
[Webinar Digest] SEO in Orbit: Nuove prospettive sui contenuti duplicati
Pubblicato: 2019-11-20Il webinar Nuove prospettive sui contenuti duplicati è l'episodio finale della serie SEO in Orbit ed è andato in onda il 24 giugno 2019. In questo episodio, unisciti all'ambasciatore OnCrawl Omi Sido e Alexis Sanders mentre esplorano la questione dei contenuti duplicati. Affrontano domande come: in che modo i fattori di ranking e le tecnologie di ricerca in evoluzione influiscono sul modo in cui gestiamo i contenuti duplicati? E: cosa riserva il futuro per contenuti simili sul web?
SEO in Orbit è la prima serie di webinar che invia SEO nello spazio. Durante la serie, abbiamo discusso del presente e del futuro della SEO tecnica con alcuni dei migliori specialisti SEO e inviato i loro migliori consigli nello spazio il 27 giugno 2019.
Guarda il replay qui:
Presentando Alexis Sanders
Alexis Sanders lavora come Technical SEO Account Manager presso Merkle. Il team tecnico SEO garantisce l'accuratezza, la fattibilità e la scalabilità delle raccomandazioni tecniche dell'agenzia su tutti i verticali. Collabora al blog Moz e creatrice della sfida TechnicalSEO.expert e del podcast SEO in the Lab.
Questo episodio è stato presentato da Omi Sido. Omi è un esperto oratore internazionale ed è noto nel settore per il suo umorismo e la capacità di fornire informazioni fruibili che il pubblico può iniziare immediatamente a utilizzare. Dalla consulenza SEO con alcune delle più grandi società di telecomunicazioni e viaggi del mondo alla gestione della SEO interna presso HostelWorld e Daily Mail, Omi ama immergersi in dati complessi e trovare i punti positivi. Attualmente, Omi è Senior Technical SEO presso Canon Europe e OnCrawl Ambassador.
Che cos'è il contenuto duplicato?
Omi fornisce la seguente definizione di contenuto duplicato:
Contenuti duplicati simili o quasi a contenuti che risiedono su un URL diverso sullo stesso (o su un altro) sito web.
Il mito della sanzione per i contenuti duplicati
Non è prevista alcuna sanzione per i contenuti duplicati.
Questo è un problema di prestazioni. Non vogliamo che un bot guardi due URL particolari e pensi che siano due contenuti diversi che possono essere classificati uno accanto all'altro.
Alexis confronta la comprensione del tuo sito Web da parte di un bot con le immagini di Joey di 10 cose che odio di te: è impossibile per un bot trovare una differenza sostanziale tra le due versioni.

Vuoi evitare di avere due cose identiche che devono competere tra loro in una situazione di posizionamento sui motori di ricerca. Invece, vuoi avere un'esperienza unica e consolidata in grado di classificarsi ed esibirsi nei motori di ricerca.
Differenza tra ciò che vedono utenti e bot
Un utente potrebbe vedere un singolo URL convincente, ma un bot potrebbe comunque vedere più versioni che sembrano essenzialmente uguali.
– Effetto sul crawl budget per siti molto grandi
Per i siti molto grandi, come Zillow o Walmart, il budget di scansione può variare per pagine diverse.
Come discusso da Alexis in un articolo del 2018 basato su una presentazione di Frederic Dubut a SMX East, i budget sono fissati a vari livelli, a livelli di sottodomini, a diversi livelli di server. I motori di ricerca, Google o Bing, vogliono essere educati crawler; non vogliono rallentare le prestazioni per gli utenti effettivi. Ogni volta che avvertono un cambiamento nelle prestazioni, si tirano indietro. Ciò può verificarsi a diversi livelli, non solo a livello di sito.
Se hai un sito enorme, vuoi assicurarti di offrire l'esperienza più consolidata e rilevante per i tuoi utenti.
Il contenuto duplicato è un contenuto o un problema tecnico?
Nonostante la parola "contenuto" in "contenuto duplicato", è in parte un problema tecnico.
