
ブレッドクラムSEO、Python 3、Oncrawl:自動化の途上にあります!
公開: 2021-04-14OnCrawlとPython3を使用してブレッドクラムベースのセグメンテーションを自動的に作成する方法を学びましょう。
オンクロールのセグメンテーションとは何ですか?
Oncrawlは、セグメンテーションを使用して一連のページをグループに分割します。 これにより、クロールレポート、ログ分析、およびクロールデータをGoogle Analytics、Google Search Console、AT Internet、Adobe Analytics、またはバックリンク用のMajesticとブレンドするその他の相互分析レポートからのデータを非常に簡単に分析できます。
セグメンテーションを作成することが重要なのはなぜですか?
クロールが完了したら、カスタムセグメンテーションを作成することが最も重要です。 これにより、サイトとその構造に最適な観点から分析を読み取ることができます。
サイトのページをセグメント化する方法はたくさんありますが、正しい方法も間違った方法もありません。 たとえば、URL構造に基づいてサイトの構造を追跡することができます。
たとえば、この種のURL「 https://www.mydomain.com/news/canada/politics 」は、次のように簡単にセグメント化できます。
- ホームページを分離するグループ
- すべてのニュースのためのグループ
- カナダディレクトリのサブグループ
- Politicsディレクトリのサブサブグループ
ご覧のとおり、セグメンテーションには最大3レベルの深さを作成できます。 これにより、セグメンテーションを切り替えることなく、SEO分析で特定のグループまたはサブグループに焦点を当てることができます。
基本的なセグメンテーションを作成するにはどうすればよいですか?
Oncrawlが最初のセグメンテーションの作成をすべて単独で処理することを知っておく必要があります。 これは、「最初のパス」またはURLで検出された最初のディレクトリに基づいています。
これにより、クロールが完了するとすぐに分析を利用できるようになります。
このセグメンテーションはサイトの構造を反映していないか、別の角度から分析したい場合があります。
したがって、OncrawlQueryLanguageの略であるOQLと呼ばれるものを使用して新しいセグメンテーションを作成します。 これはSQLのようなものですが、はるかに単純で直感的です。 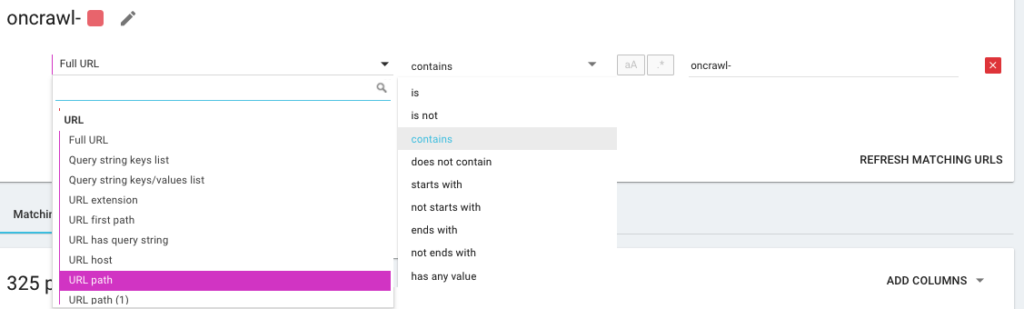
AND / OR条件演算子を使用して、可能な限り正確にすることもできます。 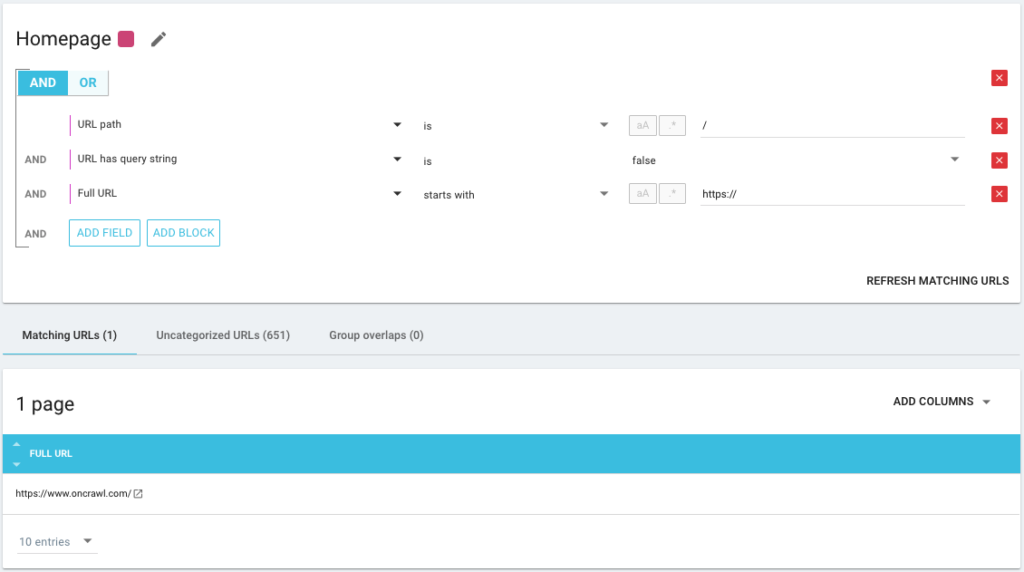
