
Previsione del traffico SEO con Prophet e Python
Pubblicato: 2021-03-16Fissare obiettivi e valutare i risultati nel tempo è un esercizio molto interessante per capire cosa siamo in grado di ottenere e se la strategia che utilizziamo è efficace o meno. Tuttavia, di solito non è così facile fissare questi obiettivi perché dovremo prima elaborare una previsione.
Creare una previsione non è una cosa semplice ma grazie ad alcune procedure di previsione disponibili, alla nostra CPU e ad alcune capacità di programmazione possiamo ridurne parecchio la complessità. In questo post, ti mostrerò come possiamo fare previsioni accurate e come puoi applicarlo alla SEO usando Python e la libreria Prophet e senza dover avere superpoteri di indovino.
Se non hai mai sentito parlare di Prophet potresti chiederti di cosa si tratta. In breve, Prophet è una procedura di previsione rilasciata dal team Core Data Science di Facebook, disponibile in Python e R e che tratta molto bene i valori anomali e gli effetti stagionali per
fornire previsioni accurate e veloci.
Quando parliamo di previsione, dobbiamo prendere in considerazione due cose:
- Più dati storici abbiamo, più accurati saranno il nostro modello e quindi le nostre previsioni.
- Il modello predittivo sarà valido solo se i fattori interni rimangono gli stessi e non ci sono fattori esterni che lo influenzano. Ciò significa che se, ad esempio, pubblichiamo un post a settimana e iniziamo a pubblicare due post a settimana, questo modello potrebbe non essere valido per prevedere quale sarà il risultato di questo cambiamento di strategia. D'altra parte, se c'è un aggiornamento dell'algoritmo, anche il modello potrebbe non essere valido. Tieni presente che il modello è costruito sulla base di dati storici.
Per applicare questo alla SEO, quello che faremo è prevedere le sessioni SEO per il prossimo mese seguendo i passaggi successivi:
- Ottenere dati da Google Analytics sulle sessioni organiche per un periodo di tempo specifico.
- Allenare il nostro modello.
- Previsione del traffico SEO per il prossimo mese.
- Valutare quanto è buono il nostro modello con l'errore medio assoluto.
Vuoi saperne di più su come funziona questa procedura di previsione? Cominciamo allora!
Ottenere i dati da Google Analytics
Possiamo avvicinarci all'estrazione dei dati da Google Analytics in due modi: esportando un file Excel dalla normale interfaccia o utilizzando l'API per recuperare questi dati.
Importazione dei dati da un file Excel
Il modo più semplice per ottenere questi dati da Google Analytics è andare nella sezione Canali della barra laterale, fare clic su Organico ed esportare i dati con il pulsante che si trova in cima alla pagina. Assicurati di selezionare nel menu a tendina nella parte superiore del grafico la variabile che desideri analizzare, in questo caso Sessions.
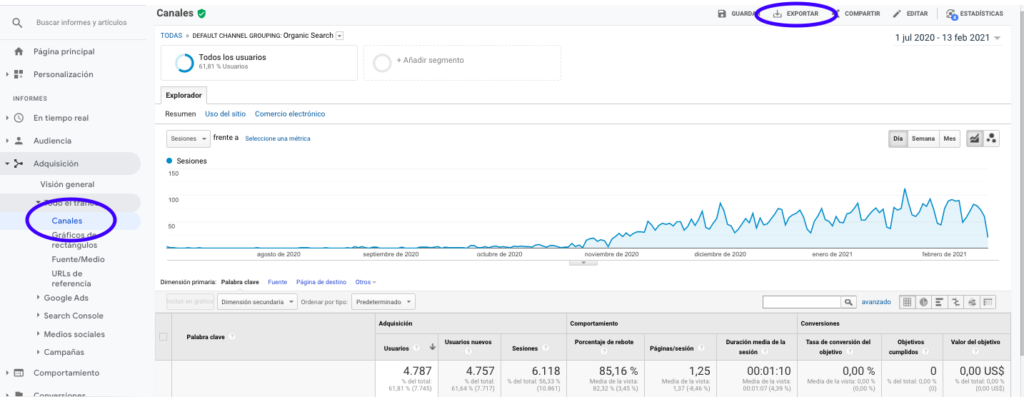
Dopo aver esportato i dati come file Excel, possiamo importarli nel nostro taccuino con Pandas. Si noti che il file Excel con tali dati conterrà schede diverse, quindi la scheda con il traffico mensile deve essere specificata come argomento nel pezzo di codice che si trova di seguito. Cancelliamo anche l'ultima riga perché contiene la quantità totale di sessioni, che distorcerebbero il nostro modello.
