
Hacking The Topic Graph con Wikipedia e l'API di Google Language
Pubblicato: 2019-08-27Uno dei miei slide deck preferiti degli ultimi dieci anni è stato realizzato da Mark Johnstone nel 2014, mentre era ancora con Distilled. Il mazzo si chiamava Come produrre idee di contenuti migliori e l'ho usato come la mia Bibbia per alcuni anni mentre creavo team per fare il duro lavoro di promozione dei contenuti.
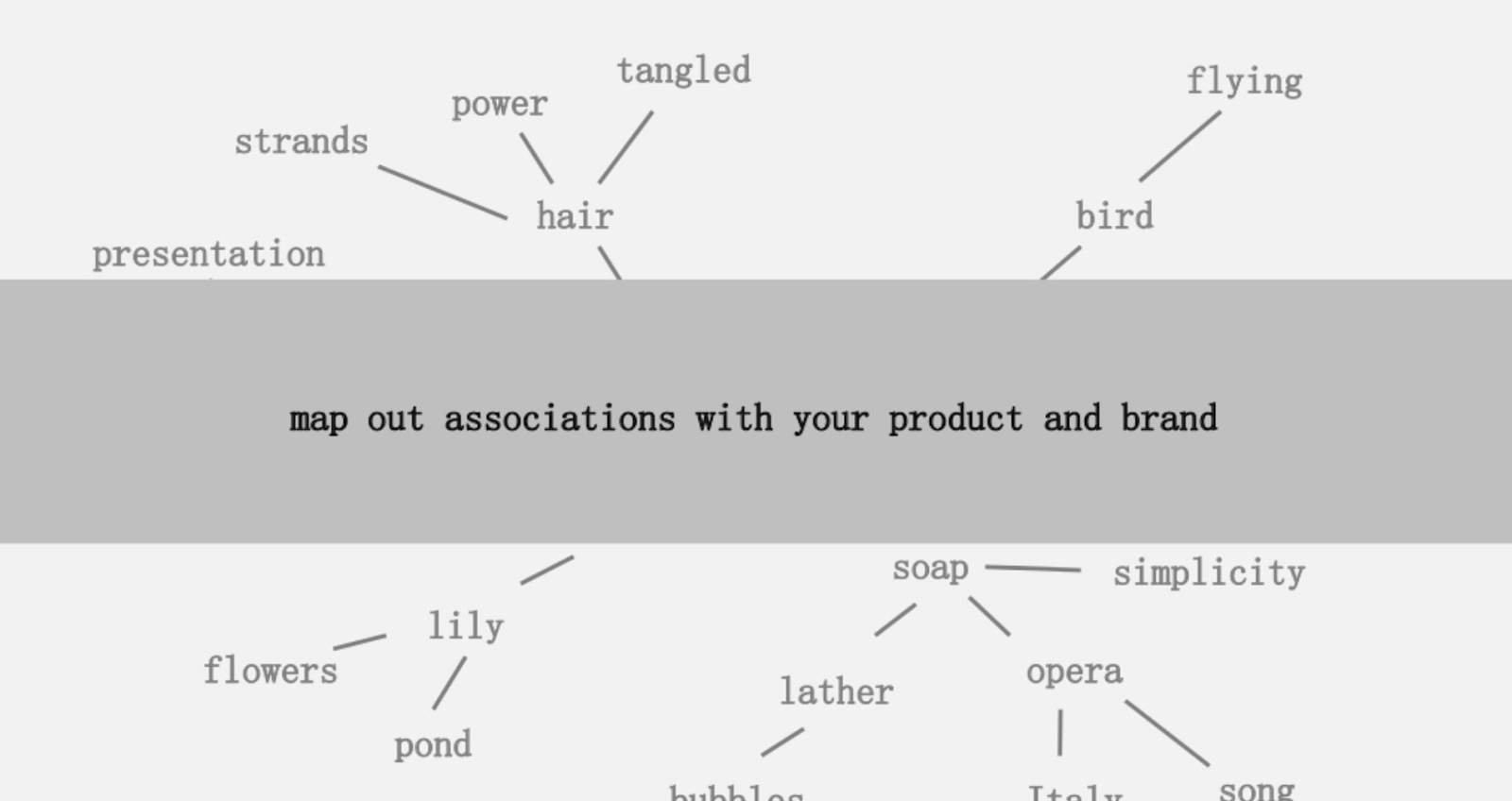
Una delle idee offerte era quella di creare una mappatura visiva della connessione delle parole associate al tuo prodotto o marchio in modo da poter fare un passo indietro e cercare modi per combinare le associazioni in qualcosa di interessante. L'obiettivo è la produzione di idee, che definisce come " una nuova combinazione di elementi precedentemente scollegati in un modo che aggiunge valore".
