
Informazioni sul rapporto sulla copertura di Search Console
Pubblicato: 2019-08-15Introduzione al rapporto di copertura e come interpretare i dati
Il rapporto sulla copertura di Search Console fornisce informazioni su quali pagine del tuo sito sono state indicizzate ed elenca gli URL che hanno presentato problemi mentre Googlebot tenta di scansionarle e indicizzarle.
La pagina principale del rapporto sulla copertura mostra gli URL del tuo sito raggruppati per stato:
- Errore: la pagina non è indicizzata. Ci sono diverse ragioni per questo, le pagine che rispondono con 404, 404 pagine morbide, tra le altre cose.
- Valido con avvisi: la pagina è indicizzata ma presenta problemi.
- Valido: la pagina è indicizzata.
- Escluso: la pagina non è indicizzata, Google sta seguendo regole sul sito come tag noindex in robots.txt o meta tag, tag canonici, ecc. che impediscono l'indicizzazione delle pagine.
Questo rapporto sulla copertura fornisce molte più informazioni rispetto alla vecchia console di ricerca di Google. Google ha davvero migliorato i dati che condivide, ma ci sono ancora alcune cose che devono essere migliorate.
Come puoi vedere di seguito, Google mostra un grafico con il numero di URL in ciascuna categoria. Se si verifica un improvviso aumento degli errori, puoi visualizzare le barre e persino correlarlo con le impressioni per determinare se un aumento degli URL con errori o avvisi può ridurre le impressioni.

Dopo l'avvio di un sito o la creazione di nuove sezioni, desideri visualizzare un numero crescente di pagine indicizzate valide. Occorrono alcuni giorni prima che Google indicizzi le nuove pagine, ma puoi utilizzare lo strumento di controllo degli URL per richiedere l'indicizzazione e ridurre i tempi di ricerca della tua nuova pagina da parte di Google.

Tuttavia, se vedi un numero di URL validi in calo o picchi improvvisi, è importante lavorare per identificare gli URL nella sezione Errori e risolvere i problemi elencati nel rapporto. Google fornisce un buon riepilogo delle azioni da eseguire in caso di aumento degli errori o degli avvisi.
Google fornisce informazioni su quali sono gli errori e quanti URL presentano questo problema:

Ricorda che Google Search Console non mostra informazioni accurate al 100%. In effetti, sono state segnalate diverse segnalazioni di bug e anomalie dei dati. Inoltre, la console di ricerca di Google richiede tempo per l'aggiornamento, è noto che i dati sono indietro di 16 giorni a 20 giorni. Inoltre, il rapporto mostrerà a volte un elenco di più di 1000 pagine in errori o categorie di avviso, come puoi vedere nell'immagine sopra, ma ti consente solo di vedere e scaricare un campione di 1000 URL da controllare e controllare.
Tuttavia, questo è un ottimo strumento per trovare problemi di indicizzazione sul tuo sito:
Quando fai clic su un errore specifico, sarai in grado di vedere la pagina dei dettagli che elenca esempi di URL:

Come puoi vedere nell'immagine sopra, questa è la pagina dei dettagli per tutti gli URL che rispondono con 404. Ogni rapporto ha un link "Ulteriori informazioni" che ti porta a una pagina della documentazione di Google che fornisce dettagli su quell'errore specifico. Google fornisce anche un grafico che mostra il conteggio delle pagine interessate nel tempo.
Puoi fare clic su ciascun URL per esaminare l'URL che è simile alla vecchia funzione "recupera come Googlebot" della vecchia Google Search Console. Puoi anche verificare se la pagina è bloccata dal tuo robots.txt
Dopo aver corretto gli URL, puoi richiedere a Google di convalidarli in modo che l'errore scompaia dal tuo rapporto. Dovresti dare la priorità alla risoluzione dei problemi che sono nello stato di convalida "non riuscito" o "non avviato".
