
Utilizzo di Python e delle Sitemap per controllare le strategie di contenuto
Pubblicato: 2020-10-08L'interesse per ciò che si può fare per conto della SEO con le librerie Python non è più un segreto. Tuttavia, la maggior parte delle persone con poca esperienza di programmazione ha difficoltà a importare e utilizzare un gran numero di librerie o a spingere, i risultati vanno oltre ciò che qualsiasi normale crawler o strumento SEO può fare.
Ecco perché una libreria Python creata appositamente per SEO, SEM, SMO, controllo SERP e analisi dei contenuti è utile a tutti.
In questo articolo, daremo un'occhiata ad alcune delle cose che si possono fare con la Libreria Python di Advertools per SEO, creata e sviluppata da Elias Dabbas, e per la quale vedo un grande potenziale in SEO, PPC e capacità di codifica in brevissimo tempo. Inoltre, utilizzeremo script Python personalizzati insieme ad altre librerie Python in modo educativo e adattivo.
Esamineremo cosa si può imparare per la SEO da una mappa del sito grazie alla funzione sitemap_to_df di Elias Dabbas che aiuta a scaricare e analizzare le mappe del sito XML (una mappa del sito è un documento in formato XML utilizzato per segnalare URL scansionabili e indicizzabili ai motori di ricerca.)
Questo articolo ti mostrerà come scrivere codici Python personalizzati per analizzare diversi siti Web in base alla loro diversa struttura, come interpretare i dati in termini di SEO e come pensare come un motore di ricerca quando si tratta di profili di contenuto, URL e strutture del sito .
Analizzare la scala dei contenuti e la strategia di un sito Web in base alla sua mappa del sito
Una mappa del sito è un componente di un sito Web in grado di acquisire molti tipi diversi di dati, come la frequenza con cui un sito Web pubblica contenuti, categorie di contenuti, date di pubblicazione, informazioni sull'autore, soggetto del contenuto...
In condizioni normali, puoi raschiare una mappa del sito con scrapy, convertirla in un DataFrame con Pandas e interpretarla con molte librerie ausiliarie diverse, se lo desideri.
Ma in questo articolo useremo solo Advertools e alcuni metodi e attributi della libreria Pandas. Verranno attivate alcune librerie per visualizzare i dati che abbiamo acquisito.
Entriamo subito e selezioniamo un sito Web per utilizzare la sua mappa del sito per concludere alcuni importanti approfondimenti SEO.
Estrazione e creazione di frame di dati da Sitemap con Adverttools
In Advertools puoi scoprire, sfogliare e combinare tutte le mappe dei siti di un sito Web con una sola riga di codice.
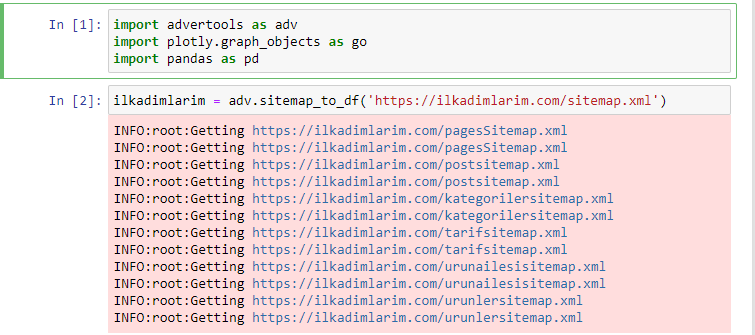
Adoro usare Jupyter Notebook invece di un normale editor di codice o IDE.
Nella prima cella abbiamo importato Panda e Advertools per la raccolta e l'organizzazione dei dati e Plotly.graph_objects per la visualizzazione dei dati.
Il comando adv.sitemap_to_df('sitemap address') raccoglie semplicemente tutte le mappe dei siti e le unifica come un DataFrame.
Se fai lo stesso usando Pandas e Advertools, puoi scoprire quale URL è disponibile in quale mappa del sito.
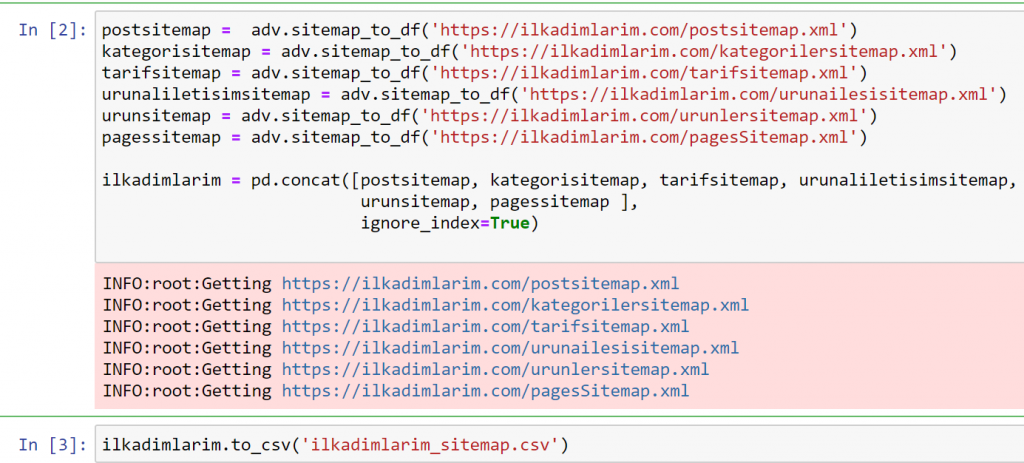
Nell'esempio sopra, abbiamo estratto le stesse mappe del sito separatamente, quindi le abbiamo combinate con il comando pd.concat e trasferito il risultato in CSV. L'esempio precedente utilizzava il file di indice della mappa del sito, nel qual caso la funzione va a recuperare tutte le altre mappe del sito. Quindi hai la possibilità di selezionare mappe del sito specifiche come abbiamo fatto qui se sei interessato a una particolare sezione del sito web.
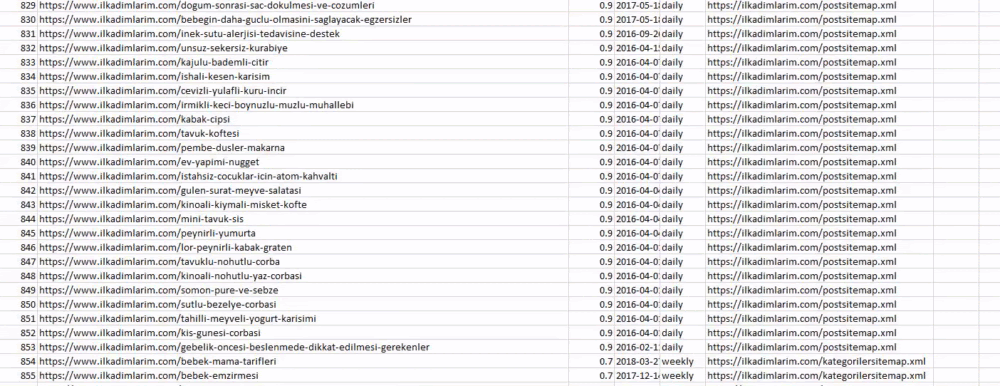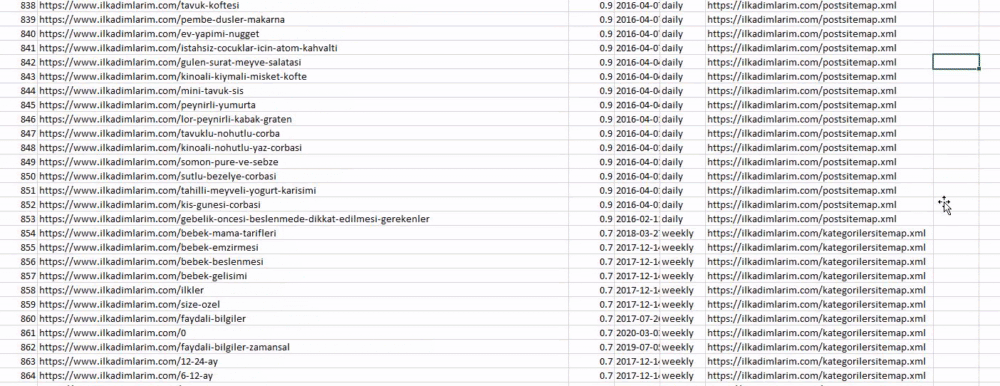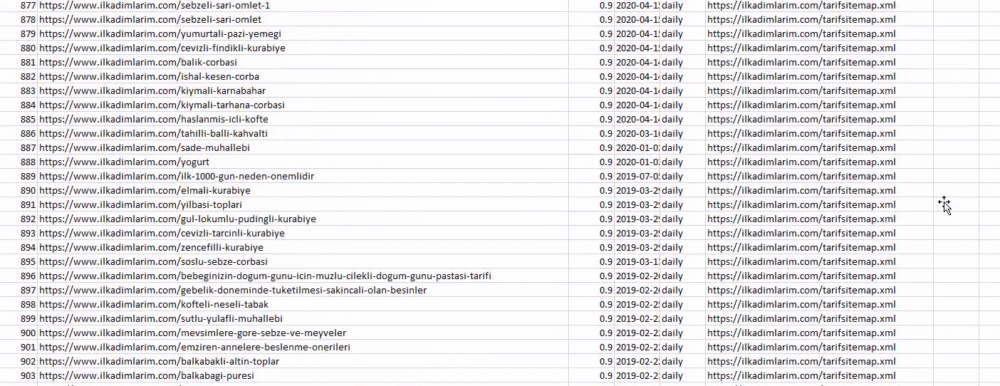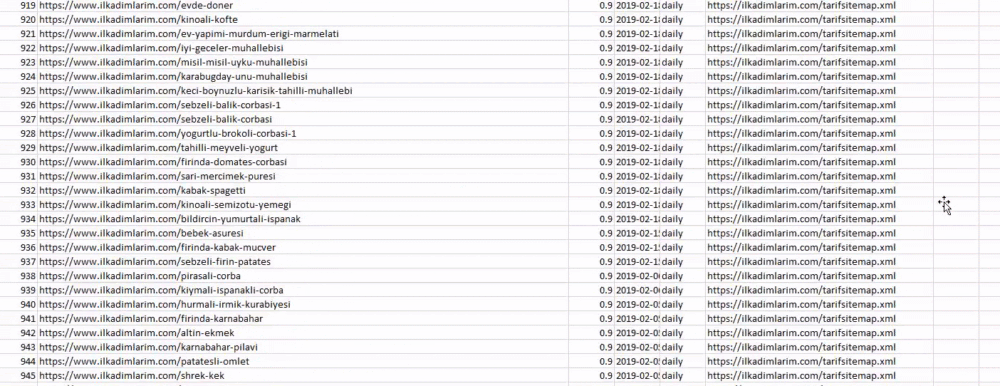
Puoi vedere una colonna con nomi di mappe del sito diversi sopra. ignore_index=La sezione True serve per l'ordine ordinato dei numeri di indice di DataFrame diversi, se ne hai uniti più di uno insieme.
Scansione dati³
 Per saperne di più
Per saperne di piùPulizia e preparazione del frame di dati della mappa del sito per l'analisi dei contenuti con Python
Per comprendere il profilo di contenuto di un sito web attraverso una mappa del sito, dobbiamo prepararlo in modo da rivedere il DataFrame che abbiamo ottenuto con Advertools.
Useremo alcuni comandi di base della libreria Pandas per modellare i nostri dati:
Ilkadimlarim = pd.read_csv('ilkadimlarim_sitemap.csv')
ilkadimlarim = ilkadimlarim.drop(columns = 'Senza nome: 0')
ilkadimlarim['lastmod'] = pd.to_datetime(ilkadimlarim['lastmod'])
ilkadimlarim = ilkadimlarim.set_index('lastmod')
"Ilkadimlarim" significa "i miei primi passi" in turco e, come puoi immaginare, è un sito per bambini, gravidanza e maternità.
Abbiamo eseguito tre operazioni con queste linee.
- Senza nome: Abbiamo rimosso una colonna vuota denominata 0 dal DataFrame. Inoltre, se usi 'index = False “ con la funzione pd.to_csv() , non vedrai questa colonna 'Unnamed 0' all'inizio.
- Abbiamo convertito i dati nella colonna Ultima modifica in Date Time.
- Abbiamo portato la colonna "lastmod" nella posizione dell'indice.
Di seguito puoi vedere la versione finale di DataFrame.
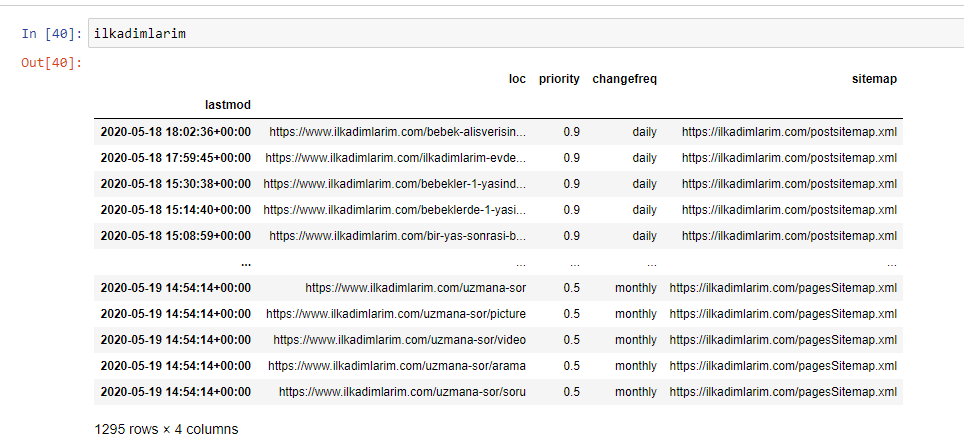
Sappiamo che Google non utilizza le informazioni sulla priorità e sulla frequenza delle mappe dei siti. Lo chiamano "un sacco di rumore". Ma se dai importanza alle prestazioni del tuo sito web per altri motori di ricerca, potresti trovare utile esaminarli anche tu. Personalmente, non mi interessa molto di questi dati, ma non ho ancora bisogno di rimuoverli dal DataFrame.
