
Aggiornamenti principali di Google: effetti, problemi e soluzioni per i siti YMYL
Pubblicato: 2019-12-04In questo caso di studio, esaminerò Hangikredi.com che è una delle più grandi risorse finanziarie e digitali della Turchia. Vedremo sottotitoli SEO tecnici e alcuni grafici.
Questo caso di studio è presentato in due articoli. Questo articolo gestisce il Google Core Update del 12 marzo, che ha avuto un forte effetto negativo sul sito Web, e cosa abbiamo fatto per contrastarlo. Esamineremo 13 problemi tecnici e soluzioni, oltre a problemi olistici.
Leggi la seconda puntata per vedere come ho applicato l'apprendimento da questo aggiornamento per diventare un vincitore di ogni aggiornamento di Google Core.
Problemi e soluzioni: correzione degli effetti dell'aggiornamento di Google Core del 12 marzo
Fino all'aggiornamento dell'algoritmo principale del 12 marzo, tutto è andato liscio per il sito Web, sulla base dei dati analitici. In un giorno, dopo che è stata rilasciata la notizia del Core Algorithm Update, c'è stato un enorme calo delle classifiche e una grande frustrazione in ufficio. Personalmente non ho visto quel giorno perché sono arrivato solo quando mi hanno assunto per avviare un nuovo progetto e processo SEO 14 giorni dopo.
[Case Study] Migliorare le classifiche, le visite organiche e le vendite con l'analisi dei file di registro
 Leggi il caso di studio
Leggi il caso di studioIl rapporto sui danni per il sito web dell'azienda dopo il 12 marzo Core Algorithm Update è di seguito:
- 36% di perdita organica della sessione
- 65% Rilascia clic
- Perdita CTR del 30%.
- 33% di perdita organica degli utenti
- 100.000 impressioni perse al giorno.
- Perdita di impressioni del 9,72%.
- 8 000 parole chiave perse

Ora, come abbiamo affermato all'inizio dell'articolo di studio del caso, dovremmo porre una domanda. Non potevamo chiedere "Quando avverrà il prossimo aggiornamento dell'algoritmo principale?" perché è già successo. Era rimasta solo una domanda.
"Quali criteri diversi ha preso in considerazione Google tra me e il mio concorrente?"
Come puoi vedere dal grafico sopra e dal rapporto sui danni, avevamo perso il nostro traffico principale e le parole chiave.
1. Problema: collegamento interno
Ho notato che quando ho controllato per la prima volta il conteggio dei link interni, il testo di ancoraggio e il flusso dei link, il mio concorrente era davanti a me.
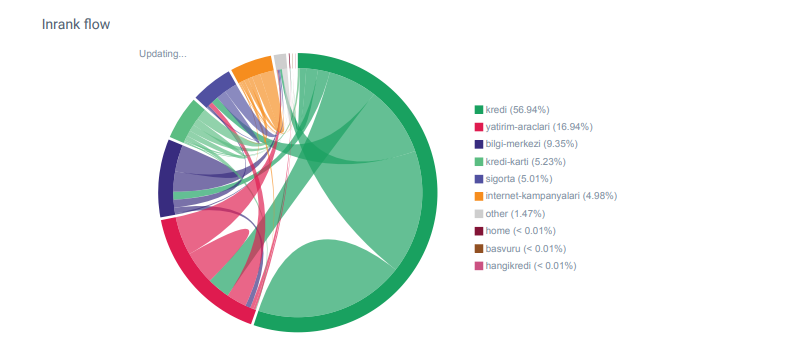
Report Linkflow per le categorie di Hangikredi.com da OnCrawl
Il mio principale concorrente ha oltre 340.000 link interni con migliaia di anchor text. In questi giorni, il nostro sito web aveva solo 70.000 link interni senza validi anchor text. Inoltre, la mancanza di collegamenti interni ha influito sul crawl budget e sulla produttività del sito web. Anche se l'80% del nostro traffico è stato raccolto su sole 20 pagine di prodotto, il 90% del nostro sito è costituito da pagine guida con informazioni utili per gli utenti. E la maggior parte delle nostre parole chiave e del punteggio di pertinenza per le query finanziarie provengono da queste pagine. Inoltre, c'erano innumerevoli pagine orfane.
A causa della struttura di collegamento interna mancante, quando ho eseguito Log Analysis con Kibana, ho notato che le pagine più scansionate erano quelle che ricevevano il minor traffico. Inoltre, quando l'ho accoppiato con la rete di link interni, ho scoperto che le pagine aziendali con il traffico più basso (Privacy, Cookie, Sicurezza, Pagine Chi siamo) hanno il numero massimo di link interni.
Come discuterò nella prossima sezione, ciò ha indotto Googlebot a rimuovere il fattore di collegamento interno da Pagerank durante la scansione del sito, rendendosi conto che i collegamenti interni non erano stati costruiti come previsto.
2. Problema: architettura del sito, Pagerank interno, traffico ed efficienza di scansione
Secondo la dichiarazione di Google, i link interni e gli anchor text aiutano Googlebot a comprendere l'importanza e il contesto di una pagina web. Pagerank interno o Inrank viene calcolato in base a più di un fattore. Secondo Bill Slawski, i link interni o esterni non sono tutti uguali. Il valore di un collegamento per il flusso di Pagerank cambia in base alla sua posizione, tipo, stile e peso del carattere.

Se Googlebot comprende quali pagine sono importanti per il tuo sito web, le eseguirà maggiormente la scansione e le indicizzerà più velocemente. I collegamenti interni e il corretto design dell'albero del sito sono fattori importanti per questo. Anche altri esperti hanno commentato questa correlazione nel corso degli anni:
“La maggior parte dei link fornisce un po' di contesto aggiuntivo attraverso il loro anchor text. Almeno dovrebbero, giusto?"
–John Mueller, Google 2017"Se hai pagine che ritieni importanti sul tuo sito , non seppellirle 15 link in profondità nel tuo sito e non sto parlando della lunghezza della directory, sto parlando di effettivamente devi fare clic su 15 link per trovare quella pagina se c'è una pagina che è importante o che ha grandi margini di profitto o converte davvero, beh, intensificare inserendo un collegamento a quella pagina dalla tua pagina principale, questo è il genere di cose in cui può avere molto senso. "
–Matt Cutts, Google 2011"Se una pagina si collega a un'altra con la parola "contatto" o la parola "informazioni" e la pagina a cui è collegata include un indirizzo, la posizione dell'indirizzo potrebbe essere considerata rilevante per la pagina che esegue il collegamento".
12 metodi di analisi dei link di Google che potrebbero essere cambiati: Bill Slawski
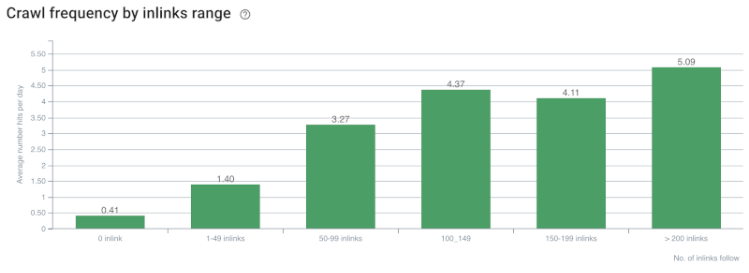
Correlazione tra velocità di scansione/domanda e conteggio dei link interni. Fonte: On Crawl.
Finora, possiamo fare queste inferenze:
- Google si preoccupa della profondità dei clic. Se una pagina web è più vicina alla home page, dovrebbe essere più importante. Ciò è stato confermato anche da John Mueller il 1° luglio 2018 in inglese Google Webmaster Hangout.
- Se una pagina web ha molti link interni che la indirizzano, dovrebbe essere importante.
- I testi di ancoraggio possono dare potere contestuale a una pagina web.
- Un collegamento interno può trasmettere diversi importi di Pagerank in base alla posizione, al tipo, al peso del carattere o allo stile.
- Un Site-Tree UX-friendly che fornisce messaggi chiari sull'autorità della pagina interna ai crawler dei motori di ricerca è una scelta migliore per la distribuzione di Inrank e l'efficienza della scansione.
