
Comprendere l'intelligenza artificiale: come abbiamo insegnato ai computer il linguaggio naturale
Pubblicato: 2023-11-28L’espressione “intelligenza artificiale” è stata utilizzata in relazione ai computer sin dagli anni ’50, ma fino all’anno scorso la maggior parte delle persone probabilmente pensava che l’intelligenza artificiale fosse ancora più fantascientifica che realtà tecnologica.
L'arrivo di ChatGPT di OpenAI nel novembre 2022 ha improvvisamente cambiato la percezione delle persone su ciò di cui era capace l'apprendimento automatico, ma cosa c'era esattamente in ChatGPT che ha fatto alzare il mondo e realizzare che l'intelligenza artificiale era qui su grande scala?
In una parola, il linguaggio: il motivo per cui ChatGPT sembrava un balzo in avanti così notevole era perché sembrava fluente nel linguaggio naturale in un modo in cui nessun chatbot era mai stato prima.
Ciò segna una nuova straordinaria fase di “elaborazione del linguaggio naturale” (NLP), la capacità dei computer di interpretare il linguaggio naturale e produrre risposte convincenti. ChatGPT è basato su un "modello linguistico di grandi dimensioni" (LLM), che è un tipo di rete neurale che utilizza il deep learning addestrato su enormi set di dati in grado di elaborare e generare contenuti.
"Come ha fatto un programma per computer a raggiungere una tale fluidità linguistica?"
Ma come siamo arrivati fin qui? Come ha fatto un programma per computer a raggiungere una tale fluidità linguistica? Come può sembrare così infallibilmente umano?
ChatGPT non è stato creato nel vuoto: si è basato su una miriade di innovazioni e scoperte diverse negli ultimi decenni. La serie di scoperte che hanno portato a ChatGPT sono state tutte pietre miliari nell'informatica, ma è possibile vederle come un'imitazione delle fasi attraverso le quali gli esseri umani acquisiscono il linguaggio.
Come impariamo la lingua?
Per capire come l’intelligenza artificiale abbia raggiunto questo stadio, vale la pena considerare la natura stessa dell’apprendimento delle lingue: iniziamo con singole parole e poi iniziamo a combinarle insieme in sequenze più lunghe finché non riusciamo a comunicare concetti, idee e istruzioni complessi.
Ad esempio, alcune fasi comuni dell'acquisizione del linguaggio nei bambini sono:
- Fase olofrastica: tra i 9 e i 18 mesi, i bambini imparano a usare singole parole che descrivono i loro bisogni o desideri di base. Comunicare con una singola parola significa che si pone l'accento sulla chiarezza piuttosto che sulla completezza concettuale. Se un bambino ha fame non dirà “voglio del cibo” o “ho fame”, ma dirà semplicemente “cibo” o “latte”.
- Fase delle due parole: durante l'età di 18-24 mesi i bambini iniziano a utilizzare semplici raggruppamenti di due parole per migliorare le loro capacità comunicative. Ora possono comunicare i loro sentimenti e bisogni con espressioni come “più cibo” o “leggi libro”.
- Fase telegrafica: tra i 24 e i 30 mesi i bambini iniziano a mettere insieme più parole per formare frasi e frasi più complesse. Il numero di parole utilizzate è ancora piccolo ma iniziano a comparire un corretto ordinamento delle parole e una maggiore complessità. I bambini iniziano ad imparare la costruzione di frasi di base, come "voglio mostrarlo alla mamma".
- Fase multiparola: dopo 30 mesi i bambini iniziano a passare alla fase multiparola. In questa fase i bambini iniziano a usare frasi grammaticalmente più corrette, complesse e composte da più proposizioni. Questa è la fase finale dell’acquisizione del linguaggio e i bambini alla fine comunicano con frasi complesse come “Se piove, voglio restare a casa e giocare”.
Una delle prime fasi fondamentali nell'acquisizione del linguaggio è la capacità di iniziare a utilizzare singole parole in modo molto semplice. Quindi il primo ostacolo che i ricercatori dell’intelligenza artificiale dovevano superare era come addestrare i modelli ad apprendere semplici associazioni di parole.
Modello 1 – Imparare parole singole con Word2Vec (documento 1 e documento 2)
Uno dei primi modelli di rete neurale che ha tentato di apprendere associazioni di parole in questo modo è stato Word2Vec, sviluppato da Tomaš Mikolov e un gruppo di ricercatori di Google. È stato pubblicato in due articoli nel 2013 (il che dimostra quanto velocemente si siano sviluppate le cose in questo campo).
Questi modelli sono stati addestrati imparando ad associare parole comunemente usate insieme. Questo approccio si basava sull’intuizione dei primi pionieri linguistici come John R. Firth, il quale notò che il significato poteva essere derivato dall’associazione di parole: “Conoscerai una parola dalla compagnia che frequenta”.
