
Cluster semantico di parole chiave in Python
Pubblicato: 2021-04-19In un mondo pieno di miti del marketing digitale, crediamo che trovare soluzioni pratiche ai problemi quotidiani sia ciò di cui abbiamo bisogno.
In PEMAVOR, condividiamo sempre la nostra esperienza e conoscenza per soddisfare le esigenze degli appassionati di marketing digitale. Quindi, pubblichiamo spesso script Python gratuiti per aiutarti ad aumentare il tuo ROI.
Il nostro SEO Keyword Clustering con Python ha aperto la strada all'acquisizione di nuove informazioni per grandi progetti SEO, con solo meno di 50 righe di codici Python.
L'idea alla base di questo script era di permetterti di raggruppare le parole chiave senza pagare "commissioni esagerate" a... beh, sappiamo chi...
Ma ci siamo resi conto che questo script non è abbastanza da solo. C'è bisogno di un altro script, così voi ragazzi potete approfondire la vostra comprensione delle vostre parole chiave: dovete essere in grado di “ raggruppare le parole chiave per significato e relazioni semantiche. "
Ora è il momento di portare Python per SEO un ulteriore passo avanti.
Scansione dati³
 Scopri di più
Scopri di piùIl modo tradizionale del clustering semantico
Come sai, il metodo tradizionale per la semantica è costruire modelli word2vec , quindi raggruppare le parole chiave con Word Mover's Distance .
Ma questi modelli richiedono molto tempo e sforzi per essere costruiti e addestrati. Quindi, vorremmo offrirti una soluzione più semplice. 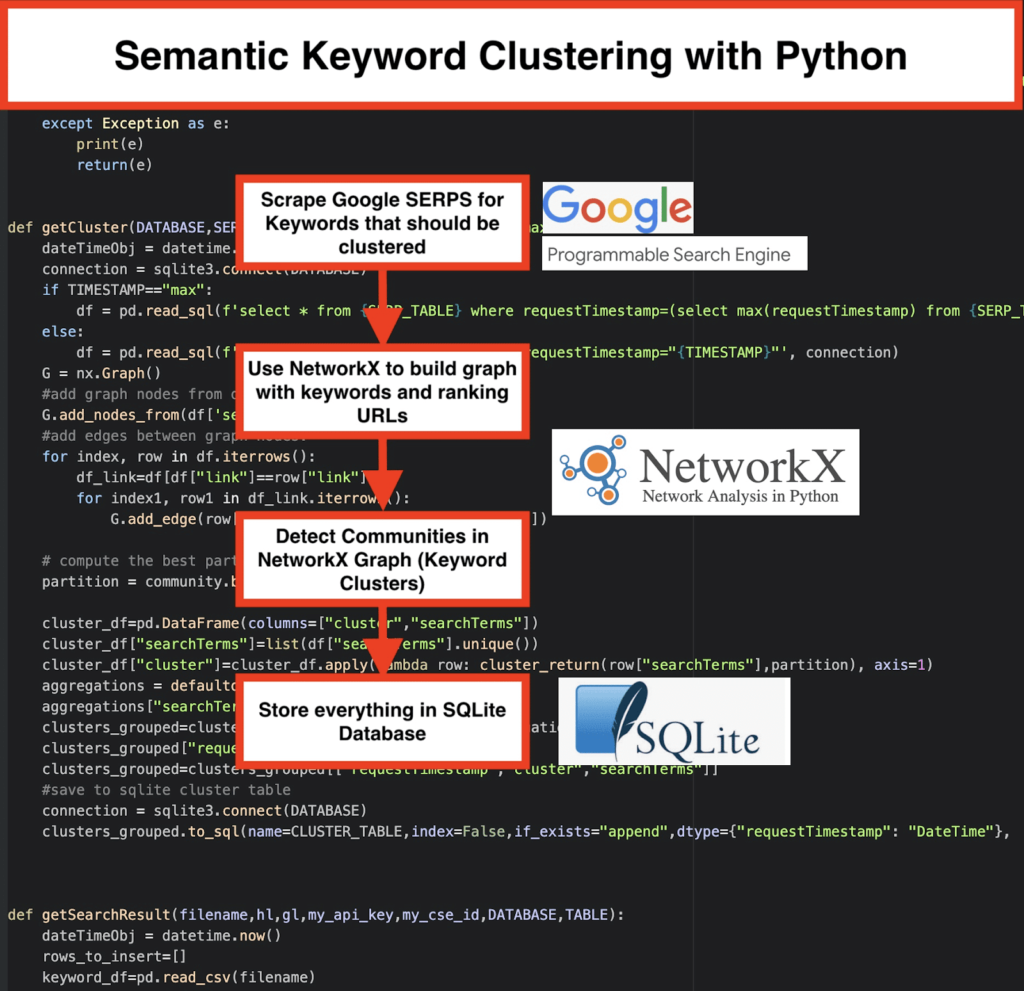
Risultati della SERP di Google e scoperta della semantica
Google utilizza i modelli NLP per offrire i migliori risultati di ricerca. È come aprire il vaso di Pandora e non lo sappiamo esattamente.
