
Introduzione al web crawler
Pubblicato: 2016-03-08Quando parlo con le persone di quello che faccio e di cos'è la SEO, di solito lo ottengono abbastanza rapidamente o agiscono come fanno. Una buona struttura del sito web, un buon contenuto, buoni backlink di supporto. Ma a volte, diventa un po' più tecnico e finisco per parlare di motori di ricerca che eseguono la scansione del tuo sito Web e di solito li perdo...
Perché eseguire la scansione di un sito Web?
La scansione del Web è iniziata con la mappatura di Internet e del modo in cui ogni sito Web era connesso tra loro. È stato utilizzato anche dai motori di ricerca per scoprire e indicizzare nuove pagine online. I web crawler sono stati utilizzati anche per testare la vulnerabilità del sito Web testando un sito Web e analizzando se sono stati individuati problemi.
Ora puoi trovare strumenti che eseguono la scansione del tuo sito Web per fornirti informazioni dettagliate. Ad esempio, OnCrawl fornisce dati relativi ai tuoi contenuti e SEO in loco o Majestic che fornisce approfondimenti su tutti i collegamenti che puntano a una pagina.
I crawler vengono utilizzati per raccogliere informazioni che possono quindi essere utilizzate ed elaborate per classificare i documenti e fornire approfondimenti sui dati raccolti.
La creazione di un crawler è accessibile a chiunque conosca un po' di codice. Tuttavia, realizzare un crawler efficiente è più difficile e richiede tempo.
Come funziona ?
Per eseguire la scansione di un sito Web o del Web, è necessario innanzitutto un punto di ingresso. I robot devono sapere che il tuo sito web esiste in modo che possano venire a dargli un'occhiata. In passato avresti inviato il tuo sito Web ai motori di ricerca per dire loro che il tuo sito Web era online. Ora puoi facilmente creare alcuni link al tuo sito web e Voilà sei nel giro!
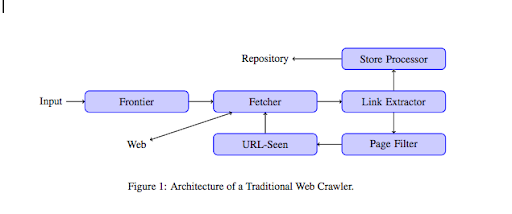
Una volta che un crawler atterra sul tuo sito Web, analizza tutti i tuoi contenuti riga per riga e segue ciascuno dei collegamenti che hai, siano essi interni o esterni. E così via fino a quando non arriva su una pagina senza più collegamenti o se incontra errori come 404, 403, 500, 503.
Da un punto di vista più tecnico, un crawler lavora con un seed (o un elenco) di URL. Questo viene passato a un Fetcher che recupererà il contenuto di una pagina. Questo contenuto viene quindi spostato su un estrattore di collegamenti che analizzerà l'HTML ed estrarrà tutti i collegamenti. Questi collegamenti vengono inviati sia a un processore Store che, come dice il nome, li memorizzerà. Questi URL passeranno anche attraverso un filtro Pagina che invierà tutti i collegamenti interessanti a un modulo visualizzato dall'URL. Questo modulo rileva se l'URL è già stato visto o meno. In caso contrario, viene inviato al Fetcher che recupererà il contenuto della pagina e così via.
Tieni presente che alcuni contenuti sono impossibili da scansionare per gli spider, come Flash. Javascript viene ora scansionato correttamente da GoogleBot, ma di tanto in tanto non ne esegue la scansione. Le immagini non sono contenuti che Google può scansionare tecnicamente, ma è diventato abbastanza intelligente da iniziare a capirle!
Se ai robot non viene detto il contrario, eseguiranno la scansione di tutto. È qui che il file robots.txt diventa molto utile. Indica ai crawler (può essere specifico per crawler, ad esempio GoogleBot o MSN Bot - scopri di più sui bot qui) quali pagine non possono scansionare. Supponiamo, ad esempio, che tu abbia la navigazione che utilizza i facet, potresti non volere che i robot li eseguano tutti perché hanno uno scarso valore aggiunto e utilizzeranno il crawl budget. L'uso di questa semplice linea ti aiuterà a impedire a qualsiasi robot di gattonare
User-agent: *
Non consentire: /cartella-a/
Questo dice a tutti i robot di non eseguire la scansione della cartella A.
User-agent: GoogleBot
Non consentire: /repertorio-b/
Questo d'altra parte specifica che solo Google Bot non può eseguire la scansione della cartella B.
Puoi anche usare l'indicazione in HTML che dice ai robot di non seguire un link specifico usando il tag rel="nofollow". Alcuni test hanno dimostrato che anche l'utilizzo del tag rel="nofollow" su un link non impedisce a Googlebot di seguirlo. Questo è contraddittorio al suo scopo, ma sarà utile in altri casi.
