
Come definire il budget di scansione?
Pubblicato: 2016-09-14Ne parliamo tutti come SEO, ma come funziona effettivamente il crawl budget? Sappiamo che il numero di pagine che i motori di ricerca scansionano e indicizzano quando visitano i siti Web dei nostri clienti è correlato al loro successo nella ricerca organica, ma è sempre meglio avere un crawl budget maggiore?
Come ogni cosa con Google, non penso che la relazione tra il budget di scansione dei tuoi siti Web e il ranking/performance della SERP sia semplice al 100%, dipende da una serie di fattori.
Perché il crawl budget è importante? A causa dell'aggiornamento 2010 della caffeina. Con questo aggiornamento Google ha ricostruito il modo in cui indicizzava i contenuti, con indicizzazione incrementale. Introducendo il sistema "percolatore", hanno rimosso il "collo di bottiglia" delle pagine che venivano indicizzate.
In che modo Google determina il budget di scansione?
Riguarda il tuo PageRank, Citation Flow e Trust Flow.
Perché non ho menzionato l'autorità di dominio? Onestamente, secondo me è una delle metriche più abusate e fraintese disponibili per SEO e content marketer che, ha il suo posto, ma troppe agenzie e SEO ci danno troppo valore, specialmente quando costruiscono collegamenti.
Il PageRank è ora, ovviamente, obsoleto, soprattutto da quando hanno abbandonato la barra degli strumenti, quindi è tutto incentrato sul rapporto di fiducia di un sito (rapporto di fiducia = flusso di fiducia/flusso di citazioni). In sostanza, i domini più potenti hanno budget di scansione più grandi, quindi come identificare l'attività dei bot di Google sul tuo sito Web e, soprattutto, identificare eventuali problemi di scansione dei bot? File di registro del server.
Ora sappiamo tutti che per indicare le pagine al bot di Google che abbiamo indicizzato (e classificato) utilizziamo la struttura di collegamento interna e le teniamo vicino al dominio principale, non 5 sottocartelle lungo l'URL. Ma per quanto riguarda problemi più tecnici? Come lo spreco di crawl budget, le trappole robotiche o se Google sta cercando di compilare moduli sul sito (succede).
Identificazione dell'attività del crawler
Per fare ciò, devi mettere le mani su alcuni file di registro del server. Potrebbe essere necessario richiederli al tuo cliente oppure puoi scaricarli direttamente dalla società di hosting.
L'idea alla base di questo è che vuoi provare a trovare una registrazione del bot di Google che colpisce il tuo sito, ma poiché questo non è un evento programmato, potrebbe essere necessario ottenere alcuni giorni di dati. Sono disponibili vari software per analizzare questi file.
Di seguito è riportato un esempio di hit su un server Apache:
50.56.92.47 – – [31/May/2012:12:21:17 +0100] “GET” – “/wp-content/themes/wp-theme/help.php” – “404” “-” “Mozilla/ 5.0 (compatibile; Googlebot/2.1; +http://www.google.com/bot.html)” – www.hit-example.com
Da qui puoi utilizzare strumenti (come OnCrawl) per analizzare i file di registro e identificare problemi come la scansione di pagine PPC da parte di Google o infinite richieste GET agli script JSON, entrambi risolvibili all'interno del file Robots.txt.
Quando il crawl budget è un problema?
Il budget di scansione non è sempre un problema, se il tuo sito ha molti URL e ha un'allocazione proporzionata di "crawl", sei a posto. Ma cosa succede se il tuo sito web ha 200.000 URL e Google esegue la scansione di solo 2.000 pagine del tuo sito ogni giorno? Potrebbero essere necessari fino a 100 giorni prima che Google noti URL nuovi o aggiornati, ora questo è un problema.
Un rapido test per vedere se il tuo budget di scansione è un problema è utilizzare Google Search Console e il numero di URL sul tuo sito per calcolare il tuo "numero di scansione".