さまざまな方法を使用してページをセグメント化する
他のKPIの使用
URLに基づくセグメンテーションは優れていますが、 / car-rental /で始まりH1が「レンタカー会社」という表現を持つURLをグループ化するなど、他のKPIとH1が「ユーティリティレンタカー会社」、それは可能ですか?
はい、可能です! セグメンテーションの作成中に、クローラーからのものだけでなく、コネクタからのものも含めて、使用するすべてのKPIを自由に使用できます。 これにより、セグメンテーションの作成が非常に強力になり、まったく異なる角度の分析が可能になります。
たとえば、Google Search Consoleコネクタのおかげで、URLの平均位置を使用してセグメンテーションを作成するのが大好きです。
このようにして、構造の奥深くでまだ実行されているURLや、Googleの2ページ目にあるホームページに近いURLを簡単に識別できます。
これらのページに重複するコンテンツがあるかどうか、空のタイトルタグがあるかどうか、十分なリンクを受け取っているかどうかを確認できます…これらのページでのGooglebotの動作も確認できます。 クロール頻度は良いですか悪いですか? つまり、SEOとROIに実際に影響を与える優先順位を付けて決定を下すのに役立ちます。
オンクロールデータ³
 もっと詳しく知る
もっと詳しく知るデータ取り込みの使用
データ取り込み機能に慣れていない場合は、最初にこのテーマに関するこの記事を読むことをお勧めします。 これは、外部データソースをOncrawlに追加できるもう1つの非常に強力なツールです。
たとえば、SEMrush、Ahrefs、Babbar.techからデータを追加できます。利点は、これらのツールから取得したメトリックに従ってページをグループ化し、関心のあるデータに基づいて分析を実行できることです。 Oncrawlでネイティブに。
最近、私はグローバルなホテルグループと仕事をしました。 ホテルの記録が正しく入力されているかどうか、画像、動画、コンテンツなどがあるかどうかを知るために、内部スコアリング方法を使用します。これらは、クロールとログファイルのデータを相互分析するために使用した完了率を決定します。
この結果により、Googlebotが正しく入力されたページにより多くの時間を費やしているかどうか、スコアが90%を超えるページが深すぎるかどうか、十分なリンクを受信していないかどうかを知ることができます。スコアが高いほど、ページへのアクセス数が多くなり、Googleによる検索が増え、GoogleSERPでの位置が向上します。 ホテル経営者にホテルリストへの記入を促すための止められない議論!