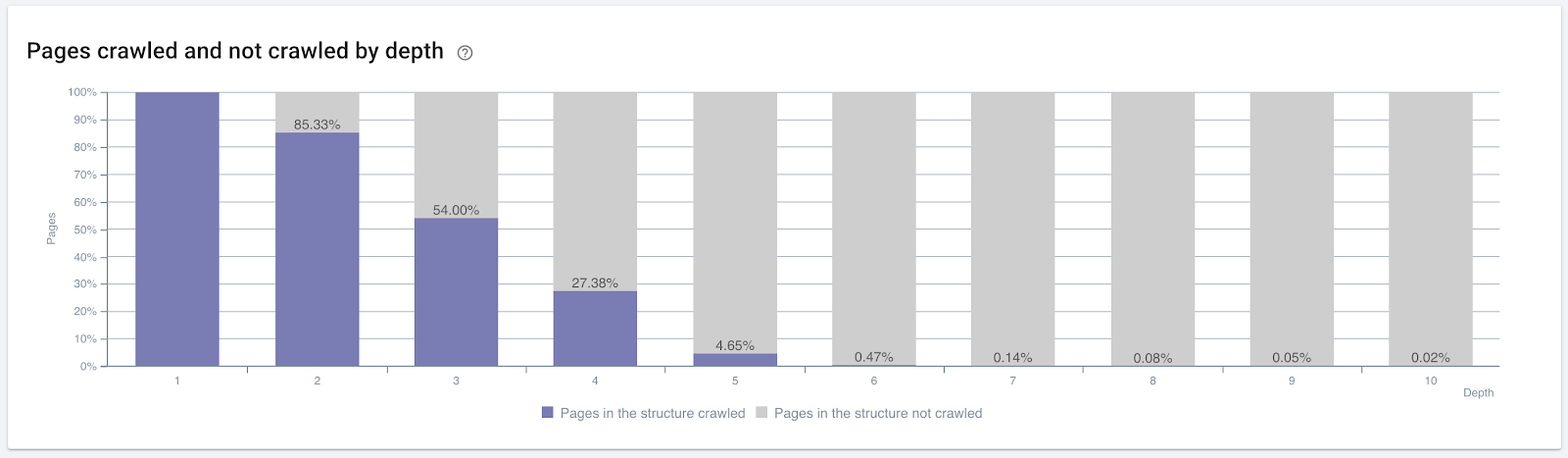
Percentuale di pagine scansionate in base alla profondità del clic. Fonte: On Crawl.
Ma questi non sono sufficienti per comprendere la natura e gli effetti dei collegamenti interni sull'efficienza della scansione.
Crawler SEO Oncrawl
 Per saperne di più
Per saperne di piùSe le tue pagine più internamente collegate non creano traffico o vengono cliccate, danno segnali che indicano che il tuo Site-Tree e la struttura dei link interni non sono costruiti secondo le intenzioni dell'utente. E Google cerca sempre di trovare le tue pagine più rilevanti con l'intento dell'utente o con entità di ricerca. Abbiamo un'altra citazione di Bill Slawski che chiarisce questo argomento:
"Se una risorsa è collegata da un numero di risorse sproporzionato rispetto al traffico ricevuto dall'uso di tali collegamenti, tale risorsa potrebbe essere retrocessa nel processo di classificazione".
L'aggiornamento di Groundhog ha avuto luogo su Google? — Bill Slawski"Il punteggio di qualità della selezione può essere più alto per una selezione che si traduce in un tempo di permanenza lungo (ad esempio, maggiore di un periodo di tempo soglia) rispetto al punteggio di qualità della selezione per una selezione che si traduce in un tempo di permanenza breve."
L'aggiornamento di Groundhog ha avuto luogo su Google? — Bill Slawski
Quindi abbiamo altri due fattori:
- Tempo di permanenza nella pagina collegata.
- Il traffico degli utenti che ha prodotto il collegamento.
Il conteggio dei link interni e lo stile/posizione non sono gli unici fattori. Anche il numero di utenti che seguono questi collegamenti e le loro metriche di comportamento sono importanti. Inoltre, sappiamo che i link e le pagine che vengono cliccati/visitati vengono scansionati da Google molto più dei link e delle pagine che non vengono cliccati o visitati.
"Ci siamo spostati sempre di più verso la comprensione delle sezioni di un sito per comprendere la qualità di quelle sezioni".
John Mueller, 2 maggio 2017, Hangout per webmaster di Google in inglese.
Alla luce di tutti questi fattori, condividerò due diversi e diversi risultati di Pagerank Simulator:
Questi calcoli di Pagerank sono effettuati partendo dal presupposto che tutte le pagine siano uguali, inclusa la Homepage. La vera differenza è determinata dalla gerarchia dei collegamenti.
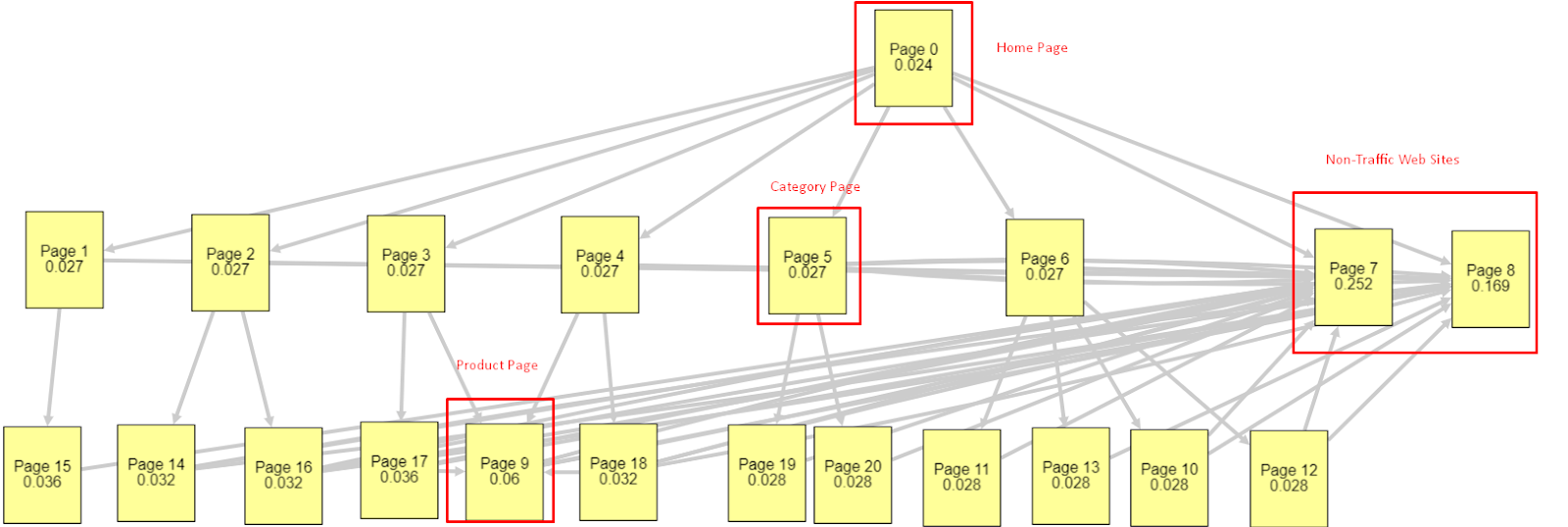
L'esempio mostrato qui è più vicino alla struttura del collegamento interno prima del 12 marzo. Homepage PR: 0.024, Pagina categoria PR: 0.027, Pagina prodotto PR: 0.06, Pagine Web non trafficate PR: 0.252.
Come puoi notare, Googlebot non può fidarsi di questa struttura di link interni per calcolare il pagerank interno e l'importanza delle pagine interne. Le pagine senza traffico e senza prodotto hanno un'autorità 12 volte maggiore rispetto alla home page. Ha più delle pagine dei prodotti.

Questo esempio è più vicino alla nostra situazione prima dell'aggiornamento dell'algoritmo di base del 5 giugno. PR della home page: 0,033, pagina della categoria: 0,037, pagina del prodotto: 0,148 e PR delle pagine non di traffico: 0,037.
