
Potenziare la sicurezza bancaria: machine learning per il rilevamento delle frodi
Pubblicato: 2023-11-14Con ogni opportunità arriva una minaccia. Il passaggio alla digitalizzazione nel settore bancario ha migliorato l’esperienza del cliente e ampliato la base di clienti a popolazioni precedentemente prive di servizi bancari. Lo svantaggio è che le transazioni online e le soluzioni di pagamento digitale hanno aperto nuove strade da sfruttare per i truffatori.
I risultati di un sondaggio sulle frodi di KMPG indicano che gli attacchi informatici stanno aumentando in frequenza e gravità, provocando perdite per miliardi di dollari.
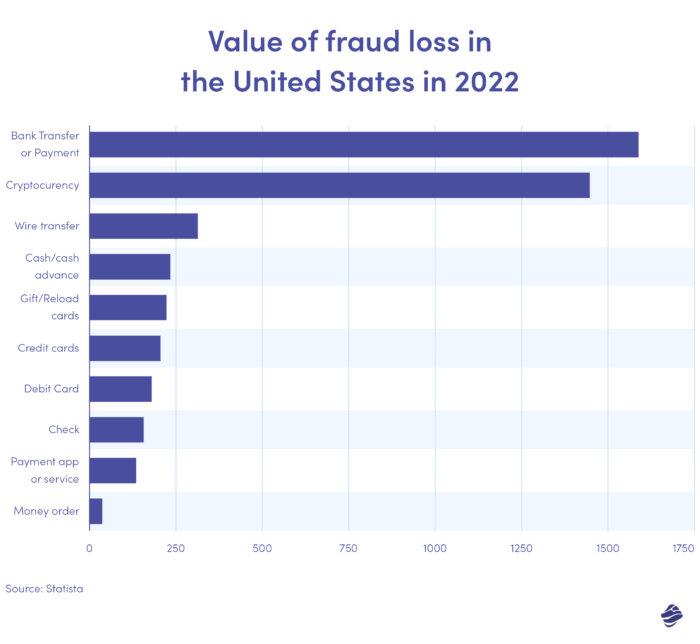
Il grafico sopra illustra il valore delle perdite dovute a frode per metodo di pagamento negli Stati Uniti nel 2022. I bonifici e i pagamenti bancari sono stati i più elevati, con una perdita di 1,59 miliardi di dollari.
Queste perdite hanno costretto gli istituti bancari ad adottare nuove soluzioni per rilevare, mitigare e prevenire le frodi finanziarie. Uno di questi metodi è l’intelligenza artificiale (AI), in particolare l’apprendimento automatico.
In questo articolo discuteremo di tutto ciò che devi sapere sull'apprendimento automatico per il rilevamento delle frodi , inclusi vantaggi e applicazioni nella vita reale.
Evoluzione del rilevamento delle frodi
Il tradizionale rilevamento delle frodi segue un approccio basato su regole. Come suggerisce il nome, opera secondo una serie di regole o condizioni che determinano se una transazione è autentica o fraudolenta. Le condizioni comuni includono il luogo (l'acquisto è fuori dall'area abituale dell'utente?) e la frequenza (il numero e il tipo di acquisto sono abituali per l'utente?).
Una transazione viene portata a termine solo quando soddisfa le condizioni. Ad esempio, un cliente in Ohio ha improvvisamente un addebito POS in Nuova Zelanda. La posizione è al di fuori del prefisso dell'utente, quindi il sistema contrassegna le transazioni come fraudolente.
Esistono diversi inconvenienti a questo tipo di sistema di rilevamento delle frodi.
- Produce un numero elevato di falsi positivi. Qui è dove blocchi i pagamenti da parte di clienti autentici.
- È inflessibile. L’approccio basato su regole utilizza risultati fissi, rendendo difficile l’adattamento alle tendenze del settore bancario digitale. È necessario modificare le regole per individuare nuove forme di frode.
- Non è in scala. Quando i dati aumentano, aumenta anche lo sforzo necessario per prevenirli. Qualsiasi modifica al sistema viene eseguita manualmente, il che rende l'operazione costosa e dispendiosa in termini di tempo.
