に、月間オーガニックトラフィックは10,000から70,000に増加しました。 (3番目のWebサイトはアゼルバイジャンのみを対象としているため、トラフィック量は前の例よりも少なくなっています。)
以下に、3番目のサイトのGSCグラフィックの過去6か月のグラフィックを示します。
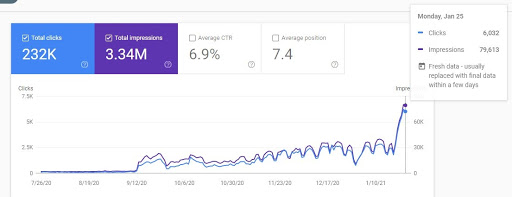
そして、以下に「辞書セクション」の最後の7か月が表示されます。
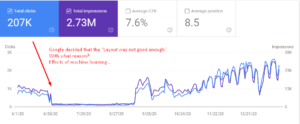
Webサイトの「辞書セクション」が「1日で」すべてのトラフィックを失ったことがわかります。 何も変更していません。 すべての違いは、Google独自の内部システムにありました。 Googleは「ディープラーニング」と「機械学習」に完全に依存し始めたので、ウェブから収集した「一般的なフィードバック」に従って「ページレイアウト」も評価していることを私は知っています。
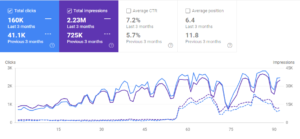
3番目のプロジェクトの過去3か月の比較。
したがって、「背景色の変更」と「ページ要素の順序」だけでページのレイアウトを変更しただけで、2日ですべてが通常の状態に戻りました。
このSEOのケーススタディと実験のこの部分は、セマンティックSEOに関するものではありませんが、ホリスティックSEOとして、「異なるもの」に焦点を当てる必要がある場合があると言いたかっただけです。 以下に、GooglePatentsの「WebsiteRepresentationVectors」を示します。
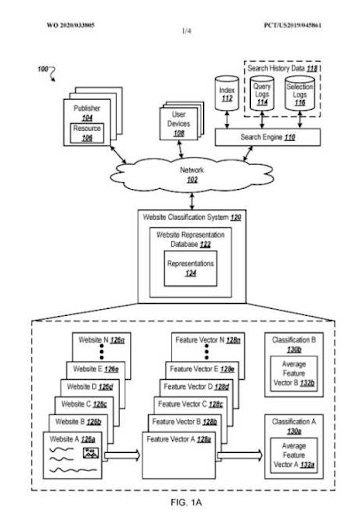
ウェブサイト表現ベクトルは、検索エンジンによるクリック後の「ユーザー満足度の可能性」を理解するために使用できます。
4番目のプロジェクト:400%のオーガニックトラフィックの増加–アラビア諸国に焦点を当てた
4番目のWebサイト(名前はまだ公開されていません)は、アラブ世界全体を対象としています。 私の主な焦点はウェブサイトになかったので(私はアラビア語を話さないので)、400%の成長しか達成されませんでした。
以下に、4番目のサイトのGSCグラフィックの過去6か月のグラフィックを示します。
私の意見では、このWebサイトでは、セマンティックSEOの力によるトラフィックの増加は十分ではありませんでした。 それはアラビア語のスキルが不足しているためです。 テクニカルSEOは「言語に依存しない」のに対し、セマンティックSEOは単語、用語、概念、言語の性質に大きく依存しています。
セマンティックSEOの最終的な証拠として、4番目のプロジェクトの3か月のGSCオーガニックトラフィックパフォーマンスの比較が表示されます。
セマンティックWeb、セマンティック検索、およびトピック権限の簡単な説明
セマンティックWebは、Web上の情報組織の状態です。 セマンティックWebは、人間の脳と宇宙の性質に由来する2つの基本要素、分類法とオントロジーを使用します。
分類法は、「タクシー」+「ノミア」から来ています。これは「物事の配置」を意味します。 オントロジーは「ont」から来ています+「logy」は「物事の本質」を意味します。 どちらも、エンティティをグループとカテゴリに分類して定義する手段です。 一緒に、分類法とオントロジーはセマンティックWebを構成します。
過去10年間、GoogleはセマンティックWebに向けたいくつかのイニシアチブを作成してきました。
2011年、Googleはウェブ上の情報を構造化するための「構造化検索エンジン」を発表しました。
そして、2012年5月に、実際のエンティティに関する情報をよりよく理解するためにナレッジグラフを立ち上げました。
2019年に、彼らはBERTを立ち上げました。これは、人間の言語と知覚における単語、概念、およびエンティティ間の関係をよりよく理解するためのモデルです。
これらのプロセスはすべて、セマンティックWeb、セマンティック検索、セマンティック検索エンジンとしてのGoogle、そしてその結果としてセマンティックSEOを作成しました。
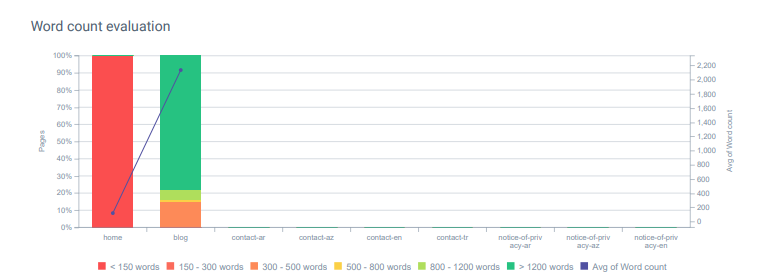
OnCrawlでのGetWordly.comの単語数の評価。 このプロジェクトのほとんどのコンテンツには、競合他社よりも多くの詳細と情報が含まれています。
この文脈において、TopicalAuthorityとTopicalCoverageは何を表していますか?
