
ProphetとPythonを使用したSEOトラフィックの予測
公開: 2021-03-16目標を設定し、時間の経過とともに達成度を評価することは、私たちが何を達成できるか、そして私たちが使用する戦略が効果的かどうかを理解するために非常に興味深い演習です。 ただし、最初に予測を立てる必要があるため、通常、これらの目標を設定するのはそれほど簡単ではありません。
予測の作成は簡単なことではありませんが、いくつかの利用可能な予測手順、CPU、およびいくつかのプログラミングスキルのおかげで、その複雑さを大幅に軽減できます。 この投稿では、PythonとライブラリProphetを使用し、占い師の超能力を持たずに、正確な予測を行う方法と、これをSEOに適用する方法を紹介します。
預言者について聞いたことがない場合は、それが何であるか疑問に思うかもしれません。 要するに、Prophetは、Facebookのコアデータサイエンスチームによってリリースされた予測手順であり、PythonとRで利用可能であり、外れ値と季節的影響を非常にうまく処理します。
正確で高速な予測を提供します。
予測について話すときは、次の2つのことを考慮する必要があります。
- 履歴データが多いほど、モデルが正確になり、予測が正確になります。
- 予測モデルは、内部要因が同じままであり、それに影響を与える外部要因がない場合にのみ有効になります。 これは、たとえば、週に1つの投稿を公開していて、週に2つの投稿を公開し始めた場合、このモデルは、この戦略変更の結果を予測するのに有効ではない可能性があることを意味します。 一方、アルゴリズムの更新がある場合は、モデルも有効でない可能性があります。 モデルは履歴データに基づいて作成されていることに注意してください。
これをSEOに適用するには、次の手順に従って、次の月のSEOセッションを予測します。
- 特定の期間のオーガニックセッションに関するデータをGoogleAnalyticsから取得します。
- モデルのトレーニング。
- 来月のSEOトラフィックを予測します。
- モデルが平均絶対誤差でどれだけ優れているかを評価します。
この予測手順がどのように機能するかについてもっと知りたいですか? それでは始めましょう!
GoogleAnalyticsからデータを取得する
Google Analyticsからのデータ抽出には、通常のインターフェースからExcelファイルをエクスポートする方法と、APIを使用してこのデータを取得する方法の2つの方法でアプローチできます。
Excelファイルからのデータのインポート
Google Analyticsからこのデータを取得する最も簡単な方法は、サイドバーの[チャンネル]セクションに移動し、[オーガニック]をクリックして、ページの上部にあるボタンでデータをエクスポートすることです。 グラフの上部にあるドロップダウンメニューで、分析する変数(この場合はセッション)を選択していることを確認してください。
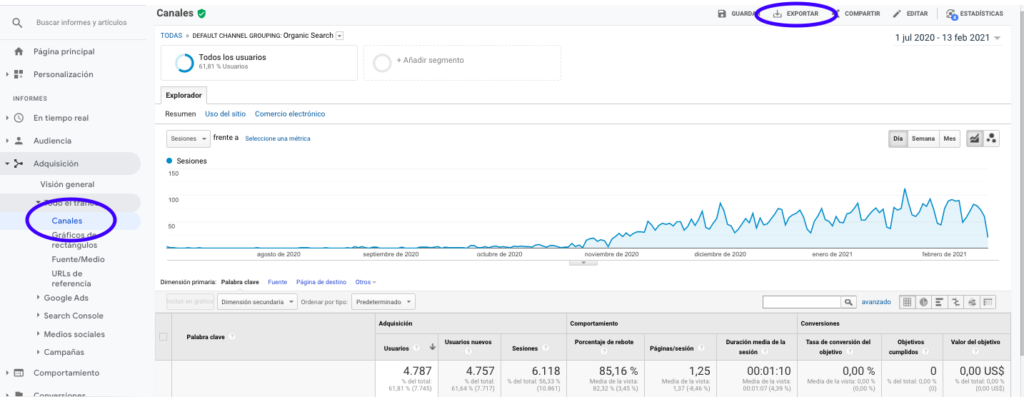
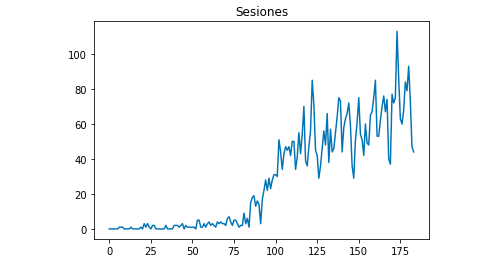
データをExcelファイルとしてエクスポートした後、Pandasを使用してノートブックにインポートできます。 このようなデータを含むExcelファイルにはさまざまなタブが含まれるため、月間トラフィックを含むタブは、以下のコードの引数として指定する必要があることに注意してください。 最後の行にはセッションの総数が含まれているため、モデルが歪むため、最後の行も消去します。
パンダをpdとしてインポートします df = pd.read_excel('.xlsx'、sheet_name = "") df = df.drop(len(df)-1) Matplotlibを使用して、データがどのように見えるかを描くことができます。 matplotlibからインポートpyplot df ["Sesiones"]。plot(title = "Sesiones") pyplot.show()
GoogleAnalyticsAPIの使用
まず、Google Analytics APIを利用するには、Googleのデベロッパーコンソールでプロジェクトを作成し、Google Analytics Reportingサービスを有効にして、資格情報を取得する必要があります。 Jean-Christophe Chouinardは、この記事でこれを設定する方法を非常によく説明しています。