Abbiamo bisogno di un'altra riga di codice per classificare le mappe dei siti in un'altra colonna.
ilkadimlarim['sitemap_cat'] = ilkadimlarim['sitemap'].str.split('/').str[3]
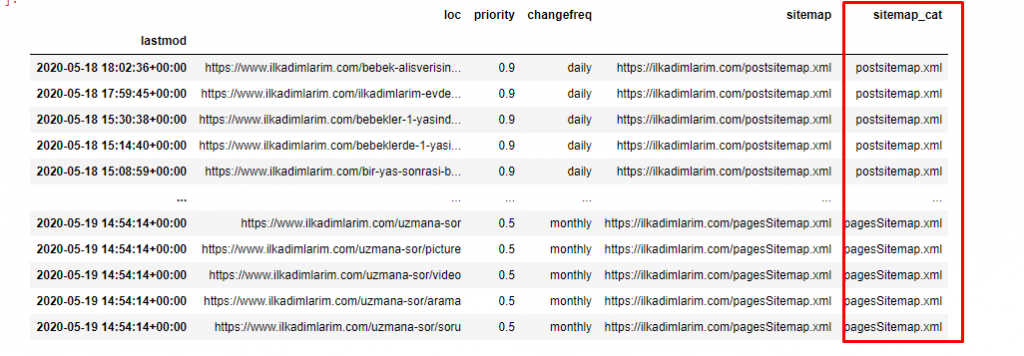
In Pandas, puoi aggiungere nuove colonne o righe a un DataFrame o aggiornarle facilmente. Abbiamo creato una nuova colonna con lo snippet di codice DataFrame['new_columns'] . DataFrame['column_name'].str ci consente di eseguire diverse operazioni modificando il tipo di dati in una colonna. Dividiamo i dati della stringa nella colonna relativa a .split ('/') per il carattere / e li mettiamo in una lista. Con .str [number] , creiamo il contenuto della nuova colonna selezionando un particolare elemento in quell'elenco.
Analisi del profilo dei contenuti in base al numero e ai tipi della mappa del sito
Dopo aver inserito le mappe del sito in una colonna diversa in base alla loro tipologia, possiamo verificare quale % dei contenuti si trova in ciascuna mappa del sito. Pertanto, possiamo anche fare un'inferenza su quale parte del sito Web è più importante.
ilkadimlarim['sitemap_cat'].value_counts(normalize = True) * 100
- DataFrame['column_name'] sta selezionando la colonna di cui vogliamo creare un processo.
- value_counts() conta la frequenza dei valori nella colonna.
- normalize=True prende il rapporto dei valori in decimale.
- Semplifichiamo la lettura aumentando i numeri decimali con *100.
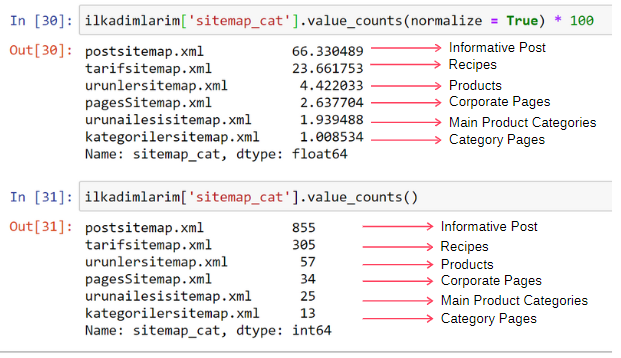
Vediamo che il 65% del contenuto è nella Sitemap Post e il 23% nella Sitemap Ricetta. La Sitemap del prodotto ha solo il 2% del contenuto.
Ciò dimostra che abbiamo un sito Web che deve creare contenuti informativi per un vasto pubblico per commercializzare i propri prodotti. Verifichiamo se la nostra tesi è corretta.
Prima di procedere, è necessario modificare il nome della colonna ilkadimlarim['sitemap_cat'] in 'URL_Count' con il codice seguente:
ilkadimlarim.rename(columns={'sitemap_cat' : 'URL_Count'}, inplace=True)
- La funzione rename() è utile per modificare il nome delle tue colonne o indici per collegare i dati e il loro significato a un livello più profondo.
- Abbiamo cambiato il nome della colonna in modo che sia permanente grazie all'attributo 'inplace=True' .
- Puoi anche modificare gli stili delle lettere delle colonne e degli indici con ilkadimlarim.rename(str.capitalize, axis='columns', inplace=True) . Questo scrive solo le prime lettere maiuscole di ogni colonna in Ilkadimlarim.

Ora possiamo procedere.
Per visualizzare queste informazioni in un unico frame, puoi utilizzare il codice seguente:
(ilkadimlarim['sitemap_cat']
.conta_valori()
.incorniciare()
.assign(percentage=lambda df: df['sitemap_cat'].div(df['sitemap_cat'].sum()))
.style.format(dict(sitemap_cat='{:,}', percent='{:.1%}')))
- to_frame() viene utilizzato per inquadrare i valori misurati da value_counts() nella colonna selezionata.
- assign() viene utilizzato per aggiungere determinati valori al frame.
- lambda si riferisce a funzioni anonime in Python.
- Qui, la funzione Lambda e i tipi di mappa del sito sono divisi per il numero totale della mappa del sito tramite il metodo Pandas div() .
- style() determina come vengono scritti i valori finali specificati.
- Qui, impostiamo quante cifre vengono scritte dopo il punto con il metodo format() .
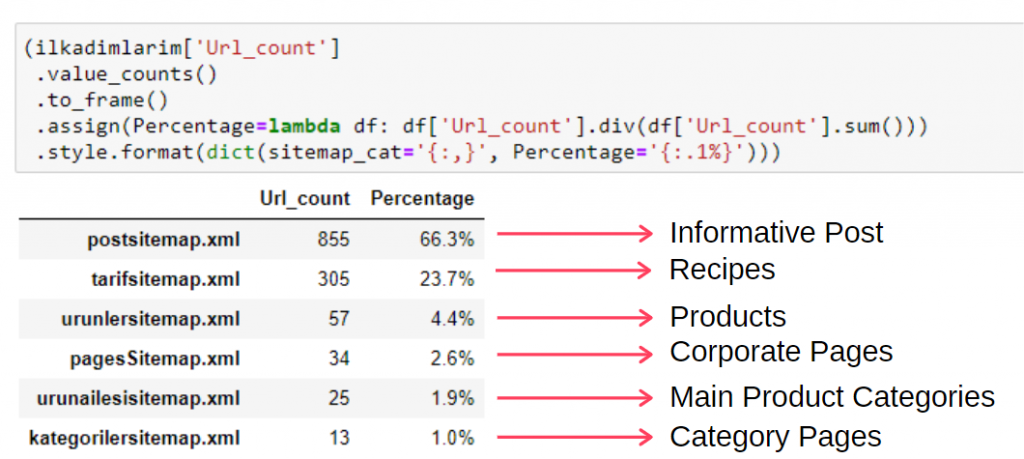
Pertanto, vediamo l'importanza del marketing dei contenuti per questo sito Web. Possiamo anche controllare le tendenze di pubblicazione degli articoli per anno con due singole righe di codice per esaminare la loro situazione in modo più approfondito.
Esaminare e visualizzare le tendenze di pubblicazione dei contenuti per anno tramite Sitemap e Python
Abbiamo eseguito la corrispondenza dei contenuti e degli intenti del sito Web esaminato in base alle categorie della mappa del sito, ma non abbiamo ancora effettuato una classificazione basata sul tempo. Useremo il metodo resample() per ottenere questo risultato.
post_per_mese = ilkadimlarim.resample('A')['loc'].count()
post_per_mese.to_frame()
Resample è un metodo nella libreria Pandas. resample('A') controlla la serie di dati per un DataFrame annuale. Per settimane puoi usare 'W', per mesi puoi usare 'M'.
Loc qui simboleggia l'indice; count significa che vuoi contare la somma degli esempi di dati.
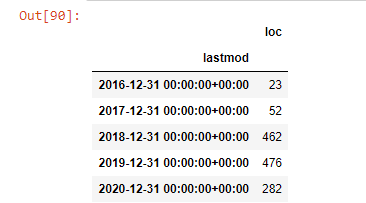
Vediamo che hanno iniziato a pubblicare articoli nel 2016, ma la loro principale tendenza alla pubblicazione è aumentata dopo il 2017. Possiamo anche inserire questo in un grafico con l'aiuto di Plotly Graph Objects.
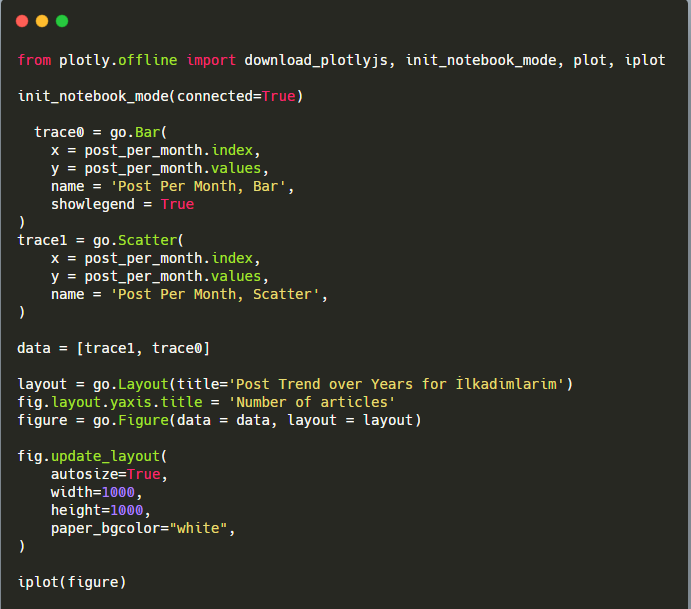
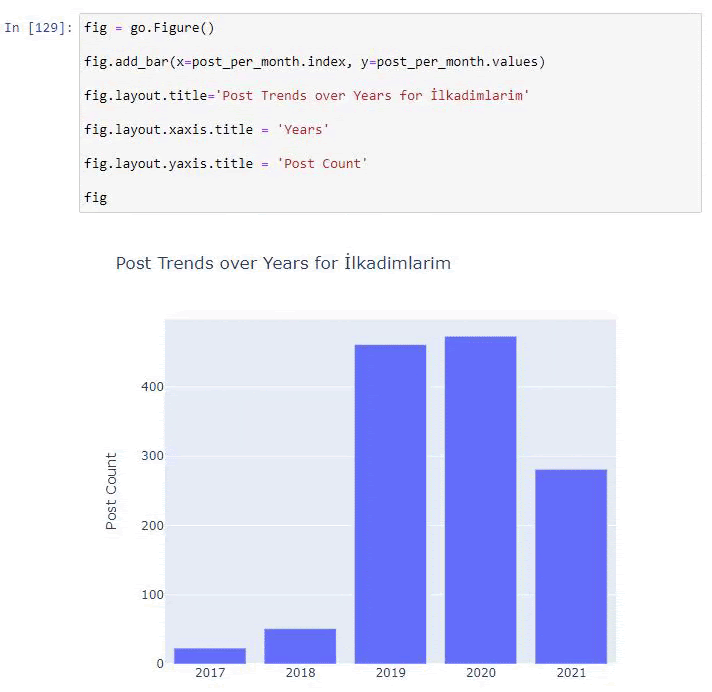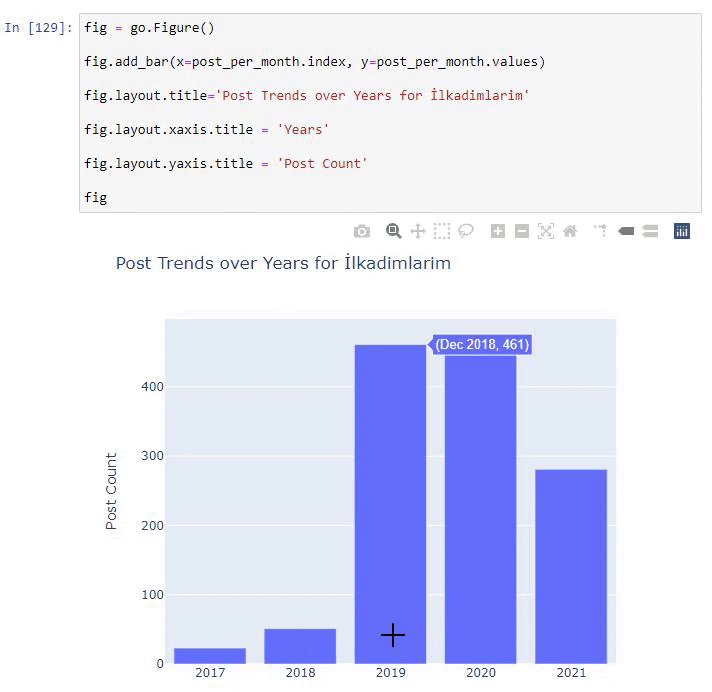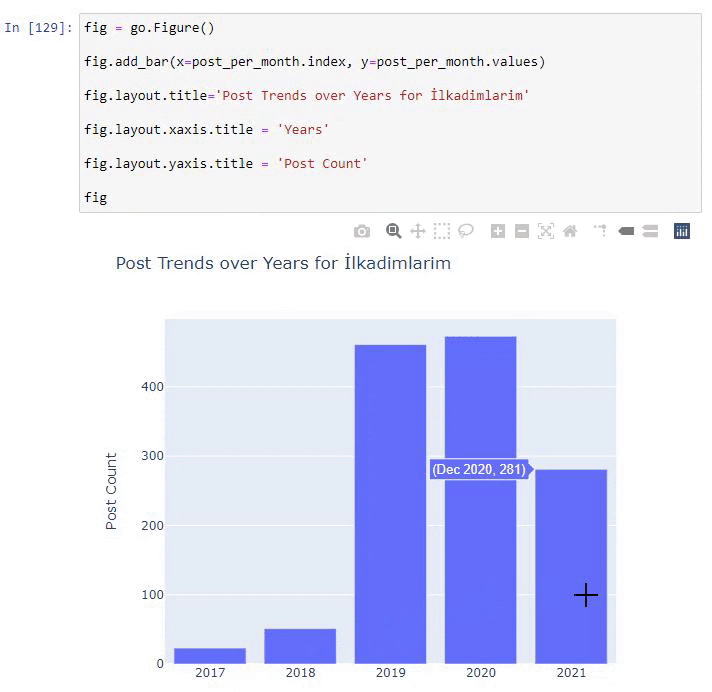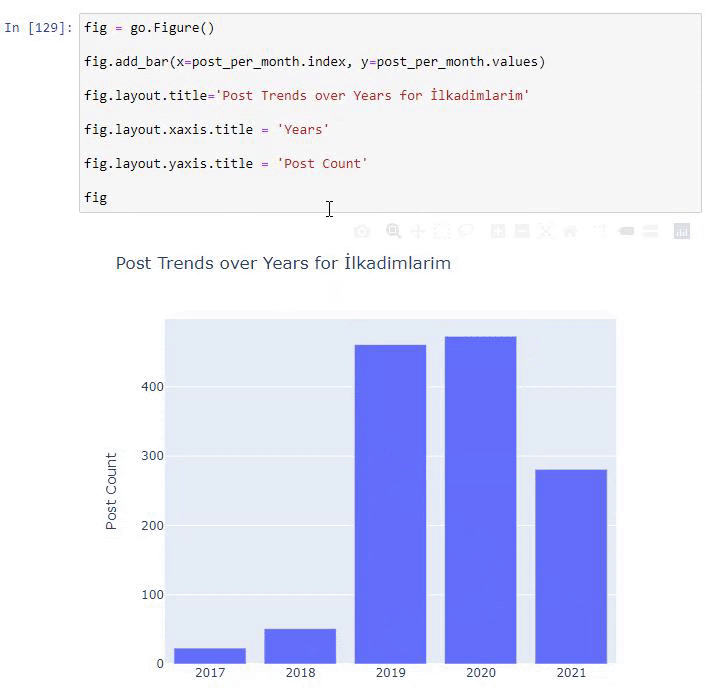
Spiegazione di questo frammento di codice Plotly Bar Plot:
- fig = go.Figure() serve per creare una figura.
