
Audit tecnico SEO rapido e sporco in 11 passaggi per la salute generale del sito web
Pubblicato: 2020-02-27La SEO tecnica è importante perché è il punto di partenza di qualsiasi progetto. Dal punto di vista di un esperto SEO, ogni sito web è un nuovo progetto. Un sito web dovrebbe avere una solida base per ottenere buoni risultati e raggiungere i KPI più importanti nella SEO come le classifiche.
Ogni volta che inizio con un nuovo progetto, la prima cosa che faccio è un audit tecnico SEO. La maggior parte delle volte la risoluzione di problemi tecnici può ottenere risultati sorprendenti non appena il sito Web viene ripetuto.
È divertente per me quando le persone parlano di contenuti e più contenuti, ma non dicono una parola sulla SEO tecnica. Una cosa è certa, la salute del sito web e la SEO tecnica sono due cose importanti che saranno cruciali nel 2020. Non intendo dire che i contenuti non siano importanti. Lo è, ma senza risolvere i problemi tecnici su un sito Web, non credo che i contenuti possano portare risultati.
Ho visto casi in cui pagine importanti sono state bloccate da direttive nel file robots.txt o le pagine di categorie o servizi più importanti sono state interrotte o bloccate da meta robot come noindex, nofollow. Come è possibile avere successo senza dare priorità risolvendo questi problemi?
Può essere sorprendente vedere il numero di SEO che non sanno come identificare i problemi tecnologici da segnalare agli specialisti dello sviluppo web per essere risolti. Mi sono ricordato che una volta, mentre lavoravo nel campo aziendale, ho creato un foglio di checklist per l'audit Tech SEO che sarà utilizzato dal mio team. In quel momento, mi sono reso conto che avere a portata di mano un foglio di correzione rapida come questo può aiutare immensamente un team e generare una rapida spinta per un cliente. Ecco perché ritengo della massima importanza investire in uno strumento/software che possa aiutarti con la diagnostica e le raccomandazioni tecniche SEO.
Iniziamo il processo pratico su come condurre un rapido audit SEO tecnologico che farà una grande differenza. Questo è un esercizio veloce che ti richiederà circa un'ora anche se non sei un professionista. Per me l'utilizzo di uno strumento SEO tecnologico come OnCrawl per far avanzare rapidamente tutte le cose in cinque minuti senza dover fare tutto il lavoro manuale mi semplifica la vita.
Esaminerò le cose più importanti da controllare quando conduco un audit tecnico SEO. Ci sono più cose che possiamo controllare per problemi sulla pagina, ma voglio concentrarmi solo su cose che creeranno problemi di indicizzazione e spreco di budget. Dare la priorità a questo è il modo per assicurarsi che le pagine più importanti vengano scansionate da Googlebot.
- Indicizzazione
- File Robots.txt
- Tag meta robot
- Errori 4xx
- Mappe del sito
- HTTP/HTTPS (problemi di sicurezza del sito Web, contenuto misto e contenuto duplicato)
- Impaginazione
- 404 pagina
- Profondità e struttura del sito
- Catene di reindirizzamento lunghe
- Implementazione di tag canonico
1) Indicizzazione
Questa è la prima cosa da controllare. Molte volte l'indicizzazione può essere influenzata dalla configurazione di un plug-in o da qualsiasi piccolo errore, ma l'impatto sulla reperibilità può essere enorme, poiché oggi ci sono oltre 6,16 miliardi di pagine Web indicizzate. Devi capire che qualsiasi motore di ricerca sta facendo uno sforzo e anche Google deve dare la priorità alla pagina più rilevante per l'esperienza dell'utente. Se non consideri di semplificare le cose a Googlebot, la concorrenza lo farà e guadagnerà molta più fiducia che deriva da un sito web sano.
