
Come prevedere le entrate del traffico organico non di marca in base alla posizione dell'URL con Python
Pubblicato: 2022-05-24Che cos'è la previsione SEO?
La previsione SEO, o stima del traffico organico, è il processo di utilizzo dei dati del tuo sito o di dati di terze parti per stimare il traffico organico futuro del tuo sito, le entrate SEO e il ROI SEO. Questa stima può essere calcolata utilizzando molti metodi diversi basati sui nostri dati.
In questo tutorial, vogliamo prevedere le nostre entrate organiche non di marca e il traffico organico non di marca in base alle posizioni dei nostri URL e alle loro entrate attuali. Questo può aiutarci come SEO a ottenere più buy-in da altre parti interessate: dall'aumento del budget mensile, trimestrale o annuale a più ore di lavoro dal team di prodotto e di sviluppo.
Tieni presente che questo tutorial non è applicabile solo al traffico organico non di marca; apportando alcune modifiche e conoscendo Python, puoi usarlo per stimare il traffico delle tue pagine target.
Di conseguenza, possiamo produrre un foglio Google come l'immagine qui sotto.
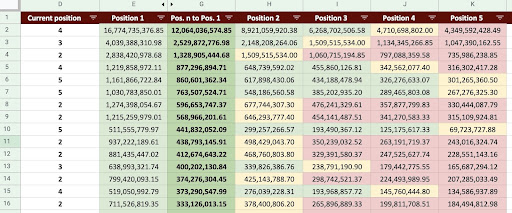
Immagine Fogli Google
Previsione del traffico SEO non di marca
La prima domanda che potresti porre dopo aver letto l'introduzione è: "Perché calcolare il traffico organico non di marca?".
Consideriamo un'azienda come Amazon. Quando vuoi acquistare un libro o una maschera, devi semplicemente cercare "acquista maschera amazon".
I marchi sono spesso al primo posto e quando vuoi acquistare qualcosa, la tua preferenza è quella di acquistare le cose di cui hai bisogno da queste aziende. In ogni settore, ci sono aziende di marca che influenzano il comportamento degli utenti nelle ricerche su Google.
Se dovessimo controllare i dati di Google Search Console (GSC) di Amazon, probabilmente scopriremmo che riceve molto traffico dalle query con marchio e, nella maggior parte dei casi, il primo risultato delle query con marchio è il sito di quel marchio.
Come SEO, come me, probabilmente hai sentito molte volte che "Solo il nostro marchio aiuta il nostro SEO!" Come possiamo dire "No, non è così" e mostrare il traffico e le entrate delle query non relative al marchio?
È ancora più complicato dimostrarlo perché sappiamo che gli algoritmi di Google sono così complessi ed è difficile separare nettamente le ricerche con marchio da quelle senza marchio. Ma questo è ciò che rende ciò che facciamo come SEO ancora più importante.
In questo tutorial, ti mostrerò come distinguere tra i due - con marchio e senza marchio - e ti mostrerò quanto può essere potente la SEO.
Anche se la tua azienda non è brandizzata, puoi comunque guadagnare molto da questo articolo: puoi imparare a stimare i dati organici del tuo sito.
SEO ROI basato sulla stima del traffico
Non importa dove ti trovi o cosa fai, c'è un limite alle risorse; che si tratti di un budget o semplicemente del numero di ore della giornata lavorativa. Sapere come allocare al meglio le tue risorse gioca un ruolo importante nel ritorno sull'investimento (ROI) generale e SEO.
Un CMO, un marketing VP o un performance marketer hanno tutti KPI diversi e richiedono risorse diverse per raggiungere i propri obiettivi. Il modo migliore per assicurarti di ottenere ciò di cui hai bisogno è dimostrarne la necessità dimostrando i ritorni che porterà all'azienda. Il ROI SEO non è diverso. Quando si avvicina il periodo dell'anno per l'allocazione del budget e il tuo team desidera richiedere un budget maggiore, la stima del ROI SEO può darti il sopravvento nella negoziazione. Dopo aver calcolato la stima del traffico non di marca, puoi valutare meglio il budget necessario per ottenere i risultati desiderati.
