
クロールとインデックス作成の制御:Robots.txtとタグに関するSEOのガイド
公開: 2019-02-19クロールバジェットの最適化とボットによるページのインデックス作成のブロックは、多くのSEOがよく知っている概念です。 しかし、悪魔は細部に宿っています。 特に、ここ数年でベストプラクティスが大幅に変更されたためです。
robots.txtファイルまたはrobotsタグに小さな変更を加えると、ウェブサイトに劇的な影響を与える可能性があります。 影響が常にサイトにプラスになるように、本日は以下について詳しく説明します。
クロール予算の最適化
Robots.txtファイルとは
メタロボットタグとは
X-Robots-Tagsとは何ですか
ロボット指令とSEO
ベストプラクティスロボットのチェックリスト
クロール予算の最適化
検索エンジンスパイダーには、サイト上でクロールできるページ数とクロールしたいページ数に対する「許容値」があります。 これは「クロール予算」として知られています。
Google検索コンソール(GSC)の「クロール統計」レポートでサイトのクロール予算を見つけます。 GSCは12個のボットの集合体であり、すべてがSEO専用ではないことに注意してください。 また、SEAボットであるAdWordsまたはAdSenseボットも収集します。 したがって、このツールを使用すると、グローバルクロールの予算はわかりますが、正確な再パーティションはわかりません。
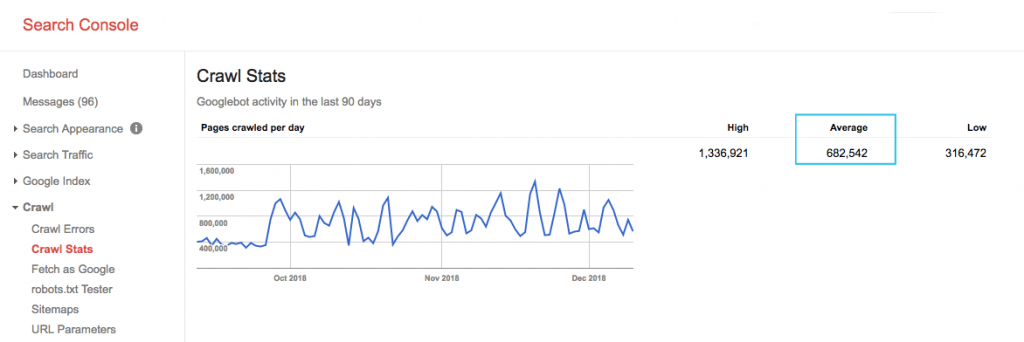
数をより実用的にするには、1日あたりにクロールされる平均ページを、サイトのクロール可能なページの総数で割ります。開発者に数を尋ねるか、無制限のサイトクローラーを実行できます。 これにより、最適化を開始するための予想されるクロール率が得られます。
もっと深く行きたいですか? サイトのサーバーログファイルを分析することで、アクセスされているページや他のクローラーの統計など、Googlebotのアクティビティのより詳細な内訳を取得します。
クロールの予算を最適化する方法はたくさんありますが、開始するのに簡単な場所は、GSCの「カバレッジ」レポートをチェックして、Googleの現在のクロールとインデックス作成の動作を理解することです。
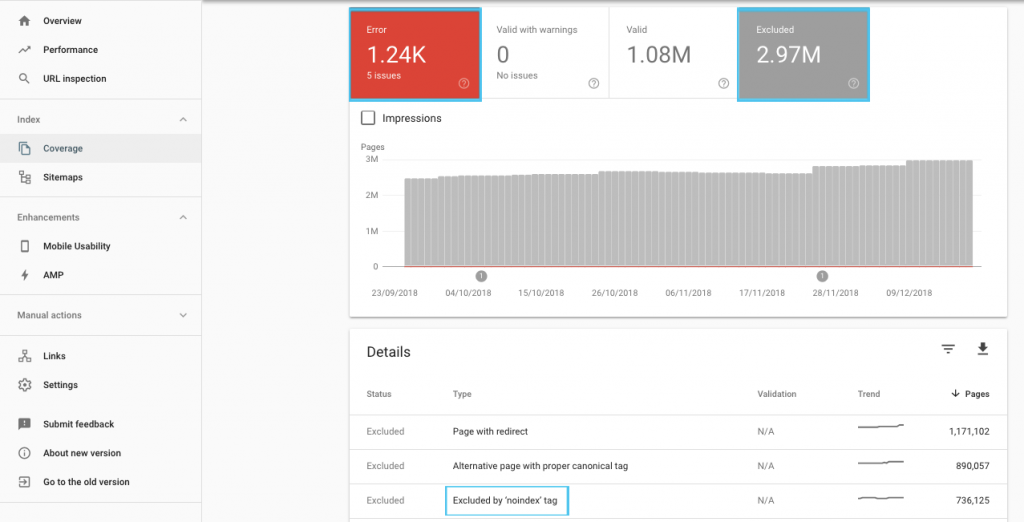
「「noindex」とマークされた送信済みURL」や「robots.txtによってブロックされた送信済みURL」などのエラーが表示された場合は、開発者と協力して修正してください。 ロボットの除外については、それらを調査して、SEOの観点から戦略的であるかどうかを理解してください。
一般的に、SEOはロボットのクロール制限を最小限に抑えることを目的とすべきです。 URLを検索エンジンにとって有用でアクセスしやすいものにするために、Webサイトのアーキテクチャを改善することが、最善の戦略です。
Google自身も、「堅実な情報アーキテクチャは、クロールの優先順位付けに焦点を当てるよりも、はるかに生産的なリソースの使用になる可能性が高い」と述べています。
そうは言っても、robots.txtファイルとrobotsタグを使用して、クロール、インデックス作成、リンクエクイティの受け渡しをガイドするために何ができるかを理解することは有益です。 そしてさらに重要なのは、それを現代のSEOにいつどのように最大限に活用するかです。
[ケーススタディ]Googleのボットクロールの管理
 ケーススタディを読む
ケーススタディを読むRobots.txtファイルとは
