
クロール、インデックス作成、Python:知っておくべきことすべて
公開: 2021-05-31この記事を非常に単純な方程式から始めたいと思います。ページがクロールされない場合、ページがインデックスに登録されることはないため、SEOのパフォーマンスは常に低下します(そして悪臭を放ちます)。
その結果として、SEOは、ウェブサイトをクロール可能にする最善の方法を見つけ、Googleに最も重要なページを提供して、インデックスを作成し、それらを介してトラフィックを獲得し始めるよう努める必要があります。
ありがたいことに、Screaming Frog、Oncrawl、Pythonなど、Webサイトのクロール性を向上させるのに役立つ多くのリソースがあります。 Pythonが、クロールのしやすさとインデックス作成の指標を分析および改善するのにどのように役立つかを示します。 ほとんどの場合、これらの種類の改善は、ランキングの向上、SERPの可視性の向上、そして最終的にはより多くのユーザーがWebサイトにアクセスすることにもつながります。
1.Pythonを使用したインデックス作成のリクエスト
1.1。 Googleの場合
Googleのインデックス作成のリクエストはいくつかの方法で行うことができますが、残念ながら私はそれらのいずれにもあまり納得していません。 長所と短所を含む3つの異なるオプションについて説明します。
- SeleniumとGoogleSearchConsole:私の観点から、それと残りのオプションをテストした後、これは最も効果的なソリューションです。 ただし、何度か試行した後、キャプチャポップアップが表示されて破損する可能性があります。
- サイトマップにpingを実行する:たとえば、新しいページがWebサイトに追加された場合など、特定のURLではなく、要求に応じてサイトマップをクロールすることは間違いなく役立ちます。
- Google Indexing API:放送局とジョブプラットフォームのウェブサイトを除いて、信頼性はあまり高くありません。 クロール速度を上げるのに役立ちますが、特定のURLにインデックスを付けることはできません。
各方法についてのこの簡単な概要の後で、それらを1つずつ詳しく見ていきましょう。
1.1.1。 SeleniumとGoogle検索コンソール
基本的に、この最初のソリューションで行うことは、Seleniumを使用してブラウザーからGoogle Search Consoleにアクセスし、Google Search Consoleでインデックスを作成するために手動で実行するのと同じプロセスを複製することですが、自動化された方法です。
注:この方法を使いすぎないでください。コンテンツが更新されている場合、またはページが完全に新しい場合にのみ、インデックス作成のためにページを送信してください。
Seleniumを使用してGoogleSearchConsoleにログインできるようにする秘訣は、GSCクロール統計レポートのダウンロードを自動化する方法についてこの記事で説明したように、最初にOUATHPlaygroundにアクセスすることです。
#これらのモジュールをインポートします インポート時間 セレンインポートWebドライバーから webdriver_manager.chromeからChromeDriverManagerをインポートします selenium.webdriver.common.keysからキーをインポートします #Seleniumドライバーをインストールします ドライバー=webdriver.Chrome(ChromeDriverManager()。install()) #OUATHプレイグラウンドアカウントにアクセスしてGoogleサービスにログインします driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope = email&access_type = offset&flowName = GeneralOAuthFlow') #Xpathで要素を選択し、メールアドレスを紹介する前に、レンダリングが完了していることを確認するために少し待ちます。 