
PythonでURLの位置に基づいてブランド化されていないオーガニックトラフィックの収益を予測する方法
公開: 2022-05-24SEO予測とは何ですか?
SEO予測、つまりオーガニックトラフィックの見積もりは、独自のサイトのデータまたはサードパーティのデータを使用して、サイトの将来のオーガニックトラフィック、SEO収益、およびSEOROIを推定するプロセスです。 この見積もりは、私たちのデータに基づいたさまざまな方法を使用して計算できます。
このチュートリアルでは、URLの位置と現在の収益に基づいて、ブランド化されていないオーガニック収益とブランド化されていないオーガニックトラフィックを予測します。 これは、SEOとして、月次、四半期、または年次の予算の増加から、製品および開発チームからの工数の増加まで、他の利害関係者からより多くの賛同を得るために役立ちます。
このチュートリアルは、ブランド化されていないオーガニックトラフィックにのみ適用できるわけではないことに注意してください。 いくつかの変更を加え、Pythonを理解することで、Pythonを使用してターゲットページのトラフィックを見積もることができます。
その結果、下の画像のようなGoogleスプレッドシートを作成できます。
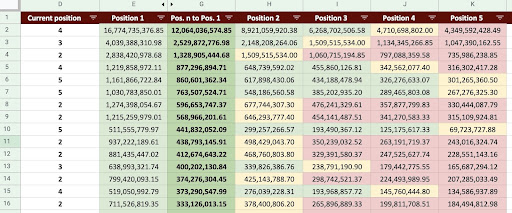
Googleスプレッドシートの画像
ブランド化されていないSEOトラフィック予測
イントロダクションを読んだ後に最初に尋ねる質問は、「ブランド化されていないオーガニックトラフィックを計算する理由」です。
アマゾンのような会社を考えてみましょう。 本やマスクを購入したい場合は、「マスクアマゾンを購入」と検索するだけです。
ブランドはしばしば頭に浮かぶものであり、何かを購入したいときは、これらの会社から必要なものを購入することを好みます。 各業界には、Google検索でのユーザーの行動に影響を与えるブランド企業があります。
AmazonのGoogleSearchConsole(GSC)データを確認すると、ブランドクエリから多くのトラフィックを受信していることがわかります。ほとんどの場合、ブランドクエリの最初の結果はそのブランドのサイトです。
私のようにSEOとして、「私たちのブランドだけが私たちのSEOを助けてくれます!」と何度も聞いたことがあるでしょう。 「いいえ、そうではありません」と言って、ブランド以外のクエリのトラフィックと収益をどのように示すことができますか?
Googleのアルゴリズムは非常に複雑であり、ブランド検索と非ブランド検索を明確に区別することは難しいため、これを証明するのはさらに複雑です。 しかし、これが私たちがSEOとして行うことをさらに重要にしている理由です。
このチュートリアルでは、ブランドと非ブランドの2つを区別する方法と、SEOがいかに強力であるかを示します。
あなたの会社がブランド化されていなくても、この記事から多くを得ることができます:あなたはあなたのサイトの有機的なデータを推定する方法を学ぶことができます。
トラフィック推定に基づくSEOROI
どこにいても、何をしていても、リソースには制限があります。 それは予算であろうと、単に就業日の時間数であろうと。 リソースを最適に割り当てる方法を知ることは、全体およびSEOの投資収益率(ROI)において主要な役割を果たします。
CMO、マーケティングVP、またはパフォーマンスマーケターはすべて、異なるKPIを持ち、目的を達成するために異なるリソースを必要とします。 あなたが必要なものを確実に手に入れるための最良の方法は、それが会社にもたらす利益を実証することによってその必要性を証明することです。 SEOROIも例外ではありません。 1年の予算配分時期が近づき、チームがより大きな予算を要求したい場合、SEO ROIを見積もることで、交渉で優位に立つことができます。 ブランド化されていないトラフィックの見積もりを計算したら、目的の結果を達成するために必要な予算をより適切に評価できます。
SEO戦略に対するSEO予測の影響