検索エンジンがページをスパイダーする前に、robots.txtをチェックします。 このファイルは、ボットがアクセスする権限を持っているURLパスを示します。 ただし、これらのエントリは単なる指示であり、義務ではありません。
Robots.txtは、ファイアウォールやパスワード保護のようにクロールを確実に防ぐことはできません。 これは、ロックされていないドアの「入力しないでください」というデジタル版のサインです。
主要な検索エンジンなどの丁寧なクローラーは、通常、指示に従います。 メールスクレーパー、スパムボット、マルウェア、サイトの脆弱性をスキャンするスパイダーなどの敵対的なクローラーは、多くの場合、注意を払っていません。
さらに、それは公開されているファイルです。 誰でもあなたのディレクティブを見ることができます。
robots.txtファイルを次の目的で使用しないでください。
- 機密情報を隠すため。 パスワード保護を使用します。
- ステージングサイトや開発サイトへのアクセスをブロックするため。 サーバー側の認証を使用します。
- 敵対的なクローラーを明示的にブロックします。 IPブロッキングまたはユーザーエージェントブロッキングを使用します(別名、.htaccessファイルまたはCloudFlareなどのツールのルールで特定のクローラーアクセスを排除します)。
すべてのウェブサイトには、少なくとも1つのディレクティブグループを含む有効なrobots.txtファイルが必要です。 1つがないと、すべてのボットにデフォルトでフルアクセスが許可されるため、すべてのページがクロール可能として扱われます。 これが意図したものであっても、robots.txtファイルを使用してすべての利害関係者にこれを明確にすることをお勧めします。 さらに、1つがないと、サーバーログはrobots.txtの失敗したリクエストでいっぱいになります。
robots.txtファイルの構造
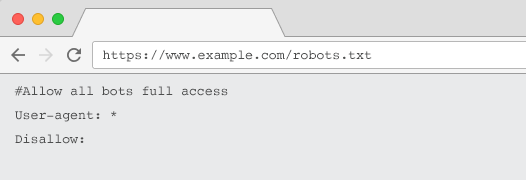
クローラーによって承認されるには、robots.txtは次の条件を満たしている必要があります。
- 「robots.txt」という名前のテキストファイルになります。 ファイル名では大文字と小文字が区別されます。 「Robots.TXT」またはその他のバリエーションは機能しません。
- 正規ドメインの最上位ディレクトリにあり、該当する場合はサブドメインにあります。 たとえば、https://www.example.comより下のすべてのURLのクロールを制御するには、robots.txtファイルをhttps://www.example.com/robots.txtに配置し、subdomain.example.comの場合は次の場所に配置する必要があります。 subdomain.example.com/robots.txt。
- 200OKのHTTPステータスを返します。
- 有効なrobots.txt構文を使用する– GoogleSearchConsoleのrobots.txtテストツールを使用して確認します。
robots.txtファイルは、ディレクティブのグループで構成されています。 エントリは主に次のもので構成されます。
- 1.ユーザーエージェント:さまざまなクローラーに対応します。 すべてのロボットに1つのグループを設定することも、グループを使用して特定の検索エンジンに名前を付けることもできます。
- 2.不許可:上記のユーザーエージェントによるクロールから除外するファイルまたはディレクトリを指定します。 ブロックごとにこれらの行を1つ以上持つことができます。