time.sleep(10) form1 = driver.find_element_by_xpath('// * [@]') form1.send_keys( "<あなたのメールアドレス>") form1.send_keys(Keys.ENTER) #ここでも同じです。少し待ってから、パスワードを紹介します。 time.sleep(10) form2 = driver.find_element_by_xpath('// * [@] / div [1] / div / div [1] / input') form2.send_keys( "<あなたのパスワード>") form2.send_keys(Keys.ENTER)
その後、Google検索コンソールのURLにアクセスできます。
driver.get('https://search.google.com/search-console?resource_id=your_domain”') time.sleep(5) box = driver.find_element_by_xpath('/ html / body / div [7] / div [2] / header / div [2] / div [2] / div [2] / form / div / div / div / div / div / div [1] / input [2]') box.send_keys( "your_URL") box.send_keys(Keys.ENTER) time.sleep(5) indexation = driver.find_element_by_xpath( "/ html / body / div [7] / c-wiz [2] / div / div [3] / span / div / div [2] / span / div [2] / div / div / div [1] / span / div [2] / div / c-wiz [2] / div [3] / span / div / span / span / div / span / span [1] ") indexation.click() time.sleep(120)
残念ながら、冒頭で説明したように、いくつかのリクエストの後、インデックスリクエストを続行するためにパズルキャプチャが必要になり始めているようです。 自動化された方法ではキャプチャを解決できないため、これはこのソリューションを不利にするものです。
1.1.2。 サイトマップにpingを実行する
サイトマップURLは、pingメソッドを使用してGoogleに送信できます。 基本的に、パラメータとしてサイトマップURLを導入する次のエンドポイントにリクエストを送信するだけで済みます。
http://www.google.com/ping?sitemap=URL/of/file
この記事で説明したように、これはPythonとリクエストを使用して非常に簡単に自動化できます。
urllib.requestをインポートします url = "http://www.google.com/ping?sitemap=https://www.example.com/sitemap.xml" 応答=urllib.request.urlopen(url)
1.1.3。 Google Indexing API
Google Indexing APIは、クロールレートを向上させるための優れたソリューションですが、通常、コンテンツをインデックスに登録するのにあまり効果的な方法ではありません。これは、WebサイトにJobPostingまたはBroadcastEventがVideoObjectに埋め込まれている場合にのみ使用されるためです。 ただし、試して自分でテストしたい場合は、次の手順に従うことができます。