セマンティックで組織化されたWebでは、すべての情報源は、さまざまなトピックについてさまざまな程度のカバレッジを持っています。 モノやエンティティは、共有属性を介して相互に接続されています。 これらの属性は「オントロジー」を表します。 物事はまた、分類階層内で相互に接続します。 この階層は「分類法」を表します。 セマンティック検索エンジンの観点からトピックの権威となるには、ソースは、さまざまなコンテキスト内のさまざまな属性をカバーする必要があります。 また、類似したもの、および親と子のカテゴリのものを参照する必要があります。
これらのSEOケーススタディの鍵は、論理的な内部リンクとアンカーテキストを使用して、コンテキストの関連性と階層内で、すべての「サブトピック」、すべての可能な質問に対してコンテンツネットワークを作成することです。
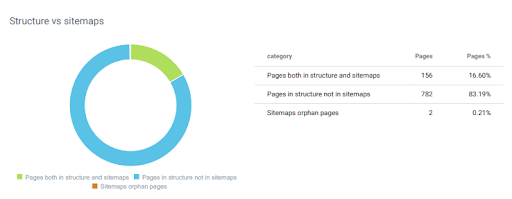
OnCrawlが言うように、このSEOのケーススタディでは、健全なサイトマップを使用しませんでした。 ここのサイトもGetWordly.comです
TopicalAuthorityとTopicalCoverageは、最も詳細で、エンティティ指向で、意味的に編成された、包括的なコンテンツネットワークで取得できます。 成功するすべてのコンテンツは、接続されたエンティティおよび関連するクエリの他のコンテンツが成功する可能性を高めます。
簡潔にするために、「すべきこと」と「すべきでないこと」のセクションに移ります。 これらのトピックの詳細や理解が必要な場合は、前述の記事を読むことをお勧めします。
セマンティックSEOを実装するにはどうすればよいですか?
セマンティックSEOの概念を完全に理解するには、検索エンジンがWebをセマンティックにする必要がある理由を理解する必要があります。 特に、ルールベースの検索エンジンランキングシステムではなく、機械学習ベースの検索エンジンランキングシステムが主流であり、自然言語処理および理解技術が使用されているため、このニーズはさらに高まっています。 したがって、以下の提案を理解するために、検索エンジンの目を通してこれらの概念にアプローチしてください。
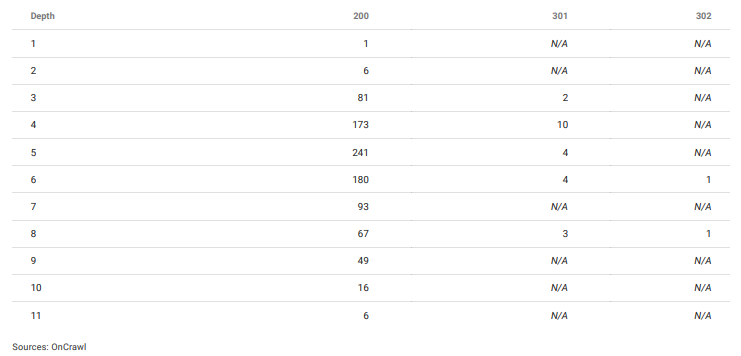
「ヘッダー」や「フッター」のメニューは一切使用していなかったので、ほとんどのページは本当に奥深いものでした。
1-最初の記事の公開を開始する前にトピックマップを作成する
オントロジーと分類法を覚えていますか? Googleの場合、辞書や百科事典とは異なる方法で物事が相互に接続される可能性があるため、Googleのナレッジグラフを確認する必要があります。 Googleは、エンジニアから提供されたWebと情報を使用して、エンティティの認識とコンテキストベクトルの計算を行います。
したがって、SERPをチェックして、どのエンティティがどのクエリにどのように接続されているかを確認する必要があります…
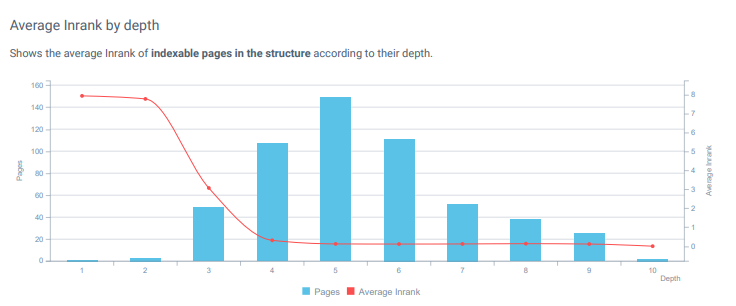
Inrankは、OnCrawlの「InternalPageRank」配布式であり、Googleの最初のオリジナルのPageRank式に触発されています。 そして、ホームページから遠く離れたページでInrankが落ちていることがわかります。
これは少し疲れるかもしれませんが、しばらくすると、Googleがどのように考え、行動し、物事を相互に結び付けるかがわかります。 トピックマップを作成するためのニッチおよびクエリグループをチェックするために実行できるいくつかのクイックプラクティスがあります。
- 競合他社のサイトマップをクロールして、トピックマップを理解します。
- Googleトレンド関連のクエリと関連トピックを取得します。
- オートコンプリートと検索候補からデータを収集します。
- 競合他社がコンテンツハブをどのように接続しているかに注目してください。
- Googleナレッジグラフを使用して、関連するエンティティをプルします。
- Web以外のリソースを使用して、エンティティのプロパティとその階層および接続を表示します。
最後の項目は、検索エンジンのナレッジベースに独自の信頼できる情報を提供するリソースになるためにも重要です。
PS:他の検索エンジンも使用してください。 特に、Swisscowsをチェックして、セマンティック検索エンジンの性質を理解することをお勧めします。 セマンティック検索を理解するためにGoogleだけに焦点を当てないでください。
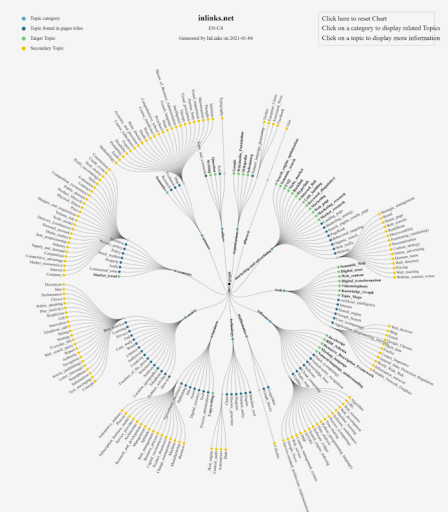