SEOブレッドクラムトレイルに基づいてセグメンテーションを作成します
これがこの記事の主題なので、問題の核心に取り掛かりましょう。 URLの構造が特定のディレクトリにページを添付していない場合、サイトのページをセグメント化することが難しい場合があります。 これは、製品ページがすべてルートにあるeコマースサイトの場合によくあります。 したがって、ページがどのグループに属しているかをURLから知ることは不可能です。
ページをグループ化するには、ページが属するグループを識別する方法を見つける必要があります。 そのため、Oncrawlが提供するScraper機能を使用して、各URLのブレッドクラムseoトレイルを取得し、ブレッドクラムseoの値に基づいてそれらを分類するというアイデアがありました。
オンクロールによるSEOブレッドクラムスクレイピング
上で見たように、パンくずリストを取得するためのスクレイピングルールを設定します。 ほとんどの場合、 divで情報を取得して取得できるため、非常に簡単です。各レベルのフィールドは次のようになります。
ulおよびliリスト: 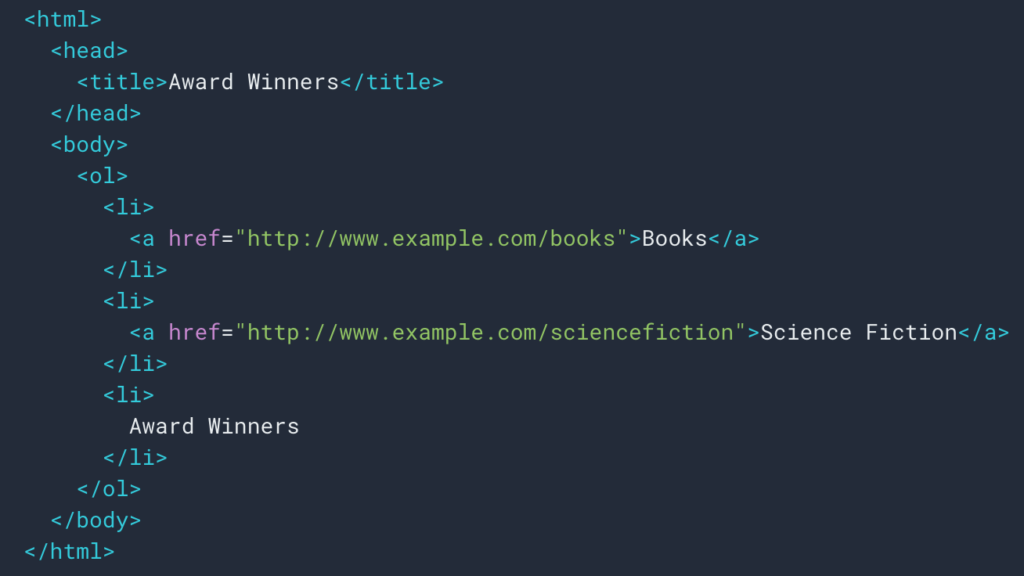
構造化データ型Breadcrumbのおかげで、情報を簡単に取得できる場合もあります。 したがって、各位置の「名前」フィールドの値を簡単に取得できます。 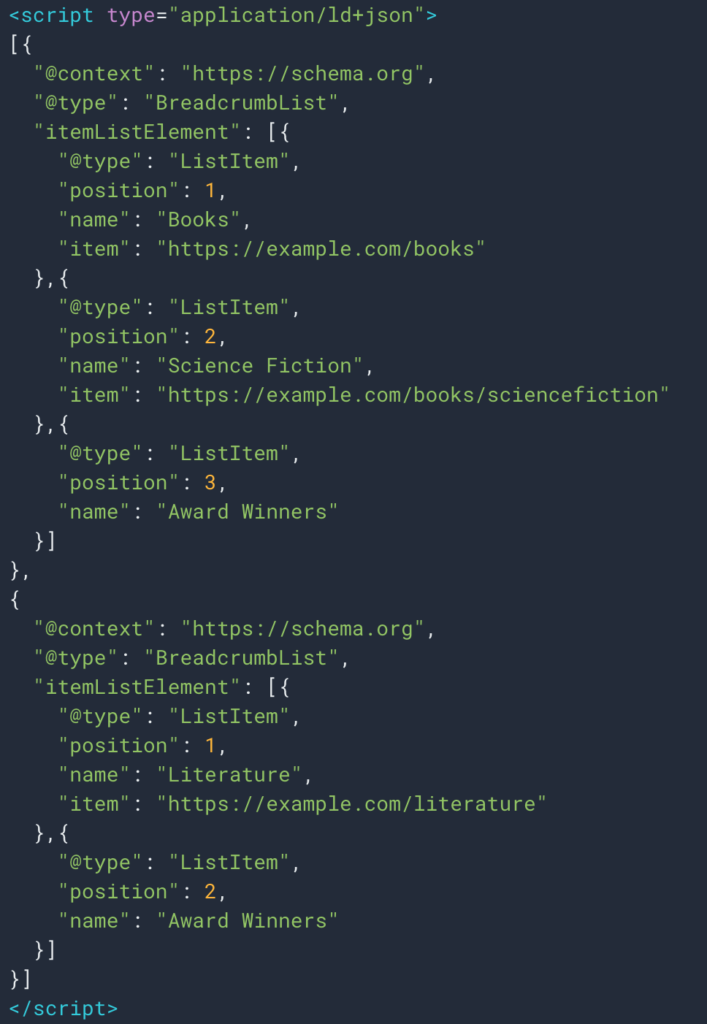
