
Estrai i dati dall'API di Google Search Console per l'analisi dei dati in Python
Pubblicato: 2022-03-01Google Search Console (GSC) è sicuramente uno degli strumenti più utili per gli Specialisti SEO, in quanto ti consente di ottenere informazioni sulla copertura degli indici e soprattutto sulle query per le quali ti stai attualmente classificando. Sapendo questo, molte persone analizzano i dati GSC utilizzando fogli di calcolo e va bene, purché tu capisca che c'è molto più spazio per migliorare con strumenti come i linguaggi di programmazione.
Sfortunatamente, l'interfaccia di GSC è piuttosto limitata sia in termini di righe visualizzate (solo 5000) che di periodo di tempo disponibile, solo 16 mesi. È chiaro che questo può limitare gravemente la tua capacità di ottenere approfondimenti e non è adatto per siti Web più grandi.
Python ti consente di ottenere facilmente i dati GSC e automatizzare calcoli più complessi che richiederebbero molto più sforzo nei tradizionali fogli di calcolo.
Questa è la soluzione per uno dei maggiori problemi in Excel, ovvero il limite di riga e la velocità. Al giorno d'oggi, hai molte più alternative per analizzare i dati rispetto a prima ed è qui che entra in gioco Python.
Non hai bisogno di alcuna conoscenza di codifica avanzata per seguire questo tutorial, solo la comprensione di alcuni concetti di base e un po' di pratica con Google Colab.
Introduzione all'API di Google Search Console
Prima di iniziare, è importante configurare l'API di Google Search Console. Il processo è piuttosto semplice, tutto ciò che serve è un account Google. I passi sono come segue:
- Crea un nuovo progetto su Google Cloud Platform. Dovresti avere un account Google e sono abbastanza sicuro che tu ne abbia uno. Vai alla console e quindi dovresti trovare un'opzione in alto per creare un nuovo progetto.
- Fai clic sul menu a sinistra e seleziona "API e servizi", arriverai a un'altra schermata.
- Dalla barra di ricerca in alto cerca "Google Search Console API" e abilitalo.
- Quindi passa alla scheda "Credenziali", è necessaria una sorta di autorizzazione per utilizzare l'API.
- Configura la schermata di "consenso", poiché è obbligatoria. Non importa per l'uso che ne faremo, se è pubblico o meno.
- Puoi selezionare "App desktop" per il tipo di applicazione
- Useremo OAuth 2.0 per questo tutorial, dovresti scaricare un file json e ora hai finito.
Questa è in realtà la parte più difficile per la maggior parte delle persone, specialmente per chi non è abituato alle API di Google. Non preoccuparti, i prossimi passi saranno molto più semplici e meno problematici.
Ottenere dati dall'API di Google Search Console con Python
Il mio consiglio è di utilizzare un taccuino come Jupyter Notebook o Google Colab. Quest'ultimo è migliore in quanto non devi preoccuparti dei requisiti. Pertanto, quello che sto per spiegare è basato su Google Colab.
Prima di iniziare, aggiorna il tuo file json su Google Colab con il seguente codice:
dai file di importazione di google.colab files.upload()
Quindi, installiamo tutte le librerie di cui avremo bisogno per la nostra analisi e miglioriamo la visualizzazione delle tabelle con questo frammento di codice:
%%catturare #carica ciò che serve !pip installa git+https://github.com/joshcarty/google-searchconsole importa panda come pd importa numpy come np importa matplotlib.pyplot come plt da google.colab import data_table !git clone https://github.com/jroakes/querycat.git !pip install -r querycat/requirements_colab.txt !pip installa umap-learn data_table.enable_dataframe_formatter() #per una migliore visualizzazione della tabella
Infine, puoi caricare la libreria di searchconsole, che offre il modo più semplice per farlo senza fare affidamento su funzioni lunghe. Esegui il codice seguente con gli argomenti che sto usando e assicurati che client_config abbia lo stesso nome del file json caricato.
importa la console di ricerca account = searchconsole.authenticate(client_config='client_secret_.json',serialize='credentials.json', flow='console')
Verrai reindirizzato a una pagina di Google per l'autorizzazione dell'applicazione, seleziona il tuo account Google e quindi copia e incolla il codice che otterrai nella barra di Google Colab.
