
Come gestire la pastorizia di bot e la disputa di ragni per le classifiche?
Pubblicato: 2020-01-23
I crawler di Google indicizzano ogni contenuto che pubblichi sul tuo sito web. Questi crawler sono software programmati che seguono link e codici e li consegnano a un algoritmo. Quindi, l'algoritmo lo indicizza e aggiunge il tuo contenuto a un vasto database. In questo modo, ogni volta che un utente cerca una parola chiave, il motore di ricerca estrae e classifica i risultati correlati dal database delle pagine già indicizzate.
Google assegna un budget di scansione a ogni sito Web e i crawler eseguono la scansione del tuo sito di conseguenza. È necessario gestire e utilizzare il budget di scansione per garantire la scansione e l'indicizzazione intelligenti dell'intero sito web.
In questo post, puoi conoscere i trucchi e gli strumenti per gestire il modo in cui i bot/spider o i crawler dei motori di ricerca eseguono la scansione e l'indicizzazione del tuo sito web.
1. Ottimizzazione della direttiva Disallow per Robot.txt:

Robots.txt è un file di testo con una sintassi rigorosa che funziona come una guida per gli spider per determinare come eseguire la scansione del tuo sito. Un file robots.txt viene salvato nei repository host del tuo sito web da dove i crawler cercano gli URL. Per ottimizzare questi Robots.txt o "Protocollo di esclusione robot", puoi utilizzare alcuni trucchi che possono aiutare gli URL del tuo sito a essere scansionati dai crawler di Google per posizionamenti più alti.
Uno di questi trucchi è usare una "Direttiva Disallow" , è come mettere un cartello di "Area riservata" su sezioni specifiche del tuo sito web. Per ottimizzare la direttiva Disallow, è necessario comprendere la prima linea di difesa: "User-agents".
Che cos'è una direttiva sugli user agent?
Ogni file Robots.txt è costituito da una o più regole e tra queste, la regola user-agent è la più importante. Questa regola fornisce ai crawler l'accesso e il non accesso a un particolare elenco sul sito Web.
Pertanto, la direttiva user-agent viene utilizzata per rivolgersi a un crawler specifico e dargli istruzioni su come eseguire la ricerca per indicizzazione.
Tipi di crawler di Google comunemente utilizzati:

Direttiva Non consentire:
Ora, dopo aver appreso del bot a cui è assegnato il crawling del tuo sito web, puoi ottimizzarne diverse sezioni in base al tipo di user-agent. Alcuni trucchi ed esempi essenziali che puoi seguire per ottimizzare la direttiva disallow del tuo sito web sono:
- Utilizzare un nome di pagina completo che può essere mostrato nel browser da utilizzare per la direttiva disallow.
- Se desideri reindirizzare il crawler da un percorso di directory, utilizza un segno "/".
- Utilizzare * per il prefisso del percorso, il suffisso o un'intera stringa.
Esempi di utilizzo delle direttive disallow sono:
# Esempio 1: blocca solo Googlebot
User-agent: Googlebot
Non consentire: /
# Esempio 2: blocca Googlebot e Adsbot
User-agent: Googlebot
User-agent: AdsBot-Google
Non consentire: /
# Esempio 3: blocca tutti tranne i crawler di AdsBot
User-agent: *
Non consentire: /
2. Una direttiva non index per Robots.txt:
Quando altri siti Web si collegano al tuo sito, è possibile che l'URL, che non desideri venga indicizzato dal crawler, possa essere esposto. Per ovviare a questo problema, puoi utilizzare una direttiva non index. Vediamo, come possiamo applicare la direttiva non index a Robots.txt:
Esistono due metodi per applicare una direttiva non index per il tuo sito web:
Tag <Meta>:
I meta tag sono frammenti di testo che descrivono il contenuto della tua pagina in un breve modo trasparente che consente ai visitatori di sapere cosa accadrà? Possiamo usare lo stesso per evitare che i crawler indicizzino la pagina.
Innanzitutto, inserisci un meta tag "<meta name= "robots" content=" noindex">" nella sezione "<head>" della tua pagina che non desideri vengano indicizzati dai crawler.
Per i crawler di Google, puoi utilizzare "<meta name="googlebot" content="noindex"/>" nella sezione "<head>".
Poiché diversi crawler dei motori di ricerca cercano le tue pagine, potrebbero interpretare la tua direttiva non index in modo diverso. Per questo motivo, le tue pagine potrebbero essere visualizzate nei risultati di ricerca.