ユーザーエージェント名の完全なリストとその他のディレクティブの例については、Yoastのrobots.txtガイドをご覧ください。
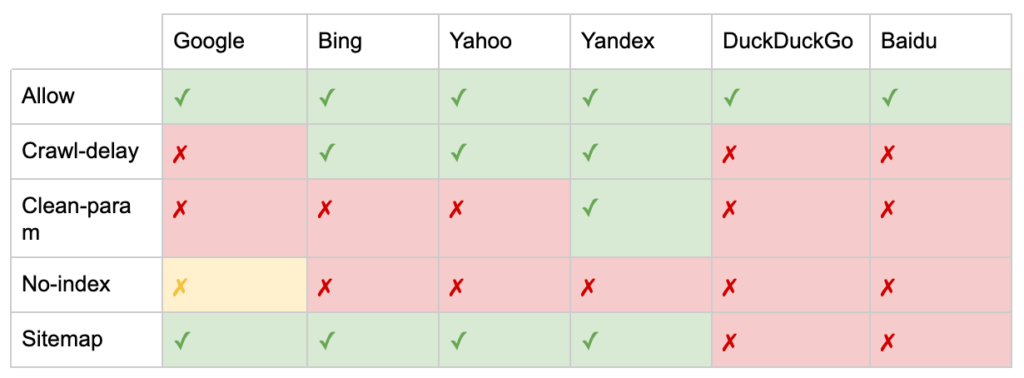
「User-agent」および「Disallow」ディレクティブに加えて、いくつかの非標準ディレクティブがあります。
- 許可:親ディレクトリのdisallowディレクティブの例外を指定します。
- クロール遅延:ページにアクセスする前に待機する秒数をボットに通知することで、重いクローラーを抑制します。 有機セッションがほとんどない場合は、クロール遅延によってサーバーの帯域幅を節約できます。 しかし、クローラーがサーバーの負荷の問題を積極的に引き起こしている場合にのみ、この努力を投資します。 Googleはこのコマンドを認識せず、Google検索コンソールでクロール速度を制限するオプションを提供します。
- Clean-param:動的パラメーターによって生成された重複コンテンツの再クロールを回避します。
- インデックスなし:クロールバジェットを使用せずにインデックスを制御するように設計されています。 Googleによる正式なサポートは終了しました。 それがまだ影響を与える可能性があるという証拠はありますが、それは信頼できず、ジョン・ミューラーなどの専門家によって推奨されていません。
@maxxeight@google@DeepCrawlそこでnoindexを使用することは本当に避けたいと思います。
— ???? ジョン???? (@JohnMu)2015年9月1日
- サイトマップ: XMLサイトマップを送信する最適な方法は、Google検索コンソールおよびその他の検索エンジンのウェブマスターツールを使用することです。 ただし、robots.txtファイルのベースにサイトマップディレクティブを追加すると、送信オプションを提供しない可能性のある他のクローラーを支援します。
SEOのためのrobots.txtの制限
robots.txtがすべてのボットのクロールを防ぐことはできないことはすでにわかっています。 同様に、ページからのクローラーを禁止しても、検索エンジンの結果ページ(SERP)にクローラーが含まれるのを防ぐことはできません。
ブロックされたページに他の強力なランキングシグナルがある場合、Googleは検索結果に表示することが適切であると見なす場合があります。 ページをクロールしていませんが。
そのURLのコンテンツはGoogleに不明であるため、検索結果は次のようになります。

ページがSERPに表示されないように確実にブロックするには、「noindex」ロボットメタタグまたはX-Robots-TagHTTPヘッダーを使用する必要があります。
この場合、 robots.txtのページを禁止しないでください。「noindex」タグを表示して従うには、ページをクロールする必要があるためです。 URLがブロックされている場合、すべてのロボットタグは無効になります。
さらに、ページに多くのインバウンドリンクが発生しているが、Googleがrobots.txtによってそれらのページをクロールすることをブロックされている場合、リンクはGoogleに認識されていますが、リンクの公平性は失われます。
メタロボットタグとは
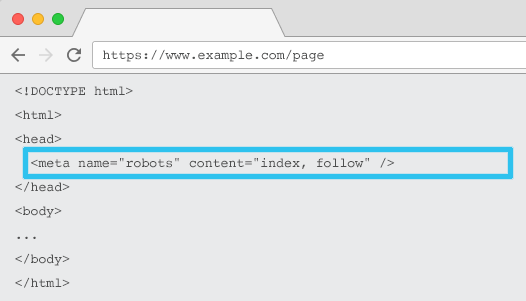
各URLのHTMLに配置されたmetaname=” robots”は、コンテンツを「インデックス化」するかどうか、およびその方法と、すべてのページ上のリンクを「フォロー」する(つまり、クロールする)かどうかをクローラーに指示し、リンクの公平性を渡します。