In questo articolo, adottiamo un approccio molto più del cervello sinistro, utilizzando Python, l'API del linguaggio di Google, insieme a Wikipedia, per esplorare le associazioni di entità che esistono da un argomento seed. L'obiettivo è una visione di alto livello delle relazioni tra entità lungo il grafico dell'argomento. Questo articolo non è per il lettore medio. I lettori che hanno familiarità con Python e hanno almeno un livello base di capacità di programmazione lo troveranno molto più istruttivo.
L'idea
Seguendo l'idea di mappatura di Mark Johnstone, ho pensato che sarebbe stato interessante lasciare che Google e Wikipedia definissero una struttura di argomenti partendo da un argomento seme o da una pagina web. L'obiettivo è costruire visivamente la mappatura delle relazioni con l'argomento principale, in un grafico ad albero che può essere rivisto per cercare connessioni ed eventualmente generare idee di contenuto. L'immagine seguente rappresenta l'idea progettuale iniziale.
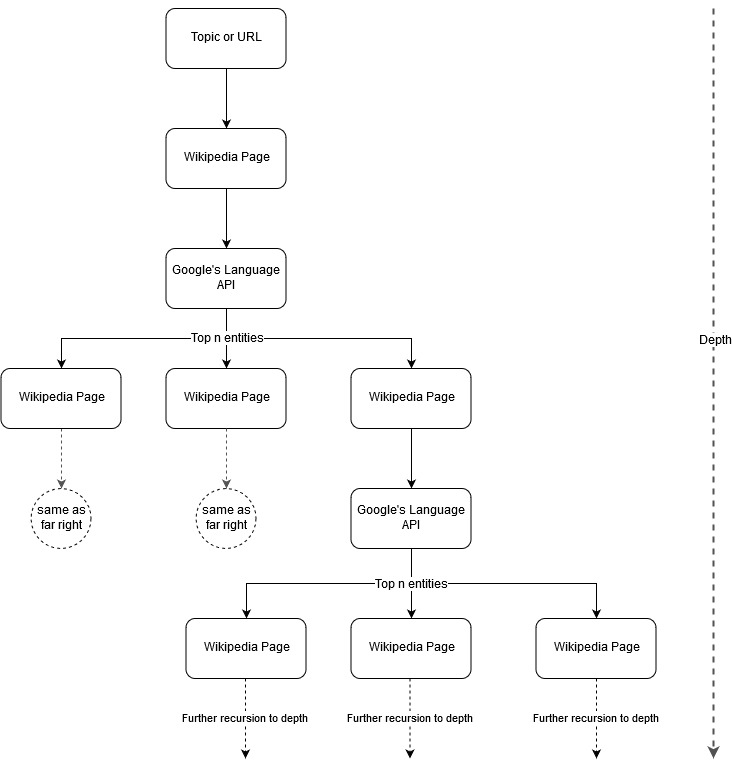
In sostanza, diamo allo strumento un argomento o un URL e lasciamo che l'API Language di Google selezioni le prime n (3 nei nostri esempi) entità (che includono gli URL di Wikipedia) per ciascuna pagina di entità e continuiamo a costruire ricorsivamente un grafico di rete per ciascuna entità trovata fino ad una profondità massima.