- fig.add_bar() serve per aggiungere un grafico a barre nella figura. Determiniamo anche quali assi X e Y saranno tra parentesi.
- Fig.layout serve per creare un titolo generale per la figura e gli assi.
- All'ultima riga chiamiamo la trama che abbiamo creato con il comando fig che è uguale a go.Figure()
Di seguito, troverai gli stessi dati per mese, con grafico a dispersione e grafico a barre:
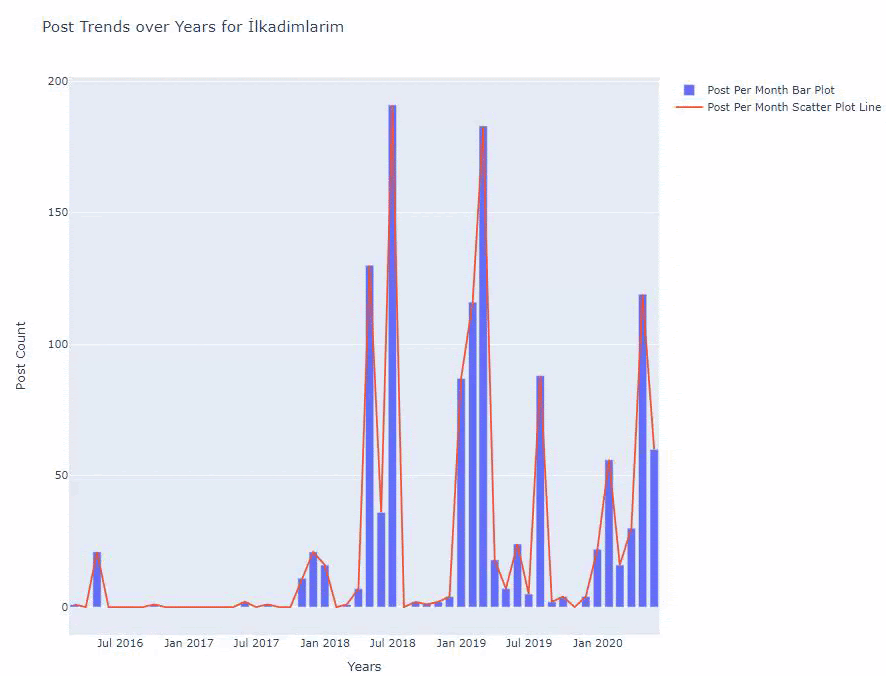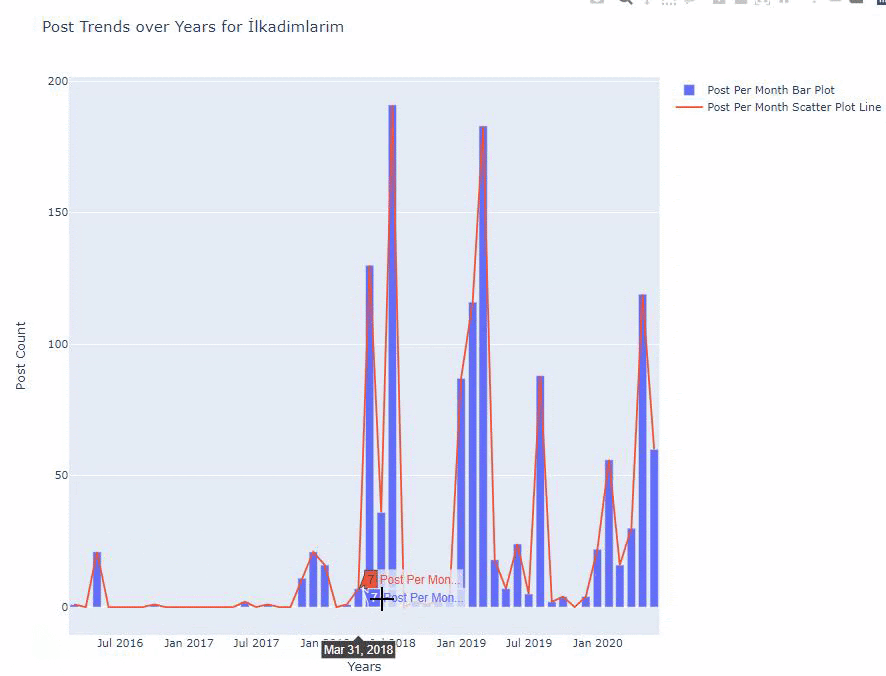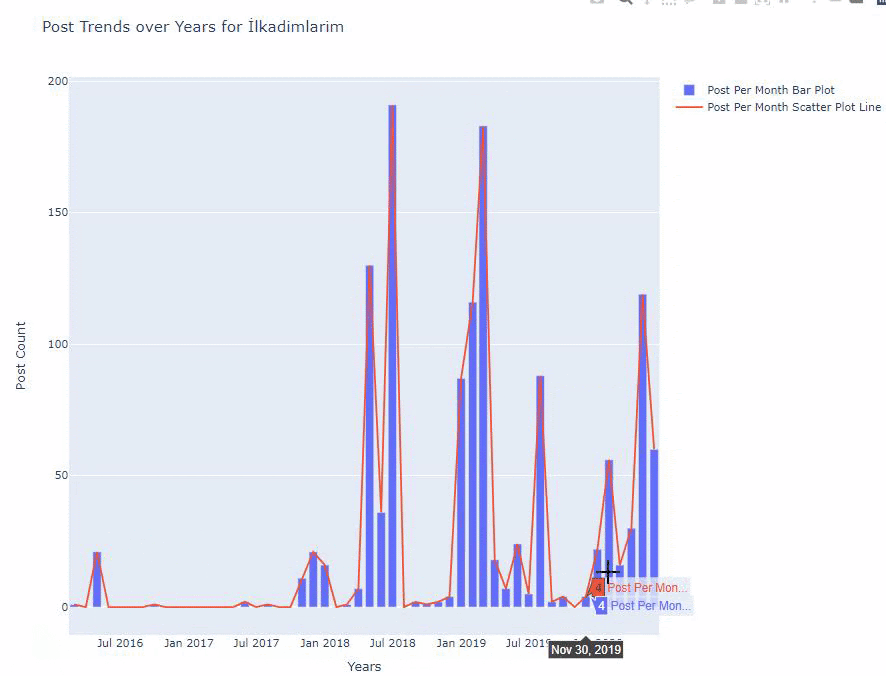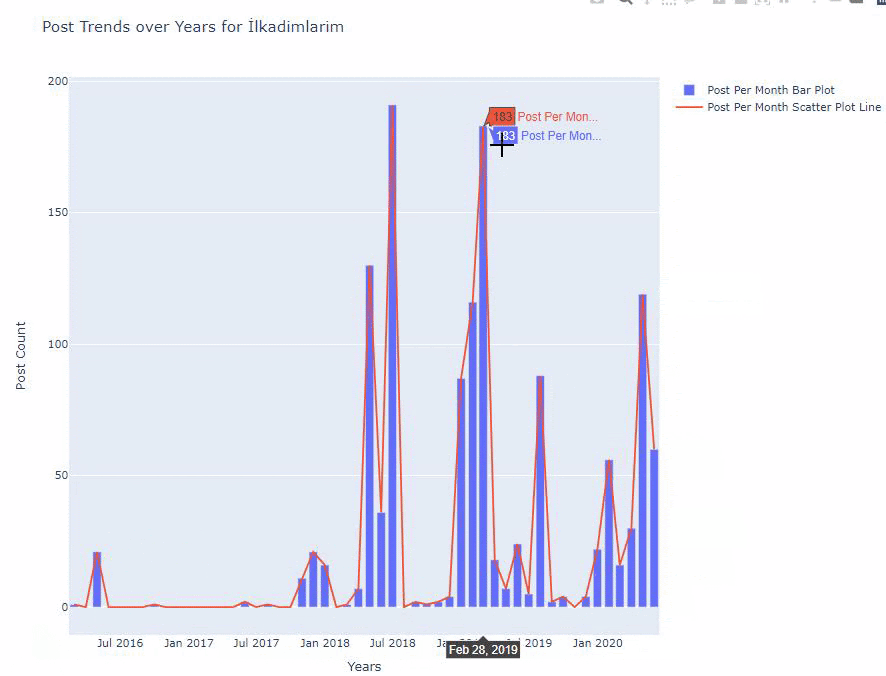
Ecco i codici per creare questa figura:
Abbiamo aggiunto una seconda trama con fig.add_scatter() , e abbiamo anche cambiato i nomi usando l'attributo name. fig.update_layout() serve per modificare le dimensioni e il colore di sfondo del grafico.
Puoi anche modificare la modalità al passaggio del mouse, la distanza tra le barre e altro. Penso che sia sufficiente condividere solo i codici, poiché spiegare ogni codice qui separatamente potrebbe farci allontanare dall'argomento principale.
Possiamo anche confrontare le tendenze di pubblicazione dei contenuti della concorrenza in base a categorie come di seguito:
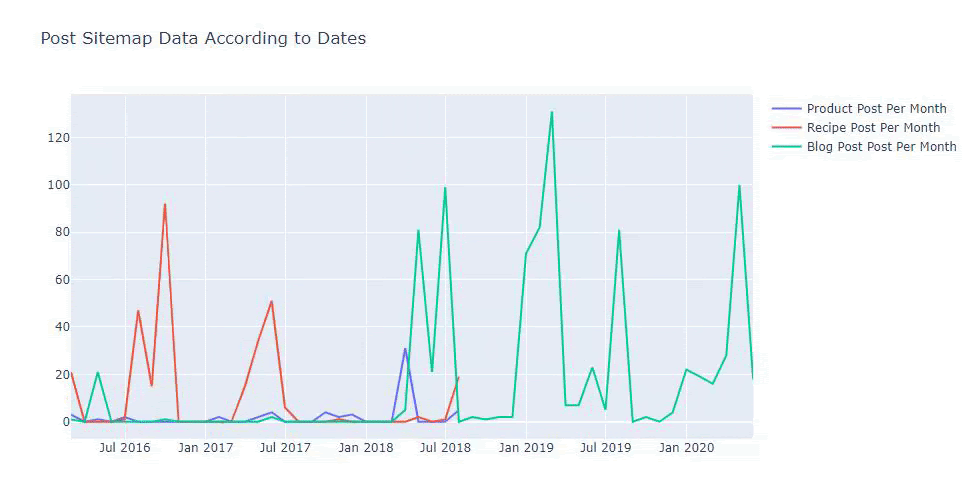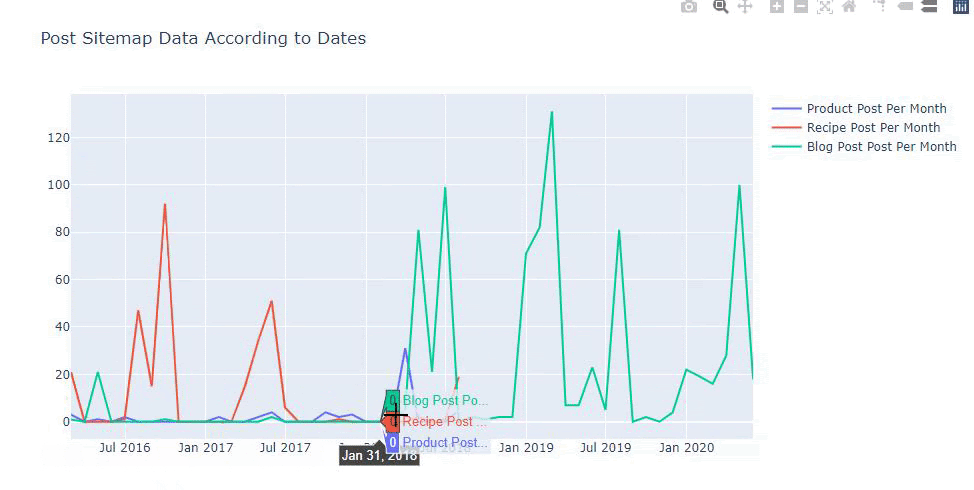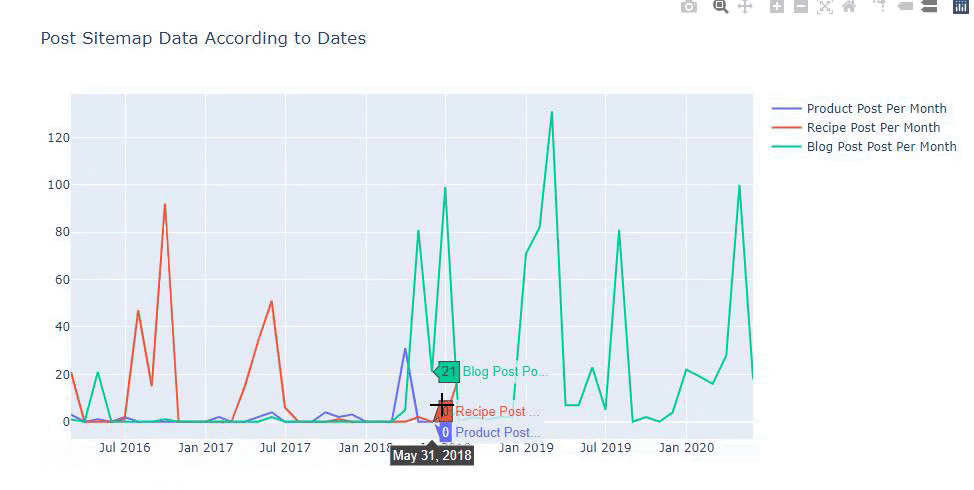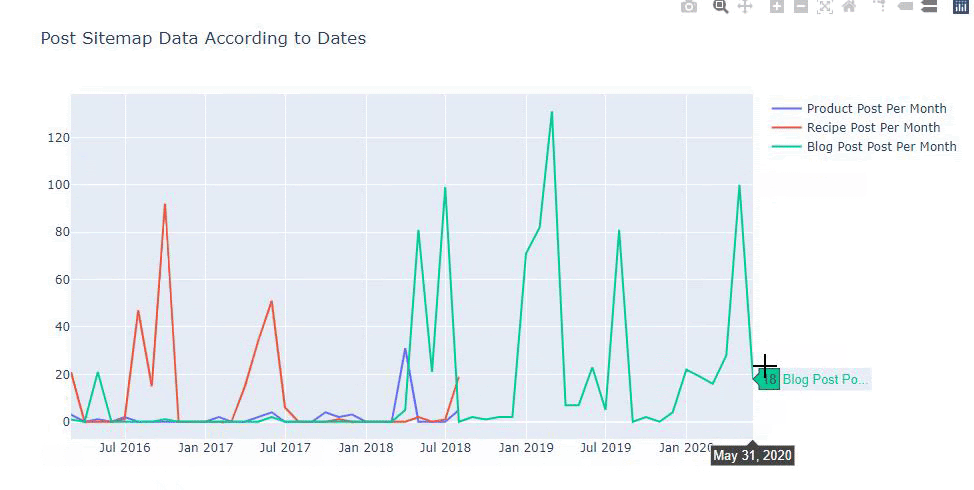
Questo grafico è stato creato con il secondo metodo, come puoi vedere non c'è alcuna differenza ma uno di questi è abbastanza semplice.