ご存知のように、3か月または6か月ごとに、SEO戦略を見直し、可能な限り最高の結果が得られるように調整します。 しかし、あなたの会社にとって最大の利益がどこにあるのかわからない場合はどうなりますか? 決定を下すことはできますが、サイトのトラフィックをより包括的に把握している場合の決定ほど効果的ではありません。
ブランド化されていないオーガニックトラフィックの収益見積もりをランディングページやクエリのセグメンテーションと組み合わせて、SEOマネージャーまたはSEOストラテジストとしてより良い戦略を立てるのに役立つ全体像を提供できます。
有機的なトラフィックを予測するさまざまな方法
SEOコミュニティには、将来のオーガニックトラフィックを予測するためのさまざまな方法とパブリックスクリプトがあります。
これらの方法のいくつかは次のとおりです。
- サイト全体のオーガニックトラフィック予測
- 特定のページ(ブログ、製品、カテゴリなど)または単一ページでのオーガニックトラフィック予測
- 特定のクエリ(クエリには「購入」、「ハウツー」などが含まれます)またはクエリに関するオーガニックトラフィック予測
- 特定の期間のオーガニックトラフィック予測(特に季節イベントの場合)
私の方法は特定のページ用で、期間は1か月です。
[ケーススタディ]ページ上のSEOで新しい市場の成長を促進する
 ケーススタディを読む
ケーススタディを読むオーガニックトラフィックの収益を計算する方法
正確な方法は、Google Analytics(GA)データに基づいています。 サイトがまったく新しい場合は、サードパーティのツールを使用する必要があります。 独自のデータがある場合は、このようなツールの使用を避けたいと思います。
使用しているサードパーティのデータを実際のページデータの一部に対してテストして、データに含まれる可能性のあるエラーを見つける必要があることを忘れないでください。
Pythonでブランド化されていないSEOトラフィックの収益を計算する方法
これまで、オーガニックトラフィックと収益予測のさまざまな側面をよりよく理解するために、精通している必要のある多くの理論的概念について説明してきました。 ここで、この記事の実用的な部分について詳しく説明します。
まず、CTR曲線を計算することから始めます。 Oncrawlに関する私のCTR曲線の記事では、2つの異なる方法と、コードにいくつかの変更を加えることで使用できる他の方法について説明します。 最初にクリックカーブの記事を読むことをお勧めします。 それはあなたにこの記事についての洞察を与えます。
この記事では、コードの一部を微調整して、トラフィックの見積もりに必要な特定の結果を取得します。 次に、GAからデータを取得し、GA収益ディメンションを使用して収益を見積もります。
Pythonを使用した非ブランドのオーガニックトラフィック収益の予測:はじめに
Pythonを知らなくても、このコードを自分で実行できます。 ただし、Python構文について少し知っていることと、この予測コードで使用するPythonライブラリについての基本的な知識があることをお勧めします。 これは、私のコードをよりよく理解し、自分に役立つ方法でカスタマイズするのに役立ちます。
このコードを実行するには、「Jupyter」拡張機能を含むMicrosoftのPython拡張機能を備えたVisualStudioCodeを使用します。 ただし、Jupyterノートブック自体は使用できます。
プロセス全体で、次のPythonライブラリを使用する必要があります。
- ゴツゴツ
- パンダ
- プロット
また、いくつかのPython標準ライブラリをインポートします。
- JSON
- pprint
#プロセスに必要なライブラリをインポートする jsonをインポートする pprintからインポートpprint numpyをnpとしてインポートします パンダをpdとしてインポートします plotly.expressをpxとしてインポートします
ステップ1:相対CTR曲線を計算する(相対クリック曲線)
最初のステップでは、相対CTR曲線を計算します。 しかし、相対的なCTR曲線は何ですか?
相対CTR曲線とは何ですか?
