
Perché siamo passati all'elaborazione serverless per distribuire build personalizzate
Pubblicato: 2018-11-22
Foto di panumas nikhomkhai di Pexels
Nell'ambito del nostro impegno a consentire ai professionisti del marketing delle prestazioni di fare di più, con meno, senza preoccupazioni , i team di TUNE sono sempre alla ricerca di nuovi modi per servire i nostri clienti. In questo caso, il nostro team di Solutions Engineering ha scoperto una tecnologia che semplifica il modo in cui implementano e supportano build personalizzate sulla nostra piattaforma. Di conseguenza, ora possono dedicare più tempo (e meno denaro) a lavorare con più clienti per creare le soluzioni di cui hanno bisogno.
In TUNE, siamo orgogliosi di fornire una piattaforma di performance marketing flessibile e completa che consente alle reti e agli inserzionisti di gestire le loro campagne di marketing digitale, le relazioni con gli editori, i pagamenti e altro ancora, immediatamente, senza dover scrivere una singola riga di codice . Ma a volte, come con altri sistemi SaaS completamente gestiti, i nostri clienti richiedono configurazioni, funzionalità o integrazioni personalizzate che possono essere ottenute solo rimboccandosi le maniche e attivando il vecchio editor di codice. Di recente, siamo passati a una nuova tecnologia che sta cambiando il modo in cui costruiamo queste soluzioni: l'elaborazione serverless.
In questo post, illustrerò i problemi che abbiamo riscontrato con lo sviluppo personalizzato, i passaggi che abbiamo adottato per impostare il nostro processo di creazione serverless e come questa nuova metodologia sta risolvendo le sfide di costi e scalabilità.
Sfida: tenere il passo con la domanda di soluzioni personalizzate
Quando abbiamo avviato per la prima volta il team di Solutions Engineering presso TUNE, abbiamo trattato ogni build personalizzata del cliente come una build separata. La maggior parte di queste build aveva un componente front-end, che di solito veniva distribuito come pagina personalizzata sulla nostra piattaforma, e un componente back-end che consisteva in un server, un database e qualsiasi altra infrastruttura richiesta per mantenere i server aggiornati -data e operativo.
All'inizio, questa metodologia ha funzionato per noi. Avendo un team piccolo e snello con alcune build personalizzate complesse, il nostro metodo di provisioning e configurazione di un server diverso per ogni build ha funzionato per noi. Ci ha permesso di creare esperienze straordinarie per i nostri clienti.
Ma man mano che il numero di build cresceva, iniziavamo a riscontrare problemi:
- Troppi server! Come puoi immaginare, il provisioning di un minimo di due box per build ci ha portato ad avere troppi server. L'enorme numero di server e tutti i problemi che li accompagnano (come aggiornamenti di sicurezza e backup) ci stavano costando più tempo di quanto vorremmo ammettere.
- Tieni attivi quei server. Poiché ogni server è una propria entità, era nostra responsabilità assicurarci che ogni server fosse sempre attivo e operativo.
- PHP non fa per me. La maggior parte delle nostre build sono generate da un'immagine Docker PHP di base. Ma man mano che il nostro team cresceva, sapevamo che costringere le persone a scrivere le build dei loro clienti in PHP 5.0 quando erano un mago Python non aveva alcun senso.
- Questo sta diventando costoso. Con tutti i nostri server implementati su ec2/RDS, stavamo iniziando a vedere un costo mensile significativo.
- La sicurezza prima. Poiché questi servizi gestivano i dati sensibili dei clienti, dovevamo fornire un metodo di autenticazione per i nostri URL pubblici per garantire la sicurezza di tali dati.
- I Cron sono duri. Molti servizi di back-end consistevano in script cron e non avevamo un modo efficiente per gestirli.
Con l'emersione di queste sfide, sapevamo di dover trovare un modo più semplice ed economico per fornire funzionalità di back-end alle build dei nostri clienti. Ma dopo un lungo dibattito e senza un chiaro precursore per una soluzione, stavamo iniziando a rimanere a corto di idee. (Inoltre, con la domanda di nuove build personalizzate che cresceva all'impazzata, il tempo non era decisamente dalla nostra parte.)
Soluzione: elaborazione serverless in soccorso
Se non hai sentito parlare di elaborazione serverless , potresti chiederti la stessa cosa che eravamo quando ne abbiamo sentito parlare per la prima volta. Come puoi eseguire codice senza un server? (Non preoccuparti; la tua comprensione fondamentale della programmazione è ancora corretta e no, non abbiamo abusato dell'happy hour speciale prima di scrivere questo.)
