
Le chiavi per costruire un Robots.txt che funzioni
Pubblicato: 2020-02-18I bot, noti anche come Crawler o Spider, sono programmi che "viaggiano" attraverso il Web automaticamente da un sito Web all'altro utilizzando i collegamenti come strada. Nonostante abbiano sempre presentato alcune curiosità, i file robot.txt possono essere strumenti molto efficaci. I motori di ricerca come Google e Bing utilizzano i bot per eseguire la scansione dei contenuti del Web. Il file robots.txt fornisce indicazioni ai diversi bot su quali pagine non dovrebbero eseguire la scansione del tuo sito. Puoi anche collegarti alla tua mappa del sito XML da robots.txt in modo che il bot abbia una mappa di ogni pagina che dovrebbe scansionare.
Perché robots.txt è utile?
robots.txt limita la quantità di pagine di cui un bot ha bisogno per eseguire la scansione e l'indicizzazione nel caso dei bot dei motori di ricerca. Se vuoi evitare che Google esegua la scansione delle pagine di amministrazione, puoi bloccarle sul tuo robots.txt per provare a mantenere una pagina fuori dai server di Google.
Oltre a impedire che le pagine vengano indicizzate, robots.txt è ottimo per ottimizzare il crawl budget. Il budget di scansione è il numero di pagine di cui Google ha determinato la scansione del tuo sito. Di solito i siti Web con più autorità e più pagine hanno un budget di scansione maggiore rispetto ai siti Web con un numero ridotto di pagine e un'autorità bassa. Dal momento che non sappiamo quanto budget di scansione è assegnato al nostro sito, vogliamo sfruttare al meglio questo tempo consentendo a Googlebot di accedere alle pagine più importanti invece di eseguire la scansione delle pagine che non vogliamo vengano indicizzate.
Un dettaglio molto importante che devi sapere su robots.txt è che mentre Google non eseguirà la scansione delle pagine bloccate da robots.txt, possono comunque essere indicizzate se la pagina è collegata da un altro sito web. Per evitare che le tue pagine vengano indicizzate e visualizzate nei risultati della Ricerca Google, devi proteggere con password i file sul tuo server, utilizzare il meta tag noindex o l'intestazione della risposta o rimuovere completamente la pagina (rispondi con 404 o 410). Per ulteriori informazioni sulla scansione e sul controllo dell'indicizzazione, puoi leggere la guida robots.txt di OnCrawl.
[Case Study] Gestione della scansione dei bot di Google
 Leggi il caso di studio
Leggi il caso di studioSintassi corretta di Robots.txt
La sintassi robots.txt a volte può essere un po' complicata, poiché diversi crawler interpretano la sintassi in modo diverso. Inoltre, alcuni crawler non affidabili vedono le direttive robots.txt come suggerimenti e non come una regola definita da seguire. Se disponi di informazioni riservate sul tuo sito, è importante utilizzare la protezione tramite password oltre a bloccare i crawler utilizzando il file robots.txt
Di seguito ho elencato alcune cose che devi tenere a mente quando lavori sul tuo robots.txt:
- Il file robots.txt deve risiedere nel dominio e non in una sottodirectory. I crawler non controllano la presenza di file robots.txt nelle sottodirectory.