Quando ci sono problemi di indicizzazione, i problemi di salute del tuo sito web si rifletteranno in una perdita di traffico organico. Il processo di indicizzazione significa che un motore di ricerca esegue la scansione di una pagina Web e organizza le informazioni che successivamente la offrono in SERP. I risultati dipendono dalla rilevanza per l'intento dell'utente. Se una pagina web non può o ha problemi con la scansione, questo favorirà altre pagine nella stessa nicchia per avere un vantaggio.
Utilizzando ad esempio gli operatori di ricerca:
Sito: www.abc.com
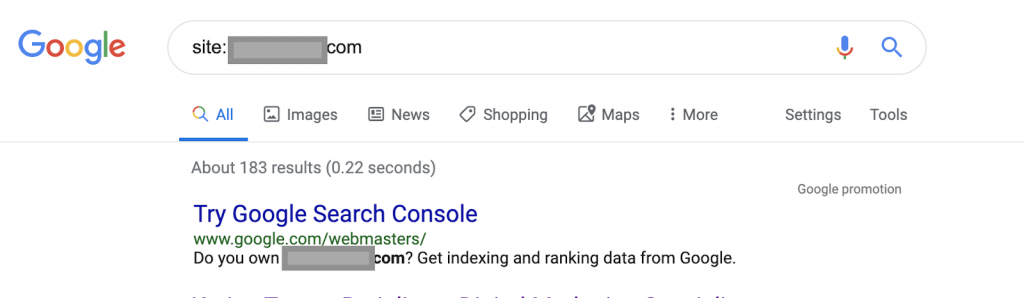
La query restituirà 183 pagine indicizzate da Google. Questa è una stima approssimativa del numero di pagine indicizzate da Google. Puoi controllare Google Search Console per il numero esatto.
Dovresti anche utilizzare un crawler web come OnCrawl per elencare tutte le pagine a cui Google ha accesso. Questo mostra un numero diverso come puoi vedere di seguito:
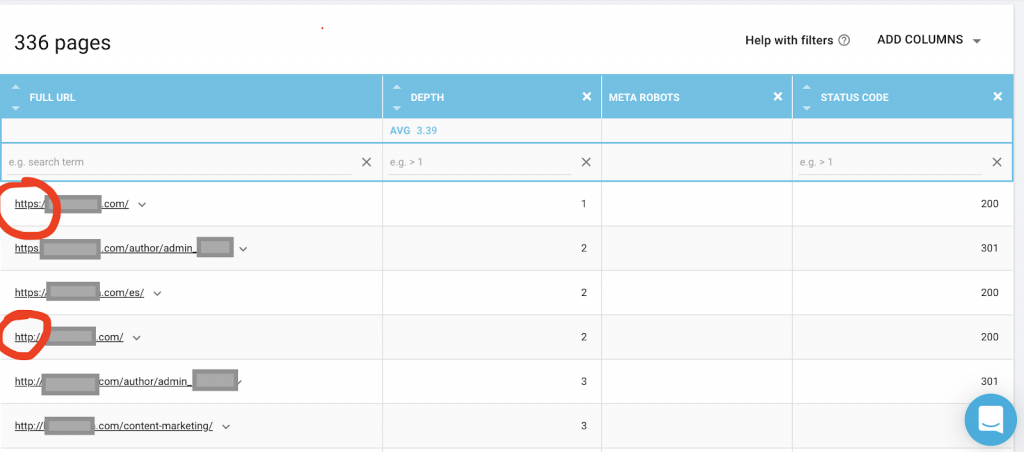
Questo sito Web ha quasi il doppio delle pagine scansionabili rispetto alle pagine indicizzate.
Ciò potrebbe rivelare un problema di contenuto duplicato o persino un problema di versione della sicurezza del sito Web tra il problema HTTP e HTTPS. Ne parlerò più avanti in questo articolo.
In questo caso, il sito Web è stato migrato da HTTP a HTTPS. Possiamo vedere in OnCrawl che le pagine HTTP sono state reindirizzate. Sia la versione HTTP che quella HTTPS sono ancora accessibili a Googlebot e potrebbe eseguire la scansione di tutte le pagine duplicate, invece di dare la priorità alle pagine più importanti che il proprietario desidera classificare, causando uno spreco di budget di scansione.