L'idea è che le parole che condividono un significato semantico simile tendono a ricorrere più frequentemente insieme. Le parole “gatti” e “cani” generalmente ricorrono più frequentemente insieme rispetto a parole come “mele” o “computer”. In altre parole, la parola “gatto” dovrebbe essere più simile alla parola “cane” di quanto “gatto” lo sia a “mela” o “computer”.
La cosa interessante di Word2Vec è il modo in cui è stato addestrato ad apprendere queste associazioni di parole:
- Indovina la parola target: al modello viene assegnato un numero fisso di parole come input con la parola target mancante e deve indovinare la parola target mancante. Questo è noto come Borsa Continua di Parole (CBOW).
- Indovina le parole circostanti: al modello viene assegnata una singola parola e quindi il compito di indovinare le parole circostanti. Questo è noto come Skip-Gram ed è l'approccio opposto al CBOW in quanto prevediamo le parole circostanti.
Un vantaggio di questi approcci è che non è necessario disporre di dati etichettati per addestrare il modello: etichettare i dati, ad esempio descrivendo il testo come “positivo” o “negativo” per insegnare l’analisi del sentiment, dopo tutto è un lavoro lento e laborioso.
Una delle cose più sorprendenti di Word2Vec sono state le complesse relazioni semantiche catturate con un approccio di formazione relativamente semplice. Word2Vec emette vettori che rappresentano la parola di ingresso. Eseguendo operazioni matematiche su questi vettori gli autori sono stati in grado di dimostrare che i vettori di parole non catturano solo elementi sintatticamente simili ma anche relazioni semantiche complesse.
Queste relazioni sono legate al modo in cui vengono usate le parole. L'esempio che gli autori hanno notato è stato il rapporto tra parole come “Re” e “Regina” e “Uomo” e “Donna”.
Ma nonostante fosse un passo avanti, Word2Vec aveva dei limiti. Aveva solo una definizione per parola: ad esempio, sappiamo tutti che "banca" può significare cose diverse a seconda che tu voglia tenerne una o pescare da una. A Word2Vec non importava, aveva solo una definizione della parola “banca” e l'avrebbe usata in tutti i contesti.
Soprattutto, Word2Vec non è in grado di elaborare istruzioni e nemmeno frasi. Poteva solo prendere una parola come input e produrre un "incorporamento di parole", o rappresentazione vettoriale, che aveva imparato per quella parola. Per basarsi su questa singola parola, i ricercatori dovevano trovare un modo per mettere insieme due o più parole in una sequenza. Possiamo immaginare questo come simile alla fase di acquisizione del linguaggio delle due parole.
Modello 2 – Apprendimento di sequenze di parole con RNN e sequenze di testo
Una volta che i bambini hanno iniziato a padroneggiare l’uso delle singole parole, tentano di mettere insieme le parole per esprimere pensieri e sentimenti più complessi. Allo stesso modo, il passo successivo nello sviluppo della PNL è stato quello di sviluppare la capacità di elaborare sequenze di parole. Il problema con l'elaborazione di sequenze di testo è che non hanno una lunghezza fissa. Una frase può variare in lunghezza da poche parole a un lungo paragrafo. Non tutta la sequenza sarà importante per il significato e il contesto complessivi. Ma dobbiamo essere in grado di elaborare l’intera sequenza per sapere quali parti sono più rilevanti.
È qui che sono nate le reti neurali ricorrenti (RNN).
Sviluppata negli anni '90, una RNN funziona elaborando il suo input in un ciclo in cui l'output dei passaggi precedenti viene trasportato attraverso la rete mentre itera attraverso ogni passaggio della sequenza.
