
Valutazione della qualità delle previsioni di impatto causale
Pubblicato: 2022-02-15CausalImpact è uno dei pacchetti più popolari utilizzati nella sperimentazione SEO. La sua popolarità è comprensibile.
La sperimentazione SEO fornisce spunti interessanti e modi per i SEO di riferire sul valore del loro lavoro.
Tuttavia, l'accuratezza di qualsiasi modello di apprendimento automatico dipende dalle informazioni di input che gli vengono fornite.
In poche parole, l'input errato può restituire la stima errata.
In questo post, mostreremo quanto possa essere affidabile (e inaffidabile) CausalImpact. Impareremo anche come acquisire maggiore sicurezza nei risultati dei tuoi esperimenti.
In primo luogo, forniremo una breve panoramica di come funziona CausalImpact. Quindi, discuteremo l'affidabilità delle stime di CausalImpact. Infine, impareremo una metodologia che può essere utilizzata per stimare i risultati dei tuoi esperimenti SEO.
Cos'è l'impatto causale e come funziona?
CausalImpact è un pacchetto che utilizza le statistiche bayesiane per stimare l'effetto di un evento in assenza di un esperimento. Questa stima è chiamata inferenza causale.
L'inferenza causale stima se un cambiamento osservato è stato causato da un evento specifico.
Viene spesso utilizzato per valutare le prestazioni degli esperimenti SEO.
Ad esempio, quando viene indicata la data di un evento, CausalImpact (CI) utilizzerà i punti dati prima dell'intervento per prevedere i punti dati dopo l'intervento. Confronterà quindi la previsione con i dati osservati e stimerà la differenza con una certa soglia di confidenza.
Inoltre, i gruppi di controllo possono essere utilizzati per rendere le previsioni più accurate.
Diversi parametri avranno anche un impatto sull'accuratezza della previsione:
- Dimensione dei dati di prova.
- Durata del periodo prima dell'esperimento.
- Scelta del gruppo di controllo da confrontare.
- Iperparametri di stagionalità.
- Numero di iterazioni.
Tutti questi parametri aiutano a fornire più contesto al modello e migliorarne l'affidabilità.
Scansione BI
 Scoprire
ScoprirePerché è importante valutare l'accuratezza degli esperimenti SEO?
Negli anni passati ho analizzato molti esperimenti SEO e qualcosa mi ha colpito.
Molte volte, l'utilizzo di diversi gruppi di controllo e tempistiche su set di test identici e date di intervento ha prodotto risultati diversi.
A titolo illustrativo, di seguito sono riportati due risultati dello stesso evento.
Il primo ha restituito un calo statisticamente significativo. 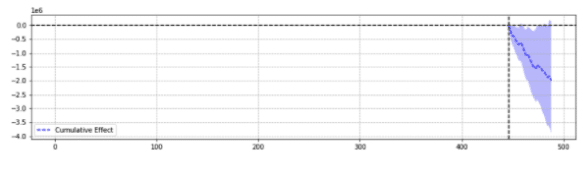
Il secondo non era statisticamente significativo. 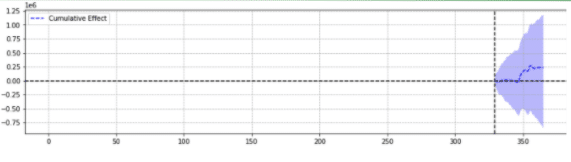
In poche parole, per lo stesso evento, sono stati restituiti risultati diversi in base ai parametri scelti.
Ci si deve chiedere quale previsione sia accurata.
Alla fine, "statisticamente significativo" non dovrebbe aumentare la fiducia nelle nostre stime?
Definizioni
Per comprendere meglio il mondo degli esperimenti SEO, il lettore dovrebbe essere a conoscenza dei concetti base degli esperimenti SEO:
- Esperimento : una procedura intrapresa per verificare un'ipotesi. Nel caso di inferenza causale, ha una data di inizio specifica.
- Gruppo di test : un sottoinsieme di dati a cui viene applicata una modifica. Può essere un intero sito Web o una parte del sito.
