
HTMLページから関連するテキストコンテンツを抽出する方法は?
公開: 2021-10-13環境
OncrawlのR&D部門では、Webページのセマンティックコンテンツに付加価値を付けることをますます求めています。 自然言語処理(NLP)の機械学習モデルを使用すると、SEOに真の付加価値をもたらすタスクを実行できます。
これらのタスクには、次のようなアクティビティが含まれます。
- ページのコンテンツを微調整する
- 自動要約の作成
- 記事に新しいタグを追加するか、既存のタグを修正します
- Google検索コンソールのデータに従ってコンテンツを最適化する
- 等
この冒険の最初のステップは、これらの機械学習モデルが使用するWebページのテキストコンテンツを抽出することです。 Webページについて話すとき、これにはHTML、JavaScript、メニュー、メディア、ヘッダー、フッターなどが含まれます。コンテンツを自動的かつ正しく抽出することは簡単ではありません。 この記事を通して、私は問題を調査し、このタスクを達成するためのいくつかのツールと推奨事項について議論することを提案します。
問題
Webページからテキストコンテンツを抽出するのは簡単に思えるかもしれません。 たとえば、数行のPythonを使用すると、いくつかの正規表現(regexp)、BeautifulSoup4などの解析ライブラリが完成します。
ますます多くのサイトがVue.jsやReactなどのJavaScriptレンダリングエンジンを使用しているという事実を数分間無視すると、HTMLの解析はそれほど複雑ではありません。 クロールでJSクローラーを利用してこの問題を解決したい場合は、「JavaScriptでサイトをクロールする方法」をお読みになることをお勧めします。
ただし、意味のある、できるだけ有益なテキストを抽出したいと思います。 たとえば、ジョンコルトレーンの最後の死後のアルバムに関する記事を読むときは、メニュー、フッターなどを無視します。もちろん、HTMLコンテンツ全体を表示しているわけではありません。 ほとんどすべてのページに表示されるこれらのHTML要素は、定型文と呼ばれます。 私たちはそれを取り除き、一部だけを残したいと思っています:関連情報を運ぶテキスト。
したがって、処理のために機械学習モデルに渡したいのはこのテキストだけです。 そのため、抽出は可能な限り定性的であることが不可欠です。
ソリューション
全体として、メニューやその他のサイドバー、連絡先要素、フッターリンクなど、メインテキストに「ぶら下がっている」すべてのものを取り除きたいと思います。これを行うにはいくつかの方法があります。 私たちは主にPythonまたはJavaScriptのオープンソースプロジェクトに関心があります。
jusText
jusTextは、博士論文「WebCorporaからのボイラープレートと重複コンテンツの削除」からPythonで提案された実装です。 このメソッドを使用すると、HTMLのテキストブロックを、さまざまなヒューリスティックに従って「良い」、「悪い」、「短すぎる」に分類できます。 これらのヒューリスティックは、主に単語数、テキスト/コード比、リンクの有無などに基づいています。アルゴリズムの詳細については、ドキュメントを参照してください。
トラフィラチュラ
同じくPythonで作成されたtrafilaturaは、HTML要素タイプとそのコンテンツの両方に関するヒューリスティックを提供します。たとえば、テキストの長さ、HTML内の要素の位置/深さ、単語数などです。 trafilaturaは、jusTextを使用していくつかの処理を実行します。
読みやすさ
FirefoxのURLバーのボタンに気づいたことがありますか? これはリーダービューです。HTMLページから定型文を削除して、メインのテキストコンテンツのみを保持することができます。 ニュースサイトに使用するのは非常に実用的です。 この機能の背後にあるコードはJavaScriptで記述されており、Mozillaでは読みやすさと呼ばれています。 これは、Arc90ラボによって開始された作業に基づいています。
フランスミュジックのウェブサイトの記事でこの機能をレンダリングする方法の例を次に示します。 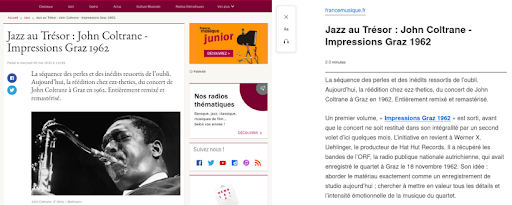
左側は元の記事からの抜粋です。 右側は、Firefoxのリーダービュー機能のレンダリングです。
その他
HTMLコンテンツ抽出ツールに関する調査により、他のツールも検討するようになりました。
- 新聞:ニュースサイト(Python)専用のコンテンツ抽出ライブラリ。 このライブラリは、OpenWebText2コーパスからコンテンツを抽出するために使用されました。
- ボイラーpy3はボイラーパイプライブラリのPythonポートです。
- ドラッグネットPythonライブラリもボイラーパイプに触発されています。
オンクロールデータ³
 もっと詳しく知る
もっと詳しく知る評価と推奨事項