Sfondo degli strumenti utilizzati
API della lingua di Google
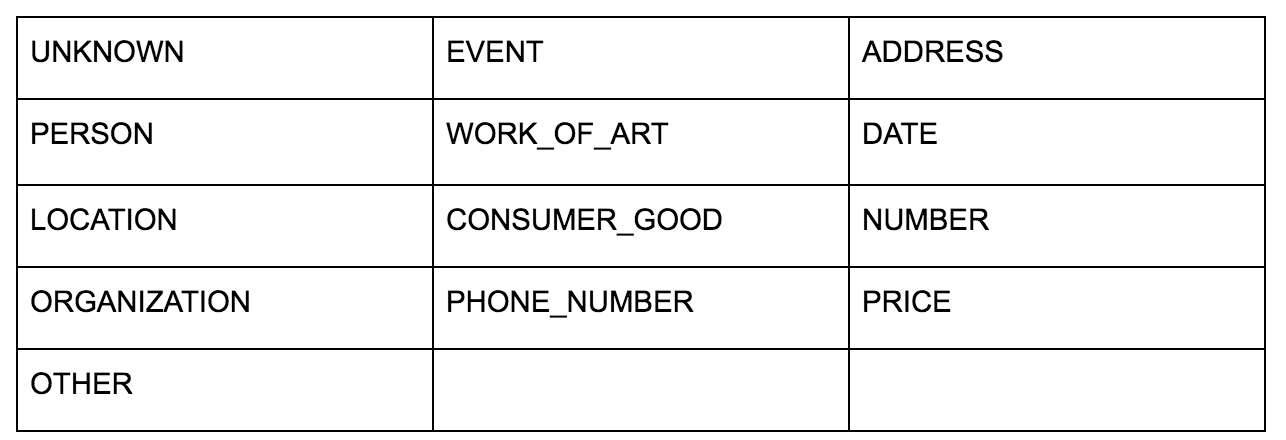
L'API della lingua di Google ti consente di passarlo in testo normale o HTML e restituisce magicamente tutte le varie entità associate al contenuto. L'API fa di più, ma per questa analisi ci concentreremo solo su questa parte. Ecco un elenco dei tipi di entità che restituisce:
L'identificazione dell'entità è stata per molto tempo una parte fondamentale del Natural Language Processing (NLP) e la terminologia corretta per l'attività è Named Entity Recognition (NER). NER è un compito difficile perché molte parole hanno significati diversi in base al contesto utilizzato, quindi gli strumenti o le API NLP devono comprendere l'intero contesto che circonda i termini per essere in grado di identificarli correttamente come entità particolare.
Ho fornito una panoramica piuttosto dettagliata di questa API, e delle entità in particolare, in un articolo su opensource.com se vuoi recuperare un po' di contesto prima di finire questo articolo.
Una caratteristica interessante dell'API Language di Google è, oltre a trovare entità rilevanti, segna anche quanto sono correlate al documento generale (rilevanza) e, per alcuni, fornisce un articolo correlato di Wikipedia (grafico della conoscenza) che rappresenta l'entità.