Come puoi notare, la struttura dei link interni non è ancora corretta, ma almeno le pagine Web non trafficate non hanno più PR delle pagine delle categorie e delle pagine dei prodotti.
Qual è un'ulteriore prova che Google ha eliminato il collegamento interno e la struttura del sito dall'ambito del Pagerank in base al flusso degli utenti, alle richieste e alle intenzioni? Naturalmente il comportamento di Googlebot e le correlazioni di Inlink Pagerank e Ranking:
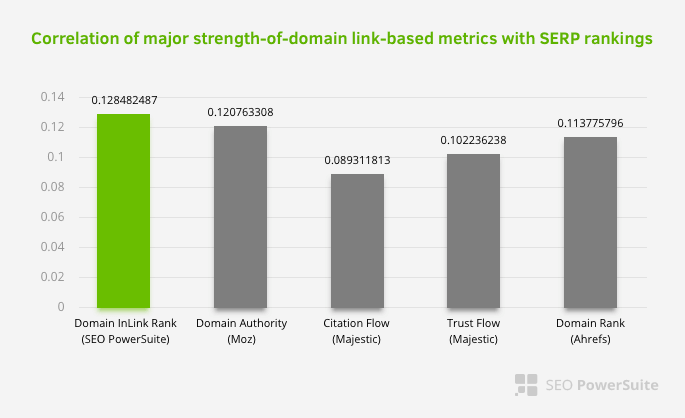
Ciò non significa che la rete di collegamento interna, in particolare, sia più importante di altri fattori. La prospettiva SEO che si concentra su un singolo punto non può mai avere successo. In un confronto tra strumenti di terze parti, mostra che il valore di Pagerank interno sta progredendo rispetto ad altri criteri.
Secondo l'Inlink Rank e la ricerca sulla correlazione del rango di Aleh Barysevich, le pagine con il maggior numero di link interni hanno un ranking più alto rispetto alle altre pagine del sito web. Secondo il sondaggio condotto il 4-6 marzo 2019, sono state analizzate 1.000.000 di pagine secondo la metrica interna Pagerank per 33.500 parole chiave. I risultati di questa ricerca condotta da SEO PowerSuite sono stati confrontati con le diverse metriche di Moz, Majestic e Ahrefs e hanno fornito risultati più accurati.
Ecco alcuni dei numeri di collegamento interni dal nostro sito prima dell'aggiornamento dell'algoritmo principale del 12 marzo:
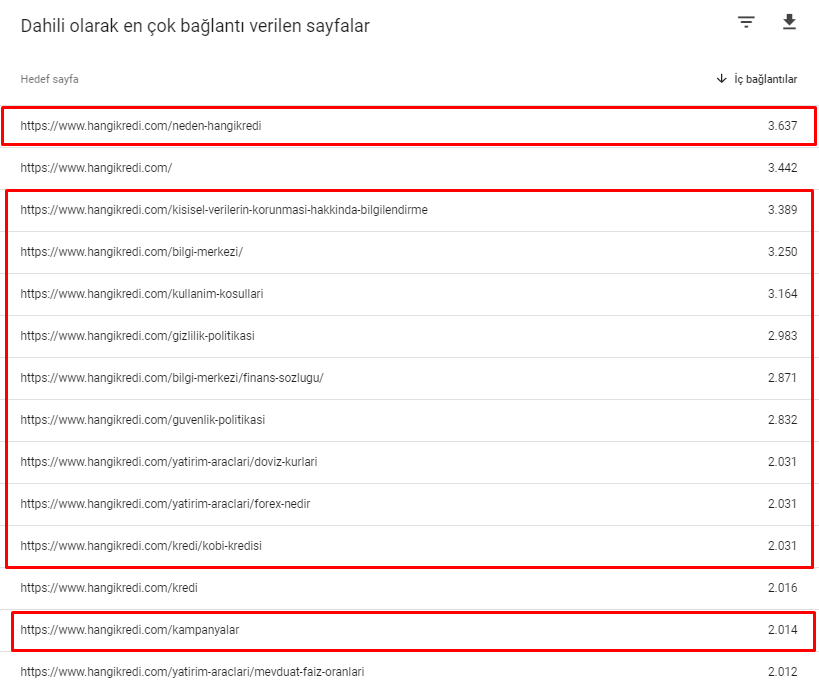
Come puoi vedere, il nostro schema di connessione interno non rifletteva l'intenzione e il flusso dell'utente. Le pagine che ricevono meno traffico (pagine di prodotto minori) o che non ricevono mai traffico (in rosso) erano direttamente nella profondità del 1° clic e ricevono PR dalla home page. E alcuni avevano anche più collegamenti interni rispetto alla home page.
Alla luce di tutto questo, ci sono solo gli ultimi due punti che possiamo mostrare su questo argomento.
- Velocità di scansione/domanda per le pagine più collegate internamente
- Link Sculpting e Pagerank
Tra il 1° febbraio e il 31 marzo, ecco le pagine che Googlebot ha scansionato più frequentemente:
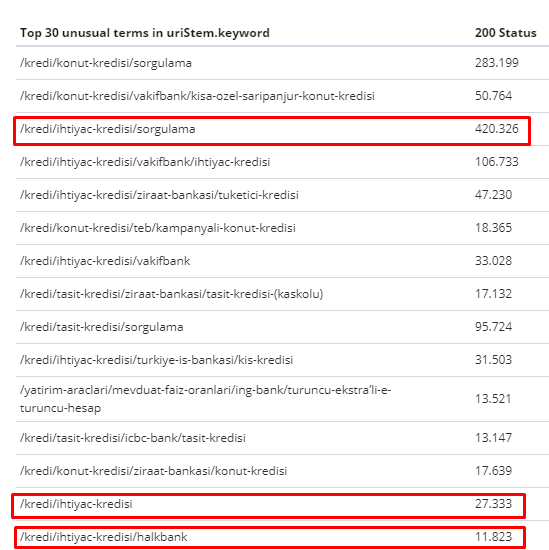
Come puoi notare, le pagine scansionate e le pagine che hanno la maggior parte dei collegamenti interni sono completamente diverse l'una dall'altra. Le pagine con il maggior numero di collegamenti interni non erano convenienti per l'intento dell'utente; non hanno parole chiave organiche o alcun tipo di valore SEO diretto. (
Gli URL nelle caselle rosse sono le nostre categorie di pagine di prodotto più visitate e importanti. Le altre pagine in questo elenco sono la seconda o la terza categoria più visitata e importanti.)
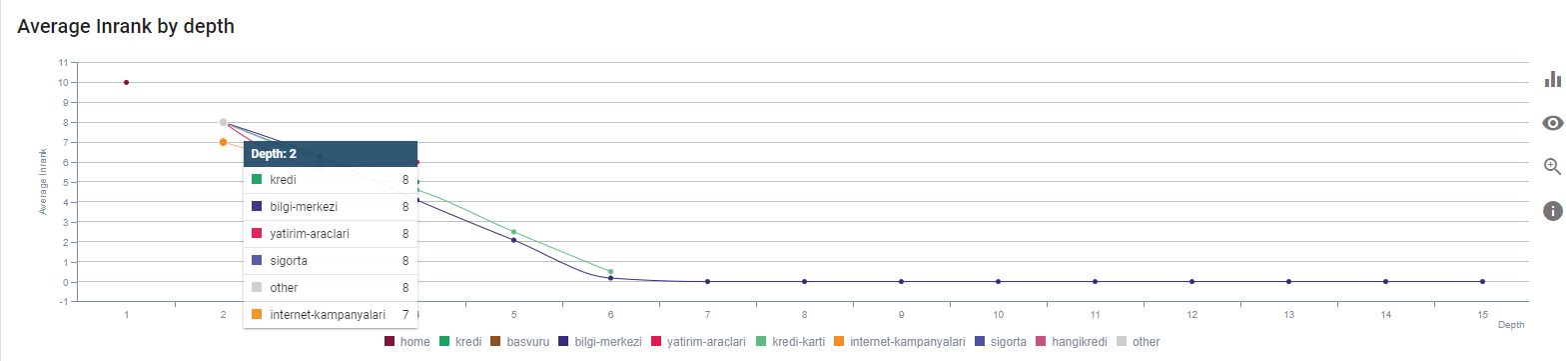
Il nostro attuale Inrank per profondità di pagina. Fonte: Oncrawl.