"Serverless" è un termine davvero confuso per una nuova tecnologia, perché - non siamo sciocchi - c'è sicuramente ancora un codice che esegue il server. Quindi cos'è esattamente il serverless?
Il serverless computing è un modello di esecuzione del cloud computing in cui il provider cloud funge da server, gestendo dinamicamente l'allocazione delle risorse della macchina. – Wikipedia
Le soluzioni cloud serverless ti consentono di creare ed eseguire applicazioni e servizi senza pensare ai problemi associati ai server. In sostanza, l'elaborazione serverless ti consente di fare ciò che sai fare meglio: scrivere codice.
Il processo di installazione senza server
Per mostrarti l'essenza di come funziona la tecnologia serverless, illustrerò i passaggi che abbiamo utilizzato per impostare questa funzionalità.
Nota: esistono molti provider cloud con funzionalità serverless. In questo esempio, utilizziamo AWS Lambda .

- Innanzitutto, crea una nuova funzione Lambda e seleziona " Blueprints ". Quindi, digita " http " nel campo della parola chiave e seleziona Python o Node microservice-http-endpoint. (I progetti sono blocchi di codice preconfezionati destinati a rendere più veloce lo sviluppo. Quanto è fantastico?) Dopo aver effettuato una selezione, fai clic su " Configura ".
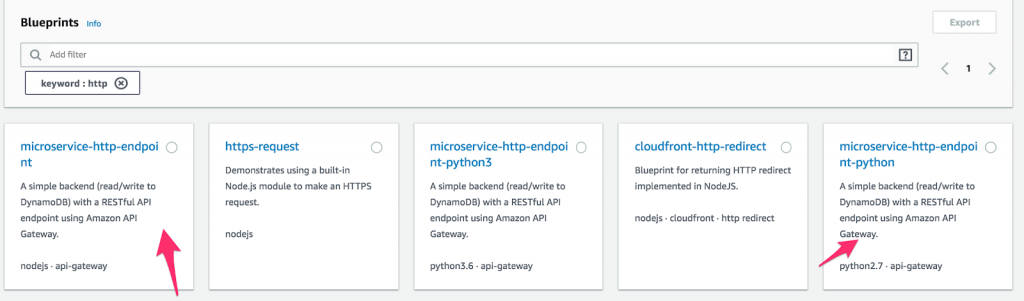
Come configurare una funzione su AWS Lambda.
- Aggiungi un nome e un ruolo di funzione. Quindi seleziona un trigger API Gateway con l'opzione di sicurezza " Apri con chiave API ". Questo gateway API fornirà un URL pubblico che attiverà la tua funzione Lambda. L'aggiunta della chiave API fornisce un metodo di autenticazione altamente raccomandato.
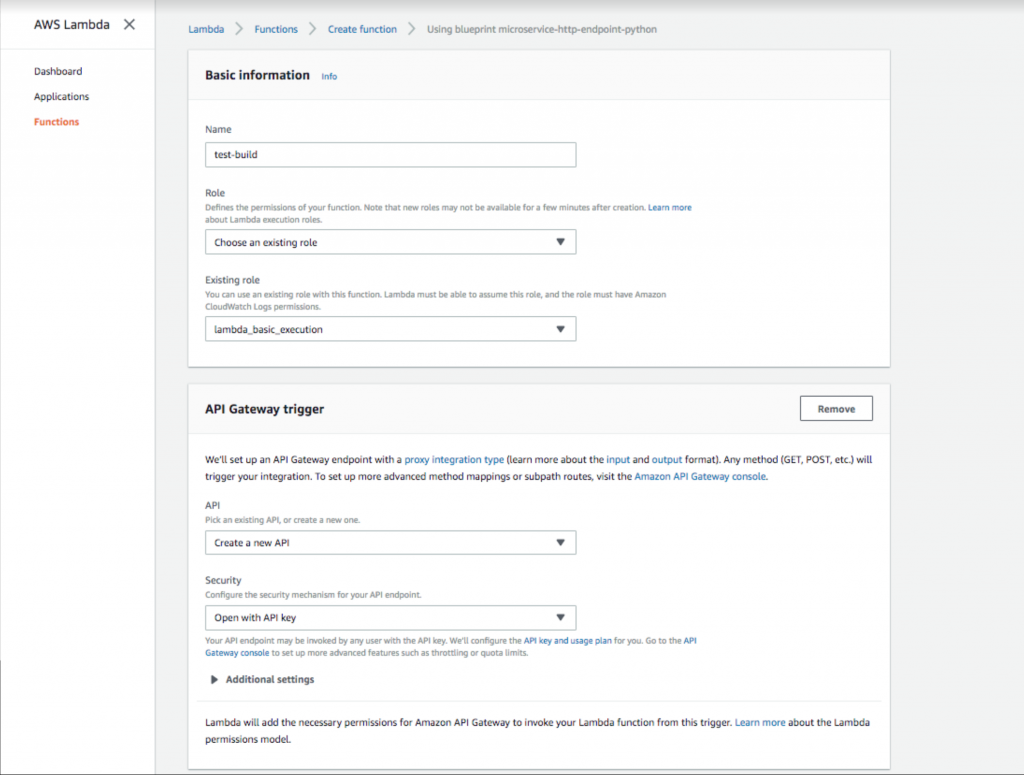
Configurazione di una chiave gateway API aperta in AWS Lambda.
