
新時代の UX: AI 製品の設計アプローチを進化させる
公開: 2024-01-18ChatGPT が 1 年前に登場するまでは、人工知能 (AI) と機械学習 (ML) は専門家やデータ サイエンティスト、つまり多くのニッチな経験と専門分野の知識を持つチームの神秘的なツールでした。 さて、状況は異なります。
おそらく、あなたの会社が OpenAI の GPT または別の LLM (大規模言語モデル) を使用して生成 AI 機能を製品に組み込むことに決めたためにこの記事を読んでいるのでしょう。 その場合は、興奮している (「素晴らしい新機能を作るのはとても簡単だ!」) か、または圧倒されている (「なぜ毎回異なる出力が得られるのか、どうすれば希望どおりにできるのか?」 )を感じているかもしれません。たぶんあなたは両方を感じているでしょう!
AI との連携は新しい挑戦かもしれませんが、恐れることはありません。 この投稿では、「従来の」ML アプローチの設計に何年も費やした私の経験を簡単な質問にまとめ、AI の設計を開始するときに自信を持って前進できるようにします。
異なる種類の UX デザイン
まず、AI UX デザインがこれまで行ってきたものとどのように異なるのかについての背景を説明します。 (注: この投稿では、AI と ML を同じ意味で使用します。) Jesse James Garrett の UX デザインの 5 層モデルについてはご存知かもしれません。
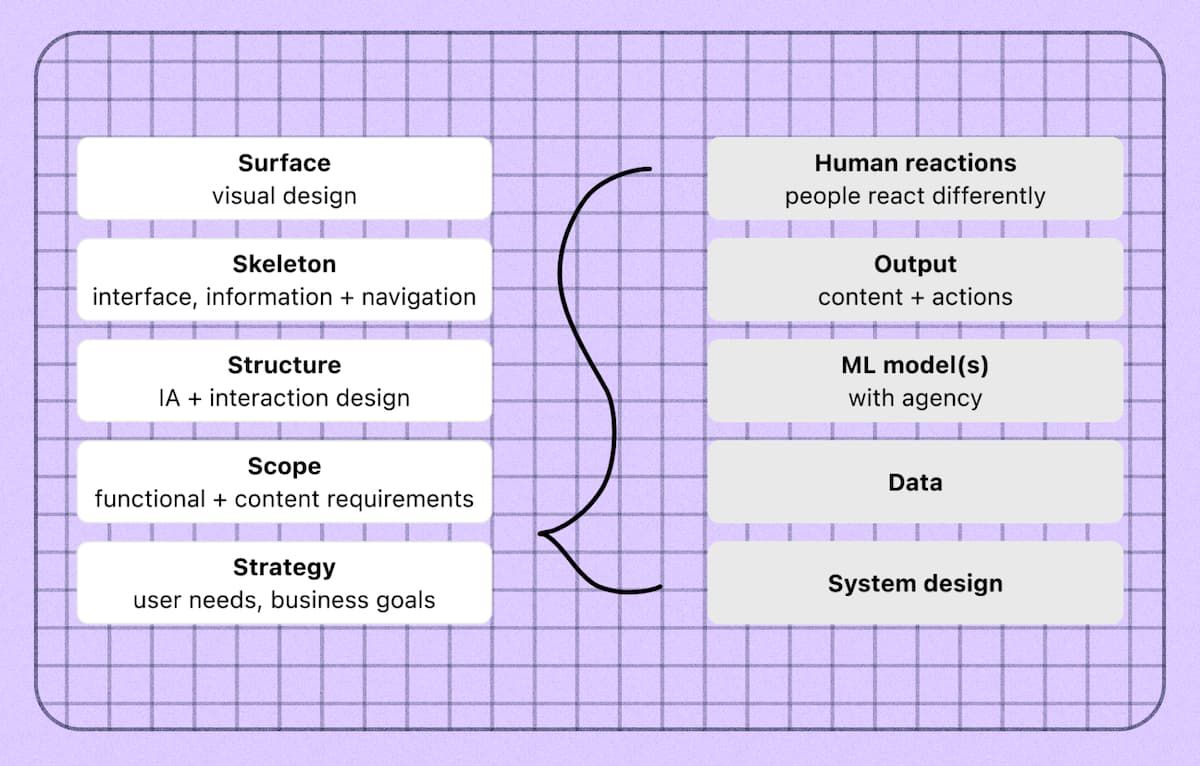
Jesse James Garrett のユーザー エクスペリエンスの要素図
Garrett のモデルは決定論的システムにはうまく機能しますが、下流の UX の考慮事項に影響を与える機械学習プロジェクトの追加要素を捉えていません。 ML を使用するということは、モデルの戦略レイヤー内およびその周囲に多数の追加レイヤーを追加することを意味します。 ここで、慣れ親しんだデザインに加えて、以下についても深く理解する必要があります。
- システムの構築方法。
- 機能にどのようなデータが利用可能か、機能に何が含まれているか、機能がどの程度優れているか、信頼性があるか。
- 使用する ML モデルとその長所と短所。
- 機能が生成する出力、出力がどのように変化するか、いつ失敗するか。
- この機能に対する人間の反応は、あなたが期待したり望んだりするものとは異なる可能性があります。
「どうすればこれができるだろうか?」と自問するのではなく、 既知の範囲が限定された問題に対して、「これを実行できるか?」と疑問に思うかもしれません。
特に LLM を使用している場合は、まったく新しい機能を解放するテクノロジから逆算して作業することになる可能性があり、既知の問題や、解決可能だと考えたことのない問題を解決するのに LLM が適切であるかどうかを判断する必要があります。前に。 通常よりも高いレベルで考える必要がある場合があります。情報の単位を表示するのではなく、大量の情報を統合して、傾向、パターン、予測を表示する必要がある場合があります。