これは、Inlinks.netのトピックマップ(トピックグラフ)の例です。 これはユニークなテクノロジーであり、 InLinksはセマンティックSEOに焦点を当てた唯一のSEO企業であるため、そのテクノロジーを確認することをお勧めします。
2-ページごとのリンク数を決定します
これらすべてのSEOのケーススタディと成果において、各Webページのリンクの総数は最大15でした。
これらのリンクのほとんどはメインコンテンツにあり、関連性のある自然なアンカーテキストが含まれていました。 フッターやヘッダーメニューは使用しませんでした。 これは、技術的なSEOにおける従来の推奨事項と矛盾します。 私はそれを受け入れなければなりませんでした、そして私はあなたがウェブページごとに15以下のリンクを使うべきだと言っているのではありません。 私はあなたがメインコンテンツ内に関連性のある文脈上のリンクを維持し、検索エンジンがそれらのリンクに焦点を合わせるようにするべきだと言っています。
次の項目を使用して、Webページに表示される内部リンクの正しい数を決定できます。
- 最小値と最大値を理解するための内部リンクカウントの業界標準。
- コンテンツ内の名前付きエンティティの数
- 名前付きエンティティのコンテキストの数
- コンテンツの「粒度」レベル
- 各見出しセクションに最大1つのリンク
- 同じタイプに属するエンティティが「リスト形式」の場合は、それぞれのページにリンクします。
[ケーススタディ]ページ上のSEOで新しい市場の成長を促進する
 ケーススタディを読む
ケーススタディを読む3-カウント、単語、および位置の観点から、自然で適切な方法でアンカーテキストを決定します
内部リンクが自然である必要性と、それらがPageRankをどのように通過するかについては説明しません。 これについては、「すべてのGoogleコアアルゴリズムアップデートから勝者になる方法」ですでに詳しく説明しました。これを読むことをお勧めします。
ただし、メインコンテンツ内のWebページにアンカーテキストを3回以上使用することはありません。 つまり、4回目は、アンカーテキスト内の単語を追加するか、いくつかの単語を変更することをお勧めします。
アンカーテキストには他にもいくつかの種類のルールがあります。
- ページの最初の段落のテキストを、そのページへのリンクのアンカーテキストとして使用することはありません。
- ページ上の段落の最初の単語を、そのページへのアンカーテキストとして使用することはありません。
- ある記事を別のコンテキストまたはサイドトピックから別の記事にリンクする場合、常に最後の見出しの段落の1つを使用します(Googleではこのタイプの接続を「補足コンテンツ」と呼んでいます)。
- 私は常に競合他社のアンカーテキストで特定の記事を社内外でチェックしています。
- アンカーテキストを作成するときは、常にトピックの同義語を使用しようとします。
- ターゲットのWebページのコンテンツとリンクソースの関連する見出しテキストに「アンカーテキスト」が存在するかどうかを常に確認します。
PS:セマンティックSEOを成功させるためにこれをしなければならないと言っているのではありません。 これらは、これらの結果を得たときに私が従ったガイドラインのほんの一例です。 これらのガイドラインに準拠していない例をいくつか見つけた場合、それはおそらく私の素敵な作者のせいです。
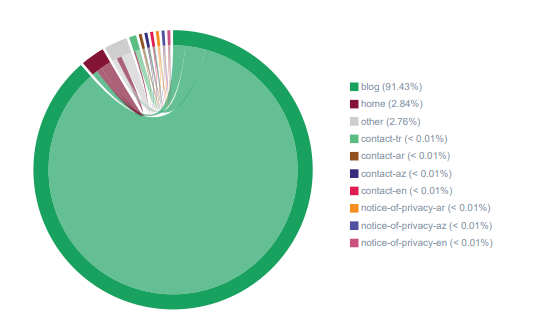
さまざまなURLカテゴリに対するOnCrawlのInrankFlowDistribution。 私はこれらのプロジェクトについて何も分類しなかったので、それはほとんど「グリーン」であり、最も重要な部分がブログであることを意味します。
4-コンテキストベクトルを決定する
この用語は、耳にとって少し「引っかき傷」になる可能性があります。 これは私にとってGooglePatentsの用語です。 文脈上のベクトル、文脈上のドメイン、文脈上のフレーズ…Google特許には掘り下げることがたくさんあります(私たちの教育者であるビル・スラフスキーに感謝します)。
簡単に言えば、コンテキストベクトルはコンテンツの角度を決定するための信号です。 トピックは「地震」であり、コンテキストは「地震の比較」、「地震の推測」、または「地震の年表」である可能性があります。
たとえば、「リンゴ」(果物)はエンティティであり、トピックでもあります。Healthlineには、「リンゴ」だけで265を超える記事があります。 リンゴの利点、リンゴの栄養、リンゴの種類、リンゴの木(基本的には別のエンティティとトピックですが、十分に近いです)。