Il rilevamento delle frodi basato su regole funziona. Tuttavia, i suoi svantaggi lo rendono inadatto ai moderni ambienti digitali. Non è in grado di riconoscere modelli e si basa sull'intervento umano.
Inoltre, gli hacker non rispettano un orario di lavoro dalle 9 alle 5 e possono implementare metodi sofisticati come lo spoofing della posizione e la imitazione del comportamento dei clienti per ingannare i sistemi di rilevamento delle frodi. Pertanto, è necessario un sistema altrettanto avanzato che funzioni 24 ore su 24, 7 giorni su 7.
Entra nell'apprendimento automatico.
L'apprendimento automatico è un'intelligenza artificiale (AI) che utilizza i dati per addestrare algoritmi di rilevamento delle frodi per scoprire modelli e relazioni di dati, acquisire informazioni e fare previsioni.
Hai già familiarità con l'apprendimento automatico, anche se non lo conosci. Ad esempio, ogni volta che interagisci con un post di Instagram, fornisci all'algoritmo informazioni sul tipo di contenuto che ti piace. Quindi esamina l'app alla ricerca di contenuti simili da aggiungere al tuo feed.
Come il machine learning trasformerà il rilevamento delle frodi
Il rilevamento delle frodi nel settore bancario utilizzando l’apprendimento automatico sta già cambiando il settore, con un’identificazione e una risposta alle frodi più rapida, flessibile e accurata.
Il sistema di intelligenza artificiale analizza i modelli nei dati dei clienti e modifica automaticamente le regole in base alle minacce storiche ed emergenti.
Ricordi la tariffa POS neozelandese di cui abbiamo parlato prima? Il rilevamento delle frodi tramite l’apprendimento automatico considererebbe che la stessa carta bancaria ha un acquisto per un volo verso quella località. Pertanto, il nuovo addebito è molto probabilmente legittimo.
Vengono utilizzati due modelli per addestrare gli algoritmi a rilevare le frodi: apprendimento automatico supervisionato e apprendimento automatico non supervisionato.
Apprendimento automatico supervisionato
Il modello di apprendimento supervisionato alimenta gli algoritmi con grandi quantità di dati contrassegnati come frode o non frode. L'algoritmo studia questi esempi e apprende quali modelli e relazioni distinguono le transazioni legittime da quelle fraudolente.
Questo modello di apprendimento richiede molto tempo in quanto richiede la codifica manuale dei dati. Inoltre, i tuoi set di dati devono essere correttamente etichettati e ben organizzati. Una transazione contrassegnata in modo errato influirà sull'accuratezza dell'algoritmo.
Inoltre, apprende solo dagli input inclusi nel set di formazione. Pertanto, le transazioni tramite le funzionalità dell'app di mobile banking appena lanciate che non facevano parte dei dati storici non verrebbero contrassegnate. Ora esiste una scappatoia che i truffatori possono sfruttare.
Apprendimento automatico non supervisionato
Il modello di apprendimento non supervisionato utilizza un input umano minimo. L'algoritmo apprende modelli e relazioni da grandi quantità di dati senza tag, raggruppando set di dati in base a somiglianze e differenze.
L'obiettivo è individuare attività insolite non incluse nel set di dati di addestramento. Pertanto, l’apprendimento non supervisionato riprende laddove l’apprendimento supervisionato si interrompe e rileva nuove frodi.
Ricorda che non devi scegliere tra un modello di machine learning supervisionato o non supervisionato. Puoi usarli insieme (modello di apprendimento semi-supervisionato) o in modo indipendente.
Vantaggi dell'utilizzo del machine learning per il rilevamento delle frodi
Abbiamo accennato ai vantaggi del rilevamento delle frodi utilizzando l'apprendimento automatico nel settore bancario, ma ne discuteremo ulteriormente.
- Velocità
I calcoli basati sull’apprendimento automatico avvengono rapidamente e forniscono decisioni sulle frodi in tempo reale. Sebbene anche gli algoritmi basati su regole decidano in tempo reale, si affidano a regole scritte per segnalare le frodi.