「あなたは、動的で入力にリアルタイムで反応する確率システムを設計しています。」
最も重要なことは、指示されたとおりに実行する決定論的なシステムを設計するのではなく、動的で入力にリアルタイムで反応する確率的なシステムを設計していることです。その結果、時には予期せぬ、または説明不可能な結果や動作が発生します。そして、トレードオフを考慮することは曖昧な作業になる可能性があります。 ここで、私の 5 つの重要な質問が役に立ちます。答えを提供するのではなく、不確実性に直面して次のステップに進むのを助けるためです。 飛び込んでみましょう。
1. 良好なデータをどのように確保しますか?
データ サイエンティストは、「ガベージ イン、ガベージ アウト」という言葉が大好きです。 不適切なデータから始めた場合、最終的に優れた AI 機能が完成する可能性は通常ありません。
たとえば、オンライン ヘルプ センターの記事など、情報ソースのコレクションに基づいて回答を生成するチャットボットを構築している場合、記事の品質が低いとチャットボットの品質も低くなります。
Intercom のチームが 2023 年初頭に Fin を立ち上げたとき、私たちは、多くのお客様が Fin を使い始めて、どのような情報が存在するのか、存在しないのか、あるいは明確であるかを知るまで、ヘルプ コンテンツの品質を正確に把握できていないことに気づきました。それらの内容。 便利な AI 機能への欲求は、チームにとってデータの品質を向上させる優れた機能となる可能性があります。
では、良いデータとは何でしょうか? 良いデータは次のとおりです。
- 正確:データは現実を正確に表しています。 つまり、私の身長が 1.7 メートルであれば、健康記録にはそのように記載されます。 身長が1.9メートルとは書いてありません。
- 完了:データには必要な値が含まれています。 予測を行うために身長の測定が必要な場合、その値はすべての患者の健康記録に存在します。
- 一貫性:データは他のデータと矛盾しません。 高さのフィールドが 2 つあり、1 つは 1.7 メートル、もう 1 つは 1.9 メートルというものではありません。
- 新鮮:データは最近のものであり、最新です。 現在成人している場合、健康記録に 10 歳の時の身長が反映されるべきではありません。身長が変わった場合は、それを反映するように記録も変更する必要があります。
- ユニーク:データは重複しません。 私の医師は私のために 2 つの患者記録を持っているべきではありません。そうしないと、どちらが正しいのかわかりません。
本当に高品質のデータが大量に存在することはまれなので、AI 製品を開発する際には品質と量のトレードオフが必要になる場合があります。 より小規模な (ただし、代表的なサンプルであることが望ましい) データを手動で作成したり、古い不正確なデータを除外して信頼性の高いセットを作成したりできる場合があります。
データの品質を正確に把握し、最初はデータが良くない場合は改善する計画を立てて、設計プロセスを開始するようにしてください。
2. 設計プロセスをどのように調整しますか?