一般的なメタ名=「robots」を使用すると、ディレクティブはすべてのクローラーに適用されます。 特定のユーザーエージェントを指定することもできます。 たとえば、meta name =” googlebot”です。 ただし、特定のスパイダーの命令を設定するために複数のメタロボットタグを使用する必要があることはめったにありません。
メタロボットタグを使用する場合、2つの重要な考慮事項があります。
- robots.txtと同様に、メタタグはディレクティブであり、必須ではないため、一部のボットでは無視される場合があります。
- robots nofollowディレクティブは、そのページのリンクにのみ適用されます。 クローラーがnofollowなしで別のページまたはWebサイトからのリンクをたどる可能性があります。 そのため、ボットは依然として不要なページに到達してインデックスを作成する可能性があります。
すべてのメタロボットタグディレクティブのリストは次のとおりです。
- index:検索結果にこのページを表示するように検索エンジンに指示します。 ディレクティブが指定されていない場合、これがデフォルトの状態です。
- noindex:検索結果にこのページを表示しないように検索エンジンに指示します。
- フォロー:ページがインデックスに登録されていない場合でも、このページのすべてのリンクをたどり、公平性を渡すように検索エンジンに指示します。 ディレクティブが指定されていない場合、これがデフォルトの状態です。
- nofollow:このページのリンクをたどったり、エクイティを渡したりしないように検索エンジンに指示します。
- all: 「インデックス、フォロー」に相当します。
- none: 「noindex、nofollow」と同等です。
- noimageindex:このページの画像にインデックスを付けないように検索エンジンに指示します。
- noarchive:検索結果にこのページへのキャッシュされたリンクを表示しないように検索エンジンに指示します。
- nocache: noarchiveと同じですが、InternetExplorerとFirefoxでのみ使用されます。
- nosnippet:検索結果にこのページのメタディスクリプションまたはビデオプレビューを表示しないように検索エンジンに指示します。
- notranslate:検索結果にこのページの翻訳を提供しないように検索エンジンに指示します。
- available_after:指定された日付以降、このページのインデックスを作成しないように検索エンジンに指示します。
- noodp:非推奨になり、検索エンジンが検索結果でDMOZのページの説明を使用できなくなっていました。
- noydir:非推奨になりましたが、Yahooが検索結果でYahooディレクトリのページの説明を使用できなくなっていました。
- noyaca: Yandexが検索結果でYandexディレクトリのページの説明を使用しないようにします。
Yoastによって文書化されているように、すべての検索エンジンがすべてのロボットのメタタグをサポートしているわけではなく、それらが何をサポートしているかを明確にしているわけでもありません。

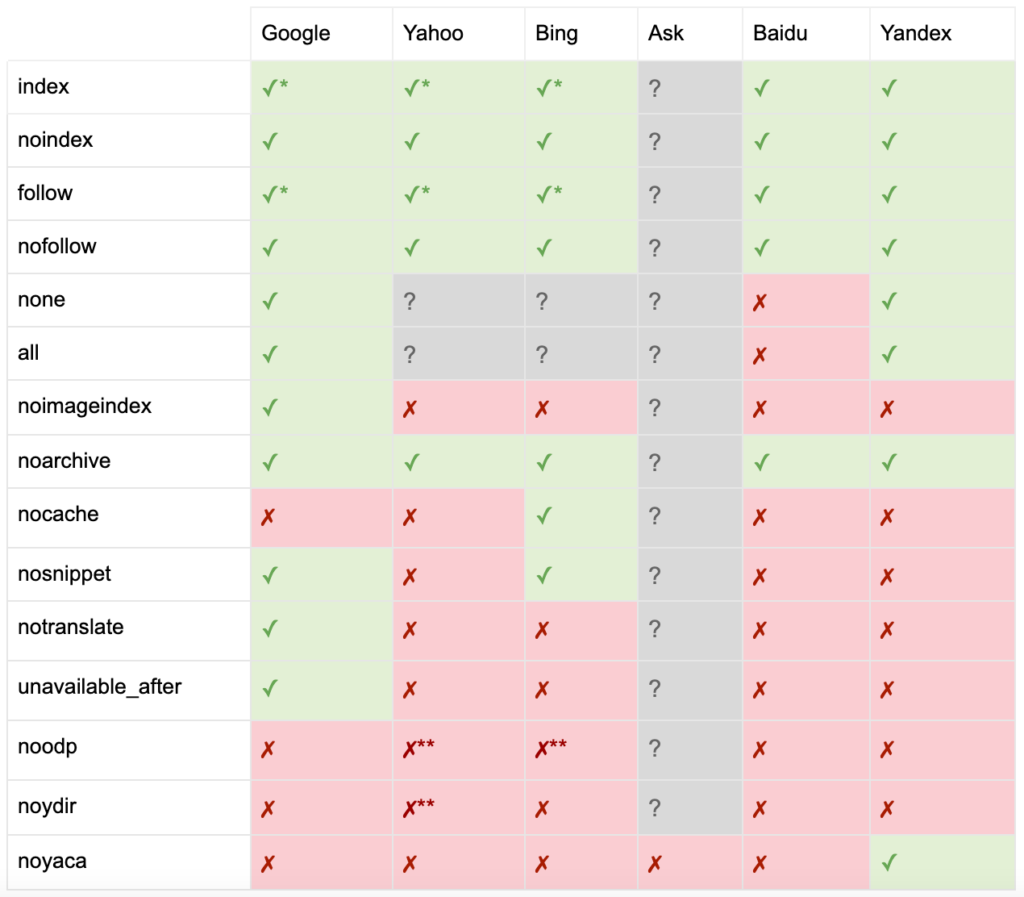
*ほとんどの検索エンジンには、これに関する特定のドキュメントはありませんが、パラメータの除外(nofollowなど)のサポートは、正の同等物(followなど)のサポートを意味すると想定されています。
