
テキストから概念とキーワードを自動的に抽出します(パートI:従来の方法)
公開: 2022-02-22OncrawlのR&D部門では、Webページのセマンティックコンテンツを強化することをますます求めています。 自然言語処理(NLP)の機械学習モデルを使用して、ページのコンテンツを詳細に比較したり、自動要約を作成したり、記事のタグを完成または修正したり、 Google検索コンソールのデータに従ってコンテンツを最適化したりできます。
前回の記事では、HTMLページからテキストコンテンツを抽出する方法について説明しました。 今回は、テキストからのキーワードの自動抽出についてお話します。 このトピックは2つの投稿に分けられます。
- 最初のものは、いくつかの具体的な例でコンテキストといわゆる「伝統的な」方法をカバーします
- 間もなく登場する2つ目は、これらのさまざまな方法をベンチマークするために、トランスフォーマーと評価方法に基づくよりセマンティックなアプローチを扱います。
環境
タイトルや要約を超えて、いくつかのキーワードを使用するよりも、テキスト、科学論文、またはWebページのコンテンツを識別するためのより良い方法はありません。 これは、はるかに長いテキストのトピックと概念を識別するためのシンプルで非常に効果的な方法です。 また、一連のテキストを分類するための良い方法でもあります。それらを識別し、キーワードでグループ化します。 PubMedやarxiv.orgなどの科学記事を提供するサイトは、これらのキーワードに基づいてカテゴリと推奨事項を提供できます。
キーワードは、非常に大きなドキュメントのインデックス作成や、検索エンジンでよく知られている専門分野である情報検索にも非常に役立ちます。
キーワードの欠如は、科学論文の自動分類[1]で繰り返し発生する問題です。多くの論文には、キーワードが割り当てられていません。 したがって、テキストから概念とキーワードを自動的に抽出するメソッドを見つける必要があります。 自動的に抽出された一連のキーワードの関連性を評価するために、データセットは、アルゴリズムによって抽出されたキーワードを、複数の人間によって抽出されたキーワードと比較することがよくあります。
ご想像のとおり、これはWebページを分類するときに検索エンジンが共有する問題です。 キーワード抽出の自動化されたプロセスをよりよく理解することで、Webページがそのようなまたはそのようなキーワードに対して配置される理由をよりよく理解することができます。 また、ターゲットにしたキーワードのランク付けを妨げるセマンティックギャップを明らかにすることもできます。
テキストまたは段落からキーワードを抽出する方法は明らかにいくつかあります。 この最初の投稿では、いわゆる「クラシック」アプローチについて説明します。
[電子ブック]データSEO:次の大冒険
 電子ブックを読む
電子ブックを読む拘束
それでも、アルゴリズムの選択にはいくつかの制限と前提条件があります。
- このメソッドは、単一のドキュメントからキーワードを抽出できる必要があります。 一部の方法では、完全なコーパス、つまり数百または数千ものドキュメントが必要です。 これらのメソッドは検索エンジンで使用できますが、単一のドキュメントには役立ちません。
- 教師なし機械学習の場合です。 フランス語、英語、またはその他の言語の注釈付きデータを含むデータセットは手元にありません。 つまり、キーワードがすでに抽出されているドキュメントは何千もありません。
- メソッドは、ドキュメントのドメイン/語彙フィールドから独立している必要があります。 ニュース記事、Webページなど、あらゆるタイプのドキュメントからキーワードを抽出できるようにする必要があります。各ドキュメントに対して既にキーワードが抽出されているデータセットの中には、ドメイン固有の医学、コンピュータサイエンスなどであることが多いことに注意してください。
- 一部の方法は、品詞タグ付けモデルに基づいています。つまり、動詞、名詞、限定詞などの文法タイプによって文中の単語を識別するNLPモデルの機能です。 限定詞ではなく名詞であるキーワードの重要性を判断することは、明らかに関連性があります。 ただし、言語によっては、品詞タグ付けモデルの品質が非常に不均一になる場合があります。
従来の方法について
いわゆる「従来の」方法と、NLP(自然言語処理)を使用する最近の方法(単語の埋め込みやコンテキストの埋め込みなどの手法)を区別します。 このトピックについては、今後の投稿で取り上げます。 しかし、最初に、古典的なアプローチに戻りましょう。2つを区別します。
- 統計的アプローチ
- グラフアプローチ
統計的アプローチは、主に単語の頻度とそれらの共起に依存します。 ヒューリスティックを構築し、重要な単語を抽出するための簡単な仮説から始めます。非常に頻繁な単語、複数回出現する一連の連続した単語など。グラフベースの方法では、各ノードが単語、グループに対応できるグラフを作成します。単語または文。 次に、各アークは、これらの単語を一緒に観察する確率(または頻度)を表すことができます。