いつものように、解決したい問題に対する理想的なユーザー エクスペリエンスを決定するには、忠実度の低い調査から始めると便利です。 おそらく本番環境では見ることはありませんが、この北極星はあなたとチームの調整を助け、興奮させるだけでなく、それが実際にどの程度実現可能であるかを調査するための具体的な出発点を提供することもできます。
「システムがどのように動作するか、データがどのように収集され使用されるか、モデル出力で見られる差異が設計に反映されているかどうかを理解するために時間をかけてください。」
これを取得したら、システム、データ、コンテンツ出力を設計します。 北極星に戻って、「私が設計したものは実際に可能ですか?」と尋ねてください。 X または Y がうまく機能しない場合のバリエーションは何ですか?」
時間をかけて、システムがどのように動作するか、データがどのように収集および使用されるか、モデルの出力に見られる差異を設計が捉えているかどうかを理解してください。 AI では、出力が低いとエクスペリエンスも低下します。 チャットボットの例では、これは、十分な詳細が示されていない、的外れな質問に答えている、または質問すべきときに質問を明確にしていない回答のように見える可能性があります。
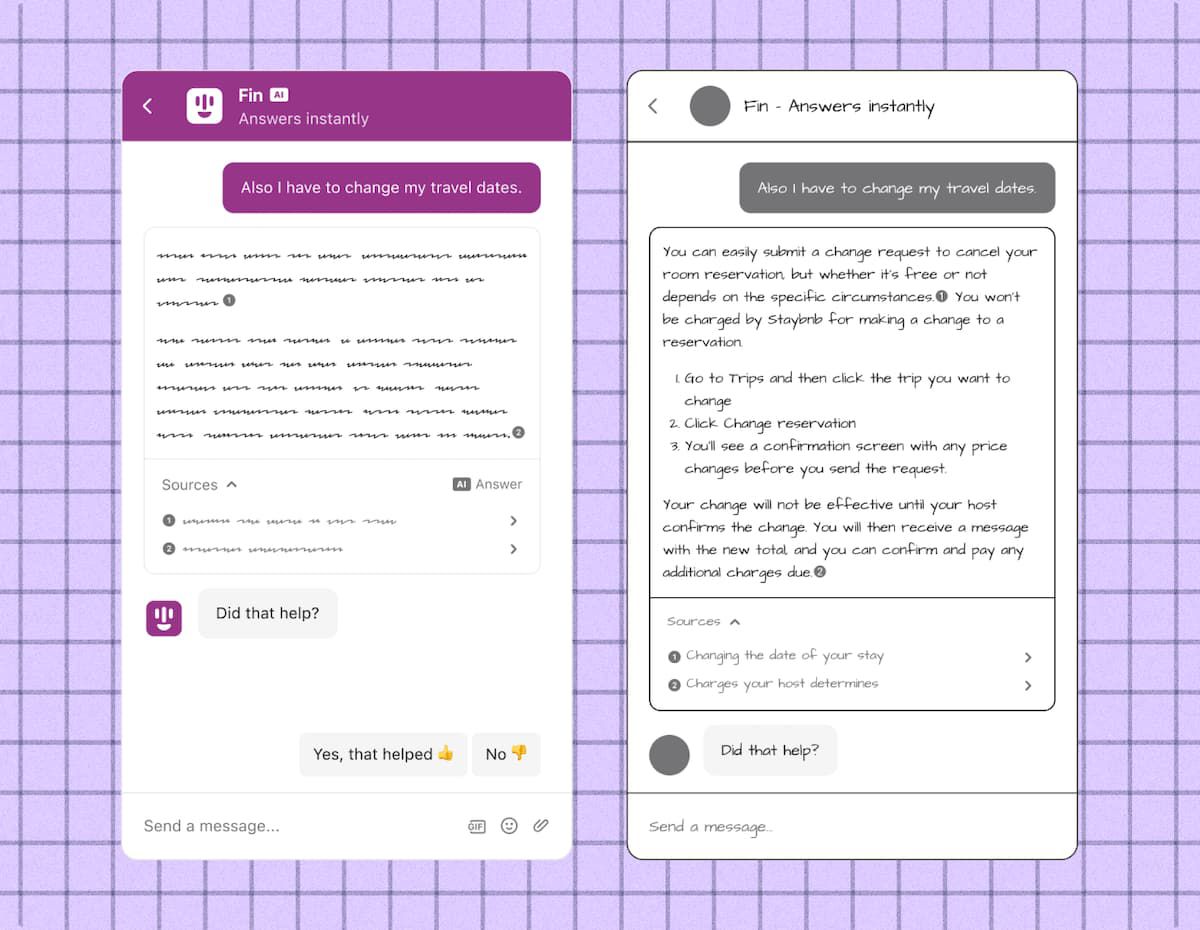
 AI チャットボットの出力を表示する方法の 2 つの例
AI チャットボットの出力を表示する方法の 2 つの例
上の図の左側の例は、Fin チャットボットの開発時に確認した多くの初期の出力に似ています。これらの出力は正確ではありましたが、回答をインラインで記述するのではなく元の記事に戻って参照しているため、あまり有益でも有用でもありませんでした。 デザインは、右側の例に到達するのに役立ちます。これには、明確な手順と書式設定を備えた、より完全な答えが含まれています。