– Fonti di duplicazione – [07:50]
Ci sono molti fattori che possono causare la duplicazione. Anche un elenco parziale può sembrare che continui all'infinito:
- Pagine ripetitive
- Siti di sosta
- URL HTTP e HTTPS
- Sottodomini diversi
- Casi diversi
- Diverse estensioni di file
- Barra finale
- Pagine indice
- Parametri URL
- Sfaccettature
- Ordina
- Versione stampabile
- Pagina della porta
- Inventario
- Contenuti sindacati
- Comunicati PR
- Ripubblicare i contenuti
- Contenuti plagiati
- Contenuti localizzati
- Contenuto sottile
- Solo-immagini
- Ricerca interna del sito
- Sito mobile separato
- Contenuti non unici
- …
– Distribuzione delle problematiche tra SEO tecnico e contenuto
In effetti, queste fonti di contenuto duplicato possono essere suddivise in fonti tecniche e di sviluppo e fonti basate sul contenuto e alcune che rientrano in una zona di sovrapposizione tra le due.
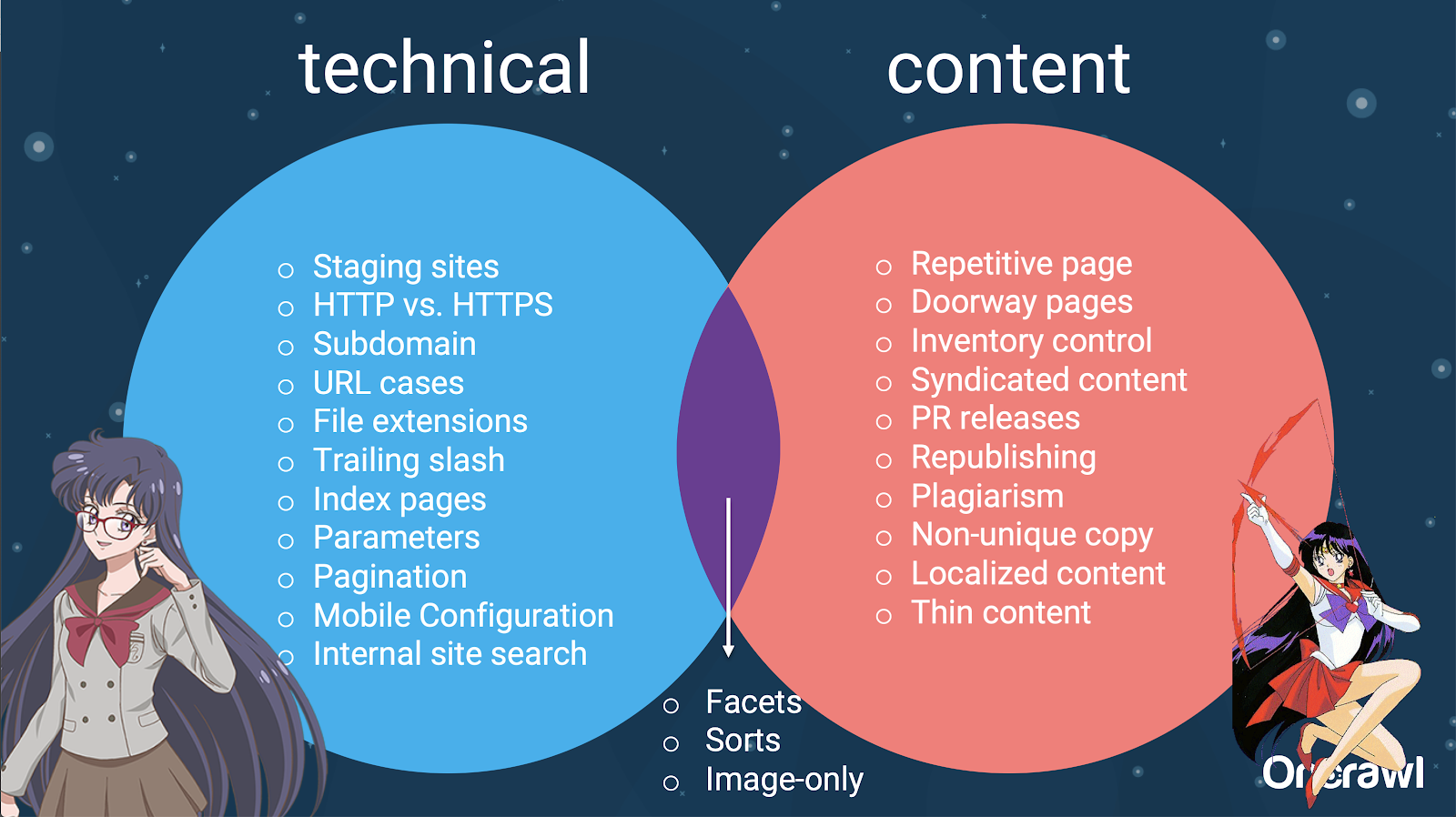
Ciò rende il contenuto duplicato un problema tra i team, il che è parte di ciò che lo rende così interessante.
