
真正性、Dalle-2 & Midjourney、そして AI が生成する画像とアートの魅力
公開: 2022-08-04この記事は、Dalle-2 や Midjourney などのプラットフォームの背後にあるテクノロジーと、作成者の Open AI が潜在的にお金を払うべきである理由について説明しています。
インターネット上で、Dalle-2 と Open AI を詐欺と呼ぶ人が増えています。 その理由は、Dalle-2 が突然収益化されたサービスになり、ベータ制限を超えてプラットフォームを使用する場合、クレジットを購入する必要があるためです。
DALLE 2 は、AI によって生成されたコンテンツへのアクセスを提供し、商用目的で使用できると主張する多くの新しいプラットフォームの 1 つにすぎません。 その他のプラットフォームには、Midjourney、Jasper Art、Nightcafe、Starry AI、Craiyon などがあります。 このブログ投稿では Dalle 2 に焦点を当てますが、法的な課題や問題に関してはほぼ同じです。
私たちの意見では、詐欺はかなり厳しい声明ですが、他の人が作成したデータ (写真、ビデオ、注釈、画像上の人物など) を使用して、それを同じ人に売り戻すことには明らかな問題があります.
私たちは単に新しいテクノロジーに魅了されているだけなので、この問題は見過ごされがちです。 まったく理解できるもの。
ただし、結局のところ、DALL-E 2 は高度なパターン認識マシンにすぎませんが、その出力はニュートラルではなく、パターンは新鮮な空気から得られるものではありません。
それらは、尋ねられるべき複数の法的質問がある大量のデータに基づいています. 生成した画像の潜在的なユーザーとして重要な質問。
 DALLE-2が作成した画像
DALLE-2が作成した画像
AIモデルは人間と比較することはできません
DALL-E 2 イメージを商用目的で使用することを検討する前に、Engadget のこの素晴らしい記事を読むことから始めてください。
Engadget の記事で、彼らはもう 1 つの非常に重要なことを指摘しています。 つまり、DALL-E 2 と OpenAI は、ユーザーが DALL-E を使用して作成した画像を商品化する独自の権利を放棄していないという事実です。 基本的には、他の人に商業的に販売する画像を生成できることを意味します。
これは、DALLE-2 推進者が確立された著者の作品を読んでいる学生と比較する場合に時々使用されるアナロジーとは意図が大きく異なることを示しています。 この例では、学生は著者のスタイルとパターンを学び、後でそれらが他のコンテキストに適用可能であることに気づき、そこで再利用することができます。
しかし、これは人間の脳が創造的な記憶を使って新しい創造的な作品を生み出すという話ではありません。 これは、パターン認識マシンが再利用し、場合によってはトレーニング データを画像に再現して使用したり、商業的に販売したりすることです。 それは、比喩的にも文字通りにも、単に 2 つの異なる世界です。
 現実世界の本物の写真
現実世界の本物の写真
JumpStory の信頼性に関する約束
この記事は、この新しい AI 画像生成技術がどのように機能するかをより深く理解したい人向けです。 しかし、始める前に、JumpStory が現在同様のマシンを構築していない理由について簡単に説明します。
もちろん、その質問は何度もされています。 特に、当社ではすでに AI を使用しており、何百万もの本物の画像にアクセスできるためです。
ただし、これは私たちにとって技術的な議論ではなく、倫理的な議論です。 私たちの真正性の約束につながった議論。
私たちは、AI によって生成された画像が例外ではなく標準になる未来に根本的に反対しています。 私たちのことを時代遅れと呼んでいますが、私たちは現実の世界は美しいと信じています。
私たちの写真とビデオは、さまざまな形やサイズの本物の人間を描いていることを誇りに思っています。 私たちは AI の使用に反対しているわけではありませんが、偽の人や現実を生成するために AI を使用するべきではないと考えています。
合成メディアや DALL-E 2 などのテクノロジーは、表面的には魅力的かもしれませんが、実際のリスクももたらします。 本物と偽物の境界線があいまいになる危険性があり、人間間の信頼に対する根本的な脅威となります。
これが、JumpStory が人工知能を使用して偽の画像を生成するのではなく、AI を使用して、どの画像がオリジナルで本物であり、もちろん商業目的での使用が合法であるかを識別する理由です。
これらは、当社のサービスを使用して見つけた画像であり、当社のアプローチを「オーセンティック インテリジェンス」と名付けました。
AI 画像がどのように生成されるかを理解する
今のところ、JumpStory と DALL-E 2 の法的な問題については十分です。 DALLE-2、Imagen、Crayion (以前の Dall-E Mini)、Midjourney などのプラットフォームで AI 画像がどのように生成されるかを見てみましょう。現在最も話題になっている例として DALLE-2 を使用します。