Che cos'è il Link Sculpting e cosa fare con i link internamente non seguiti?
Contrariamente a quanto credono la maggior parte dei SEO, i link contrassegnati con un tag "nofollow" passano comunque il valore interno del Pagerank. Per me, dopo tutti questi anni, nessuno ha raccontato questo elemento SEO meglio di Matt Cutts nel suo Pagerank Sculpting Article del 15 giugno 2009.
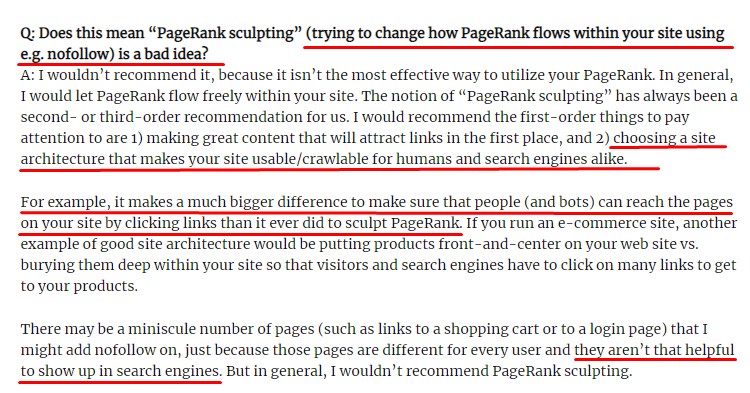
Una parte utile per Link Sculpting, che mostra il vero scopo di Pagerank Sculpting.
"Consiglierei di non usare nofollow per il tipo di scultura del PageRank all'interno di un sito Web perché probabilmente non fa quello che pensi che faccia."
–John Mueller, Google 2017
Se hai pagine web inutili in termini di Google e utenti, non dovresti taggarle con "nofollow". Non fermerà il flusso di Pagerank. Dovresti disabilitarli dal file robots.txt. In questo modo, Googlebot non li eseguirà per indicizzazione ma non passerà loro il Pagerank interno. Ma dovresti usarlo solo per pagine davvero inutili, come disse Matt Cutts dieci anni fa. Le pagine che effettuano reindirizzamenti automatici per il marketing di affiliazione o le pagine per lo più senza contenuto sono alcuni esempi utili qui.
Soluzione: struttura di collegamento interna migliore e più naturale
Il nostro concorrente ha avuto uno svantaggio. Il loro sito web aveva più anchor text, più link interni, ma la loro struttura non era naturale e utile. Lo stesso anchor text è stato utilizzato con la stessa frase su ogni pagina del loro sito. Il paragrafo di entrata per ogni pagina è stato coperto con questo contenuto ripetitivo. Ogni utente e motore di ricerca può facilmente riconoscere che questa non è una struttura naturale che considera il vantaggio dell'utente.
Quindi ho deciso tre cose da fare per correggere la struttura dei collegamenti interni:
- L'architettura dell'informazione del sito o l'albero del sito devono seguire un percorso diverso dai collegamenti inseriti all'interno del contenuto. Dovrebbe seguire più da vicino la mente dell'utente e una rete neurale di parole chiave.
- In ogni contenuto, le parole chiave laterali dovrebbero essere utilizzate insieme alle parole chiave principali della pagina target.
- I testi di ancoraggio dovrebbero essere naturali, adattati al contenuto e dovrebbero essere usati in un punto diverso di ogni pagina con attenzione alla percezione dell'utente
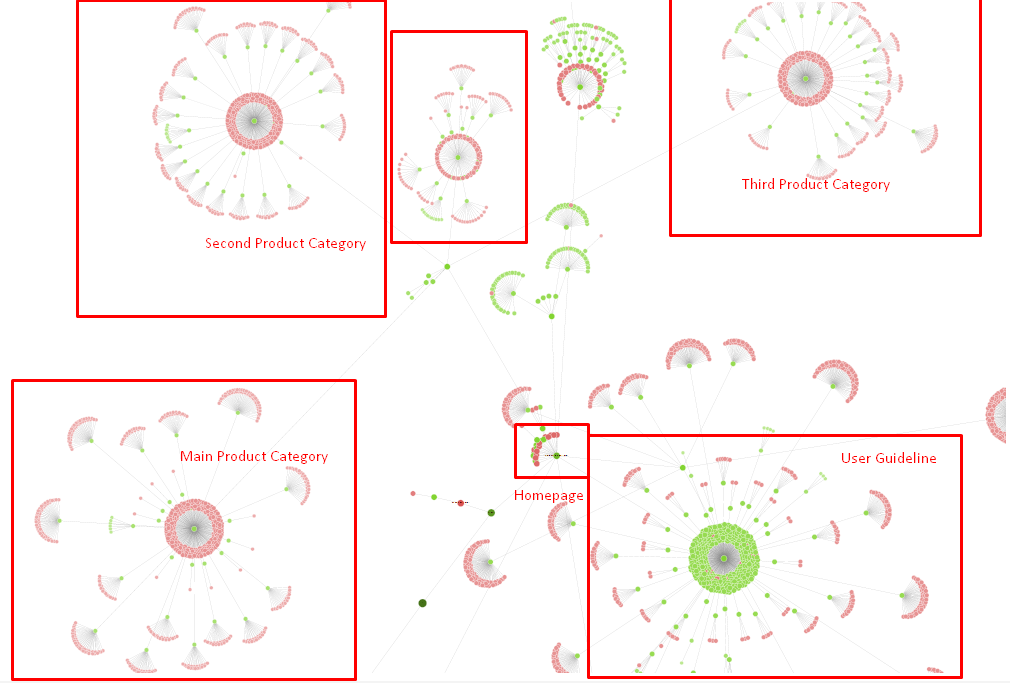
Il nostro albero del sito e una parte della struttura di collegamento per ora.
Nel diagramma sopra, puoi vedere il nostro attuale collegamento al link interno e l'albero del sito.
Alcune delle cose che abbiamo fatto per risolvere questo problema sono di seguito:
- Abbiamo creato altri 30.000 collegamenti interni con ancoraggi utili..
- Abbiamo utilizzato punti naturali e parole chiave per l'utente.
- Non abbiamo usato le frasi e gli schemi ripetitivi per i collegamenti interni.
- Abbiamo dato i segnali giusti al Googlebot sull'Inrank di una pagina web.
- Abbiamo esaminato gli effetti della corretta struttura dei link interni sull'efficienza della scansione tramite Log Analysis e abbiamo visto che le nostre pagine principali dei prodotti sono state scansionate di più rispetto alle statistiche precedenti.
- Creato più di 50.000 link interni per le pagine orfane.
- Utilizzato i collegamenti interni della home page per alimentare le sottopagine e creato più sorgenti di collegamento interne nella home page.
- Per proteggere Pagerank Power, abbiamo utilizzato anche il tag nofollow per alcuni link esterni non necessari. (Non si trattava di collegamenti interni ma serve allo stesso obiettivo.)
3. Problema: struttura dei contenuti
Google afferma che per i siti Web YMYL, l'affidabilità e l'autorità sono molto più importanti rispetto ad altri tipi di siti.

Ai vecchi tempi, le parole chiave erano solo parole chiave. Ma ora sono anche entità ben definite, singolari, significative e distinguibili. Nel nostro contenuto, c'erano quattro problemi principali:
- Il nostro contenuto era breve. (Normalmente, la lunghezza del contenuto non è importante. Ma in questo caso non contenevano informazioni sufficienti sugli argomenti.)
- I nomi dei nostri scrittori non erano singolari, significativi o distinguibili come entità.
- Il nostro contenuto non era accattivante. In altre parole, non era contenuto da "fast food". Era contenuto senza sottotitoli.
- Abbiamo usato il linguaggio del marketing. Nello spazio di un paragrafo, potremmo identificare il nome del marchio e la sua pubblicità per l'utente.
- C'erano molti pulsanti che indirizzavano gli utenti alle pagine dei prodotti dalle pagine informative.
- Nei contenuti delle nostre pagine prodotto non c'erano informazioni sufficienti o linee guida complete.