Cosa succede in nuovi scenari senza regole predefinite? Porta a falsi positivi o falsi negativi.
L'apprendimento automatico rileva automaticamente nuovi modelli, analizzando l'attività regolare dei clienti e calcolando i risultati appropriati in pochi millisecondi.
- Precisione
I sistemi di rilevamento basati su regole bloccano le transazioni autentiche o consentono quelle fraudolente perché non rilevano le sfumature nel comportamento dei clienti.
I sistemi di apprendimento automatico considerano le variabili che vanno oltre le regole scritte, ad esempio il comportamento fraudolento noto. Queste variabili aiutano a contestualizzare la transazione, abbassando il tasso di falsi positivi.
- Flessibilità
L’apprendimento automatico è flessibile e reattivo. La capacità di autoapprendimento consente a questo sistema di adattarsi a nuovi scenari e di rilevare nuove minacce. I sistemi basati su regole sono rigidi e non hanno capacità di apprendimento. Pertanto, può rispondere alle attività fraudolente solo secondo regole predefinite.
- Efficienza
Gli algoritmi di apprendimento automatico possono analizzare migliaia di dati di transazioni al secondo. Invece di spendere manodopera e spese generali per indagare su casi di frode da bassi a moderati, l’apprendimento automatico può elaborare frodi ripetitive o evidenti. Consente agli specialisti delle frodi di concentrarsi su modelli complessi che necessitano di informazioni umane.
- Scalabilità
L’aumento del volume di dati mette sotto pressione i sistemi basati su regole. Le nuove regole aumentano la complessità del sistema, rendendone difficile la manutenzione. Qualsiasi errore o contraddizione può rendere inefficace l’intero modello.
I sistemi di apprendimento automatico sono l’opposto. Non solo assimilano grandi volumi di nuovi dati, ma li migliorano anche.
Tecniche di machine learning utilizzate nel rilevamento delle frodi
Prima di esaminare i diversi algoritmi utilizzati nel rilevamento delle frodi tramite intelligenza artificiale, diamo una panoramica di come funziona il sistema.
Il primo passo è l'immissione dei dati. La precisione del modello dipende dal volume e dalla qualità dei dati. Più dati di alta qualità aggiungi, più accurato diventa il modello.
Successivamente, il modello analizza i dati ed estrae le caratteristiche chiave che descrivono i comportamenti normali rispetto a quelli fraudolenti. Queste funzionalità includono l'identità del cliente (e-mail o numero di telefono), la posizione (IP o indirizzo di spedizione), i metodi di pagamento (nome del titolare della carta e paese di origine) e altro ancora.
Il terzo passo è addestrare l'algoritmo (con più dati) a distinguere tra transazioni autentiche e fraudolente. Il modello riceve un set di dati di addestramento e prevede la probabilità di frode in vari casi. Una volta che l'algoritmo è sufficientemente addestrato, sei pronto per avviarlo.
Ora diamo un'occhiata ai vari algoritmi che puoi utilizzare.
1. Regressione logistica
La regressione logistica è un algoritmo di apprendimento supervisionato. Calcola la probabilità di frode su scala binaria – frode o non frode – in base ai parametri del modello.
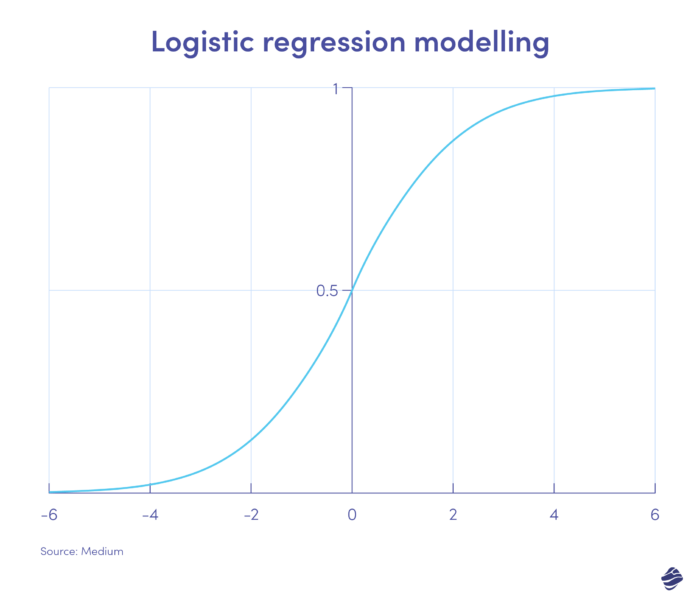
Le transazioni che rientrano nel lato positivo del grafico sono molto probabilmente fraudolente, mentre quelle sul lato negativo sono molto probabilmente legittime.