Un altro problema comune tra i siti Web trascurati o i siti Web di grandi dimensioni come i siti di e-commerce sono i problemi di contenuto misto. Per farla breve, i problemi si verificano quando la tua pagina protetta ha risorse come file multimediali (più frequentemente: immagini) caricati da una versione non protetta.
Come sistemarlo:
Puoi chiedere a uno sviluppatore web di forzare tutte le pagine HTTP alla versione HTTPS e reindirizzare gli indirizzi HTTP a HTTPS una volta utilizzando un codice di stato 301.
Per problemi di contenuto misto puoi controllare manualmente l'origine della pagina e cercare risorse caricate come "src=http://example.com/media/images" che è quasi folle farlo soprattutto per i siti Web di grandi dimensioni. Ecco perché abbiamo bisogno di utilizzare uno strumento SEO tecnico.
2) File Robots.txt:
Il file robots.txt indica agli agenti di scansione quali pagine non devono scansionare. La guida alle specifiche di Robots.txt indica che il formato del file deve essere di testo normale con una dimensione massima di 500 KB.
Consiglierò di aggiungere la mappa del sito a robots.txt.file. Non tutti lo fanno, ma credo sia una buona pratica. Il file robots.txt deve essere posizionato nel tuo server ospitato in public_html e va dopo il dominio principale.
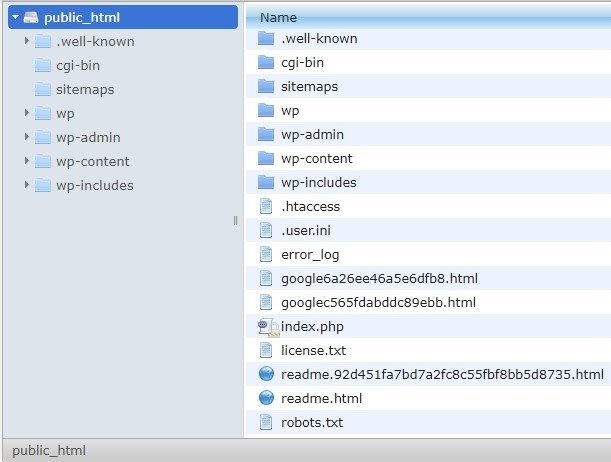
Possiamo utilizzare le direttive nel file robots.txt per impedire ai motori di ricerca di eseguire la scansione di pagine non necessarie o con informazioni sensibili, come la pagina di amministrazione, i modelli o il carrello degli acquisti (/carrello, /checkout, /login, cartelle come /tag utilizzati nei blog) , aggiungendo queste pagine nel file robots.txt.
Consiglio : assicurati di non bloccare la cartella dei file multimediali perché ciò escluderà dall'indicizzazione le tue immagini, i tuoi video o altri media auto-ospitati. I media possono essere molto importanti per la pertinenza della pagina, nonché per il posizionamento organico e il traffico di immagini o video.
3) Tag Meta Robot
Questo è un pezzo di codice HTML che indica ai motori di ricerca se eseguire la scansione e indicizzare una pagina, con tutti i collegamenti all'interno di quella pagina. Il tag HTML va nella testata della tua pagina web. Esistono 4 tag HTML comuni per i robot:
- Non seguire
- Seguire
- Indice
- Nessun indice
Quando non sono presenti meta tag robots, i motori di ricerca seguiranno e indicizzeranno il contenuto per impostazione predefinita.