まず、このAPIの使用を開始するには、Google Cloud Consoleにアクセスして、プロジェクトとサービスアカウントのクレデンシャルを作成する必要があります。 その後、ライブラリからIndexing APIを有効にし、サービスアカウントのクレデンシャルで指定されたメールアカウントをGoogle検索コンソールのプロパティ所有者として追加する必要があります。 このメールアドレスをプロパティの所有者として追加できるようにするには、古いバージョンのGoogle検索コンソールを使用する必要がある場合があります。
前の手順を実行すると、次のコードを使用して、このAPIでインデックス作成とインデックス解除を開始できるようになります。
oauth2client.service_accountからインポートServiceAccountCredentials
httplib2をインポートします
SCOPES = ["https://www.googleapis.com/auth/indexing"]
ENDPOINT = "https://indexing.googleapis.com/v3/urlNotifications:publish"
client_secrets = "path_to_your_credentials.json"
クレデンシャル=ServiceAccountCredentials.from_json_keyfile_name(client_secrets、scopes = SCOPES)
クレデンシャルがNoneまたはcredentials.invalidの場合:
クレデンシャル=tools.run_flow(flow、storage)
http = authentication.authorize(httplib2.Http())
list_urls = ["https://www.example.com"、 "https://www.example.com/test2/"]
範囲内の反復の場合(len(list_urls)):
コンテンツ='''{
'url': "'''+ str(list_urls [iteration])+'''"、
'type': "URL_UPDATED"
}'''
応答、コンテンツ= http.request(ENDPOINT、method = "POST"、body = content)
印刷(応答)
print(content)インデックスの解除を依頼する場合は、リクエストタイプを「URL_UPDATED」から「URL_DELETED」に変更する必要があります。 前のコードは、APIからの応答を通知時間とそのステータスとともに出力します。 ステータスが200の場合、リクエストは正常に行われています。
1.2。 Bingの場合
SEOについて話すとき、私たちはGoogleだけを思い浮かべることがよくありますが、一部の市場には、Bingのようなかなりの市場シェアを持つ他の主要な検索エンジンや他の検索エンジンがあることを忘れることはできません。
最初から、BingにはBing Webmaster Toolsに非常に便利な機能があり、ほとんどの場合、1日あたり最大10,000のURLの送信を要求できることに注意してください。 1日のクォータが10,000URL未満の場合もありますが、ニーズを満たすためにより大きなクォータが必要になると思われる場合は、クォータの増分をリクエストするオプションがあります。 このページでこれについてもっと読むことができます。
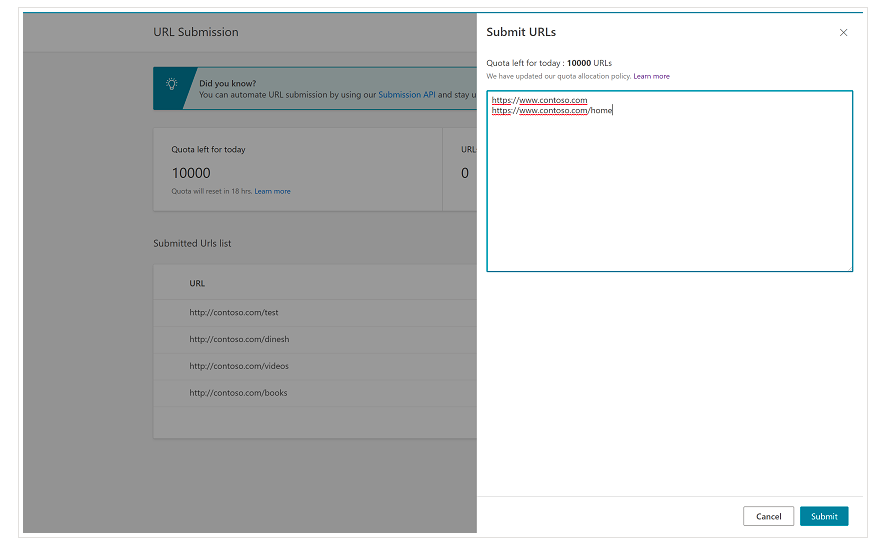
この機能は、Bing Webmaster Toolsの通常のインターフェイスからURL送信ツールのさまざまな行にURLを導入するだけでよいため、一括URL送信に非常に便利です。
1.2.1。 BingインデックスAPI
Bing Indexing APIは、パラメーターとして導入する必要のあるAPIキーとともに使用できます。 このAPIキーは、Bing Webmaster Toolsで取得できます。APIアクセスセクションに移動し、その後、APIキーを生成します。
APIキーを取得したら、次のコードを使用してAPIを試すことができます(APIキーとサイトのURLを追加するだけで済みます)。
インポートリクエスト
list_urls = ["https://www.example.com"、 "https://www.example/test2/"]