- Gruppo di controllo : un sottoinsieme di dati a cui non è stata applicata alcuna modifica. Puoi avere uno o più gruppi di controllo. Può trattarsi di un sito separato nello stesso settore o di una parte diversa dello stesso sito.
L'esempio seguente aiuterà a illustrare questi concetti:
La modifica del titolo (esperimento) dovrebbe aumentare il CTR organico dell'1% (ipotesi) delle pagine dei prodotti in cinque città (gruppo di test). Le stime verranno migliorate utilizzando un titolo invariato su tutte le altre città (gruppo di controllo).
Pilastri di una previsione accurata degli esperimenti SEO
- Per semplicità, ho raccolto alcuni spunti interessanti per i professionisti SEO che imparano a migliorare la precisione degli esperimenti:
- Alcuni input in CausalImpact restituiranno stime errate, anche se statisticamente significative. Questo è ciò che chiamiamo "falsi positivi" e "falsi negativi".
- Non esiste una regola generale che determini quale controllo utilizzare rispetto a un set di test. È necessario un esperimento per definire i migliori dati di controllo da utilizzare per un set di test specifico.
- L'uso di CausalImpact con il giusto controllo e la giusta lunghezza dei dati pre-periodo può essere molto preciso, con un errore medio di appena 0,1%.
- In alternativa, l'utilizzo di CausalImpact con il controllo sbagliato può portare a un forte tasso di errore. Gli esperimenti personali hanno mostrato variazioni statisticamente significative fino al 20%, quando in realtà non ci sono state variazioni.
- Non tutto può essere testato. Alcuni gruppi di test non restituiscono quasi mai stime accurate.
- Gli esperimenti con o senza gruppi di controllo richiedono lunghezze di dati diverse prima dell'intervento.
Non tutti i gruppi di test restituiranno stime accurate
Alcuni gruppi di test restituiranno sempre previsioni imprecise. Non dovrebbero essere usati per la sperimentazione.
I gruppi di test con grandi variazioni di traffico anormali spesso restituiscono risultati inaffidabili.
Ad esempio, nello stesso anno un sito Web ha subito una migrazione del sito, è stato colpito dalla pandemia di covid e una parte del sito è stata "non indicizzata" per 2 settimane a causa di un errore tecnico. Fare esperimenti su quel sito fornirà risultati inaffidabili.
I risultati di cui sopra sono stati raccolti attraverso un'ampia serie di test effettuati utilizzando la metodologia descritta di seguito.
Quando non si utilizzano i gruppi di controllo
- L'utilizzo di un controllo invece di un semplice pre-post può aumentare fino a 18 volte la precisione della stima.
- L'utilizzo di 16 mesi di dati precedenti era preciso come l'utilizzo di 3 anni.
Quando si utilizzano i gruppi di controllo
- Usare il controllo giusto è spesso meglio che usare più controlli. Tuttavia, un unico controllo aumenta i rischi di previsioni errate nei casi in cui il traffico del controllo varia molto.
- La scelta del controllo giusto può aumentare la precisione di 10 volte (ad es. uno riporta +3,1% e l'altro +4,1% quando in realtà era +3%).
- La maggior parte dei modelli di traffico correlati tra dati di test e dati di controllo non significano necessariamente stime migliori.
- L'utilizzo di 16 mesi di dati precedenti NON era preciso come l'utilizzo di 3 anni.
Fai attenzione alla lunghezza dei dati prima degli esperimenti
È interessante notare che, durante la sperimentazione con i gruppi di controllo, l'utilizzo di 16 mesi di dati precedenti può causare un tasso di errore molto intenso.
In effetti, gli errori possono essere grandi quanto stimare un aumento di 3 volte il traffico quando non ci sono state modifiche effettive.
Tuttavia, l'utilizzo di 3 anni di dati ha rimosso tale tasso di errore. Ciò è in contrasto con i semplici esperimenti pre-post in cui tale tasso di errore non è stato aumentato aumentando la durata da 16 a 36 mesi.
Ciò non significa che l'uso dei controlli sia dannoso. È proprio il contrario.

Mostra semplicemente come l'aggiunta del controllo influisca sulle previsioni.
Questo è il caso in cui ci sono grandi variazioni nel gruppo di controllo.