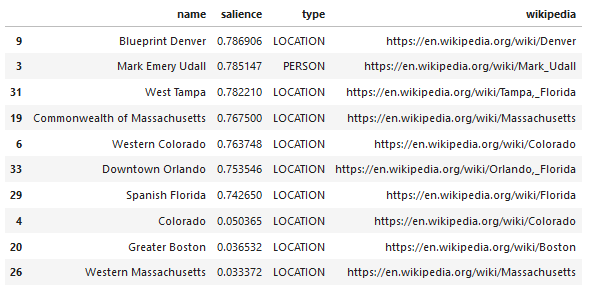
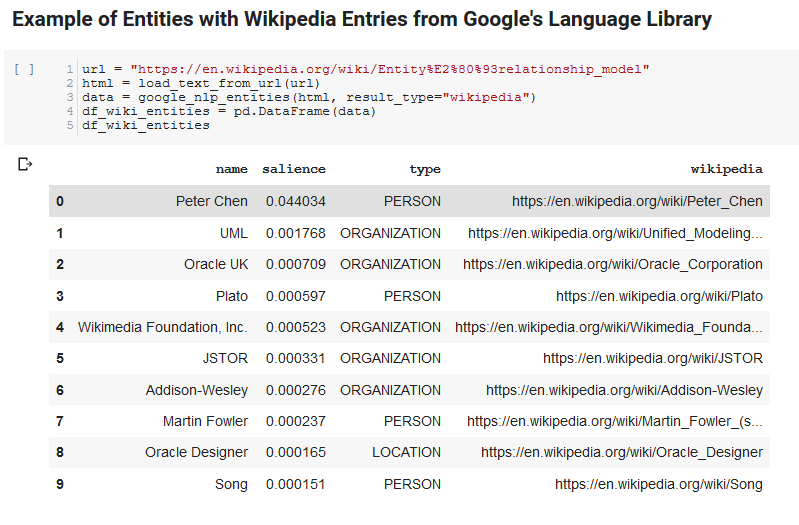
Ecco un esempio di output di ciò che l'API restituisce (ordinato per salienza):
Sviluppatore in scansione
 Per saperne di più
Per saperne di piùPitone
Python è un linguaggio software che è diventato popolare nello spazio della scienza dei dati grazie a un insieme ampio e in crescita di librerie che semplificano l'acquisizione, la pulizia, la manipolazione e l'analisi di insiemi di dati di grandi dimensioni. Beneficia anche di un ambiente collaborativo chiamato Jupyter notebook che consente agli utenti di testare e annotare facilmente il proprio codice in modo semplice.
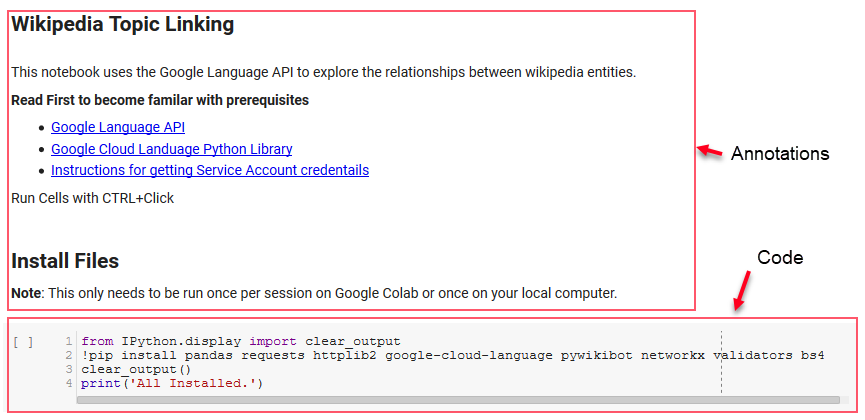
Per questa recensione, utilizzeremo alcune librerie di chiavi che ci consentiranno di fare alcune cose interessanti con i dati NLP di Google.
- Panda: pensa di essere in grado di eseguire uno script di Microsoft Excel per leggere, salvare, analizzare o riorganizzare i fogli di calcolo e avrai un'idea di cosa fa Panda. I panda sono fantastici. (collegamento)
- Networkx: Networkx è uno strumento per la costruzione di grafici di nodi e bordi che definiscono le relazioni tra i nodi. Ha anche un supporto integrato per tracciare i grafici in modo che siano facili da visualizzare. (collegamento)
- Pywikibot: Pywikibot è una libreria che ti permette di interagire con Wikipedia per cercare, modificare, trovare relazioni, ecc., con tutto il contenuto di ogni sito Wikipedia. (collegamento)
Il processo
Condividiamo qui un taccuino di Google Colab che può essere utilizzato per seguire. (Un ringraziamento speciale a Tyler Reardon per un controllo di integrità dell'articolo e di questo taccuino.)