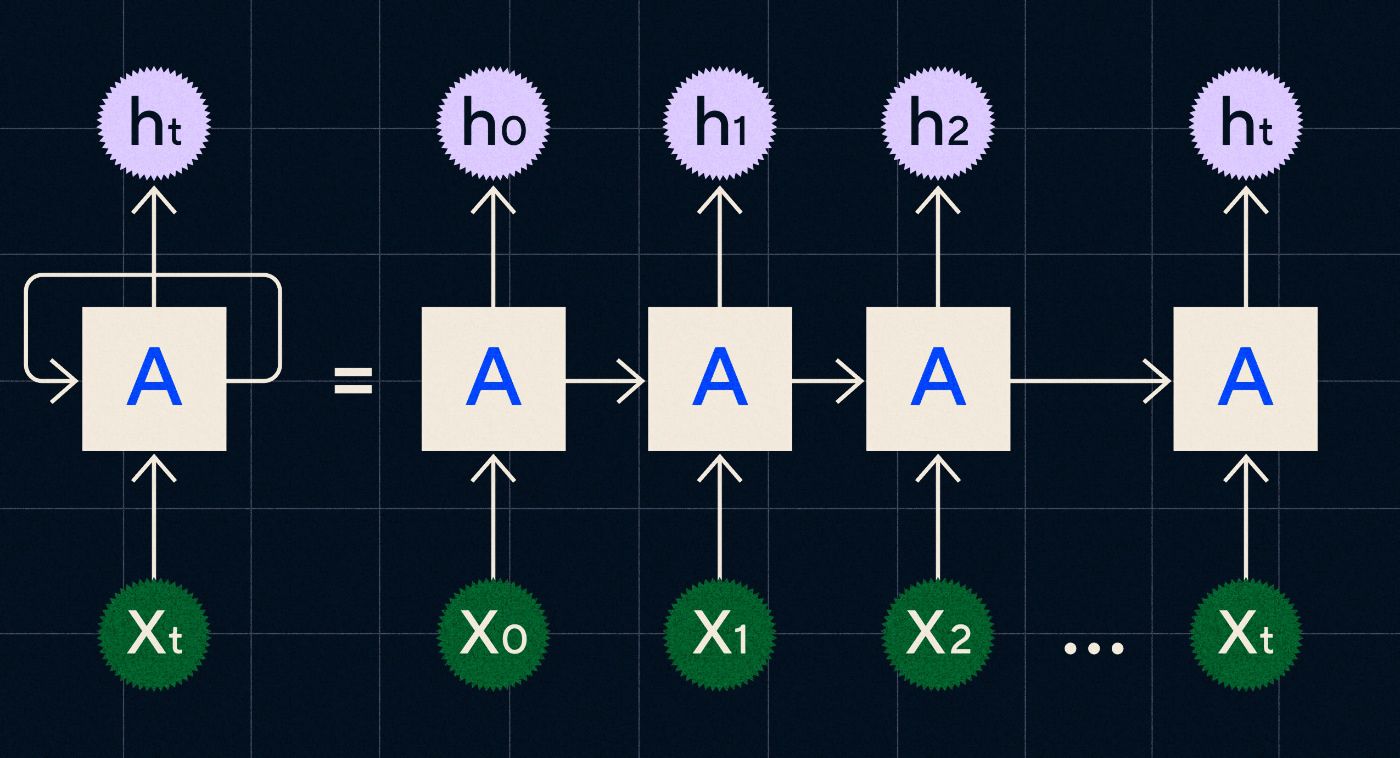
Fonte: post sul blog di Christopher Olah sulle RNN
Il diagramma sopra mostra come immaginare una RNN come una serie di reti neurali (A) in cui l'output del passaggio precedente (h0, h1, h2…ht) viene portato al passaggio successivo. In ogni passo la rete elabora anche un nuovo ingresso (X0, X1, X2...Xt).
Le RNN (e in particolare le reti di memoria a lungo termine o LSTM, un tipo speciale di RNN introdotto da Sepp Hochreiter e Jurgen Schmidhuber nel 1997) ci hanno permesso di creare architetture di reti neurali in grado di eseguire compiti più complessi come la traduzione.
Nel 2014, è stato pubblicato un articolo da Ilya Sutskever (un co-fondatore di OpenAI), Oriol Vinyals e Quoc V Le di Google, che descriveva i modelli Sequence to Sequence (Seq2Seq). Questo articolo ha mostrato come addestrare una rete neurale a ricevere un testo di input e restituire una traduzione di quel testo. Puoi considerarlo un primo esempio di rete neurale generativa, in cui le dai un prompt e restituisce una risposta. Tuttavia, l’attività era fissa, quindi se fosse stato addestrato alla traduzione, non potevi “suggerirlo” di fare qualcos’altro.
Ricorda che il modello precedente, Word2Vec, poteva elaborare solo parole singole. Quindi, se gli passassi una frase come "il dentista mi ha tirato il dente", genererebbe semplicemente un vettore per ogni parola come se non fossero correlate.
Tuttavia, l'ordine e il contesto sono importanti per attività come la traduzione. Non puoi semplicemente tradurre singole parole, devi analizzare sequenze di parole e quindi generare il risultato. È qui che gli RNN hanno consentito ai modelli Seq2Seq di elaborare le parole in questo modo.