- Ogni sottodominio ha bisogno del proprio file robots.txt:
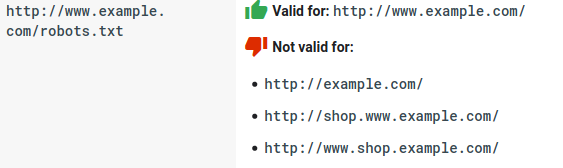
- Robots.txt fa distinzione tra maiuscole e minuscole:
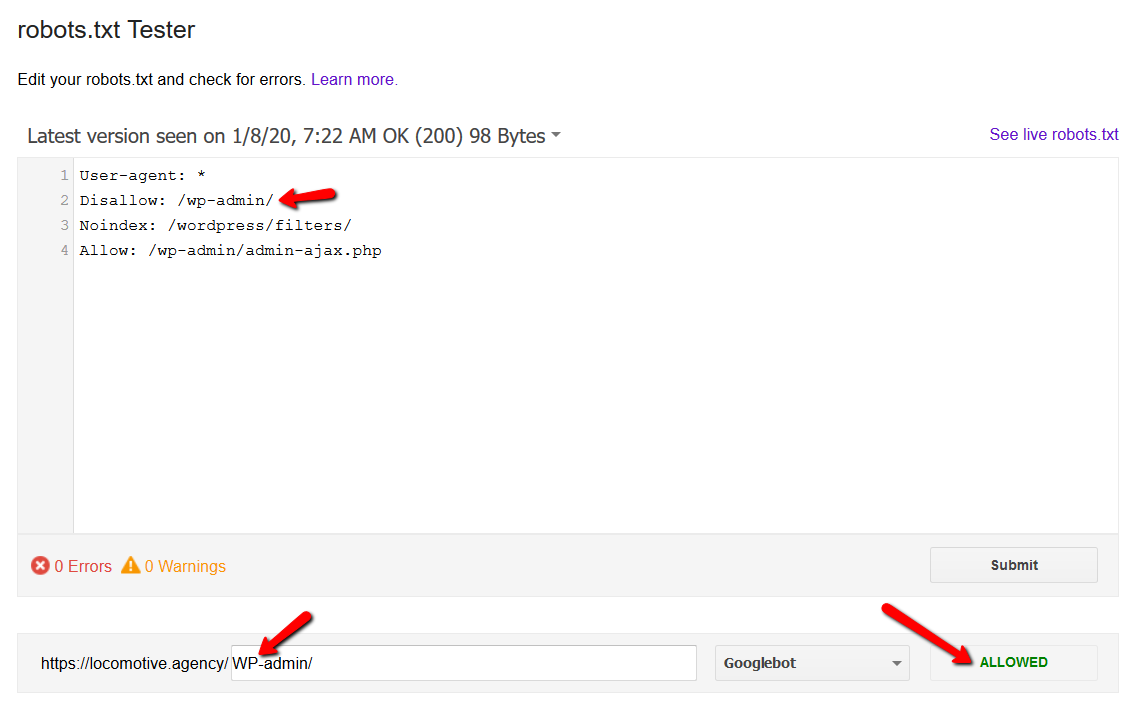
- La direttiva noindex: quando usi noindex nel robots.txt, funzionerà allo stesso modo di disallow. Google interromperà la scansione della pagina ma la manterrà nel suo indice. @jroakes e io abbiamo creato un test in cui abbiamo utilizzato la direttiva Noindex sull'articolo /wordpress/filters/ e inviato la pagina a Google. Puoi vedere nello screenshot qui sotto che mostra che l'URL è stato bloccato:
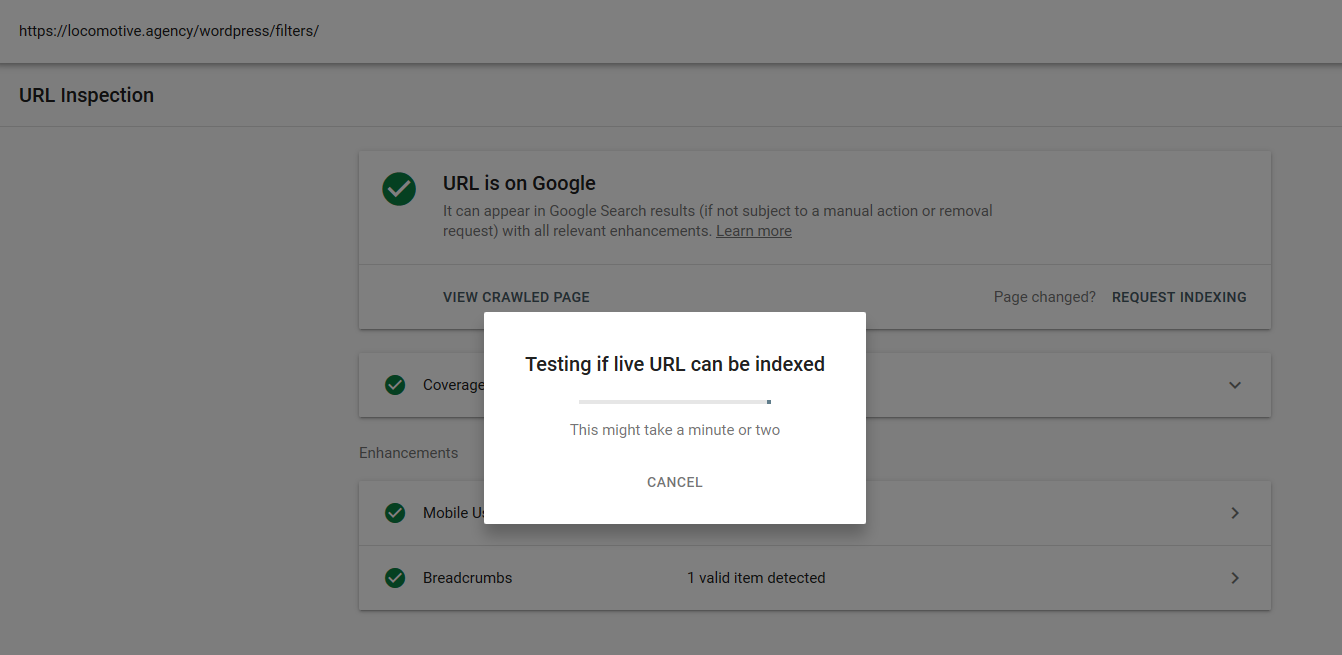
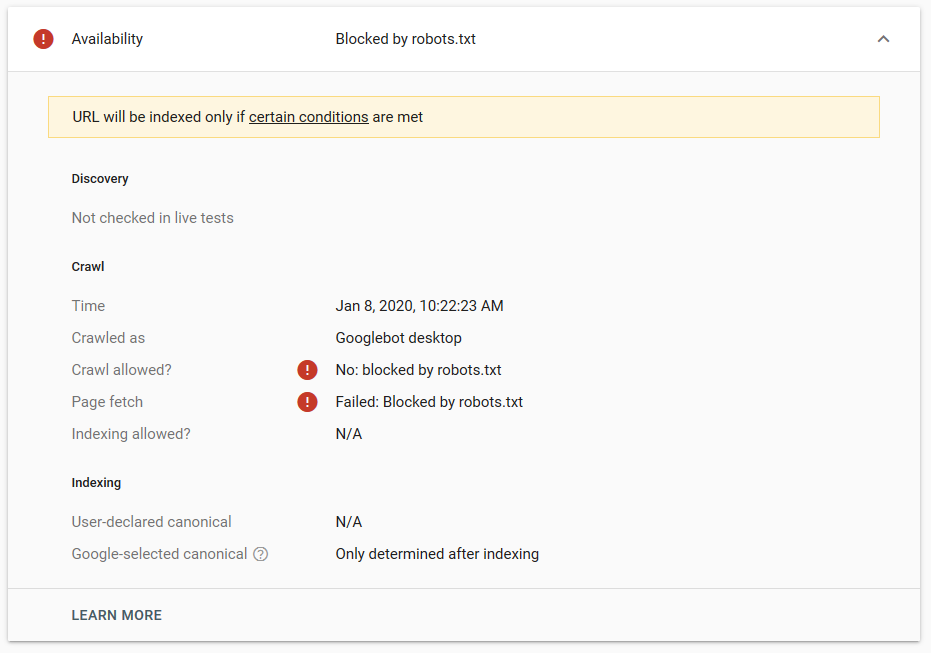
Abbiamo fatto diversi test su Google e la pagina non è mai stata rimossa dall'indice:

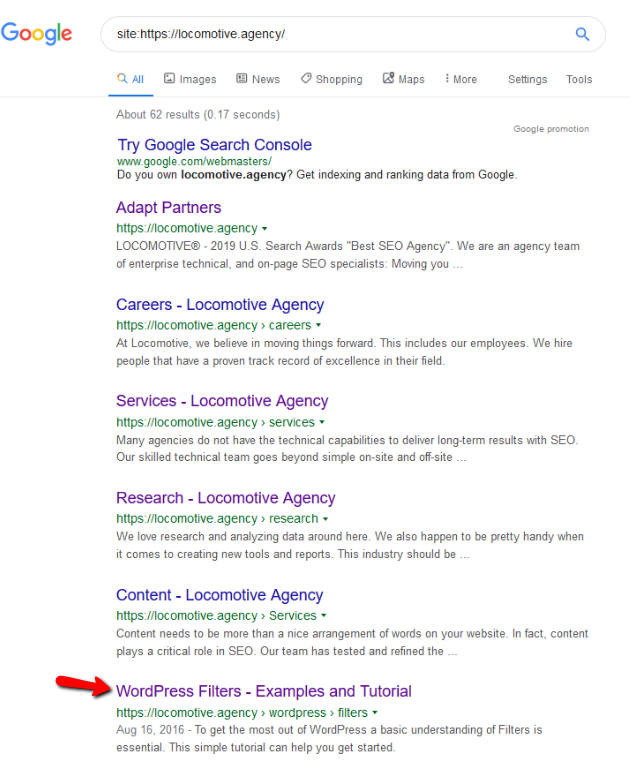
L'anno scorso c'è stata una discussione sulla direttiva noindex che funzionava nel robots.txt, rimuovendo le pagine tranne Google. Ecco un thread in cui Gary Illyes ha affermato che sarebbe andato via. In questo test possiamo vedere che la