
非表示にする場所がない:検索エンジンスパイダーからのコンテンツのブロック
公開: 2022-06-12TL; DR
- 検索エンジンからコンテンツを除外することを検討している場合は、最初に正しい理由でそれを行っていることを確認してください。
- ボットが理解できない言語やフォーマットでコンテンツを非表示にできると誤解しないでください。 それは近視眼的な戦略です。 robots.txtファイルまたはMetaRobotsタグを使用して、事前にそれらを把握してください。
- 安全なコンテンツをブロックするために推奨される方法を使用しているという理由だけで、それを忘れないでください。 コンテンツをブロックすると、サイトがボットにどのように表示されるかを理解します。
検索エンジンインデックスからコンテンツを除外する時期と方法
SEOの主要な側面は、あなたのウェブサイトが評判が良く、検索者に真の価値を提供することを検索エンジンに納得させることです。 また、検索エンジンがコンテンツの価値と関連性を判断するには、ユーザーの立場に立つ必要があります。
現在、サイトを監視するソフトウェアには、特定のリソースを検索エンジンから隠しておくためにSEOが従来から利用してきた特定の制限があります。 ただし、ボットは開発を続けており、人間のユーザーがブラウザで表示するようにWebページを表示するための取り組みがますます高度になっています。 検索エンジンボットが利用できないサイトのコンテンツと、それが利用できない理由を再検討するときが来ました。 ボットにはまだ制限があり、ウェブマスターには特定のコンテンツをブロックまたは外部化する正当な理由があります。 検索エンジンはユーザーに高品質のコンテンツを提供するサイトを探しているので、ユーザーエクスペリエンスにプロジェクトをガイドさせれば、残りは適切に機能します。
なぜコンテンツをブロックするのですか?

- プライベートコンテンツ。 ページにインデックスを付けるということは、ページを検索結果に表示できるため、一般に公開されることを意味します。 プライベートページ(顧客のアカウント情報、個人の連絡先情報など)がある場合は、それらをインデックスから除外します。 (一部のwhoisタイプのサイトでは、JavaScriptで登録者情報を表示して、スクレーパーボットが個人情報を盗むのを防ぎます。)
- 重複したコンテンツ。 テキストのスニペット(商標情報、スローガン、説明)でも、ページ全体(サイト内のカスタム検索結果など)でも、サイトの複数のURLに表示されるコンテンツがある場合、検索エンジンのスパイダーはそれを低品質と見なす可能性があります。 。 使用可能なオプションの1つを使用して、それらのページ(またはページ上の個々のリソース)の索引付けをブロックできます。 それらをユーザーに表示したままにして、検索結果からブロックすることができます。これにより、検索に表示したいコンテンツのランキングが損なわれることはありません。
- 他のソースからのコンテンツ。 サードパーティのソースによって生成され、Web全体の複数の場所に複製される広告などのコンテンツは、ページの主要コンテンツの一部ではありません。 その広告コンテンツがWeb全体で何度も複製される場合、Webマスターは、広告がページの一部として表示されないようにしたい場合があります。
それはなぜ、どうですか?
よろしくお願いします。 コンテンツをインデックスから除外するために使用されてきた1つの方法は、ボットが解析または実行できない言語を使用して、ブロックされた外部ソースからコンテンツをロードすることです。 部屋にいる幼児に自分が何を話しているのかを知られたくないので、別の大人に言葉を綴るようなものです。 問題は、この状況の幼児が賢くなっていることです。 長い間、検索エンジンから何かを隠したい場合は、JavaScriptを使用してそのコンテンツを読み込むことができます。つまり、ユーザーはそれを取得しますが、ボットは取得しません。
しかし、Googleは、ボットを使用してJavaScriptを解析したいという彼らの願望についてまったく気が狂っていません。 そして彼らはそれを始めています。 ウェブマスターツールのFetchasGoogleツールを使用すると、Googleのボットが見ているように個々のページを見ることができます。

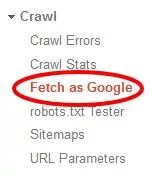
JavaScriptを使用してサイトのコンテンツをブロックしている場合は、このツールのいくつかのページを確認する必要があります。 チャンスは、グーグルはそれを見ています。
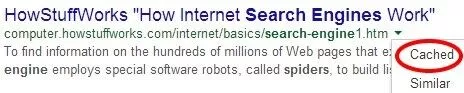
ただし、GoogleがJavaScriptでコンテンツをレンダリングできるからといって、コンテンツがキャッシュされているとは限らないことに注意してください。 「フェッチとレンダリング」ツールは、ボットが見ることができるものを示します。 インデックスに登録されているものを見つけるには、キャッシュされたバージョンのページを確認する必要があります。
人々が議論するコンテンツを外部化するための他の方法はたくさんあります:iframes、AJAX、jQuery。 しかし、2012年までさかのぼると、実験では、Googleがiframeに配置されたリンクをクロールできることが示されていました。 だからそのテクニックがあります。 実際、ボットが理解できない言語を話す時代は終わりに近づいています。
しかし、ボットに特定のものを見ないように丁寧に頼んだらどうなるでしょうか。 robots.txtまたはMetaRobotsタグの要素をブロックまたは禁止することは、要素またはページがインデックスに登録されないようにする唯一の確実な方法です(パスワードで保護するサーバーディレクトリを除く)。
John Muellerは最近、AJAX / JSONフィードで生成されたコンテンツは、「JavaScriptのクロールを禁止した場合、[Google]には表示されない」とコメントしました。 彼はさらに、CSSまたはJavaScriptをブロックするだけでは、必ずしもランキングが損なわれるわけではないことを明確にしています。 したがって、コンテンツをインデックスから除外する最善の方法は、検索エンジンにコンテンツのインデックスを作成しないように依頼することです。 これは、個々のURL、ディレクトリ、または外部ファイルにすることができます。
それで、これは私たちを最初に戻します:なぜ。 コンテンツをブロックすることを決定する前に、それを実行している理由とリスクを確認してください。 まず、CSSファイルまたはJavaScriptファイル(特にサイトのレイアウトに大きく影響するファイル)をブロックするのは危険です。 特に、ページがモバイル向けに最適化されているかどうかを検索エンジンが認識できないようにすることができます。 それだけでなく、Panda 4.0のロールアウト後、大きな打撃を受けた一部のサイトは、CSSとJavaScriptのブロックを解除することでリバウンドすることができました。これは、ボットからこれらの要素をブロックするためのGoogleのアルゴリズムのターゲットになっていることを示しています。
コンテンツをブロックするときに実行するもう1つのリスク:検索エンジンのスパイダーは、ブロックされているものを確認できない場合がありますが、何かがブロックされていることを知っているため、そのコンテンツが何であるかを推測する必要があります。 たとえば、広告はiframeやCSSに隠されていることがよくあります。 そのため、ページの上部近くにブロックされたコンテンツが多すぎると、「トップヘビー」ページレイアウトアルゴリズムに見舞われるリスクがあります。 iframeの使用を検討しているこれを読んでいるウェブマスターは、まず評判の良いSEOに相談することを強く検討する必要があります。 (恥知らずなBCIプロモーションをここに挿入します。)