La chiave dei modelli Seq2Seq era la progettazione della rete neurale, che utilizzava due RNN uno dopo l’altro. Uno era un codificatore che trasformava l'input dal testo in un incorporamento, e l'altro era un decodificatore che prendeva come input gli incorporamenti emessi dal codificatore:
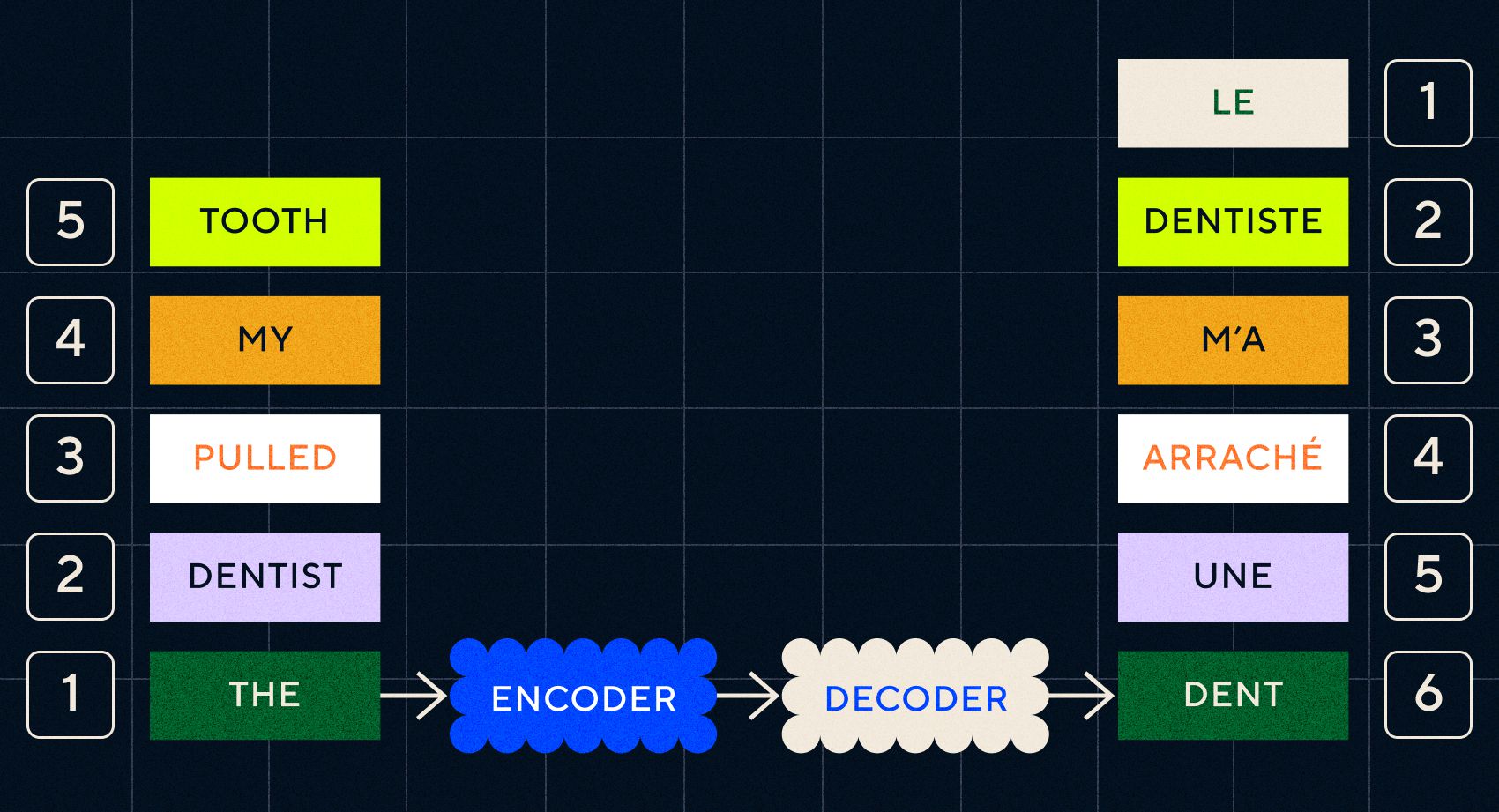
Una volta che il codificatore ha elaborato gli input in ogni passaggio, inizia a passare l'output al decodificatore che trasforma gli incorporamenti in un testo tradotto.
Possiamo vedere con l'evoluzione di questi modelli che stanno iniziando ad assomigliare, in qualche forma semplice, a quello che vediamo oggi con ChatGPT. Tuttavia, possiamo anche vedere quanto limitati fossero questi modelli in confronto. Come per lo sviluppo del nostro linguaggio, per migliorare davvero le nostre abilità linguistiche dobbiamo sapere esattamente a cosa prestare attenzione per creare frasi ed espressioni più complesse.
Modello 3 – Apprendimento tramite attenzione e scalabilità con Transformers
Abbiamo notato in precedenza che le fasi telegrafiche erano quelle in cui i bambini iniziavano a creare brevi frasi con due o più parole. Un aspetto chiave di questa fase di acquisizione del linguaggio è che i bambini iniziano a imparare a costruire frasi corrette.
I modelli RNN e Seq2Seq hanno aiutato i modelli linguistici a elaborare più sequenze di parole, ma erano ancora limitati nella lunghezza delle frasi che potevano elaborare. All’aumentare della lunghezza della frase dobbiamo prestare attenzione alla maggior parte delle cose nella frase.
Ad esempio, prendi la seguente frase "C'era così tanta tensione nella stanza che potevi tagliarla con un coltello". C'è molto da fare lì. Per sapere che qui non stiamo letteralmente tagliando qualcosa con un coltello dobbiamo collegare “taglio” con “tensione” all’inizio della frase.