さまざまなツールを評価および比較する前に、NLPコミュニティがこれらのツールのいくつかを使用してコーパス(大量のドキュメント)を準備しているかどうかを知りたいと思いました。 たとえば、GPT-Neoのトレーニングに使用されるThe Pileというデータセットには、Wikipedia、Openwebtext2、Github、CommonCrawlなどからの+800 GBの英語テキストがあります。BERTと同様に、GPT-Neoは型変換器を使用する言語モデルです。 これは、GPT-3アーキテクチャと同様のオープンソース実装を提供します。

記事「ThePile:言語モデリング用の多様なテキストの800GBデータセット」では、CommonCrawlのコーパスの大部分にjusTextを使用することに言及しています。 このグループの研究者は、さまざまな抽出ツールのベンチマークを実行することも計画していました。 残念ながら、彼らはリソース不足のために計画された仕事をすることができませんでした。 彼らの結論では、次のことに注意する必要があります。
- jusTextは時々あまりにも多くのコンテンツを削除しましたが、それでも良い品質を提供しました。 彼らが持っていたデータの量を考えると、これは彼らにとって問題ではありませんでした。
- trafilaturaは、HTMLページの構造を維持するのに優れていましたが、定型文が多すぎました。
評価方法は約30ページあります。 メインコンテンツを「手動」で抽出しました。 次に、さまざまなツールのテキスト抽出を、このいわゆる「参照」コンテンツと比較しました。 指標として、主に自動テキスト要約の評価に使用されるROUGEスコアを使用しました。
また、これらのツールを、HTML解析ルールに基づく「自家製」ツールと比較しました。 trafilatura、jusText、および当社の自家製ツールは、このメトリックの他のほとんどのツールよりも優れていることがわかりました。
ROUGEスコアの平均と標準偏差の表を次に示します。
| ツール | 平均 | 標準 |
|---|---|---|
| トラフィラチュラ | 0.783 | 0.28 |
| オンクロール | 0.779 | 0.28 |
| jusText | 0.735 | 0.33 |
| ボイラーピー3 | 0.698 | 0.36 |
| 読みやすさ | 0.681 | 0.34 |
| ドラッグネット | 0.672 | 0.37 |
標準偏差の値を考慮すると、抽出の品質は大きく異なる可能性があることに注意してください。 HTMLの実装方法、タグの一貫性、および言語の適切な使用により、抽出結果に多くのばらつきが生じる可能性があります。
最高のパフォーマンスを発揮する3つのツールは、trafilatura、この機会に「oncrawl」という名前の社内ツール、およびjusTextです。 jusTextはtrafilaturaによるフォールバックとして使用されるため、最初の選択肢としてtrafilaturaを使用することにしました。 ただし、後者が失敗してゼロワードを抽出する場合は、独自のルールを使用します。
trafilaturaコードは、数百ページのベンチマークも提供することに注意してください。 抽出されたコンテンツ内の特定の要素の有無に基づいて、精度スコア、f1スコア、および精度を計算します。 2つのツールが際立っています:trafilaturaとgoose3。 また、以下をお読みください。
- Webからコンテンツを抽出するための適切なツールの選択(2020)
- Githubリポジトリ:記事抽出ベンチマーク:オープンソースライブラリと商用サービス
結論
HTMLコードの品質とページタイプの不均一性により、高品質のコンテンツを抽出することは困難です。 The PileとGPT-Neoの背後にいるEleutherAIの研究者が発見したように、完璧なツールはありません。 すべてのボイラープレートが削除されていない場合、テキスト内の切り捨てられたコンテンツと残留ノイズの間にはトレードオフがあります。
これらのツールの利点は、コンテキストがないことです。 つまり、コンテンツを抽出するために、ページのHTML以外のデータは必要ありません。 Oncrawlの結果を使用すると、サイトのすべてのページで特定のHTMLブロックが出現する頻度を使用して、それらを定型文として分類するハイブリッド方式を想像できます。
Webで出会ったベンチマークで使用されているデータセットについては、ニュース記事やブログ投稿など、同じタイプのページであることがよくあります。 保険、旅行代理店、eコマースなどのサイトが必ずしも含まれているわけではなく、テキストコンテンツの抽出がより複雑な場合があります。
ベンチマークに関しては、リソースが不足しているため、スコアのより詳細なビューを取得するには30ページ程度では不十分であると認識しています。 理想的には、ベンチマーク値を改善するために、より多くの異なるWebページを用意したいと考えています。 また、goose3、html_text、inscriptisなどの他のツールも含めたいと思います。