Questo takeaway è particolarmente importante per i siti Web che hanno avuto variazioni di traffico anomale nell'ultimo anno (errore tecnico critico, pandemia COVID, ecc.).
Come valutare la previsione dell'impatto causale?
Ora, nella libreria CausalImpact non è presente alcun punteggio di accuratezza. Quindi, si deve dedurre diversamente.
Si può osservare come altri modelli di machine learning stimano l'accuratezza delle loro previsioni e rendersi conto che la Sum of Squares Errors (SSE) è una metrica molto comune.
La somma degli errori ai quadrati, o somma residua dei quadrati, calcola la somma di tutte le (n) differenze tra le aspettative (yi) e i risultati effettivi (f(xi)), al quadrato. 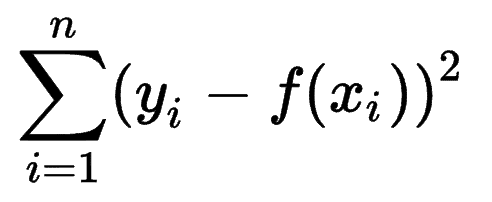
Più basso è il SSE, migliore è il risultato.
La sfida è che con gli esperimenti pre-post sul traffico SEO, non ci sono risultati effettivi.
Sebbene non siano state apportate modifiche in loco, alcune modifiche potrebbero essere avvenute al di fuori del tuo controllo (ad es. aggiornamento dell'algoritmo di Google, nuovo concorrente, ecc.). Anche il traffico SEO non varia di un numero fisso, ma varia progressivamente su e giù.
Gli specialisti SEO potrebbero chiedersi come superare la sfida.
Presentazione delle varianti false
Per essere certo dell'entità della variazione causata da un evento, lo sperimentatore può introdurre variazioni fisse in diversi momenti e vedere se CausalImpact ha stimato con successo il cambiamento.
Ancora meglio, l'esperto SEO può ripetere il processo per diversi gruppi di test e controllo.
Utilizzando Python, sono state introdotte variazioni fisse ai dati in date di intervento diverse per il periodo successivo.
La somma degli errori ai quadrati è stata quindi stimata tra la variazione riportata da CausalImpact e la variazione introdotta.
L'idea è questa:
- Scegli un test e controlla i dati.
- Introdurre falsi interventi nei dati reali in date diverse (es. aumento del 5%).
- Confronta le stime di CausalImpact con ciascuna delle variazioni introdotte.
- Calcola la somma degli errori dei quadrati (SSE).
- Ripetere il passaggio 1 con più controlli.
- Scegli il controllo con il più piccolo SSE per esperimenti nel mondo reale
La metodologia
Con la metodologia seguente, ho creato una tabella che ho potuto utilizzare per identificare quale controllo presentava i tassi di errore migliori e peggiori in momenti diversi.
Per prima cosa, scegli un test e controlla i dati e introduci variazioni da -50% a 50%.
Quindi, esegui CausalImpact (CI) e sottrai le variazioni riportate da CI alla variazione che hai effettivamente introdotto.
Dopo, calcola i quadrati di queste differenze e somma tutti i valori insieme.
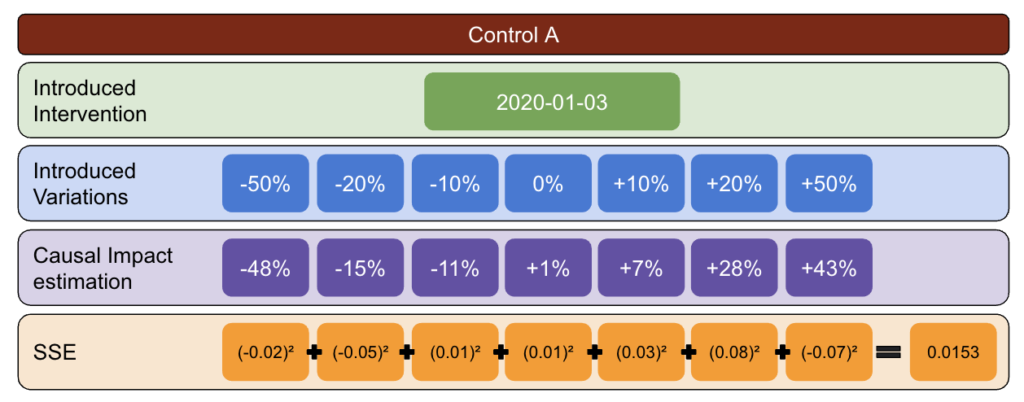
Quindi, ripeti lo stesso processo in date diverse per ridurre il rischio di una distorsione causata da una variazione reale in una data specifica.