L'effetto della previsione SEO sulla strategia SEO
Come sappiamo, ogni 3 o 6 mesi esaminiamo la nostra strategia SEO e la adattiamo per ottenere i migliori risultati possibili. Ma cosa succede quando non sai dove è il massimo profitto per la tua azienda? Puoi prendere decisioni, ma non saranno efficaci quanto le decisioni prese quando avrai una visione più completa del traffico del sito.
La stima delle entrate del traffico organico non di marca può essere combinata con le pagine di destinazione e la segmentazione delle query per fornire un quadro generale che ti aiuterà a sviluppare strategie migliori come SEO manager o SEO strategist.
I diversi modi per prevedere il traffico organico
Ci sono molti metodi diversi e script pubblici nella comunità SEO per prevedere il traffico organico futuro.
Alcuni di questi metodi includono:
- Previsione organica del traffico su tutto il sito
- Previsione organica del traffico sulle pagine specifiche (blog, prodotti, categorie, ecc.) o su una singola pagina
- Previsione organica del traffico su query specifiche (le query contengono "acquista", "come fare", ecc.) o una query
- Previsione organica del traffico per periodi specifici (soprattutto per eventi stagionali)
Il mio metodo è per pagine specifiche e il periodo di tempo è di un mese.
[Case Study] Guidare la crescita in nuovi mercati con la SEO on-page
 Leggi il caso di studio
Leggi il caso di studioCome calcolare i ricavi da traffico organico
Il modo accurato si basa sui dati di Google Analytics (GA). Se il tuo sito è nuovo di zecca, dovrai utilizzare strumenti di terze parti. Preferisco evitare di utilizzare tali strumenti quando hai i tuoi dati.
Ricorda, dovrai testare i dati di terze parti che stai utilizzando rispetto ad alcuni dei dati della tua pagina reale per trovare eventuali errori nei loro dati.
Come calcolare le entrate del traffico SEO non di marca con Python
Finora, abbiamo trattato molti concetti teorici con cui dovremmo avere familiarità per comprendere meglio i diversi aspetti del nostro traffico organico e la previsione delle entrate. Ora, ci tufferemo nella parte pratica di questo articolo.
Innanzitutto, inizieremo calcolando la nostra curva CTR. Nel mio articolo sulla curva CTR su Oncrawl, spiego due metodi diversi e anche altri metodi che puoi utilizzare apportando alcune modifiche al mio codice. Ti consiglio di leggere prima l'articolo sulla curva dei clic; ti dà spunti su questo articolo.
In questo articolo, modifico alcune parti del mio codice per ottenere i risultati specifici che desideriamo nella stima del traffico. Quindi, otterremo i nostri dati da GA e utilizzeremo la dimensione delle entrate di GA per stimare le nostre entrate.
Previsione delle entrate del traffico organico non di marca con Python: per iniziare
Puoi eseguire questo codice da solo, senza conoscere Python. Tuttavia, preferisco che tu conosca un po' la sintassi di Python e le conoscenze di base sulle librerie Python che userò in questo codice di previsione. Questo ti aiuterà a capire meglio il mio codice e a personalizzarlo in un modo che sia utile per te.
Per eseguire questo codice, utilizzerò Visual Studio Code con l'estensione Python di Microsoft, che include l'estensione "Jupyter". Ma puoi usare il notebook Jupyter stesso.
Per l'intero processo, dobbiamo usare queste librerie Python:
- Numpy
- Panda
- Tramamente
Inoltre, importeremo alcune librerie standard Python:
- JSON
- stampa
# Importazione delle librerie di cui abbiamo bisogno per il nostro processo importa json da pprint importa pprint importa numpy come np importa panda come pd importa plotly.express come px
Passaggio 1: calcolo della curva CTR relativa (curva di clic relativa)
Nella prima fase, vogliamo calcolare la nostra curva CTR relativa. Ma qual è la curva CTR relativa?
Qual è la curva CTR relativa?
Iniziamo parlando della 'curva CTR assoluta'. Quando calcoliamo la curva CTR assoluta, diciamo che il CTR mediano (o CTR medio) della prima posizione è 36% e la seconda posizione è 20%, e così via.