まず、「絶対CTR曲線」について説明します。 絶対CTR曲線を計算するとき、最初の位置の中央値CTR(または平均CTR)は36%、2番目の位置は20%というようになります。
パーセンテージの瞬間である相対CTR曲線では、各位置の中央値を最初の位置のCTRで除算します。 たとえば、最初の位置の相対CTR曲線は0.36 / 0.36 = 1になり、2番目の位置は0.20 / 0.36=0.55になります。
なぜこれを計算することが有用なのか疑問に思っているのではないでしょうか。 CTRが44%の1位にランク付けされたページについて考えてみてください。 このページが2番目の位置に移動した場合、クリック率曲線は20%に減少せず、クリック率が44%* 0.55 = 24.2%に減少する可能性が高くなります。
1.GSCからブランドおよび非ブランドのオーガニックトラフィックデータを取得する
計算プロセスでは、GSCからデータを取得する必要があります。 初回はすべてのデータがブランドクエリに基づいており、次回はすべてのデータが非ブランドクエリに基づいています。
このデータを取得するには、Pythonスクリプトから、または「SearchAnalyticsforSheets」GoogleSheetsアドオンからのさまざまな方法を使用できます。 GSCAPIエクスプローラーを使用します。
このデータの出力は、各ページのパフォーマンスを示す2つのJSONファイルです。 1つのJSONファイルはブランドクエリに基づくランディングページのパフォーマンスを示し、もう1つは非ブランドクエリに基づくランディングページのパフォーマンスを示します。
GSC APIエクスプローラーからデータを取得するには、次の手順に従います。
- https://developers.google.com/webmaster-tools/v1/searchanalytics/queryにアクセスします。
- ページの右上隅にあるAPIエクスプローラーを最大化します。
- 「
siteUrl」フィールドに、ドメイン名を挿入します。 たとえば、「https://www.example.com」または「http://your-domain.com」。 - リクエスト本文では、最初に「
startDate」パラメータと「endDate」パラメータを定義する必要があります。 私の好みは過去30日です。 - 次に、「
dimensions」を追加し、このリストの「page」を選択します。 - 次に、「
dimensionFilterGroups」を追加してクエリをフィルタリングします。 1回目はブランド化されたクエリ用で、もう1回はブランド化されていないクエリ用です。 - 最後に、「
rowLimit」を25,000に設定します。 毎月オーガニックトラフィックを獲得するサイトページが25Kを超える場合は、リクエスト本文を変更する必要があります。 - 各リクエストを行った後、JSONレスポンスを保存します。 ブランド化されたパフォーマンスの場合は、JSONファイルを「
branded_data.json」として保存し、ブランド化されていないパフォーマンスの場合は、JSONファイルを「non_branded_data.json」として保存します。
リクエスト本文のパラメータを理解したら、リクエスト本文の下にコピーして貼り付けるだけです。 ブランド名を「 brand variation names 」に置き換えることを検討してください。
パイプラインまたは「 | 」でブランド名を区切る必要があります」。 たとえば、「 amazon|amazon.com|amazn 」。
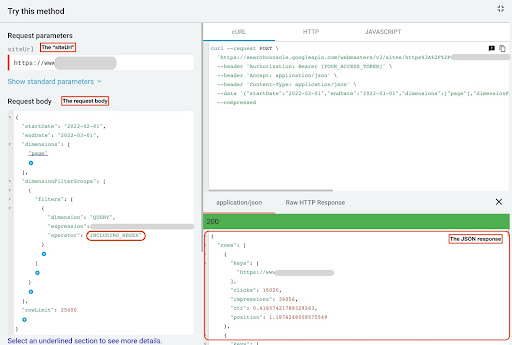
GSCAPIエクスプローラー
ブランドのリクエスト本文:
{{
"startDate": "2022-02-01"、
"endDate": "2022-03-01"、
「寸法」:[
"ページ"
]、
"dimensionFilterGroups":[
{{
「フィルター」:[
{{
「寸法」:「QUERY」、
「表現」:「ブランドバリエーション名」、
"演算子": "INCLUDING_REGEX"
}
]
}
]、
「rowLimit」:25000
}
ブランド化されていないリクエスト本文:
{{
"startDate": "2022-02-01"、
"endDate": "2022-03-01"、
「寸法」:[
"ページ"
]、
"dimensionFilterGroups":[
{{
「フィルター」:[
{{
「寸法」:「QUERY」、
「表現」:「ブランドバリエーション名」、
"演算子": "EXCLUDING_REGEX"
}
]
}
]、
「rowLimit」:25000
}