Impostare
Le prime poche celle del notebook si occupano dell'installazione di alcune librerie, della messa a disposizione di tali librerie per Python e della fornitura di credenziali e file di configurazione rispettivamente per l'API Language di Google e Pywikibot. Ecco tutte le librerie che dobbiamo installare per garantire che lo strumento possa essere eseguito:
- panda
- richieste
- httplib2
- google-cloud-linguaggio
- pywikibot
- retex
- validatori
- Bs4
Nota: la parte più difficile di poter eseguire questo notebook è ottenere le credenziali da Google per accedere alle loro API. Per chi non ha esperienza con questo, ci vorrà circa un'ora per capirlo. Abbiamo collegato le Istruzioni per ottenere le credenziali dell'account di servizio nella parte superiore del taccuino per aiutarti. Di seguito è riportato un esempio di come abbiamo incluso il nostro.
Funzioni per la vittoria
Nella cella indicata da "Definisci alcune funzioni per Google NLP", sviluppiamo otto funzioni che gestiscono cose come l'interrogazione dell'API del linguaggio, l'interazione con Wikipedia, l'estrazione del testo della pagina Web e la creazione e la stampa di grafici. Le funzioni sono essenzialmente piccole unità di codice che raccolgono alcuni dati delle impostazioni, svolgono un po' di lavoro e producono qualcosa. Tutte le funzioni sono commentate per indicare le variabili che prendono e cosa producono.

Testare l'API
Le due celle seguenti prendono un URL, estraggono il testo dall'URL ed estraggono le entità dall'API Language di Google. Uno estrae solo le entità che hanno URL di Wikipedia e l'altro estrae tutte le entità da quella pagina.
Questo è stato un primo passo importante solo per correggere la parte di estrazione del contenuto e capire come funzionava l'API Language e come restituiva i dati.
Retex
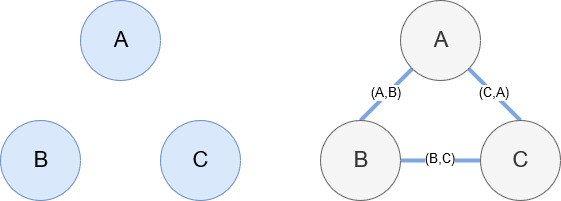
Networkx, come accennato in precedenza, è una meravigliosa libreria con cui è abbastanza intuitivo giocare. In sostanza, devi dirgli quali sono i tuoi nodi e come sono collegati i nodi. Ad esempio, nell'immagine seguente, diamo a Networkx tre nodi (A,B,C). Diciamo quindi a Networkx che sono collegati da archi (A,B), (B,C), (C,A) che definiscono le relazioni tra i nodi. Per il nostro utilizzo, le entità con gli URL di Wikipedia saranno i nodi e gli spigoli saranno definiti da nuove entità trovate su una pagina dell'entità corrente. Quindi, se stiamo esaminando la pagina di Wikipedia per l'Entità A, e in quella pagina viene scoperta l'Entità B, allora quello è un margine tra l'Entità A e l'Entità B.
Mettere tutto insieme
La sezione successiva del quaderno si chiama Wikipedia Topic Branching by URL. Qui è dove avviene la magia. In precedenza avevamo definito una funzione speciale (recurse_entities) che ricorre nelle pagine di Wikipedia seguendo le nuove entità definite dall'API del linguaggio di Google. Abbiamo anche aggiunto una funzione davvero difficile da capire (hierarchy_pos) che abbiamo preso da Stack Overflow che fa un buon lavoro nel presentare un grafico ad albero con molti nodi. Nella cella sottostante, definiamo l' input come "Ottimizzazione per i motori di ricerca" e specifichiamo una profondità di 3 (questo è il numero di pagine che segue in modo ricorsivo) e un limite di 3 (questo è il numero di entità che estrae per pagina).