したがって、この文脈では、これらのサイトはすべて第二言語教育業界からのものでした。 「英語学習」がメイントピックです。 ゲーム、ビデオ、映画、歌、友達から英語を学ぶことは…異なる文脈です。
よりコンテキストに沿った接続を作成するために、私は常に、さまざまなタイプのピラークラスターコンテンツの助けを借りて、さまざまなトピックとその中のエンティティ間のギャップを埋めようとしています。 また、Googleの特許からのコンテキストベクトルと知識ドメインについて読むことをお勧めします。

OnCrawlの内部リンクステータステーブル。 検索エンジンの明確な「内部リンク」ステータスコードとクロールパスはありませんでした。
5-書き込みおよび公開されるコンテンツ数を決定する
コンテンツ数はランキング要素ではありません。 実際、より包括的で信頼できる記事を使用して、より少ないコンテンツでより多くのことを伝えることは、クロール予算、PageRankの配布、被リンクの希薄化、または共食いの問題などの多くの側面に適しています。
ただし、プロセスを計画するには、コンテンツ数が重要です。 なぜなら、必要な著者の数、または1日または1週間に公開する記事の数を知る必要があるからです。 コンテンツの公開やコンテンツの更新頻度など、このエグゼクティブサマリーには多くのSEO用語を含めませんでした…しかし、トピック、コンテンツ、コンテキスト、エンティティを決定しても、必要なコンテンツの量はわかりません。 Googleは、同じページのトピックに異なるコンテキストを表示するサイトを好む場合もありますが、別の場合には、異なるページに異なるコンテキストを表示することを好む場合もあります。

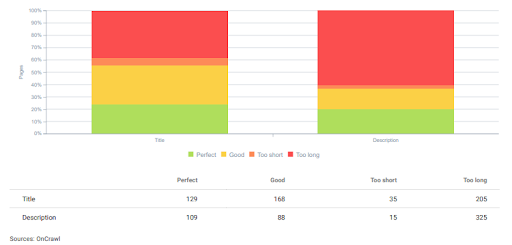
Webページの見出しレベルごとの平均見出し数は上記のとおりです。 見出しタイプごとの見出し数は、SEOのコンテンツの詳細、長さ、粒度レベルを明らかにすることができます。
コンテンツ/記事の正確な数を知るために、GoogleのSERPタイプを調べるには、競合他社のコンテンツネットワークの形が重要です。 これは、プロジェクトの予算にとっても重要です。 120個のコンテンツが必要であると顧客に伝えた後、実際には180個のコンテンツが必要であることに気付いた場合、それは信頼にとって深刻な問題です。
そして、 SEOのサクセスストーリーでは、明確なコミュニケーションが必須です。
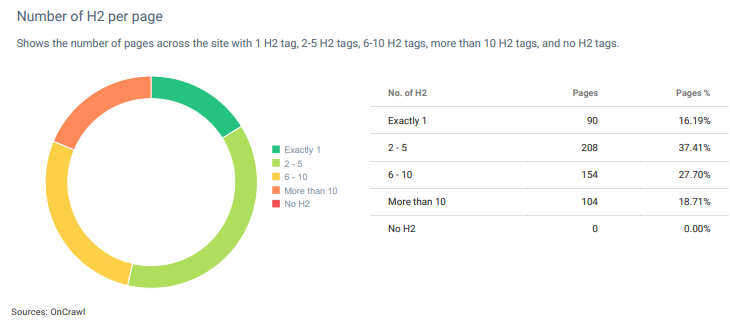
H2の数から、ソースがコンテンツ構造に「ぎこちない文」を使用していない場合、Webページの詳細レベルを理解できます。

6-URLカテゴリと階層を決定する
ここでのSEOのケーススタディでは、URLカテゴリは使用されていません。 ただし、これは、URLカテゴリと対応するブレッドクラムがセマンティックSEOに有益でないことを意味するものではありません。 URLパスの同じフォルダに同様のコンテンツを保持すると、検索エンジンがWebサイトを理解しやすくなります。 また、ユーザーにヒントを提供し、サイト内のナビゲーションを容易にします。
もしそうなら、なぜ私はそれを使わなかったのですか? 同じ2つの理由で、私は技術的なSEOを使用していません。時間の制約と、将来のSEO実験を実行したいからです。
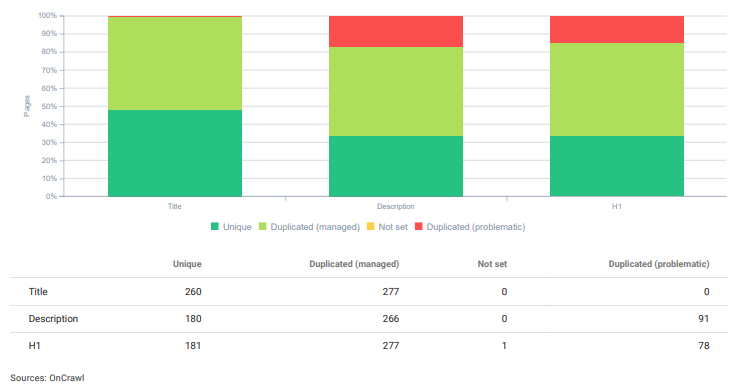
これらのSEOプロジェクトには、問題のある管理された重複がサイト全体に存在します。
7- URL階層で調整することにより、コンテキストベクトルを使用してトピック階層を作成します
サブトピックは2020年1月にGoogleによって使用されることが確認されていますが、実際には、Googleは以前にそれらを「ニューラルネット」または「ニューラルネットワーク」と呼んでいました。 Google DevelopersのYouTubeチャンネルでは、階層とロジック内でトピックがどのように相互に関連しているかについての優れた要約も示しました。 そのため、分類法とオントロジーがセマンティックSEOの鍵となります。
しかし、「コンテキストベクトルを使用してトピック階層を作成する」とはどういう意味ですか? これは、論理URL構造でグループ化することにより、すべてのトピックがすべての可能なコンテキストおよび関連エンティティで処理されている必要があることを意味します。
これにより、検索エンジンは、よりきめ細かく詳細な情報アーキテクチャのおかげで、より優れたトピックの権限と専門知識をソースに提供できるようになります。