資格情報を取得したら、リクエストを行う前に認証する必要があります。 認証は、Googleの開発者コンソールから最初に取得した資格情報ファイルを使用して行う必要があります。 また、使用するプロパティのGAビューIDをコードに書き留める必要があります。
apiclient.discoveryインポートビルドから oauth2client.service_accountからインポートServiceAccountCredentials SCOPES = ['https://www.googleapis.com/auth/analytics.readonly'] KEY_FILE_LOCATION ='' 見る_ 資格情報=ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION、SCOPES) analytics = build('analyticsreporting'、'v4'、credentials = credits)
認証後、リクエストを行うだけです。 毎日のオーガニックセッションに関するデータを取得するために使用する必要があるのは次のとおりです。
response = analytics.reports()。batchGet(body = {
'reportRequests':[{
'viewId':VIEW_ID、
'dateRanges':[{'startDate': '2020-09-01'、'endDate': '2021-01-31'}]、
'メトリクス':[
{"式": "ga:sessions"}
]、 "寸法":[
{"名前": "ga:date"}
]、
"filtersExpression": "ga:channelGrouping =〜Organic"、
"includeEmptyRows": "true"
}]})。実行する()dateRangesで時間の範囲を選択することに注意してください。 私の場合、9月1日から1月31日までのデータを取得します:[{'startDate': '2020-09-01'、'endDate': '2021-01-31'}]
この後、応答ファイルをフェッチするだけで、オーガニックセッションのある日をリストに追加できます。
list_values = [] for x in response ["reports"] [0] ["data"] ["rows"]: list_values.append([x ["dimensions"] [0]、x ["metrics"] [0] ["values"] [0]])
ご覧のとおり、Google Analytics APIの使用は非常に簡単で、多くの目的に使用できます。 この記事では、Google Analytics APIを使用してアラートを作成し、パフォーマンスの低いページを検出する方法について説明しました。

リストをデータフレームに適合させる
Prophetを利用するには、「ds」と「y」という名前を付ける必要のある2つの列を持つデータフレームを入力する必要があります。 Excelファイルからデータをインポートした場合は、すでにデータフレームとしてデータが含まれているため、列に「ds」と「y」という名前を付けるだけで済みます。
df.columns = ['ds'、'y']
APIを使用してデータを取得した場合は、リストをデータフレームに変換し、必要に応じて列に名前を付ける必要があります。
パンダからインポートDataFrame df_sessions = DataFrame(list_values、columns = ['ds'、'y'])
モデルのトレーニング
必要な形式のデータフレームを取得したら、次の方法でモデルを非常に簡単に決定およびトレーニングできます。
fbprophetをインポートする fbprophetからimportProphet モデル=Prophet() model.fit(df_sessions)
予測を行う
最後に、モデルをトレーニングした後、予測を開始できます。 予測を進めるには、最初に、予測したい時間の範囲を含むリストを作成し、日時の形式を調整する必要があります。