È importante ricordare che non dovresti aspettarti che tutti gli URL del tuo sito vengano indicizzati. Google afferma che l'obiettivo del webmaster dovrebbe essere quello di indicizzare tutti gli URL canonici. Le pagine duplicate o alternative verranno classificate come escluse poiché hanno contenuti simili a quelli della pagina canonica.
È normale che i siti abbiano più pagine incluse nella categoria esclusa. La maggior parte dei siti Web avrà diverse pagine senza meta tag di indice o bloccate tramite robots.txt. Quando Google identifica una pagina duplicata o alternativa, assicurati che tali pagine abbiano un tag canonico che punta all'URL corretto e prova a trovare l'equivalente canonico nella categoria valida.
Google ha incluso un filtro a discesa in alto a sinistra del rapporto in modo da poter filtrare il rapporto per tutte le pagine conosciute, tutte le pagine inviate o gli URL in una mappa del sito specifica. Il rapporto predefinito include tutte le pagine conosciute che includono tutti gli URL scoperti da Google. Tutte le pagine inviate includono tutti gli URL che hai segnalato tramite una mappa del sito. Se hai inviato diverse mappe del sito, puoi filtrare per URL in ciascuna mappa del sito.
[Case Study] Aumenta il crawl budget su pagine strategiche
 Leggi il caso di studio
Leggi il caso di studioErrori, Avvisi, URL validi ed esclusi
Errore
- Errore del server (5xx): il server ha restituito un errore 500 quando Googlebot ha tentato di eseguire la scansione della pagina.
- Errore di reindirizzamento: quando Googlebot ha eseguito la scansione dell'URL si è verificato un errore di reindirizzamento, perché la catena era troppo lunga, c'era un ciclo di reindirizzamento, l'URL ha superato la lunghezza massima dell'URL o c'era un URL errato o vuoto nella catena di reindirizzamento.
- URL inviato bloccato da robots.txt: gli URL in questo elenco sono bloccati dal file robts.txt.
- URL inviato contrassegnato come 'noindex': gli URL in questo elenco hanno un tag meta robots 'noindex' o un'intestazione http.
- L' URL inviato sembra essere un soft 404: si verifica un errore soft 404 quando una pagina che non esiste (è stata rimossa o reindirizzata) visualizza un messaggio "pagina non trovata" all'utente ma non riesce a restituire un codice di stato HTTP 404. I soft 404 si verificano anche quando le pagine vengono reindirizzate a pagine non rilevanti, ad esempio una pagina che reindirizza alla home page invece di restituire un codice di stato 404 o reindirizzare a una pagina pertinente.
- L' URL inviato restituisce una richiesta non autorizzata (401): la pagina inviata per l'indicizzazione restituisce una risposta HTTP non autorizzata 401.
- URL inviato non trovato (404): la pagina ha risposto con un errore 404 non trovato quando Googlebot ha tentato di eseguire la scansione della pagina.
- L'URL inviato presenta un problema di scansione: Googlebot ha riscontrato un errore di scansione durante la scansione di queste pagine che non rientra in nessuna delle altre categorie. Dovrai controllare ogni URL e determinare quale potrebbe essere stato il problema.
Avvertimento
- Indicizzata, sebbene bloccata da robots.txt: la pagina è stata indicizzata perché Googlebot vi ha effettuato l'accesso tramite link esterni che puntano alla pagina, tuttavia la pagina è bloccata dal tuo robots.txt. Google contrassegna questi URL come avvisi perché non sono sicuri che la pagina debba essere effettivamente bloccata dalla visualizzazione nei risultati di ricerca. Se desideri bloccare una pagina, dovresti utilizzare un meta tag "noindex" o un'intestazione di risposta HTTP noindex.
Se Google è corretto e l'URL è stato bloccato in modo errato, dovresti aggiornare il file robots.txt per consentire a Google di eseguire la scansione della pagina.
Valido
- Inviato e indicizzato: URL che hai inviato a Google tramite sitemap.xml per l'indicizzazione e sono stati indicizzati.