Per tracciare la frequenza e l'andamento della pubblicazione di contenuti da tre mappe del sito separate, dobbiamo posizionare la mappa del sito, che ha l'intervallo più lungo, sull'asse X. Pertanto, possiamo confrontare la frequenza con cui il sito Web che stiamo esaminando pubblica ogni diverso tipo di contenuto per diversi intenti di ricerca.
Quando esamini i codici pertinenti di seguito, vedrai che non è molto diverso da quanto sopra.
Per creare un grafico a dispersione con più assi Y, puoi utilizzare il codice seguente.
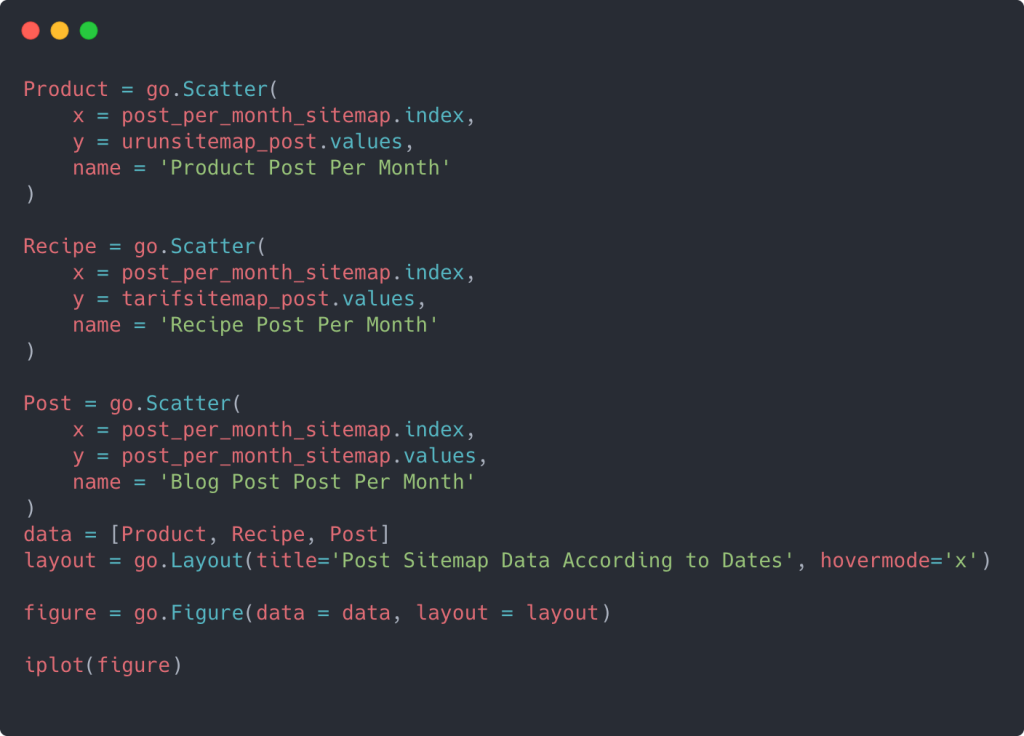
Esistono altri metodi come unificare diverse mappe del sito e utilizzare un ciclo for per le colonne per utilizzare più assi Y nel grafico a dispersione, ma per un sito così piccolo non ne abbiamo bisogno. Per la maggior parte, sarebbe più logico utilizzare questo metodo su siti Web con centinaia di mappe del sito.
Inoltre, poiché il sito Web è piccolo, la grafica potrebbe sembrare superficiale, ma come vedrai più avanti nell'articolo su un sito Web con milioni di URL, tale grafica è un ottimo modo per confrontare siti diversi e per confrontare diverse categorie di stesso sito web.
Esaminare e visualizzare categorie di contenuti, intenzioni e tendenze editoriali con Sitemap e Python
In questa sezione, verificheremo che abbiano scritto un gran numero di contenuti in un dominio di conoscenza specifico per commercializzare un numero limitato di prodotti, come abbiamo detto all'inizio dell'articolo. Grazie a questo, potremmo vedere se hanno una partnership di contenuto con altri marchi o meno.
Per mostrare cos'altro si può trovare sulle mappe del sito, continueremo a scavare un po' di più. Possiamo anche ottenere alcune informazioni dalla parte "loc" della mappa del sito come altre.
Non vi è alcuna suddivisione per categoria negli URL di Ilkadimlarim. Se un sito Web ha una suddivisione per categoria nei suoi URL, possiamo imparare molto di più sulla distribuzione dei contenuti. In caso contrario, possiamo accedere agli stessi dati scrivendo codice aggiuntivo, ma solo con minore certezza.
A questo punto, puoi immaginare quanto meno costose rendano le scomposizioni degli URL per i motori di ricerca che eseguono la scansione di miliardi di siti per capire il tuo sito web.
a = ilkadimlarim['loc'].str.contains(“bebek|hamile|haftalik”)
Bebek: piccola
Emilia: incinta
Haftalik: settimanale o “incinta di settimane”
baby_post_count = ilkadimlarim[a].resample('M')['loc'].count()
baby_post_count.to_frame()
Il metodo str() anche qui ci consente di impostare la colonna in cui selezioniamo determinate operazioni.
Con il metodo contiene() , determiniamo i dati per verificare se sono inclusi nei dati convertiti in una stringa.
Qui, “|” tra i termini significa “o” .
Quindi assegniamo i dati che abbiamo filtrato a una variabile e utilizziamo il metodo resample() utilizzato in precedenza.
metodo di conteggio , d'altra parte, misura quali dati vengono utilizzati e quante volte.
Il risultato ottenuto con count() è nuovamente racchiuso tra to_frame() .
Inoltre, str.contains() accetta i valori Regex per impostazione predefinita, il che significa che puoi creare condizioni di filtro più complicate con meno codice.
In altre parole, a questo punto assegniamo gli URL contenenti le parole “bambino”, “settimanale”, “incinta” ad una variabile in ilkadimlarim , quindi mettiamo la data di pubblicazione degli URL nelle condizioni appropriate per questo filtro che creato in una cornice.
Quindi facciamo lo stesso per gli URL contenenti la parola 'aptamil'. Aptamil è il nome di un prodotto per l'alimentazione del bambino introdotto da Ilkadimlarim. Pertanto, possiamo prestare attenzione anche alla densità di trasmissione di contenuti informativi e commerciali.
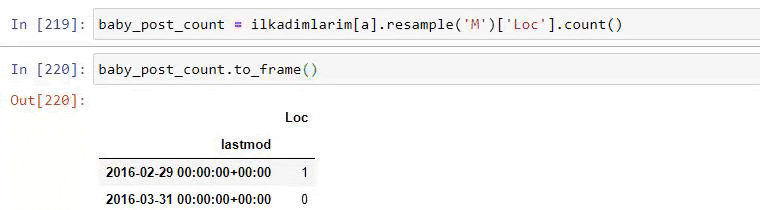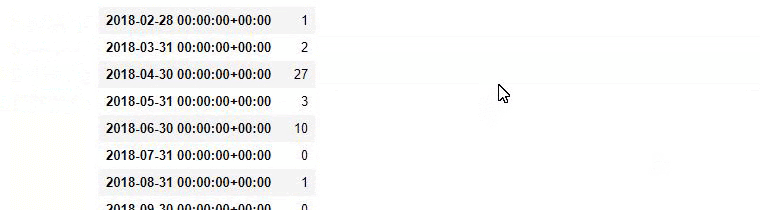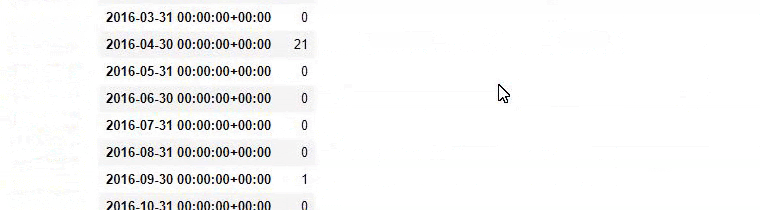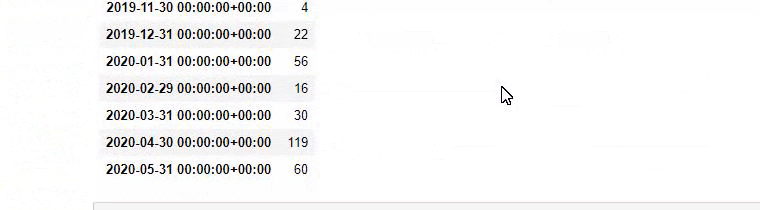
E potresti vedere i due diversi gruppi di contenuti che pubblicano pianificazioni nel corso degli anni per diversi intenti di ricerca con maggiore certezza e informazioni precise dagli URL.
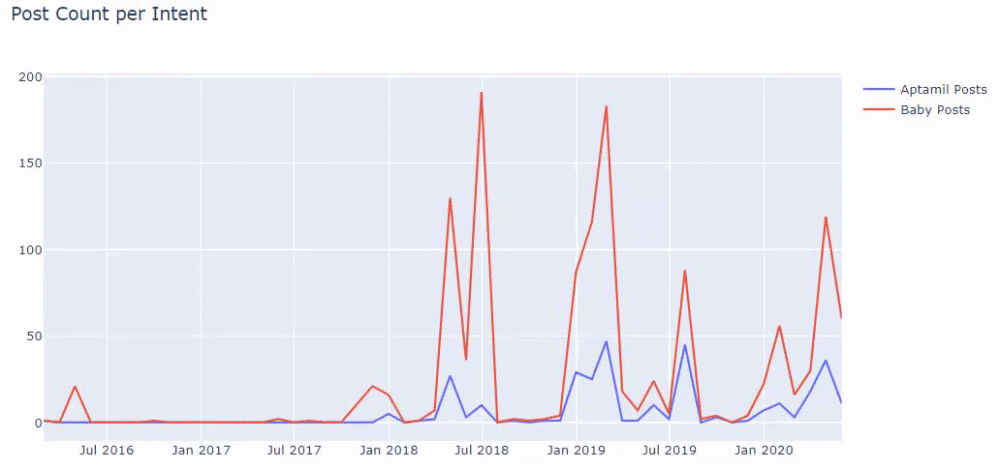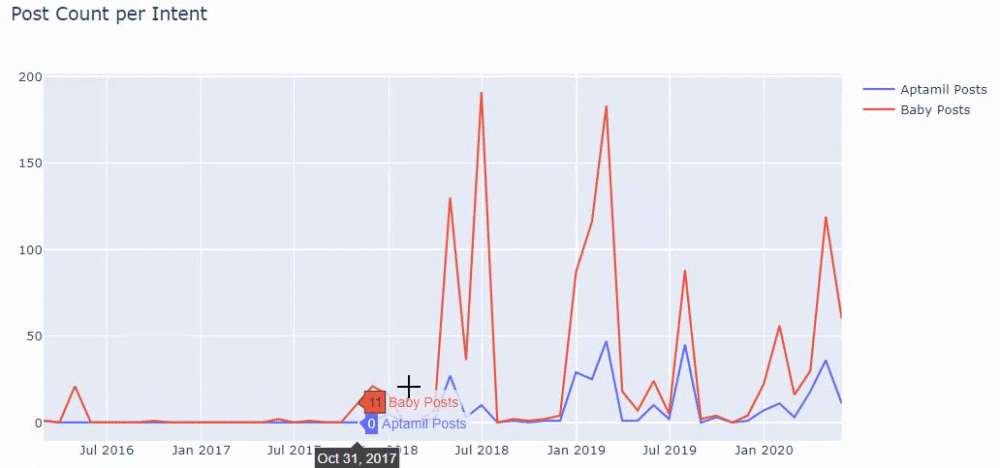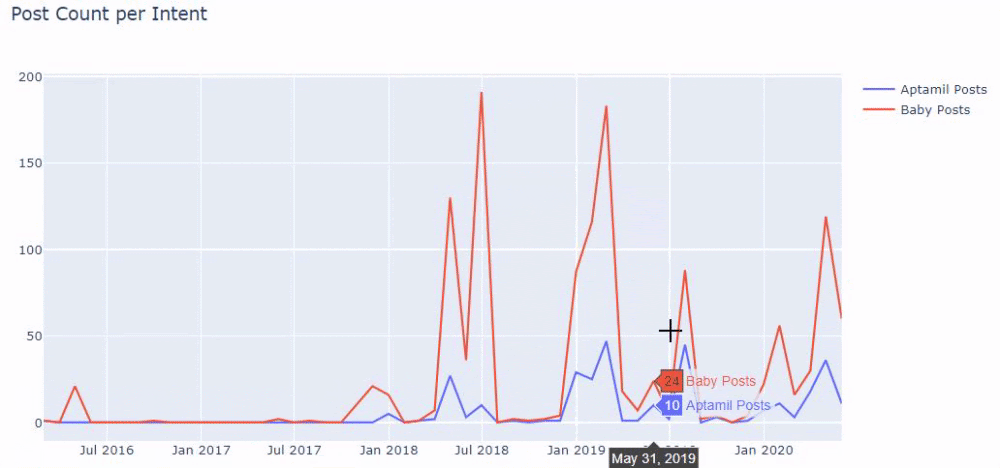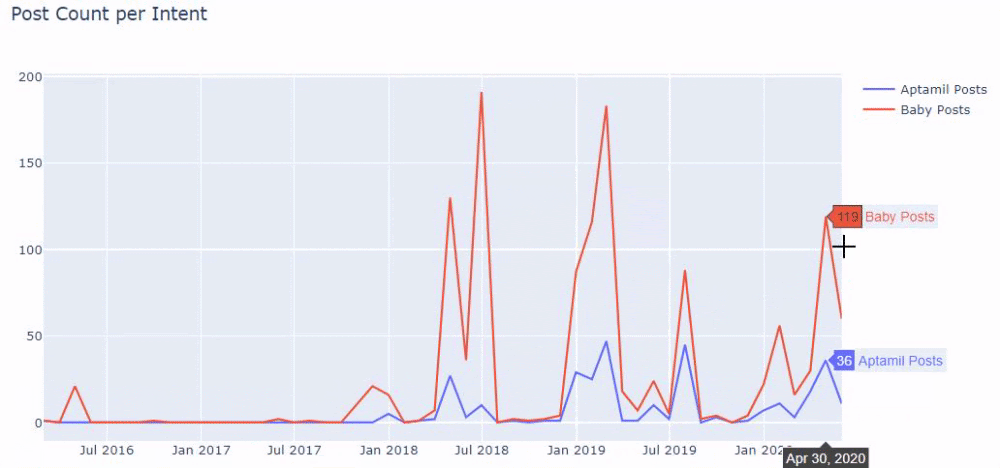
Il codice per produrre questo grafico non è stato condiviso in quanto è lo stesso utilizzato per il grafico precedente
Con l'aiuto degli operatori di ricerca su Google, ottengo 38 risultati quando voglio le pagine in cui la parola Aptamil è usata nell'anchor text su Ilkadimlarim.com. Un numero importante di queste pagine sono informative e collegano contenuti commerciali.