soluzione di Google è a posto, poiché la direttiva noindex non ha rimosso la pagina dai risultati di ricerca.
Di recente, c'è stato un altro thread interessante su Twitter di Christian Oliveira, in cui ha condiviso diversi dettagli da tenere in considerazione quando si lavora su robots.txt.
- Se vogliamo avere regole generiche e regole solo per Googlebot, dobbiamo duplicare tutte le regole generiche sotto User-agent: Google bot set di regole. Se non sono inclusi, Googlebot ignorerà tutte le regole:

- Un altro comportamento confuso è che la priorità delle regole (all'interno dello stesso gruppo User-agent) non è determinata dal loro ordine, ma dalla lunghezza della regola.
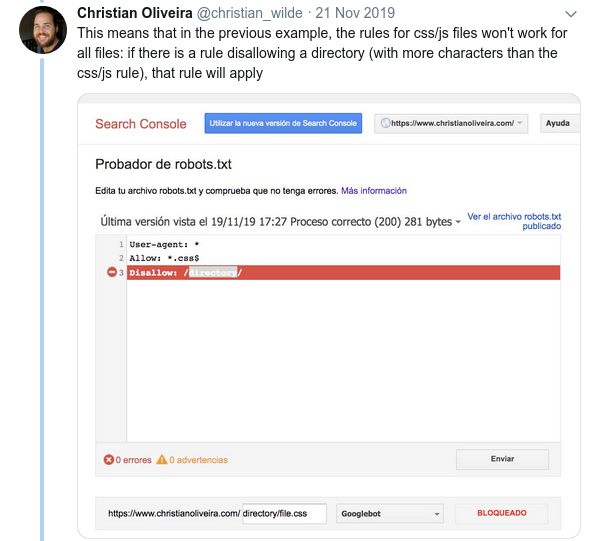
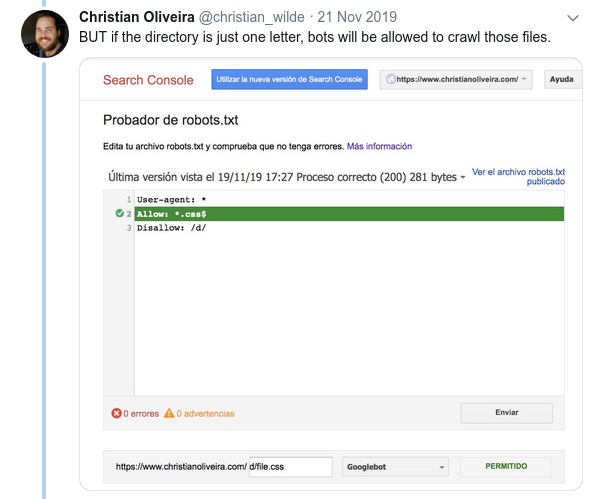
- Ora, quando hai due regole, con la stessa lunghezza e comportamento opposto (una che consente la scansione e l'altra che non la consente), si applica la regola meno restrittiva:
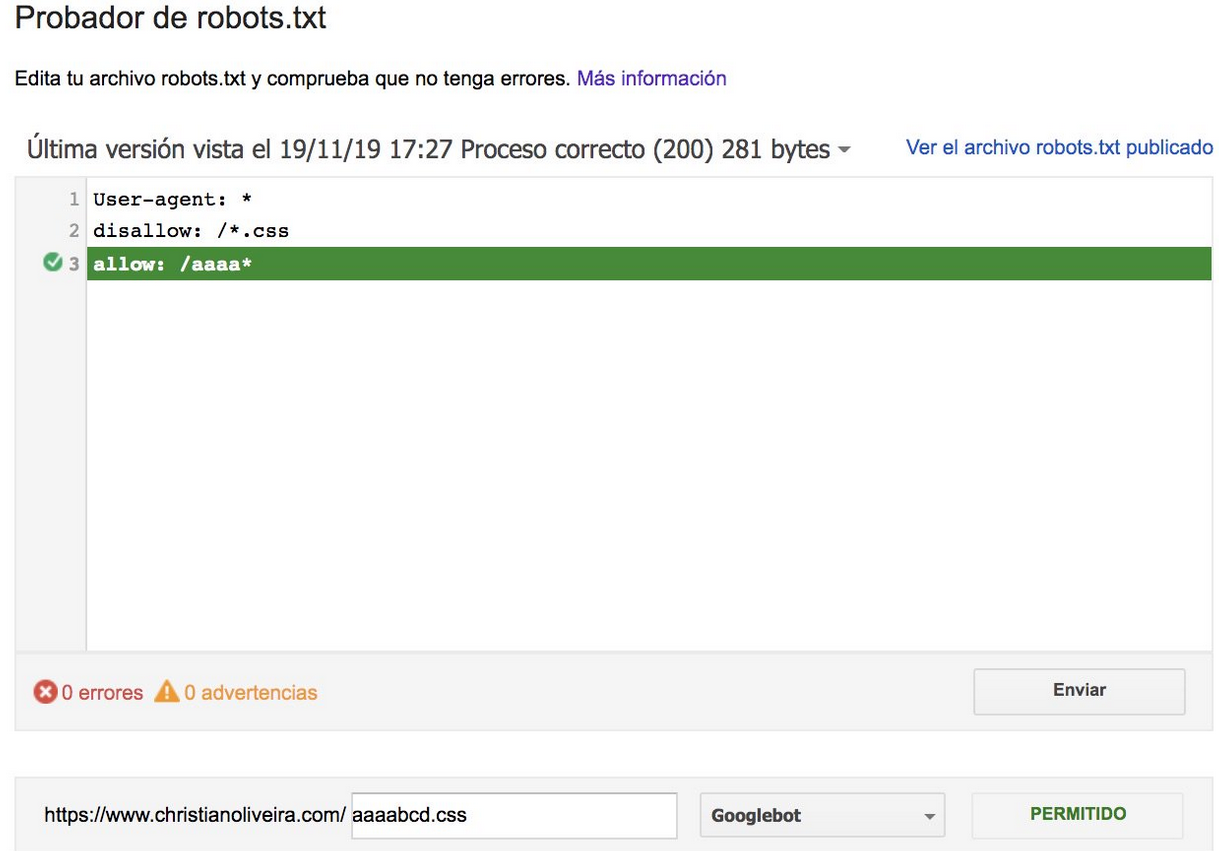
Per ulteriori esempi, leggi le specifiche robots.txt fornite da Google.