list_urlsのyの場合:
url ='https://ssl.bing.com/webmaster/api.svc/json/SubmitUrlbatch?apikey=yourapikey'
myobj ='{"siteUrl": "https://www.example.com"、 "urlList":["' + str(y)+'"]}'
headers = {'Content-type':'application / json; charset = utf-8'}
x = requests.post(url、data = myobj、headers = headers)
print(str(y)+ ":" + str(x))これにより、反復ごとにURLとその応答コードが出力されます。 Google Indexing APIとは対照的に、このAPIはあらゆる種類のウェブサイトに使用できます。
[ケーススタディ]Googlebotのウェブサイトのクロール性を改善して可視性を向上させる
 ケーススタディを読む
ケーススタディを読む2.サイトマップの分析、作成、アップロード
ご存知のとおり、サイトマップは、検索エンジンボットにクロールするURLを提供するための非常に便利な要素です。 検索エンジンボットにサイトマップの場所を知らせるために、サイトマップはGoogle検索コンソールとBing Webmaster Toolsにアップロードされ、残りのボットのrobots.txtファイルに含まれるようになっています。
Pythonを使用すると、サイトマップに関連する主に3つの異なる側面、つまり分析、作成、Google検索コンソールからのアップロードと削除に取り組むことができます。
2.1。 Pythonによるサイトマップのインポートと分析
Advertoolsは、Elias Dabbasによって作成された優れたライブラリであり、サイトマップのインポートや他の多くのSEOタスクに使用できます。 以下を使用するだけで、サイトマップをデータフレームにインポートできます。
sitemap_to_df('https://example.com/robots.txt', recursive=False)
このライブラリは、通常のXMLサイトマップ、ニュースサイトマップ、およびビデオサイトマップをサポートしています。
一方、サイトマップからURLをインポートすることだけに関心がある場合は、ライブラリリクエストとBeautifulSoupを使用することもできます。
インポートリクエスト bs4からインポートBeautifulSoup r = requests.get( "https://www.example.com/your_sitemap.xml") xml = r.text スープ=BeautifulSoup(xml) urls = soup.find_all( "loc") urls = [[x.text] for x in urls]
サイトマップがインポートされると、この記事でKoray Tugberkが説明しているように、抽出されたURLを試して、コンテンツ分析を実行できます。
2.2。 Pythonを使用したサイトマップの作成
この記事でJCChouinardが説明したように、Pythonを利用してURLのリストからsitemaps.xmlを作成することもできます。 これは、URLが急速に変化する非常に動的なWebサイトで特に役立ち、上記で説明したpingメソッドとともに、Googleに新しいURLを提供し、それらをクロールしてインデックスに登録するための優れたソリューションになります。
最近、Greg Bernhardtは、サイトマップを生成するためにStreamlitとPythonを使用してAPPも作成しました。
2.3。 Google検索コンソールからのサイトマップのアップロードと削除
Google Search Consoleには、主に2つの異なる方法で使用できるAPIがあります。ウェブパフォーマンスに関するデータを抽出する方法とサイトマップを処理する方法です。 この投稿では、サイトマップをアップロードおよび削除するオプションに焦点を当てます。