2. Albero decisionale
Un albero decisionale è un algoritmo di apprendimento supervisionato ma va oltre gli algoritmi di regressione logistica. È una struttura decisionale gerarchica che analizza i dati in livelli per determinare se una transazione è autentica o fraudolenta.
Di seguito è riportata un'illustrazione di un albero decisionale per il rilevamento delle frodi con carte di credito.
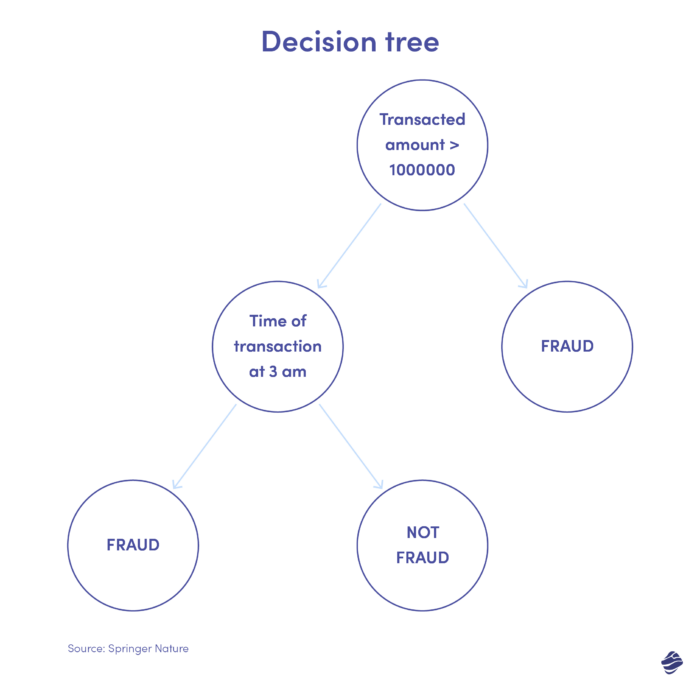
La condizione per identificare se la transazione è fraudolenta è l'importo della transazione. Se il valore della transazione supera una soglia prestabilita, l'algoritmo la considera fraudolenta. In caso contrario, l'albero controlla un'altra condizione: l'ora della transazione. Se l'orario è insolito (qui, le 3 del mattino), è probabile che si tratti di una frode. In caso contrario, controlla un'altra condizione. Si prosegue.
3. Foresta casuale
La foresta casuale è una combinazione di molti alberi decisionali, in cui ciascun albero decisionale verifica condizioni diverse: identità, posizione, ecc.