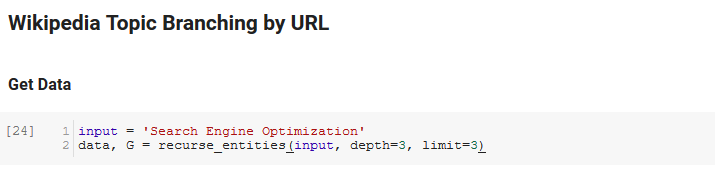
Eseguendolo per il termine "Ottimizzazione per i motori di ricerca" possiamo vedere il seguente percorso intrapreso dallo strumento, partendo dalla pagina di Ottimizzazione per i motori di ricerca di Wikipedia (Livello 0) e seguendo, ricorsivamente, le pagine fino alla profondità massima specificata (3).

Quindi prendiamo tutte le entità trovate e le aggiungiamo a un Pandas DataFrame, il che rende davvero facile il salvataggio come CSV. Ordiniamo questi dati per salienza (che è quanto è importante l'entità per la pagina in cui è stata trovata), ma questo punteggio è un po' fuorviante in questo contesto perché non ti dice quanto sia correlata l'entità al tuo termine originale (" Ottimizzazione del motore di ricerca"). Lasceremo questo ulteriore lavoro al lettore.

Infine, tracciamo il grafico costruito dallo strumento per mostrare la connessione di tutte le entità. Nella cella sottostante, i parametri che puoi passare alla funzione sono: ( G : il Grafico costruito prima dalla funzione recurse_entities, w: la larghezza del grafico, h: l'altezza del grafico, c: la percentuale circolare del grafico plot e filename: il file PNG che viene salvato nella cartella images.)