2. Jupyterノートブックにデータをインポートし、サイトディレクトリを抽出します
次に、データをJupyterノートブックにロードして、データを変更し、そこから必要なものを抽出できるようにする必要があります。 上で中断したところから始めましょう。
ブランドデータを読み込むには、次のコードブロックを実行する必要があります。
#ブランドでのウェブサイトURLのパフォーマンスとブランドクエリのデータフレームを作成する
open( "./ branded_data.json")をjson_fileとして使用:
branded_data = json.loads(json_file.read())["rows"]
branded_df = pd.DataFrame(branded_data)
#「キー」列の名前を「ランディングページ」列に変更し、「ランディングページ」リストをURLに変換する
branded_df.rename(columns = {"keys": "landing page"}、inplace = True)
branded_df ["landing page"] = branded_df ["landing page"]。apply(lambda x:x [0])
ブランド化されていないパフォーマンスのランディングページの場合、次のコードブロックを実行する必要があります。
#ブランド化されていないクエリでのWebサイトURLパフォーマンスのDataFrameを作成する
open( "./ non_branded_data.json")をjson_fileとして使用:
non_branded_data = json.loads(json_file.read())["rows"]
non_branded_df = pd.DataFrame(non_branded_data)
#「キー」列の名前を「ランディングページ」列に変更し、「ランディングページ」リストをURLに変換する
non_branded_df.rename(columns = {"keys": "landing page"}、inplace = True)
non_branded_df ["landing page"] = non_branded_df ["landing page"]。apply(lambda x:x [0])
データをロードしてから、ディレクトリを抽出するためにサイト名を定義する必要があります。
#引用符の間にサイト名を定義します。 たとえば、「https://www.example.com/」または「http://mydomain.com/」 SITE_NAME = "https://www.your_domain.com/"
ブランド化されていないパフォーマンスからディレクトリを抽出するだけで済みます。
#各ランディングページ(URL)ディレクトリを取得する
non_branded_df["ディレクトリ"]=non_branded_df["ランディングページ"]。str.extract(
pat = f "((?<= {SITE_NAME})[^ /] +)"
)。
次に、このプロセスで重要なディレクトリを選択するために、ディレクトリを印刷します。 サイトをより深く理解するために、すべてのディレクトリを選択することをお勧めします。
#出力内のすべてのディレクトリを取得するには、Pandasオプションを操作する必要があります pd.set_option( "display.max_rows"、None) #ウェブサイトディレクトリ non_branded_df ["directory"]。value_counts()
ここでは、重要なディレクトリを挿入できます。
"""CTR曲線を取得するために重要なディレクトリを選択します。 'important_directories'変数にディレクトリを挿入します。 たとえば、'product、tag、product-category、mag'です。 ディレクトリ値はコンマで区切ります。 "" " IMPORTANT_DIRECTORIES = "your_important_directories" IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split( "、")
3.位置に基づいてページにラベルを付け、相対CTR曲線を計算します
次に、ランディングページの位置に基づいてラベルを付ける必要があります。 これを行うのは、ランディングページの位置に基づいて、各ディレクトリの相対CTR曲線を計算する必要があるためです。

#ブランド化されていないポジションのラベル付け
範囲(1、11)のiの場合:
non_branded_df.loc [
(non_branded_df ["position"]> = i)&(non_branded_df ["position"] <i + 1)、