- Indicizzato, non inviato nella mappa del sito: l'URL è stato rilevato da Google e indicizzato, ma non è stato incluso nella mappa del sito. Si consiglia di aggiornare la mappa del sito e di includere tutte le pagine di cui si desidera eseguire la scansione e l'indicizzazione da parte di Google.
Escluso
- Escluso dal tag "noindex": quando Google ha cercato di indicizzare la pagina, ha trovato un meta tag "noindex" o un'intestazione HTTP.
- Bloccato dallo strumento di rimozione della pagina: qualcuno ha inviato una richiesta a Google di non indicizzare questa pagina utilizzando la richiesta di rimozione dell'URL in Google Search Console. Se desideri che questa pagina venga indicizzata, accedi alla Search Console di Google e rimuovila dall'elenco delle pagine rimosse.
- Bloccato da robots.txt: il file robots.txt ha una riga che esclude l'URL dalla scansione. Puoi controllare quale linea sta facendo questo usando il tester robots.txt.
- Bloccato a causa di una richiesta non autorizzata (401): come nella categoria Errore, le pagine qui vengono restituite con un'intestazione HTTP 401.
- Anomalia di scansione: questa è una specie di categoria generica, gli URL qui rispondono con codici di risposta di livello 4xx o 5xx; Questi codici di risposta impediscono l'indicizzazione della pagina.
- Scansionato – attualmente non indicizzato: Google non fornisce un motivo per cui l'URL non è stato indicizzato. Suggeriscono di inviare nuovamente l'URL per l'indicizzazione. Tuttavia, è importante verificare se la pagina ha contenuto sottile o duplicato, è canonicata in una pagina diversa, ha una direttiva noindex, le metriche mostrano un'esperienza utente negativa, tempo di caricamento della pagina elevato, ecc. Potrebbero esserci diversi motivi per cui Google non vuole indicizzare la pagina.
- Scoperta – attualmente non indicizzata: la pagina è stata trovata ma Google non l'ha inclusa nel suo indice. Puoi inviare l'URL per l'indicizzazione per accelerare il processo come accennato in precedenza. Google afferma che il motivo tipico per cui ciò accade è che il sito era sovraccarico e Google ha riprogrammato la scansione.
- Pagina alternativa con tag canonico corretto: Google non ha indicizzato questa pagina perché ha un tag canonico che punta a un URL diverso. Google ha seguito la regola canonica e ha indicizzato correttamente l'URL canonico. Se intendevi che questa pagina non venisse indicizzata, non c'è nulla da risolvere qui.
- Duplica senza canonico selezionato dall'utente: Google ha trovato duplicati per le pagine elencate in questa categoria e nessuna utilizza tag canonici. Google ha selezionato una versione diversa come tag canonico. È necessario rivedere queste pagine e aggiungere un tag canonico che punta all'URL corretto.
- Duplicato, Google ha scelto canonico diverso dall'utente: gli URL in questa categoria sono stati scoperti da Google senza una richiesta di scansione esplicita. Google li ha trovati tramite collegamenti esterni e ha stabilito che esiste un'altra pagina che rende canonica migliore. Google non ha indicizzato queste pagine per questo motivo. Google consiglia di contrassegnare questi URL come duplicati del canonico.
- Non trovato (404): quando Googlebot tenta di accedere a queste pagine, risponde con un errore 404. Google afferma che questi URL non sono stati inviati, questi URL sono stati trovati tramite collegamenti esterni che puntano a questi URL. È una buona idea reindirizzare questi URL a pagine simili per sfruttare l'equità del collegamento e assicurarsi anche che gli utenti arrivino a una pagina pertinente.
- Pagina rimossa a causa di un reclamo legale: qualcuno si è lamentato di queste pagine a causa di problemi legali, come una violazione del copyright. Puoi presentare ricorso contro il reclamo legale presentato qui.
- Pagina con reindirizzamento: questi URL stanno reindirizzando, quindi sono esclusi.