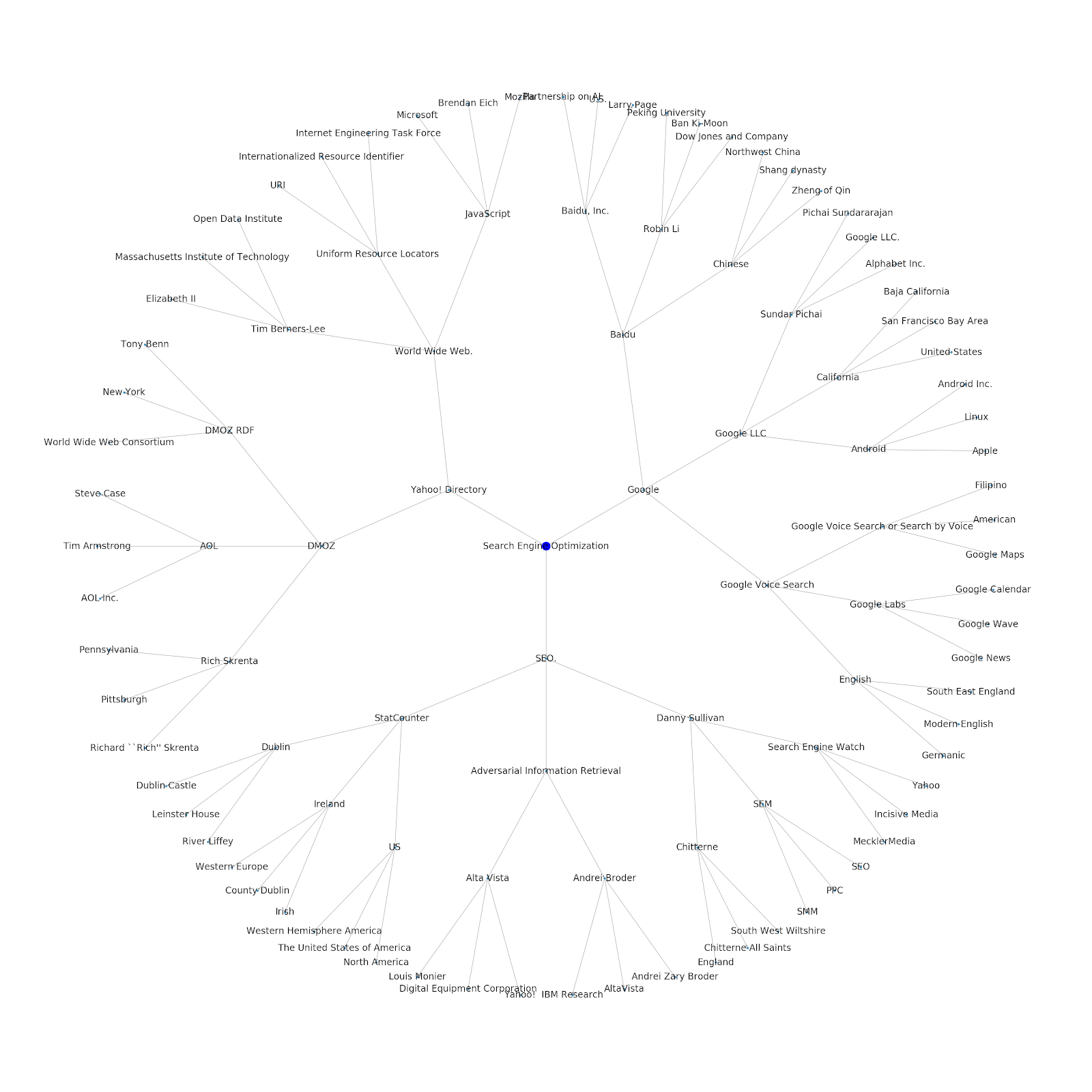
Abbiamo aggiunto la possibilità di assegnargli un argomento seed o un URL seed. In questo caso, esaminiamo le entità associate all'articolo I problemi di indicizzazione di Google continuano ma questo è diverso
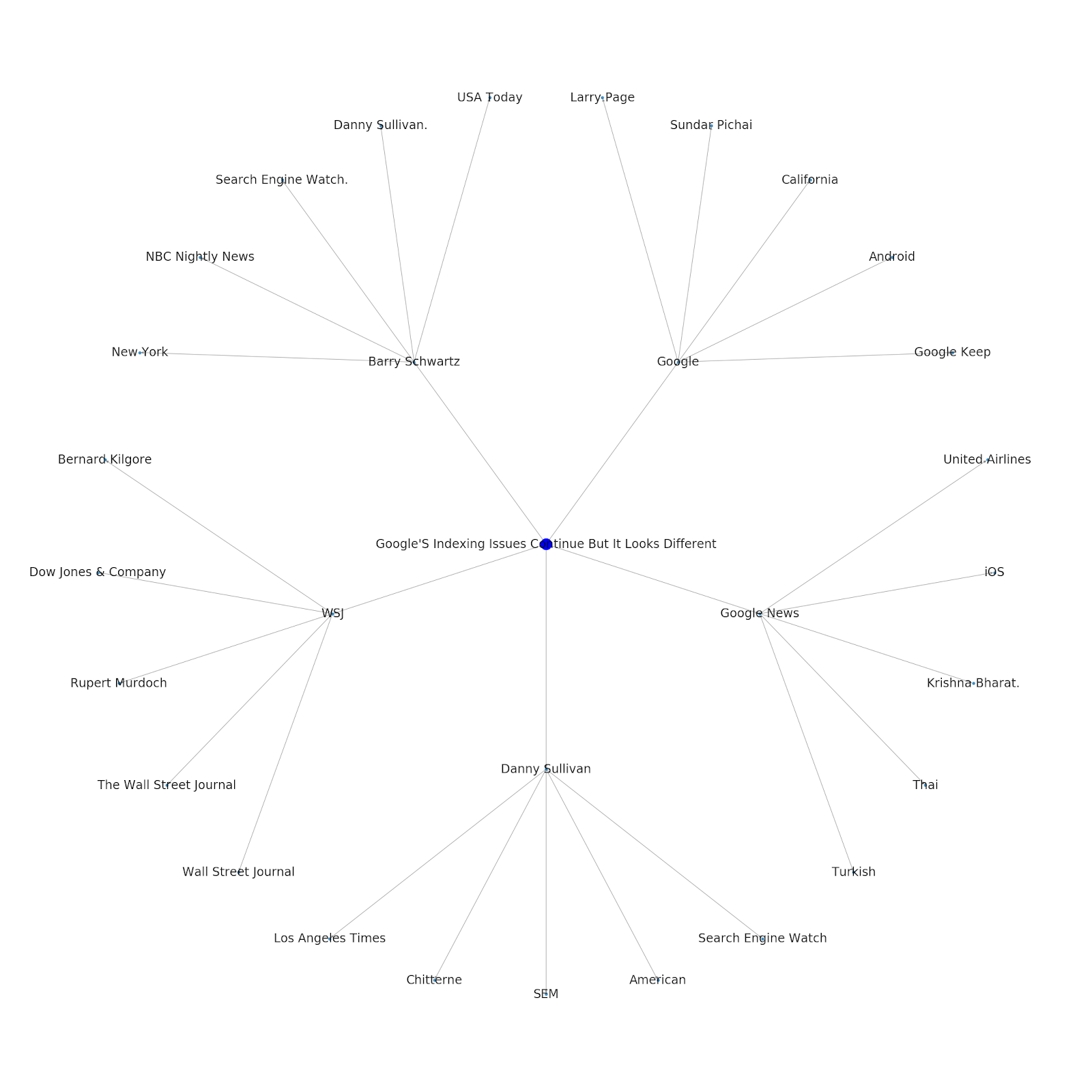
Ecco il grafico dell'entità di Google/Wikipedia per Python.
Cosa significa
Comprendere il livello tematico di Internet è interessante dal punto di vista SEO perché ti costringe a pensare in termini di come le cose sono collegate e non solo su singole query. Poiché Google utilizza questo livello per abbinare le affinità dei singoli utenti agli argomenti, come menzionato nella reintroduzione di Google Discover, potrebbe diventare un flusso di lavoro più importante per i SEO incentrati sui dati. Nel grafico "Python" sopra, si può dedurre che la familiarità di un utente con gli argomenti relativi a un argomento seed può essere un indicatore ragionevole del suo livello di esperienza con l'argomento seed.
L'esempio seguente mostra due utenti con i punti salienti in verde che mostrano il loro interesse storico o l'affinità con argomenti correlati. L'utente a sinistra, comprendendo cos'è un IDE e comprendendo cosa significano