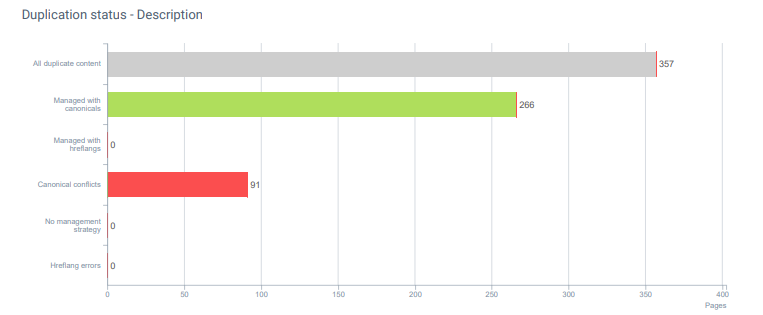
また、「正規の競合」もあります。
8-見出しベクトルを調整する
見出しベクトル…多くの耳にとって異質な別の用語。 見出しベクトルは、実際には、コンテンツの主な角度とトピックを決定するための信号としての見出しの順序です。 Google Quality Raterガイドラインによると、コンテンツは「メインコンテンツ」、「広告」、「補足コンテンツ」の3つの異なるセクションで構成されていると見なされます。
グーグルが折り目の上のコンテンツまたは記事の「上部セクション」のコンテンツをより重視していることは誰もが知っています。 そのため、コンテンツの上部のクエリは、下部のクエリよりも常にランクが高くなります。 Googleにとって、下部のセクションは実際には「補足コンテンツ」を表しています。
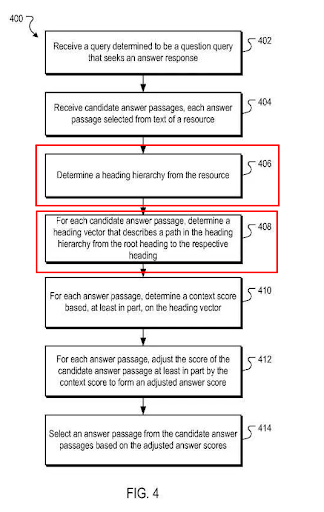
見出しベクトルを介して計算するコンテキスト回答パッセージスコアに関するGoogleの方法論の表現。
そのため、見出し階層内でコンテキストの関連性とロジックを使用することが重要です。 簡単に言えば、セマンティックSEOに関する私の視点での見出しベクトルの基本的なガイドラインは次のとおりです。
- 検索エンジンが何を言おうとも、見出しタグを含むセマンティックHTMLタグを使用します。
- 見出しベクトルはタイトルタグから始まるため、見出しとタイトルタグは互いに準拠している必要があります。
- すべての見出しは異なる情報に焦点を当てる必要があり、それらの見出しの後の段落は以前に提供された情報を繰り返さないようにする必要があります。
- 同様のアイデアに焦点を当てた見出しは、グループ化する必要があります。
- 別のエンティティを含める必要がある見出しも、それにリンクする必要があります。
- すべての見出しのコンテンツは、リスト、表、説明的な定義を含む適切な形式である必要があります…
ご覧のとおり、このセクションのすべてに実際には基本的なロジックがあります。 新しいことは何もありません。 しかし、Googleの特許の1つである「回答パッセージのコンテキストスコア調整」を以下に示します。

出典:回答パッセージのコンテキストスコア調整
見出しベクトルを使用して、Googleは、特定のクエリに最適なコンテキストベクトルを持つパッセージを選択しようとします。 そのため、これらの見出しの間に明確な論理構造を作成することをお勧めします。
必要に応じて、ビル・スラフスキーの分析的観点からこの特許を読むこともできます:コンテキストによる注目のスニペット回答の調整。
14日間の無料トライアルを開始する
 トライアルを開始する
トライアルを開始する9-コンテキスト内のトピックの関連エンティティを接続する
接続するエンティティとエンティティの関連付けは、互いに密接な関係があります。 エンティティの関連付けは、エンティティの属性に基づいて検索エンジンで実行できます。また、検索目的の可能性についてクエリをどのように表現するかによっても実行できます。
エンティティを接続し、コンテキスト内でエンティティを相互に関連付けることは、オントロジーの実用的なアプリケーションです。 たとえば、これらのSEOプロジェクトの業界である「英語学習」のコンテキストでは、「句動詞」のトピックに、「不規則動詞」、「最もよく使用される動詞」、「弁護士に役立つ動詞」を使用することもできます。 」、「ラテン語起源の動詞の語源」、「あまり知られていない動詞」は、互いに接続することができます。
SEO関連のHTMLタグは、長さとタグ内の用語の観点から最適化する必要があります。 ご覧のとおり、これらのプロジェクトでは、これらを実装しませんでした。
これらの文脈はすべて、実際には「英語の動詞」に焦点を当てています。 これらはすべて、「文法規則」、「文の例」、「発音」、「時制の違い」に関連しています。 これらすべてのコンテキストとエンティティを相互に詳細化、構造化、分類、および接続できます。
基本的にトピックとすべての関連エンティティのすべての可能なコンテキストをカバーした後、セマンティック検索エンジンには、これらの可能な検索インテントの信頼できるソースとしてあなたを選択する以外に、他のチャンスはありません。
10-考えられる検索インテントの質問と回答を生成する
