
フェイクニュースがSEOをどのように変えたか&あなたのサイトにさらに事実を追加する方法
公開: 2022-06-122017年4月21日の更新:フェイクニュースが再び脚光を浴びています。
グーグルはグーグルの検索結果で偽のニュースを呼び出すことについてより積極的になっている。 昨年10月、Googleは、パブリッシャーがスキーママークアップを使用して、ニュース記事の「ファクトチェック」タグをGoogleニュースに表示できることを発表しました。 このラベルは、ニュース発行者やファクトチェック組織によってファクトチェックされた情報を含む記事を識別します。」
今週、「ファクトチェック」ラベルがすべてのGoogle検索に公開されました。
Share the FactsボックスのHTMLコードをSchema.orgのClaimReviewスキーマでマークアップすると、検索結果に「ファクトチェック」ラベルが表示される可能性があります。 ライブSERPで見られる例を次に示します。
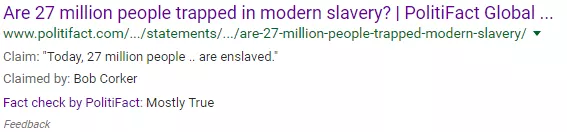
Googleのレーベルの背後にある技術は、Duke University Reporters'LabとAlphabetInc.のJigsawインキュベーター(AlphabetはGoogleの親会社)の合弁事業として開発されました。 これら2つのグループの努力により、Share the Factsウィジェットが作成されました。このウィジェットは、記事またはブログ投稿のHTMLコードに、クレーム/ステートメントとそれが正しいかどうかを含む「SharetheFacts」ボックスを挿入します。
ShareTheFacts.comはそのウィジェットコードについて次のように述べています。
「SharetheFactsボックスも完全に機械可読であり、インターネット全体からのファクトチェック結果の自動コレクションを組み立てる新しい方法を可能にします。」
検索結果のこの新しいリッチスニペットは、SEOのゲームチェンジャーです。 これは、ユーザーが結果をクリックする前でも、申し立ての正確性を確認できるようになったためです。 これは、偽のニュースの可視性を減らすためのGoogleの現在のイニシアチブの継続でもあります。 これについての詳細は、以下の元の投稿で読むことができます。
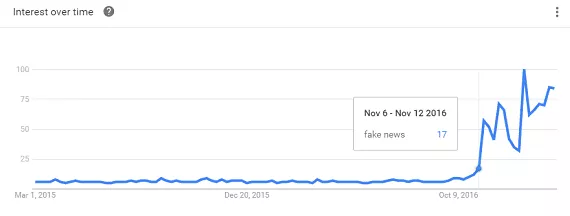
「フェイクニュース」の概念は、2016年の大統領選挙シーズンの終わりに時代精神に爆発しました。 それ以来、脚光を浴びています。
2016年12月にGoogleのCEOであるSundarPichaiにインタビューしたところ、Googleはフェイクニュースに関心を持っています。 ピチャイは言う:
グーグルでは、ユーザーに最も関連性のある正確な結果を提供することに常に気を配っています…(偽のニュースが)指摘された例がいくつかあり、明らかにそれが正しくありませんでした…最後の2つだけです偽のニュースとして特定したものから広告を削除することを発表した日。
ここでのPichaiの焦点は有料広告に向けられていますが、メディアでのフェイクニュースに関する話題が高まる中、SEOはフェイクニュースがオーガニック検索に与える影響について質問しています。
肝心なのは、Googleはユーザーのクエリの意図を正確に満たす質の高い回答をユーザーに提供する必要があるということです。
では、なぜSEOは気にする必要があるのでしょうか。 あなたは何ができますか? これらは、オーガニック検索マーケターが疑問に思っている質問です。

フェイクニュースを制御しようとしています
フェイクニュースはGoogleの制御能力を超えていますか? あなたは検索エンジンがそのスタンスをとらないに違いない。
GoogleとBingは、コンテンツの正確性をある程度検証することができます。 そして、検索エンジンはすでに、オーガニック検索結果でのフェイクニュースの拡散を緩和するのに適した位置にあります。
私たちが知っていることを読んでください:
- Googleが検索結果で事実上正確なコンテンツをアルゴリズムで宣伝する方法。