ここにいくつかの方法があります:
- 統計ベース
- TF-IDF
- レーキ
- ヤケ
- グラフベース
- TextRank
- TopicRank
- SingleRank
与えられたすべての例は、このWebページから取られたテキストを使用しています:Jazz au Tresor:John Coltrane – ImpressionsGraz1962。
統計的アプローチ
RakeとYakeの2つの方法を紹介します。 SEOの文脈では、TF-IDFメソッドについて聞いたことがあるかもしれません。 ただし、ドキュメントのコーパスが必要なため、ここでは扱いません。
レーキ
RAKEは、RapidAutomaticKeywordExtractionの略です。 Pythonには、rake-nltkなど、このメソッドの実装がいくつかあります。 各キーワードのスコアは、複数の単語が含まれているためキーフレーズとも呼ばれ、単語の頻度と共起の合計という2つの要素に基づいています。 各キーフレーズの構成は非常に単純で、次のもので構成されています。
- テキストを文章にカットする
- 各文をキーフレーズにカットします
次の文では、句読点要素またはストップワードで区切られたすべての単語グループを取り上げます。
直前、コルトレーンはクインテットを率いており、エリック・ドルフィーが彼の側にいて、レジー・ワークマンがコントラバスに乗っていました。
これにより、次のキーフレーズが生成される可能性があります。
"Just before", "Coltrane", "head", "quintet", "Eric Dolphy", "sides", "Reggie Workman", "double bass" 。
ストップワードは、「「」 the 「」 in 「および」 or 「 it 」などの非常に頻繁な一連の単語であることに注意してください。 古典的な方法は単語の出現頻度の計算に基づいていることが多いため、ストップワードを慎重に選択することが重要です。 ほとんどの場合、キーフレーズの提案に>"to" 、 "the" or "of"などの単語を含めたくありません。 実際、これらのストップワードは特定の語彙フィールドに関連付けられていないため、たとえば「 jazz 」や「 saxophone 」という単語よりも関連性がはるかに低くなります。
いくつかの候補キーフレーズを分離したら、単語の頻度と共起に応じてスコアを付けます。 スコアが高いほど、キーフレーズの関連性が高くなります。

ジョン・コルトレーンに関する記事のテキストを使って簡単に試してみましょう。
#rakeのpythonスニペット rake_nltkからimportRake #「text」変数にすでに記事があるとします rake = Rake(stopwords = FRENCH_STOPWORDS、max_length = 4) rake.extract_keywords_from_text(text) rake_keyphrases = rake.get_ranked_phrases_with_scores()[:TOP]
最初の5つのキーフレーズは次のとおりです。
「オーストリアのナショナル・パブリック・ラジオ」、「叙情的なピークがより天国にある」、「グラーツには2つの特徴がある」、「ジョン・コルトレーンのテナーサックス」、「録音されたバージョンのみ」
この方法にはいくつかの欠点があります。 1つ目は、ストップワードを選択することの重要性です。ストップワードは、文を候補のキーフレーズに分割するために使用されるためです。 2つ目は、キーフレーズが長すぎると、存在する単語が共起するため、スコアが高くなることがよくあるということです。 キーフレーズの長さを制限するために、 max_length=4でメソッドを設定しました。
ヤケ
YAKEはYetAnotherKeywordExtractorの略です。 この方法は、次の記事YAKEに基づいています。 2020年にさかのぼる複数のローカル機能を使用した単一のドキュメントからのキーワード抽出。これは、作成者がGithubで利用可能なPython実装を提案したRAKEよりも新しい方法です。
RAKEについては、単語の頻度と共起に依存します。 著者はまた、いくつかの興味深いヒューリスティックを追加します。
- 小文字の単語と大文字の単語(最初の文字または単語全体)を区別します。 ここでは、大文字で始まる単語(文の先頭を除く)が他の単語よりも関連性が高いと想定します。人、都市、国、ブランドの名前です。 これは、すべての大文字の単語で同じ原則です。
- 各候補キーフレーズのスコアは、テキスト内での位置によって異なります。 候補のキーフレーズがテキストの最初に表示されている場合は、最後に表示されている場合よりもスコアが高くなります。 たとえば、ニュース記事では、記事の冒頭に重要な概念が記載されていることがよくあります。