Come trovare contenuti duplicati
La maggior parte dei contenuti duplicati non è intenzionale. Per Omi, questo indica che esiste una responsabilità condivisa tra i team dei contenuti e quelli tecnici per la ricerca e la correzione dei contenuti duplicati.
– Lo strumento preferito di Omi: Grammarly
Grammarly è lo strumento preferito di Omi per trovare contenuti duplicati e non è nemmeno uno strumento SEO. Usa il controllo del plagio. Chiede all'editore di contenuti di verificare se un nuovo contenuto è già stato pubblicato altrove.
– Volume di contenuti duplicati non intenzionali
Il problema dei contenuti duplicati involontari è molto familiare agli ingegneri. In un libro intitolato Introduction to Information Retrieval (2008), che è chiaramente molto obsoleto, hanno stimato che circa il 40% del web in quel momento era duplicato.

– Assegnare priorità alle strategie per gestire i contenuti duplicati
Per gestire i contenuti duplicati, dovresti:
- Inizia conoscendo il percorso dell'utente, che ti aiuterà a capire dove si adatta ogni contenuto. Questo può essere estremamente difficile da fare, in particolare quando i siti Web sono stati creati 20 anni fa, quando non sapevamo quanto sarebbero diventati grandi o come si sarebbero ridimensionati. Sapere dove si trova il tuo utente in un dato momento del suo viaggio ti aiuterà a stabilire le priorità in alcuni dei passaggi successivi.