Nella curva CTR relativa, istante di percentuale, dividiamo ogni mediana di posizione per il CTR della prima posizione. Ad esempio, la curva CTR relativa della prima posizione sarebbe 0,36 / 0,36 = 1, la seconda sarebbe 0,20 / 0,36 = 0,55 e così via.
Forse ti stai chiedendo perché è utile calcolarlo? Pensa a una pagina classificata alla prima posizione, che ha il 44% di CTR. Se questa pagina va alla posizione due, la curva CTR non scende al 20%, è più probabile che il CTR diminuisca al 44% * 0,55 = 24,2%.
1. Ottenere dati sul traffico organico con e senza marchio da GSC
Per il nostro processo di calcolo, dobbiamo ottenere i nostri dati da GSC. La prima volta, tutti i dati saranno basati su query con marchio e la volta successiva, tutti i dati saranno basati su query senza marchio.
Per ottenere questi dati, puoi utilizzare diversi metodi: dagli script Python o dal componente aggiuntivo Fogli Google "Search Analytics for Sheets". Userò l'esploratore API GSC.
L'output di questi dati è costituito da due file JSON che mostrano le prestazioni di ciascuna pagina. Un file JSON che mostra il rendimento delle pagine di destinazione in base alle query con marchio e l'altro mostra il rendimento delle pagine di destinazione in base alle query senza marchio.
Per ottenere dati da GSC API explorer, attenersi alla seguente procedura:
- Vai a https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
- Massimizza l'API explorer che si trova nell'angolo in alto a destra della pagina.
- Nel campo “
siteUrl”, inserisci il tuo nome di dominio. Ad esempio "https://www.example.com" o "http://your-domain.com". - Nel corpo della richiesta, dobbiamo prima definire i parametri “
startDate” e “endDate”. La mia preferenza sono gli ultimi 30 giorni. - Quindi aggiungiamo "
dimensions" e selezioniamo "page" per questo elenco. - Ora aggiungiamo "
dimensionFilterGroups" per filtrare le nostre query. Una volta per quelli di marca e una seconda per le query non di marca. - Alla fine, impostiamo il nostro "
rowLimit" a 25.000. Se le pagine del tuo sito che ricevono traffico organico ogni mese sono superiori a 25.000, devi modificare il corpo della richiesta. - Dopo aver effettuato ogni richiesta, salva la risposta JSON. Per le prestazioni con marchio, salva il file JSON come "
branded_data.json" e per le prestazioni senza marchio, salva il file JSON come "non_branded_data.json".
Dopo aver compreso i parametri nel nostro corpo della richiesta, l'unica cosa che devi fare è copiare e incollare sotto i corpi della richiesta. Prendi in considerazione la possibilità di sostituire i nomi dei tuoi marchi con " brand variation names ".
È necessario separare i nomi dei marchi con una pipeline o “ | ”. Ad esempio " amazon|amazon.com|amazn ".
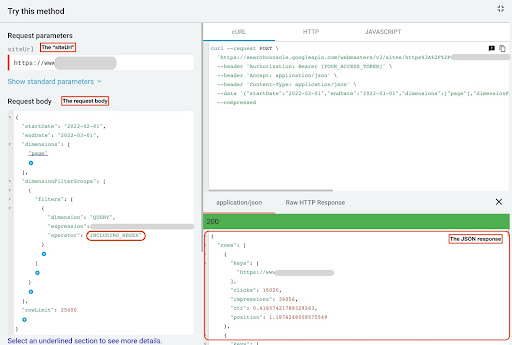
Esplora API di GSC
Corpo della richiesta con marchio:
{
"startDate": "01-02-2022",
"endDate": "2022-03-01",
"dimensioni": [
"pagina"
],
"dimensionFilterGroups": [
{
"filtri": [
{
"dimensione": "QUERY",
"expression": "nomi di varianti di marca",
"operatore": "INCLUDING_REGEX"
}
]
}
],
"limite di riga": 25000
}
Ente richiesta senza marchio:
{
"startDate": "01-02-2022",
"endDate": "2022-03-01",
"dimensioni": [
"pagina"
],
"dimensionFilterGroups": [
{
"filtri": [
{
"dimensione": "QUERY",
"expression": "nomi di varianti di marca",
"operatore": "EXCLUDING_REGEX"
}
]
}
],
"limite di riga": 25000
}
2. Importazione dei dati nel nostro notebook Jupyter ed estrazione delle directory del sito
Ora, dobbiamo caricare i nostri dati nel nostro notebook Jupyter per poterlo modificare ed estrarre ciò che vogliamo da esso. Riprendiamo da dove ci siamo lasciati sopra.