まず、Google Cloud Consoleから既存のプロジェクトを作成または使用して、OUATHクレデンシャルを取得し、GoogleSearchConsoleサービスを有効にすることが重要です。 JC Chouinardは、Pythonを使用してGoogle Search Console APIにアクセスするために従う必要のある手順と、この記事で最初のリクエストを行う方法について詳しく説明しています。 基本的に、彼のコードを完全に利用できますが、変更を導入することによってのみ、スコープに「https://www.googleapis.com」の代わりに「https://www.googleapis.com/auth/webmasters」を追加します。 APIを使用して、サイトマップを読み取るだけでなく、アップロードおよび削除するためです。

APIに接続したら、APIを試して、次のコードでGoogle検索コンソールのプロパティからすべてのサイトマップを一覧表示できます。
verifyed_sites_urlsのsite_urlの場合:
印刷(site_url)
#送信されたサイトマップのリストを取得する
sitemaps = webmasters_service.sitemaps()。list(siteUrl = site_url).execute()
サイトマップの「sitemap」の場合:
sitemap_urls = [s ['path'] for s in sitemaps ['sitemap']]
印刷( "" + "\ n" .join(sitemap_urls))
特定のサイトマップに関しては、次のセクションで詳しく説明する3つのタスク、つまり、情報のアップロード、削除、および要求を実行できます。
2.3.1。 サイトマップのアップロード
Pythonでサイトマップをアップロードするには、サイトのURLとサイトマップのパスを指定して、次のコードを実行するだけです。
WEBSITE ='yourGSCproperty' SITEMAP_PATH ='https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps()。submit(siteUrl = WEBSITE、feedpath = SITEMAP_PATH).execute()
2.3.2。 サイトマップの削除
コインの反対側は、サイトマップを削除したいときです。 「送信」の代わりに「削除」メソッドを使用して、PythonでGoogle検索コンソールからサイトマップを削除することもできます。
WEBSITE ='yourGSCproperty' SITEMAP_PATH ='https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps()。delete(siteUrl = WEBSITE、feedpath = SITEMAP_PATH).execute()
2.3.3。 サイトマップからの情報のリクエスト
最後に、メソッド「get」を使用してサイトマップから情報を要求することもできます。
WEBSITE ='yourGSCproperty' SITEMAP_PATH ='https://www.example.com/page-sitemap.xml' webmasters_service.sitemaps()。get(siteUrl = WEBSITE、feedpath = SITEMAP_PATH).execute()
これにより、次のようなJSON形式の応答が返されます。 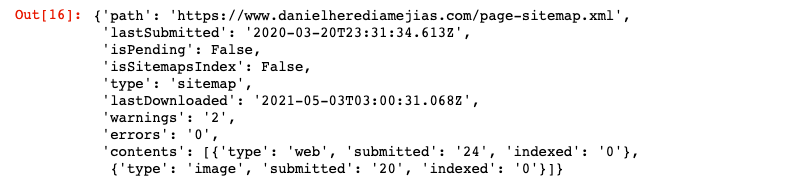
3.内部リンク分析と機会
適切な内部リンク構造を持つことは、検索エンジンボットがWebサイトをクロールするのを容易にするのに非常に役立ちます。 非常に洗練された技術設定で多くのWebサイトを監査することによって私が遭遇した主な問題のいくつかは、次のとおりです。