これが私が使用するスクレイピングルールの例です: 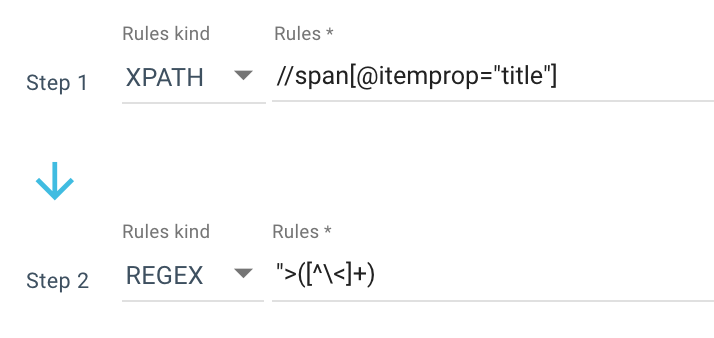
または、次のルール: //li[contains(@class, "current-menu-ancestor") or contains(@class, "current-menu-parent") or contains(@class, "current-menu-item")]/a/text()
したがって、Xpathを使用してすべてのspan itemprop=”title”を取得し、正規表現を使用して、 >文字ではない“>の後のすべてを抽出します。 正規表現について詳しく知りたい場合は、このテーマに関するこの記事と正規表現に関するチートシートを読むことをお勧めします。

出力として次のようないくつかの値を取得します。 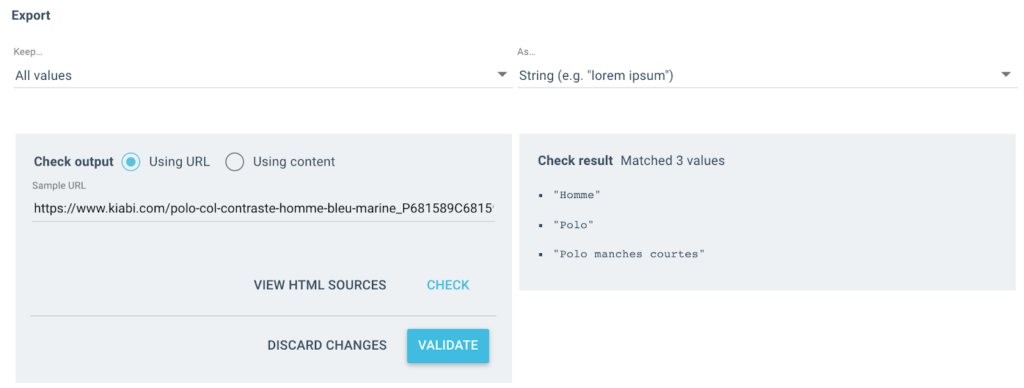
テストされたURLには、次の3つの値を持つ「ブレッドクラム」フィールドがあります。
- おとこ
- ポロシャツ
- 半袖ポロ
jsonをインポートする
ランダムにインポート
インポートリクエスト
#本物
#ブラウザからリクエストヘッダーを取得するよりもx-oncrawl-tokenを使用する2つの方法