** noodp属性とnoydir属性は引き続き「サポート」されている可能性がありますが、ディレクトリは存在しなくなり、これらの値は何もしない可能性があります。
通常、robotsタグは「index、follow」に設定されます。 一部のSEOは、このタグをHTMLに追加すると、デフォルトと同じくらい冗長になると考えています。 反対の議論は、指令の明確な指定が人間の混乱を避けるのに役立つかもしれないということです。
注:「noindex」タグが付いたURLはクロールの頻度が低くなり、長期間存在する場合、最終的にGoogleはページのリンクをフォローしなくなります。
メタロボットタグが付いたページ上のすべてのリンクを「フォローしない」ユースケースを見つけることはめったにありません。 rel =” nofollow”リンク属性を使用して個々のリンクに「nofollow」が追加されるのを見るのがより一般的です。 たとえば、ユーザーが生成したコメントや有料リンクにrel =” nofollow”属性を追加することを検討できます。
基本的なインデックス作成に対応せず、キャッシング、画像インデックス作成、スニペット処理などの動作に従うロボットタグディレクティブのSEOユースケースがあることはさらにまれです。
メタロボットタグの課題は、画像、ビデオ、PDFドキュメントなどのHTML以外のファイルには使用できないことです。 ここで、X-Robots-Tagsに目を向けることができます。
X-Robots-Tagsとは何ですか
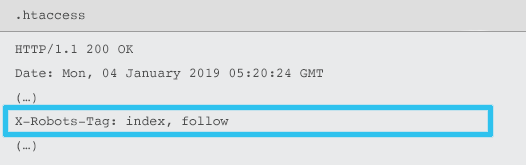
X-Robots-Tagは、.htaccessファイルとhttpd.confファイルを使用して、特定のURLのHTTP応答ヘッダーの要素としてサーバーから送信されます。
ロボットのメタタグディレクティブは、X-Robots-Tagとして指定することもできます。 ただし、X-Robots-Tagは、いくつかの追加の柔軟性と機能を提供します。
次の場合は、メタロボットタグよりもX-Robots-Tagを使用します。
- HTMLファイルだけではなく、非HTMLファイルのロボットの動作を制御します。
- ページ全体ではなく、ページの特定の要素のインデックス作成を制御します。
- ページにインデックスを付けるかどうかにルールを追加します。 たとえば、著者が5つを超える公開記事を持っている場合は、そのプロファイルページにインデックスを付けます。
- ページ固有ではなく、サイト全体のレベルでインデックスとフォローのディレクティブを適用します。
- 正規表現を使用します。
同じページでメタロボットとx-robots-tagの両方を使用することは避けてください。そうすることは冗長になります。
X-Robots-Tagsを表示するには、Google検索コンソールの「FetchasGoogle」機能を使用できます。
ロボット指令とSEO
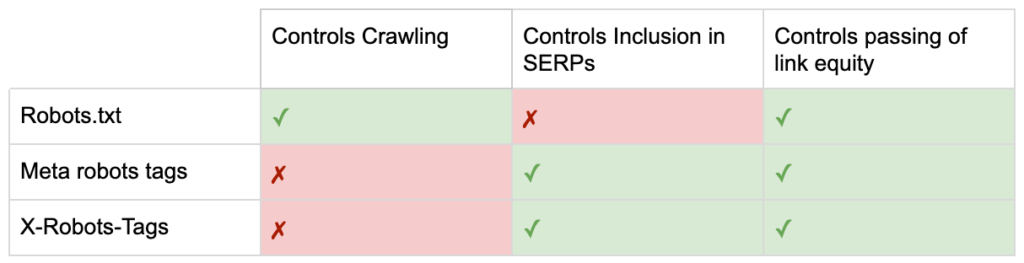
これで、3つのロボットディレクティブの違いがわかりました。
robots.txtはクロール予算の節約に重点を置いていますが、検索結果にページが表示されるのを妨げることはありません。 これは、Webサイトの最初のゲートキーパーとして機能し、ページが要求される前にボットにアクセスしないように指示します。
どちらのタイプのロボットタグも、インデックス作成とリンクエクイティの受け渡しの制御に重点を置いています。 ロボットのメタタグは、ページが読み込まれた後にのみ有効になります。 X-Robots-Tagヘッダーはよりきめ細かい制御を提供し、サーバーがページ要求に応答した後に有効になります。