Strumenti per testare il tuo Robots.txt
Se vuoi testare il tuo file robots.txt, ci sono diversi strumenti che possono aiutarti e anche un paio di repository github se vuoi crearne uno tuo:
- Distillato
- Google ha lasciato qui lo strumento tester robots.txt dalla vecchia Google Search Console
- Su Python
- In C++
Risultati di esempio: uso efficace di un Robots.txt per l'e-commerce
Di seguito ho incluso un caso in cui stavamo lavorando con un sito Magento che non aveva un file robots.txt. Magento e altri CMS hanno pagine e directory di amministrazione con file di cui non vogliamo che Google esegua la scansione. Di seguito, abbiamo incluso un esempio di alcune delle directory che abbiamo incluso nel robots.txt:
# # Directory generali di Magento Non consentire: / app / Non consentire: / downloader / Non consentire: / errori / Non consentire: / include / Non consentire: /lib / Non consentire: / pkginfo / Non consentire: / shell / Non consentire: / var / # # Non indicizza la pagina di ricerca e le categorie di link non ottimizzate Non consentire: /catalog/product_compare/ Non consentire: /catalog/categoria/visualizza/ Non consentire: /catalog/product/view/ Non consentire: /catalog/product/gallery/ Non consentire: /catalogsearch/
L'enorme quantità di pagine che non dovevano essere sottoposte a scansione influiva sul budget di scansione e Googlebot non riusciva a eseguire la scansione di tutte le pagine dei prodotti sul sito.
Puoi vedere nell'immagine qui sotto come le pagine indicizzate sono aumentate dopo il 25 ottobre, quando è stato implementato il robots.txt:
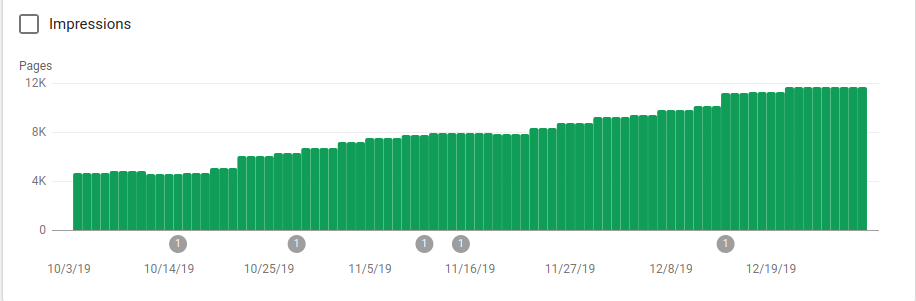
Oltre a bloccare diverse directory che non dovevano essere sottoposte a scansione, i robot includevano un collegamento alle mappe del sito. Nello screenshot qui sotto puoi vedere come il numero di pagine indicizzate è aumentato rispetto alle pagine escluse:
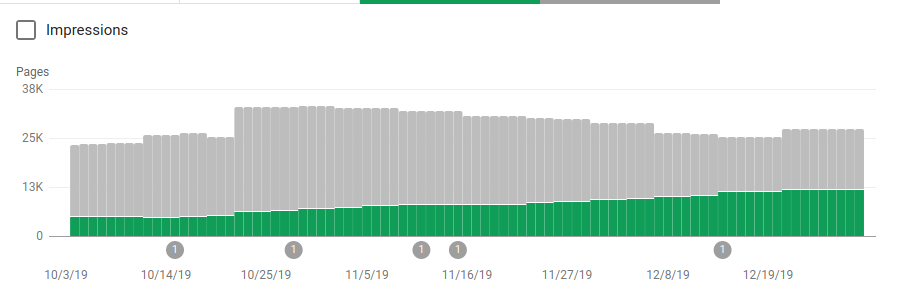
C'è un andamento positivo sulle pagine valide indicizzate come mostrato dalle barre verdi e un andamento negativo sulle pagine escluse rappresentate dalle barre grigie.
Avvolgendo
L'importanza di robots.txt a volte può essere sottovalutata e come puoi vedere da questo post ci sono molti dettagli che devono essere considerati quando ne crei uno. Ma il lavoro ripaga: ho mostrato alcuni dei risultati positivi che puoi ottenere impostando correttamente un robots.txt.