#またはここにAPIトークンを使用:https://app.oncrawl.com/account/tokens
API_ACCESS_TOKEN =''
#ブレッドクラムカスタムフィールドがある場所にクロールIDを設定します
クロール_
#セグメンテーションで取得したくない禁止されているブレッドクラムアイテムを更新します
FORBIDDEN_BREADCRUMB_ITEMS =('Accueil'、)
FORBIDDEN_BREADCRUMB_ITEMS_LIST = [
v.strip()
FORBIDDEN_BREADCRUMB_ITEMS.split('、')のvの場合
]
def random_color():
random_number = random.randint(0、16777215)
hex_number = str(hex(random_number))
hex_number = hex_number [2:]。ljust(6、 '0')
f'#{hex_number}'を返します
def value_to_group(value):
戻る {
'color':random_color()、
'名前':値、
'oql':{'または':[{'field':['custom_Breadcrumb'、'equals'、value]}]}
}
def walk_dict(dictionary、level = 0):
ret = {
「アイコン」:「ダッシュボード」、
「転移因子」:偽、
"名前":"ブレッドクラム"
}ルールが定義されたので、クロールを起動できます。Oncrawlは、ブレッドクラムの値を自動的に取得し、クロールされた各URLに関連付けます。
Pythonでマルチレベルセグメンテーションの作成を自動化する
各URLのすべてのSEOブレッドクラム値を取得したので、Google Colabでseo自動化Pythonスクリプトを使用して、Oncrawlと互換性のあるセグメンテーションを自動的に作成します。
スクリプト自体には、次の3つのライブラリを使用します。
- json(Jsonで記述されたセグメンテーションを生成するため)
- csv
- ランダム(各グループの16進カラーコードを生成するため)
スクリプトが起動されると、プロジェクトでのセグメンテーションの作成が自動的に処理されます。 
分析におけるデータプレビュー
セグメンテーションが作成されたので、パンくずリストに基づいてセグメント化されたビューを使用して、さまざまな分析にアクセスできます。 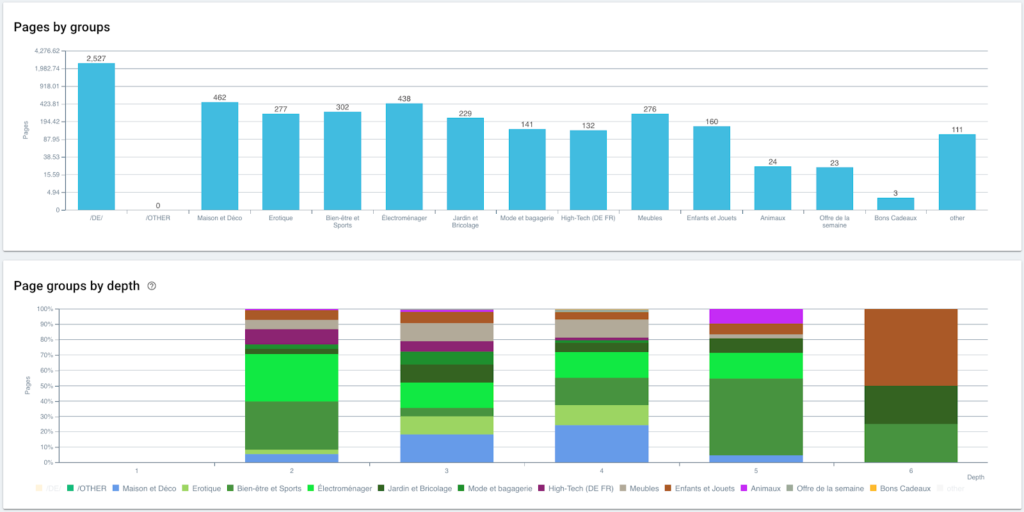
グループ別および深さ別のページの配布
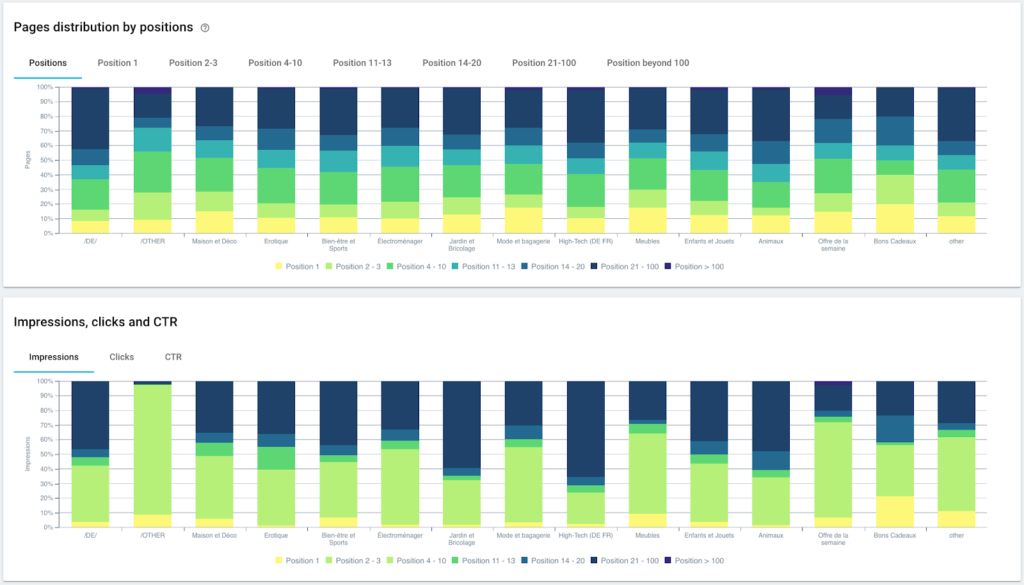
ランキングパフォーマンス(GSC)
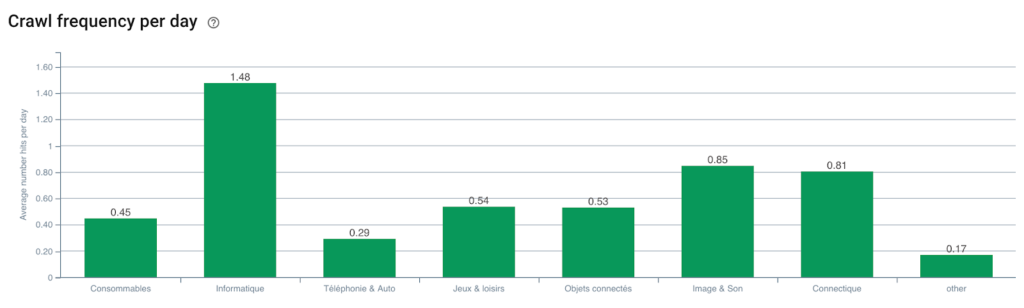