この理解により、SEOは、ロボットディレクティブを使用してクロールとインデックス作成の課題を解決する方法を進化させることができます。
サーバー帯域幅を節約するためのボットのブロック
問題:ログファイルを分析すると、多くのユーザーエージェントが帯域幅を使用しているが、ほとんど価値がないことがわかります。
- MJ12bot(Majesticから)またはAhrefsbot(Ahrefsから)などのSEOクローラー。
- WebcopierやTeleportなど、デジタルコンテンツをオフラインで保存するツール。
- BaiduspiderやYandexなど、市場に関係のない検索エンジン。
最適ではない解決策: robots.txtでこれらのスパイダーをブロックすることは、それが尊重されることが保証されておらず、かなり公的な宣言であり、利害関係者に競争力のある洞察を与える可能性があるためです。
ベストプラクティスアプローチ:ユーザーエージェントブロッキングのより微妙なディレクティブ。 これはさまざまな方法で実行できますが、通常は.htaccessファイルを編集して、不要なスパイダーリクエストを403 –Forbiddenページにリダイレクトします。
クロール予算を使用した内部サイト検索ページ
問題:多くのWebサイトでは、内部サイト検索結果ページが静的URLで動的に生成されるため、クロール予算が消費され、インデックスに登録されている場合、コンテンツのシンや重複の問題が発生する可能性があります。
最適ではない解決策: robots.txtでディレクトリを禁止します。 これにより、クローラートラップを防ぐことができますが、主要な顧客検索およびそのようなページがリンクの公平性を渡すためにランク付けする能力が制限されます。
ベストプラクティスアプローチ:関連性のある大量のクエリを既存の検索エンジンに適したURLにマッピングします。 たとえば、/ search / samsung-phoneの新しいページを作成するのではなく、「samsung phone」を検索した場合は、/ phone/samsungにリダイレクトします。
これが不可能な場合は、パラメータベースのURLを作成します。 その後、Google検索コンソール内でパラメータをクロールするかどうかを簡単に指定できます。
クロールを許可する場合は、そのようなページがランク付けするのに十分な品質であるかどうかを分析します。 そうでない場合は、短期的な解決策として「noindex、follow」ディレクティブを追加し、SEOとユーザーエクスペリエンスの両方を支援するために結果の品質を向上させる方法を戦略化します。
ロボットによるパラメータのブロック
問題:ファセットナビゲーションやトラッキングによって生成されるようなクエリ文字列パラメータは、クロール予算を使い果たし、重複するコンテンツURLを作成し、ランキング信号を分割することで有名です。
最適ではない解決策: robots.txtまたは「noindex」robotsメタタグを使用したパラメーターのクロールを禁止します。両方(前者はすぐに、後者は長期間にわたって)がリンクの公平性の流れを妨げるためです。
ベストプラクティスのアプローチ:すべてのパラメーターに存在する明確な理由があることを確認し、キーを1回だけ使用して、空の値を防ぐ順序付けルールを実装します。 rel = canonical link属性を適切なパラメータページに追加して、ランキング機能を組み合わせます。 次に、Google Search Consoleですべてのパラメーターを構成します。ここには、クロール設定を伝達するためのより詳細なオプションがあります。 詳細については、検索エンジンジャーナルのパラメータ処理ガイドをご覧ください。