Per caricare i dati di marca, è necessario eseguire questo blocco di codice:
# Creazione di un DataFrame per le prestazioni degli URL del sito Web sul marchio e query di marca
con open("./branded_data.json") come json_file:
branded_data = json.loads(json_file.read())["righe"]
branded_df = pd.DataFrame(branded_data)
# Rinominare la colonna "chiavi" in colonna "pagina di destinazione" e convertire l'elenco "pagina di destinazione" in un URL
branded_df.rename(columns={"keys": "pagina di destinazione"}, inplace=True)
branded_df["pagina di destinazione"] = branded_df["pagina di destinazione"].apply(lambda x: x[0])
Per le prestazioni senza marchio delle pagine di destinazione, dovrai eseguire questo blocco di codice:
# Creazione di un DataFrame per le prestazioni degli URL del sito Web sulle query non di marca
con open("./non_branded_data.json") come json_file:
non_branded_data = json.loads(json_file.read())["rows"]
non_branded_df = pd.DataFrame(non_branded_data)
# Rinominare la colonna "chiavi" in colonna "pagina di destinazione" e convertire l'elenco "pagina di destinazione" in un URL
non_branded_df.rename(columns={"keys": "pagina di destinazione"}, inplace=True)
non_branded_df["pagina di destinazione"] = non_branded_df["pagina di destinazione"].apply(lambda x: x[0])
Carichiamo i nostri dati, quindi dobbiamo definire il nome del nostro sito per estrarne le directory.
# Definire il nome del tuo sito tra virgolette. Ad esempio, "https://www.example.com/" o "http://miodominio.com/" SITE_NAME = "https://www.tuo_dominio.com/"
Abbiamo solo bisogno di estrarre le directory dalla performance senza marchio.
# Ottenere ogni directory della pagina di destinazione (URL).
non_branded_df["directory"] = non_branded_df["pagina di destinazione"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
Quindi stampiamo le directory per selezionare quali sono importanti per questo processo. Potresti voler selezionare tutte le directory per avere una visione migliore del tuo sito.

# Per ottenere tutte le directory nell'output, dobbiamo manipolare le opzioni di Pandas
pd.set_option("display.max_rows", Nessuno)
# Directory del sito web
non_branded_df["directory"].value_counts()
Qui puoi inserire qualsiasi directory sia importante per te.
""" Scegli quali directory sono importanti per ottenere la loro curva CTR.
Inserisci le directory nella variabile 'important_directories'.
Ad esempio, 'product,tag,product-category,mag'. Separare i valori delle directory con una virgola.
"""
IMPORTANT_DIRECTORIES = "le tue_importanti_directory"
IMPORTANTI_DIRECTORIES = IMPORTANTI_DIRECTORIES.split(",")
3. Etichettare le pagine in base alla loro posizione e calcolare la relativa curva CTR
Ora dobbiamo etichettare le nostre pagine di destinazione in base alla loro posizione. Lo facciamo, perché dobbiamo calcolare la curva CTR relativa per ciascuna directory in base alla posizione della sua pagina di destinazione.
# Etichettatura di posizioni senza marchio
per i nell'intervallo(1, 11):
non_branded_df.loc[
(non_branded_df["posizione"] >= i) & (non_branded_df["posizione"] < i + 1),
"etichetta di posizione",
] = io
Quindi, raggruppiamo le pagine di destinazione in base alla loro directory.
# Raggruppamento delle pagine di destinazione in base al loro valore di "directory". non_brand_grouped_df = non_branded_df.groupby(["directory"])
Definiamo la funzione per calcolare la curva CTR relativa.
def each_dir_relative_ctr_curve(dir_df, chiave):
"""La funzione calcola ciascuna curva CTR relativa di IMPORTANT_DIRECTORIES.