- オンクリックイベントで導入されたリンク:つまり、Googlebotはボタンをクリックしないため、リンクがオンクリックイベントで挿入された場合、Googlebotはボタンをたどることができなくなります。
- クライアント側でレンダリングされたリンク: Googlebotやその他の検索エンジンはJavaScriptの実行がはるかに優れていますが、それでもかなり難しいので、サーバー側でこれらのリンクをレンダリングして生のHTMLに提供する方がはるかに優れています。検索エンジンボットは、JavaScriptスクリプトを実行することを期待するよりも。
- ログインおよび/または年齢ゲートポップアップ:ログインポップアップおよび年齢ゲートは、検索エンジンボットがこれらの「障害物」の背後にあるコンテンツをクロールするのを防ぐことができます。
- Nofollow属性の乱用:貴重な内部ページを指す多くのnofollow属性を使用すると、検索エンジンボットがそれらをクロールするのを防ぐことができます。
- Noindexとfollow:技術的にはnoindexとfollowディレクティブの組み合わせにより、検索エンジンボットはそのページにあるリンクをクロールできるようになります。 ただし、しばらくすると、Googlebotはnoindexディレクティブを使用してこれらのページのクロールを停止するようです。
Pythonを使用すると、内部リンク構造を分析し、バルクモードでの新しい内部リンクの機会を見つけることができます。
3.1。 Pythonによる内部リンク分析
数か月前、PythonとライブラリNetworkxを使用してグラフを作成し、内部リンク構造を非常に視覚的に表示する方法についての記事を書きました。
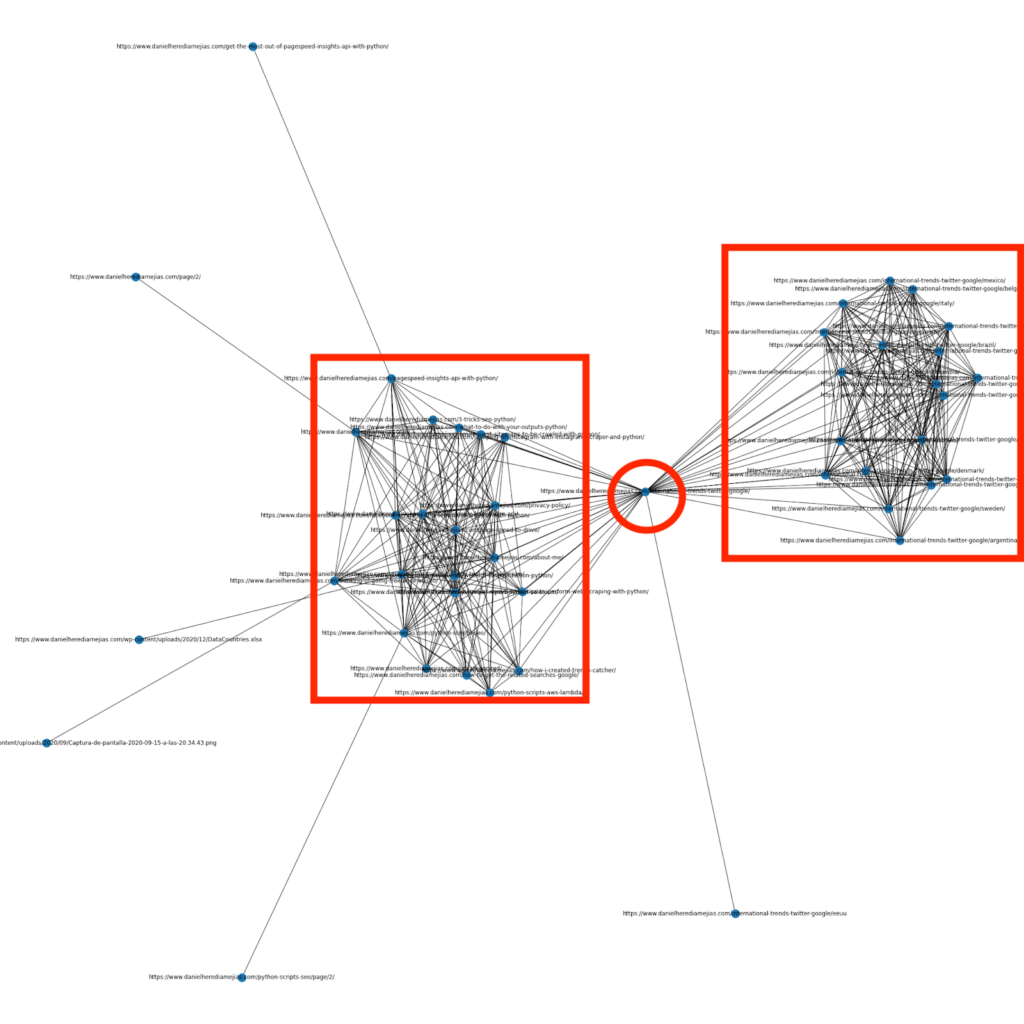
これはScreamingFrogから取得できるものと非常に似ていますが、この種の分析にPythonを使用する利点は、基本的に、これらのグラフに含めるデータを選択し、次のようなほとんどのグラフ要素を制御できることです。色、ノードサイズ、または追加するページとしても使用できます。
3.2。 Pythonを使用した新しい内部リンクの機会を見つける
サイト構造の分析とは別に、Pythonを使用して、多数のキーワードとURLを提供し、それらのURLを繰り返してコンテンツ内の提供された用語を検索することにより、新しい内部リンクの機会を見つけることもできます。
これは、SemrushまたはAhrefsのエクスポートで非常にうまく機能し、すでにキーワードでランク付けされているため、すでに何らかの権限を持っている一部のページから強力なコンテキスト内部リンクを見つけることができます。
この方法の詳細については、こちらをご覧ください。
4. Webサイトの速度、5xxおよびソフトエラーページ
このページでGoogleがGoogleにとってクロール予算の意味について述べているように、サイトを高速化すると、ユーザーエクスペリエンスが向上し、クロール速度が向上します。 一方、ソフトエラーページ、低品質のコンテンツ、オンサイトの重複コンテンツなど、クロールの予算に影響を与える可能性のある他の要因もあります。
4.1。 ページ速度とPython
4.2.1Pythonを使用したWebサイトの速度の分析
Page Speed Insights APIは、ページ速度の観点からWebサイトのパフォーマンスを分析し、さまざまなページ速度メトリック(ほぼ50)とコアWebバイタルに関する多くのデータを取得するのに非常に役立ちます。
PythonでのPageSpeedInsightsの操作は非常に簡単で、APIキーとリクエストのみを使用する必要があります。 例えば:
urllib.request、jsonをインポートします url = "https://www.googleapis.com/pagespeedonline/v5/runPagespeed?url=your_URL&strategy=mobile&locale=en&key=yourAPIKey" #パラメータURLを使用してURLを挿入できます。また、デスクトップのデータを取得する場合は、デバイスパラメータを変更することもできます。 応答=urllib.request.urlopen(url) data = json.loads(response.read())