- Per prima cosa devi determinare quante pagine ci sono sul tuo sito, puoi farlo facendo un sito: ricerca, ad esempio oncrawl.com ha circa 512 pagine nell'indice:
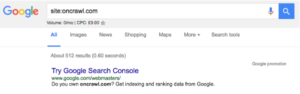

- In secondo luogo, devi accedere al tuo account Google Search Console e andare su Scansione, quindi Statistiche di scansione. Se il tuo account GSC non è stato configurato correttamente, potresti non avere questi dati.
- Il terzo passaggio consiste nel prendere il numero medio di "Pagine scansionate al giorno" (quello centrale) e il numero totale di URL sul tuo sito Web e dividerli:
Pagine totali sul sito/Pagine media scansionate al giorno = X
Se X è maggiore di 10, devi cercare di ottimizzare il tuo crawl budget. Se è inferiore a 5, bravo. Non è necessario continuare a leggere.
Ottimizzazione della capacità del "crawl budget".
Puoi avere il più grande budget di scansione su Internet, ma se non sai come usarlo, è inutile.
Sì, è un cliché, ma è vero. Se Google esegue la scansione di tutte le pagine del tuo sito e scopre che la maggior parte di esse è duplicata, vuota o si carica così lentamente da causare errori di timeout, il tuo budget potrebbe anche essere nullo.
Per ottenere il massimo dal tuo crawl budget (anche senza accedere ai file di registro del server) devi assicurarti di eseguire le seguenti operazioni:
Rimuovi le pagine duplicate
Spesso sui siti di e-commerce, strumenti come OpenCart possono creare più URL per lo stesso prodotto, ho visto istanze dello stesso prodotto su 4 URL con sottocartelle variabili tra la destinazione e la radice.
Non vuoi che Google indicizzi più di una versione di ogni pagina, quindi assicurati di disporre di tag canonici che indichino a Google la versione corretta.
Risolvi i collegamenti interrotti
Usa Google Search Console o un software di scansione e trova tutti i link interni ed esterni non funzionanti sul tuo sito e correggili. L'uso di 301 è fantastico, ma se sono collegamenti di navigazione o collegamenti a piè di pagina interrotti, è sufficiente modificare l'URL a cui puntano senza fare affidamento su un 301.
Non scrivere pagine sottili
Evita di avere molte pagine sul tuo sito che offrono poco o nessun valore agli utenti o ai motori di ricerca. Senza contesto, Google ha difficoltà a classificare le pagine, il che significa che non contribuiscono alla pertinenza generale del sito e sono solo passeggeri che occupano il crawl budget.
Rimuovi 301 catene di reindirizzamento
I reindirizzamenti a catena sono inutili, disordinati e fraintesi. Le catene di reindirizzamento possono danneggiare il tuo crawl budget in diversi modi. Quando Google raggiunge un URL e vede un 301, non sempre lo segue immediatamente, ma aggiunge il nuovo URL a un elenco e poi lo segue.
Devi anche assicurarti che la tua mappa del sito XML (e la mappa del sito HTML) sia accurata e, se il tuo sito web è multilingue, assicurati di avere mappe del sito per ogni lingua del sito web. Devi anche implementare un'architettura del sito intelligente, un'architettura URL e velocizzare le tue pagine. Anche mettere il tuo sito dietro una CDN come CloudFlare sarebbe vantaggioso.
TL; DR:
Il budget di scansione come qualsiasi budget è un'opportunità, in teoria stai utilizzando il tuo budget per guadagnare tempo che Googlebot, Bingbot e Slurp trascorrono sul tuo sito, è importante sfruttare al meglio questo tempo.
L'ottimizzazione del crawl budget non è facile e di certo non è una "vincita rapida". Se hai un sito di piccole dimensioni o un sito di medie dimensioni ben mantenuto, probabilmente stai bene. Se hai un sito colosso con decine di migliaia di URL e i file di registro del server ti passano sopra la testa, potrebbe essere il momento di chiamare gli esperti.