- Avrai bisogno di una gerarchia che funzioni, al fine di fornire un posto per ogni tipo di contenuto. Comprendere la tua architettura delle informazioni è molto importante nei passaggi per gestire i contenuti duplicati.
- Dai la priorità ai contenuti duplicati che influiscono sulle prestazioni. L'elenco parziale delle fonti di cui sopra è troppo lungo per essere qualcosa che puoi realisticamente attaccare tutto in una volta.
- Gestisci la duplicazione al 100%.
- Segnala contenuti duplicati
- Fai una scelta strategica su come gestire la duplicazione: consolida, crea, elimina, ottimizza
- Gestisci i contenuti rubati

– Strumenti: utilizzo della segmentazione in OnCrawl
Ad Alexis piace molto la possibilità di segmentare il tuo sito Web in OnCrawl, che ti consente di immergerti in cose significative per te.
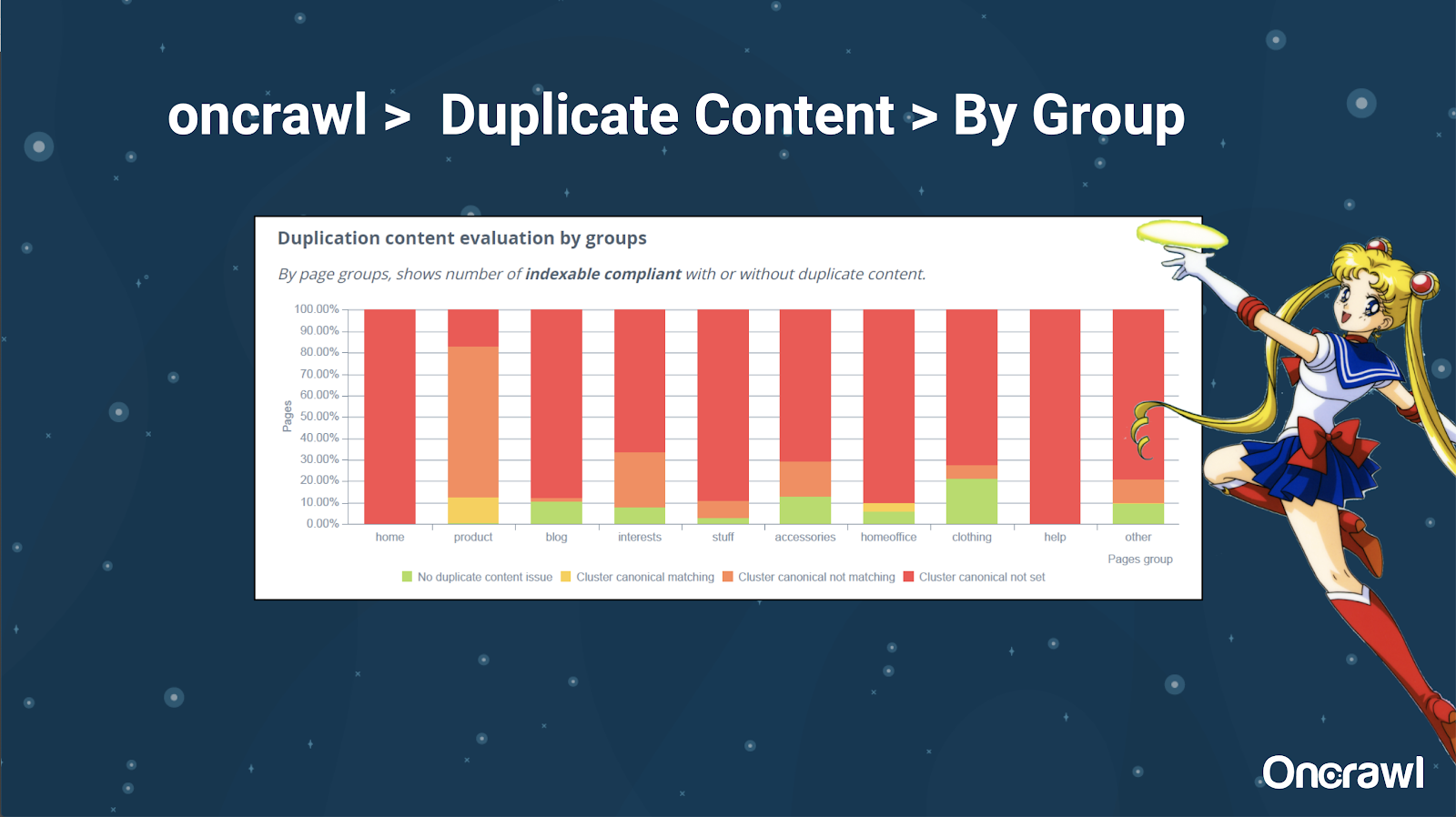
Pagine di tipi diversi hanno quantità diverse di duplicazione; questo permette di avere una visione delle sezioni che presentano più problemi. Nell'esempio sopra, il sito ha bisogno di molta attenzione.
– Strumenti: ricerca Google e GSC
Puoi anche verificare la presenza di contenuti duplicati utilizzando il motore di ricerca stesso. In Google puoi:
- Usa virgolette dirette
- Usa sito: ricerche
- Utilizzo di operatori aggiuntivi come inurl:, intitle: o filetype:

Google Search Console ha anche aggiunto un rapporto sui contenuti duplicati, che è molto utile per identificare ciò che Google ritiene essere contenuti duplicati dalla loro parte.