- Il design non era facile da usare. Stavamo usando praticamente lo stesso colore per font e sfondo. (Questo è per lo più ancora il caso a causa di problemi infrastrutturali.)
- Immagini e video non sono stati visti come parte del contenuto.
- L'intento dell'utente e l'intento di ricerca per una parola chiave specifica non erano stati considerati importanti prima.
- C'erano molti contenuti duplicati, non necessari e ripetitivi per lo stesso argomento.
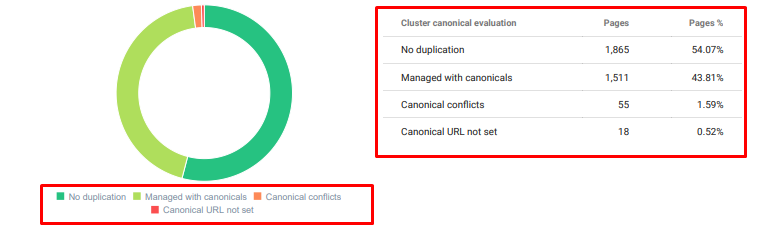
Oncrawl Duplicated Content Audit da oggi.
Soluzione: una migliore struttura dei contenuti per la fiducia degli utenti
Quando si verifica un problema a livello di sito, l'utilizzo di un programma di audit a livello di sito come assistente è un modo migliore per organizzare il tempo dedicato ai progetti SEO. Come nella sezione dei collegamenti interni, ho utilizzato Oncrawl Site Audit insieme ad altri strumenti e ispezioni Xpath.
In primo luogo, risolvere ogni problema nella sezione dei contenuti avrebbe richiesto troppo tempo. In quei giorni di crisi che crollavano, il tempo era un lusso. Quindi ho deciso di risolvere problemi di vincita rapida come:
- Eliminazione di contenuti duplicati, non necessari e ripetitivi
- Unificazione di contenuti brevi e sottili privi di informazioni complete
- Ripubblicazione di contenuti privi di sottotitoli e struttura tracciabile dagli occhi
- Correzione del tono di marketing intensivo nel contenuto
- Eliminazione di molti pulsanti di invito all'azione dal contenuto
- Migliore comunicazione visiva con immagini e video
- Rendere il contenuto e le parole chiave di destinazione compatibili con l'utente e l'intento di ricerca
- Usare e mostrare entità finanziarie ed educative nel contenuto per la fiducia
- Utilizzo della comunità sociale per creare prove sociali di approvazione
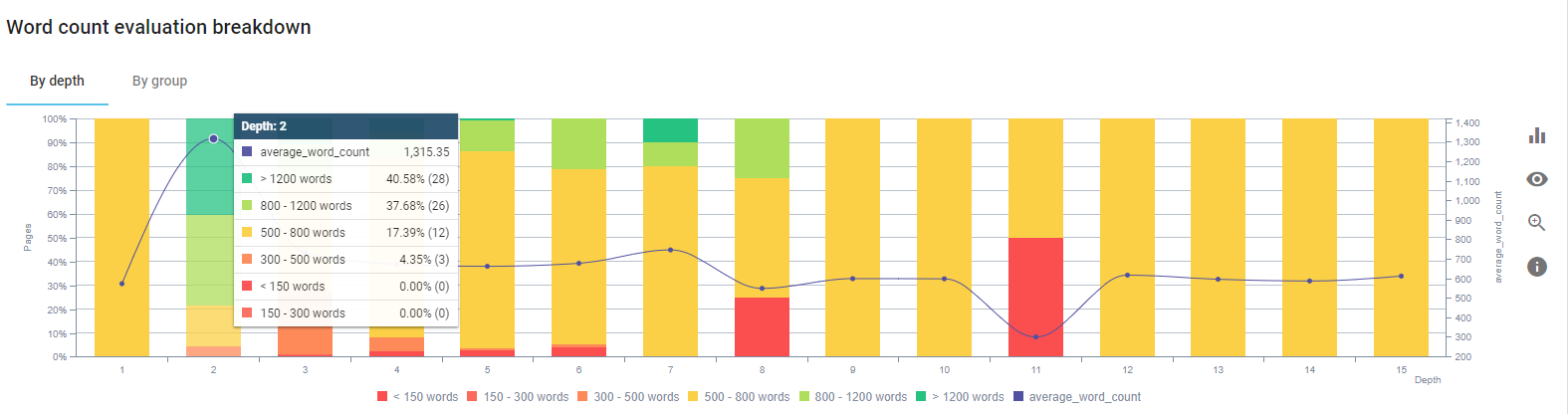

Ci siamo concentrati sulla correzione dei contenuti delle pagine dei prodotti e delle pagine guida a loro più vicine.
All'inizio di questo processo, la maggior parte dei nostri prodotti e pagine di destinazione/linee guida transazionali contenevano meno di 500 parole senza informazioni complete.
In 25 giorni, le azioni che abbiamo svolto sono le seguenti:
- Eliminate 228 pagine con contenuti duplicati, non necessari e ripetitivi. (I profili di backlink di Ccontent sono stati controllati prima del processo di eliminazione. E abbiamo utilizzato codici di stato 301 o 410 per una migliore comunicazione con Googlebot.)
- Combinato più di 123 pagine prive di informazioni complete.
- Sottotitoli utilizzati in base alla loro importanza e alla domanda degli utenti nei contenuti.
- Cancellati il nome del marchio e i pulsanti CTA con linguaggio in stile marketing.
- Includi testo nelle immagini per rafforzare l'argomento principale.
Questo è uno screenshot di Vision AI di Google. Google può leggere il testo nelle immagini e rilevare sentimenti e identità all'interno delle entità.
- Attivato il nostro social network per attirare più utenti.
- Ha esaminato il divario di contenuto tra i concorrenti e noi e ha creato più di 80 nuovi contenuti.
- Utilizzato Google Analytics, Search Console e Google Data Studio per determinare le pagine con prestazioni inferiori a quelle con una frequenza di rimbalzo elevata e traffico ridotto.
- Ha cercato i frammenti in primo piano, le loro parole chiave e la struttura dei contenuti. Abbiamo aggiunto le stesse intestazioni e la stessa struttura dei contenuti nei nostri contenuti correlati Ciò ha aumentato i nostri frammenti in primo piano.
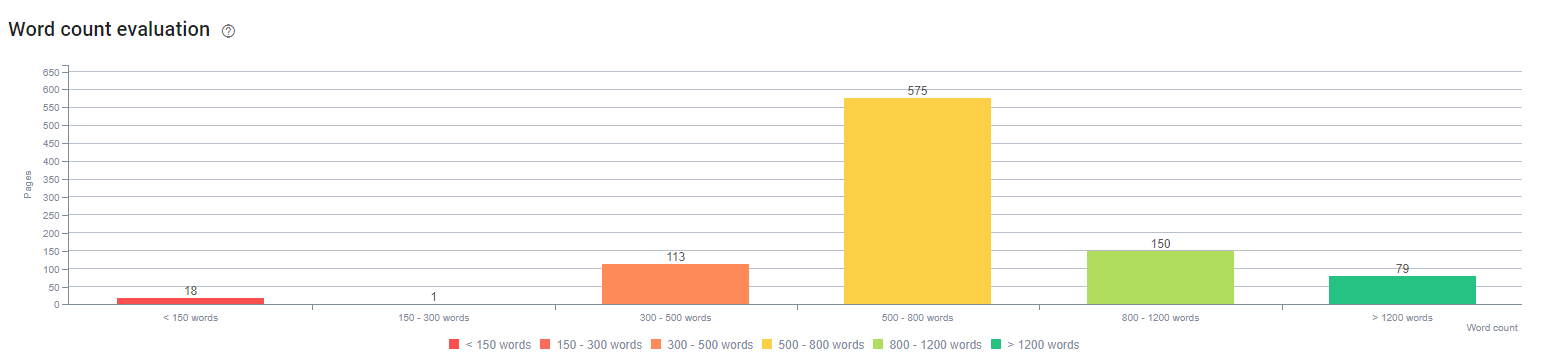
All'inizio di questo processo, i nostri contenuti erano composti principalmente da 150 e 300 parole. La durata media dei nostri contenuti è aumentata di 350 parole per tutto il sito.
