
CTR曲線とは何ですか?Pythonで計算する方法は?
公開: 2022-03-22CTR曲線、つまり位置に基づくオーガニッククリック率は、検索エンジンの結果ページ(SERP)上の青いリンクの数が位置に基づいてCTRを取得していることを示すデータです。 たとえば、ほとんどの場合、SERPの最初の青いリンクが最も多くのクリック率を獲得します。
このチュートリアルの最後に、サイトのディレクトリに基づいてサイトのCTR曲線を計算したり、CTRクエリに基づいてオーガニックCTRを計算したりできるようになります。 私のPythonコードの出力は、サイトのCTR曲線を説明する洞察に満ちたボックスと棒グラフです。
初心者でクリック率の定義がわからない場合は、次のセクションで詳しく説明します。
有機CTRまたは有機クリックスルー率とは何ですか?
CTRは、オーガニッククリックをインプレッションに分割することで得られます。 たとえば、100人が「アップル」を検索し、30人が最初の結果をクリックした場合、最初の結果のクリック率は30/100 * 100 = 30%になります。
これは、100回の検索ごとに30%を取得することを意味します。 Google検索コンソール(GSC)の表示回数は、サーチャービューポートでのウェブサイトリンクの表示に基づいていないことを覚えておくことが重要です。 結果がサーチャーSERPに表示される場合、検索ごとに1つのインプレッションが得られます。
CTR曲線の用途は何ですか?
SEOの重要なトピックの1つは、オーガニックトラフィックの予測です。 いくつかのキーワードセットのランキングを向上させるには、より多くのシェアを獲得するために数千ドルを割り当てる必要があります。 しかし、企業のマーケティングレベルでの質問は、「この予算を割り当てることはコスト効率が良いか」ということです。
また、SEOプロジェクトの予算配分のトピックに加えて、将来のオーガニックトラフィックの増減の見積もりを取得する必要があります。 たとえば、競合他社の1つがSERPランクの位置で私たちを置き換えようと懸命に努力しているのを見た場合、これにはどれくらいの費用がかかりますか?
この状況または他の多くのシナリオでは、サイトのCTR曲線が必要です。
CTR曲線スタディを使用してデータを使用しないのはなぜですか?
簡単に答えると、SERPであなたのサイトの特徴を持っているウェブサイトは他にありません。
さまざまな業界やさまざまなSERP機能でCTR曲線について多くの調査が行われていますが、データがある場合は、サードパーティのソースに依存するのではなく、サイトでCTRを計算しないのはなぜですか。
これを始めましょう。
Pythonを使用したCTR曲線の計算:はじめに
位置に基づくGoogleのクリック率の計算プロセスに入る前に、基本的なPython構文を理解し、Pandasなどの一般的なPythonライブラリについて基本的に理解している必要があります。 これは、コードをよりよく理解し、自分のやり方でカスタマイズするのに役立ちます。
さらに、このプロセスでは、Jupyterノートブックを使用することを好みます。
位置に基づいてオーガニックCTRを計算するには、次のPythonライブラリを使用する必要があります。
- パンダ
- プロット
- カレイド
また、次のPython標準ライブラリを使用します。
- os
- json
前述したように、CTR曲線を計算する2つの異なる方法を検討します。 Pythonパッケージのインポート、プロット画像出力フォルダーの作成、出力プロットサイズの設定など、いくつかの手順は両方の方法で同じです。
#プロセスに必要なライブラリをインポートする OSのインポート jsonをインポートする パンダをpdとしてインポートします plotly.expressをpxとしてインポートします plotly.ioをpioとしてインポートします カレイドをインポート
ここでは、プロット画像を保存するための出力フォルダを作成します。
#プロット画像出力フォルダの作成
そうでない場合はos.path.exists('./ output plot images'):
os.mkdir('./ output plot images')
以下の出力プロット画像の高さと幅を変更できます。
#出力プロット画像の幅と高さを設定する pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
クエリCTRに基づく最初のメソッドから始めましょう。
最初の方法:クエリCTRに基づいてWebサイト全体または特定のURLプロパティのCTR曲線を計算します