Non abbiamo ancora finito, devi selezionare la proprietà per la quale avrai bisogno dei dati. Puoi facilmente controllare le tue proprietà tramite account.webproperties per vedere cosa dovresti scegliere.
property_name = input('Inserisci il nome del tuo sito web come elencato in GSC: ')
proprietà web=account[str(nome_proprietà)]
Una volta terminato, eseguirai una funzione personalizzata per creare un oggetto contenente i nostri dati.
def extract_gsc_data(webproperty, start, stop, *args):
se la proprietà web non è Nessuno:
print(f'Estrazione dei dati per {webproperty}')
gsc_data = webproperty.query.range(start, stop).dimension(*args).get()
restituisce gsc_data
altro:
print('Proprietà web non trovata, seleziona quella corretta')
ritorno Nessuno
L'idea della funzione è quella di prendere la proprietà che hai definito prima e un periodo di tempo, sotto forma di date di inizio e fine, insieme alle dimensioni.
La scelta di poter selezionare le dimensioni è fondamentale per gli Specialisti SEO perché permette di capire se è necessario un certo livello di granularità. Ad esempio, in alcuni casi potresti non essere interessato a ottenere la dimensione della data.
Il mio suggerimento è di scegliere sempre query e pagina, poiché l'interfaccia di Google Search Console può esportarli separatamente ed è molto fastidioso unirli ogni volta. Questo è un altro vantaggio dell'API di Search Console.
Nel nostro caso possiamo ottenere direttamente anche la dimensione della data, per mostrare alcuni scenari interessanti in cui è necessario tenere conto del tempo.
ex = extract_gsc_data(webproperty, '2021-09-01', '2021-12-31', 'query', 'page', 'date')
Seleziona un intervallo di tempo adeguato, considerando che per proprietà più grandi dovrai aspettare molto tempo. Per questo esempio, sto solo considerando un intervallo di tempo di 3 mesi, che è in media sufficiente per ottenere informazioni preziose dalla maggior parte dei set di dati.
Puoi selezionare anche una settimana se hai a che fare con un'enorme quantità di dati, ciò che ci interessa è il processo.
Quello che ti mostrerò qui è basato su dati sintetici o dati reali modificati per essere adatti come esempi. Di conseguenza, ciò che vedi qui è totalmente realistico e può riflettere scenari del mondo reale.
Pulizia dei dati
Per chi non lo sapesse, non possiamo utilizzare i nostri dati così come sono, ci sono alcuni passaggi aggiuntivi per assicurarci di lavorare correttamente. Prima di tutto, dobbiamo convertire il nostro oggetto in un dataframe Pandas, una struttura dati che devi conoscere in quanto è la base dell'analisi dei dati in Python.
df = pd.DataFrame(data=ex) df.head()
Il metodo head può mostrare le prime 5 righe del tuo set di dati, è molto utile dare un'occhiata all'aspetto dei tuoi dati. Possiamo contare quante pagine abbiamo usando una semplice funzione.
Un buon modo per rimuovere i duplicati è convertire un oggetto in un insieme, perché gli insiemi non possono contenere elementi duplicati.
Alcuni frammenti di codice sono stati ispirati dal taccuino di Amleto Batista e un altro da Masaki Okazawa.
Rimozione dei termini di marca
La prima cosa da fare è rimuovere le parole chiave di marca, stiamo cercando quelle query che non contengono i nostri termini di marca. Questo è abbastanza semplice da fare con una funzione personalizzata e di solito avrai una serie di termini di marca.
Per scopi dimostrativi non è necessario filtrarli tutti, ma per favore fallo per analisi reali. È uno dei passaggi più importanti per la pulizia dei dati in SEO, altrimenti rischi di presentare risultati fuorvianti.
nome_dominio = str(input('Inserisci termini del marchio separati da una virgola: ')).replace(',', '|')
importare ri
nome_dominio = re.sub(r"\s+", "", nome_dominio)
print('Rimuovi tutti gli spazi usando RegEx:\n')
df['Brand/Non-branded'] = np.where(
df['query'].str.contains(domain_name), 'Brand', 'Non-branded'
)
Aggiungeremo una nuova colonna al nostro set di dati per riconoscere la differenza tra le due classi. Possiamo visualizzare tramite tabelle o grafici a barre quanto rappresentano il numero totale di query.
Non ti mostrerò il grafico a barre perché è molto semplice e penso che una tabella sia migliore per questo caso.
brand_count_df = df['Brand/Non-branded'].value_counts().rename_axis('cats').to_frame('counts')
brand_count_df['Percentuale'] = brand_count_df['conta']/sum(brand_count_df['conta'])
pd.options.display.float_format = '{:.2%}'.format
brand_count_df
Puoi vedere rapidamente qual è il rapporto tra parole chiave di marca e non di marca per avere un'idea di quanto rimuoverai dal tuo set di dati. Non esiste un rapporto ideale qui, anche se vuoi sicuramente avere una percentuale più alta di parole chiave non di marca.