PyPy e CPython, sarebbe un utente molto più esperto con Python, rispetto a qualcuno che sa che è un linguaggio, ma non molto altro. Questo sarebbe facile da trasformare in punteggi numerici per ogni argomento, per ogni utente.

Conclusione
Il mio obiettivo oggi era condividere quello che è un processo piuttosto standard che ho seguito per testare e rivedere l'efficacia di vari strumenti o API utilizzando Jupyter Notebooks. L'esplorazione del grafico dell'argomento è incredibilmente interessante e ci auguriamo che tu possa trovare gli strumenti condivisi che ti diano il vantaggio di cui hai bisogno per iniziare a esplorare da solo. Con questi strumenti puoi creare grafici di argomenti che esplorano molti livelli di relazione, limitati solo all'estensione della quota dell'API Language di Google (che è 800.000 al giorno). (Aggiornamento: il prezzo si basa su unità di 1.000 caratteri unicode inviati all'API ed è gratuito fino a 5.000 unità. Poiché gli articoli di Wikipedia possono diventare lunghi, è necessario tenere d'occhio la spesa. Un consiglio a John Murch per averlo sottolineato.) Se migliori il taccuino o trovi custodie interessanti, spero che me lo farai sapere. Puoi trovarmi su @jroakes su Twitter.