まず、クリック率、平均掲載順位、インプレッションを含むすべてのクエリを取得する必要があります。 先月の完全な1か月分のデータを使用することをお勧めします。
これを行うために、GoogleDataStudioのGSCサイトインプレッションデータソースからクエリデータを取得します。 または、GSCAPIや「SearchAnalyticsfor Sheets」Googleスプレッドシートアドオンなど、任意の方法でこのデータを取得することもできます。 このように、ブログまたは製品ページに専用のURLプロパティがある場合、それらをGDSのデータソースとして使用できます。
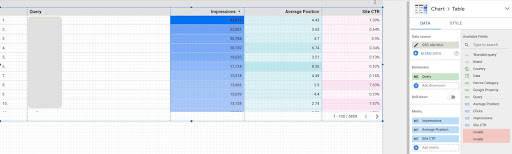
1. Google Data Studio(GDS)からクエリデータを取得する
これをする:
- レポートを作成し、それにテーブルチャートを追加します
- サイトの「サイトインプレッション」データソースをレポートに追加します
- ディメンションには「クエリ」を選択し、指標には「ctr」、「平均掲載順位」、「インプレッション」を選択します
- フィルタを作成して、ブランド名を含むクエリを除外します(ブランドを含むクエリはクリック率が高くなり、データの精度が低下します)
- テーブルを右クリックし、[エクスポート]をクリックします
- 出力をCSVとして保存
2.データを読み込み、位置に基づいてクエリにラベルを付ける
ダウンロードしたCSVの操作には、パンダを使用します。
プロジェクトのフォルダー構造のベストプラクティスは、すべてのデータを保存する「data」フォルダーを作成することです。
ここでは、チュートリアルの流動性のために、これを行いませんでした。
query_df = pd.read_csv('./ downloaded_data.csv')
次に、クエリの位置に基づいてクエリにラベルを付けます。 位置1から10にラベルを付けるための「for」ループを作成しました。
たとえば、クエリの平均位置が2.2または2.9の場合、「2」というラベルが付けられます。 平均位置範囲を操作することにより、希望の精度を実現できます。
範囲(1、11)のiの場合:
query_df.loc [(query_df ['Average Position']> = i)&(
query_df['平均位置']<i+ 1)、'位置ラベル']= i
次に、位置に基づいてクエリをグループ化します。 これは、次のステップで各位置クエリデータをより適切に操作するのに役立ちます。
query_grouped_df = query_df.groupby(['position label'])
3.CTR曲線計算のためにデータに基づいてクエリをフィルタリングする
CTR曲線を計算する最も簡単な方法は、すべてのクエリデータを使用して計算することです。 でも; データの2番目の位置に1つのインプレッションがあるクエリを考えることを忘れないでください。
これらのクエリは、私の経験に基づいて、最終的な結果に大きな違いをもたらします。 しかし、最善の方法は自分で試すことです。 データセットに基づいて、これは変更される可能性があります。
この手順を開始する前に、棒グラフ出力のリストと、操作されたクエリを格納するためのDataFrameを作成する必要があります。
#「query_df」操作データを保存するためのDataFrameを作成する modify_df = pd.DataFrame() #棒グラフの各ポジション平均を保存するためのリスト mean_ctr_list = []
次に、 query_grouped_dfグループをループし、インプレッションに基づいて上位20%のクエリをmodified_dfに追加します。
インプレッション数が最も多いクエリの上位20%のみに基づいてクリック率を計算することが最適でない場合は、それを変更できます。
これを行うには、 .quantile(q=your_optimal_number, interpolation='lower')]を操作して増減でき、 your_optimal_numberは0から1の間でなければなりません。
たとえば、クエリの上位30%を取得する場合、 your_optimal_numは1と0.3(0.7)の差です。
範囲(1、11)のiの場合:
#試してみてください-ディレクトリに一部の位置のデータがない状況を処理する場合を除きます
試す:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions']> = query_grouped_df.get_group(i)['impressions']