#yakeのpythonスニペット yakeからインポートKeywordExtractorasYake yake = Yake(lan = "fr"、stopwords = FRENCH_STOPWORDS) yake_keyphrases = yake.extract_keywords(text)
RAKEと同様に、上位5つの結果は次のとおりです。
「トレジャージャズ」、「ジョンコルトレーン」、「インプレッションズグラーツ」、「グラーツ」、「コルトレーン」
一部のキーフレーズで特定の単語が重複しているにもかかわらず、この方法は非常に興味深いようです。
グラフアプローチ
このタイプのアプローチは、単語の共起も計算するという意味で、統計的アプローチからそれほど遠くありません。 TextRankなどの一部のメソッド名に関連付けられているランクサフィックスは、 PageRankアルゴリズムの原則に基づいており、着信リンクと発信リンクに基づいて各ページの人気を計算します。
[電子ブック]OncrawlによるSEOの自動化
 電子ブックを読む
電子ブックを読むTextRank
このアルゴリズムは、2004年の論文TextRank:Bringing Order into Textsに由来し、 PageRankアルゴリズムと同じ原則に基づいています。 ただし、ページとリンクを使用してグラフを作成する代わりに、単語を使用してグラフを作成します。 各単語は、共起に応じて他の単語とリンクされます。
Pythonにはいくつかの実装があります。 この記事では、pytextrankを紹介します。 品詞タグ付けに関する制約の1つを打ち破ります。 実際、グラフを作成するときに、すべての単語をノードとして含めるわけではありません。 動詞と名詞のみが考慮されます。 ストップワードを使用して無関係な候補を除外する以前の方法と同様に、TextRankアルゴは文法的なタイプの単語を使用します。
これは、アルゴによって作成されるグラフの一部の例です。 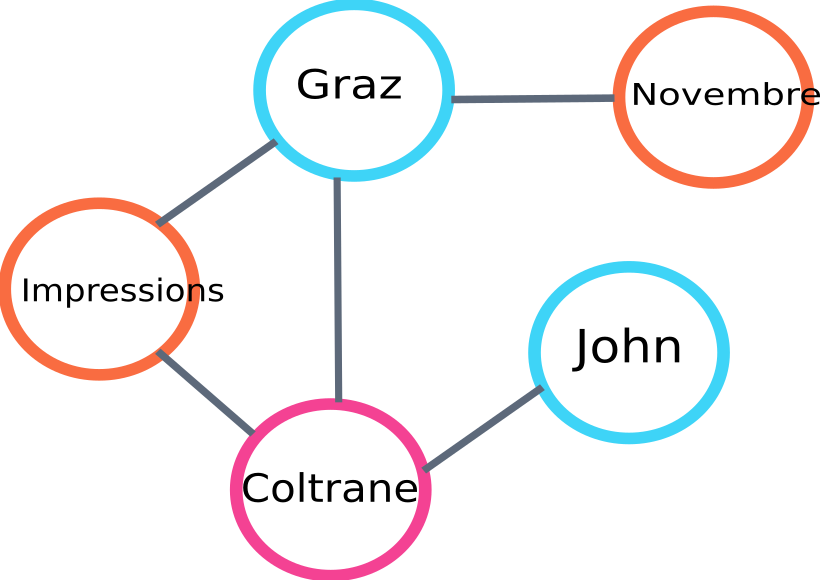
テキストランクグラフの例
Pythonでの使用例を次に示します。 この実装では、spaCyライブラリのパイプラインメカニズムを使用していることに注意してください。 品詞タグ付けができるのはこのライブラリです。
#pytextrankのPythonスニペット インポートスペーシー pytextrankをインポートする #フランスのモデルを読み込む nlp = spacy.load( "fr_core_news_sm") #パイプにpytextrankを追加します nlp.add_pipe( "textrank") doc = nlp(text) textrank_keyphrases =doc._。phrases
上位5つの結果は次のとおりです。
「コペンハーゲン」、「11月」、「印象グラーツ」、「グラーツ」、「ジョン・コルトレーン」
TextRankは、キーフレーズを抽出するだけでなく、文も抽出します。 これは、いわゆる「抽出要約」を作成するのに非常に役立ちます。この側面については、この記事では取り上げません。
結論
ここでテストされた3つの方法のうち、最後の2つは、テキストの主題に非常に関連しているように思われます。 これらのアプローチをよりよく比較するために、より多くの例でこれらの異なるモデルを評価する必要があることは明らかです。 これらのキーワード抽出モデルの関連性を測定するための指標は確かにあります。
これらのいわゆる従来のモデルによって生成されたキーワードのリストは、ページが適切にターゲットにされていることを確認するための優れた基盤を提供します。 さらに、検索エンジンがコンテンツをどのように理解して分類するかについての最初の概算を提供します。
一方、BERTなどの事前トレーニング済みのNLPモデルを使用する他の方法を使用して、ドキュメントから概念を抽出することもできます。 いわゆる古典的なアプローチとは対照的に、これらの方法は通常、セマンティクスのより良いキャプチャを可能にします。
さまざまな評価方法、コンテキスト埋め込み、トランスフォーマーは、このテーマに関する2番目の記事で紹介されます。
この記事から抽出されたキーワードのリストは、次の3つの方法のいずれかで示されています。
「メソッド」、「キーワード」、「キーワード」、「テキスト」、「抽出されたキーワード」、「自然言語処理」
書誌参照
- [1]より多くの言語知識を与えられた改善された自動キーワード抽出、Anette Hulth、2003
- [2]個々のドキュメントからの自動キーワード抽出、StuartRoseet。 al、2010
- [3]ヤケ! 複数のローカル機能を使用した単一のドキュメントからのキーワード抽出、RicardoCamposet。 al、2020
- [4] TextRank:テキストに秩序をもたらす、RadaMihalceaet。 al、2004
14日間の無料トライアルを開始する
 トライアルを開始する
トライアルを開始する