Quindi, sarebbe utile definire le direttive per le pagine in base ai crawler o agli user-agent.
È possibile utilizzare i seguenti meta tag per applicare la direttiva a diversi crawler:
<meta name=”googlebot” content=”noindex”>
<meta name="googlebot-news" content="nosnippet">
Tag X-Robot:
Sappiamo tutti delle intestazioni HTTP che vengono utilizzate come risposte alla richiesta del client o del motore di ricerca di informazioni aggiuntive relative alle tue pagine Web come la posizione o il server che le fornisce. Ora, per ottimizzare queste risposte di intestazione HTTP per la direttiva non-index, puoi aggiungere tag X-Robots come elemento della risposta di intestazione HTTP per qualsiasi URL del tuo sito web.
Puoi combinare diversi tag X-Robots con le risposte dell'intestazione HTTP. È possibile specificare varie direttive in un elenco separato da una virgola. Di seguito è riportato un esempio di una risposta di intestazione HTTP con diverse direttive combinate con tag X-Robots.
HTTP/1.1 200 OK
Data: mar, 25 gennaio 2020 21:42:43 GMT
(…)
X-Robots-Tag: noarchive
X-Robots-Tag: non disponibile_dopo: 25 luglio 2020 15:00:00 PST
(…)
3. Padroneggiare i link canonici: 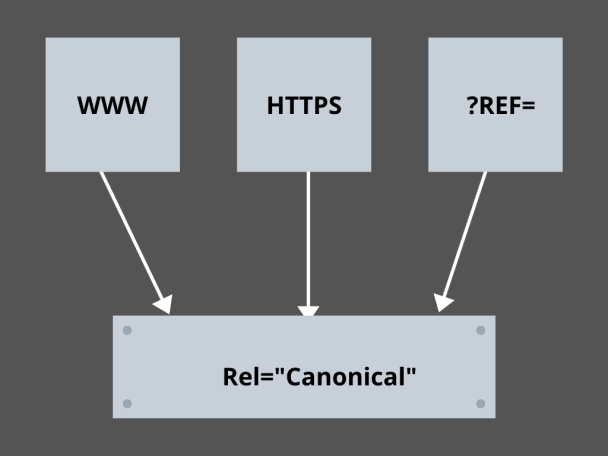
Qual è il fattore più temuto nella SEO oggi? Classifiche? Traffico? No! È la paura che i motori di ricerca penalizzino il tuo sito web per contenuti duplicati. Quindi, mentre stai pianificando il tuo crawl budget, devi stare attento a non esporre i tuoi contenuti duplicati.

Qui, padroneggiare i tuoi link canonici ti aiuterà a gestire i tuoi problemi di contenuto duplicato. La parola contenuto duplicato non è ciò che significa. Facciamo un esempio di due pagine di un sito e-commerce:
Ad esempio, hai un sito Web di e-commerce con un paio di pagine identiche per uno smartwatch ed entrambi hanno contenuti simili. Quando i robot dei motori di ricerca scansionano il tuo URL, controllano la presenza di contenuti duplicati e possono scegliere uno qualsiasi degli URL. Per reindirizzarli all'URL che è essenziale per te, è possibile impostare un collegamento canonico per le pagine. Vediamo come puoi farlo:
- Scegli una pagina qualsiasi dalle due pagine per la tua versione canonica.
- Scegli quello che riceve più visitatori.
- Ora aggiungi rel="canonical" alla tua pagina non canonica.
- Reindirizza il collegamento della pagina non canonica alla pagina canonica.
- Unirà entrambi i link della tua pagina come un unico link canonico.
4. Strutturazione del sito web:
I crawler hanno bisogno di indicatori e cartelli per aiutarli a scoprire gli URL importanti del tuo sito e, se non strutturi il tuo sito Web, i crawler hanno difficoltà a eseguire la scansione dei tuoi URL. Per questo, utilizziamo le mappe del sito perché forniscono ai crawler collegamenti a tutte le pagine importanti del tuo sito web.
I formati standard delle mappe dei siti per siti Web o anche app sviluppate tramite processi di sviluppo di app mobili sono mappe dei siti XML, Atom e RSS. Per ottimizzare la scansione, è necessario combinare mappe del sito XML e feed RSS/Atom.
- Poiché le mappe dei siti XML forniscono ai crawler le indicazioni per tutte le pagine del tuo sito Web o app.