Googlebotのクロール頻度
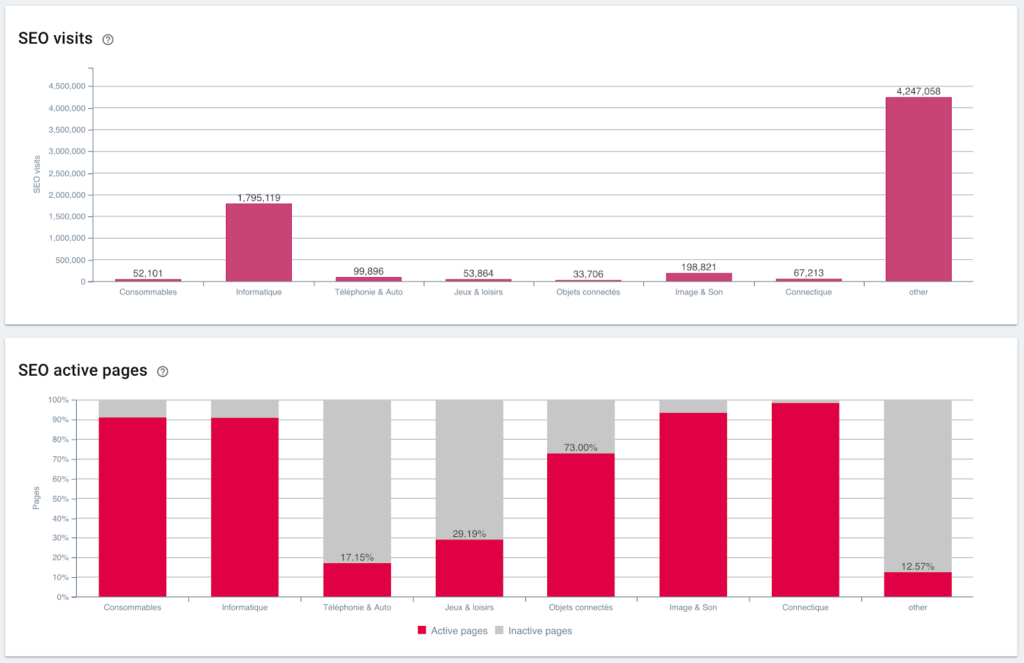
SEOの訪問とアクティブなページの比率
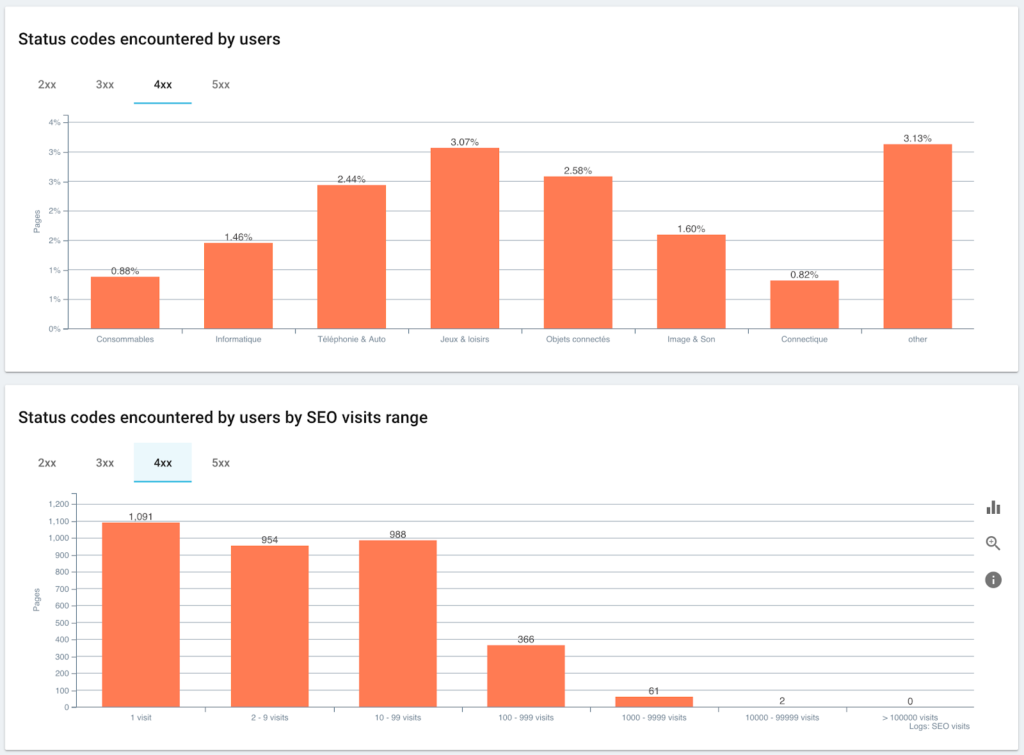
ユーザーとSEOセッションで遭遇したステータスコード
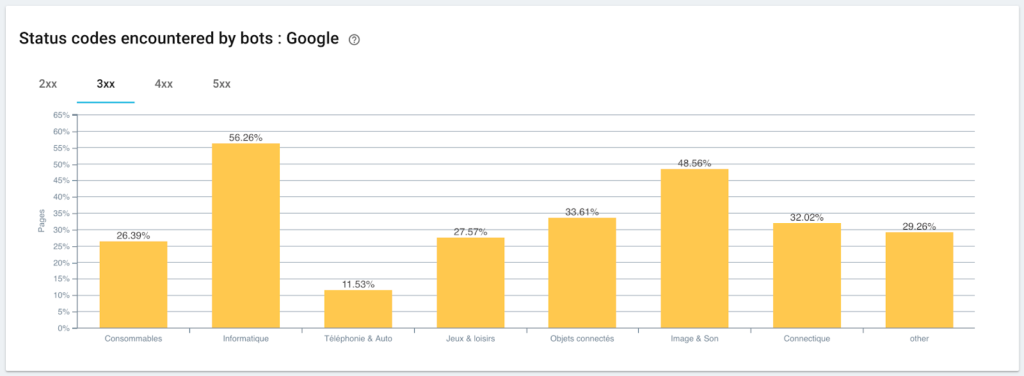
Googlebotが検出したステータスコードの監視
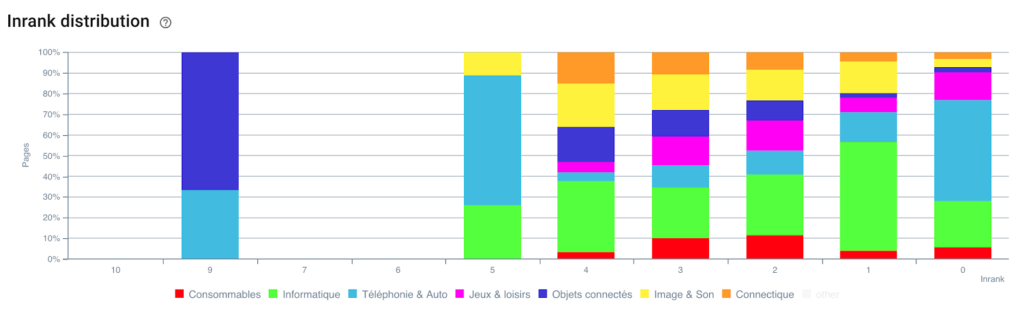
インランクの分布
PythonとOnCrawlを使用したスクリプトのおかげで、セグメンテーションが自動的に作成されました。 これで、すべてのページがパンくずリストに従ってグループ化され、これは3つのレベルの深さでグループ化されます。 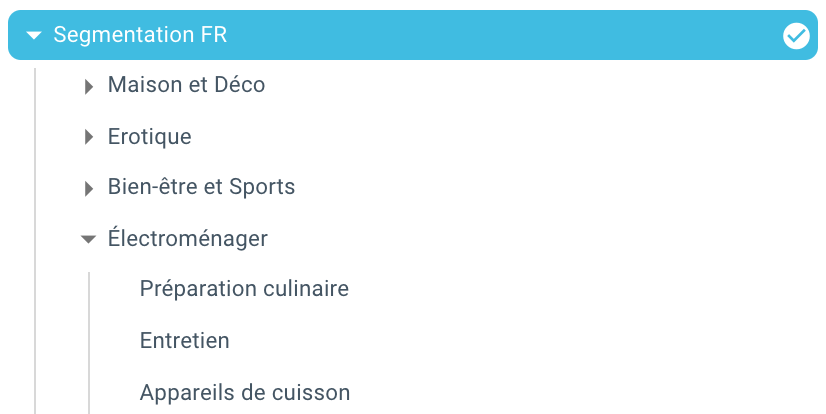
利点は、ページの各グループおよびサブグループのさまざまなKPI(クロール、深度、内部リンク、クロール予算、SEOセッション、SEO訪問、ランキングパフォーマンス、読み込み時間)を監視できることです。
OncrawlによるSEOの未来
この「すぐに使える」機能があるのは素晴らしいことだと思っているかもしれませんが、必ずしもすべてを実行する時間はありません。 幸いなことに、近い将来、この機能を直接統合するよう取り組んでいます。