4. Problema: inquinamento dell'indice, rigonfiamento e tag canonici
Google non ha mai rilasciato una dichiarazione sull'inquinamento dell'indice e infatti non sono sicuro se qualcuno lo abbia usato prima come termine SEO o meno. Tutte le pagine che non hanno senso per Google per un punteggio dell'indice più efficiente dovrebbero essere rimosse dalle pagine dell'indice di Google. Le pagine che causano l'inquinamento dell'indice sono pagine che non producono traffico da mesi. Hanno zero CTR e zero parole chiave organiche. Nei casi in cui hanno poche parole chiave organiche, dovrebbero diventare concorrenti di altre pagine del tuo sito per le stesse parole chiave.
Inoltre, abbiamo condotto una ricerca per il rigonfiamento dell'indice e trovato pagine indicizzate ancora più non necessarie. Queste pagine esistevano a causa di una struttura errata delle informazioni sul sito oa causa di una struttura URL errata.
Un altro motivo di questo problema è stato l'utilizzo errato di tag canonici. Per più di due anni, i tag canonici sono stati trattati come semplici suggerimenti per Googlebot. Se vengono utilizzati in modo errato, Googlebot non li calcolerà né presterà attenzione durante la valutazione del sito. Inoltre, per questo calcolo, probabilmente consumerai il tuo crawl budget in modo inefficiente. A causa dell'utilizzo errato dei tag canonici, sono state indicizzate più di 300 pagine di commenti con contenuti duplicati.
L'obiettivo della mia teoria è mostrare a Google solo pagine di qualità e necessarie con il potenziale di guadagnare clic e creare valore per gli utenti.
Soluzione: correzione dell'inquinamento dell'indice e del gonfiore
Per prima cosa, ho ricevuto consigli da John Mueller di Google. Gli ho chiesto se avessi usato il tag noindex per queste pagine, ma avrei comunque permesso a Googlebot di seguirle, "perderei l'equità dei link e l'efficienza della scansione?"
Come puoi immaginare, all'inizio ha detto di sì, ma poi ha suggerito che l'utilizzo di collegamenti interni può superare questo ostacolo.
Ho anche scoperto che l'utilizzo di tag noindex contemporaneamente a dofollow ha ridotto la velocità di scansione di Googlebot su queste pagine. Queste strategie mi hanno permesso di fare in modo che Googlebot esegua più spesso la scansione del mio prodotto e delle pagine delle linee guida importanti. Ho anche modificato la mia struttura interna dei link come consigliato da John Mueller.
In poco tempo:
- Sono state scoperte pagine indicizzate non necessarie.
- Più di 300 pagine sono state rimosse dall'indice.
- Il tag Noindex è stato implementato.
- La struttura interna dei link è stata modificata per le pagine che hanno ricevuto link da pagine che sono state rimosse dall'indice.
- L'efficienza e la qualità della scansione sono state esaminate nel tempo.
5. Problema: codici di stato errati
All'inizio, ho notato che Googlebot visita molti contenuti eliminati dal passato. Anche le pagine di otto anni fa venivano ancora scansionate. Ciò era dovuto all'uso di codici di stato errati, in particolare per i contenuti eliminati.
C'è un'enorme differenza tra 404 e 410 funzioni. Uno di questi è per una pagina di errore in cui non esiste alcun contenuto e l'altro è per il contenuto eliminato. Inoltre, le pagine valide facevano riferimento anche a molti URL di origine e di contenuto eliminati. Alcune immagini eliminate e risorse CSS o JS sono state utilizzate anche nelle pagine pubblicate valide come risorse. Infine, c'erano molte pagine soft 404 e più catene di reindirizzamento e reindirizzamenti temporanei 302-307 per pagine reindirizzate in modo permanente.
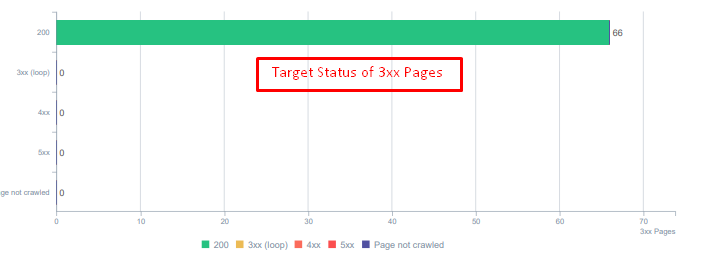
Codici di stato per le risorse reindirizzate oggi.
Soluzione: correzione di codici di stato errati
- Ogni codice di stato 404 è stato convertito in codice di stato 410. (Più di 30000)
- Ogni risorsa con codice di stato 404 è stata sostituita con una nuova risorsa valida. (Più di 500)
- Ogni reindirizzamento 302-307 è stato convertito in reindirizzamento permanente 301. (Più di 1500)
- Le catene di reindirizzamento sono state rimosse dalle risorse in uso.
- Ogni mese, abbiamo ricevuto più di 25.000 visite su pagine e risorse con un codice di stato 404 nella nostra analisi del registro. Ora sono meno di 50 per 404 codici di stato al mese e zero riscontri per 410 codici di stato...
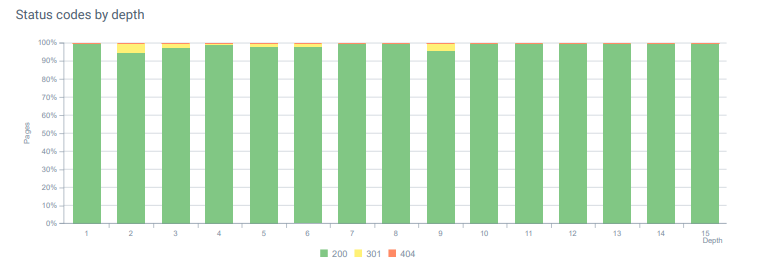
Codici di stato in tutta la profondità della pagina oggi.
6. Problema: HTML semantico
La semantica si riferisce a cosa significa qualcosa. L'HTML semantico include tag che danno il significato al componente della pagina all'interno di una gerarchia. Con questa struttura di codice gerarchica, puoi dire a Google qual è lo scopo di una parte del contenuto. Inoltre, nel caso in cui Googlebot non sia in grado di eseguire la scansione di tutte le risorse necessarie per eseguire il rendering completo della tua pagina, puoi almeno specificare il layout della tua pagina web e le funzioni dei tuoi contenuti su Googlebot.
Su Hangikredi.com, dopo l'aggiornamento dell'algoritmo di Google Core del 12 marzo, sapevo che non c'era abbastanza budget di scansione a causa della struttura non ottimizzata del sito web. Quindi, per far capire a Googlebot lo scopo, la funzione, il contenuto e l'utilità della pagina web più facilmente, ho deciso di utilizzare l'HTML semantico.
Soluzione: utilizzo semantico dell'HTML
Secondo le Linee guida per la valutazione della qualità di Google, ogni ricercatore ha un intento e ogni pagina web ha una funzione in base a tale intento. Per dimostrare queste funzioni a Googlebot, abbiamo apportato alcuni miglioramenti alla nostra struttura HTML per alcune delle pagine che vengono scansionate meno da Googlebot.
- Usato il tag <main> per mostrare il contenuto principale e la funzione della pagina.
- Usato <nav> per la parte di navigazione.
- Usato <footer> per il footer del sito.
- Usato <articolo> per l'articolo.
- Usato i tag <section> per ogni tag di intestazione.
- Usato i tag <picture>, <table>, <citation> per immagini, tabelle e citazioni nel contenuto.
- Usato, tag <aside> per il contenuto supplementare.
- Risolti i problemi di gerarchia H1-H6 (nonostante l'ultima affermazione di Google "l'utilizzo di due H1 non è un problema", l'utilizzo della struttura corretta aiuta Googlebot.)
- Come nella sezione relativa alla struttura del contenuto, abbiamo utilizzato anche l'HTML semantico per gli snippet in primo piano, abbiamo utilizzato tabelle ed elenchi per ulteriori risultati degli snippet in primo piano.

Per noi, questo non è stato uno sviluppo realisticamente implementabile per l'intero sito. Tuttavia, con ogni aggiornamento del design, continuiamo a implementare tag HTML semantici per pagine Web aggiuntive.