Quindi, possiamo semplicemente eliminare tutte le righe contrassegnate come con marchio e procedere con altri passaggi.
#seleziona solo parole chiave non di marca df = df.loc[df['Brand/Non-branded'] == 'Non-branded']
Riempimento di valori mancanti e altri passaggi
Se il tuo set di dati presenta valori mancanti (o NA in gergo) hai diverse opzioni. I più comuni sono eliminarli tutti o riempirli con un valore segnaposto come 0 o la media di quella colonna.
Non esiste una risposta corretta ed entrambi gli approcci hanno i loro pro e contro, oltre che dei rischi. Per i dati di Google Search Console il mio miglior consiglio è di inserire un valore segnaposto come 0, per sottovalutare l'effetto di alcune metriche.
df.fillna(0, inplace = True)
Prima di passare all'analisi dei dati effettiva, dobbiamo regolare le nostre funzionalità, in particolare le colonne del nostro set di dati. La posizione è particolarmente interessante, poiché vogliamo usarla per alcune fantastiche tabelle pivot.
Possiamo arrotondare la posizione in modo che sia un numero intero, che serve al nostro scopo.
df['posizione'] = df['posizione'].round(0).astype('int64')
Dovresti seguire tutti gli altri passaggi di pulizia descritti sopra e quindi regolare la colonna della data.
Stiamo estraendo mesi e anni con l'aiuto dei panda. Non è necessario essere così specifici se si lavora con un lasso di tempo più breve, questo è un esempio che tiene conto di sei mesi.
#converti la data nel formato corretto df['data'] = pd.to_datetime(df['data']) #mesi estratti df['mese'] = df['data'].dt.mese #anni estratti df['anno'] = df['data'].dt.anno
[Ebook] Data SEO: la prossima grande avventura
 Leggi l'ebook
Leggi l'ebookAnalisi dei dati esplorativi
Il vantaggio principale di Python è che puoi fare le stesse cose che fai in Excel ma con molte più opzioni e più facilmente. Cominciamo con qualcosa che ogni analista conosce molto bene: le tabelle pivot.
Analisi del CTR medio per gruppo di posizioni
Analizzando la media Il CTR per gruppo di posizioni è una delle attività più approfondite in quanto consente di comprendere la situazione generale di un sito web. Applica il pivot e poi traccialo.
pd.options.display.float_format = '{:.2%}'.format
query_analysis = df.pivot_table(index=['position'], values=['ctr'], aggfunc=['mean'])
query_analysis.sort_values(by=['position'], ascending=True).head(10)
ax = query_analysis.head(10).plot(kind='bar')
ax.set_xlabel('Posizione media')
ax.set_ylabel('CTR')
ax.set_title('CTR per posizione media')
ax.grid('on')
ax.get_legend().remove()
plt.xticks(rotazione=0)
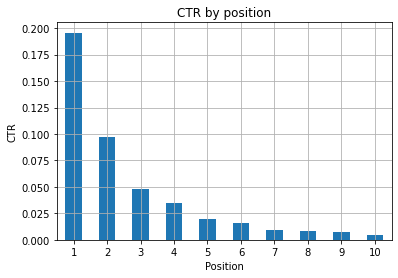
Figura 1: Rappresentazione del CTR in base alla posizione per individuare le anomalie.
Lo scenario ideale qui è avere un CTR migliore sul lato sinistro del grafico, poiché normalmente i risultati in Posizione 1 dovrebbero presentare un CTR molto più alto. Fai attenzione, però, potresti vedere alcuni casi in cui i primi 3 punti hanno un CTR inferiore al previsto e devi indagare.
Per favore, considera anche i casi limite, ad esempio quelli in cui la posizione 11 è meglio che essere prima. Come spiegato nella documentazione di Google per Search Console, questa metrica non segue l'ordine che potresti pensare all'inizio.
Inoltre, aggiunge che questa metrica è una media, poiché la posizione del collegamento cambia ogni volta ed è impossibile avere una precisione del 100%.
A volte le tue pagine si posizionano in alto ma non sono abbastanza convincenti, quindi potresti provare a correggere il titolo. Poiché questa è una panoramica di alto livello, non vedrai differenze granulari, quindi aspettati di agire rapidamente se questo problema è su larga scala.
Tieni inoltre presente quando un gruppo di pagine nelle posizioni più basse ha un CTR medio più alto rispetto a quelle nelle posizioni migliori.
Per questo motivo potresti voler estendere la tua analisi fino alla posizione 15 o più, per individuare schemi strani.