.quantile(q = 0.8、interpolation ='lower')]
mean_ctr_list.append(tmp_df ['ctr']。mean())
modify_df = modify_df.append(tmp_df、ignore_index = True)
KeyErrorを除く:
mean_ctr_list.append(0)
#メモリ使用量を減らすために'tmp_df'DataFrameを削除する
デル[tmp_df]
4.箱ひげ図を描く
このステップは私たちが待ち望んでいたことです。 プロットを描画するには、Matplotlib、Matplotlibのラッパーとしてseaborn、またはPlotlyを使用できます。
個人的には、Plotlyを使用することは、データの探索を愛するマーケターに最適なものの1つだと思います。
Mathplotlibと比較すると、Plotlyは非常に使いやすく、数行のコードで美しいプロットを描くことができます。
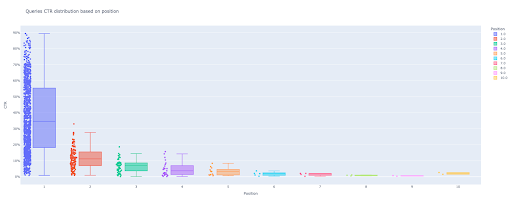
#1。箱ひげ図
box_fig = px.box(modified_df、x ='position label'、y ='Site CTR'、title ='位置に基づいてCTR分布を照会'、
points ='all'、color ='position label'、labels = {'position label':'Position'、'Site CTR':'CTR'})
#10個すべてのx軸ティックを表示
box_fig.update_xaxes(tickvals = [i for i in range(1、11)])
#y軸の目盛り形式をパーセンテージに変更
box_fig.update_yaxes(tickformat = "。0%")
#プロットを「出力プロット画像」ディレクトリに保存
box_fig.write_image('./ output plot images /クエリボックスプロットCTRcurve.png')
これらの4つの線だけで、美しい箱ひげ図を取得して、データの探索を開始できます。
この列を操作する場合は、新しいセルで次の手順を実行します。
box_fig.show()
これで、インタラクティブな出力に魅力的な箱ひげ図ができました。
出力セルのインタラクティブプロットにカーソルを合わせると、関心のある重要な数字は各位置の「男性」です。
これは、各ポジションの平均クリック率を示しています。 平均の重要性のため、ご存知のように、各ポジションの平均を含むリストを作成します。 次に、次のステップに進み、各位置の平均に基づいて棒グラフを描画します。
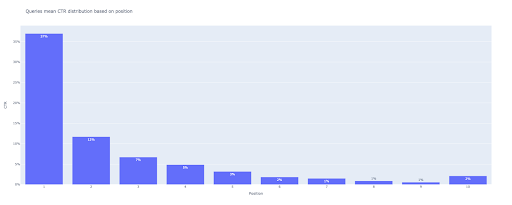
5.棒グラフを描く
箱ひげ図のように、棒グラフの描画はとても簡単です。 px.bar()のtitle引数を変更することで、チャートのtitleを変更できます。
#2。棒グラフ
bar_fig = px.bar(x = [pos for pos in range(1、11)]、y = mean_ctr_list、title ='クエリは位置に基づく平均CTR分布'、
labels = {'x':'Position'、'y':'CTR'}、text_auto = True)
#10個すべてのx軸ティックを表示
bar_fig.update_xaxes(tickvals = [i for i in range(1、11)])
#y軸の目盛り形式をパーセンテージに変更
bar_fig.update_yaxes(tickformat ='。0%')
#プロットを「出力プロット画像」ディレクトリに保存
bar_fig.write_image('./出力プロット画像/クエリ棒グラフCTRcurve.png')
出力で、次のプロットが得られます。
箱ひげ図と同様に、 bar_fig.show()を実行してこのプロットを操作できます。
それでおしまい! 数行のコードで、クエリデータの位置に基づいたオーガニッククリックスルー率を取得します。
サブドメインまたはディレクトリごとにURLプロパティがある場合は、これらのURLプロパティクエリを取得して、それらのCTR曲線を計算できます。
[ケーススタディ]ログファイル分析によるランキング、オーガニック訪問、売上の改善
 ケーススタディを読む
ケーススタディを読む2番目の方法:各ディレクトリのランディングページのURLに基づいてCTR曲線を計算する
最初の方法では、クエリCTRに基づいてオーガニックCTRを計算しましたが、このアプローチでは、すべてのランディングページデータを取得してから、選択したディレクトリのCTR曲線を計算します。