- Una volta creata la funzione, ora puoi configurare il tuo codice. Come puoi vedere, il progetto ti ha già fornito un fantastico hook del punto di ingresso che ti consente di interagire con una tabella Dynamo (se stai cercando di aggiungere un database). Qualunque cosa si trovi sotto lambda_handler verrà eseguita quando viene caricato l'URL pubblico. Poiché stiamo aggiungendo anche un database, andiamo su Dynamo e creiamone uno.
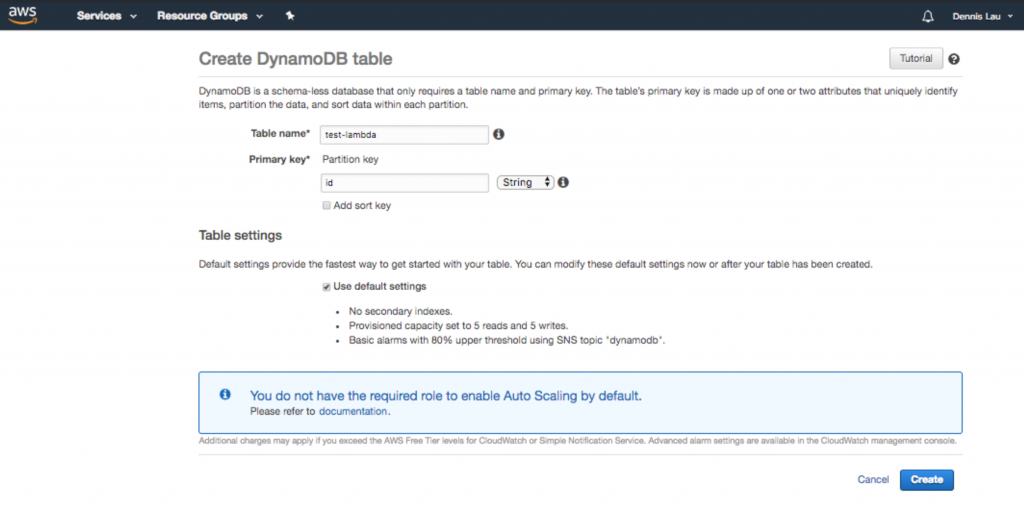
Creazione di una tabella di database Dynamo in AWS Lambda.
- Una volta creata la tabella Dynamo, eseguiamo una chiamata a questa funzione Lambda da un URL pubblico. Torna alla tua funzione e fai clic sull'icona " API Gateway " in alto. Dovresti vedere che l'endpoint e la chiave API sono già stati creati per te.