「位置ラベル」、
] = i
次に、ディレクトリに基づいてランディングページをグループ化します。
#「ディレクトリ」の値に基づいてランディングページをグループ化する non_brand_grouped_df = non_branded_df.groupby(["directory"])
相対CTR曲線を計算する関数を定義しましょう。
def each_dir_relative_ctr_curve(dir_df、key):
"" "この関数は、各IMPORTANT_DIRECTORIES相対CTR曲線を計算します。
"" "
#「positionlabel」値に基づいて「non_brand_grouped_df」をグループ化
dir_grouped_df = dir_df.groupby(["position label"])
#各ポジションの中央値CTRを保存するためのリスト
median_ctr_list = []
#各ディレクトリをキーとして保存し、値として「median_ctr_list」
directorys_median_ctr = {}
#各「dir_grouped_df」グループをループします
範囲(1、11)のiの場合:
#試してみてください-たとえば、ディレクトリに位置4のデータがないような状況を処理する場合を除きます
試す:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df ["ctr"]))
を除外する:
median_ctr_list.append(0)
#相対CTR曲線の計算
directorys_median_ctr [key] = np.array(median_ctr_list)/ np.array(
[median_ctr_list [0]] * 10
)。
ディレクトリを返す_median_ctr
関数を定義した後、それを実行します。
#ディレクトリをループして「each_dir_relative_ctr_curve」関数を実行する
directorys_median_ctr_dict = dict()
キーの場合、non_brand_grouped_dfのアイテム:
IMPORTANT_DIRECTORIESを入力した場合:
directorys_median_ctr_dict.update(each_dir_relative_ctr_curve(item、key))
pprint(directories_median_ctr_dict)
次に、ブランドと非ブランドのランディングページのパフォーマンスを読み込み、非ブランドデータの相対CTR曲線を計算します。 ブランド以外のデータに対してのみこれを行うのはなぜですか? ブランド以外のオーガニックトラフィックと収益を予測したいからです。
ステップ2:ブランド化されていないオーガニックトラフィックの収益を予測する
この2番目のステップでは、収益データを取得して収益を予測する方法について説明します。
1.ブランドと非ブランドのオーガニックデータのマージ
次に、ブランド化されたデータとブランド化されていないデータをマージします。 これは、すべてのトラフィックと比較した、各ランディングページのブランド化されていないオーガニックトラフィックの割合を計算するのに役立ちます。
#「main_df」は、「サイト全体のデータ」と「非ブランドデータ」のDataFrameの組み合わせです。
#このDataFrameを使用すると、クリックとインプレッションのほとんどがどこにあるかを見つけることができます
#ブランド化されていないクエリから取得されます。
main_df = non_branded_df.merge(
branded_df、on = "landing page"、suffixes =( "_ non_brand"、 "_branded")
)。
次に、列を変更して不要な列を削除します。
#'main_df'列を必要な列に変更する
main_df = main_df [
[
"ランディングページ"、
"clicks_non_brand"、
"ctr_non_brand"、
"ディレクトリ"、
「位置ラベル」、
"clicks_branded"、
]
]
それでは、ランディングページの合計クリック数に対するブランド化されていないクリック数の割合を計算してみましょう。
#ブランド化されていないクエリのクリック数を、ランディングページ全体に対するランディングページに基づいて計算する
main_df.loc [:、 "clicks_non_brand_percentage"] = main_df.apply(
ラムダx:x ["clicks_non_brand"] /(x ["clicks_non_brand"] + x ["clicks_branded"])、