Puoi utilizzare qualsiasi combinazione più adatta alle tue esigenze. Ad esempio, utilizzando OnCrawl ho scoperto che una "pagina dell'autore" di questo sito Web non ha meta robot. Ciò significa che per impostazione predefinita la direzione è ("segui, indicizza")
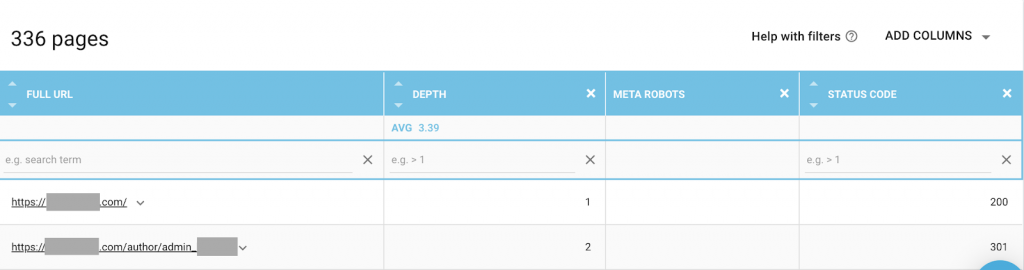
Dovrebbe essere ("noindex, nofollow").
Come mai?
Ogni caso è diverso, ma questo sito è un piccolo blog personale. C'è un solo autore che pubblica sul blog e il dominio è il nome dell'autore. In questo caso, la pagina “autore” non fornisce informazioni aggiuntive anche se è generata dalla piattaforma di blogging.
Un altro scenario può essere un sito Web in cui le categorie sul blog sono importanti. Quando il proprietario vuole classificarsi per le categorie sul proprio blog, i meta robot dovrebbero essere ("segui, indicizza") o predefiniti nelle pagine delle categorie.
In uno scenario diverso, per un sito Web grande e noto in cui i principali esperti SEO scrivono articoli seguiti dalla community, il nome dell'autore in Google funge da marchio. In questo caso probabilmente vorrai indicizzare alcuni nomi di autori.
Come puoi vedere, i meta robot possono essere utilizzati in molti modi diversi.
Come sistemarlo:
Chiedi a uno sviluppatore web di modificare il tag meta robot quando ne hai bisogno. Nel caso sopra per un piccolo sito Web, posso farlo da solo andando su ciascuna pagina e modificandola manualmente. Se stai utilizzando WordPress, puoi modificarlo dalle impostazioni di RankMath o Yoast.
4) Errori 4xx:
Questi sono errori sul lato client e possono essere 401, 403 e 404.
- 404 pagina non trovata:
Questo errore si verifica quando una pagina non è disponibile all'indirizzo URL indicizzato. Potrebbe essere stato spostato o eliminato e il vecchio indirizzo non è stato reindirizzato correttamente utilizzando la funzione 301 del server Web. Gli errori 404 sono una brutta esperienza per gli utenti e rappresentano un problema tecnico SEO che dovrebbe essere affrontato. È una buona cosa controllare spesso i 404 e risolverli, e non lasciarli da provare ancora e ancora per gli agenti striscianti che sprecano il loro budget.
Come sistemarlo:
Dobbiamo trovare gli indirizzi che restituiscono 404 e risolverli utilizzando i reindirizzamenti 301 se il contenuto esiste ancora. Oppure, se sono immagini, possono essere sostituite con altre nuove mantenendo lo stesso nome file.
- 401 Non autorizzato
Questo è un problema di autorizzazione. L'errore 401 di solito si verifica quando è richiesta l'autenticazione come nome utente e password.
Come sistemarlo:
Ecco due opzioni: la prima è bloccare la pagina dai motori di ricerca utilizzando robots.txt. La seconda opzione è rimuovere il requisito di autenticazione.
- 403 Proibito
Questo errore è simile all'errore 401. L'errore 403 si verifica perché la pagina contiene collegamenti non accessibili al pubblico.

Come sistemarlo:
Modificare il requisito nel server per consentire l'accesso alla pagina (solo se si tratta di un errore). Se desideri che questa pagina sia inaccessibile, rimuovi tutti i collegamenti interni ed esterni dalla pagina.
- 400 Richiesta errata
Ciò si verifica quando il browser non riesce a comunicare con il server web. Questo errore si verifica comunemente per una sintassi URL errata.
Come sistemarlo:
Trova i collegamenti a questi URL e correggi la sintassi. Se questo non è risolvibile, dovrai contattare lo sviluppatore web per risolverli.