7. Problema: utilizzo strutturato dei dati
Analogamente all'utilizzo dell'HTML semantico, i Dati strutturati possono essere utilizzati per mostrare a Googlebot le funzioni e le definizioni delle parti di pagine Web. Inoltre, i dati strutturati sono obbligatori per i risultati multimediali. Sul nostro sito web i dati strutturati non sono stati utilizzati o, più comunemente, sono stati utilizzati in modo errato fino alla fine di marzo. Al fine di creare migliori relazioni con le entità sul nostro sito Web e i nostri account off-page, abbiamo iniziato a implementare i dati strutturati.
Soluzione: utilizzo corretto e testato dei dati strutturati
Per gli istituti finanziari e i siti Web YMYL, i dati strutturati possono risolvere molti problemi. Ad esempio, possono mostrare l'identità del marchio, il tipo di contenuto e creare una migliore visualizzazione degli snippet. Abbiamo utilizzato i seguenti tipi di dati strutturati per le singole pagine e per l'intero sito:
- Domande frequenti sui dati strutturati per le pagine dei prodotti principali
- Dati strutturati della pagina web
- Dati strutturati dell'organizzazione
- Dati strutturati breadcrumb
8. Ottimizzazione della mappa del sito e di Robots.txt
Su Hangikredi.com non esiste una Sitemap dinamica. La mappa del sito esistente all'epoca non includeva tutte le pagine necessarie e includeva anche il contenuto eliminato. Inoltre, nel file Robots.txt, alcune delle pagine referrer di affiliazione con migliaia di link esterni non sono state disabilitate. Ciò includeva anche alcuni file JS di terze parti non correlati al contenuto e altre risorse aggiuntive non necessarie per Googlebot.
Sono stati applicati i seguenti passaggi:
- Creato un sitemap_index.xml per più sitemap che vengono create in base alle categorie del sito per migliori segnali di scansione e un migliore esame della copertura.
- Alcuni dei file JS di terze parti e alcuni file JS non necessari non sono stati consentiti nel file robots.txt.
- Le pagine di affiliazione con link esterni e nessun valore di pagina di destinazione sono state disabilitate, come accennato nella sezione Pagerank o Scultura di link interni.
- Risolti più di 500 problemi di copertura. (La maggior parte di esse erano pagine indicizzate nonostante non fossero consentite da Robots.txt.)
Puoi vedere la nostra velocità di scansione, carico e aumento della domanda dal grafico seguente:
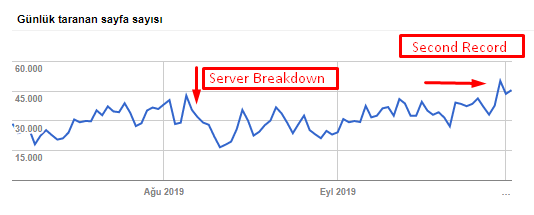
Numero di pagine scansionate al giorno da Googlebot. Si è verificato un aumento costante delle pagine scansionate al giorno fino al 1° agosto. Dopo che un attacco ha causato un guasto al server all'inizio di agosto, ha riguadagnato la sua stabilità in poco più di un mese.

Il caricamento giornaliero scansionato da Googlebot si è evoluto parallelamente al numero di pagine scansionate al giorno.
9. Risoluzione dei problemi AMP
Sul sito web dell'azienda, ogni pagina del blog ha una versione AMP. A causa dell'implementazione errata del codice e dei canoni AMP mancanti, tutte le pagine AMP sono state ripetutamente eliminate dall'indice. Ciò ha creato un punteggio indice instabile e mancanza di fiducia per il sito web. Inoltre, le pagine AMP avevano termini e parole inglesi per impostazione predefinita sui contenuti in turco.
- I tag canonici sono stati corretti per più di 400 pagine AMP.
- Sono state trovate e corrette implementazioni di codice errate. (Era principalmente dovuto all'errata implementazione dei tag AMP-Analytics e AMP-Canonical.)
- I termini inglesi per impostazione predefinita sono stati tradotti in turco.
- La stabilità dell'indice e del ranking è stata creata per il lato blog del sito Web dell'azienda.
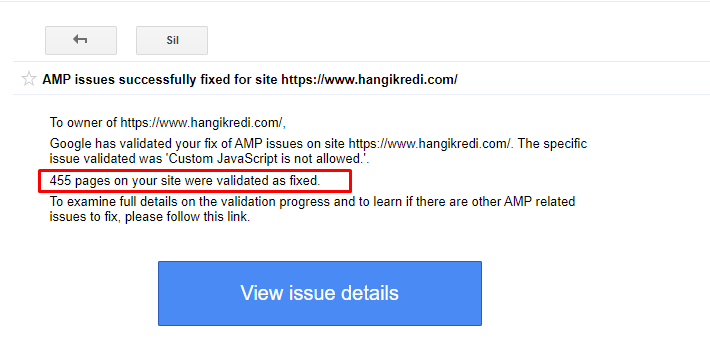
Un messaggio di esempio in GSC sui miglioramenti AMP
10. Problemi e soluzioni dei meta tag
A causa dei problemi di crawl budget, a volte nelle query di ricerca critiche per importanti pagine di prodotti principali, Google non ha indicizzato né visualizzato i contenuti nei meta tag. Invece del meta titolo, l'elenco SERP mostrava solo il nome dell'azienda formato da due parole. Non è stata mostrata alcuna descrizione dello snippet. Ciò stava abbassando il nostro CTR e danneggiando la nostra identità del marchio. Abbiamo risolto questo problema spostando i meta tag nella parte superiore del nostro codice sorgente come mostrato di seguito.
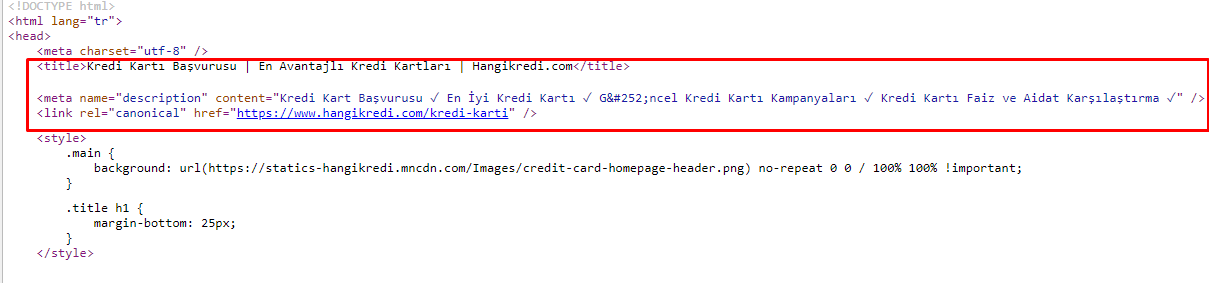
Oltre al crawl budget, abbiamo anche ottimizzato più di 600 meta tag per pagine transazionali e informative:
- Lunghezza dei caratteri ottimizzata per i dispositivi mobili.
- Utilizzate più parole chiave nei titoli
- Utilizzato uno stile diverso di meta tag ed esaminato il CTR, il gap di parole chiave e le modifiche al ranking
- Creato più pagine con una corretta struttura ad albero del sito per indirizzare meglio le parole chiave secondarie grazie a questi processi di ottimizzazione.
- Sul nostro sito abbiamo ancora diversi meta titoli, descrizioni e intestazioni per testare l'algoritmo di Google e cercare il CTR degli utenti.
11. Problemi di prestazioni dell'immagine e soluzioni
I problemi di immagine possono essere divisi in due tipi. Per comodità dei contenuti e per la velocità della pagina. Per entrambi, il sito web dell'azienda ha ancora molto da fare.
A marzo e aprile a seguito dell'aggiornamento negativo dell'algoritmo core del 12 marzo:
- Le immagini non avevano tag alt o avevano tag alt errati.
- Non avevano titoli.
- Non avevano una struttura URL corretta.
- Non avevano estensioni di nuova generazione.
- Non sono stati compressi.
- Non avevano la risoluzione giusta per tutte le dimensioni dello schermo del dispositivo.
- Non avevano didascalie.
