
Come estrarre contenuto di testo rilevante da una pagina HTML?
Pubblicato: 2021-10-13Contesto
Nel reparto R&D di Oncrawl, cerchiamo sempre di più di aggiungere valore al contenuto semantico delle tue pagine web. Utilizzando modelli di machine learning per l'elaborazione del linguaggio naturale (NLP), è possibile svolgere attività con un reale valore aggiunto per la SEO.
Questi compiti includono attività come:
- Perfezionare il contenuto delle tue pagine
- Fare riepiloghi automatici
- Aggiungere nuovi tag ai tuoi articoli o correggere quelli esistenti
- Ottimizzazione dei contenuti in base ai dati di Google Search Console
- eccetera.
Il primo passo in questa avventura è estrarre il contenuto testuale delle pagine web che utilizzeranno questi modelli di machine learning. Quando si parla di pagine web, questo include HTML, JavaScript, menu, media, intestazione, piè di pagina, … Estrarre automaticamente e correttamente i contenuti non è facile. Attraverso questo articolo, mi propongo di esplorare il problema e di discutere alcuni strumenti e raccomandazioni per raggiungere questo compito.
Problema
L'estrazione di contenuto di testo da una pagina Web potrebbe sembrare semplice. Con poche righe di Python, ad esempio, un paio di espressioni regolari (regexp), una libreria di analisi come BeautifulSoup4 ed è fatta.
Se ignori per qualche minuto il fatto che sempre più siti utilizzano motori di rendering JavaScript come Vue.js o React, l'analisi dell'HTML non è molto complicata. Se vuoi limitare questo problema sfruttando il nostro crawler JS nelle tue scansioni, ti suggerisco di leggere "Come eseguire la scansione di un sito in JavaScript?".
Tuttavia, vogliamo estrarre un testo che abbia un senso, che sia il più informativo possibile. Quando leggi un articolo sull'ultimo album postumo di John Coltrane, ad esempio, ignori i menu, il piè di pagina e, ovviamente, non stai visualizzando l'intero contenuto HTML. Questi elementi HTML che appaiono su quasi tutte le tue pagine sono chiamati boilerplate. Vogliamo liberarcene e conservarne solo una parte: il testo che contiene informazioni rilevanti.
È quindi solo questo testo che vogliamo passare ai modelli di apprendimento automatico per l'elaborazione. Ecco perché è essenziale che l'estrazione sia il più qualitativa possibile.
Soluzioni
Nel complesso, vorremmo sbarazzarci di tutto ciò che "si blocca" nel testo principale: menu e altre barre laterali, elementi di contatto, collegamenti a piè di pagina, ecc. Esistono diversi metodi per farlo. Siamo principalmente interessati a progetti Open Source in Python o JavaScript.
giusto testo
jusText è un'implementazione proposta in Python da una tesi di dottorato: "Rimuovere Boilerplate e Duplicate Content from Web Corpora". Il metodo consente di classificare i blocchi di testo dell'HTML come "buoni", "cattivi", "troppo corti" in base a diverse euristiche. Queste euristiche si basano principalmente sul numero di parole, sul rapporto testo/codice, sulla presenza o assenza di collegamenti, ecc. Puoi leggere di più sull'algoritmo nella documentazione.
trafilatura
trafilatura, anch'essa realizzata in Python, offre euristiche sia sul tipo di elemento HTML che sul suo contenuto, ad esempio lunghezza del testo, posizione/profondità dell'elemento nell'HTML o conteggio delle parole. trafilatura utilizza anche justText per eseguire alcune elaborazioni.
leggibilità
Hai mai notato il pulsante nella barra degli URL di Firefox? E' la Reader View: permette di rimuovere il boilerplate dalle pagine HTML per mantenere solo il contenuto principale del testo. Abbastanza pratico da usare per i siti di notizie. Il codice alla base di questa funzione è scritto in JavaScript ed è chiamato leggibilità da Mozilla. Si basa sul lavoro avviato dal laboratorio Arc90.
Ecco un esempio di come eseguire il rendering di questa funzione per un articolo dal sito Web di France Musique. 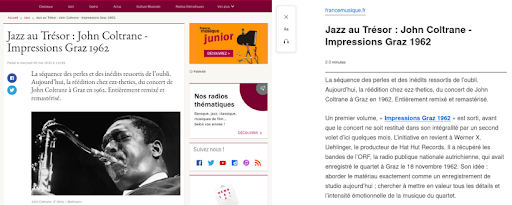
A sinistra, è un estratto dell'articolo originale. Sulla destra, è un rendering della funzione Reader View in Firefox.
Altri
La nostra ricerca sugli strumenti di estrazione dei contenuti HTML ci ha portato anche a considerare altri strumenti:
- giornale: una libreria di estrazione di contenuti piuttosto dedicata ai siti di notizie (Python). Questa libreria è stata utilizzata per estrarre contenuto dal corpus di OpenWebText2.
- boilerpy3 è un port Python della libreria boilerpipe.
- Libreria Python dragnet ispirata anche a boilerpipe.