Man mano che la lunghezza della frase aumenta, diventa più difficile sapere quali parole si riferiscono a quale per dedurne il significato corretto. È qui che le RNN hanno iniziato a incontrare limiti e avevamo bisogno di un nuovo modello per passare alla fase successiva dell’acquisizione del linguaggio.
“Pensa di provare a riassumere una conversazione man mano che diventa sempre più lunga con un limite fisso di parole. Ad ogni passo inizi a perdere sempre più informazioni”
Nel 2017, un gruppo di ricercatori di Google ha pubblicato un articolo in cui proponeva una tecnica per consentire ai modelli di prestare meglio attenzione al contesto importante in un pezzo di testo.
Ciò che hanno sviluppato è stato un modo per consentire ai modelli linguistici di cercare più facilmente il contesto di cui avevano bisogno durante l'elaborazione di una sequenza di testo di input. Hanno chiamato questo approccio “architettura del trasformatore” e ha rappresentato il più grande passo avanti nell’elaborazione del linguaggio naturale fino ad oggi.
Questo meccanismo di ricerca rende più semplice per il modello identificare quale delle parole precedenti ha fornito più contesto alla parola corrente in fase di elaborazione. Gli RNN cercano di fornire il contesto trasmettendo uno stato aggregato di tutte le parole che sono già state elaborate in ogni passaggio. Pensa di provare a riassumere una conversazione man mano che diventa sempre più lunga con un limite fisso di parole. Ad ogni passo inizi a perdere sempre più informazioni. Invece, i trasformatori hanno ponderato le parole (o i token, che non sono parole intere ma parti di parole) in base alla loro importanza per la parola corrente in termini di contesto. Ciò ha reso più semplice l’elaborazione di sequenze di parole sempre più lunghe senza il collo di bottiglia riscontrato negli RNN. Questo nuovo meccanismo di attenzione ha inoltre consentito di elaborare il testo in parallelo invece che in sequenza come un RNN.
Immaginate quindi una frase del tipo “L'animale non ha attraversato la strada perché era troppo stanco”. Per un RNN dovrebbe rappresentare tutte le parole precedenti in ogni passaggio. Man mano che il numero di parole tra “esso” e “animale” aumenta, diventa più difficile per la RNN identificare il contesto corretto.

Con l'architettura del trasformatore, il modello ora ha la capacità di cercare la parola che con maggiore probabilità si riferisce a “esso”. Il diagramma seguente mostra come i modelli del trasformatore siano in grado di concentrarsi sulla parte "animale" del testo mentre tentano di elaborare una frase.
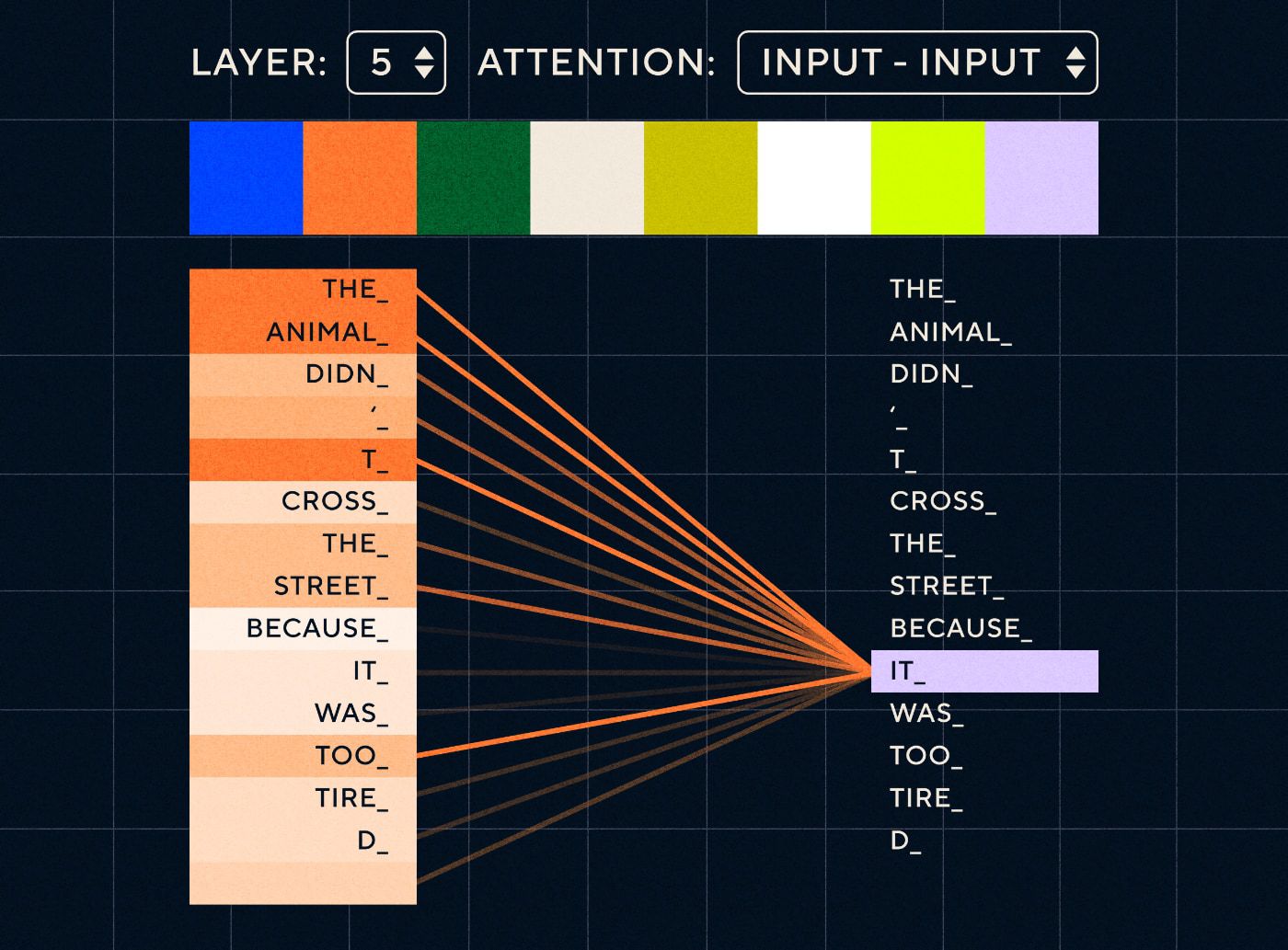
Fonte: Il trasformatore illustrato
Il diagramma sopra mostra l'attenzione al livello 5 della rete. Ad ogni livello il modello sta sviluppando la sua comprensione della frase e "prestando attenzione" a una parte particolare dell'input che ritiene sia più rilevante per il passaggio che sta elaborando in quel momento, cioè sta prestando maggiore attenzione "al animale" per "esso" in questo livello. Fonte: Il trasformatore illustrato
Pensatelo come un database in cui è possibile recuperare la parola con il punteggio più alto che molto probabilmente è correlata a “esso”.