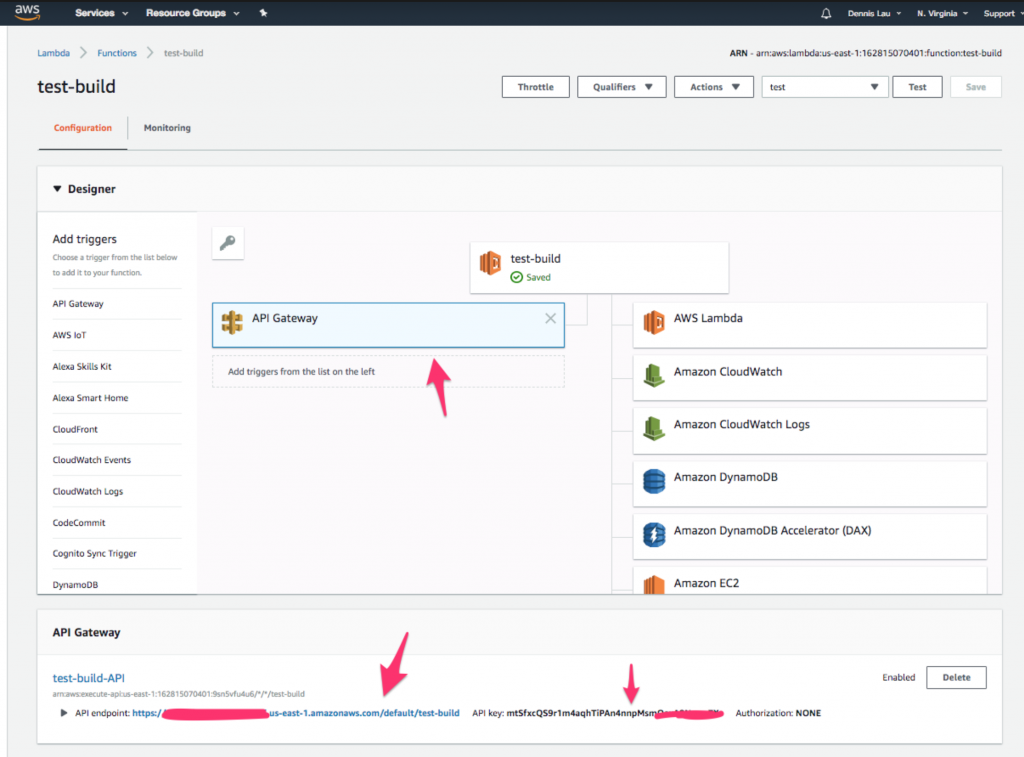
Dove trovare l'icona API Gateway nelle funzioni AWS Lambda.
- Ora apri il terminale e aggiungi la chiave API sotto l'intestazione " x-api-key" , quindi aggiungi il nome della tabella che hai creato sotto il parametro della stringa di query TableName .

Immettere la chiave e il nome del database nel terminale per terminare.
- Innanzitutto, crea una nuova funzione Lambda e seleziona " Blueprints ". Quindi, digita " http " nel campo della parola chiave e seleziona Python o Node microservice-http-endpoint. (I progetti sono blocchi di codice preconfezionati destinati a rendere più veloce lo sviluppo. Quanto è fantastico?) Dopo aver effettuato una selezione, fai clic su " Configura ".
Questo è tutto! Ora hai un back-end funzionante e sicuro connesso a un database. Sono bastati cinque semplici passaggi.
Come l'informatica serverless ha affrontato le nostre sfide
Ora che ti abbiamo mostrato come configurare build serverless, diamo un'occhiata e vediamo come si comporta questo modello basato su cloud rispetto al nostro elenco di problemi.
- Troppi server! Serverless … il che significa niente più server, giusto?
- Tieni attivi quei server. Poiché l'elaborazione serverless è gestita dal provider cloud, ottieni il vantaggio di avere questi provider (insieme ai loro metodi collaudati e collaudati) per monitorare i tuoi server. Per quelli di voi che vogliono giocare a Sherlock Holmes, potete anche vedere tutti i log del server emessi dalla vostra funzione su Cloudwatch .
- PHP non fa per me. I modelli serverless ti consentono di scrivere in C#, Python, NodeJS, Go e persino Java.
- Questo sta diventando costoso. Con le soluzioni serverless, i costi vengono misurati in base al tempo di esecuzione (per 100 millisecondi) e alla quantità di dati trasferiti. A differenza del pagamento mensile, che include il tempo di inattività dei server, paghi solo per ciò che usi. Con costi a partire da $ 0,000000208 per 100 ms di esecuzione, l'elaborazione serverless potrebbe farti risparmiare una notevole quantità di denaro.
- La sicurezza prima. Il serverless è sicuro? Con un sistema di autenticazione con chiave API integrato, puoi scommetterci che lo è.
- I Cron sono duri. Con un sistema di gestione cron costruito nativamente su Cloudwatch, basta impostare una finestra temporale e non pensarci più. Cloudwatch gestisce tutta la registrazione e l'esecuzione.
Pensieri finali
Per il team di Solutions Engineering di TUNE, il passaggio all'elaborazione serverless è stato un punto di svolta. La sua facilità d'uso, il risparmio sui costi e le funzionalità agili hanno cambiato il modo in cui gestiamo tutte le nuove build dei clienti. Le soluzioni basate su cloud serverless sono destinate a cambiare il mondo dell'elaborazione lato server. Non so voi, ma una cosa è certa: il team di TUNE Solutions Engineering è pronto.
Per saperne di più sulla piattaforma TUNE e sui servizi di sviluppo personalizzati che forniamo, visita la nostra pagina dei Servizi Professionali .