私はこの方法が大好きです。 ご存知のように、当社の製品ページのクリック率は、ブログ投稿や他のページのクリック率とは大きく異なります。 各ディレクトリには、位置に基づいた独自のCTRがあります。
より高度な方法では、各ディレクトリページを分類し、一連のページの位置に基づいてGoogleのオーガニッククリック率を取得できます。

1.ランディングページデータの取得
最初の方法と同様に、Google Search Console(GSC)データを取得する方法はいくつかあります。 この方法では、https://developers.google.com/webmaster-tools/v1/searchanalytics/queryにあるGSCAPIエクスプローラーからランディングページデータを取得することをお勧めします。
このアプローチで必要なものについては、GDSは確実なランディングページデータを提供しません。 また、「スプレッドシートの検索分析」Googleスプレッドシートアドオンを使用することもできます。
Google API Explorerは、データのページ数が25K未満のサイトに適していることに注意してください。 大規模なサイトの場合、ランディングページのデータを部分的に取得して連結したり、「for」ループを使用してPythonスクリプトを記述して、GSCからすべてのデータを取得したり、サードパーティのツールを使用したりできます。
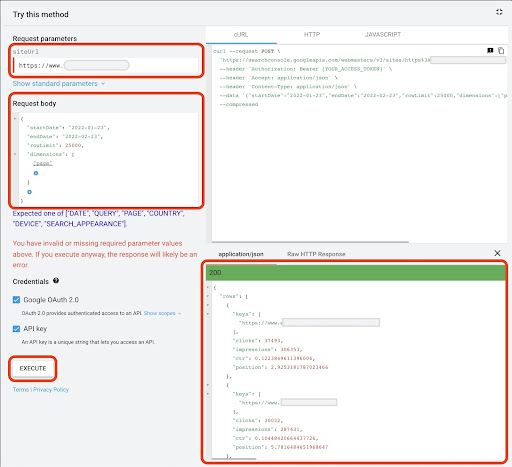
Google API Explorerからデータを取得するには:
- 「SearchAnalytics:query」GSC APIドキュメントページに移動します:https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- ページの右側にあるAPIエクスプローラーを使用します
- 「siteUrl」フィールドに、
https://www.example.com//www.example.comなどのURLプロパティアドレスを挿入します。 また、次のようにドメインプロパティを挿入できますsc-domain:example.com - 「リクエスト本文」フィールドに
startDateとendDateを追加します。 私は先月のデータを取得することを好みます。 これらの値の形式はYYYY-MM-DDです。 -
dimensionを追加し、その値をpageに設定します - 「dimensionFilterGroups」を作成し、ブランドバリエーション名を使用してクエリを除外します(
brand_variation_namesをブランド名RegExpに置き換えます) -
rawLimitを追加し、25000に設定します - 最後に「実行」ボタンを押します
以下のリクエスト本文をコピーして貼り付けることもできます。
{{
"startDate": "2022-01-01"、
"endDate": "2022-02-01"、
「寸法」:[
"ページ"
]、
"dimensionFilterGroups":[
{{
「フィルター」:[
{{
「寸法」:「QUERY」、
"式": "brand_variation_names"、
"演算子": "EXCLUDING_REGEX"
}
]
}
]、
「rowLimit」:25000
}
リクエストが実行されたら、それを保存する必要があります。 応答形式のため、JSONファイルを作成し、すべてのJSON応答をコピーして、 downloaded_data.jsonファイル名で保存する必要があります。
SASS会社のサイトのようにサイトが小さく、ランディングページデータが1000ページ未満の場合は、GSCで日付を簡単に設定し、[ページ]タブのランディングページデータをCSVファイルとしてエクスポートできます。
2.ランディングページデータの読み込み
このチュートリアルでは、Google API Explorerからデータを取得し、それをJSONファイルに保存すると仮定します。 このデータをロードするには、以下のコードを実行する必要があります。
#ダウンロードしたデータのDataFrameを作成する
open('./ downloaded_data.json')をjson_fileとして使用:
着陸データ=json.loads(json_file.read())['行']
landing_df = pd.DataFrame(landings_data)
さらに、列名を変更して意味を持たせ、「ランディングページ」列で直接ランディングページのURLを取得する関数を適用する必要があります。