- Googleがコンピュータプログラムをトレーニングして、人間の品質評価者のガイドラインを新たに更新することで、偽のニュースを見つけて排除する方法。
- さらに、データベース駆動型データを使用して、信頼できる事実情報をコンテンツに統合する方法。
検索結果の事実の正確性に対するアルゴリズムによる解決策:Googleの事実のデータベース
2年前、SEOコミュニティは、ドメイン権限を測定する主要な方法として、バックリンクではなく事実に基づく証拠の使用を主張する著名なGoogle社員の最初の兆候を見ました。
ニューサイエンティストは、「Googleはリンクではなく事実に基づいてウェブサイトをランク付けしたい」というタイトルの記事でこのアイデアを要約しました。 この記事は、Googleがサイトを有機的にランク付けする方法への潜在的な変更を概説する長い研究論文を要約しました。
多くのSEOにとって、この論文は、Webページが正確な事実の証拠に適切に言及している場合、これがその信頼性に貢献し、したがって有機的なランキングを高める可能性があることを示唆しています。 これは理にかなっています。特に、コンテンツが王様であることは誰もが知っているからです。
さらに、この論文の主張は、「非構造化ドキュメントとさまざまなドメインのオラクルの構築」から事実の証拠を抽出してカタログ化する方法について、Googleが10年前に出願した特許と一致しています(私たちを強調)。
これらの文書から、次のことが推測できます。
- Googleには、何年にもわたって構築されてきた事実の証拠の大規模なリポジトリがあり、必要に応じて参照できます。
- Googleは、サイトの実際の正確性を測定することに非常に関心を持っているため、特定のユーザーに質問に対する正しい回答が提供されるようにすることができます。
グーグルや他の検索エンジンが正確な事実を非常に重視している場合、SEOは事実とフィクションの公開がそれらにどのように影響するかを認識することが不可欠です。

さらに、Googleが偽のニュースを公開しているサイトの可視性を減らすためにアルゴリズム的に行動を起こすことに取り組んでいるといういくつかの証拠があります…
検索品質評価者ガイドラインの更新
グーグルは不正確な事実のためにサイトにペナルティを課すことについて公式には何も言っていないが、事実情報が検索エンジンの目に重要であるという兆候が見られている。
先週、Googleは検索品質評価ガイドラインの更新を公開しました。 Jennifer Sleggは、何が変更されたかをまとめた投稿で、アルゴリズムによるアクションが、人間の品質評価者がWeb上の偽のニュースページを特定するのに役立つガイドラインの意図された目標であることを示唆しています。
「(GoogleエンジニアのPaul)Haahrは、評価者からトレーニングデータを取得するには、ガイドラインにこれらの特定の変更を加える必要があると述べました。 また、トレーニングデータの必要性は、偽のニュース、憎悪サイト、または疑わしい裏付けのない理論や主張を持つ他のサイトのカテゴリに分類されるサイトをアルゴリズムで検出してダウンランクする方法を探していることを意味します。」
「フェイクニュース」というラベルが付けられないようにするための手順
検索エンジンの目から見て権威あるものとして認識されることは容易ではありません。 Googleの事実上の正確性チェックに合格するためにあなたがしなければならないことは次のとおりです。
- 可能な限り、信頼できるソースを使用してください。
- コンテンツを確認する際のファクトチェック。 あなたのページで事実として渡されたものの検証を探してください。
- 虚偽の可能性がある情報をユーザーと共有することは避けてください。
そして、ここにもう1つのプロのヒントがあります。 可能な場合は、データベース駆動型データを使用して、信頼できる事実情報をコンテンツに統合します。
このヒントの例を次に示します。 不動産サイトは、特定の地域に関する情報をユーザーに提供することに特に関心があります。 目的は、人々が家の領域についてもっと学ぶのを助け、それが今度は回心を促進することです。