Con questo sviluppo, i modelli linguistici non si sono limitati all’analisi di brevi sequenze testuali. Invece potresti usare sequenze di testo più lunghe come input. Sappiamo che esporre i bambini a più parole attraverso una “conversazione impegnata” aiuta a migliorare il loro sviluppo linguistico.
Allo stesso modo, con il nuovo meccanismo di attenzione, i modelli linguistici sono stati in grado di analizzare più e vari tipi di dati di addestramento testuale. Ciò includeva articoli di Wikipedia, forum online, Twitter e qualsiasi altro dato di testo che potresti analizzare. Come nel caso dello sviluppo infantile, l’esposizione a tutte queste parole e il loro utilizzo in contesti diversi ha aiutato i modelli linguistici a sviluppare capacità linguistiche nuove e più complicate.
È stato in questa fase che abbiamo iniziato a vedere una corsa al ridimensionamento in cui le persone lanciavano sempre più dati su questi modelli per vedere cosa potevano imparare. Questi dati non avevano bisogno di essere etichettati dagli esseri umani: i ricercatori potevano semplicemente racimolare Internet e inserirli nel modello e vedere cosa imparava.
“Modelli come BERT hanno infranto ogni record disponibile sull’elaborazione del linguaggio naturale. In effetti, i set di dati di test utilizzati per queste attività erano troppo semplici per questi modelli di trasformatori”
Il modello BERT (Bidirection Encoder Representations from Transformers) merita una menzione speciale per alcuni motivi. È stato uno dei primi modelli a utilizzare la funzione di attenzione che è il cuore dell'architettura Transformer. Innanzitutto, BERT era bidirezionale nel senso che poteva esaminare il testo sia a sinistra che a destra dell'input corrente. Questo era diverso dagli RNN che potevano elaborare il testo solo in sequenza da sinistra a destra. In secondo luogo, BERT ha utilizzato anche una nuova tecnica di addestramento chiamata “mascheramento” che, in un certo senso, costringeva il modello ad apprendere il significato di diversi input “nascondendo” o “mascherando” token casuali per garantire che il modello non potesse “imbrogliare” e concentrarsi su un singolo token in ogni iterazione. E infine, BERT potrebbe essere messo a punto per eseguire diversi compiti di PNL. Non è stato necessario addestrarlo da zero per questi compiti.
I risultati sono stati sorprendenti. Modelli come BERT hanno infranto ogni record disponibile sull’elaborazione del linguaggio naturale. In effetti, i set di dati di test utilizzati per queste attività erano troppo semplici per questi modelli di trasformatori.
Ora avevamo la capacità di addestrare modelli linguistici di grandi dimensioni che fungevano da modelli di base per nuove attività di elaborazione del linguaggio naturale. In precedenza le persone addestravano i propri modelli per lo più da zero. Ma ora i modelli pre-addestrati come BERT e i primi modelli GPT erano così buoni che non aveva senso farlo da soli. In effetti, questi modelli erano così validi che le persone scoprirono che potevano eseguire nuovi compiti con relativamente pochi esempi: furono descritti come "studenti con poche abilità", in modo simile a come la maggior parte delle persone non ha bisogno di troppi esempi per afferrare nuovi concetti.