#「キー」列の名前を「ランディングページ」列に変更し、「ランディングページ」リストをURLに変換する
landing_df.rename(columns = {'keys':'landing page'}、inplace = True)
ランディングページ['ランディングページ']=ランディングページ['ランディングページ']。apply(lambda x:x [0])
3.すべてのランディングページのルートディレクトリを取得する
まず、サイト名を定義する必要があります。
#引用符の間にサイト名を定義します。 たとえば、「https://www.example.com/」または「http://mydomain.com/」 site_name =''
次に、ランディングページのURLで関数を実行してルートディレクトリを取得し、出力でそれらを選択して選択します。
#各ランディングページ(URL)ディレクトリを取得する
landing_df ['directory'] = landing_df ['landing page']。str.extract(pat = f'((?<= {site_name})[^ /] +)')
#出力内のすべてのディレクトリを取得するには、Pandasオプションを操作する必要があります
pd.set_option( "display.max_rows"、None)
#ウェブサイトディレクトリ
着陸_df['ディレクトリ']。value_counts()
次に、CTR曲線を取得するために必要なディレクトリを選択します。
ディレクトリをimportant_directories変数に挿入します。
たとえば、 product,tag,product-category,mag 。 ディレクトリ値はコンマで区切ります。
important_directories ='' important_directories =important_directories.split('、')
4.ランディングページのラベル付けとグループ化
クエリと同様に、ランディングページにも平均位置に基づいてラベルを付けます。
#ランディングページの位置のラベル付け
範囲(1、11)のiの場合:
landing_df.loc [(landings_df ['position']> = i)&(
Landings_df ['position'] <i + 1)、'position label'] = i
次に、「ディレクトリ」に基づいてランディングページをグループ化します。
#「ディレクトリ」の値に基づいてランディングページをグループ化する 着陸_グループ化_df=着陸_df.groupby(['ディレクトリ'])
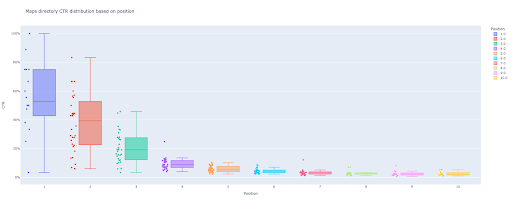
5.ディレクトリのボックスプロットとバープロットを生成する
前の方法では、プロットを生成するために関数を使用しませんでした。 でも; さまざまなランディングページのCTR曲線を自動的に計算するには、関数を定義する必要があります。
#各ディレクトリチャートを作成・保存する機能
def each_dir_plot(dir_df、key):
#「位置ラベル」の値に基づいてディレクトリランディングページをグループ化する
dir_grouped_df = dir_df.groupby(['position label'])
#「dir_grouped_df」操作データを保存するためのDataFrameを作成する
modify_df = pd.DataFrame()
#棒グラフの各ポジション平均を保存するためのリスト
mean_ctr_list = []
'''
'query_grouped_df'グループをループし、インプレッションに基づいて上位20%のクエリを'modified_df'DataFrameに追加します。
インプレッション数が最も多いクエリの上位20%のみに基づいてクリック率を計算することが最適でない場合は、それを変更できます。
変更するには、'.quantile(q = your_optimal_number、interpolation ='lower')]'を操作して増減できます。
'you_optimal_number'は0から1の間でなければなりません。
たとえば、クエリの上位30%を取得する場合、「your_optimal_num」は1と0.3(0.7)の差です。
'''
範囲(1、11)のiの場合:
#試してみてください-ディレクトリに一部の位置のデータがない状況を処理する場合を除きます
試す:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions']> = dir_grouped_df.get_group(i)['impressions']