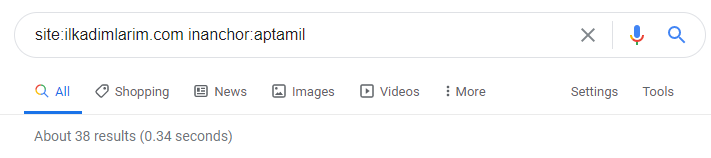
La nostra tesi è stata dimostrata.
"I miei primi passi" utilizza centinaia di contenuti informativi sulla maternità, la cura del bambino e la gravidanza per raggiungere il suo pubblico di destinazione. "Ilkadimlarim" collega le pagine contenenti i prodotti Aptamil da questo contenuto e indirizza gli utenti lì.
Profilazione comparativa dei contenuti e analisi della strategia dei contenuti tramite Sitemap con Python
Ora, se vuoi, facciamo lo stesso per un'azienda dello stesso settore e facciamo un confronto per capire l'aspetto generale di questo settore e le differenze strategiche tra questi due marchi.

Come secondo esempio, ho scelto Prima.com.tr, che è Pampers, ma usa il marchio Prima in Turchia. Poiché Prima ha un'unica mappa del sito, non saremo in grado di classificare in base alle mappe del sito, ma almeno hanno interruzioni diverse nei loro URL. Quindi siamo molto fortunati: dovremo scrivere meno codice.
Immagina quanto sono più costosi gli algoritmi che Google deve eseguire per te quando crei un sito difficile da capire! Questo può aiutare a rendere il calcolo dei costi di scansione più tangibile nella tua mente, anche solo per quanto riguarda la struttura dell'URL.
Per non aumentare ulteriormente il volume dell'articolo, non posizioniamo i codici delle lavorazioni che sono simili a quelli che abbiamo già fatto.
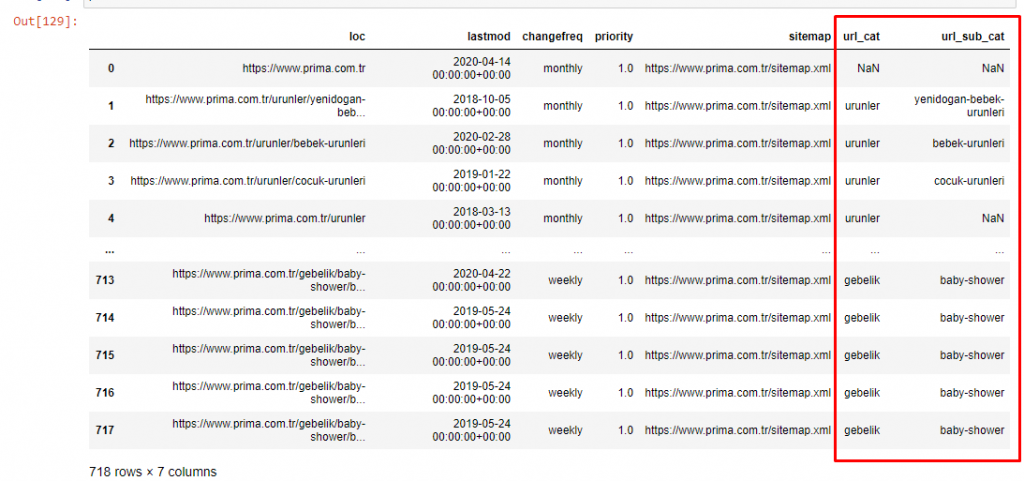
Ora possiamo esaminare la distribuzione delle loro categorie di contenuti per categorie di URL e sottocategorie di URL. Vediamo che hanno una quantità eccessiva di pagine web aziendali. Queste pagine web aziendali si trovano nella sezione "prima-hakkinda" ("Informazioni su Prima"). Ma quando li controllo con Python, vedo che hanno unificato i loro prodotti e le pagine Web aziendali in un'unica categoria. Puoi vedere la loro distribuzione dei contenuti di seguito:

Possiamo fare lo stesso per le seguenti sottocategorie.
È interessante notare che Prima usa “gebelik” (gravidanza in turco) che è una variante di “hamilelik” (gravidanza in arabo), ed entrambi significano periodo di gravidanza.

Ora vediamo una categorizzazione più profonda sul loro contenuto. Il 9,2% del contenuto riguarda una gravidanza sana, il 7,3% riguarda il processo di crescita dei bambini, l'8,3% riguarda le attività che possono essere svolte con i bambini, lo 0,7% riguarda l'ordine di sonno dei bambini. Ci sono anche argomenti come la dentizione con il 3,9%, la sicurezza del bambino con l'1,9% e la rivelazione di una gravidanza alla famiglia con l'1,4%. Come puoi vedere, puoi conoscere un settore solo con gli URL e la loro percentuale di distribuzione.
Questa non è la categorizzazione perfetta, ma almeno possiamo vedere la mentalità e le tendenze del marketing dei contenuti dei nostri concorrenti e il contenuto del loro sito Web in base alle categorie. Ora controlliamo la frequenza di pubblicazione dei contenuti per mese.
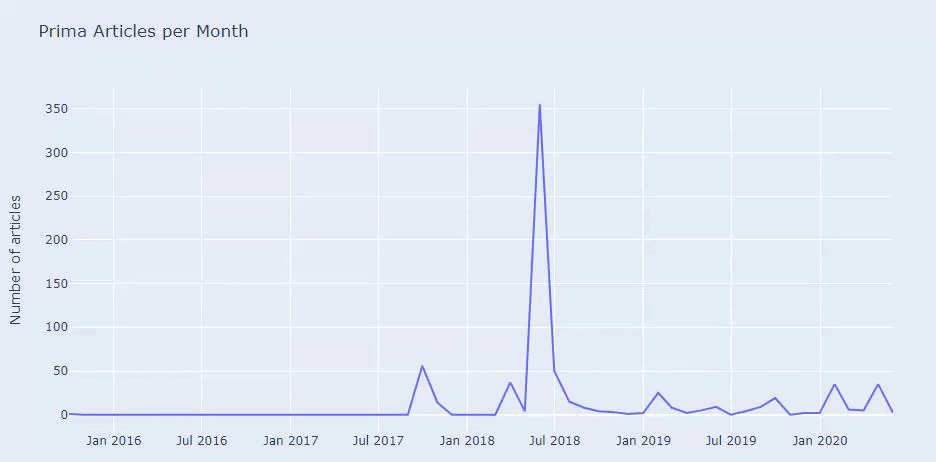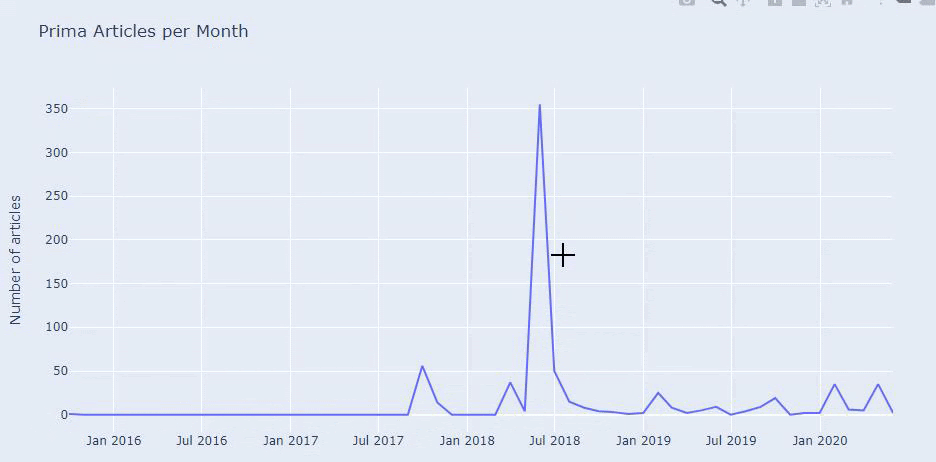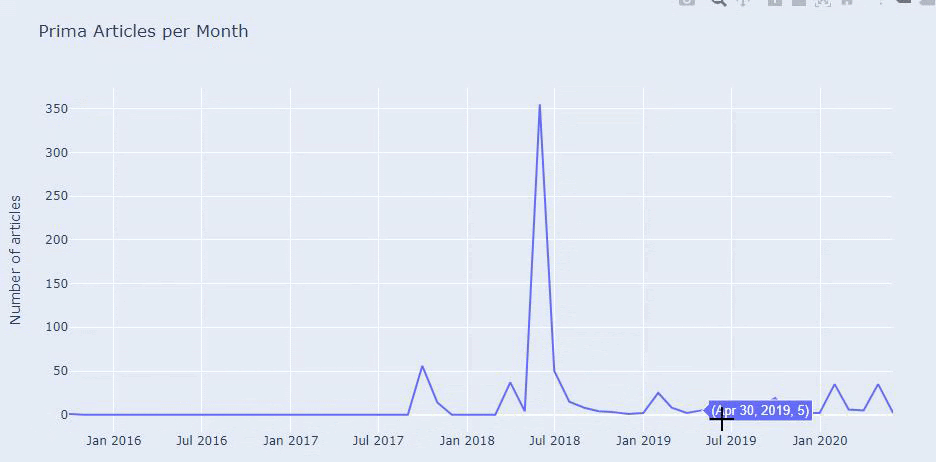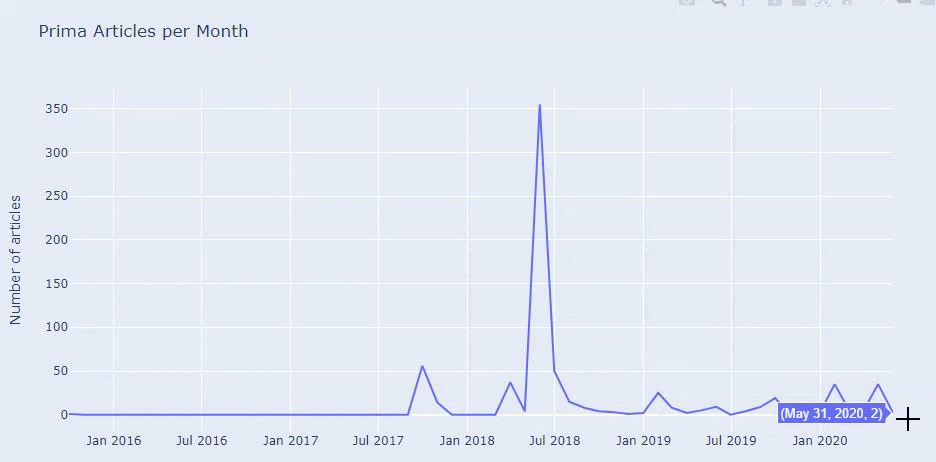
Vediamo che hanno pubblicato 355 articoli a luglio 2018 e, secondo Sitemap, i loro contenuti non sono stati aggiornati da allora. Possiamo anche confrontare le loro tendenze di pubblicazione dei contenuti in base alle categorie nel corso degli anni. Come puoi vedere, il loro contenuto si trova principalmente in quattro diverse categorie e la maggior parte di esse viene pubblicata nello stesso mese.
Prima di procedere, devo dire che i dati della mappa del sito potrebbero non essere sempre corretti. Ad esempio, i dati Lastmod potrebbero essere stati aggiornati per tutti gli URL perché hanno rinnovato tutte le Sitemap in questa data. Per aggirare questo problema, possiamo anche verificare che da allora non abbiano modificato i loro contenuti utilizzando la Wayback Machine.
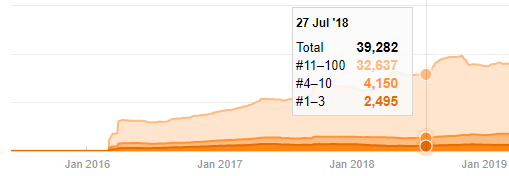
Anche se sembra sospetto, questi dati possono essere reali. Molte aziende in Turchia hanno la tendenza a dare un numero elevato di ordini e pubblicare contenuti per un momento prima. Quando controllo il conteggio delle loro parole chiave, vedo un salto in questo periodo di tempo. Quindi, se stai eseguendo un profilo di contenuto comparativo e un'analisi strategica, dovresti anche pensare a questi problemi.