「回答から質問を生成する」…もう1つのGoogle特許。 ただし、この記事はすでに十分に長いので、詳しくは説明しません。 基本的に、検索エンジンはWeb上のコンテンツから質問を生成し、これらの質問をクエリの書き換えを伴うクエリと照合します。 そして、これらの質問を使用して、Web上で考えられる検索インテントの考えられるコンテンツのギャップを埋めます。
そのため、すべてのエンティティを相互に接続しながら、すべてのコンテキストですべてのエンティティを処理するように指示します。 ただし、情報抽出とは何かも知っておく必要があります。 情報抽出とは、ドキュメントから概念に関する重要な事実と決定的なつながりを引き出すことです。 情報抽出のおかげで、検索エンジンは、ドキュメントからどの質問に答えることができるか、またはどの事実を理解できるかを理解できます。 情報抽出は、エンティティとその属性の間の知識グラフを作成するために使用することもでき、関連する質問を生成するために使用することもできます。

検索クエリに関連する質問を生成する
SEARCH VOLUMEだけに注目するべきではありません! これまで誰もこの質問をしたことがないかもしれません。 そして、検索エンジンでさえ、この質問に対する答えを知らないかもしれません。 ただし、この一意の情報がトピック内のエンティティの属性を定義するのに役立つ場合は、これらの質問を生成して回答し、Webおよびニッチの検索エンジンの一意の情報源になります。
11-キーワードギャップの代わりに情報ギャップを見つける
まず、以下の引用を読んでください。
「特定のドキュメントの情報獲得スコアは、ユーザーが以前に表示したドキュメントに含まれる情報以外に、ドキュメントに含まれる追加情報を示します。」

出典:特許「リンク情報ゲインのコンテキスト推定」
2020年という最近でも、「毎日のクエリの15%は新規であり、GoogleはRankBrainを使用して、これらのクエリを可能な検索インテントや新しいドキュメントと照合します」。 また、Googleは常に固有の情報を検索し、ユーザーからの将来のクエリの可能性について回答します。 独自の情報を提供し、あまり知られていない「用語、関連情報、質問、研究、人、場所、イベント、提案」を含めるようにしてください。
したがって、「より長いコンテンツ」または「キーワード」は、これらのSEOケーススタディの鍵ではありません。 「詳細情報」と「独自の質問」と「独自のつながり」が鍵となります。 これらのプロジェクトのすべてのコンテンツには、検索ボリュームとは関係のない固有の見出しがあり、ユーザーでさえそれらに気付かない可能性があります。
以下に、拡張クエリと関連する可能性のある検索アクティビティのコンテキスト関連性を示す別のGoogle特許を示します。
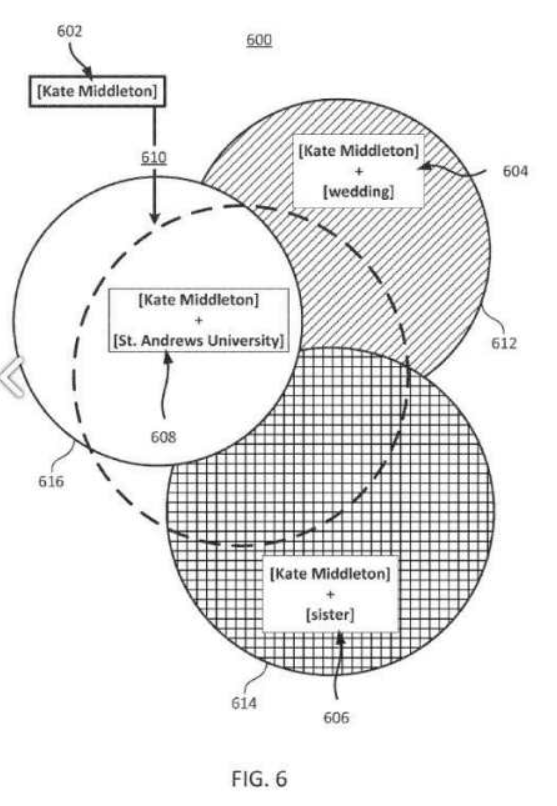
知識グラフ情報を使用した拡張検索クエリ
「コアを説明しながら、関連するすべてのエンティティをコンテキスト接続とともに含める」ことは、その重要性とともにここでも見ることができます。
12-キーワードの量や難易度を気にするのをやめる
キーワードの量については、すでに意見を述べています。 これらの4つのプロジェクトの間、私は主に、質が高く理解しやすい「教育書」を作成していると思っていました。
- プロジェクトの開始時に、大量の被リンクを持つ権威ある競合他社は私を脅迫しませんでした。
- キーワードの難易度など、サードパーティの指標は気にしませんでした。
- 競合他社の過去のデータとブランド力は私を怖がらせませんでした。
- そして最後に、「GoogleSearchConsoleを使用してクライアントにプロジェクトの最新の状況を表示する」ことに頼るのを避けました。 グーグルの反応をレビューすることを除いて、私はGSCに入りませんでした。
記事を書くときに、トピックのセマンティック構造にサブトピックが必要な場合は、それを書く必要があります。 検索ボリュームが「0」の場合でも書き込む必要があります。 キーワード難易度が100の場合でも書く必要があります。
ここにもう一つ重要なポイントがあります。
「フレーズ」のSERPで最初にランク付けする場合は、関連するすべてのフレーズと、関連するすべてのトピックグラフのすべての詳細を含める必要があります。 言い換えれば、セマンティックSEOでは、関連する各トピックを完全に処理せずに、そのトピックに関連するクエリのランキングの増加を確認することはできません。
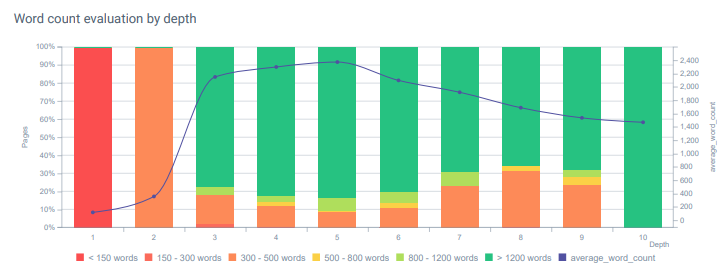
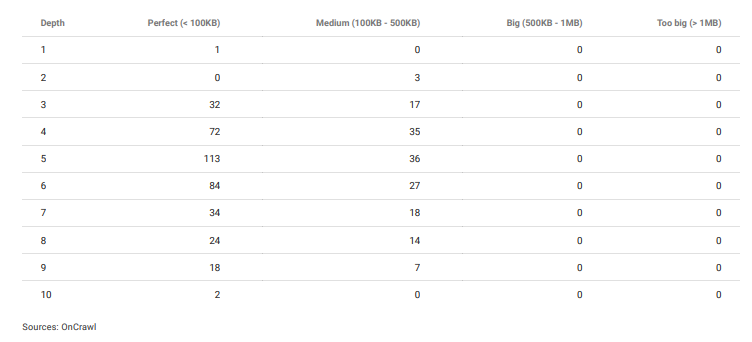