出力の内容をエンジニアに任せてはいけません。出力のエクスペリエンスはデザインされるべきです。 LLM ベースの製品に取り組んでいる場合、これは、プロンプト エンジニアリングを試して、出力の形と範囲がどうあるべきかについて独自の視点を開発する必要があることを意味します。
また、潜在的なエラー状態、リスク、制約の新しいセットを設計する方法を検討する必要もあります。
エラー状態
- コールド スタートの問題:顧客が初めて機能を使用するとき、データがほとんど、またはまったくない可能性があります。 最初からどのようにして価値を得ることができるのでしょうか?
- 予測なし:システムには答えがありません。 それでは何が起こるでしょうか?
- 悪い予測:システムの出力が不十分でした。 ユーザーはそれが間違っていることに気づくでしょうか? 彼らはそれを直すことができるでしょうか?
リスク
- 誤検知、天気予報では雨が予想されていたのに、雨が降らなかった場合などです。 あなたの製品でこのようなことが起こった場合、マイナスの結果が生じますか?
- 偽陰性、天気予報では雨が降らないと予想されていたのに、土砂降りが降った場合などです。 あなたの機能でこれが起こった場合、結果はどうなりますか?
- 現実世界のリスク(ML の出力が人々の生活、生計、機会に直接影響を与える場合など)。 これらはあなたの製品に当てはまりますか?
新しい制約
- ユーザーの制約: システムの動作方法に関する誤ったメンタル モデル、製品に対する非現実的な期待や恐れ、時間の経過とともに満足してしまう可能性など。
- API やストレージ、コンピューティングのコスト、レイテンシ、稼働時間、データの可用性、データ プライバシー、セキュリティなどの技術的な制約。 これらは主にエンジニアの問題ですが、ユーザー エクスペリエンスに直接影響を与える可能性もあるため、制限と可能性を理解する必要があります。