- Soft 404: come spiegato sopra, questi URL sono esclusi perché dovrebbero rispondere con un 404. Controlla le pagine e assicurati che se ha un messaggio "non trovato" per loro di rispondere con un'intestazione HTTP 404.
- URL inviato duplicato non selezionato come canonico: simile a "Google ha scelto canonico diverso dall'utente", tuttavia, gli URL in questa categoria sono stati inviati da te. È una buona idea controllare le mappe del sito e assicurarsi che non siano incluse pagine duplicate.
Come utilizzare i dati e gli elementi di azione per migliorare il sito
Lavorando in un'agenzia, ho accesso a molti siti diversi e ai loro rapporti sulla copertura. Ho passato del tempo ad analizzare gli errori segnalati da Google nelle diverse categorie.
È stato utile trovare problemi con la canonizzazione e il contenuto duplicato, tuttavia a volte si verificano discrepanze come quella segnalata da @jroakes:

Sembra che Google Search Console > Controllo URL > Live Test riporti erroneamente tutti i file JS e CSS come Scansione consentita: No: bloccato da robots.txt. Testare circa 20 file su 3 domini. pic.twitter.com/fM3WAcvK8q
— JR%20Oakes ???? (@jroakes) 16 luglio 2019
AJ Koh, ha scritto un ottimo articolo subito dopo che la nuova Google Search Console è diventata disponibile in cui spiega che il vero valore dei dati è usarli per dipingere un quadro di salute per ogni tipo di contenuto sul tuo sito:
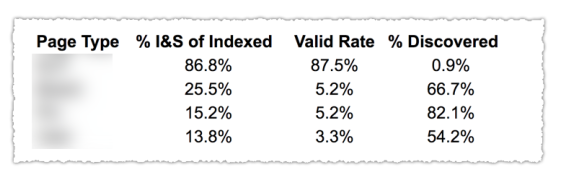
Come puoi vedere nell'immagine sopra, gli URL delle diverse categorie nel rapporto di copertura sono stati classificati per modello di pagina come blog, pagina di servizio, ecc. L'utilizzo di diverse mappe del sito per diversi tipi di URL può aiutare con questa attività poiché Google consente filtrare le informazioni sulla copertura in base alla mappa del sito. Quindi ha incluso tre colonne con le seguenti informazioni % di pagine indicizzate e inviate, tasso valido e % di scoperte.
Questa tabella ti offre davvero un'ottima panoramica dello stato di salute del tuo sito. Ora, se vuoi approfondire le diverse sezioni, ti consiglio di rivedere i rapporti e ricontrollare gli errori presentati da Google.
Puoi scaricare tutti gli URL presentati in diverse categorie e utilizzare OnCrawl per verificarne lo stato HTTP, i tag canonici, ecc. e creare un foglio di calcolo come questo:
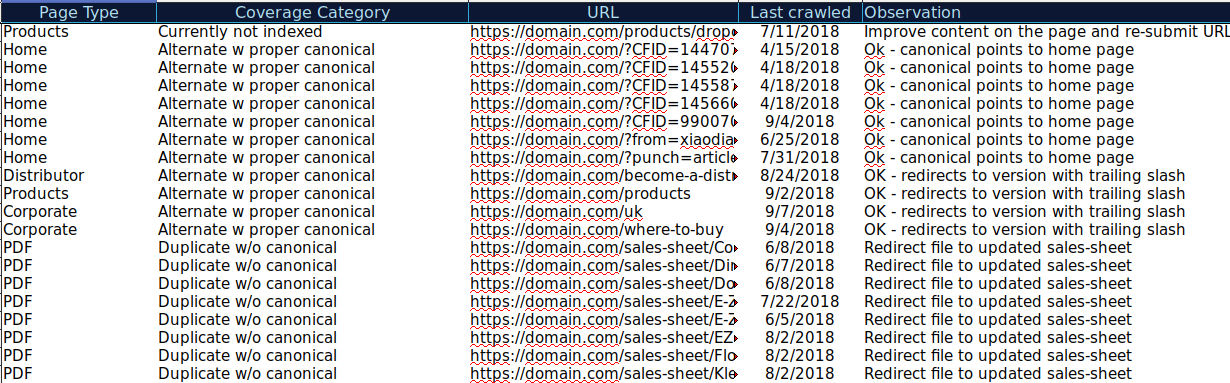
Organizzare i tuoi dati in questo modo può aiutarti a tenere traccia dei problemi e ad aggiungere elementi di azione per gli URL che devono essere migliorati o corretti. Inoltre, puoi selezionare gli URL corretti e non sono necessari elementi di azione nel caso di quegli URL con parametri con implementazione di tag canonica corretta.