Scansione dati³
 Scopri di più
Scopri di piùValutazione e raccomandazioni
Prima di valutare e confrontare i diversi strumenti, volevamo sapere se la comunità NLP utilizza alcuni di questi strumenti per preparare il proprio corpus (grande insieme di documenti). Ad esempio, il set di dati chiamato The Pile utilizzato per addestrare GPT-Neo ha +800 GB di testi in inglese da Wikipedia, Openwebtext2, Github, CommonCrawl, ecc. Come BERT, GPT-Neo è un modello linguistico che utilizza trasformatori di tipo. Offre un'implementazione open source simile all'architettura GPT-3.

L'articolo "The Pile: An 800GB Dataset of Diverse Text for Language Modeling" menziona l'uso di jusText per gran parte del loro corpus da CommonCrawl. Questo gruppo di ricercatori aveva anche pianificato di fare un benchmark dei diversi strumenti di estrazione. Sfortunatamente, non sono stati in grado di svolgere il lavoro previsto per mancanza di risorse. Nelle loro conclusioni, va notato che:
- justText a volte rimuoveva troppi contenuti ma forniva comunque una buona qualità. Data la quantità di dati che avevano, questo non era un problema per loro.
- la trafilatura è stata migliore nel preservare la struttura della pagina HTML ma ha mantenuto troppo standard.
Per il nostro metodo di valutazione, abbiamo preso una trentina di pagine web. Abbiamo estratto il contenuto principale “manualmente”. Abbiamo quindi confrontato l'estrazione testuale dei diversi strumenti con questo cosiddetto contenuto di “riferimento”. Abbiamo utilizzato il punteggio ROUGE, utilizzato principalmente per valutare i riepiloghi di testo automatici, come metrica.
Abbiamo anche confrontato questi strumenti con uno strumento "fatto in casa" basato su regole di analisi HTML. Si scopre che trafilatura, jusText e il nostro strumento fatto in casa funzionano meglio della maggior parte degli altri strumenti per questa metrica.
Ecco una tabella delle medie e delle deviazioni standard del punteggio ROUGE:
| Strumenti | Significare | Std |
|---|---|---|
| trafilatura | 0,783 | 0,28 |
| A gattonare | 0,779 | 0,28 |
| giusto testo | 0,735 | 0,33 |
| boilerpy3 | 0,698 | 0,36 |
| leggibilità | 0,681 | 0,34 |
| rete a strascico | 0,672 | 0,37 |
In considerazione dei valori delle deviazioni standard, si noti che la qualità dell'estrazione può variare notevolmente. Il modo in cui viene implementato l'HTML, la coerenza dei tag e l'uso appropriato del linguaggio possono causare molte variazioni nei risultati dell'estrazione.
I tre strumenti che funzionano meglio sono trafilatura, il nostro strumento interno chiamato per l'occasione "oncrawl" e jusText. Poiché jusText viene utilizzato come ripiego dalla trafilatura, abbiamo deciso di utilizzare la trafilatura come prima scelta. Tuttavia, quando quest'ultimo fallisce ed estrae zero parole, utilizziamo le nostre regole.
Si noti che il codice di trafilatura offre anche un benchmark su diverse centinaia di pagine. Calcola i punteggi di precisione, il punteggio f1 e l'accuratezza in base alla presenza o all'assenza di determinati elementi nel contenuto estratto. Spiccano due strumenti: trafilatura e goose3. Potresti anche voler leggere:
- Scegliere lo strumento giusto per estrarre contenuti dal Web (2020)
- il repository Github: benchmark di estrazione di articoli: librerie open source e servizi commerciali
Conclusioni
La qualità del codice HTML e l'eterogeneità del tipo di pagina rendono difficile l'estrazione di contenuti di qualità. Come hanno scoperto i ricercatori di EleutherAI, che stanno dietro a The Pile e GPT-Neo, non esistono strumenti perfetti. C'è un compromesso tra contenuto a volte troncato e rumore residuo nel testo quando non tutto il boilerplate è stato rimosso.
Il vantaggio di questi strumenti è che sono privi di contesto. Ciò significa che non hanno bisogno di dati diversi dall'HTML di una pagina per estrarre il contenuto. Utilizzando i risultati di Oncrawl, potremmo immaginare un metodo ibrido che utilizza le frequenze di occorrenza di determinati blocchi HTML in tutte le pagine del sito per classificarli come boilerplate.
Per quanto riguarda i set di dati utilizzati nei benchmark che abbiamo trovato sul Web, sono spesso dello stesso tipo di pagina: articoli di notizie o post di blog. Non includono necessariamente assicurazioni, agenzie di viaggio, e-commerce ecc. i cui contenuti testuali a volte sono più complicati da estrarre.
Per quanto riguarda il nostro benchmark e per mancanza di risorse, siamo consapevoli che una trentina di pagine non sono sufficienti per avere una visione più dettagliata dei punteggi. Idealmente, vorremmo avere un numero maggiore di pagine Web diverse per perfezionare i nostri valori di riferimento. E vorremmo anche includere altri strumenti come goose3, html_text o inscriptis.