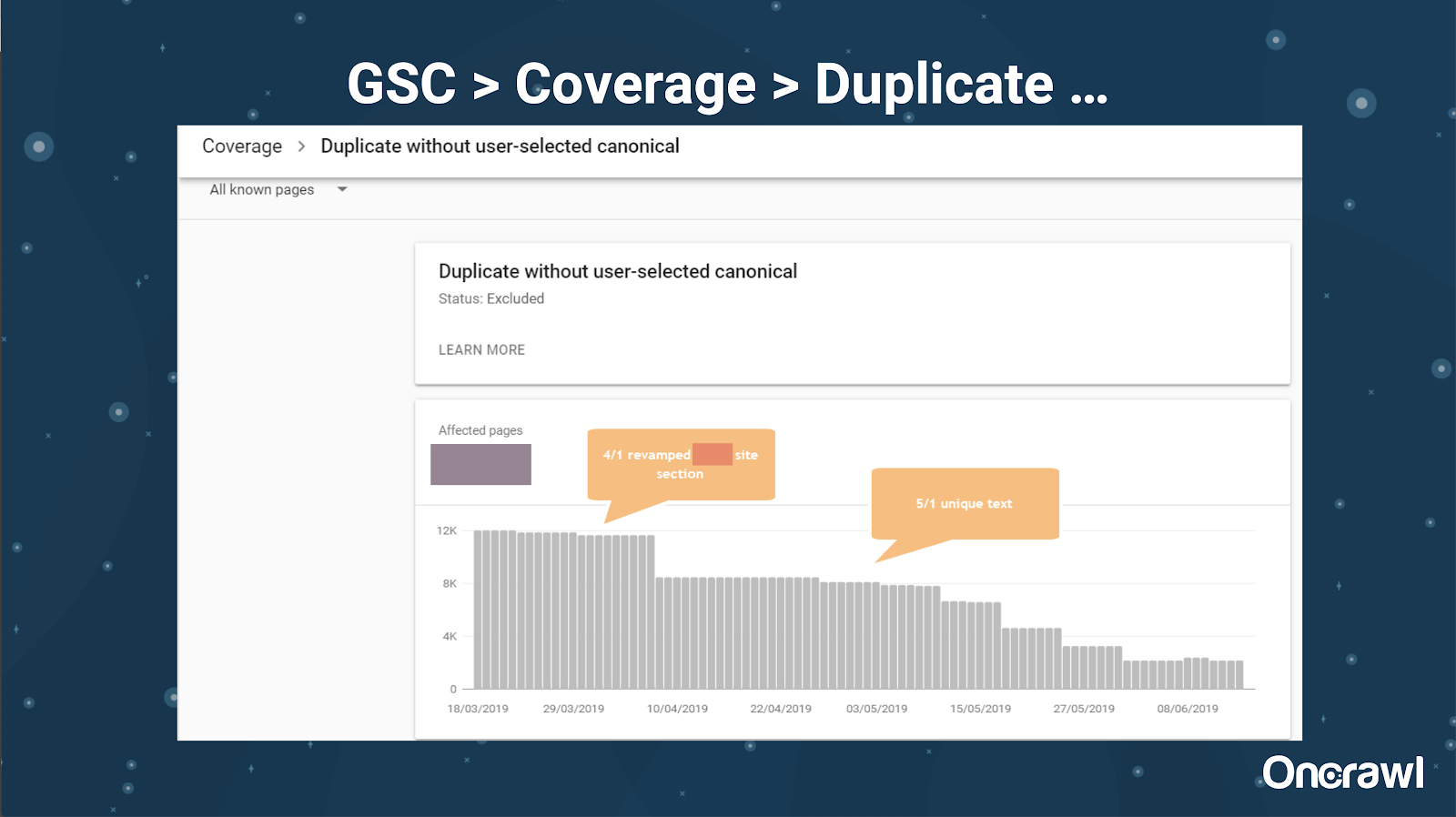
– Strumenti: strumenti per il plagio
Come Omi, anche Alexis utilizza diversi strumenti di plagio:
Quetext
Noplag
PaperRater
Grammaticamente
CopyScape
Vuoi assicurarti che i tuoi contenuti non siano solo originali, ma anche dal punto di vista di un bot, che non vengano percepiti come tratti da un'altra fonte.
Questi possono anche aiutarti a trovare segmenti all'interno di un articolo che potrebbero essere simili a contenuti altrove su Internet.
Alexis adora il modo in cui disponiamo di questi strumenti che ci consentono di essere "empatici con i robot dei motori di ricerca", poiché nessuno di noi è un robot. Quando gli strumenti ci segnalano che i contenuti sono troppo simili, anche se sappiamo che c'è una differenza, è un buon segno che c'è qualcosa su cui approfondire.

– Strumenti: strumenti per la densità delle parole chiave
Due esempi di strumenti per la densità delle parole chiave utilizzati da Alexis sono:
TagCrowd
SEObook
Problemi che dipendono dal tipo di sito
La risoluzione dei contenuti duplicati dipende in realtà dal tipo di contenuto che stai pubblicando e dal tipo di problema che stai affrontando. I blog non devono affrontare gli stessi casi di contenuti duplicati dei siti di e-commerce, ad esempio.
Casi memorabili
Alexis condivide casi di clienti recenti in cui ha riscontrato problemi di contenuti duplicati memorabili.