これは、クリックするだけで、廃棄されたフィールドまたはデータインジェストからのフィールドにセグメンテーションをすぐに自動的に作成できるようになることを意味します。 そしてそれはあなたが信じられないほどの断面SEO分析を実行することを可能にしながらあなたにたくさんの時間を節約するでしょう。
ページのソースコードからデータを取得したり、URLごとにKPIを統合したりできると想像してみてください。 唯一の限界はあなたの想像力です!
たとえば、製品の販売価格を取得して、価格に応じた深さ、インランク、バックリンク、クロール予算を確認できます。
ただし、メディア記事の作成者の名前を取得して、誰が最もパフォーマンスが高いかを確認し、最も効果的な書き込み方法を適用することもできます。
商品のレビューと評価を取得し、最小限のクリックで最高の商品にアクセスできるかどうか、十分なリンクを受信できるかどうか、バックリンクがあるかどうか、Googlebotによって適切にクロールされているかどうかなどを確認できます。
売上高、マージン、コンバージョン率、Google広告費用などのビジネスデータを統合できます。
データを相互参照して分析を拡張し、適切なSEO決定を行う方法を想像するのは、あなた次第です。
ブレッドクラムトレイルで自動セグメンテーションをテストしますか? Oncrawl内から直接チャットボックス経由でお問い合わせください。
クロールをお楽しみください!