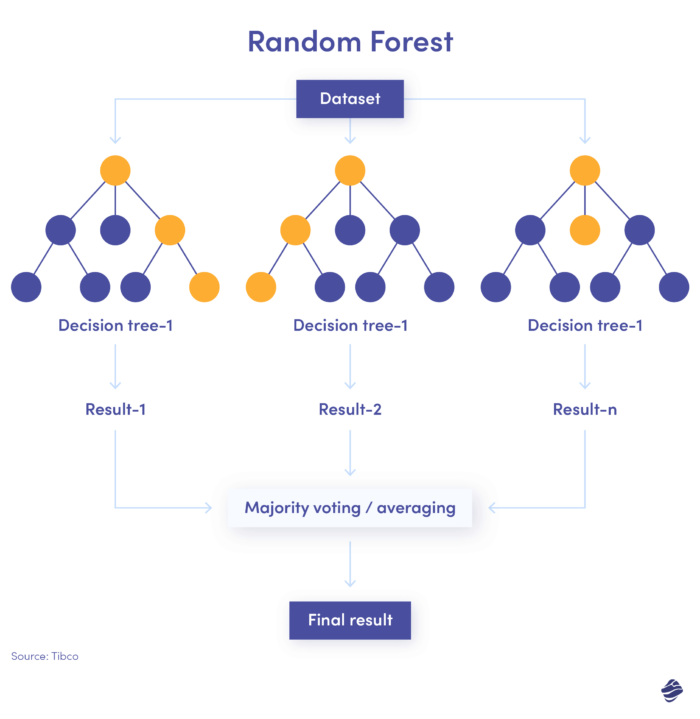
Dopo aver controllato tutti i parametri, ogni sottoalbero offre una decisione. Il totale combinato determina se la transazione è autentica o fraudolenta.

4. Reti neurali
Le reti neurali sono algoritmi complessi e non supervisionati. Ispirate al cervello umano, le reti neurali elaborano i dati su più livelli per estrarre funzionalità di alto livello. Questo algoritmo va di pari passo con il deep learning, che può riconoscere modelli in immagini, testo, audio e altri dati.
Ecco una versione semplificata di una rete neurale.
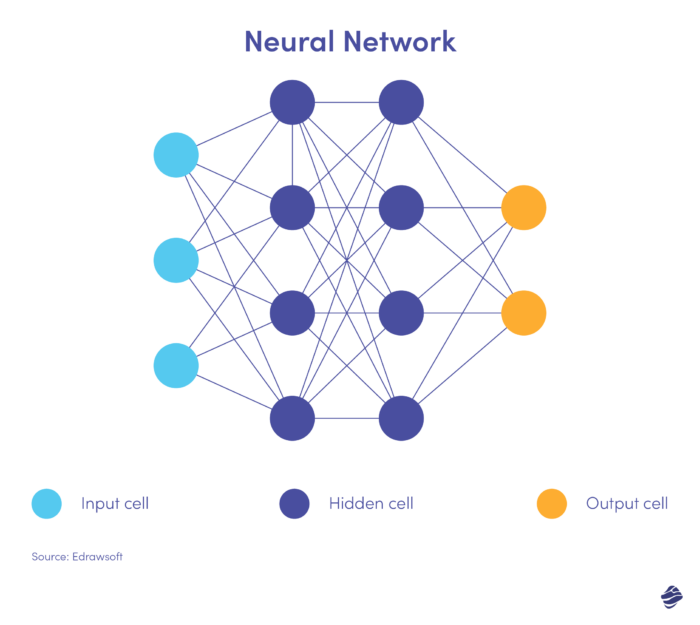
Una rete neurale ha tre livelli: input, nascosto e output. Il livello di input elabora i dati, il livello nascosto analizza i dati dal livello di input per identificare modelli nascosti e il livello di output classifica i dati.
Le reti neurali profonde hanno diversi livelli nascosti. Sono ottimi per identificare relazioni non lineari e rilevare scenari di frode senza precedenti.
5. Supporta la macchina vettoriale
Le Support Vector Machines (SVM) sono algoritmi di apprendimento supervisionato che prevedono, classificano e rilevano valori anomali.