Nota: possiamo trovare 400 errori con gli strumenti o in Google Console

5) Mappe del sito
La mappa del sito è un elenco di tutti gli URL contenuti nel sito web. Avere una mappa del sito migliora la reperibilità perché aiuta i crawler a trovare e comprendere i tuoi contenuti.
Abbiamo diversi tipi di mappe del sito e dobbiamo assicurarci che siano tutte in buone condizioni.
Le mappe del sito che dovremmo avere sono:
- Mappa del sito HTML: sarà sul tuo sito web e aiuterà gli utenti a navigare e trovare le pagine del tuo sito web
- Mappa del sito XML: questo è un file che aiuterà i motori di ricerca a eseguire la scansione del tuo sito web (come best practice dovrebbe essere incluso nel tuo file robots.txt).
- Mappa del sito XML video: come sopra.
- Immagini Mappa del sito XML: è anche la stessa di cui sopra. Si consiglia di creare mappe del sito separate per immagini, video e contenuti.
Per i siti Web di grandi dimensioni, si consiglia di disporre di diverse Sitemap per una migliore scansione, poiché le Sitemap non devono contenere più di 50.000 URL.
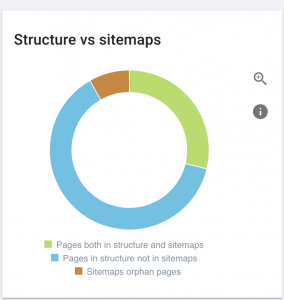
Questo sito ha problemi con la mappa del sito.
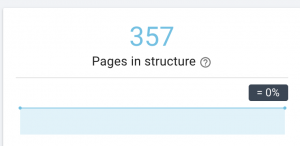
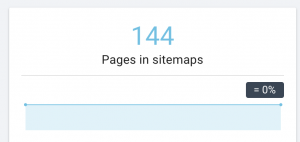
Come lo risolviamo:
Risolviamo questo problema generando mappe del sito diverse per: contenuto, immagini e video. Quindi, li inviamo tramite Google Search Console e creiamo anche una mappa del sito HTML per il sito web. Non abbiamo bisogno di uno sviluppatore web per questo. Possiamo utilizzare qualsiasi strumento online gratuito per generare mappe del sito.
6) HTTP/HTTPS (contenuto duplicato)
Molti siti Web presentano questi problemi a causa della migrazione da HTTP a HTTPS. In tal caso, il sito Web mostrerà le versioni HTTP e HTTPS nei motori di ricerca. In conseguenza di questo problema tecnico comune, le classifiche vengono diluite. Questi problemi generano anche problemi di contenuto duplicato.
![]()

Come sistemarlo:
Chiedi a uno sviluppatore web di risolvere questo problema forzando tutti gli HTTP su HTTPS.
Nota : non reindirizzare mai tutti gli HTTP alla home page di HTTPS perché genererà errori 404 morbidi. (Dovresti dirlo allo sviluppatore web; ricorda che non sono SEO.)
7) Impaginazione
Questo è l'uso di un tag HTML ("rel = prev" e "rel = next") che stabilisce le relazioni tra le pagine e mostra ai motori di ricerca che i contenuti presentati in pagine diverse devono essere identificati o correlati a una singola. L'impaginazione serve per limitare il contenuto per UX e il peso di una pagina per la parte tecnica, mantenendoli sotto i 3MB. Possiamo usare uno strumento gratuito per controllare l'impaginazione.
L'impaginazione dovrebbe avere riferimenti auto-canonici e indicare un "rel = prev" e "rel = next". Le uniche informazioni duplicate saranno il meta titolo e la meta descrizione, ma questo può essere modificato dagli sviluppatori per creare un piccolo algoritmo in modo che ogni pagina abbia un meta titolo e una meta descrizione generati.
Come sistemarlo:
Chiedi a uno sviluppatore web di implementare tag HTML di impaginazione con tag autocanonici.