"""
# Raggruppamento di "non_brand_grouped_df" in base al loro valore di 'etichetta di posizione'
dir_grouped_df = dir_df.groupby(["etichetta di posizione"])
# Un elenco per salvare il CTR mediano di ciascuna posizione
median_ctr_list = []
# Memorizzazione di ogni directory come chiave, ed è "median_ctr_list" come valore
directory_median_ctr = {}
# Ciclo su ogni gruppo "dir_grouped_df".
per i nell'intervallo(1, 11):
# Un try-tranne per gestire quelle situazioni in cui una directory, ad esempio, non ha dati per la posizione 4
Tentativo:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"])))
tranne:
median_ctr_list.append(0)
# Calcolo della curva CTR relativa
directory_median_ctr[chiave] = np.array(median_ctr_list) / np.array(
[lista_ctr_mediana[0]] * 10
)
ritorna directory_median_ctr
Dopo aver definito la funzione, la eseguiamo.
# Eseguire il ciclo delle directory ed eseguire la funzione 'each_dir_relative_ctr_curve'
directory_median_ctr_dict = dict()
per la chiave, elemento in non_brand_grouped_df:
se si digita IMPORTANT_DIRECTORIES:
directory_median_ctr_dict.update(each_dir_relative_ctr_curve(elemento, chiave))
pprint(directory_median_ctr_dict)
Ora caricheremo le nostre pagine di destinazione, brandizzate e non, il rendimento e calcoleremo la curva CTR relativa per i nostri dati non brand. Perché lo facciamo solo per i dati non di marca? Perché vogliamo prevedere il traffico organico e le entrate non di marca.
Passaggio 2: prevedere le entrate del traffico organico non di marca
In questo secondo passaggio, analizzeremo come recuperare i nostri dati sulle entrate e prevedere le nostre entrate.
1. Unione di dati organici di marca e non di marca
Ora uniremo i nostri dati brandizzati e non brandizzati. Questo ci aiuterà a calcolare la percentuale di traffico organico non di marca su ciascuna pagina di destinazione rispetto a tutto il traffico.
# 'main_df' è una combinazione di 'dati dell'intero sito' e 'dati non di marca' DataFrame.
# Usando questo DataFrame, puoi scoprire dove la maggior parte dei nostri clic e impressioni
# provengono da query prive di marchio.
main_df = non_branded_df.merge(
branded_df, on="pagina di destinazione", suffissi=("_non_brand", "_branded")
)
Quindi modifichiamo le colonne per rimuovere quelle inutili.
# Modifica delle colonne 'main_df' in quelle di cui abbiamo bisogno
main_df = main_df[
[
"pagina di destinazione",
"clicks_non_brand",
"ctr_non_brand",
"directory",
"etichetta di posizione",
"clicks_branded",
]
]
Ora, calcoliamo la percentuale di clic senza marchio rispetto ai clic totali di una pagina di destinazione.
# Calcolo della percentuale di clic delle query senza marchio in base alle pagine di destinazione rispetto all'intera pagina di destinazione
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_branded"]),
asse=1,
)
[Ebook] Automatizzare la SEO con Oncrawl
 Leggi l'ebook
Leggi l'ebook2. Caricamento delle entrate del traffico organico
Proprio come il recupero dei dati GSC, abbiamo diversi modi per ottenere i dati GA: potremmo utilizzare il "componente aggiuntivo Fogli di Google Analytics" o l'API GA. In questo tutorial preferisco utilizzare Google Data Studio (GDS) per la sua semplicità.
Per ottenere i dati GA da GDS, attenersi alla seguente procedura:
- In GDS, crea un nuovo rapporto o esploratore e una tabella.
- Per la dimensione aggiungi "pagina di destinazione" e per la metrica, dobbiamo aggiungere "Fatturato".
- Quindi, dovrai creare un segmento personalizzato in GA basato su sorgente e mezzo. Filtra il traffico “Google/organico”. Dopo la creazione del segmento, aggiungilo alla sezione del segmento in GDS.
- Al passaggio finale, esporta la tabella e salvala come "
landing_pages_revenue.csv".