管理者またはアカウント領域のブロック
問題:検索エンジンがプライベートコンテンツをクロールしてインデックスに登録できないようにします。
最適ではない解決策: robots.txtを使用してディレクトリをブロックします。これは、プライベートページをSERPから除外することが保証されていないためです。
ベストプラクティスのアプローチ:パスワード保護を使用して、クローラーがページにアクセスしたり、HTTPヘッダーの「noindex」ディレクティブがフォールバックしたりしないようにします。
マーケティングランディングページとありがとうページのブロック
問題:多くの場合、専用のメールやCPCキャンペーンのランディングページなど、オーガニック検索を目的としていないURLを除外する必要があります。 同様に、コンバージョンに至っていない人がSERPを介してサンキューページにアクセスすることは望ましくありません。
最適ではない解決策:robots.txtを含むファイルを禁止します。これにより、リンクが検索結果に含まれるのを防ぐことができます。
ベストプラクティスのアプローチ:「noindex」メタタグを使用します。
オンサイトの重複コンテンツを管理する
問題:一部のWebサイトでは、ページのプリンター対応バージョンなど、ユーザーエクスペリエンスの理由から特定のコンテンツのコピーが必要ですが、重複ページではなく正規ページが検索エンジンによって認識されるようにしたい場合があります。 他のWebサイトでは、コンテンツが重複しているのは、同じアイテムを複数のカテゴリのURLで販売するなど、開発慣行が不十分なためです。
最適ではない解決策: robots.txtでURLを禁止すると、重複したページがランキング信号を通過できなくなります。 ロボットのインデックスを作成しないと、最終的にはGoogleがリンクを「nofollow」として扱うことになり、重複したページがリンクの公平性を通過するのを防ぎます。
ベストプラクティスのアプローチ:重複するコンテンツが存在する理由がない場合は、ソースを削除し、検索エンジンに適したURLに301リダイレクトします。 存在する理由がある場合は、rel =canonicallink属性を追加してランキング信号を統合します。
アクセス可能なアカウント関連ページの薄いコンテンツ
問題:ログイン、登録、ショッピングカート、チェックアウト、お問い合わせフォームなどのアカウント関連のページは、コンテンツが少なく、検索エンジンにはほとんど価値がありませんが、ユーザーには必要です。
最適ではない解決策: robots.txtを含むファイルを禁止します。これにより、リンクが検索結果に含まれるのを防ぐことができます。
ベストプラクティスアプローチ:ほとんどのWebサイトでは、これらのページの数は非常に少ないはずであり、ロボット処理の実装によるKPIへの影響は見られない場合があります。 必要性を感じた場合は、そのようなページの検索クエリがない限り、「noindex」ディレクティブを使用することをお勧めします。
クロール予算を使用してページにタグを付ける
問題:制御されていないタグ付けはクロールの予算を使い果たし、多くの場合、薄いコンテンツの問題につながります。
最適ではない解決策: robots.txtを禁止するか、「noindex」タグを追加します。どちらもSEO関連のタグのランク付けを妨げ、(即時または最終的に)リンクの公平性の通過を妨げます。