3. ML が失敗した場合、どのように機能しますか?
「もし」ではなく「いつ」。 AI 製品が本番環境で失敗することに驚いた場合は、事前に十分なテストを行っていなかったことになります。 チームは、機能を顧客に出荷する直前まで待つのではなく、ビルド プロセス全体を通じて製品と出力をテストする必要があります。 厳密なテストにより、製品がいつどのように故障する可能性があるかを確実に把握できるため、それらの故障を軽減するユーザー エクスペリエンスを構築できます。 製品を効果的にテストする方法をいくつか紹介します。

デザインのプロトタイプから始める
可能な限り実際のデータを使用してプロトタイプを作成します。 ここでは「Lorem ipsum」が敵です。実際の例を使用して製品のストレス テストを行ってください。 たとえば、AI チャットボット Fin を開発する場合、実際のヘルプセンター記事をソース資料として使用して、実際の顧客の質問に対する回答の品質をテストすることが重要でした。
2 人のデザイナーが AI 生成の回答を提供するチャットボットの設計にどのようにアプローチするかを示す例
この比較では、左側のカラフルな例の方が視覚的に魅力的であることがわかりますが、回答生成エクスペリエンスの品質については詳しく説明されていません。 視覚的な忠実度は高くなりますが、コンテンツの忠実度は低くなります。 右側の例は、コンテンツの忠実度が高いため、AI 応答が実際に高品質であることをテストおよび検証する場合により有益です。
デザイナーは、多くの場合、視覚的な忠実度の範囲に沿って作業することに慣れています。 ML 用に設計している場合は、出力がユーザーにとって十分な品質であることを完全に検証するまで、コンテンツの忠実度の範囲に沿って作業することを目指す必要があります。
カラフルな Fin のデザインは、チャットボットが顧客が料金を支払うほど十分に質問に回答できるかどうかを判断するのには役立ちません。 たとえ基本的なものであっても、実際のデータからの実際の出力を示すプロトタイプを顧客に示すことで、より良いフィードバックが得られます。
大規模なテスト
一貫して高品質の出力が得られたと思われる場合は、バックテストを行って、出力の品質をより大規模に検証してください。 これは、エンジニアに遡って、出力の品質を知っている、または確実に判断できるより多くの履歴データに対してアルゴリズムを実行させることを意味します。 出力の品質と一貫性を確認し、意外な点がないかを明らかにする必要があります。
テストとして実用最小限の製品 (MVP) にアプローチする
MVP またはベータ リリースは、残りの疑問を解決し、さらに潜在的な驚きを見つけるのに役立ちます。 MVP を既成概念にとらわれずに考えてください。製品内で構築することも、単なるスプレッドシートであることもできます。
「アウトプットを機能させてから、それを中心に製品のエンベロープを構築する」
たとえば、記事のグループをトピック領域にクラスタリングしてからトピックを定義する機能を作成している場合は、完全な UI を構築する前にクラスタリングを適切に行っていることを確認する必要があります。 クラスターが悪い場合は、別の方法で問題にアプローチするか、クラスター サイズを調整するために別の操作を許可する必要がある場合があります。
出力と名前付きトピックの単なるスプレッドシートである MVP を「構築」し、それを行った方法に顧客が価値を見出すかどうかを確認したい場合があります。 出力を機能させてから、それを中心に製品エンベロープを構築します。
MVP の起動時に A/B テストを実行する
機能のプラスまたはマイナスの影響を測定する必要があるでしょう。 デザイナーとして、あなたはおそらくこれの設定を担当することはありませんが、結果を理解するよう努める必要があります。 指標はあなたの製品が価値があることを示していますか? 表示されている内容に基づいて変更する必要がある可能性のある UI または UX の交絡要因はありますか?
「製品の使用状況から得られるテレメトリと定性的なユーザー フィードバックを組み合わせて使用すると、ユーザーが機能とどのようにやり取りしているか、そしてユーザーがその機能から得ている価値をよりよく理解できます。」
Intercom AI チームでは、十分な量のインタラクションを伴う新機能をリリースするたびに A/B テストを実行し、数週間以内に統計的有意性を判断します。 ただし、一部の機能については、ボリュームがありません。その場合は、製品の使用状況からのテレメトリと定性的なユーザー フィードバックを組み合わせて使用することで、ユーザーが機能とどのようにやり取りしているか、およびユーザーがそこから得ている価値をよりよく理解できます。それ。
4. 人間はどのようにシステムに適応するのでしょうか?