.quantile(q = 0.8、interpolation ='lower')]
mean_ctr_list.append(tmp_df ['ctr']。mean())
modify_df = modify_df.append(tmp_df、ignore_index = True)
KeyErrorを除く:
mean_ctr_list.append(0)
#1。箱ひげ図
box_fig = px.box(modified_df、x ='position label'、y ='ctr'、title = f'{key}ディレクトリ位置に基づくCTR分布'、
points ='all'、color ='position label'、labels = {'position label':'Position'、'ctr':'CTR'})
#10個すべてのx軸ティックを表示
box_fig.update_xaxes(tickvals = [i for i in range(1、11)])
#y軸の目盛り形式をパーセンテージに変更
box_fig.update_yaxes(tickformat = "。0%")
#プロットを「出力プロット画像」ディレクトリに保存
box_fig.write_image(f'./ output plot images / {key} directory-Box plot CTRcurve.png')
#2。棒グラフ
bar_fig = px.bar(x = [pos for pos in range(1、11)]、y = mean_ctr_list、title = f'{key}ディレクトリは位置に基づくCTR分布を意味します'、
labels = {'x':'Position'、'y':'CTR'}、text_auto = True)
#10個すべてのx軸ティックを表示
bar_fig.update_xaxes(tickvals = [i for i in range(1、11)])
#y軸の目盛り形式をパーセンテージに変更
bar_fig.update_yaxes(tickformat ='。0%')
#プロットを「出力プロット画像」ディレクトリに保存
bar_fig.write_image(f'./ output plot images /{key}ディレクトリ-棒グラフCTRcurve.png')
上記の関数を定義した後、CTR曲線を取得するディレクトリデータをループするための「for」ループが必要です。
#ディレクトリをループして「each_dir_plot」関数を実行する
キーの場合、landings_grouped_dfのアイテム:
important_directoriesを入力した場合:
each_dir_plot(item、key)
出力では、 output plot imagesフォルダーにプロットを取得します。
高度なヒント!
クエリのランディングページを使用して、さまざまなディレクトリのCTR曲線を計算することもできます。 関数にいくつかの変更を加えることで、ランディングページディレクトリに基づいてクエリをグループ化できます。
以下のリクエスト本文を使用して、API ExplorerでAPIリクエストを作成できます(25000行の制限を忘れないでください)。
{{
"startDate": "2022-01-01"、
"endDate": "2022-02-01"、
「寸法」:[
「クエリ」、
"ページ"
]、
"dimensionFilterGroups":[
{{
「フィルター」:[
{{
「寸法」:「QUERY」、
"式": "brand_variation_names"、
"演算子": "EXCLUDING_REGEX"
}
]
}
]、
「rowLimit」:25000
}
Pythonで計算するCTR曲線をカスタマイズするためのヒント
クリック率曲線を計算するためのより正確なデータを取得するには、サードパーティのツールを使用する必要があります。
たとえば、どのクエリに注目のスニペットがあるかを知るだけでなく、より多くのSERP機能を調べることができます。 また、サードパーティのツールを使用している場合は、SERP機能に基づいて、そのクエリのランディングページランクを持つクエリのペアを取得できます。
次に、ランディングページにルート(親)ディレクトリのラベルを付け、ディレクトリ値に基づいてクエリをグループ化し、SERP機能を検討し、最後に位置に基づいてクエリをグループ化します。 CTRデータの場合、GSCからのCTR値をピアクエリにマージできます。