さらに、この記事で説明されているように、ページ速度を向上させるために要求された変更を行った場合に、PythonとLighthouseScoring計算機を使用して全体的なパフォーマンススコアがどの程度向上するかを予測することもできます。
4.2.2Pythonによる画像の最適化とサイズ変更
KorayTugberkとGregBernhardtが書いたこれらの記事で説明されているように、Webサイトの速度に関連して、Pythonを使用して画像を最適化、圧縮、サイズ変更することもできます。
- FTP経由のPythonで画像圧縮を自動化します。
- Pythonを使用して画像のサイズを一括で変更します。
- SEOおよびUX用にPythonを介して画像を最適化します。
4.2。 Pythonによる5xxおよびその他の応答コードエラーの抽出
5xx応答コードエラーは、サーバーが受信しているすべての要求を処理するのに十分な速度ではないことを示している可能性があります。 これは、クロールレートに非常に悪影響を与える可能性があり、ユーザーエクスペリエンスを損なう可能性もあります。
Webサイトが期待どおりに機能していることを確認するために、PythonとSeleniumを使用してクロール統計レポートのダウンロードを自動化し、ログファイルを注意深く監視できます。
4.3。 Pythonによるソフトエラーページの抽出
最近、Jose Luis Hernandoが、Hamlet Batistaに敬意を表して、Node.jsを使用してカバレッジレポートの抽出を自動化する方法についての記事を公開しました。 これは、クロール速度に悪影響を与える可能性のあるソフトエラーページや5xx応答エラーを抽出するためのすばらしいソリューションになる可能性があります。
この同じプロセスをPythonで複製して、1つのExcelタブで、Google Search Consoleによって提供されたすべてのURLを誤ったもの、警告付きで有効なもの、有効なもの、除外されたものとしてコンパイルすることもできます。
まず、この記事で前述したように、PythonとSeleniumを使用してGoogle検索コンソールにログインする必要があります。 その後、すべてのURLステータスボックスを選択し、ページごとに最大100行を追加し、GSCによって報告されたすべてのタイプのURLの反復を開始し、すべてのExcelファイルをダウンロードします。
インポート時間
セレンインポートWebドライバーから
webdriver_manager.chromeからChromeDriverManagerをインポートします
selenium.webdriver.common.keysからキーをインポートします
ドライバー=webdriver.Chrome(ChromeDriverManager()。install())
driver.get('https://accounts.google.com/o/oauth2/v2/auth/oauthchooseaccount?redirect_uri=https%3A%2F%2Fdevelopers.google.com%2Foauthplayground&prompt=consent&response_type=code&client_id=407408718192.apps.googleusercontent .com&scope = email&access_type = offset&flowName = GeneralOAuthFlow')
time.sleep(5)
searchBox = driver.find_element_by_xpath('// * [@]')
searchBox.send_keys( "<youremailaddress>")
searchBox.send_keys(Keys.ENTER)
time.sleep(5)