Inizia la tua prova gratuita di 14 giorni
 Inizia la tua prova
Inizia la tua provaPuoi anche aggiungere più informazioni a questo foglio di lavoro da altre fonti come ahrefs, Majestic e Google Analytics con integrazioni OnCrawl. Ciò ti consentirebbe di estrarre i dati dei collegamenti, nonché i dati sul traffico e sulle conversioni per ciascuno degli URL in Google Search Console. Tutti questi dati possono aiutarti a prendere decisioni migliori su cosa fare per ogni pagina, ad esempio se hai un elenco di pagine con 404, puoi collegarlo con i backlink per determinare se stai perdendo l'equità dei link dai domini che si collegano a pagine rotte sul tuo sito. Oppure puoi controllare le pagine indicizzate e quanto traffico organico stanno ricevendo. Puoi identificare le pagine indicizzate che non ottengono traffico organico e lavorare per ottimizzarle (migliorando il contenuto e l'usabilità) per aumentare il traffico verso quella pagina.
Con questi dati aggiuntivi, puoi creare una tabella di riepilogo su un altro foglio di calcolo. Puoi utilizzare la formula =COUNTIF(intervallo, criteri) per contare gli URL in ogni tipo di pagina (questa tabella può integrare la tabella suggerita sopra da AJ Kohn). Puoi anche utilizzare un'altra formula per aggiungere backlink, visite o conversioni che hai estratto per ciascun URL e mostrarli nella tabella di riepilogo con la seguente formula =SUMIF (intervallo, criteri, [sum_range]). Otterresti qualcosa del genere:
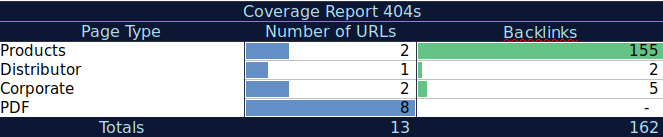
Mi piace molto lavorare con tabelle di riepilogo che possono darmi una vista riepilogativa dei dati e possono aiutarmi a identificare le sezioni su cui devo concentrarmi per prima cosa sulla correzione.
Pensieri finali
Quello a cui devi pensare quando lavori per risolvere i problemi e guardare i dati in questo rapporto è: Il mio sito è ottimizzato per la scansione? Le mie pagine indicizzate e valide stanno aumentando o diminuendo? Le pagine con errori stanno aumentando o diminuendo? Sto permettendo a Google di dedicare tempo agli URL che porteranno più valore ai miei utenti o sta trovando molte pagine inutili? Con le risposte a queste domande puoi iniziare a migliorare il tuo sito in modo che Googlebot possa spendere il suo budget di scansione in pagine che possono fornire valore ai tuoi utenti invece di pagine inutili. Puoi utilizzare il tuo robots.txt per migliorare l'efficienza della scansione, rimuovere gli URL inutili quando possibile o utilizzare tag canonici o noindex per evitare contenuti duplicati.
Google continua ad aggiungere funzionalità e ad aggiornare l'accuratezza dei dati ai diversi rapporti nella console di ricerca di Google, quindi speriamo di continuare a vedere più dati in ciascuna delle categorie nel rapporto sulla copertura e in altri rapporti in Google Search Console.