importa panda come pd
df = pd.read_excel ('.xlsx', sheet_name= "")
df = df.drop(len(df) - 1)
Possiamo disegnare con Matplotlib come appaiono i dati:
da matplotlib import pyplot
df["Sesioni"].plot(title = "Sezioni")
pyplot.show() 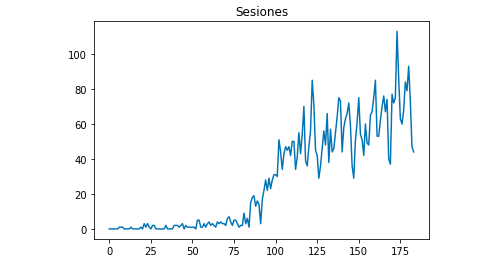
Utilizzo dell'API di Google Analytics
Innanzitutto, per poter utilizzare l'API di Google Analytics, è necessario creare un progetto sulla console degli sviluppatori di Google, abilitare il servizio di Reporting di Google Analytics e ottenere le credenziali. Jean-Christophe Chouinard spiega molto bene in questo articolo come impostarlo.
Una volta ottenute le credenziali, dobbiamo autenticarci prima di fare la nostra richiesta. L'autenticazione deve essere eseguita con il file delle credenziali ottenuto inizialmente dalla console per sviluppatori di Google. Dovremo anche annotare nel nostro codice il GA View ID dalla proprietà che vorremmo utilizzare.
da apiclient.discovery import build
da oauth2client.service_account import ServiceAccountCredentials
AMBITI = ['https://www.googleapis.com/auth/analytics.readonly']
KEY_FILE_LOCATION = ''
VISUALIZZA_
credenziali = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES)
analytics = build('analyticsreporting', 'v4', credenziali=credenziali)Dopo l'autenticazione, dobbiamo solo fare la richiesta. Quello che dobbiamo usare per ottenere i dati sulle sessioni organiche per ogni giorno è:
risposta = analytics.reports().batchGet(body={
'richieste di report': [{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
'metriche': [
{"expression": "ga:sessions"}
], "dimensioni": [
{"name": "ga:data"}
],
"filtersExpression":"ga:channelGrouping=~Organico",
"includeEmptyRows": "vero"
}]}).eseguire()Nota che selezioniamo l'intervallo di tempo in dateRanges. Nel mio caso recupererò i dati dal 1 settembre al 31 gennaio: [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
Dopo questo dobbiamo solo recuperare il file di risposta per aggiungere a un elenco i giorni con le loro sessioni organiche:
valori_lista = [] per x in risposta["report"][0]["data"]["rows"]: list_values.append([x["dimensioni"][0],x["metriche"][0]["valori"][0]])
Come puoi vedere, l'utilizzo dell'API di Google Analytics è abbastanza semplice e può essere utilizzata per molti obiettivi. In questo articolo, ho spiegato come utilizzare l'API di Google Analytics per creare avvisi per rilevare le pagine con prestazioni insufficienti.

Adattamento delle liste ai Dataframe
Per utilizzare Prophet dobbiamo inserire un Dataframe con due colonne che devono essere nominate: "ds" e "y". Se hai importato i dati da un file Excel, lo abbiamo già come Dataframe quindi dovrai solo nominare le colonne "ds" e "y":
df.colonne = ['ds', 'y']
Nel caso in cui tu abbia utilizzato l'API per recuperare i dati, dobbiamo trasformare l'elenco in un dataframe e denominare le colonne come richiesto:
da panda importa DataFrame df_sessions = DataFrame(list_values,columns=['ds','y'])
Allenare il modello
Una volta che abbiamo il Dataframe con il formato richiesto, possiamo determinare e addestrare il nostro modello molto facilmente con:
importa fbprophet da fbprophet import Prophet modello = Profeta() model.fit(df_sessions)
Fare le nostre previsioni
Finalmente dopo aver addestrato il nostro modello possiamo iniziare a fare previsioni! Per procedere con le previsioni dovremo prima creare un elenco con l'intervallo di tempo che vorremmo prevedere e regolare il formato datetime:
da panda import to_datetime previsioni_giorni = [] per x nell'intervallo(1, 28): data = "2021-02-" + str(x) forecast_days.append([data]) forecast_days = DataFrame(forecast_days) forecast_days.columns = ['ds'] forecast_days['ds']= to_datetime(forecast_days['ds'])
In questo esempio utilizzo un loop che creerà un dataframe che conterrà tutti i giorni da febbraio. E ora si tratta solo di utilizzare il modello che è stato addestrato in precedenza:
forecast = model.predict(forecast_days)
Possiamo tracciare un grafico che evidenzia il periodo di tempo previsto:
da matplotlib import pyplot model.plot (previsione) pyplot.show()
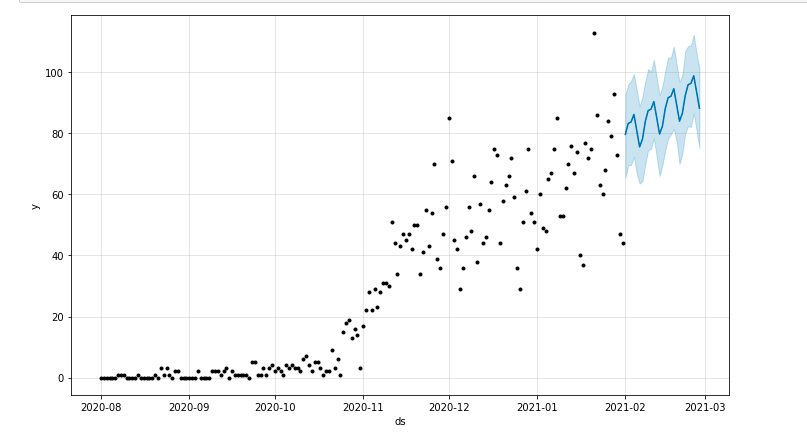
Valutazione del modello
Infine, possiamo valutare quanto sia accurato il nostro modello eliminando alcuni giorni dai dati utilizzati per addestrare il modello, prevedendo le sessioni per quei giorni e calcolando l'errore medio assoluto.
Ad esempio, quello che farò è eliminare dal dataframe originale gli ultimi 12 giorni da gennaio, prevedendo le sessioni per ogni giorno e confrontando il traffico effettivo con quello previsto.
Per prima cosa eliminiamo dal dataframe originale gli ultimi 12 giorni con pop e creiamo un nuovo dataframe che includerà solo quei 12 giorni che verranno utilizzati per la previsione:
treno = df_sessions.drop(df_sessions.index[-12:]) futuro = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
Ora formiamo il modello, facciamo la previsione e calcoliamo l'errore medio assoluto. Alla fine, possiamo tracciare un grafico che mostrerà la differenza tra i valori effettivi previsti e quelli reali. Questo è qualcosa che ho imparato da questo articolo scritto da Jason Brownlee.
da sklearn.metrics import mean_absolute_error
importa numpy come np
dall'array di importazione numpy
#Formiamo il modello
modello = Profeta()
modello.fit (treno)
#Adatta il dataframe utilizzato per i giorni di previsione al formato richiesto da Prophet.
futuro = lista(futuro)
futuro = DataFrame(futuro)
futuro = futuro.rename(colonne={0: 'ds'})
# Facciamo la previsione
previsione = model.predict(futuro)
# Calcoliamo il MAE tra i valori effettivi e quelli previsti
y_true = df_sessions['y'][-12:].values
y_pred = previsione['yhat'].valori
mae = errore_assoluto_medio(y_true, y_pred)
# Tracciamo l'output finale per una comprensione visiva
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='Attuale')
pyplot.plot(y_pred, label='Previsto')
pyplot.legend()
pyplot.show()
stampa (mae) 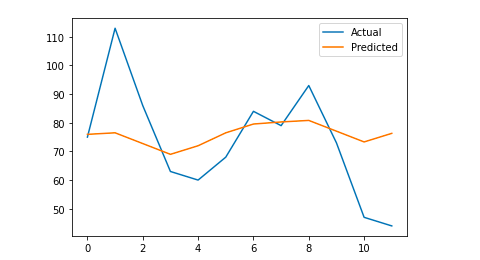
Il mio errore assoluto medio è 13, il che significa che il mio modello previsto assegna a ogni giorno 13 sessioni in più rispetto a quelle reali, il che sembra essere un errore accettabile.
È tutto gente! Spero che tu abbia trovato questo articolo interessante e che tu possa iniziare a fare le tue previsioni SEO per fissare obiettivi.
Andando oltre: OnCrawl Labs
Se ti è piaciuto prevedere il tuo traffico con questo metodo, sarai anche interessato a OnCrawl Labs, il laboratorio di scienza dei dati e apprendimento automatico di OnCrawl che offre progetti precodificati per i tuoi flussi di lavoro SEO.
Nelle previsioni SEO, OnCrawl Labs ti aiuterà a perfezionare le tue proiezioni SEO:
- Ottieni una migliore comprensione delle teorie e del processo alla base dell'algoritmo Facebook Prophet
- Analizza un segmento di traffico, ad esempio il traffico solo su parole chiave a coda lunga o solo parole chiave con marchio...
- Segui un processo passo dopo passo per impostare gli eventi storici, regolandone l'influenza e la probabilità che si ripetano.