[Case Study] Aumenta la visibilità migliorando la scansione del sito Web per Googlebot
 Leggi il caso di studio
Leggi il caso di studio
Hai menzionato il crawl budget, ma che cos'è?
Diciamo che hai un sito web che è stato scoperto dai motori di ricerca. Vengono regolarmente per vedere se hai apportato aggiornamenti sul tuo sito Web e creato nuove pagine.
Ogni sito Web ha il proprio budget di scansione a seconda di diversi fattori come il numero di pagine del tuo sito Web e la sua sanità mentale (se ha molti errori, ad esempio). Puoi facilmente avere una rapida idea del tuo budget di scansione accedendo a Search Console.
Il tuo budget di scansione fisserà il numero di pagine che un robot esegue la scansione sul tuo sito web ogni volta che arriva per una visita. È proporzionalmente collegato al numero di pagine che hai sul tuo sito web ed è già stato scansionato. Alcune pagine vengono scansionate più spesso di altre, specialmente se vengono aggiornate regolarmente o se sono collegate da pagine importanti.
Ad esempio, la tua casa è il tuo punto di ingresso principale che verrà scansionato molto spesso. Se hai un blog o una pagina di categoria, verranno spesso scansionati se è collegata alla navigazione principale. Anche un blog verrà scansionato spesso poiché viene aggiornato regolarmente. Un post di un blog potrebbe essere scansionato spesso quando è stato pubblicato per la prima volta, ma dopo alcuni mesi probabilmente non verrà aggiornato.
Più spesso viene eseguita la scansione di una pagina, più un robot la considera importante rispetto ad altri. Questo è il momento in cui devi iniziare a lavorare per ottimizzare il tuo budget di scansione.
Ottimizzazione del budget di scansione
Per ottimizzare il tuo budget e assicurarti che le tue pagine più importanti ricevano l'attenzione che meritano, puoi analizzare i log del tuo server e guardare come viene eseguita la scansione del tuo sito web:
- Con quale frequenza vengono scansionate le tue pagine principali
- Riesci a vedere pagine meno importanti sottoposte a scansione più di altre più importanti?
- I robot ottengono spesso un errore 4xx o 5xx durante la scansione del tuo sito web?
- I robot incontrano trappole per ragni? (Matthew Henry ha scritto un ottimo articolo su di loro)
Analizzando i tuoi log, vedrai quali pagine ritieni meno importanti vengono sottoposte a molte ricerche per indicizzazione. È quindi necessario scavare più a fondo nella struttura dei collegamenti interni. Se viene sottoposto a scansione, deve avere molti collegamenti che puntano ad esso.
Puoi anche lavorare per correggere tutti questi errori (4xx e 5xx) con OnCrawl. Migliorerà la scansione e l'esperienza dell'utente, è un caso vantaggioso per tutti.
Scansione VS scraping?
Scansione e scraping sono due cose diverse che vengono utilizzate per scopi diversi. La scansione di un sito Web significa atterrare su una pagina e seguire i collegamenti che trovi durante la scansione del contenuto. Un crawler si sposterà quindi su un'altra pagina e così via.
Scraping, d'altra parte, è scansionare una pagina e raccogliere dati specifici dalla pagina: tag del titolo, meta descrizione, tag h1 o un'area specifica del tuo sito Web come un elenco di prezzi. Gli scraper di solito agiscono come "umani", ignoreranno qualsiasi regola dal file robots.txt, file nei moduli e utilizzeranno uno user-agent del browser per non essere rilevati.
I crawler dei motori di ricerca di solito agiscono come scrapper e hanno bisogno di raccogliere dati per elaborarli per il loro algoritmo di ranking. Non cercano dati specifici rispetto allo scrapper, usano solo tutti i dati disponibili sulla pagina e anche di più (il tempo di caricamento è qualcosa che non puoi ottenere da una pagina). I crawler dei motori di ricerca si identificheranno sempre come crawler in modo che il proprietario di un sito Web possa sapere quando è stato l'ultima volta a visitare il suo sito Web. Questo può essere molto utile quando si tiene traccia dell'attività reale dell'utente.
Quindi ora sai qualcosa in più sulla scansione, su come funziona e perché è importante, il passaggio successivo consiste nell'iniziare ad analizzare i log del server. Questo ti fornirà informazioni approfondite su come i robot interagiscono con il tuo sito web, quali pagine visitano spesso e quanti errori incontrano durante la visita del tuo sito web.
Per ulteriori informazioni tecniche e storiche sul web crawler puoi leggere “Una breve storia dei web crawler”