axis = 1、
)。
[電子ブック]OncrawlによるSEOの自動化
 電子ブックを読む
電子ブックを読む2.オーガニックトラフィック収益の読み込み
GSCデータを取得するのと同じように、GAデータを取得する方法はいくつかあります。「GoogleAnalyticsSheetsアドオン」またはGAAPIを使用できます。 このチュートリアルでは、その単純さからGoogle Data Studio(GDS)を使用することを好みます。
GDSからGAデータを取得するには、次の手順に従います。
- GDSで、新しいレポートまたはエクスプローラーとテーブルを作成します。
- ディメンションには「ランディングページ」を追加し、メトリックには「収益」を追加する必要があります。
- 次に、ソースとメディアに基づいてGAでカスタムセグメントを作成する必要があります。 「Google/オーガニック」トラフィックをフィルタリングします。 セグメントの作成後、GDSのセグメントセクションに追加します。
- 最後のステップで、テーブルをエクスポートして「
landing_pages_revenue.csv」として保存します。
ランディングページの収益csvエクスポート
データをロードしましょう。
Organic_revenue_df = pd.read_csv( "./ data / landing_pages_revenue.csv")
次に、GAランディングページのURLにサイト名を追加する必要があります。
GAからデータをエクスポートする場合、ランディングページは相対形式ですが、GSCデータは絶対形式です。
GAランディングページのデータを確認することを忘れないでください。 使用したデータセットでは、GAデータを毎回少しクリーンアップする必要があることがわかりました。
#GAランディングページのURLをSITE_NAMEと連結します。
#また、列の名前を変更する
Organic_revenue_df.loc [:、"ランディングページ"]=(
SITE_NAME [:-1] + Organic_revenue_df [organic_revenue_df.columns [0]]
)。
Organic_revenue_df.rename(columns = {"ランディングページ": "ランディングページ"、 "収益": "収益"}、inplace = True)
それでは、GSCデータをGAデータとマージしてみましょう。
#このステップでは、「main_df」を「dk_organic_revenue_df」とマージします。DataFrameには、ブランド以外のクエリデータの割合が含まれています main_df = main_df.merge(organic_revenue_df、on = "landing page"、how = "left")
このセクションの最後で、DataFrame列を少しクリーンアップします。
#'main_df'DataFrameを少しクリーンアップします
main_df = main_df [
[
"ランディングページ"、
"clicks_non_brand"、
"ctr_non_brand"、
"ディレクトリ"、
「位置ラベル」、
"clicks_non_brand_percentage"、
"収益"、
]
]
3.ブランド化されていない収益の計算
このセクションでは、データを処理して、探している情報を抽出します。
ただし、何よりもまず、「 IMPORTANT_DIRECTORIES 」に基づいてランディングページをフィルタリングしましょう。
#「IMPORTANT_DIRECTORIES」に含まれていない他のディレクトリのランディングページを削除する
main_df =(
main_df [main_df ["directory"]。isin(IMPORTANT_DIRECTORIES)]
.dropna(subset = ["revenue"])
.reset_index(drop = True)
)。
それでは、ブランド化されていないオーガニック収益トラフィックを計算してみましょう。
簡単に計算できないメトリックを定義しました。これは、番号を割り当てるための何よりも直感的です。
「 brand_influence 」メトリックは、ブランドの強さを示します。 ブランド以外の検索によってビジネスへの売り上げが減少すると思われる場合は、この数値を低くしてください。 たとえば0.8のようなもの。
#ブランドが非常に強力であるため、ブランドなしでクエリを実行しても、ブランドを使用してクエリを実行するのと同じくらい売れる場合は、1が適しています。
#クエリにブランド名が含まれていない本を探すことを検討してください。 アマゾンを見るとき、あなたは他の市場や店から購入しますか?