パンダからインポートto_datetime Forecast_days = [] range(1、28)のxの場合: 日付="2021-02-"+ str(x) Forecast_days.append([date]) Forecast_days = DataFrame(forecast_days) Forecast_days.columns = ['ds'] Forecast_days ['ds'] = to_datetime(forecast_days ['ds'])
この例では、2月からのすべての日を含むデータフレームを作成するループを使用します。 そして今、それは以前に訓練されたモデルを使用するだけの問題です:
予測=model.predict(forecast_days)
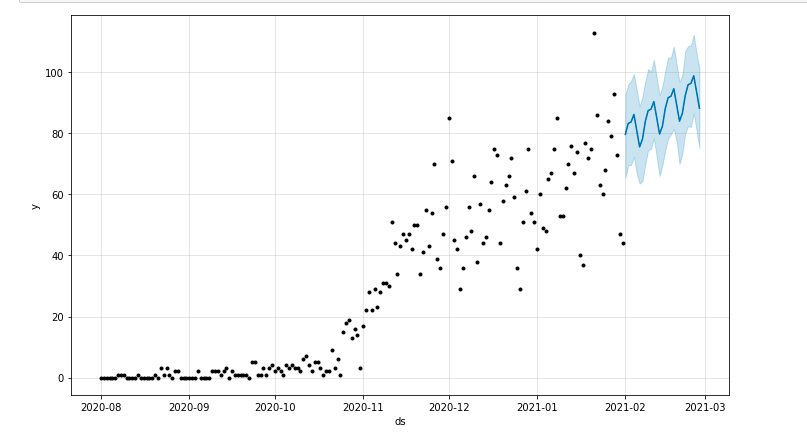
予測期間を強調するプロットを描くことができます。
matplotlibからインポートpyplot model.plot(予測) pyplot.show()
モデルの評価
最後に、モデルのトレーニングに使用されるデータから数日を削除し、それらの日のセッションを予測し、平均絶対誤差を計算することで、モデルの正確性を評価できます。
例として、1月からの過去12日間を元のデータフレームから削除し、毎日のセッションを予測し、実際のトラフィックを予測されたトラフィックと比較します。
まず、元のデータフレームから最後の12日間をポップで削除し、予測に使用される12日間のみを含む新しいデータフレームを作成します。
train = df_sessions.drop(df_sessions.index [-12:]) future = df_sessions.loc [df_sessions ["ds"]> train.iloc [len(train)-1] ["ds"]] ["ds"]
次に、モデルをトレーニングし、予測を行い、平均絶対誤差を計算します。 最後に、実際の予測値と実際の予測値の違いを示すプロットを描くことができます。 これは、ジェイソン・ブラウンリーが書いたこの記事から私が学んだことです。
sklearn.metricsからimportmean_absolute_error
numpyをnpとしてインポートします
numpyインポート配列から
#モデルをトレーニングします
モデル=Prophet()
model.fit(train)
#予測日に使用されるデータフレームを、預言者の必要な形式に適合させます。
future = list(future)
future = DataFrame(future)
future = future.rename(columns = {0:'ds'})
#予測します
予測=model.predict(future)
#実際の値と予測値の間のMAEを計算します
y_true = df_sessions ['y'] [-12:]。values
y_pred =Forecast['yhat']。values
mae = mean_absolute_error(y_true、y_pred)
#視覚的に理解するために最終出力をプロットします
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true、label ='Actual')
pyplot.plot(y_pred、label ='予測')
pyplot.legend()
pyplot.show()
print(前) 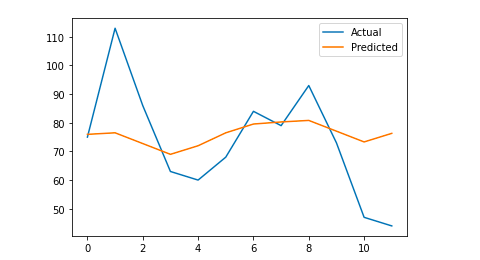
私の平均絶対誤差は13です。これは、予測されたモデルが実際のセッションよりも毎日13多いセッションを割り当てることを意味します。これは、許容可能なエラーのようです。
それはすべての人々です! この記事がおもしろく、目標を設定するためにSEO予測を開始できることを願っています。
さらに進む:OnCrawl Labs
この方法でトラフィックを予測することを楽しんだ場合は、SEOワークフロー用に事前にコード化されたプロジェクトを提供するOnCrawlのデータサイエンスおよび機械学習ラボであるOnCrawlLabsにも興味があります。
SEO予測では、OnCrawlLabsがSEO予測を改善するのに役立ちます。
- FacebookProphetアルゴリズムの背後にある理論とプロセスをよりよく理解する
- ロングテールキーワードのみのトラフィックやブランドキーワードのみのトラフィックなど、トラフィックのセグメントを分析します…
- ステップバイステップのプロセスに従って、履歴イベントを設定し、それらの影響と再発の可能性を調整します。