Tuttavia, invece di costruire i nostri modelli, possiamo usare questa casella per raggruppare le parole chiave in base alla loro semantica e significato.
Ecco come lo facciamo:
️ Innanzitutto, crea un elenco di parole chiave per un argomento.
️ Quindi, raschiare i dati SERP per ciascuna parola chiave.
️ Successivamente, viene creato un grafico con la relazione tra pagine di ranking e parole chiave.
️ Finché le stesse pagine si posizionano per parole chiave diverse, significa che sono correlate tra loro. Questo è il principio fondamentale alla base della creazione di cluster di parole chiave semantiche.
È ora di mettere insieme tutto in Python
Lo script Python offre le seguenti funzioni:
- Utilizzando il motore di ricerca personalizzato di Google, scarica le SERP per l'elenco delle parole chiave. I dati vengono salvati in un database SQLite . Qui dovresti impostare un'API di ricerca personalizzata.
- Quindi, utilizza la quota gratuita di 100 richieste al giorno. Ma offrono anche un piano a pagamento per $ 5 per 1000 missioni se non vuoi aspettare o se hai grandi set di dati.
- È meglio utilizzare le soluzioni SQLite se non hai fretta: i risultati SERP verranno aggiunti alla tabella ad ogni esecuzione. (Semplicemente prendi una nuova serie di 100 parole chiave quando hai di nuovo la quota il giorno successivo.)
- Nel frattempo, devi impostare queste variabili nello script Python .
- CSV_FILE="keywords.csv" => memorizza le tue parole chiave qui
- LINGUA = “it”
- PAESE = “it”
- API_KEY=" xxxxxxx"
- CSE_ID="xxxxxxx"
- L'esecuzione
getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE)scriverà i risultati SERP nel database. - Il Clustering viene eseguito da networkx e dal modulo di rilevamento della comunità. I dati vengono recuperati dal database SQLite : il clustering viene chiamato con
getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP) - I risultati del Clustering possono essere trovati nella tabella SQLite : finché non si cambia, il nome è "keyword_clusters" per impostazione predefinita.