– Sito di grandi dimensioni: risultati dopo l'aggiunta di contenuti unici
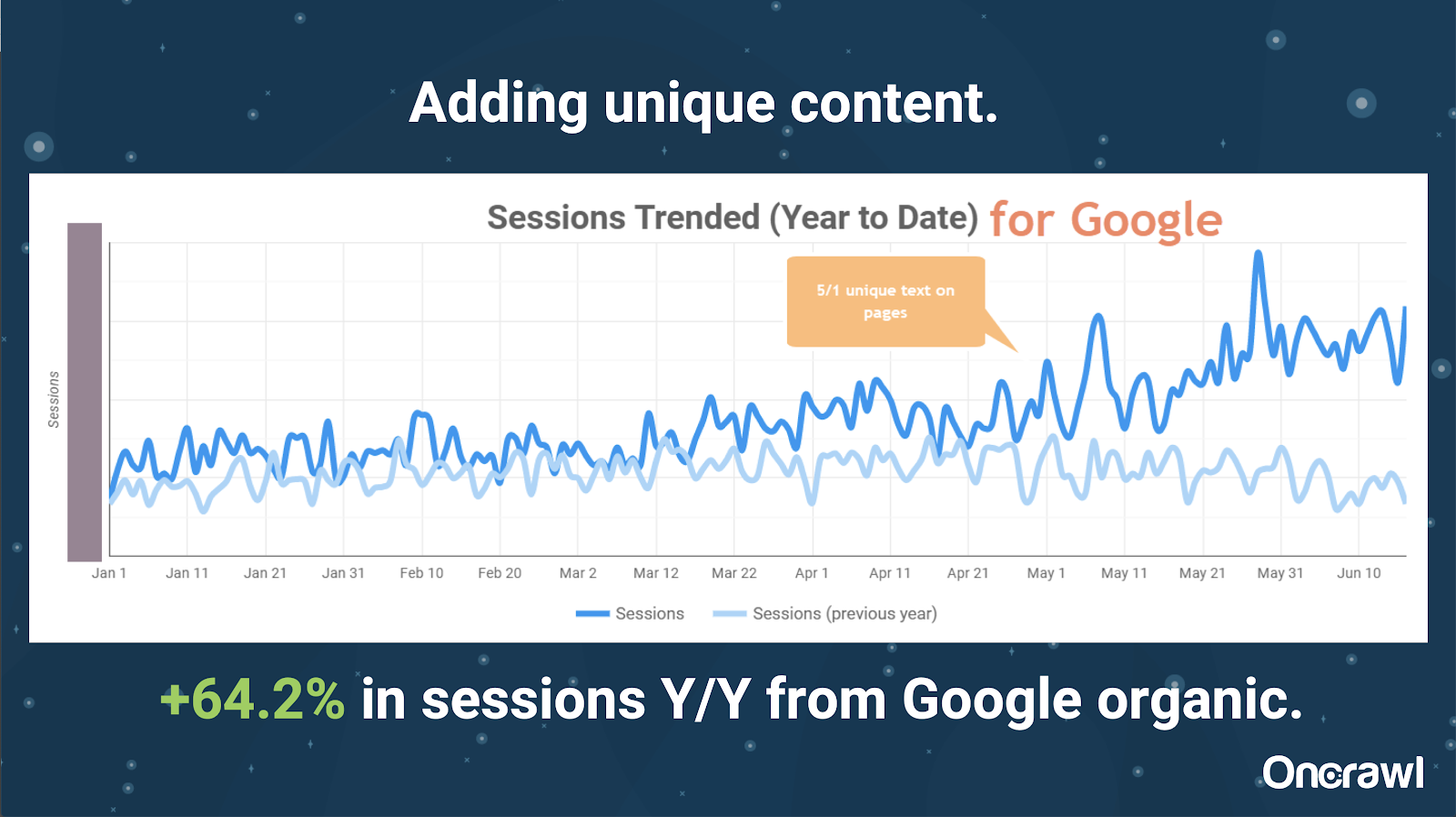
Questo sito era enormemente grande e presenta problemi di crawl budget. Ha 86 milioni di pagine che non sono state ancora indicizzate e solo l'1% circa delle sue pagine è stato indicizzato.