searchBox = driver.find_element_by_xpath('// * [@] / div [1] / div / div [1] / input')
searchBox.send_keys( "<yourpassword>")
searchBox.send_keys(Keys.ENTER)
time.sleep(5)
yourdomain = str(input( "ここにhttpプロパティまたはドメインを挿入します。ドメインの場合:'sc-domain':"))
driver.get('https://search.google.com/search-console/index?resource_https://search.google.com/search-console/index?resource_Tabla')
listvalues = [list_problems [x] for i in range(len(df1 ["URL"]))]
df1 ['Type'] = listvalues
list_results = df1.values.tolist()
そうしないと:
df2 = pd.read_excel(yourdomain.replace( "sc-domain:"、 "")。replace( "/"、 "_")。replace( ":"、 "_")+ "-Coverage-Drilldown-" +今日+"(" + str(x)+ ").xlsx"、'タブラ')
listvalues = [list_problems [x] for i in range(len(df2 ["URL"]))]
df2 ['Type'] = listvalues
list_results = list_results + df2.values.tolist()
df = pd.DataFrame(list_results、columns = ["URL"、 "TimeStamp"、 "Type"])
df.to_csv('<filename> .csv'、header = True、index = False、encoding = "utf-8")
最終的な出力は次のようになります。 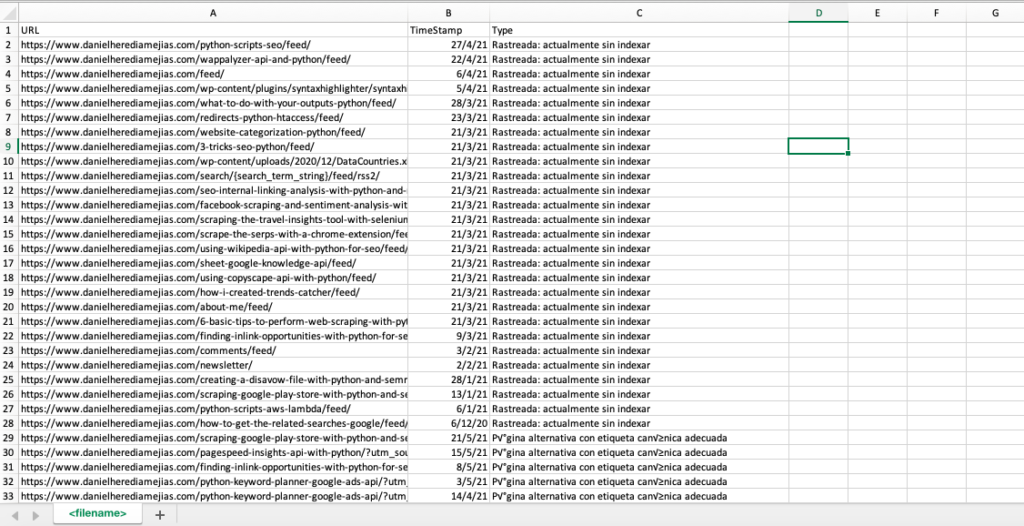
4.4。 Pythonを使用したログファイル分析
Google Search Consoleのクロール統計レポートで利用できるデータだけでなく、Pythonを使用して独自のファイルを分析し、検索エンジンボットがWebサイトをクロールする方法に関する詳細情報を取得することもできます。 SEO用のログアナライザーをまだ使用していない場合は、Pythonを使用したログ分析について説明しているSEOGardenのこの記事を読むことができます。
[電子ブック]SEOログ分析を活用するための4つのユースケース
無料でダウンロード5.最終的な結論
Pythonは、さまざまな方法でWebサイトのクロールとインデックス作成を分析および改善するための優れた資産になる可能性があることを確認しました。 また、何千時間もの時間を必要とする面倒で手動のタスクのほとんどを自動化することで、生活をはるかに楽にする方法も見てきました。
残念ながら、Googleが現在提供しているソリューションで、多数のURLのインデックス作成をリクエストすることについては十分に確信していませんが、より良いソリューションを提供することへの恐れはある程度理解できます。多くのSEOは傾向があるかもしれません。それを使いすぎる。
それとは対照的に、Bingがあります。これは、APIを介して、さらにはBingWebmasterToolsの通常のインターフェイスを介してURLインデックスを要求するための優れた便利なソリューションを提供します。
GoogleインデックスAPIには改善の余地があるため、アクセス可能で更新されたサイトマップの配置、内部リンク、ページ速度、ソフトエラーページ、重複した低品質のコンテンツなどの他の要素は、確実にするためにさらに重要になります。 Webサイトが適切にクロールされ、最も重要なページがインデックスに登録されていること。