ページの深さによる単語数の評価。 この例では、標準の内部ナビゲーションを使用していないため、コンテンツが古くなるほどページのクリック深度が増加します。 しかし、10番目の深さでも、競合他社よりも強力なコンテンツがあります。 これにより、Googleはさらに深く調べるようになります。
13-履歴データを使用してトピックの範囲と権限に焦点を当てる
トピックグラフは、どのトピックがどの接続内で相互に接続されているかを示すグラフです。 トピックカバレッジとは、このグラフをどれだけうまくカバーするかを意味します。 履歴データとは、このトピックグラフを特定のレベルでカバーしている期間を指します。
トピックの権限=トピックの範囲*履歴データ
そのため、私が紹介するすべてのグラフィックで、一定の時間が経過すると「急速な成長」が見られます。 そして、私は自然言語処理と理解を使用しているので、波形を伴うこの初期の急速な有機トラフィックの増加のほとんどは、注目のスニペットから来ています。
トピックの注目のスニペットを取得できる場合、それは、検索エンジンのわかりやすいコンテンツ構造を備えた信頼できるソースになり始めたことを意味します。
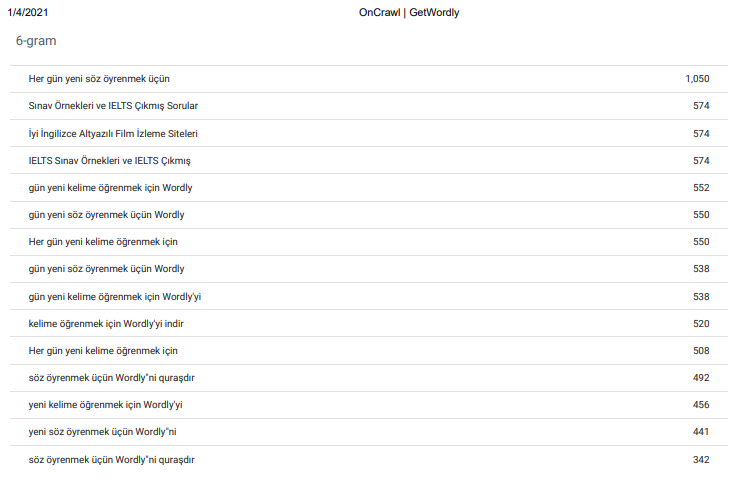
N-Gram Analysisは、私にとってOnCrawlの最高の機能の1つです。 そしてそれはSEOクローラーのユニークな機能です。 上記の「サイト全体としての6グラム分析」をご覧ください。 「英語を学び、教える」(Ingilizce Ogrenmek ve Ogretmek)は、このエンティティの主要なテーマです。
14-作成者と自然言語処理用語を使用して、可能な限り最良の文の構造とコンテンツ形式を決定します
著者を教育します。
GoogleがNLPとNLUをどのように使用しているかを示します。 「品詞タグ」とは何か、「名前付きエンティティの認識」と「名前付きエンティティのリンク」とは何かを教えてください。 N-Grams、Skip-Grams、Word2Vecを具体的な結果と実践とともに使用して、マシンで実行されるテキスト分析を理解できるようにします。 Googleナレッジグラフがどのように機能するかを示します。
ニューラルマッチングまたはエンティティタイプマッチングとは何かを教えてください。 コンテンツを修正しながらGoogleドキュメントに対する間違いを示してから、注目のスニペットを使用してオーガニックトラフィックの増加を示します。
私はこれを「注目のスニペット指向のコンテンツマーケティング」と呼ぶことがあります。 GoogleはNLPモデルを使用してコンテンツを理解し、正直に言うと、GoogleのNLPベースのアルゴリズムのおかげで、最も権威のある競合他社を打ち負かすのは2011年よりも簡単です。
そして、このセマンティックSEOマニフェストの冒頭で述べたように、私は1日ですべての注目のスニペットを失いました。 これは、Googleがマイナーアップデートを実行して、注目のスニペットの割合を1日で4%減少させたときに発生しました。 同時に、過剰なトラフィックのためにサーバーがダウンしています。 さらに、「再ランク付けの需要」を生み出すために、新しいコンテンツを公開し続けながら、多くのコンテンツを更新しました。
コンテンツが意見ベースか事実ベースかをGoogleがどのように理解しようとするか。 特許名:文書内の意見を識別するための機械学習。
以下に、私の作者のための私のルールのいくつかを見つけることができます:
- 記事であなたの意見を決して与えないでください。
- 記事で「日常の言葉」を使用しないでください。
- 類推を使用しないでください。
- 不要な言葉は使わないでください。
- コンテンツはできるだけ短く、必要に応じて長くする必要があります。
- 長い文ではなく、常に短い文を使用してください。
- 常に直接かつ正確に答えてください。
- ステートメントを作成する前に、必ず「ソース」を権限として使用してください。
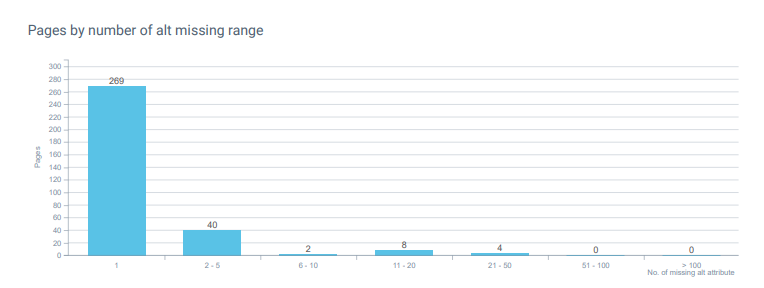
そして、それほど驚くことではありませんが、画像に「altタグ」を使用しませんでした。 しかし、これはアクセシビリティの問題でもあるため、SEO実験の場合でも、サイトをアクセスできない状況のままにしておくのは適切ではありません。 実験のために、店舗の車椅子の入り口を削除するとします。 同じ原則がウェブサイトにも当てはまります。
Sometimes it is difficult to get your authors to follow these rules, and I am not saying that you must follow them.