Di seguito, vedrai il codice completo:
# Clustering semantico di parole chiave di Pemavor.com # Autore: Stefan Neefischer ([email protected]) da googleapiclient.discovery import build importa panda come pd importare Levenshtein da datetime import datetime da fuzzywuzzy import fuzz da urllib.parse import urlparse da tld import get_tld importare languida importa json importa panda come pd importa numpy come np importa retex come nx comunità di importazione importa sqlite3 importa la matematica importa io dalle raccolte import defaultdict def cluster_return(searchTerm,partition): partizione di ritorno[searchTerm] def language_detection(str_lan): lan=langid.classify(str_lan) lan di ritorno[0] def extract_domain(url, remove_http=True): uri = urlparse(url) se remove_http: nome_dominio = f"{uri.netloc}" altro: nome_dominio = f"{uri.netloc}://{uri.netloc}" restituisce nome_dominio def extract_mainDomain(url): res = get_tld(url, as_object=True) ritorno ris.fld def fuzzy_ratio(str1,str2): return fuzz.ratio(str1,str2) def fuzzy_token_set_ratio(str1,str2): restituisce fuzz.token_set_ratio(str1,str2) def google_search(search_term, api_key, cse_id,hl,gl, **kwargs): Tentativo: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,hl=hl,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)' ,num=10, cx=cse_id, **kwargs).execute() ris tranne Eccezione come e: stampa(e) ritorno(e) def google_search_default_language(search_term, api_key, cse_id,gl, **kwargs): Tentativo: service = build("customsearch", "v1", developerKey=api_key,cache_discovery=False) res = service.cse().list(q=search_term,gl=gl,fields='queries(request(totalResults,searchTerms,hl,gl)),items(title,displayLink,link,snippet)',num=10 , cx=cse_id, **kwargs).execute() ris tranne Eccezione come e: stampa(e) ritorno(e) def getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP="max"): dateTimeObj = datetime.now() connessione = sqlite3.connect(DATABASE) se TIMESTAMP=="max": df = pd.read_sql(f'select * da {SERP_TABLE} dove requestTimestamp=(select max(requestTimestamp) da {SERP_TABLE})', connection) altro: df = pd.read_sql(f'select * da {SERP_TABLE} dove requestTimestamp="{TIMESTAMP}"', connessione) G = nx.Grafico() #aggiungi nodi del grafico dalla colonna dataframe G.add_nodes_from(df['searchTerms']) #aggiungi bordi tra i nodi del grafico: per index, riga in df.iterrows(): df_link=df[df["link"]==riga["link"]] per index1, riga1 in df_link.iterrows(): G.add_edge(row["searchTerms"], row1['searchTerms']) # calcola la migliore partizione per la comunità (cluster) partizione = community.best_partition(G) cluster_df=pd.DataFrame(columns=["cluster","searchTerms"]) cluster_df["searchTerms"]=list(df["searchTerms"].unique()) cluster_df["cluster"]=cluster_df.apply(riga lambda: cluster_return(row["searchTerms"],partition), asse=1) aggregazioni = defaultdict() aggregati["searchTerms"]=' | '.giuntura clusters_grouped=cluster_df.groupby("cluster").agg(aggregazioni).reset_index() clusters_grouped["requestTimestamp"]=dateTimeObj clusters_grouped=clusters_grouped[["requestTimestamp","cluster","searchTerms"]] #salva nella tabella del cluster sqlite connessione = sqlite3.connect(DATABASE) clusters_grouped.to_sql(name=CLUSTER_TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connessione) def getSearchResult(filename,hl,gl,my_api_key,my_cse_id,DATABASE,TABLE): dateTimeObj = datetime.now() righe_da_inserire=[] keyword_df=pd.read_csv(nome file) parole chiave=parola chiave_df.iloc[:,0].tolist() per query nelle parole chiave: se hl=="predefinito": risultato = google_search_default_language(query, my_api_key, my_cse_id, gl) altro: risultato = google_search(query, my_api_key, my_cse_id,hl,gl) se "elementi" nel risultato e "query" nel risultato: for position in range(0,len(result["items"])): risultato["items"][posizione]["posizione"]=posizione+1 result["items"][position]["main_domain"]= extract_mainDomain(result["items"][position]["link"]) risultato["items"][posizione]["title_matchScore_token"]=fuzzy_token_set_ratio(result["items"][posizione]["titolo"],query) risultato["items"][posizione]["snippet_matchScore_token"]=fuzzy_token_set_ratio(result["items"][posizione]["snippet"],query) risultato["items"][posizione]["title_matchScore_order"]=fuzzy_ratio(result["items"][posizione]["titolo"],query) risultato["items"][posizione]["snippet_matchScore_order"]=fuzzy_ratio(result["items"][posizione]["snippet"],query) result["items"][position]["snipped_language"]=language_detection(result["items"][position]["snippet"]) for