Conteggio query per posizione e misurazione degli sforzi SEO
Un aumento delle query per le quali ti stai classificando è sempre un buon segnale, ma non significa necessariamente un posizionamento migliore in futuro. Il conteggio delle query è il processo di conteggio del numero di query per cui ti stai classificando ed è una delle attività più importanti che puoi eseguire con i dati GSC.
Le tabelle pivot sono ancora una volta di grande aiuto e possiamo tracciare i risultati.
ranking_queries = df.pivot_table(index=['position'], values=['query'], aggfunc=['count']) ranking_queries.sort_values(by=['position']).head(10)
Quello che vuoi come specialista SEO è avere un numero di query più alto sul lato più a sinistra, i primi posti. Il motivo è abbastanza naturale, le posizioni alte ottengono in media un CTR migliore, che può tradursi in più persone che fanno clic sulla tua pagina.
ax = ranking_queries.head(10).plot(kind='bar')
ax.set_ylabel('Conteggio delle query')
ax.set_xlabel('Posizione')
ax.set_title('Distribuzione classifica')
ax.grid('on')
ax.get_legend().remove()
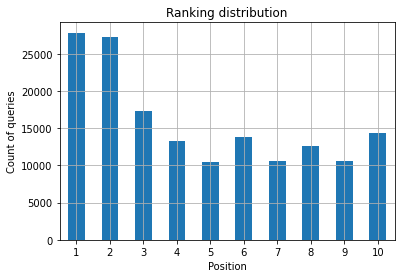
Figura 2: quante query ho per posizione?
Quello che ti interessa è aumentare il conteggio delle query nelle prime posizioni con il passare del tempo.
Giocare con la dimensione della data
Vediamo come variano i clic in un intervallo di tempo considerato, otteniamo prima la somma dei clic:
clicks_sum = df.groupby('date')['clicks'].sum()
Stiamo raggruppando i dati in base alla dimensione della data e ottenendo la somma dei clic per ciascuno di essi, è un tipo di riepilogo.
Ora siamo pronti per tracciare ciò che abbiamo ottenuto, il codice sarà piuttosto lungo solo per migliorare la visualizzazione, non spaventarti.

# Somma dei clic nel periodo
%config InlineBackend.figure_format = 'retina'
dalla figura di importazione matplotlib.pyplot
figura(dimensione=(8, 6), dpi=80)
ax = clicks_sum.plot(color='rosso')
ax.grid('on')
ax.set_ylabel('Somma dei clic')
ax.set_xlabel('Mese')
ax.set_title('Come variavano i clic su base mensile')
xlab = ax.xaxis.get_label()
ylab = ax.yaxis.get_label()
xlab.set_style('corsivo')
xlab.set_size(10)
ylab.set_style('corsivo')
ylab.set_size(10)
ttl = ax.titolo
ttl.set_weight('grassetto')
ax.spines['right'].set_color((.8,.8,.8))
ax.spines['top'].set_color((.8,.8,.8))
ax.yaxis.set_label_coords(-.15, .50)
ax.fill_between(clicks_sum.index, clicks_sum.values, facecolor='giallo')
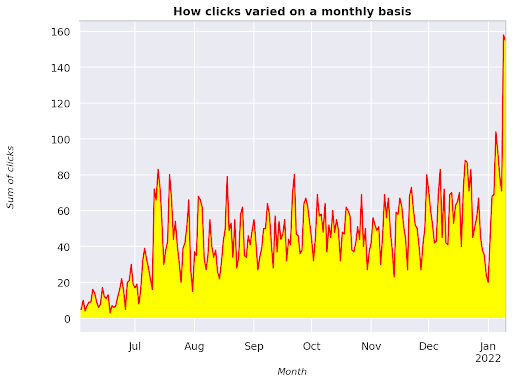
Figura 3: Rappresentazione della somma dei clic in relazione alla variabile del mese
Questo è un esempio che inizia da giugno 2021 e va direttamente a metà gennaio 2022. Tutte le righe che vedi sopra hanno il ruolo di rendere questa visualizzazione più carina, puoi provare a giocarci per vedere cosa succede.