まず、DALLE-2 はさまざまな種類のタスクを実行できますが、このブログ投稿では画像生成のタスクに焦点を当てます。
どのように機能するかというと、テキスト プロンプトがテキスト エンコーダーに入力されます。 このエンコーダーは、プロンプトを表現空間にマッピングするようにトレーニングされています。 その後、いわゆる事前モデルが、エンコードされたテキストを、テキスト エンコーディング プロンプトのセマンティック情報をキャプチャする対応する画像エンコーディングにマップします。
(これがもうちょっとマニアックになっているのであれば、大変申し訳ありませんが、さらに悪化します )
イメージ エンコーダーの最後の手順は、エンコーダーが受け取ったセマンティック情報を視覚化するイメージを生成することです。 これは Open AI のような機械の基本です。
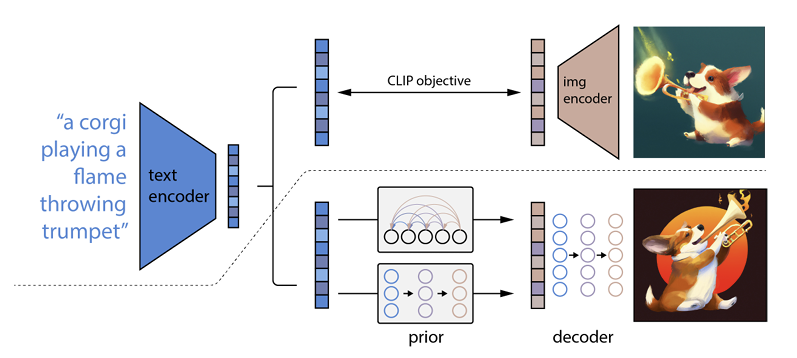
テキストとビジュアルの関係
DALL-E 2 および類似のテクノロジーは、テキストから画像へのジェネレーターと呼ばれることがよくあります。 その理由は、テキスト入力を受け取り、画像出力を配信する能力にあります。
例を挙げると、これは「アンディ・ウォーホルのスタイルで馬に乗っている宇宙飛行士:

ソース: DALLE-2
ここで起こることは、CLIP という名前の Open AI のモデルに基づいています。 CLIP は「Contrastive Language-Image Pre-training」の略で、何百万もの画像とキャプションでトレーニングされた非常に複雑なモデルです。
CLIP が特に得意とするのは、特定のテキストが特定の画像にどの程度関連しているかを理解することです。 ここで重要なのはキャプションではなく、特定のキャプションが特定の画像にどの程度関連しているかです。
この種の技術は「対照的」と名付けられており、CLIPができることは自然言語からセマンティクスを学習することです。 CLIPがこれを学習した方法は、目的が次のプロセスによるものです (現在は技術文書を引用しています)。 /キャプションのペア。
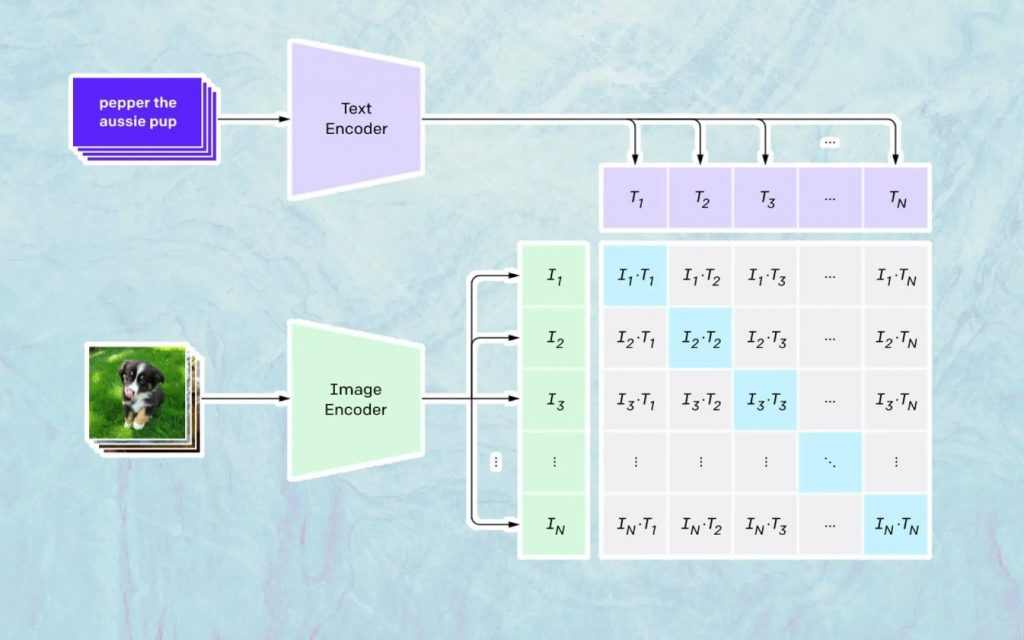
画像の生成
上記のように、CLIP モデルは、画像とテキストのエンコーディングがどのように関連しているかを判断できる表現空間を学習します。
次のタスクは、このスペースを使用して画像を生成することです。 この目的のために、Open AI は GLIDE という名前の別のモデルを開発しました。このモデルは、CLIP からの入力を使用し、拡散モデルを使用して画像生成を実行できます。
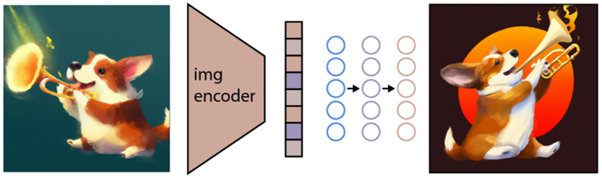
拡散モデルとは何かを簡単に説明すると、基本的には、段階的なノイズ プロセスを逆にしてデータを生成することを学習するモデルです。 申し訳ありませんが、これは非常に技術的なものになりました。Open AI のドキュメントにある説明を引用すると、次のようになります。
「ノイズ処理は、パラメータ化されたマルコフ連鎖と見なされ、画像に徐々にノイズを追加して画像を破損させ、最終的に (漸近的に) 純粋なガウス ノイズが発生します。 拡散モデルは、このチェーンに沿って逆方向にナビゲートすることを学習し、一連のタイムステップでノイズを徐々に除去して、このプロセスを逆転させます。」

テクノロジーについてさらに深く知りたい場合は、Ryan O'Connor によるこの優れた記事を読むことをお勧めします。