
クロール予算を定義する方法は?
公開: 2016-09-14私たちは皆それをSEOとして話しますが、クロール予算は実際にどのように機能しますか? 検索エンジンがクライアントのウェブサイトにアクセスしたときにクロールしてインデックスに登録するページ数は、オーガニック検索での成功と相関関係があることはわかっていますが、クロール予算が大きいほど常に優れていますか?
グーグルのすべてのように、私はあなたのウェブサイトのクロール予算とランキング/ SERPパフォーマンスの間の関係が100%単純であるとは思わない、それは多くの要因に依存している。
クロール予算が重要なのはなぜですか? 2010年のカフェインアップデートのため。 このアップデートにより、Googleは、インクリメンタルインデックスを使用して、コンテンツのインデックス作成方法を再構築しました。 「パーコレーター」システムの導入により、インデックスに登録されるページの「ボトルネック」が削除されました。
Googleはクロール予算をどのように決定しますか?
それはすべてあなたのPageRank、引用フローと信頼フローについてです。
ドメインオーソリティについて言及しなかったのはなぜですか? 正直なところ、私の意見では、SEOやコンテンツマーケターが利用できる最も誤用され誤解されている指標の1つであり、その場所はありますが、特にリンクを構築する場合は、あまりにも多くの代理店やSEOがそれを重視しすぎています。
もちろん、PageRankは、特にツールバーを削除したため、古くなっています。したがって、サイトの信頼率(信頼率=信頼フロー/引用フロー)がすべてです。 基本的に、より強力なドメインはクロールの予算が大きいので、WebサイトでのGoogleボットのアクティビティをどのように特定し、重要なことに、ボットのクロールの問題を特定しますか? サーバーログファイル。
これで、Googleボットにページを示すために、内部リンク構造を使用してインデックスを作成(およびランク付け)し、URLに沿った5つのサブフォルダーではなくルートドメインの近くに保持することがわかりました。 しかし、もっと技術的な問題はどうですか? クロール予算の浪費のように、ボットトラップ、またはGoogleがサイトのフォームに記入しようとしている場合(発生します)。
クローラーアクティビティの識別
これを行うには、いくつかのサーバーログファイルを入手する必要があります。 これらをクライアントにリクエストする必要がある場合もあれば、ホスティング会社から直接ダウンロードすることもできます。
この背後にある考え方は、Googleボットがサイトを攻撃した記録を見つけようとすることです。ただし、これはスケジュールされたイベントではないため、数日分のデータを取得する必要がある場合があります。 これらのファイルを分析するために利用できるさまざまなソフトウェアがあります。
以下は、Apacheサーバーへのヒット例です。
50.56.92.47 – – [31 / May / 2012:12:21:17 +0100]“ GET” –“ /wp-content/themes/wp-theme/help.php” –“ 404”“-”“ Mozilla / 5.0(互換性; Googlebot / 2.1; + http://www.google.com/bot.html)」– www.hit-example.com
ここから、ツール(OnCrawlなど)を使用してログファイルを分析し、GoogleのクロールPPCページやJSONスクリプトへの無限のGETリクエストなどの問題を特定できます。どちらもRobots.txtファイル内で修正できます。
クロール予算はいつ問題になりますか?
クロールの予算は必ずしも問題ではありません。サイトに多数のURLがあり、「クロール」が比例して割り当てられている場合は、問題ありません。 しかし、Webサイトに200,000のURLがあり、Googleが毎日サイトの2,000ページしかクロールしない場合はどうなるでしょうか。 Googleが新しいURLまたは更新されたURLに気付くまでに最大100日かかる可能性がありますが、これが問題になっています。
クロールの予算が問題であるかどうかを確認する簡単なテストの1つは、Google検索コンソールとサイトのURLの数を使用して、「クロール数」を計算することです。
- まず、サイトに何ページあるかを判断する必要があります。これは、サイトを実行することで実行できます。たとえば、oncrawl.comのインデックスには約512ページがあります。
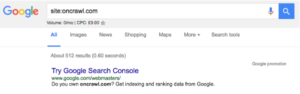

- 次に、Google Search Consoleアカウントに移動し、[クロール]、[クロール統計]の順に移動する必要があります。 GSCアカウントが適切に構成されていない場合は、このデータがない可能性があります。
- 3番目のステップは、「1日あたりにクロールされたページ」の平均数(真ん中のページ)とWebサイト上のURLの総数を取得し、それらを分割することです。
サイト上の総ページ数/1日あたりのクロールされた平均ページ数=X
Xが10より大きい場合は、クロールバジェットの最適化を検討する必要があります。 5未満の場合は、ブラボー。 読み進める必要はありません。
「クロール予算」の容量を最適化する
あなたはインターネット上で最大のクロール予算を持つことができます、しかしあなたがそれを使う方法を知らなければ、それは価値がありません。
はい、それは決まり文句ですが、それは本当です。 Googleがサイトのすべてのページをクロールし、それらの大部分が重複しているか、空白であるか、読み込みが非常に遅いことがわかった場合、タイムアウトエラーが発生し、予算が無駄になる可能性があります。
クロールバジェットを最大限に活用するには(サーバーログファイルにアクセスできない場合でも)、次のことを確認する必要があります。
重複するページを削除する
多くの場合、eコマースサイトでは、OpenCartなどのツールで同じ商品の複数のURLを作成できます。宛先とルートの間でサブフォルダーが異なる、4つのURLで同じ商品のインスタンスを確認しました。
Googleが各ページの複数のバージョンをインデックスに登録することは望ましくないため、Googleが正しいバージョンを指すように正規のタグが配置されていることを確認してください。
壊れたリンクを解決する
Google検索コンソールまたはクロールソフトウェアを使用して、サイト上の壊れた内部リンクと外部リンクをすべて見つけて修正します。 301を使用するのは素晴らしいことですが、ナビゲーションリンクやフッターリンクが壊れている場合は、301に依存せずに、ポイントしているURLを変更するだけです。
薄いページを書かないでください
ユーザーや検索エンジンにほとんどまたはまったく価値を提供しないページをサイトにたくさん配置することは避けてください。 コンテキストがないと、Googleはページを分類するのが難しいと感じています。つまり、ページはサイトの全体的な関連性に何の貢献もしておらず、クロール予算を費やしているだけの乗客です。
301リダイレクトチェーンを削除します
チェーンリダイレクトは不要で、面倒で誤解されています。 リダイレクトチェーンは、さまざまな方法でクロール予算に損害を与える可能性があります。 GoogleがURLに到達して301を検出すると、すぐにフォローするわけではなく、代わりに新しいURLをリストに追加してフォローします。
また、XMLサイトマップ(およびHTMLサイトマップ)が正確であることを確認する必要があります。また、Webサイトが多言語である場合は、Webサイトの各言語のサイトマップがあることを確認してください。 また、スマートサイトアーキテクチャ、URLアーキテクチャを実装し、ページを高速化する必要があります。 CloudFlareのようなCDNの背後にサイトを配置することも有益です。
TL; DR:
他の予算と同じように予算をクロールすることはチャンスです。理論的には、予算を使用して、Googlebot、Bingbot、Slurpがサイトで費やす時間を購入しています。この時間を最大限に活用することが重要です。
クロール予算の最適化は簡単ではなく、それは確かに「迅速な勝利」ではありません。 小規模なサイト、または手入れの行き届いた中規模のサイトがある場合は、おそらく問題ありません。 数万のURLを含む巨大なサイトがあり、サーバーログファイルが頭を悩ませている場合は、専門家に連絡する時期かもしれません。