position in range(0,len(result["items"])): rows_to_insert.append({"requestTimestamp":dateTimeObj,"searchTerms":query,"gl":gl,"hl":hl, "totalResults":result["queries"]["request"][0]["totalResults"],"link":result["items"][position]["link"], "displayLink":result["items"][position]["displayLink"],"main_domain":result["items"][position]["main_domain"], "position":result["items"][position]["position"],"snippet":result["items"][position]["snippet"], "snipped_language":result["items"][position]["snippet_language"],"snippet_matchScore_order":result["items"][position]["snippet_matchScore_order"], "snippet_matchScore_token":result["items"][position]["snippet_matchScore_token"],"title":result["items"][position]["title"], "title_matchScore_order":result["items"][position]["title_matchScore_order"],"title_matchScore_token":result["items"][posizione]["title_matchScore_token"], }) df=pd.DataFrame(righe_da_inserire) #salva i risultati serp nel database sqlite connessione = sqlite3.connect(DATABASE) df.to_sql(name=TABLE,index=False,if_exists="append",dtype={"requestTimestamp": "DateTime"}, con=connessione) ################################################################ ################################################################ ##################################################### #Leggimi: # ################################################################ ################################################################ ##################################################### #1- Devi configurare un motore di ricerca personalizzato di Google. # # Fornisci la chiave API e l'ID ricerca. # # Imposta anche il paese e la lingua in cui desideri monitorare i risultati SERP. # # Se non disponi ancora di una chiave API e di un ID ricerca, # # puoi seguire i passaggi nella sezione Prerequisiti in questa pagina https://developers.google.com/custom-search/v1/overview#prerequisiti # # # #2- Devi anche inserire i nomi di database, tabelle serp e tabelle cluster da utilizzare per salvare i risultati. # # # #3- inserisci il nome del file CSV o il percorso completo che contiene le parole chiave che verranno utilizzate per serp # # # #4- Per il clustering delle parole chiave, inserire il timestamp per i risultati serp che verranno utilizzati per il clustering. # # Se è necessario raggruppare i risultati dell'ultimo serp, immettere "max" per timestamp. # # oppure puoi inserire un timestamp specifico come "2021-02-18 17:18:05.195321" # # # #5- Sfoglia i risultati tramite il browser DB per il programma Sqlite # ################################################################ ################################################################ ##################################################### #csv nome del file con parole chiave per serp CSV_FILE="keywords.csv" # determina la lingua LINGUA = "it" #determina città PAESE = "it" #google ricerca personalizzata chiave API json API_KEY="INSERIRE QUI LA CHIAVE" #ID motore di ricerca CSE_ #sqlite nome del database DATABASE="parole chiave.db" #nome della tabella per salvare i risultati della serp su di essa SERP_TABLE="keywords_serps" # esegui serp per le parole chiave getSearchResult(CSV_FILE,LANGUAGE,COUNTRY,API_KEY,CSE_ID,DATABASE,SERP_TABLE) #nome della tabella che i risultati del cluster salveranno su di essa. CLUSTER_TABLE="keyword_cluster" #Inserisci timestamp, se desideri creare cluster per timestamp specifici #Se devi creare dei cluster per l'ultimo risultato serp, invialo con il valore "max". #TIMESTAMP="2021-02-18 17:18:05.195321" TIMESTAMP="max" #esegui cluster di parole chiave in base alle reti e agli algoritmi della community getCluster(DATABASE,SERP_TABLE,CLUSTER_TABLE,TIMESTAMP)

Risultati della SERP di Google e scoperta della semantica
Ci auguriamo che ti sia piaciuto questo script con la sua scorciatoia per raggruppare le tue parole chiave in cluster semantici senza fare affidamento sui modelli semantici. Poiché questi modelli sono spesso complessi e costosi, è importante esaminare altri modi per identificare le parole chiave che condividono proprietà semantiche.
Trattando insieme le parole chiave semanticamente correlate, puoi coprire meglio un argomento, collegare meglio gli articoli sul tuo sito tra loro e aumentare il ranking del tuo sito Web per un determinato argomento.