Crawler SEO Oncrawl
 Decouvrir
Decouvrir8) Pagina personalizzata 404 non trovata
Una risposta 404 è, come abbiamo discusso prima, un errore " Non trovato " che porta gli utenti a un collegamento interrotto o a una pagina inesistente. Questa è un'opportunità per reindirizzare gli utenti nel posto giusto. Ci sono ottimi esempi di 404 pagine personalizzate. Questo è un must.
Ecco un esempio di una fantastica pagina personalizzata 404:

Come sistemarlo:
Crea una pagina 404 personalizzata: pensa a qualcosa di straordinario da aggiungere. Trasforma questo errore in un'opportunità per la tua attività.
9) Profondità/struttura del sito
La profondità della pagina è il numero di clic che la tua pagina si trova dal dominio principale. John Mueller di Google ha affermato che "le pagine più vicine alla home page hanno più peso". Immaginiamo ad esempio che la pagina qui presente richieda la seguente navigazione per essere raggiunta:

La pagina "tappeti" è a 4 clic dalla home page. Si consiglia di non avere pagine che si trovano a più di 4 clic di distanza da casa, poiché i motori di ricerca hanno difficoltà a eseguire la scansione di pagine più profonde.
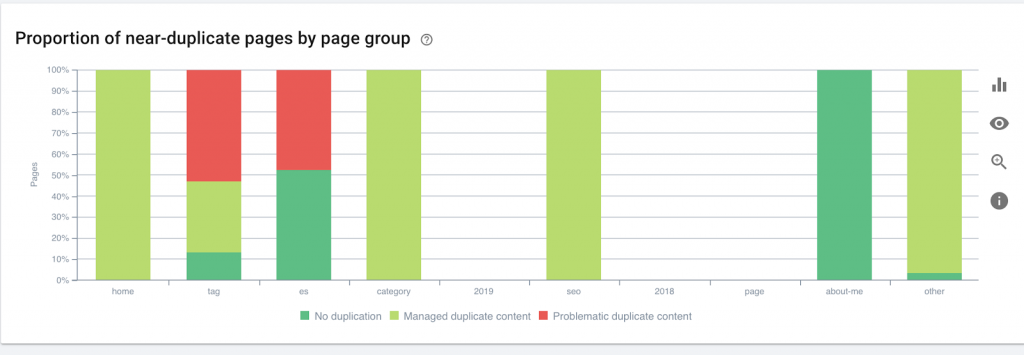
Questo grafico mostra il gruppo di pagine per profondità. Ci aiuta a capire se la struttura di un sito web ha bisogno di essere rielaborata.
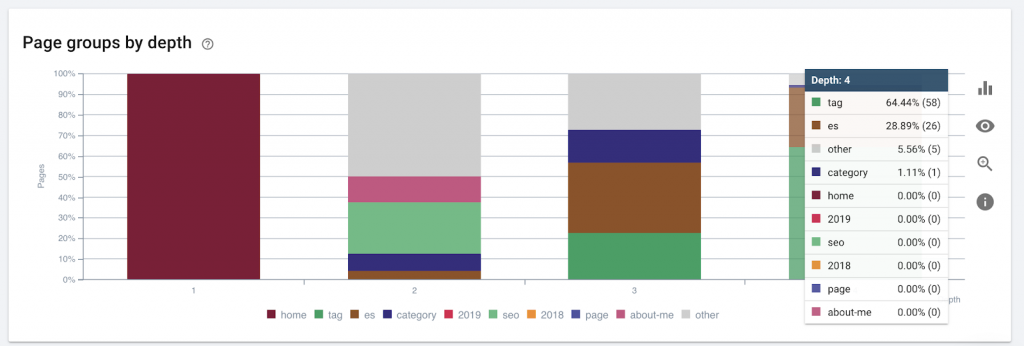
Come sistemarlo:
Le pagine più importanti dovrebbero essere più vicine alla homepage per UX, per un facile accesso da parte degli utenti e per una migliore struttura del sito web. È molto importante tenerne conto al momento della creazione della struttura di un sito Web o della ristrutturazione di un sito Web.