Truliaが物件リストページに公開しているローカルデータは、地域の人口統計、近隣の企業、学校、犯罪統計です。 これらの統計は、サードパーティのデータベースから取得されます。 これらの公開されている統計を含めることは、Googleがこれらの事実を認識し、問題の物件についてより多くを学ぶことを目的として訪問者を支援する貴重な情報としてそれらを評価するため、有利です。
したがって、この情報をページの残りのコンテンツに追加することで、Trulia(および同じことを行う他の不動産サイト)は、ユーザーのワンストップ情報ショップになることで、クエリの意図をより適切に満たすことができます。
同様に、もう1つの有名なブランドであるパブリックストレージは、ユーザーエクスペリエンスを向上させるため、またはクエリの目的をより適切に満たすために、一部のページにパブリックデータを含めています。
以下は、地域に関するインデックス可能なコンテンツを含む[都市情報]タブを含むストレージ施設の都市ページのスクリーンショットです。
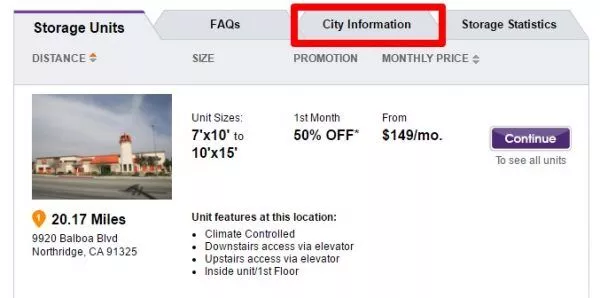
繰り返しになりますが、この情報だけを含めることはパブリックストレージを最適なサイトにするわけではありませんが、ユーザーエクスペリエンスを向上させると同時に、より充実した意味のある方法でクエリの意図を実現します。
要約すると、これらのような関連するデータベースオプションが業界または関連する業種で利用できる場合は、次の目的でそれらをコンテンツに(適切に)統合します。
- クエリの意図をよりよく満たす。
- UXを改善します。
- あなたのページが特徴とする正確な事実情報に追加してください。
- 検索者のためのワンストップショップとして、競合他社とは一線を画すサイトを設定します。
- コンテンツを検証可能に正確にします。
サイトのコンテンツで機能する可能性のあるデータソースを探すことに興味がある場合は、Google Public Data、Data.gov、またはQliqから始めることができます。 ここでマイニングできるデータベースがたくさんあります。
事実が検証されるフェイクニュースの世界では、正確な情報でコンテンツをサポートすることにより、ページを際立たせます。
データベース駆動型コンテンツに関するクイック警告
権威を測定する方法として事実を使用することがすべてではありません、すべてのランキング要素を終わらせてください。
2015年、GoogleのGaryIllyesとBingのDuaneForresterは、公開データだけでサイトを構築することに反対しました。
明らかに、検索エンジンはあなたが参照している公開データを見たり知ったりしているので、既存の機関をランク付けしようとすることは最善の戦略ではありません。
また、検索エンジンは他の要素も考慮しているため、データのみを提供しても自動的に最適になるわけではありません。 上記のTruliaとPublicStorageで見たように、データと事実だけでは不十分です。 100%のファクトを持つWebページは、同じファクト、元のコンテンツ、優れたUXを備えた競合ページを上回ることを期待するべきではありません。
Googleはフェイクニュースを抑制するために行動を起こしますか?
偽のニュースを特定することに関する懸念を反映するように検索品質評価ガイドラインを更新することにより、Googleは、価値のないページをページ1のランキングにすり抜けさせようとしていないことを示しました。
グーグルが偽のニュースや事実上不正確なコンテンツに対してアルゴリズム的な行動を取るのか、それとも単に手動の行動を使うのかはまだ100パーセント明確ではありません。 しかし、私たちが見てきたすべてのことから、Googleには、有機的な結果で不正確な事実情報を持つサイトを抑制する自動化されたプロセスを最終的に実装する手段があります。 検索エンジンはすでに正確な情報を提供するために非常に長い時間を費やしているので、これは単に彼らの既存の努力の継続であるでしょう。
あなたが見ているものが好きなら、ブルースクレイブログを購読してください。