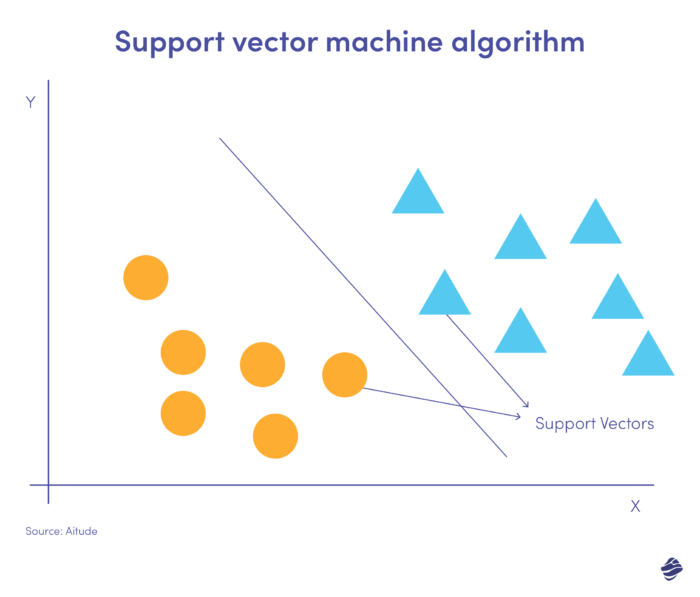
Questa illustrazione SVM lineare mostra due set di dati separati da una linea retta chiamata iperpiano. È il confine decisionale che classifica i dati come frode e non frode.
I punti dati più lontani dall'iperpiano sono facilmente classificabili. I vettori di supporto (più vicini all'iperpiano) sono difficili da classificare. Questi valori anomali possono influenzare la posizione dell'iperpiano se rimossi.
6. K-vicino più vicino
K-nearest neighbor (KNN) è un algoritmo di apprendimento supervisionato. Funziona partendo dal presupposto che elementi simili esistano vicini l'uno all'altro.
Di seguito è riportata una semplice illustrazione.
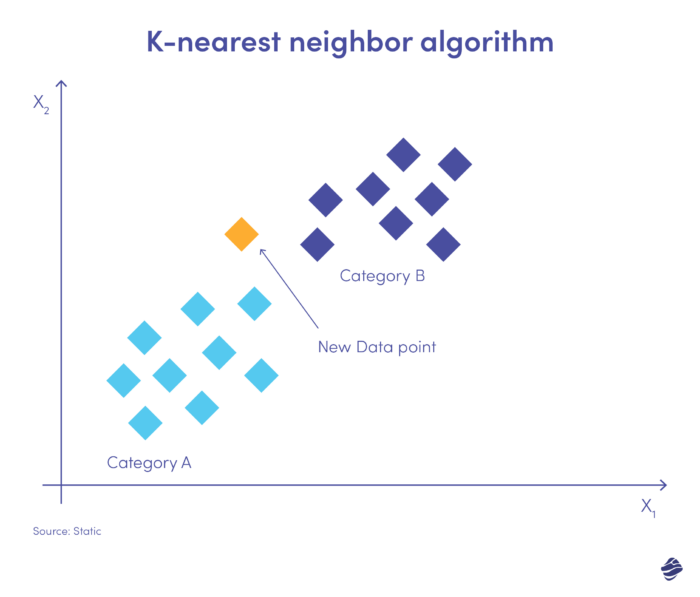
La nuova immissione di dati deve essere inserita nella categoria A o B. L'algoritmo calcola la distanza tra i punti dati utilizzando un'equazione matematica chiamata distanza euclidea. Il nuovo punto dati rientra nel gruppo con il maggior numero di vicini. Se il set di dati più vicino è contrassegnato come "frode", la transazione viene classificata come fraudolenta.
Affrontare sfide e considerazioni strategiche
Come tutta la tecnologia, ci sono crescenti difficoltà associate all’integrazione dell’apprendimento automatico per il rilevamento delle frodi. Ecco alcune sfide comuni che potresti dover affrontare.
Infrastrutture inadeguate
Molti sistemi bancari non sono in grado di analizzare grandi quantità di dati complessi. Inoltre, la maggior parte dei dati viene archiviata e conservata in strutture di archiviazione separate.
Sfortunatamente, non esiste una soluzione rapida a questo problema. È necessario investire nell'hardware e nel software appropriati.
Dovrai collaborare con un'agenzia esperta di sviluppo di app Fintech e configurare un'infrastruttura per selezionare automaticamente gli algoritmi appropriati per set di dati specifici, importare dati grezzi e prepararli per l'apprendimento automatico, visualizzare i dati, testare l'algoritmo e altro ancora.