10. Catene di reindirizzamento
Una catena di reindirizzamento è quando si verifica una serie di reindirizzamenti tra gli URL. Queste catene di reindirizzamento possono anche creare loop. Presenta anche problemi a Googlebot e spreca il crawl budget.
Possiamo identificare le catene di reindirizzamenti utilizzando il percorso di reindirizzamento dell'estensione di Chrome o in OnCrawl.
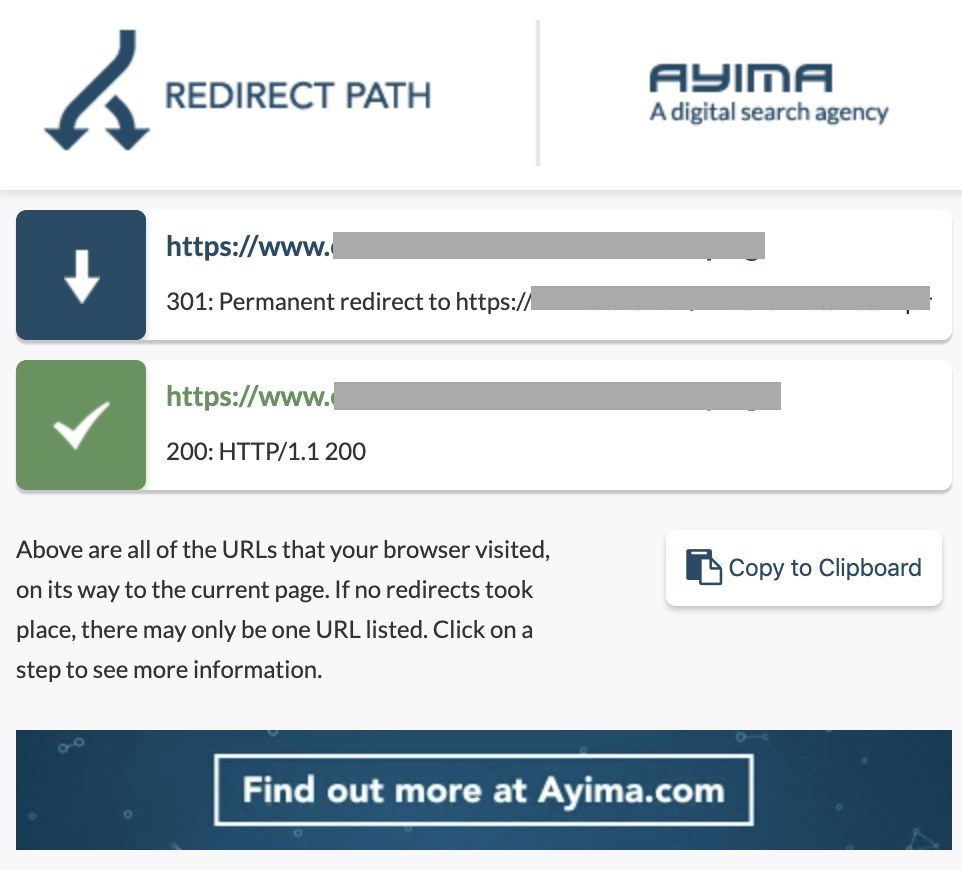
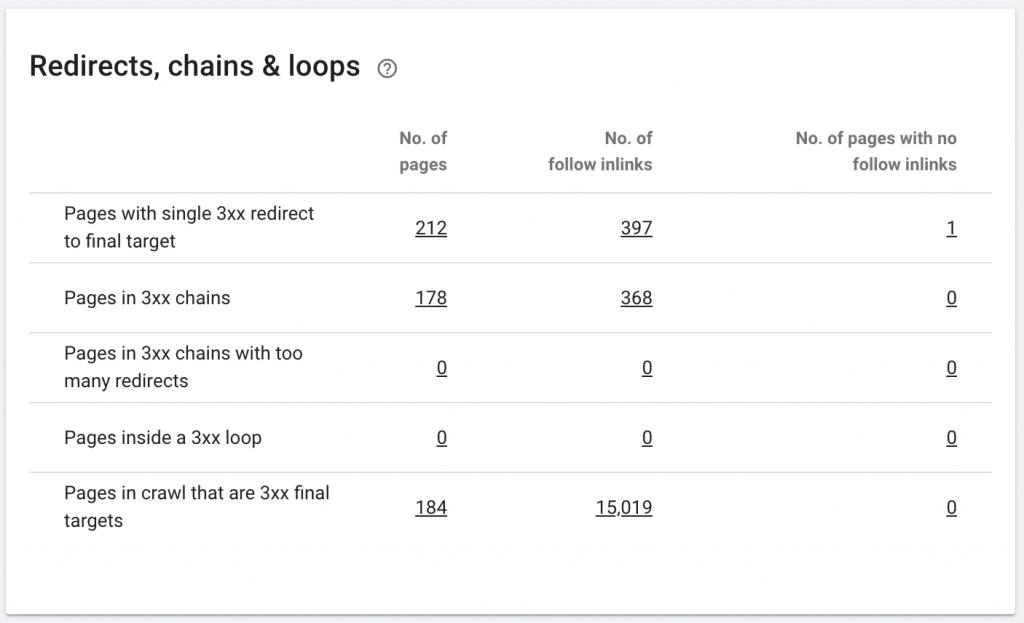
Come sistemarlo:
Risolvere questo problema è davvero facile se stai lavorando con un sito Web WordPress. Vai al reindirizzamento e cerca la catena: elimina tutti i collegamenti coinvolti nella catena se tali modifiche sono avvenute più di 2-3 mesi fa e lascia semplicemente l'ultimo reindirizzamento all'URL corrente. Gli sviluppatori Web possono anche aiutare con questo apportando tutte le modifiche richieste nel file .htacces, se necessario. Puoi controllare e modificare le lunghe catene di reindirizzamento nei tuoi plugin SEO.
11) Canonici
Un tag canonico dice ai motori di ricerca che l'URL è una copia di un'altra pagina. Questo è un grosso problema presente su molti siti web. Non implementare i canonici nel modo giusto, o non implementarli affatto, creerà problemi di contenuto duplicati.
I Canonical sono comunemente usati nei siti di e-commerce in cui un prodotto può essere trovato più volte in diverse categorie come: taglia, colore, ecc.