Questo è un sito immobiliare, quindi gran parte del contenuto non è particolarmente unico e molte delle loro pagine sono molto, molto simili. Alexis ha finito per aggiungere contenuti alla pagina per aggiungere informazioni specifiche sulla posizione per differenziare le pagine. È stato sorprendente quanto velocemente questo abbia prodotto risultati. (Questi sono solo dati organici di Google.)
Per Alexis, questo è un caso di studio piuttosto generico. Per quanto oggi si parli di EAT e cose simili, ciò dimostra che non appena i motori di ricerca vedono i contenuti come unici e di valore, ciò viene comunque premiato.

Su questo sito, un problema di tag canonico accidentale ha causato l'invio di circa 250 pagine al protocollo sbagliato.
Questo è un caso in cui i tag canonici hanno indicato la pagina principale sbagliata, spingendo le pagine HTTP al posto della pagina HTTPS.
Cambiamenti negli ultimi 18 mesi
Alexis ha scritto un articolo molto completo, Contenuto duplicato e risoluzione strategica, circa 18 mesi prima di questo webinar. La SEO cambia rapidamente e devi costantemente rinnovare e rivalutare le tue conoscenze.
Per Alexis, la maggior parte di ciò che è menzionato nell'articolo è ancora rilevante oggi, con l'eccezione per rel=next/prev. Tuttavia, spera che cesserà di essere rilevante entro i prossimi cinque o dieci anni.
Problemi tecnici gestiti dagli sviluppatori: troppo manuale
Molti dei problemi relativi ai contenuti duplicati gestiti dagli sviluppatori sono troppo manuali. Alexis ritiene che dovrebbero essere gestiti invece da CMS e Adobe. Ad esempio, non dovresti passare manualmente e assicurarti che tutti i canonici siano impostati e coerenti.
– Opportunità di automazione/notifica
Ci sono molte opportunità per l'automazione nell'area dei problemi tecnici con contenuti duplicati. Per fare un esempio: dovremmo essere in grado di rilevare immediatamente se dei collegamenti stanno andando su HTTP quando dovrebbero andare su HTTPS e correggerli.
– L'età del sito e l'infrastruttura legacy come ostacolo
Alcuni sistemi back-end sono troppo vecchi per supportare determinate modifiche e automazioni. È estremamente difficile migrare un vecchio CMS in uno nuovo. Omi fornisce l'esempio della migrazione dei siti Web Canon a un nuovo CMS personalizzato. Non solo era costoso, ma ci sono voluti 12 mesi.
Rel prev/next e comunicazione da Google
A volte la comunicazione da parte di Google è un po' confusa. Omi cita un esempio in cui, applicando rel=prev/next, il suo cliente ha visto un aumento significativo delle prestazioni nel 2018, nonostante l'annuncio di Google del 2019 che questi tag non sono stati utilizzati per anni.
– Mancanza di soluzioni universali
La difficoltà con la SEO è che ciò che una persona osserva accadere sul proprio sito Web non è necessariamente lo stesso di ciò che un altro SEO vede sul proprio sito Web; non esiste una SEO valida per tutti.
La capacità di Google di fare annunci pertinenti a tutti i SEO dovrebbe essere riconosciuta come un'impresa importante, anche alcune delle loro affermazioni sono mancate, come nel caso di rel=next/prev.
Speranze per il futuro della gestione dei contenuti duplicati
Le speranze di Alexis per il futuro:
- Contenuti duplicati meno tecnici (come dicono i CMS).
- Più automazione (test unitari e test esterni). Ad esempio, strumenti come OnCrawl potrebbero eseguire regolarmente la scansione del tuo sito e avvisarti non appena notano determinati errori.
- Rileva automaticamente pagine e tipi di pagina ad alta somiglianza per scrittori e gestori di contenuti. Ciò automatizzerebbe alcune delle verifiche che vengono attualmente eseguite manualmente in strumenti come Grammarly: quando qualcuno tenta di pubblicare, il CMS dovrebbe dire "questo è un po' simile, sei sicuro di volerlo pubblicare?" C'è molto valore nel guardare i singoli siti Web e nel confronto tra siti Web.
- Google continua a migliorare i propri sistemi e il rilevamento esistenti.
- Forse un sistema di avviso per intensificare il problema di Google che non utilizza il canonico giusto. Sarebbe utile poter avvisare Google del problema e risolverlo.