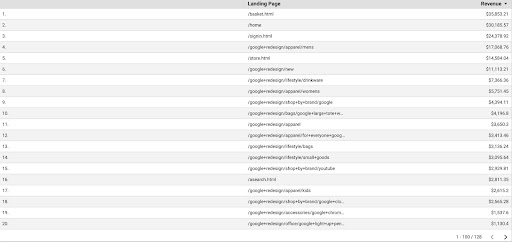
Esportazione csv delle entrate delle pagine di destinazione
Carichiamo i nostri dati.
organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
Ora, dobbiamo aggiungere il nome del nostro sito agli URL delle pagine di destinazione GA.
Quando esportiamo i nostri dati da GA, le pagine di destinazione sono in forma relativa, ma i nostri dati GSC sono in forma assoluta.
Non dimenticare di controllare i dati delle tue pagine di destinazione GA. Nei set di dati con cui ho lavorato, ho scoperto che i dati GA necessitano di una piccola pulizia ogni volta.
# URL delle pagine di destinazione GA concatenate con SITE_NAME.
# Inoltre, rinominando le colonne
organic_revenue_df.loc[:, "Pagina di destinazione"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
organic_revenue_df.rename(columns={"Pagina di destinazione": "Pagina di destinazione", "Entrate": "entrate"}, inplace=True)
Ora uniamo i nostri dati GSC con i dati GA.
# In questo passaggio, unisco 'main_df' con 'dk_organic_revenue_df' DataFrame che contiene la percentuale di dati di query non di marca main_df = main_df.merge(organic_revenue_df, on="pagina di destinazione", how="sinistra")
Alla fine di questa sezione, eseguiamo una piccola pulizia sulle nostre colonne DataFrame.
# Un po' di pulizia del DataFrame 'main_df'
main_df = main_df[
[
"pagina di destinazione",
"clicks_non_brand",
"ctr_non_brand",
"directory",
"etichetta di posizione",
"clicks_non_brand_percentage",
"reddito",
]
]
3. Calcolo delle entrate non di marca
In questa sezione elaboreremo i dati per estrarre le informazioni che stiamo cercando.
Ma prima di tutto, filtriamo le nostre landing page in base a " IMPORTANT_DIRECTORIES ":
# Rimozione di altre pagine di destinazione delle directory, non incluse in "IMPORTANT_DIRECTORIES"
main_df = (
main_df[main_df["directory"].isin(IMPORTANT_DIRECTORIES)]
.dropna(subset=["ricavi"])
.reset_index(drop=True)
)
Ora, calcoliamo il traffico delle entrate organiche non di marca.
Ho definito una metrica che non possiamo calcolare facilmente ed è più l'intuizione che altro che ci porta ad assegnarle un numero.
La metrica " brand_influence " mostra la forza del tuo marchio. Se ritieni che le ricerche non di marca portino meno vendite alla tua attività, riduci questo numero; qualcosa come 0,8 per esempio.
# Se il tuo marchio è così forte che interrogare senza il tuo marchio può vendere tanto quanto interrogare con il tuo marchio, allora 1 va bene per te.
# Pensa alla ricerca di un libro senza un marchio incluso nella tua query. Quando vedi Amazon, acquisti da altri mercati o negozi?
brand_influenza = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["entrate"] * x["clicks_non_brand_percentage"] * brand_influence, asse=1
)
Tracciamo un grafico a torta per avere un'idea delle entrate non di marca basate sulle directory importanti.
# In questa cella voglio ottenere tutte le entrate delle pagine di destinazione non di marca in base alla loro directory
non_branded_directory_dist_revenue_df = pd.pivot_table(
main_df,
index="directory",
valori=["non_brand_revenue"],
aggfunc={"non_brand_revenue": "somma"},
)
pie_fig = px.pie(
directory_non_branded_dist_revenue_df,
valori="non_brand_revenue",
nomi=directory_non_branded_dist_revenue_df.index,
title="Entrate non di marca basate sulle directory del sito Web",
)
pie_fig.update_traces(textposition="inside", textinfo="percent+label")
torta_fig.show()
Questo grafico mostra la distribuzione delle query senza marchio nelle tue IMPORTANT_DIRECTORIES .