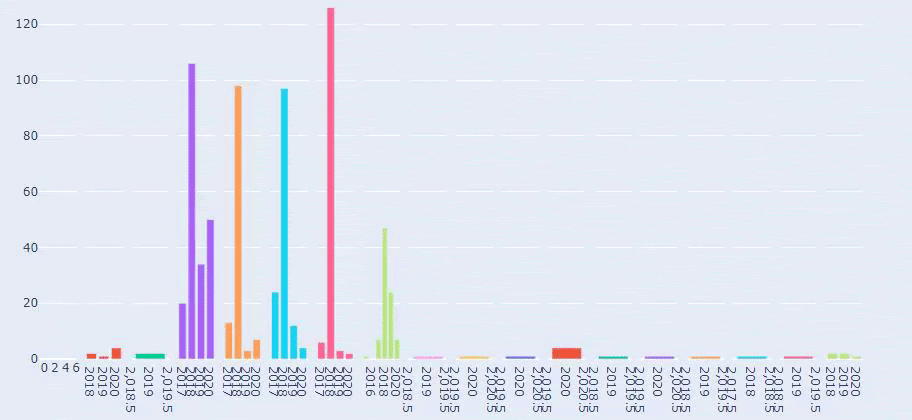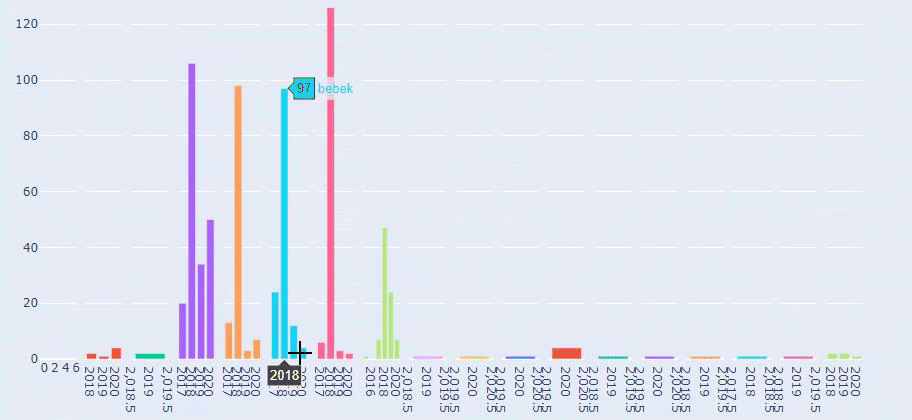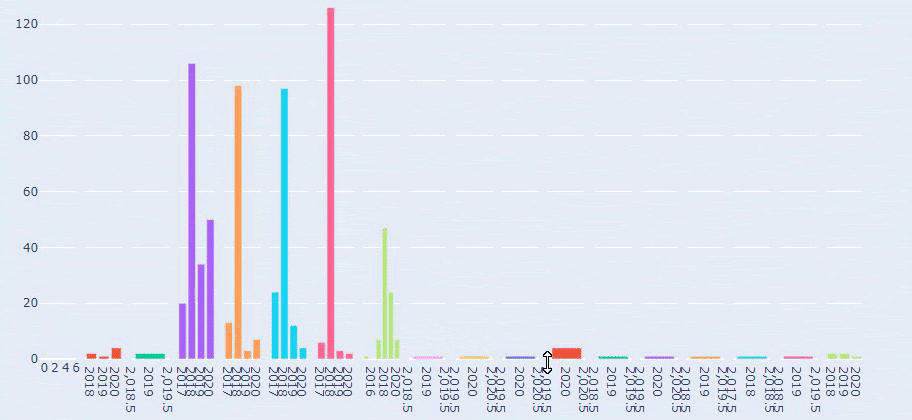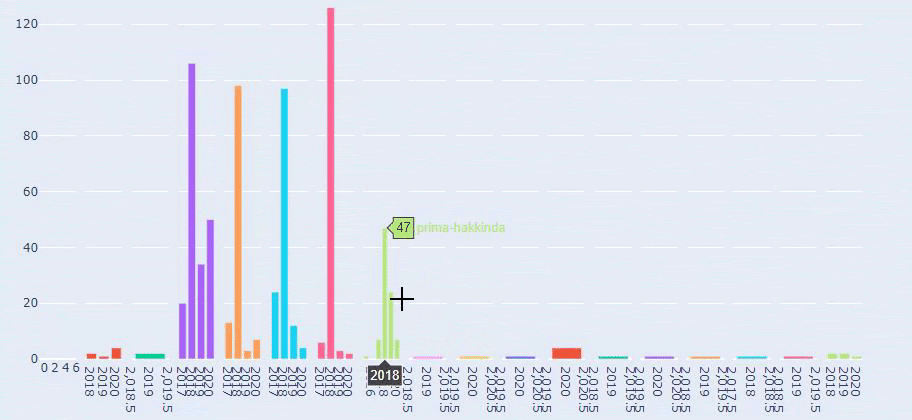
Questo è un confronto tra le tendenze di pubblicazione dei contenuti di ogni categoria negli anni per Prima.com.tr
Ora possiamo confrontare le categorie di contenuti dei due diversi siti Web e le loro tendenze di pubblicazione.
Quando osserviamo la frequenza con cui Prima pubblica articoli sulla crescita del bambino, la gravidanza e la maternità, vediamo una somiglianza con Ilkadimlarim:
- La maggior parte degli articoli sono stati pubblicati in un determinato momento.
- Non venivano aggiornati da molto tempo.
- Il numero di prodotti e pagine era molto basso rispetto al numero di pagine di contenuto informativo.
- Di recente, hanno appena aggiunto nuovi prodotti ai loro siti.
Possiamo considerare queste quattro caratteristiche come la mentalità predefinita del settore e potremmo utilizzare queste debolezze a favore della nostra campagna. Dopotutto, la qualità richiede freschezza (come affermato da Amit Singhal, Google Fellow).
A questo punto, vediamo anche che il settore non ha familiarità con il comportamento di Googlebot. Invece di caricare 250 contenuti in un giorno e quindi non apportare modifiche per un anno, è meglio aggiungere periodicamente nuovi contenuti e aggiornare regolarmente i vecchi contenuti. Pertanto, puoi mantenere la qualità dei contenuti, Googlebot può comprendere il tuo sito più facilmente e i valori della frequenza della tua domanda di scansione saranno superiori a quelli dei tuoi concorrenti.
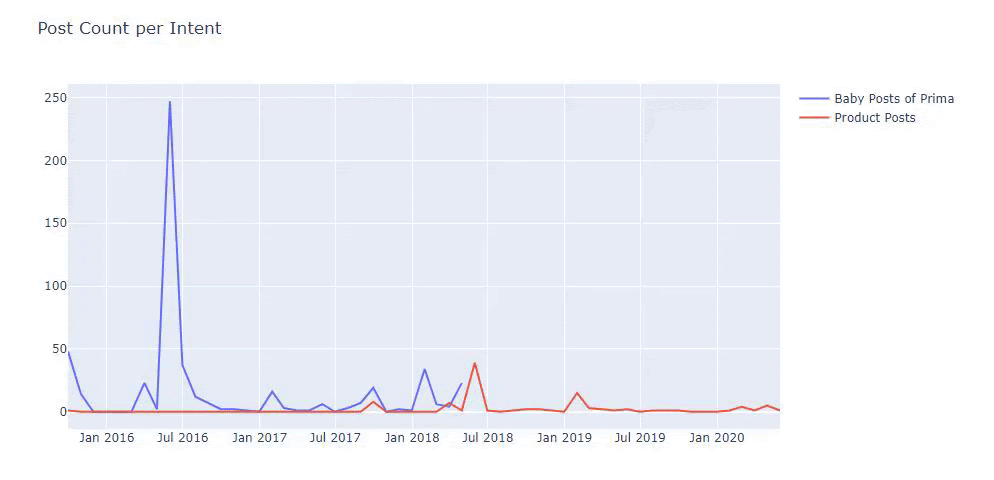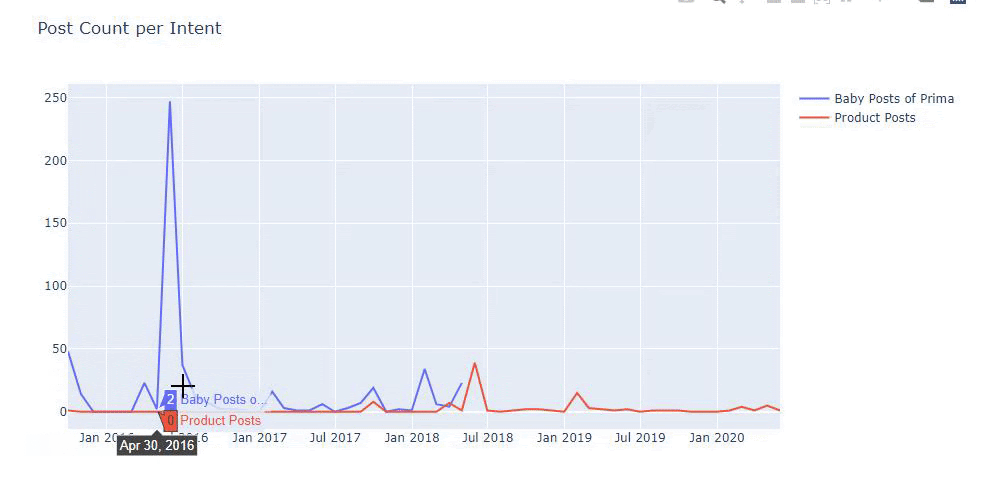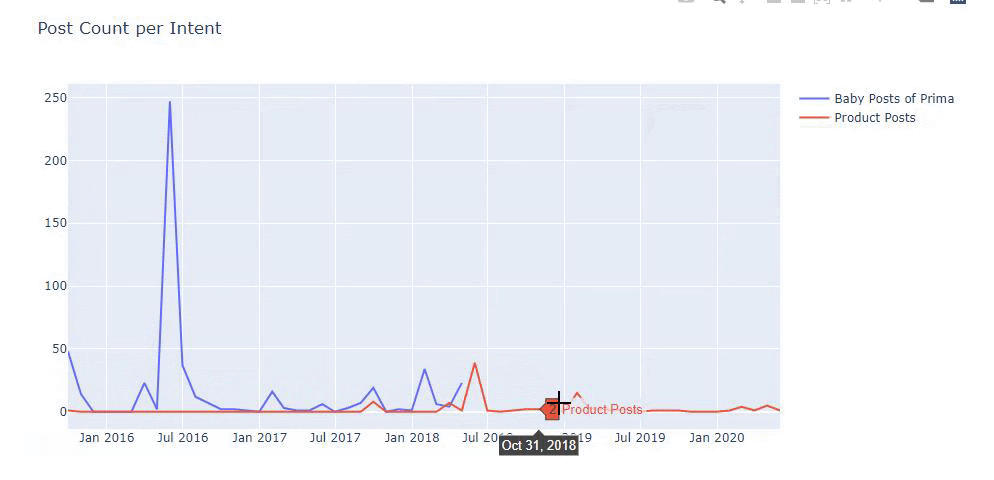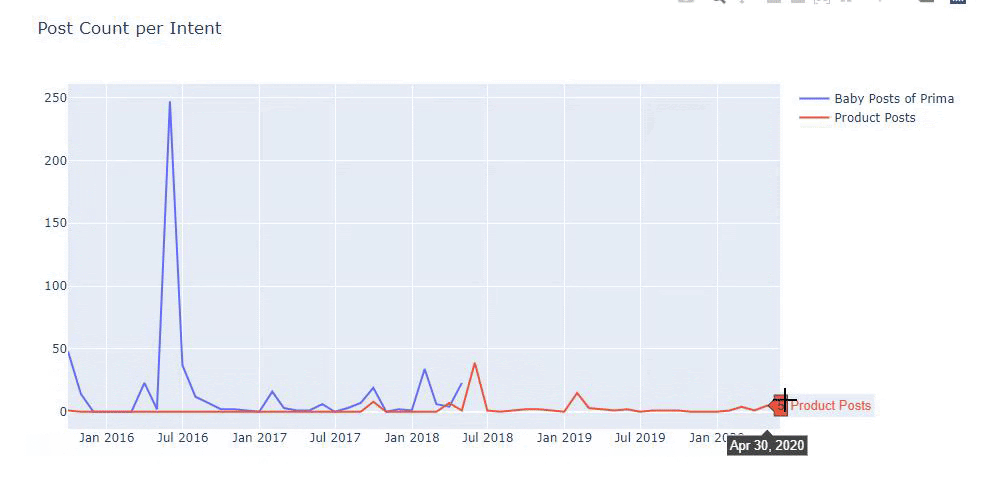
Ho utilizzato i metodi precedenti per distinguere tra pagine di prodotto e pagine di contenuto informativo e ho profilato le parole più utilizzate negli URL. Baby Posts qui significa che si tratta di contenuti informativi.
Come puoi vedere, hanno aggiunto 247 contenuti in un giorno. Inoltre, non hanno pubblicato o aggiornato contenuti informativi in oltre un anno e solo occasionalmente aggiungono nuove pagine di prodotti.
Ora confrontiamo le loro tendenze editoriali in un'unica figura ma con due trame diverse. Ho usato i codici seguenti per creare questa figura:
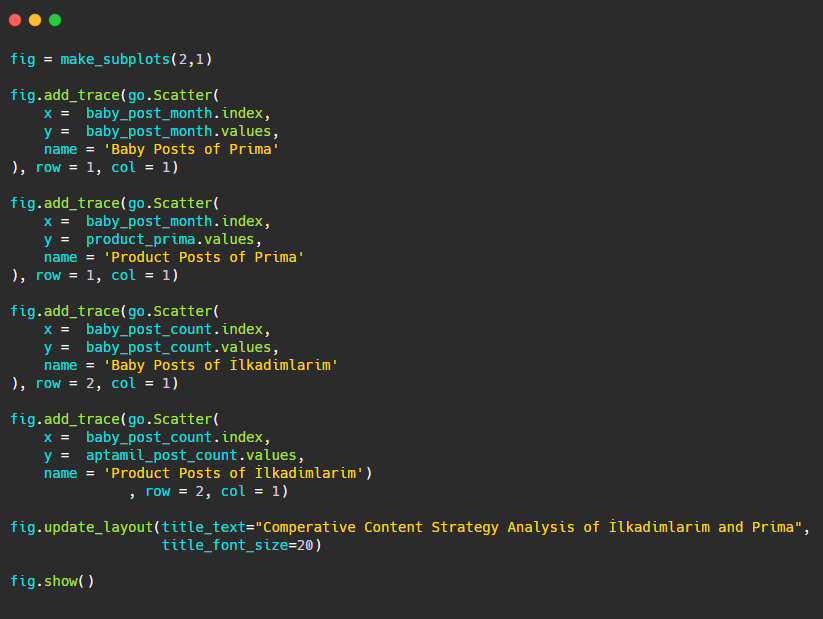
Poiché questa grafica è diversa dalle precedenti, volevo mostrarvi il codice. Qui, due lotti separati sono collocati nella stessa figura. Per questo, il metodo make_subplots è stato chiamato con il comando da plotly.subplots import make_subplots.
È stato creato come una figura a due righe e una colonna con make_subplots (2,1) .
Pertanto, col e row vengono scritti alla fine delle tracce e vengono specificate le loro posizioni. È un sistema che chiunque abbia familiarità con il sistema a griglia in CSS può facilmente riconoscere.