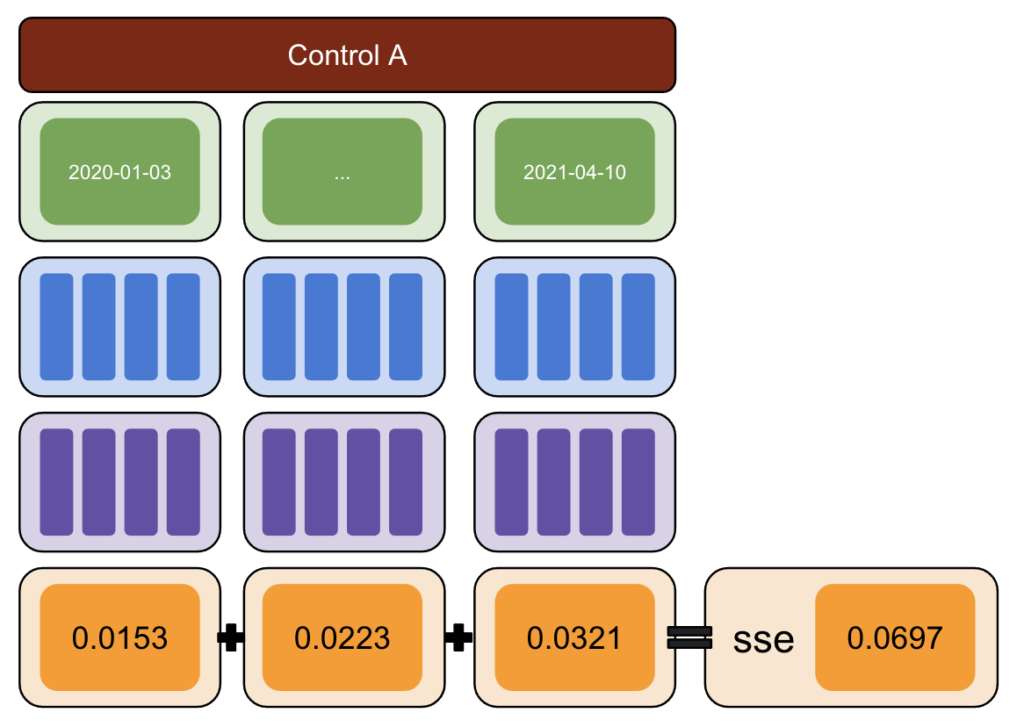
Ancora una volta, ripeti con più gruppi di controllo.
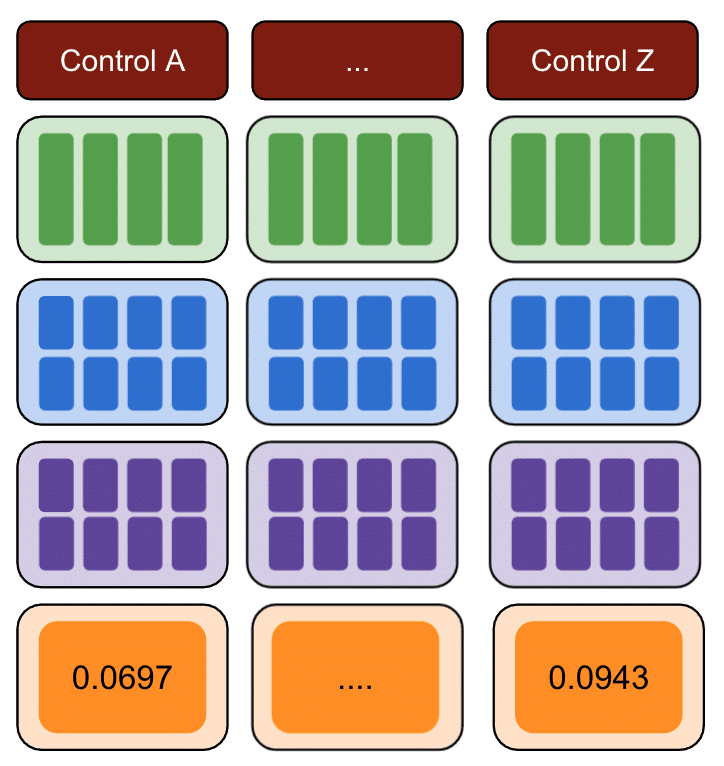
Infine, il controllo con la somma più piccola di errori quadrati è il miglior gruppo di controllo da utilizzare per i dati del test.