ベストプラクティスのアプローチ:現在の各タグの値を評価します。 データがページが検索エンジンまたはユーザーにほとんど価値を追加しないことを示している場合、301はそれらをリダイレクトします。 カリングを生き残ったページについては、ページ上の要素を改善して、ユーザーとボットの両方にとって価値のあるものになるようにします。
JavaScriptとCSSのクロール
問題:以前は、ボットはJavaScriptやその他のリッチメディアコンテンツをクロールできませんでした。 これは変更されており、オプションでページをレンダリングするために、検索エンジンがJSファイルとCSSファイルにアクセスできるようにすることを強くお勧めします。
最適ではない解決策: robots.txtでJavaScriptファイルとCSSファイルを禁止してクロールの予算を節約すると、インデックス作成が不十分になり、ランキングに悪影響を与える可能性があります。 たとえば、広告インタースティシャルまたはリダイレクトユーザーにサービスを提供するJavaScriptへの検索エンジンアクセスをブロックすると、クローキングと見なされる場合があります。
ベストプラクティスのアプローチ: 「Fetchas Google」ツールでレンダリングの問題を確認するか、「BlockedResources」レポートでブロックされているリソースの概要を確認します。どちらもGoogle検索コンソールで利用できます。 検索エンジンがページを適切にレンダリングするのを妨げる可能性のあるリソースがブロックされている場合は、robots.txtの許可を削除してください。
オンクロールSEOクローラー
 もっと詳しく知る
もっと詳しく知るベストプラクティスロボットのチェックリスト
エラーを制御するロボットによってウェブサイトが誤ってGoogleから削除されることは恐ろしいほど一般的です。
それでも、ロボットの取り扱いは、SEOの使用方法を知っている場合、SEOの武器に強力に追加される可能性があります。 賢明かつ慎重に進めるようにしてください。
役立つように、ここに簡単なチェックリストがあります:
- パスワード保護を使用して個人情報を保護する
- サーバー側認証を使用して開発サイトへのアクセスをブロックする
- 帯域幅を使用するが、ユーザーエージェントのブロックでほとんど価値を提供しないクローラーを制限する
- プライマリドメインとサブドメインのトップレベルディレクトリに「robots.txt」という名前のテキストファイルがあり、200コードが返されることを確認します。
- robots.txtファイルにuser-agent行とdisallow行を含むブロックが少なくとも1つ含まれていることを確認します
- robots.txtファイルに少なくとも1つのサイトマップ行があり、最後の行として入力されていることを確認してください
- GSCrobots.txtテスターでrobots.txtファイルを検証します
- インデックス可能なすべてのページで、ロボットのタグディレクティブが指定されていることを確認します
- robots.txt、robotsメタタグ、X-Robots-Tags、.htaccessファイル、GSCパラメータの処理の間に矛盾したまたは冗長なディレクティブがないことを確認してください
- GSCカバレッジレポートの「「noindex」とマークされた送信済みURL」または「robots.txtによってブロックされた送信済みURL」エラーを修正します
- GSCカバレッジレポートでロボット関連の除外の理由を理解する
- GSCの「ブロックされたリソース」レポートに関連するページのみが表示されていることを確認します
ロボットの取り扱いをチェックして、正しく行っていることを確認してください。