AI 製品を構築する場合、製品使用ライフサイクルには 3 つの主要な段階があり、考慮する必要があります。
- 使用前に機能を設定します。 これには、製品が動作する自律性レベルの選択、予測に使用されるデータのキュレーションとフィルタリング、アクセス制御の設定などが含まれる場合があります。 この例としては、SAE International の自動運転車自動化フレームワークが挙げられます。このフレームワークでは、車両が単独で実行できることと、人間の介入がどの程度許可または要求されるかを概説しています。
- 動作中の機能を監視します。 システムの動作中に軌道を維持するには人間が必要ですか? 品質を保証するために承認ステップが必要ですか? これは、AI 出力がエンドユーザーに送信される前の動作チェック、人間によるガイダンス、またはライブ承認を意味する場合があります。 この例としては、AI 記事執筆アシスタントが挙げられます。AI 記事執筆アシスタントは、ヘルプ記事の下書きへの編集を提案し、公開する前にライターが承認する必要があります。
- リリース後に機能を評価します。 これは通常、レポートを作成し、フィードバックを提供または実行し、長期にわたるデータの変化を管理することを意味します。 この段階で、ユーザーは自動化システムのパフォーマンスを振り返り、過去のデータと比較したり、品質を調べて改善方法を決定したりします(モデルのトレーニング、データの更新、またはその他の方法を通じて)。 この例としては、エンド ユーザーが AI チャットボットにどのような質問をしたのか、その回答は何だったのか、将来の質問に対するチャットボットの回答を改善するために行うことができる変更の提案を詳細に記載したレポートが挙げられます。
これら 3 つのフェーズを使用して、製品開発ロードマップを知らせることもできます。 同じまたは非常に類似したバックエンド ML テクノロジーに基づいた複数の製品と複数の UI を使用し、人間が関与する部分を変更するだけで済みます。 ライフサイクルのさまざまな時点で人間が関与すると、製品の提案が完全に変わる可能性があります。
また、時間の観点から AI 製品設計にアプローチすることもできます。つまり、特定の時点で人間が必要になる可能性のあるものを今構築しますが、エンド ユーザーが出力と品質に慣れたら、人間を削除するか、別の段階に移動する計画を立ててください。 AI機能のこと。
5. システムに対するユーザーの信頼をどのように構築しますか?
AI を製品に導入すると、システム内で動作する主体性を持つモデルを導入することになります。これまではユーザー自身だけが主体性を持っていました。 これにより、顧客にとってリスクと不確実性が増大します。 当然のことながら、製品に対する監視のレベルは高まり、ユーザーの信頼を獲得する必要があります。
いくつかの方法でそれを試みることができます。
- 顧客が出力をエンド ユーザーに公開せずに比較したり、出力を確認したりできる「ダーク ローンチ」またはサイドバイサイド エクスペリエンスを提供します。 これは、プロセスの初期に行ったバックテストのユーザー向けバージョンのようなものだと考えてください。ここでのポイントは、機能や製品が提供する出力の範囲と品質について顧客に自信を与えることです。 たとえば、Intercom の Fin AI チャットボットを立ち上げたとき、顧客が自分のデータをアップロードしてボットをテストできるページを提供しました。
- まず人間の監視下で機能を起動します。 しばらくして良好なパフォーマンスが得られると、顧客は人間による監視なしで動作することを信頼するようになるでしょう。
- 機能が動作しない場合に簡単に機能をオフにできるようにします。 何かを台無しにしてそれを止められなくなるリスクがなければ、ユーザーは自分のワークフロー (特にビジネス ワークフロー) に AI 機能を導入するのが簡単になります。
- ユーザーが悪い結果を報告できるようにフィードバック メカニズムを構築し、理想的にはシステムがそれらの報告に基づいて動作し、システムを改善します。 ただし、顧客がすぐに改善されることを期待しないように、フィードバックがいつどのように実行されるかについては、必ず現実的な期待を設定してください。
- 堅牢なレポート メカニズムを構築して、顧客が AI のパフォーマンスとそこから得られる ROI を理解できるようにします。
製品によっては、ユーザーが経験を積んで製品に快適に感じられるように、これらを複数試してみることをお勧めします。
AIに関しては忍耐が美徳である
これら 5 つの質問が、AI 製品開発の新しい急速に変化する世界へ旅立つ際のガイドとなることを願っています。 最後のアドバイス: 製品をリリースするときは辛抱強く待ってください。 ML 機能を立ち上げて実行し、企業の好みの働き方に調整するには多大な労力がかかるため、導入曲線が予想とは異なる可能性があります。
「いくつかの AI 機能を構築すると、特定の顧客が新製品の発売に対してどのように反応するかがよりよくわかるようになります。」
おそらく、顧客が最大の価値を感じるまで、あるいは AI にはコストに見合う価値があり、より広範囲にユーザーに導入する必要があることを関係者に納得させるまでに、少し時間がかかると思われます。
あなたの機能に本当に興奮している顧客でも、データのクリーニングなどの準備作業が必要なため、または機能を開始する前に信頼を築くために取り組んでいるため、実装までに時間がかかる可能性があります。 どのような導入が期待されるかを予測するのは難しいかもしれませんが、いくつかの AI 機能を構築すると、特定の顧客が新しいリリースに対してどのように反応するかをよりよく把握できるようになります。