Puoi utilizzare OnCrawl per sapere se le tue pagine hanno tag canonici e se sono implementati correttamente o meno. È quindi possibile esplorare e correggere eventuali problemi.
Come lo risolviamo:
Possiamo risolvere problemi canonici utilizzando Yoast SEO se stiamo lavorando in WordPress. Andiamo sulla dashboard di WordPress e poi su Yoast -setting - advanced.
Esecuzione del tuo audit
I SEO che vogliono iniziare ad approfondire la SEO tecnica hanno bisogno di una guida di passaggi rapidi da seguire per migliorare la salute della SEO. Parlando di SEO tecnico con John Shehata, il vicepresidente di Audience Grow presso Conde Nast e fondatore di NewzDash in occasione del Global Marketing Day a New York lo scorso ottobre 2019.
Ecco cosa mi ha detto:
“Molte persone nel settore SEO non sono tecniche. Ora, non tutti i SEO capiscono come programmare ed è difficile chiedere alle persone di farlo. Alcune aziende, quello che fanno è assumere sviluppatori e addestrarli a diventare SEO per colmare il divario tecnico SEO ".
A mio avviso, i SEO che non hanno la conoscenza completa del codice possono comunque fare grandi cose in Tech SEO sapendo come eseguire un audit, identificare gli elementi chiave, creare report, chiedere agli sviluppatori web l'implementazione e infine testare le modifiche.
Pronto per iniziare? Scarica l'elenco di controllo per questi problemi principali.