Qualità e sicurezza dei dati
La qualità dei dati è un problema significativo per le istituzioni finanziarie che desiderano implementare l’apprendimento automatico per il rilevamento delle frodi. I modelli di machine learning non distinguono tra dati buoni e cattivi. Pertanto, se l'algoritmo è contaminato da dati irrilevanti o incompleti, l'accuratezza del modello non sarà corretta.
Le soluzioni di acquisizione dati come Amazon Kinesis raccolgono, puliscono e trasformano i dati grezzi, rendendoli adatti ai modelli di machine learning. Una volta che i dati sono stati puliti e organizzati, è necessario separare i dati sensibili da quelli non sensibili. Crittografare le informazioni riservate e archiviarle in strutture protette. Dovresti anche limitare l'accesso a questi dati.
Mancanza di talento
Nonostante ciò che la gente teme, il machine learning non sta rubando posti di lavoro. È proprio il contrario. Abbiamo ancora bisogno di analisti di frodi per gestire casi complessi che richiedono competenza ed esperienza umana. Inoltre, l’apprendimento automatico è una nuova tecnologia e non ci sono abbastanza esperti nel settore.
Questa è una buona notizia per chi cerca lavoro, ma non per le istituzioni che non riescono a sfruttare appieno il potenziale dell’apprendimento automatico. Puoi superare questo ostacolo collaborando con aziende dotate delle competenze necessarie per implementare l’apprendimento automatico.
Casi di studio sul rilevamento delle frodi nel settore bancario utilizzando l'apprendimento automatico
Ora diamo un'occhiata ad esempi reali di rilevamento di frodi nel settore bancario utilizzando l'apprendimento automatico.
Intercettazione di una frode
Danske Bank è una multinazionale finanziaria danese. È la banca più grande della Danimarca e una delle principali banche al dettaglio del Nord Europa. Con il sistema di rilevamento basato su regole, la banca ha faticato a mitigare le frodi. Aveva un tasso di rilevamento delle frodi del 40% e un tasso di falsi positivi del 99,5%.
Collaborando con Teradata, una società di software di dati, Danske ha integrato un software di deep learning per identificare potenziali attività fraudolente. Il risultato è stato una riduzione del 60% dei falsi positivi e un aumento del 50% dei veri positivi.
Antiriciclaggio
OakNorth è una banca di prestito commerciale nel Regno Unito, che fornisce servizi finanziari aziendali e personali ad aziende in espansione. La banca aveva un processo di screening frammentato, con un fornitore per gli assegni antiriciclaggio e un altro per i clienti. Inoltre, gli screening per le persone politicamente esposte (PEP) hanno generato molti falsi positivi.
Collaborando con ComplyAdvantage, una società di rilevamento di frodi e antiriciclaggio, la banca ha integrato una soluzione di screening e monitoraggio continuo per semplificare la conformità e consolidare i dati. Ciò ha facilitato il rapido trasferimento dei dati tra le operazioni di prestito e di risparmio della banca.
Sottoscrizione del credito
Hawaii USA Credit Union è la più grande cooperativa di credito delle Hawaii e una delle migliori cooperative di credito della rivista Forbes. Voleva essere competitiva rispetto alle società Fintech e ampliare il proprio portafoglio di prestiti personali senza aumentare i rischi.
Lavorando con Zest AI, la cooperativa di credito ha automatizzato i suoi processi decisionali utilizzando un modello di prestito personale basato sull'intelligenza artificiale. Il modello utilizzava 278 variabili per fornire approfondimenti più approfonditi rispetto al sistema di punteggio del credito VantageScore. Il risultato è stato un aumento del 21% nel tasso di approvazione e un tasso di frode per richieste di default/prestito pari allo 0%.
Considerazioni chiave sull'utilizzo del machine learning per il rilevamento delle frodi
Sebbene il rilevamento delle frodi nel settore bancario tramite l’apprendimento automatico sia efficiente, è anche scoraggiante. Questi sistemi richiedono molti dati accurati, altrimenti i modelli non funzionano come dovrebbero.
Quindi, ecco alcuni suggerimenti per ottimizzare il processo di machine learning.