Se ripeti ciascuno dei passaggi per ciascuno dei dati del test, il risultato varierà.
Nella tabella risultante, ogni riga rappresenta un gruppo di controllo, ogni colonna rappresenta un gruppo di test. I dati all'interno sono SSE.
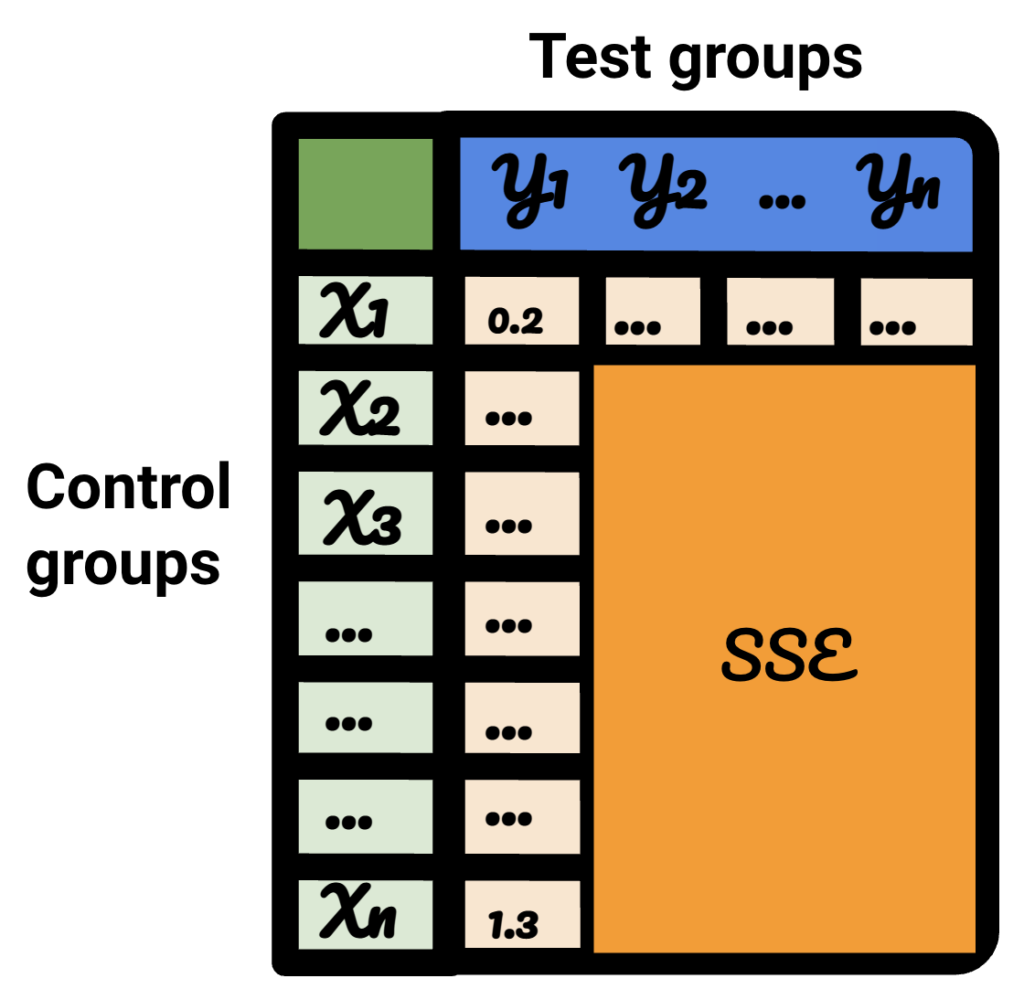
Ordinando quella tabella, ora sono sicuro di poter selezionare il miglior gruppo di controllo per ciascuno dei gruppi di test.