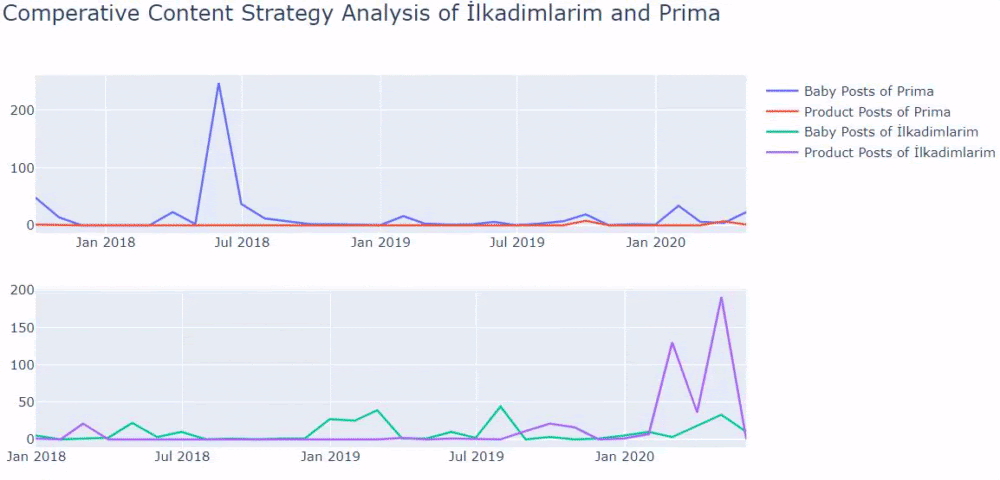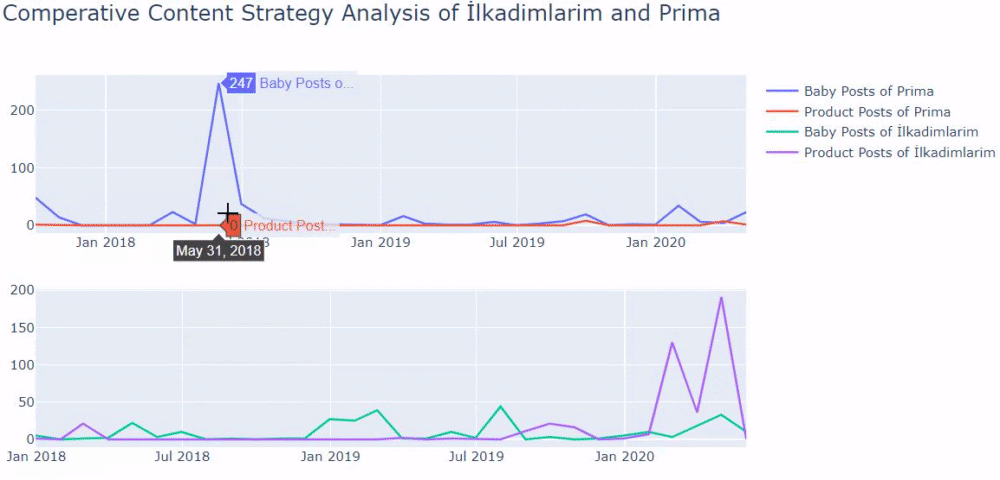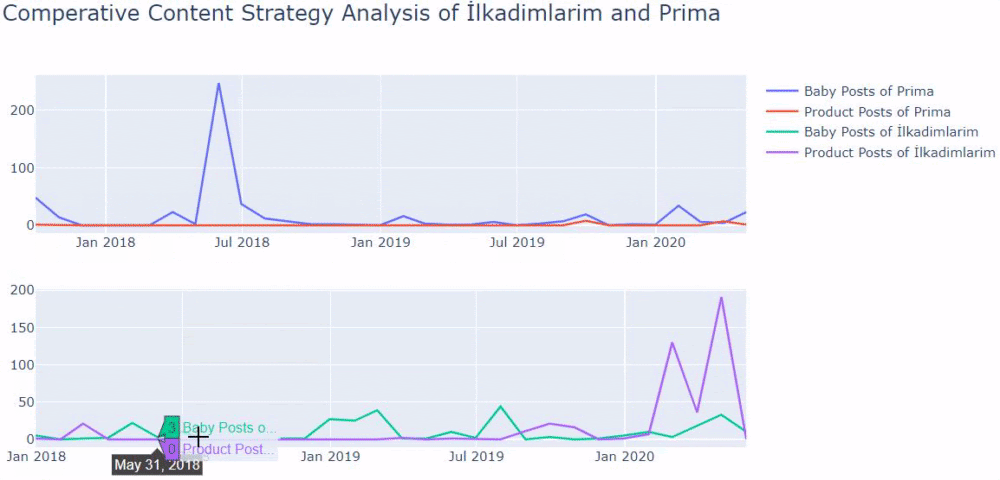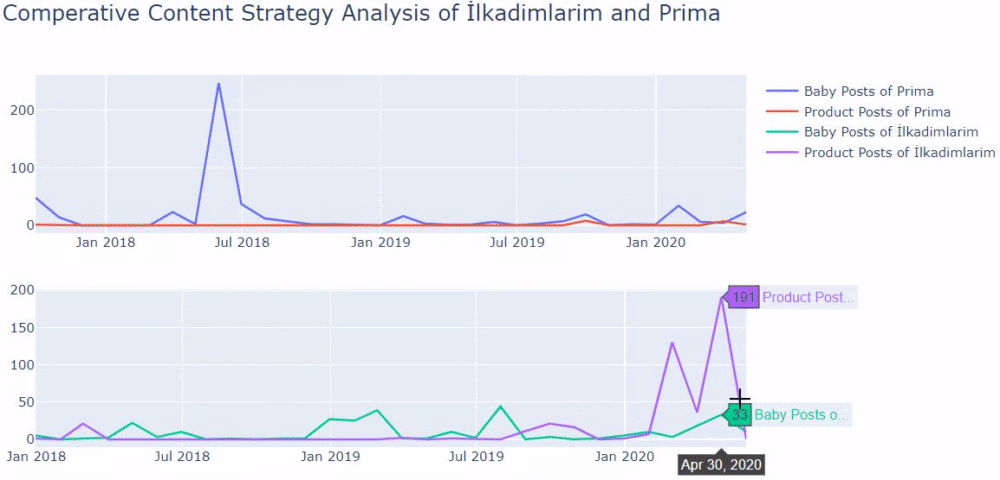
Se hai un cliente nello stesso settore, puoi utilizzare questi dati per creare una strategia di contenuto, per vedere i punti deboli dei tuoi concorrenti e la loro rete di query/landing page su SERP. Inoltre, puoi capire quale quantità di contenuto dovresti pubblicare nello stesso dominio della conoscenza o per lo stesso intento dell'utente.
Prima di concludere con ciò che possiamo imparare dalle mappe dei siti come parte di un'analisi della strategia dei contenuti, possiamo esaminare un ultimo sito Web con un numero di URL molto più elevato da un altro settore.
Analisi della strategia dei contenuti di entità Web di notizie su valute con Python e Sitemap
In questa sezione utilizzeremo il grafico della mappa di calore di Seaborn e anche alcuni metodi più elaborati di framing ed estrazione dei dati.

Elias Dabbas ha un archivio Kaggle interessante e davvero utile in termini di Data Science e SEO. Questo mese ha aperto una nuova sezione Kaggle Dataset per i siti di notizie turchi per consentirmi di scrivere i codici necessari ed eseguire un'analisi della strategia dei contenuti con Advertools tramite le mappe dei siti.
Prima di iniziare a utilizzare queste tecniche su Kaggle, in questo articolo vorrei mostrare alcuni esempi di cosa accadrebbe se utilizzassimo le stesse tecniche su entità Web più grandi.
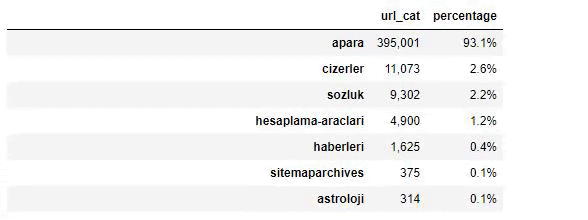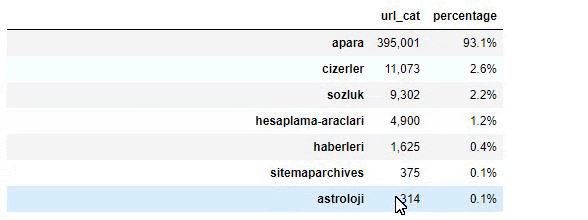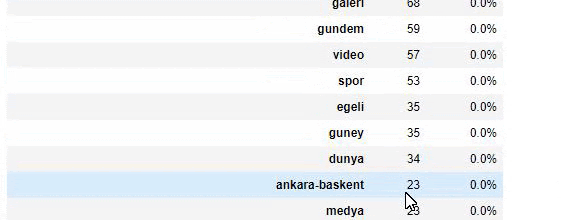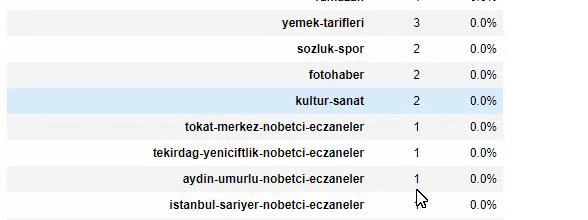
Quando analizziamo il contenuto di Sabah Newspaper, vediamo che una parte significativa dei suoi contenuti (81%) è in una categoria chiamata "apara". Inoltre, hanno alcune grandi categorie per l'astrologia, il calcolo, il dizionario, il tempo e le notizie dal mondo. (Para significa i soldi in turco)
Per Sabah Newspaper possiamo analizzare i contenuti anche con sitemap che abbiamo raccolto solo con Advertools, ma poiché il giornale in questione è molto grande, non l'ho preferito per via dell'alto numero di sitemap e del contenuto di diverse sitemap contenenti lo stesso URL Categoria.
Di seguito puoi anche vedere l'eccesso di sitemap con Advertools.
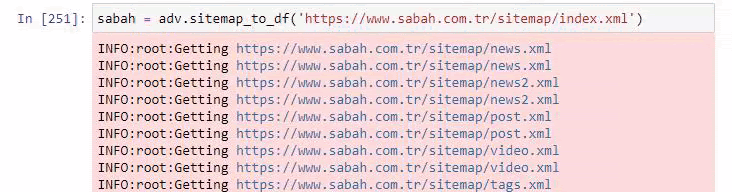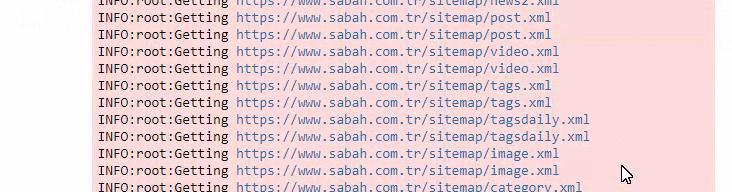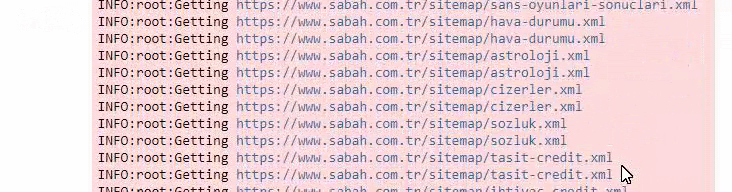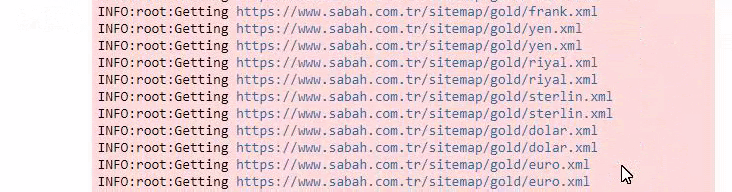
Potremmo vedere che hanno mappe del sito diverse per le stesse categorie di URL come oro, credito, valute, tag, tempi di preghiera e orari di lavoro della farmacia, ecc...
In breve, possiamo ottenere questi dettagli concentrandoci sulle sottocategorie di URL. Invece di unificare diverse mappe del sito tramite variabili. Quindi, ho unificato tutte le mappe del sito con il metodo sitemap_to_df() di Advertools come all'inizio dell'articolo.
Possiamo anche utilizzare un altro insieme di funzioni create da Elias Dabbas per creare frame di dati migliori. Se controlli le funzioni dataset_utitilites, puoi vedere alcuni esempi. Il codice seguente fornisce il totale e la percentuale di una regex URL specificata insieme alla somma cumulativa mediante stilizzazione.
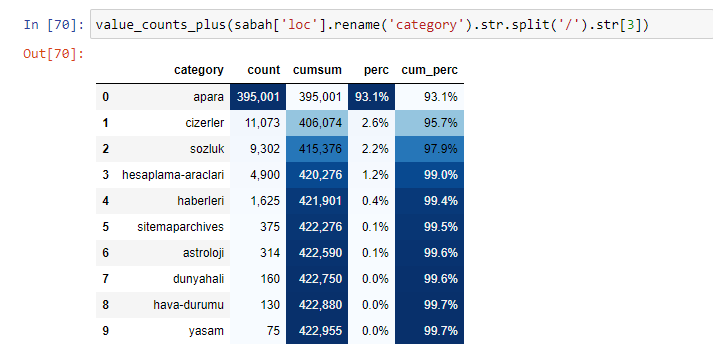
Se facciamo lo stesso con una suddivisione sotto-URL di Sabah Newspaper, otterremo il seguente risultato.
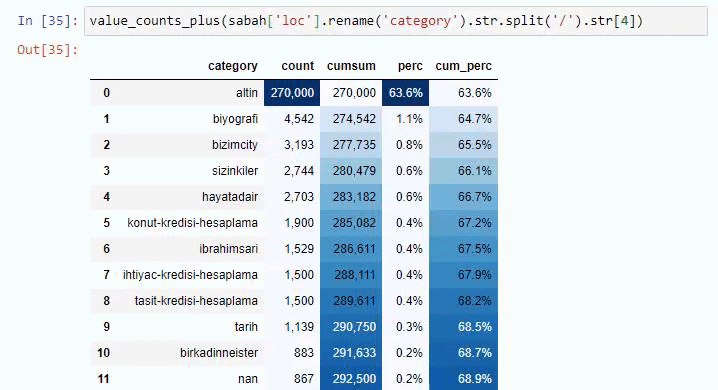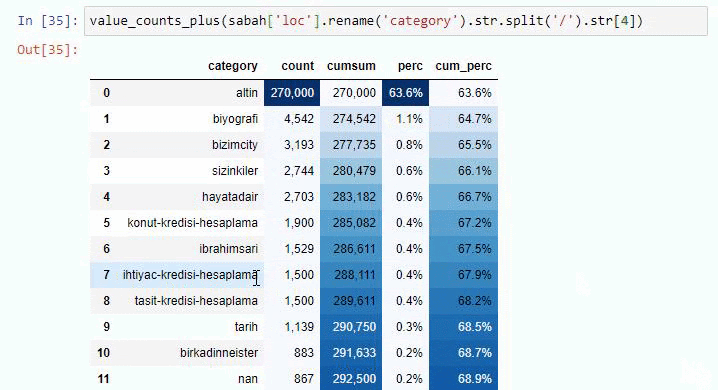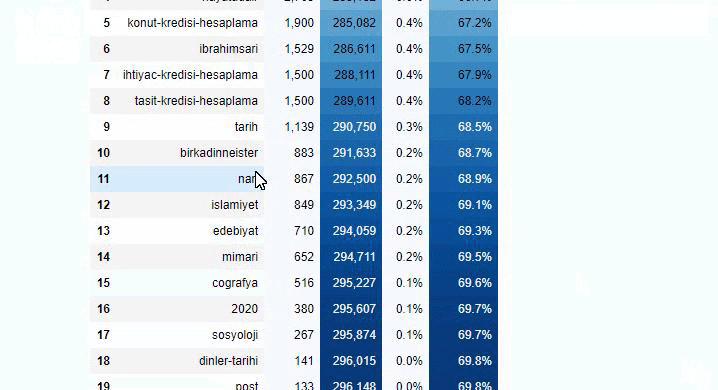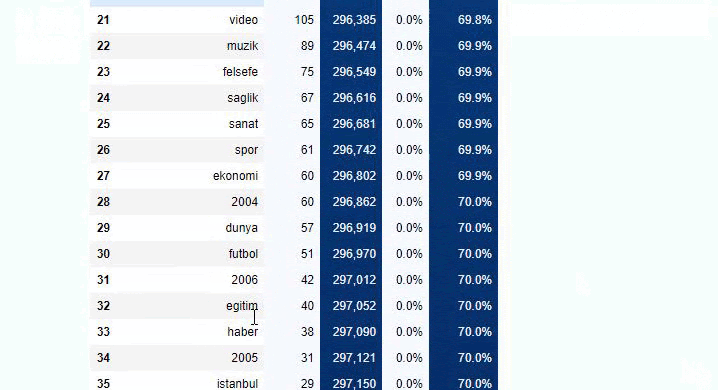
È possibile aumentare il numero di righe che la funzione in questione produrrà modificando la riga sottostante. Inoltre, se esamini il contenuto della funzione, vedrai che è simile a quelli che abbiamo usato prima.