1. Limitare il numero di variabili di input
In questo articolo abbiamo detto di più è di più. Ciò rimane vero per quanto riguarda il volume dei dati. Tuttavia, meno è meglio per quanto riguarda il numero di variabili di rilevamento delle frodi.
Le caratteristiche tipiche da considerare quando si indaga su una frode includono:
- indirizzo IP
- Indirizzo e-mail
- Indirizzo di spedizione
- Valore medio dell'ordine/transazione
Il vantaggio di un minor numero di funzionalità è rappresentato dai tempi di addestramento dell'algoritmo più brevi. Si evitano inoltre problemi di set di dati sovrapposti o irrilevanti.
2. Garantire la conformità normativa
Prevenire le frodi è una parte della sicurezza dei dati. L'altro è la privacy dei dati. Molti paesi hanno leggi su come le istituzioni possono raccogliere, utilizzare e archiviare i dati dei clienti. C'è la legge cinese sulla protezione delle informazioni personali (PIPL), il California Consumer Privacy Act (CCPA) e il regolamento generale sulla protezione dei dati (GDPR) dell'Unione europea, solo per citarne alcuni.
Queste leggi hanno implicazioni per i dati utilizzati nell’apprendimento automatico. Il principio fondamentale della maggior parte delle normative sulla conformità alla privacy dei dati è l'avviso/consenso. È necessario notificare e ricevere l'autorizzazione per utilizzare i dati dei clienti per scopi diversi dalle richieste degli utenti, inclusi i dati per l'addestramento degli algoritmi di machine learning.
Il modo più semplice per garantire il rispetto degli standard sulla privacy è utilizzare partner tecnici con caratteristiche conformi alle normative. Ad esempio, dovresti collaborare con una società di sviluppo di app bancarie che sappia come mantenere la privacy e la sicurezza dei dati.
3. Stabilire una soglia ragionevole
Le regole del valore della transazione hanno requisiti minimi per attivare una risposta di accettazione o rifiuto. Desideri una soglia che bilanci sicurezza ed esperienza utente. Se la soglia è troppo rigida, rischi di bloccare le transazioni legittime. Se la soglia è troppo permissiva, aumenterai il tasso di frode riuscita.
Calcola la tua propensione al rischio per trovare il giusto equilibrio. I livelli di rischio differiscono per ciascun istituto finanziario o prodotto. Ad esempio, un’offerta bancaria di microprestiti può fissare una soglia elevata per i prestiti di basso valore. Una banca commerciale non può essere così generosa con i mutui ipotecari.
Anticipare il futuro
Il futuro è adesso, ma solo il 17% delle organizzazioni utilizza il machine learning nei programmi antifrode. Non rimanere indietro.
Ecco alcune innovazioni che puoi aspettarti nella sicurezza della tua banca attraverso l'apprendimento automatico.
- Profilazione dei dispositivi : identifica i diversi dispositivi che si collegano alla tua rete bancaria, analizzando le caratteristiche e i comportamenti di ogni dato dispositivo.
- Rilevamento e risposta automatizzati alle anomalie : identifica comportamenti fraudolenti da dispositivi noti e isola i sistemi interessati.
- Rilevamento zero-day : identifica vulnerabilità e malware precedentemente sconosciuti per proteggere le organizzazioni dagli attacchi informatici.
- Mascheramento dei dati : rileva e rende anonimi automaticamente i dati riservati.
- Approfondimenti su scala : identifica le tendenze delle frodi su più dispositivi e posizioni.
- Politica innovativa : utilizza le informazioni approfondite del machine learning per promuovere politiche di sicurezza pertinenti.
Che tu sia un istituto di gestione patrimoniale o una cooperativa di credito, l'intelligenza artificiale e l'apprendimento automatico offrono enormi opportunità per il rilevamento delle frodi.
Tuttavia, è fondamentale ricordare che gli hacker utilizzano queste tecnologie anche per eludere le misure di protezione. Aggiorna i tuoi modelli di machine learning per stare al passo con questi attacchi. Puoi anche rafforzare la tua sicurezza basata sull’intelligenza artificiale con la buona vecchia intelligenza umana.