Dovremmo usare i gruppi di controllo o no?
L'evidenza mostra che l'uso dei gruppi di controllo aiuta ad avere stime migliori rispetto al semplice pre-post.
Tuttavia, questo è vero solo se scegliamo il gruppo di controllo giusto.
Quanto dovrebbe essere lungo il periodo di stima?
La risposta dipende dai controlli che stiamo selezionando.
Quando non si utilizza un controllo, l'esperimento di 16 mesi prima sembra sufficiente.
Quando si utilizza un controllo, l'utilizzo di soli 16 mesi può portare a enormi tassi di errore. Usare 3 anni aiuta a ridurre il rischio di interpretazioni errate.
Dovremmo usare 1 controllo o controlli multipli?
La risposta a questa domanda dipende dai dati del test.
Dati di test molto stabili possono funzionare bene se confrontati con più controlli. In questo caso, questo è positivo perché l'uso di molti controlli rende il modello meno influenzato da fluttuazioni insospettate in uno dei controlli.
In altri set di dati, l'utilizzo di più controlli può rendere il modello 10-20 volte meno preciso rispetto all'utilizzo di uno solo.
Lavoro interessante nella comunità SEO
CausalImpact non è l'unica libreria che può essere utilizzata per i test SEO, né la metodologia di cui sopra è l'unica soluzione per testarne l'accuratezza.
Per conoscere soluzioni alternative, leggi alcuni degli incredibili articoli condivisi dalle persone della community SEO.
In primo luogo, Andrea Volpini ha scritto un articolo interessante sulla misurazione dell'efficacia SEO utilizzando l'analisi di impatto causale.
Quindi, Daniel Heredia ha coperto il pacchetto Prophet di Facebook per la previsione del traffico SEO con Prophet e Python.
Sebbene la biblioteca del Profeta sia più appropriata per le previsioni che per gli esperimenti, vale la pena imparare varie biblioteche per acquisire una solida conoscenza del mondo delle previsioni.
Infine, sono stato molto contento della presentazione di Sandy Lee al SEO di Brighton, dove ha condiviso le informazioni sulla scienza dei dati per i test SEO e ha sollevato alcune delle insidie dei test SEO.
Cose da considerare quando si fanno esperimenti SEO
- Gli strumenti di split test SEO di terze parti sono ottimi ma possono anche essere imprecisi. Sii accurato quando scegli la tua soluzione.
- Anche se ne ho scritto in passato, non è possibile eseguire esperimenti di split test SEO con Google Tag Manager, a meno che non sia lato server. Il modo migliore è distribuire tramite CDN.
- Sii audace durante il test. I piccoli cambiamenti di solito non vengono rilevati da CausalImpact.
- I test SEO non dovrebbero essere sempre la tua prima scelta.
- Esistono alternative per testare modifiche più piccole come i tag del titolo. Test A/B di Google Ads o test A/B su piattaforma. I test A/B reali sono più accurati dello split test SEO e di solito forniscono maggiori informazioni sulla qualità dei tuoi titoli.
Risultati riproducibili
In questo tutorial, volevo concentrarmi su come migliorare l'accuratezza degli esperimenti SEO senza l'onere di sapere come programmare. Inoltre, la fonte dei dati può variare e ogni sito è diverso.
Quindi, il codice Python che ho usato per produrre questo contenuto non faceva parte dello scopo di questo articolo.
Tuttavia, con la logica, puoi riprodurre gli esperimenti di cui sopra.
Conclusione
Se avessi solo un takeaway da ottenere da questo articolo, sarebbe che l'analisi CausalImpact può essere molto accurata, ma può sempre essere lontana.
È molto importante per i SEO che desiderano utilizzare questo pacchetto per capire con cosa hanno a che fare. Il risultato del mio viaggio è che non mi fiderei di CausalImpact senza prima testare l'accuratezza del modello sui dati di input.