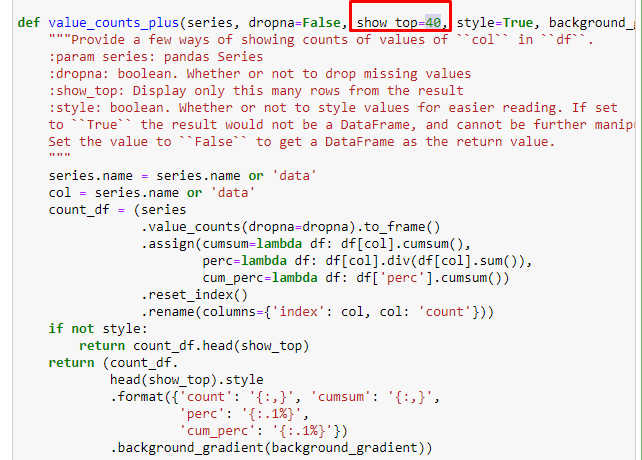
Nelle sotto-interruzioni vediamo diverse suddivisioni come "Storia della religione", "Biografia", "Nomi delle città", "Calcio", "Bizimcity (Caricature)", "Credito ipotecario". La ripartizione più grande è nella categoria "Oro".
Quindi, come può un giornale avere 295.000 URL per i prezzi dell'oro?
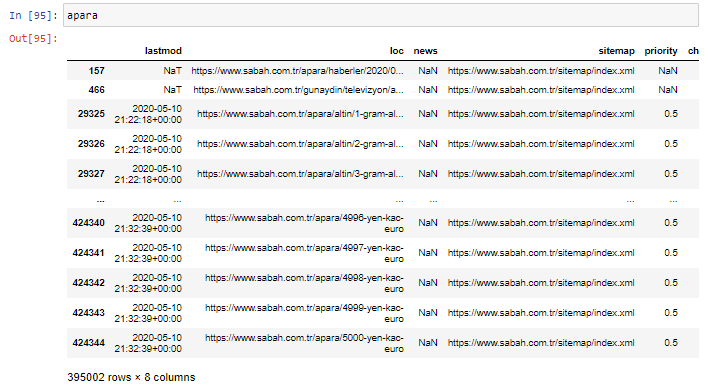
Prima di tutto, getto tutti gli URL che contengono "apara" nella prima scomposizione URL di Sabah Newspaper in una variabile.
apara = sabah[sabah['loc'].str.contains('apara')]
Ecco il risultato:
Possiamo anche filtrare le colonne con il metodo .filter():
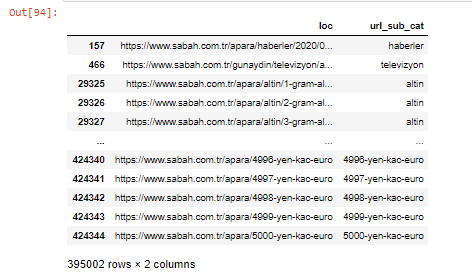
Ora, possiamo vedere in fondo al DataFrame perché Sabah Newspaper ha una quantità eccessiva di URL Apara perché hanno aperto pagine Web diverse per ogni importo di calcolo della valuta come 5000 Euro, 4999 Euro, 4998 Euro e altro ancora...
Ma, prima di qualsiasi conclusione, dobbiamo essere sicuri perché più di 250.000 di questi URL appartengono alla categoria "altin (gold)".
apara.filter(['loc', 'url_sub_cat' ]).tail(60) ci mostrerà le ultime 60 righe di questo Data Frame:

Possiamo fare lo stesso per la ripartizione degli URL gold all'interno del gruppo Apara.
gold = apara[apara['loc'].str.contains('altin')]
gold.filter(['loc','url_sub_cat']).tail(85)
gold.filter(['loc','url_sub_cat']).head(85)
A questo punto, vediamo che Sabah Newspaper ha aperto 5000 pagine diverse per convertire ogni valuta in Dollaro, Euro, Oro e TL (lire turche). C'è una pagina di calcolo separata per ogni unità di denaro tra 1 e 5000. Puoi vedere l'esempio delle prime 85 e delle ultime 85 righe del gruppo dell'oro di seguito. È stata aperta una pagina separata per ogni grammo di prezzo dell'oro.


Non abbiamo dubbi sul fatto che queste pagine non siano necessarie, con molti contenuti duplicati ed eccessivamente grandi, ma Sabah Newspaper è un sito Web così forte che Google continua a mostrarlo in quasi tutte le query, al primo posto.
A questo punto, possiamo anche vedere che la tolleranza ai costi di scansione è elevata per un vecchio sito di notizie con un'elevata autorità.
Tuttavia, questo non spiega perché la categoria oro abbia più URL di altre.
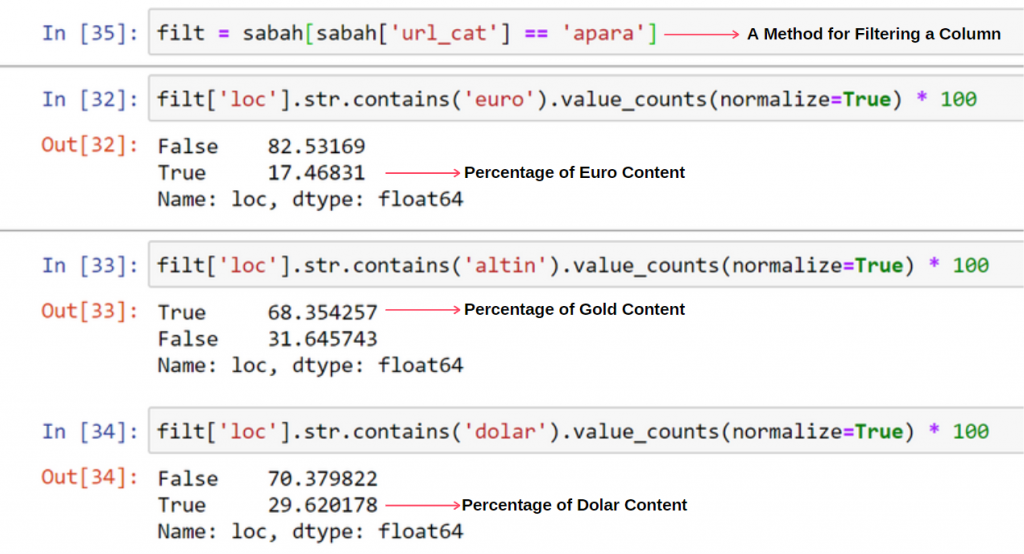
Non vedo nulla di strano nella sovrapposizione di valori che superano il 100%.
A meno che non mi sfugga qualcosa?
Come noterai, quando aggiungiamo tutti i True Values, otteniamo il risultato del 115,16%. La ragione di ciò è di seguito.
Anche il gruppo principale ha un'intersezione tra loro in questo modo. Potremmo anche analizzare questi incroci, ma potrebbe essere oggetto di un altro articolo.
Vediamo che il 68% dei contenuti nel gruppo URL Apara è correlato a GOLD.
Per comprendere meglio questa situazione, la prima cosa che dobbiamo fare è scansionare gli URL nella rifrazione dell'oro.
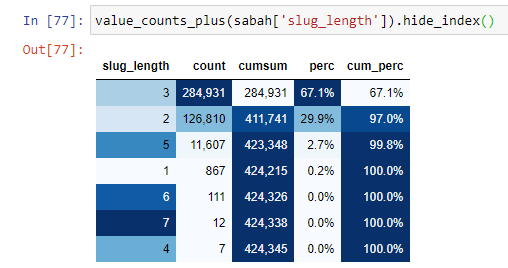
Quando classifichiamo gli URL in base alla quantità di '/' che hanno dalla sezione radice, vediamo che il numero di URL con un massimo di 3 interruzioni è elevato. Quando analizziamo questi URL, vediamo che 270.000 dei 3 URL slug_length sono nella categoria Gold.
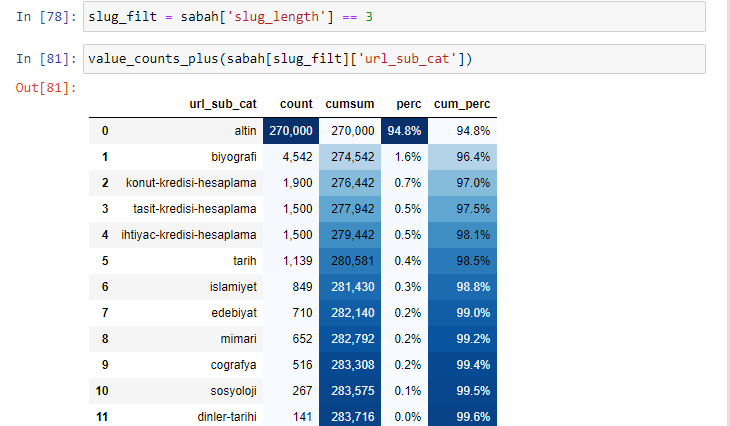
morning_filt = morning ['slug_length'] == 3 Significa che ottieni solo quelli che sono uguali a 3 dal gruppo di dati di tipo int in una determinata colonna di un determinato frame di dati. Quindi, sulla base di queste informazioni, inquadriamo gli URL che sono convenienti per la condizione con il conteggio, le somme e i tassi di aggregazione con la somma cumulativa.
Quando estraiamo le parole più comunemente usate negli URL gold, ci imbattiamo in parole che rappresentano "pieno", "repubblica", "quarto", "grammo", "metà", "antenato". I tipi di oro Ata e Republic sono unici per la Turchia. Uno di loro rappresenta la sovranità turca e l'altro è il fondatore della Repubblica, Kemal Ataturk. Ecco perché i loro volumi di ricerca delle query sono elevati.
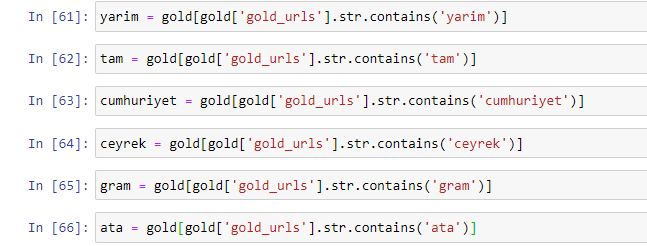
Prima di tutto, abbiamo rimosso le parole comuni che si trovano negli URL e le abbiamo assegnate a variabili separate. Successivamente, utilizzeremo queste variabili in Gold DataFrame per creare colonne specifiche per i loro tipi.
Dopo aver creato nuove colonne tramite variabili, dobbiamo filtrarle insieme ai valori booleani.
Come puoi vedere, siamo stati in grado di classificare tutti gli URL gold con 270.000 righe e 6 colonne. Il motivo principale dell'alto numero di pagine specifiche per l'oro è che il dollaro o l'euro non hanno tipi separati, mentre l'oro ha tipi separati. Allo stesso tempo, la diversità di incroci tra oro e valute diverse è maggiore rispetto ad altre valute a causa della loro tradizionale fiducia nel popolo turco.
Secondo me, tutti i tipi di pagine gold dovrebbero essere equamente distribuiti, giusto?
Possiamo facilmente testarlo con la funzione Heatmap di Seaborn.
import seaborn come sns
importa matplotlib.pyplot come plt
plt.figure(figsize=(10,8))
sns.heatmap(a,yticklabels=False,cbar=False,cmap=”viridis”)
plt.show()
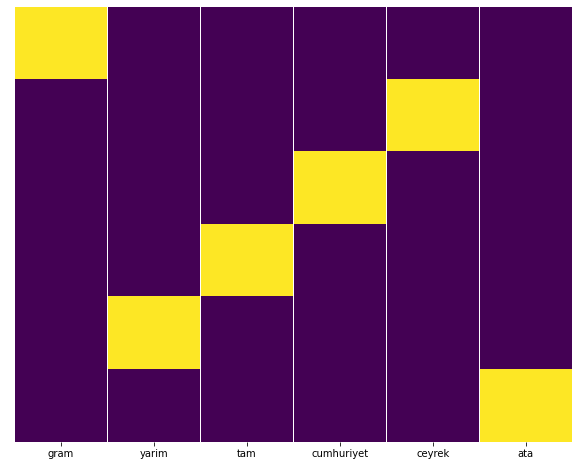
Qui sulla Heat Map, i Trues in ogni colonna sono semplicemente contrassegnati. Come si può vedere, la dimensione di ciascuno è simmetrica tra loro ed è ordinatamente disposta sulla mappa.
Pertanto, abbiamo adottato un'ampia prospettiva sulla politica dei contenuti del giornale Sabah.com.tr sulle valute e sul calcolo delle valute.
In futuro scriverò siti Web di notizie turchi e le loro strategie di contenuto basati su Sitemaps Kaggle, lanciato da Elias Dabbas, ma in questo articolo abbiamo parlato abbastanza di ciò che si può scoprire su siti Web grandi e piccoli con le Sitemap .
Conclusione e Takeaway
Penso che abbiamo visto quanto sia facile capire un sito Web, grazie a una struttura URL fluida e semantica. Dovremmo anche ricordare quanto può essere preziosa una struttura URL adeguata per Google.
In futuro vedremo molti SEO che hanno sempre più familiarità con la scienza dei dati, la visualizzazione dei dati, la programmazione front-end e altro ancora... Vedo questo processo come l'inizio di un cambiamento inevitabile: il divario tra SEO e sviluppatori sarà completamente colmato in pochi anni.
Con Python, puoi portare questo tipo di analisi ancora oltre: è possibile ottenere dati dalla comprensione delle opinioni politiche di un sito di notizie, a chi scrive su cosa, con quale frequenza e con quali sentimenti. Preferisco non approfondire qui poiché questi processi riguardano più la pura scienza dei dati che la SEO (e questo articolo è già piuttosto lungo).
Ma se sei interessato, ci sono molti altri tipi di audit che possono essere eseguiti tramite Sitemap e Python, come controllare i codici di stato degli URL in una Sitemap.
Non vedo l'ora di sperimentare e condividere altre attività SEO che puoi svolgere con Python e Advertools.