- E il feed RSS/Atom fornisce aggiornamenti nelle tue pagine del sito Web ai crawler.
- Poiché le mappe dei siti XML forniscono ai crawler le indicazioni per tutte le pagine del tuo sito Web o app.
5. Navigazione delle pagine:
La navigazione della pagina è essenziale per gli spider e anche per i visitatori del tuo sito web. Questi stivali cercano le pagine del tuo sito web e una struttura gerarchica predefinita può aiutare i crawler a trovare le pagine importanti per il tuo sito web. Altri passaggi da seguire per una migliore navigazione della pagina sono:
- Mantieni la codifica in HTML o CSS.
- Organizza gerarchicamente le tue pagine.
- Utilizzare una struttura del sito Web poco profonda per una migliore navigazione della pagina.
- Mantieni il menu e le schede nell'intestazione in modo che siano minimi e specifici.
- Aiuterà la navigazione della pagina a essere più semplice.
6. Evitare le trappole per ragni:
Le trappole di ragno sono URL infiniti che puntano allo stesso contenuto sulle stesse pagine quando i crawler eseguono la scansione del tuo sito web. Questo è più come sparare a salve. Alla fine, consumerà il tuo crawl budget. Questo problema si intensifica ad ogni scansione e si ritiene che il tuo sito Web abbia contenuti duplicati poiché ogni URL su cui viene eseguita la scansione nella trappola non sarà univoco.
Puoi rompere la trappola bloccando la sezione tramite Robots.txt o utilizzare una delle direttive follow o no follow per bloccare pagine specifiche. Infine, puoi cercare di risolvere il problema tecnicamente interrompendo il verificarsi di URL infiniti.
7. Struttura di collegamento:
L'interconnessione è una delle parti essenziali dell'ottimizzazione della scansione. I crawler possono trovare meglio le tue pagine con link ben strutturati in tutto il tuo sito web. Alcuni dei trucchi chiave per una grande struttura di collegamento sono:
- Utilizzo di link di testo, poiché i motori di ricerca li scansionano facilmente: <a href="new-page.html">link di testo</a>
- Uso di anchor text descrittivo nei tuoi link
- Supponiamo che tu gestisca un sito web di palestra e desideri collegare tutti i tuoi video di palestra, puoi utilizzare un collegamento come questo. Sentiti libero di sfogliare tutti i nostri <a href="videos.html">video di palestra</a>.
8. Felicità HTML:
La pulizia dei documenti HTML e la riduzione al minimo della dimensione del payload dei documenti HTML è importante in quanto consente ai crawler di eseguire rapidamente la scansione degli URL. Un altro vantaggio dell'ottimizzazione HTML è che il tuo server viene caricato pesantemente a causa di diverse scansioni da parte dei motori di ricerca e questo può rallentare il caricamento della pagina, il che non è un ottimo segno per la SEO o la scansione dei motori di ricerca. L'ottimizzazione HTML può ridurre il carico della scansione sul server, mantenendo il caricamento della pagina rapido. Aiuta anche a risolvere gli errori di scansione dovuti a timeout del server o altri problemi vitali.
9. Incorporalo semplice:
Nessun sito Web oggi offrirà contenuti senza immagini e video eccezionali a supporto del contenuto, poiché è ciò che rende il loro contenuto visivamente più attraente e ottenibile per i crawler dei motori di ricerca. Tuttavia, se questo contenuto incorporato non è ottimizzato, può ridurre la velocità di caricamento, allontanando i crawler dai tuoi contenuti che possono essere classificati.
In questo caso, attenersi all'HTML per il contenuto incorporato può aiutare a ottenere una migliore scansione dai motori di ricerca. Tecnologie come AJAX, Javascript, ecc. sono abbastanza brave a fornire nuove funzionalità, ma rendono anche piuttosto complicata la scansione dei motori di ricerca.
Conclusione:
Con una maggiore attenzione alla SEO e un traffico più elevato, ogni proprietario di un sito Web è alla ricerca di modi migliori per gestire il bot herding e lo spider wrangling. Tuttavia, le soluzioni risiedono nelle ottimizzazioni granulari che devi apportare nel tuo sito Web e nella scansione degli URL che possono rendere la scansione dei motori di ricerca più specifica e ottimizzata per rappresentare il meglio del tuo sito Web che può classificarsi più in alto nelle pagine dei risultati dei motori di ricerca.