I am saying that I (mostly) followed these rules during these SEO projects.
15- Educate Your Customer instead of Keeping them in the Dark
I see that most of the SEO agencies do not explain SEO's subtle sides to their customers. The main reason for this lies the basic side of their business model. SEO is a business model based on the subscription economy model. It means that customers should continue to buy the service.
But you can also use the “IKEA Effect” for your business. The IKEA Effect is when you make customers contribute to the work, and it makes them love you more. As an owner of a “one-man-one-desk” company, I use my customers' team for our SEO projects. In other words, I don't need an SEO team for myself because I already have multiple teams that I educate.
OnCrawl's response size report according to the click depth. Having a “bad design” can also be useful if you want to have “smaller response sizes”. It is not an intentional situation but it is a natural outcome.
And when the customer starts to understand, to learn from you and to work hands-on on their own project, they start to love SEO and they feel the IKEA Effect. They give more value to the SEO project through self-association and effort justification.
Thus, they will listen to you easier, and sharing the “real know-how” won't jeopardize your business. Instead, it will make things easier. I even educate interns or sometimes enter job interviews for my customers' job applicants, because their future team member is also my team member.
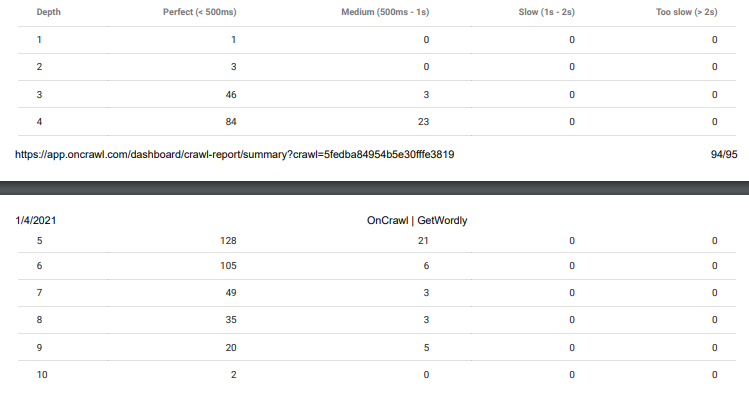
OnCrawl's response time report. After a server crash due to the organic traffic increase, we have bought a new server. That's why this crawl report shows better response timing. The other side of reality can be seen below.
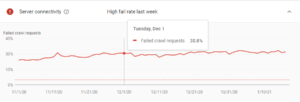
During the SEO case study and experiment, even the most important thing was not enough: the server. A screenshot from Interingilizce.com's Server Connectivity report from Google Search Console's Crawl Stats Report.
As an entrepreneur, this is my own model that is born from my own conditions. I hope this also fits for you as in other articles. Semantic SEO relies on patience, costly authors, highly theoric SEO terms, and content engineering with algorithmic knowledge. Without educating the customer, it might not be possible to convince the customer to follow you on this road.
And when you do convince them, they are happier to work with you, even when you propose theories that sound new or different to them:
“Koray likes to apply new things to our projects in a very short time. We got huge spikes in our web sites with his strategy. We like his enthusiasm. If you don't work with him, you haven't seen an advanced SEO theory glossary.”
Savas Ates
Owner of the KonusarakOgren
Last Thoughts on Semantic SEO
While writing this guide for this SEO case study with four different SEO projects, I have tried to keep things simple as much as possible. And I have told everything with complete honesty. If you can endure long theoric articles with a deep analytical analysis for SEO, I recommend you read the article that I recommended in the beginning that explains more than 40 different lesser-known SEO terms to understand everything behind this methodology.
As you have seen, in order to focus on an initial, rapid gain in traffic, I neglected a lot of SEO improvements for these sites. Working on these different technical SEO elements that you have seen in screenshots throughout the article will also improve traffic even more, but I wanted to be able to clearly show you the effects of semantic SEO alone.
Thanks to deep learning and machine learning, semantic SEO will soon become a more popular strategy. And I believe that technical SEO and branding will give more power to the SEOs who give value to the theoretical side of SEO and who try to protect their holistic approach.
See you in the future SEO case studies and experiments.