Abbiamo bisogno di strumenti migliori, strumenti interni migliori, ma si spera che mentre Google svilupperà i propri sistemi, aggiungeranno elementi per aiutarci un po'.
I trucchi tecnici preferiti da Alexis
Alexis ha diversi trucchi tecnici preferiti:
- Istanza del computer remoto EC2. Questo è davvero un ottimo modo per accedere a un computer reale per crawl molto grandi o qualsiasi cosa che richieda molta potenza di calcolo. È estremamente veloce una volta impostato. Assicurati solo di terminarlo quando hai finito, poiché costa denaro.
- Controlla lo strumento di test mobile first. Google ha affermato che questa è l'immagine più accurata di ciò che stanno guardando. Guarda il DOM.
- Passa allo user agent in Googlebot. Questo ti darà un'idea di ciò che stanno realmente vedendo i Googlebot.
- Utilizzando lo strumento robots.txt di TechnicalSEO.com. Questo è uno degli strumenti di Merkle, ma ad Alexis piace davvero perché robots.txt a volte può creare molta confusione.
- Usa un analizzatore di log.
- Realizzato con il controllo htaccess di Love.
- Utilizzo di Google Data Studio per generare rapporti sulle modifiche (sincronizzazione di Fogli con aggiornamenti, filtraggio di ogni pagina in base agli aggiornamenti pertinenti).
Difficoltà tecniche SEO: robots.txt
Robots.txt è davvero confuso.
È un file arcaico che sembra essere in grado di supportare RegEx, ma non lo fa.
Ha regole di precedenza diverse per le regole di non autorizzazione e autorizzazione, che possono creare confusione.
Robot diversi possono ignorare cose diverse, anche se non dovrebbero.
Le tue ipotesi su ciò che è giusto non sono sempre giuste.

Domande e risposte
– HSTS: è necessario il protocollo diviso?
Devi avere tutti gli HTTPS per i contenuti duplicati se hai HSTS.
– Il contenuto tradotto è contenuto duplicato?
Spesso, quando usi hreflang, lo usi per disambiguare tra versioni localizzate all'interno della stessa lingua, come una pagina in lingua inglese statunitense e irlandese. Alexis non prenderebbe in considerazione questo contenuto duplicato, ma consiglierebbe sicuramente di avere i tag hreflang impostati correttamente per indicare che si tratta della stessa esperienza, ottimizzata per un pubblico diverso.
– Puoi utilizzare tag canonici invece di reindirizzamenti 301 per una migrazione HTTP/HTTPS?
Sarebbe utile verificare cosa sta realmente accadendo nelle SERP. L'istinto di Alexis è di dire che andrebbe bene, ma dipende da come si sta effettivamente comportando Google. Idealmente, se si tratta della stessa identica pagina, dovresti usare un 301, ma in passato ha visto che i tag canonici funzionano per questo tipo di migrazione. In realtà l'ha anche visto accadere accidentalmente.
Secondo l'esperienza di Omi, suggerirebbe vivamente di utilizzare i 301 per evitare problemi: se stai migrando il sito web, potresti anche migrarlo correttamente per evitare errori attuali e futuri.
– Effetto dei titoli delle pagine duplicati
Diciamo che hai un titolo molto simile per luoghi diversi, ma il contenuto è molto diverso. Anche se questo non è un contenuto duplicato per Alexis, vede i motori di ricerca come trattarlo come una cosa di tipo "generale" e i titoli sono qualcosa che può essere utilizzato per identificare le aree con possibili problemi.
Qui è dove potresti voler usare una ricerca [site: + intitle: ].
Tuttavia, solo perché hai lo stesso tag del titolo, non causerà un problema di contenuto duplicato.
Dovresti comunque puntare a titoli e meta descrizioni univoci, anche su pagine impaginate o molto simili. Questo non è dovuto a contenuti duplicati, ma riguarda il modo in cui vuoi ottimizzare il modo in cui presenti le tue pagine nelle SERP.
Il miglior consiglio
"Il contenuto duplicato è una sfida sia tecnica che di marketing dei contenuti".
SEO in Orbit è andato nello spazio
Se ti sei perso il nostro viaggio nello spazio il 27 giugno, prendilo qui e scopri tutti i suggerimenti che abbiamo inviato nello spazio.