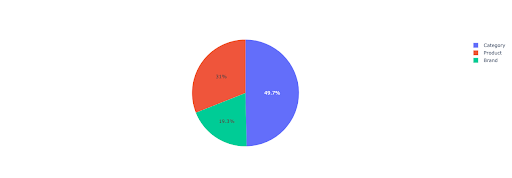
Distribuzione di query senza marchio
Sulla base dei dati della mia curva CTR, vedo che non posso fare affidamento sul CTR per posizioni superiori a 5. Per questo motivo, filtro i miei dati in base alla posizione.
Puoi modificare il blocco di codice sottostante in base ai tuoi dati.
# A causa della precisione del CTR nella nostra curva CTR, penso che possiamo saltare gli atterraggi con una posizione superiore a 5. Per questo motivo, ho filtrato altre pagine di destinazione main_df = main_df[main_df["etichetta di posizione"] < 6].reset_index(drop=True)
4. Calcolo dei "ricavi per clic" (RPC)
Qui, ho creato una metrica personalizzata e l'ho chiamata "Entrate per clic" o RPC. Questo ci mostra le entrate generate da ciascun clic senza marchio.
Puoi utilizzare questa metrica in diversi modi. Ho trovato una pagina con un RPC elevato, ma clic bassi. Quando ho controllato la pagina, ho scoperto che era stata indicizzata meno di una settimana fa e che possiamo utilizzare diversi metodi per ottimizzare la pagina.
# Calcolo delle entrate generate con ogni clic (RPC: Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], asse=1
)
5. Prevedere le entrate!
Stiamo arrivando alla fine, abbiamo aspettato fino ad ora per prevedere i nostri ricavi organici non di marca.
Eseguiamo gli ultimi blocchi di codice.
# La funzione principale per calcolare i ricavi in base alle diverse posizioni
per index, row_values in main_df.iterrows():
# Passa da una directory all'altra Elenco CTR
ctr_curve = directory_median_ctr_dict[row_values["directory"]]
# Passa dalla posizione 1 alla 5 e calcola le entrate in base all'aumento o alla diminuzione del CTR
per i nell'intervallo(1, 6):
if i == valori_riga["etichetta di posizione"]:
main_df.loc[indice, i] = valori_riga["entrate_non_marca"]
altro:
# main_df.loc[indice, i + 1] ==
main_df.loc[indice, i] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ctr_curve[int(row_values["etichetta di posizione"] - 1)]
)
# Calcolo della metrica "N a 1". Questo mostra l'aumento delle entrate quando il tuo grado passa da "N" a "1"
main_df.loc[indice, "da N a 1"] = main_df.loc[indice, 1] - main_df.loc[indice, valori_riga["etichetta di posizione"]]
Guardando l'output finale, abbiamo nuove colonne. I nomi di queste colonne sono “1”, “2”, “3”, “4”, “5”.
Cosa significano questi nomi? Ad esempio, abbiamo una pagina in posizione 3 e vogliamo prevederne le entrate se migliora la sua posizione, oppure vogliamo sapere quanto perderemo se cali di ranking.
Le colonne "1" e "2" mostrano le entrate della pagina quando la posizione media di questa pagina migliora e le colonne "4" e "5" mostrano le entrate di questa pagina quando scendiamo nella classifica.
La colonna "3" in questo esempio mostra le entrate correnti della pagina.
Inoltre, ho creato una metrica chiamata "N a 1". Questo ti mostra se la posizione media di questa pagina passa da "3" (o N) a "1" e quanto la mossa può influenzare le entrate.
Avvolgendo
Ho trattato molto in questo articolo e ora tocca a te sporcarti le mani e prevedere le entrate del traffico organico non di marca.
Questo è il modo più semplice in cui possiamo utilizzare questa previsione. Potremmo rendere questo algoritmo più complesso e combinarlo con alcuni modelli ML, ma ciò renderebbe l'articolo più complicato.
Preferisco salvare questi dati in un CSV e caricarli su un foglio Google. Oppure, se ho intenzione di condividerlo con gli altri membri del mio team o dell'organizzazione, lo aprirò con excel e formatterò le colonne usando i colori in modo che sia più facile da leggere.
Sulla base di questi dati, puoi prevedere il ROI del traffico organico non di marca e utilizzarlo nel processo di negoziazione.