brand_influence = 1
main_df.loc [:、 "non_brand_revenue"] = main_df.apply(
ラムダx:x ["revenue"] * x ["clicks_non_brand_percentage"] * brand_influence、axis = 1
)。
重要なディレクトリに基づいて、ブランド化されていない収益についての洞察を得るために、円グラフをプロットしてみましょう。
#このセルでは、ディレクトリに基づいて、ブランド以外のすべてのランディングページの収益を取得したいと考えています
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df、
index = "ディレクトリ"、
values = ["non_brand_revenue"]、
aggfunc = {"non_brand_revenue": "sum"}、
)。
pie_fig = px.pie(
non_branded_directory_dist_revenue_df、
values = "non_brand_revenue"、
names = non_branded_directory_dist_revenue_df.index、
title = "ウェブサイトディレクトリに基づく非ブランド収益"、
)。
pie_fig.update_traces(textposition = "inside"、textinfo = "percent + label")
pie_fig.show()
このプロットは、 IMPORTANT_DIRECTORIESでのブランド化されていないクエリの分布を示しています。
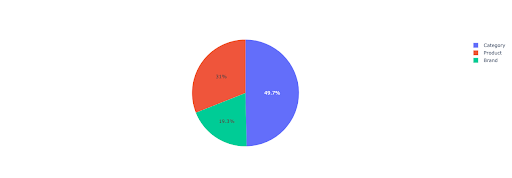
ブランド化されていないクエリの配布
CTR曲線データに基づくと、5より高い位置のCTRに依存できないことがわかります。このため、位置に基づいてデータをフィルタリングします。
データに基づいて、以下のコードブロックを変更できます。
#CTR曲線のCTR精度により、5を超える位置のランディングをスキップできると思います。このため、他のランディングページをフィルタリングしました。 main_df = main_df [main_df ["position label"] <6] .reset_index(drop = True)
4.「クリックあたりの収益」(RPC)の計算
ここでは、カスタムメトリックを作成し、それを「クリック単価」またはRPCと呼びました。 これは、ブランド化されていないクリックごとに発生した収益を示しています。
このメトリックはさまざまな方法で使用できます。 RPCは高いが、クリック数が少ないページを見つけました。 ページを確認したところ、1週間以内にインデックスが作成されており、さまざまな方法でページを最適化できることがわかりました。
#クリックごとに生成される収益を計算する(RPC:クリックあたりの収益)
main_df ["rpc"] = main_df.apply(
ラムダx:x ["non_brand_revenue"] / x ["clicks_non_brand"]、axis = 1
)。
5.収益を予測する!
終わりに近づいており、ブランド化されていないオーガニック収益を予測するのを今まで待っていました。
最後のコードブロックを実行してみましょう。
#さまざまなポジションに基づいて収益を計算する主な機能
インデックスの場合、main_df.iterrows()のrow_values:
#ディレクトリを切り替えるCTRリスト
ctr_curve = directorys_median_ctr_dict [row_values ["directory"]]
#位置1から5にループし、クリック率の増減に基づいて収益を計算します
範囲(1、6)のiの場合:
if i == row_values ["position label"]:
main_df.loc [index、i] = row_values ["non_brand_revenue"]
そうしないと:
#main_df.loc [index、i + 1] ==
main_df.loc [index、i] =(
row_values ["non_brand_revenue"]
*(ctr_curve [i-1])
/ ctr_curve [int(row_values ["position label"]-1)]
)。
#「Nto1」メトリックを計算します。 これは、ランクが「N」から「1」になったときの収益の増加を示しています。
main_df.loc [index、 "N to 1"] = main_df.loc [index、1] --main_df.loc [index、row_values ["position label"]]
最終出力を見ると、新しい列があります。 これらの列の名前は、「1」、「2」、「3」、「4」、「5」です。
これらの名前はどういう意味ですか? たとえば、位置3にページがあり、その位置が改善された場合の収益を予測したり、ランクが下がった場合にどれだけの損失が発生するかを知りたいとします。
「1」と「2」の列は、このページの平均位置が向上したときのページの収益を示し、「4」と「5」の列は、ランキングを下げたときのこのページの収益を示しています。
この例の列「3」は、ページの現在の収益を示しています。
また、「Nto1」という指標を作成しました。 これは、このページの平均位置が「3」(またはN)から「1」に移動するかどうか、および移動が収益にどの程度影響するかを示します。
まとめ
この記事では多くのことを取り上げましたが、今度は手を汚して、ブランド化されていないオーガニックトラフィックの収益を予測する番です。
これは、この予測を使用できる最も簡単な方法です。 このアルゴリズムをより複雑にして、いくつかのMLモデルと組み合わせることができますが、それでは記事がより複雑になります。
このデータをCSVで保存し、Googleスプレッドシートにアップロードすることを好みます。 または、チームや組織の他のメンバーと共有する予定がある場合は、Excelで開いて、読みやすいように色を使用して列をフォーマットします。
このデータに基づいて、ブランド化されていないオーガニックトラフィックのROIを予測し、交渉プロセスで使用できます。