Questo è stato un enorme punto di svolta nello sviluppo di questi modelli e delle loro capacità linguistiche. Ora dovevamo solo migliorare nelle istruzioni per la creazione.
Modello 4 – Istruzioni di apprendimento con InstructGPT
Una delle cose che i bambini imparano nella fase finale dell'acquisizione del linguaggio, la fase multi-parola, è la capacità di usare parole funzionali per collegare gli elementi che trasportano informazioni in una frase. Le parole funzionali ci parlano della relazione tra le diverse parole in una frase. Se vogliamo creare istruzioni, i modelli linguistici dovranno essere in grado di creare frasi con parole di contenuto e parole funzionali che catturino relazioni complesse. Ad esempio, la seguente istruzione ha le parole funzionali evidenziate in grassetto:
- “ Voglio che tu scriva una lettera…”
- " Dimmi cosa pensi del testo sopra "
Ma prima di poter provare ad addestrare i modelli linguistici a seguire le istruzioni, dovevamo capire esattamente cosa già sapevano sulle istruzioni.
GPT-3 di OpenAI è stato rilasciato nel 2020. Era un assaggio di ciò di cui erano capaci questi modelli, ma dovevamo ancora capire come sbloccare le capacità sottostanti di questi modelli. Come potremmo interagire con questi modelli per fargli svolgere compiti diversi?
Ad esempio, GPT-3 ha dimostrato che l’aumento delle dimensioni del modello e dei dati di addestramento ha consentito ciò che gli autori hanno chiamato “meta-apprendimento”: è qui che il modello linguistico sviluppa un ampio insieme di abilità linguistiche, molte delle quali erano inaspettate, e può utilizzarle. capacità di comprendere un determinato compito.
"Il modello sarebbe in grado di comprendere l'intento dell'istruzione ed eseguire l'attività anziché semplicemente prevedere la parola successiva?"
Ricorda, GPT-3 e i modelli linguistici precedenti non erano progettati per sviluppare queste abilità: erano per lo più addestrati semplicemente a prevedere la parola successiva in una sequenza di testo. Ma, attraverso i progressi con RNN, Seq2Seq e reti di attenzione, questi modelli sono stati in grado di elaborare più testo, in sequenze più lunghe e concentrarsi meglio sul contesto rilevante.
Puoi pensare a GPT-3 come a un test per vedere fino a che punto potremmo spingerci. Quanto grandi potremmo realizzare i modelli e quanto testo potremmo alimentarli? Quindi, dopo averlo fatto, invece di fornire semplicemente al modello del testo di input da completare, potremmo utilizzare il testo di input come istruzione. Il modello sarebbe in grado di comprendere l’intento dell’istruzione ed eseguire l’attività anziché semplicemente prevedere la parola successiva? In un certo senso è stato come cercare di capire a quale stadio di acquisizione del linguaggio fossero arrivati questi modelli.
Ora lo descriviamo come “suggerimento”, ma nel 2020, al momento della pubblicazione del documento, questo era un concetto molto nuovo.
Allucinazioni e allineamento
Il problema con GPT-3, come ora sappiamo, era che non era eccezionale nel seguire fedelmente le istruzioni nel testo di input. GPT-3 può seguire le istruzioni ma perde facilmente l'attenzione, può comprendere solo istruzioni semplici e tende a inventare cose. In altre parole, i modelli non sono “allineati” alle nostre intenzioni. Quindi il problema ora non è tanto migliorare la capacità linguistica dei modelli, ma piuttosto la loro capacità di seguire le istruzioni.
Vale la pena notare che GPT-3 non è mai stato veramente addestrato su istruzioni. Non veniva detto cosa fosse un'istruzione, o in cosa differisse da altri testi, o come avrebbe dovuto seguire le istruzioni. In un certo senso, è stato “ingannato” a seguire le istruzioni facendogli “completare” un prompt come altre sequenze di testo. Di conseguenza, OpenAI doveva addestrare un modello che fosse in grado di seguire meglio le istruzioni come un essere umano. E lo hanno fatto in un articolo giustamente intitolato Modelli linguistici di formazione per seguire le istruzioni con feedback umano pubblicato all’inizio del 2022. InstructGPT si sarebbe rivelato un precursore di ChatGPT più tardi nello stesso anno.