Per prepararti al prossimo aggiornamento dell'algoritmo di Google Core:
- Le immagini sono state compresse.
- Le loro estensioni sono state parzialmente modificate.
- I tag Alt sono stati scritti per la maggior parte di essi.
- I titoli e le didascalie sono stati corretti per l'utente.
- Le strutture degli URL sono state parzialmente corrette per l'utente.
- Abbiamo trovato alcune immagini inutilizzate che sono ancora caricate dal browser e le abbiamo cancellate dal sistema.
A causa dell'infrastruttura del sito, abbiamo parzialmente implementato le correzioni SEO delle immagini.
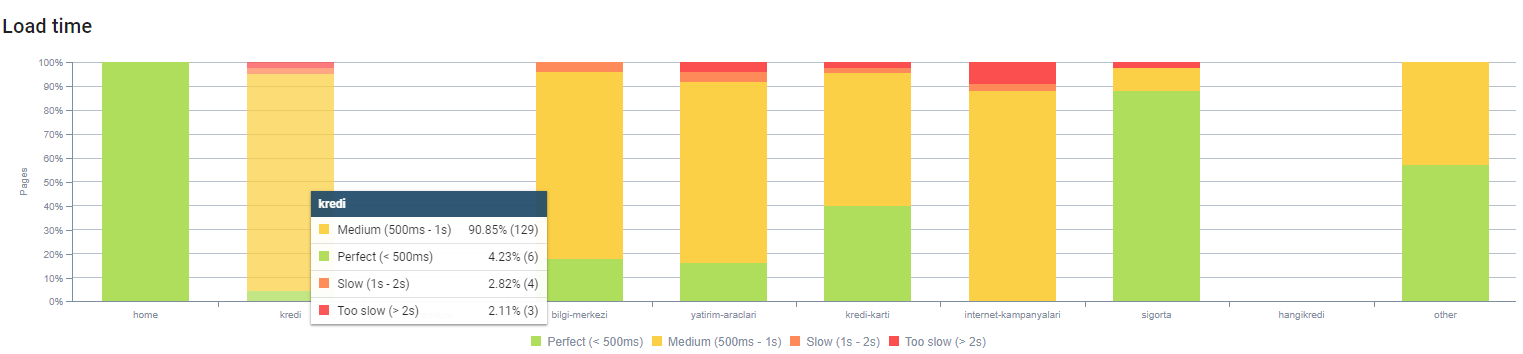
Puoi osservare il nostro tempo di caricamento della pagina in base alla profondità della pagina sopra. Come puoi vedere, la maggior parte delle pagine dei prodotti sono ancora pesanti.
12. Problemi e soluzioni di cache, precaricamento e precaricamento
Prima dell'aggiornamento del Core Algorithm del 12 marzo, c'era un sistema di cache allentata sul sito web dell'azienda. Alcune parti del contenuto erano nella cache, ma altre no. Questo è stato un problema soprattutto per le pagine dei prodotti perché erano 2 volte più lente delle pagine dei prodotti dei nostri concorrenti. La maggior parte dei componenti delle nostre pagine Web sono in realtà sorgenti statiche, ma non avevano ancora Etag per indicare l'intervallo di cache.
Per prepararti al prossimo aggiornamento dell'algoritmo di Google Core:
- Abbiamo memorizzato nella cache alcuni componenti per ogni pagina Web e li abbiamo resi statici.
- Queste pagine erano pagine di prodotti importanti.
- Continuiamo a non utilizzare E-Tag a causa dell'infrastruttura del sito.
- Soprattutto le immagini, le risorse statiche e alcune parti di contenuto importanti ora sono completamente memorizzate nella cache a livello di sito.
- Abbiamo iniziato a utilizzare il codice dns-prefetch per alcune risorse esternalizzate dimenticate.
- Non utilizziamo ancora il codice di precaricamento ma stiamo lavorando sul percorso dell'utente sul sito per implementarlo in futuro.
13. Ottimizzazione e minimizzazione di HTML, CSS e JS
A causa dei problemi con l'infrastruttura del sito, non c'erano molte cose da fare per la velocità del sito. Ho cercato di colmare il divario con ogni metodo possibile, inclusa l'eliminazione di alcuni componenti della pagina. Per importanti pagine di prodotti, abbiamo pulito la struttura del codice HTML, l'abbiamo ridotta a icona e compressa.
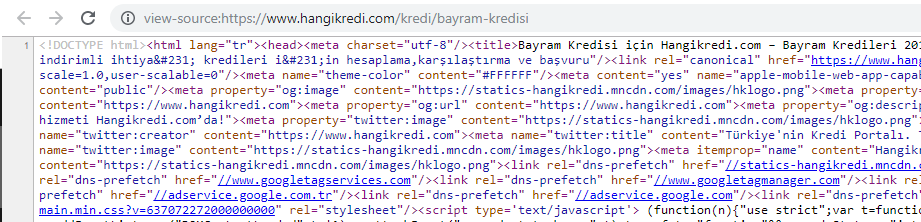
Uno screenshot da uno dei nostri codici sorgente stagionali ma importanti della pagina del prodotto. L'utilizzo dei dati strutturati delle domande frequenti, la minimizzazione dell'HTML, l'ottimizzazione delle immagini, l'aggiornamento dei contenuti e i collegamenti interni ci hanno dato il primo posto al momento giusto. (La parola chiave è “Bayram Kredisi” in turco, che significa “credito vacanze”)
Abbiamo anche implementato parzialmente CSS Factoring, Refactoring e JS Compression con piccoli passaggi. Quando la classifica è scesa, abbiamo esaminato il divario di velocità del sito tra le pagine del nostro concorrente e le nostre. Avevamo scelto delle pagine urgenti che avremmo potuto velocizzare. Abbiamo anche parzialmente purificato e compresso i file CSS critici su queste pagine. Abbiamo avviato il processo di rimozione di alcuni dei file JS di terze parti utilizzati da diversi dipartimenti dell'azienda, ma non sono stati ancora rimossi. Per alcune pagine di prodotto, siamo stati anche in grado di modificare l'ordine di caricamento delle risorse.
Esame dei concorrenti
Oltre a ogni miglioramento tecnico SEO, l'ispezione della concorrenza è stata la mia migliore guida per comprendere la natura e gli obiettivi di un Core Algorithm Update. Ho utilizzato alcuni programmi utili e utili per seguire i cambiamenti di design, contenuto, classifica e tecnologia del mio concorrente.
- Per le modifiche al ranking delle parole chiave, ho usato Wincher, Semrush e Ahrefs.
- Per le menzioni del marchio, ho utilizzato Google Alert, BuzzSumo, Talkwalker.
- Per nuovi link e nuove parole chiave che guadagnano rapporti ho usato Ahrefs Alert.
- Per le modifiche al contenuto e al design, ho utilizzato Visualping.
- Per i cambiamenti tecnologici, ho usato SimilarTech.
- Per Google Update News and Inspection, ho utilizzato principalmente Semrush Sensor, Algoroo e CognitiveSEO Signals.
- Per controllare la cronologia degli URL dei concorrenti, ho utilizzato Wayback Machine.
- Per la velocità del server dei concorrenti, ho usato Chrome DevTools e ByteCheck.
- Per i costi di scansione e rendering, ho utilizzato "Quanto costa il mio sito". (Since last month, I have started using Onely's new JS Tools like WWJD or TL:DR..)

A screenshot from SimilarTech for my main competitor.
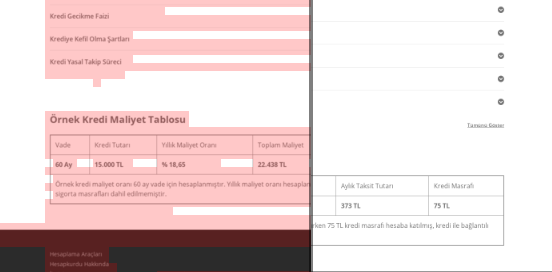
A screenshot from Visualping which shows the layout changes for my secondary competitor.
Testing the value of the changes
With all of these problems identified and solutions in place, I was ready to see whether the website would hold up to the next Google core algorithm updates.
In the next article, I'll look at the major core algorithm updates over the next several months, and how the site performed.