I passaggi delineati in quel documento sono stati utilizzati anche per addestrare ChatGPT. La formazione didattica ha seguito 3 fasi principali:
- Passaggio 1: perfezionare GPT-3: poiché GPT-3 sembrava funzionare così bene con l'apprendimento in pochi passaggi, si pensava che sarebbe stato meglio se fosse stato perfezionato su esempi di istruzioni di alta qualità. L'obiettivo era rendere più semplice allineare l'intento dell'istruzione con la risposta generata. Per fare ciò, OpenAI ha chiesto agli etichettatori umani di creare risposte ad alcuni suggerimenti inviati da persone che utilizzano GPT-3. Utilizzando istruzioni reali, gli autori speravano di catturare una "distribuzione" realistica delle attività che gli utenti stavano cercando di far eseguire a GPT-3. Queste sono state utilizzate per mettere a punto GPT-3 per aiutarlo a migliorare la sua capacità di risposta rapida.
- Passaggio 2: chiedere agli esseri umani di classificare il nuovo e migliorato GPT-3: per valutare la nuova istruzione GPT-3 ottimizzata, gli etichettatori ora hanno valutato le prestazioni dei modelli su diversi prompt senza risposta predefinita. La classifica era correlata a importanti fattori di allineamento come l’essere utile, veritiero e non tossico, parziale o dannoso. Assegna quindi un compito al modello e valuta le sue prestazioni in base a questi parametri. Il risultato di questo esercizio di classificazione è stato poi utilizzato per addestrare un modello separato per prevedere quali risultati avrebbero probabilmente preferito gli etichettatori. Questo modello è noto come modello di ricompensa (RM).
- Passaggio 3: utilizzare l'RM per addestrarsi su più esempi: infine, l'RM è stato utilizzato per addestrare il nuovo modello di istruzioni per generare meglio risposte allineate alle preferenze umane.
È difficile comprendere appieno cosa sta succedendo qui con l’apprendimento per rinforzo dal feedback umano (RLHF), i modelli di ricompensa, gli aggiornamenti delle politiche e così via.
Un modo semplice di pensarci è che sia semplicemente un modo per consentire agli esseri umani di generare esempi migliori di come seguire le istruzioni. Ad esempio, pensa a come proveresti a insegnare a un bambino a dire grazie:
- Genitore: “Quando qualcuno ti dà X, dici grazie”. Questo è il passaggio 1, un esempio di set di dati di prompt e risposte appropriate
- Genitore: “Ora, cosa dici a Y qui?”. Questo è il passaggio 2 in cui chiediamo al bambino di generare una risposta e poi il genitore la valuterà. "Si, va bene."
- Infine, negli incontri successivi il genitore ricompenserà il bambino sulla base di esempi positivi o negativi di risposte in scenari simili futuri. Questo è il passaggio 3, dove ha luogo il comportamento di rinforzo.
Da parte sua, OpenAI afferma che tutto ciò che fa è semplicemente sbloccare funzionalità che erano già presenti in modelli come GPT-3, "ma che erano difficili da ottenere solo attraverso la pronta ingegneria", come afferma il documento.
In altre parole, ChatGPT non sta realmente imparando “ nuove ” funzionalità, ma semplicemente imparando una migliore “ interfaccia ” linguistica per utilizzarle.
La magia del linguaggio
ChatGPT sembra un magico balzo in avanti, ma in realtà è il risultato di un minuzioso progresso tecnologico nel corso di decenni.
Osservando alcuni dei principali sviluppi nel campo dell’intelligenza artificiale e della PNL negli ultimi dieci anni possiamo vedere come ChatGPT “sta sulle spalle dei giganti”. I modelli precedenti imparavano prima a identificare il significato delle parole. Quindi i modelli successivi mettono insieme queste parole e potremmo addestrarli a svolgere compiti come la traduzione. Una volta che hanno potuto elaborare le frasi, abbiamo sviluppato tecniche che hanno consentito a questi modelli linguistici di elaborare sempre più testo e di sviluppare la capacità di applicare questi apprendimenti a compiti nuovi e imprevisti. E poi, con ChatGPT abbiamo finalmente sviluppato la capacità di interagire meglio con questi modelli specificando le nostre istruzioni in un formato di linguaggio naturale.
“Poiché il linguaggio è il veicolo dei nostri pensieri, insegnare ai computer tutto il potere del linguaggio porterà a un’intelligenza artificiale indipendente?”
Tuttavia, l’evoluzione della PNL rivela una magia più profonda alla quale di solito siamo ciechi: la magia del linguaggio stesso e di come noi, come esseri umani, lo acquisiamo.
Ci sono ancora molte domande e controversie aperte su come i bambini apprendono la lingua. Ci sono anche domande sull'esistenza di una struttura sottostante comune a tutte le lingue. Gli esseri umani si sono evoluti per usare il linguaggio o è il contrario?
La cosa curiosa è che, man mano che ChatGPT e i suoi discendenti migliorano il loro sviluppo linguistico, questi modelli possono aiutare a rispondere ad alcune di queste importanti domande.
Infine, poiché il linguaggio è il veicolo dei nostri pensieri, insegnare ai computer tutto il potere del linguaggio porterà a un’intelligenza artificiale indipendente? Come sempre nella vita, c’è ancora tanto da imparare.