Conteggio query per posizione, snapshot mensile
Un'altra fantastica visualizzazione che possiamo tracciare in Python è la mappa di calore, che è ancora più visiva di un semplice grafico a barre. Ti mostrerò come visualizzare il conteggio delle query nel tempo e in base alla sua posizione.
import seaborn come sns sns.set_theme() df_new = df.loc[(df['posizione'] <= 10) & (df['anno'] != 2022),:] # Carica il set di dati dei voli di esempio e convertilo in formato lungo df_heat = df_new.pivot_table(index = "posizione", colonne = "mese", valori = "query", aggfunc='count') # Disegna una mappa termica con i valori numerici in ogni cella f, ax = plt.subplots(figsize=(20, 12)) x_axis_labels = ["Settembre", "Ottobre", "Novembre", "Dicembre"] sns.heatmap(df_heat, annot=True, linewidths=.5, ax=ax, fmt='g', cmap = sns.cm.rocket_r, xticklabels=x_axis_labels) ax.set(xlabel = 'Mese', ylabel='Posizione', title = 'Come il conteggio delle query per posizione cambia con il tempo') #ruota Posiziona le etichette per renderle più leggibili plt.yticks(rotazione=0)
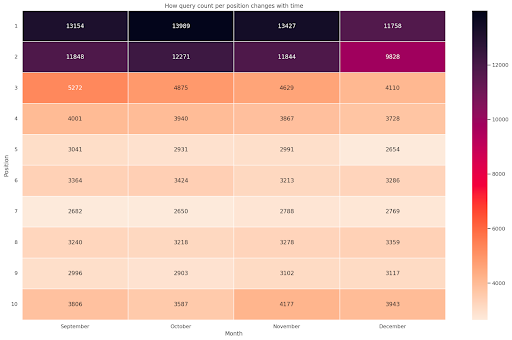
Figura 4: Heatmap che mostra l'andamento del conteggio delle query in base alla posizione e al mese.
Questo è uno dei miei preferiti, le mappe di calore possono essere abbastanza efficaci per visualizzare tabelle pivot, come in questo esempio. Il periodo si estende su 4 mesi e se lo leggi in orizzontale puoi vedere come cambia il conteggio delle query con il passare del tempo. Per la posizione 10 si ha un piccolo aumento da settembre a dicembre, ma per la posizione 2 si ha una forte diminuzione, come dimostra il colore viola.
Nello scenario seguente hai la maggior parte delle query nei primi posti, il che può essere sorprendentemente insolito. Se ciò accade, potresti voler tornare indietro e analizzare il dataframe, cercando eventuali termini di marca, se presenti.
Come puoi vedere dal codice, non è così difficile creare trame complesse, purché tu abbia la logica dietro.
Il conteggio delle query dovrebbe aumentare con il tempo se stai facendo le cose "giuste" e possiamo tracciare la differenza su due diversi intervalli di tempo. Nell'esempio che ho fornito non è chiaramente il caso, in quanto, specialmente per le prime posizioni, dove dovresti avere un CTR più alto.
Presentazione di alcuni concetti di base della PNL
Natural Language Processing (NLP) è una manna dal cielo per la SEO e non è necessario essere un esperto per applicare gli algoritmi di base. Gli N-grammi sono una delle idee più potenti ma semplici che possono fornirti informazioni dettagliate con i dati GSC.
Gli N-grammi sono sequenze contigue di lettere, sillabe o parole. Per la nostra analisi le parole saranno l'unità di misura. Un n-gram è chiamato bigram quando gli elementi adiacenti sono due (una coppia) e trigram se sono tre, e così via. Ti consiglio di provare con diverse combinazioni e di arrivare fino a 5 grammi al massimo.
In questo modo, puoi individuare le frasi più comuni nelle pagine dei tuoi concorrenti o valutare le tue. Poiché Google può fare affidamento sull'indicizzazione basata su frasi, è meglio ottimizzare per le frasi piuttosto che per le singole parole chiave, come dimostrano i brevetti di Google che coinvolgono questo argomento.
Come affermato nella pagina precedente dallo stesso Bill Slawski, il valore della comprensione dei termini correlati è di grande valore per l'ottimizzazione e per i tuoi utenti.
La libreria nltk è molto famosa per le applicazioni NLP e ci offre la possibilità di rimuovere le parole di stop in una determinata lingua, come l'inglese. Pensali come rumori che vuoi rimuovere, infatti articoli e parole molto frequenti non aggiungono alcun valore alla comprensione di un testo.
importa nltk
nltk.download('stopwords')
da nltk.corpus import stopwords
stoplist = stopwords.words('inglese')
da sklearn.feature_extraction.text import CountVectorizer
c_vec = CountVectorizer(stop_words=stoplist, ngram_range=(2,3))
# matrice di ngram
ngrams = c_vec.fit_transform(df['query'])
# frequenza di conteggio di ngram
count_values = ngrams.toarray().sum(asse=0)
# elenco di ngram
vocabolario = c_vec.vocabolario_
df_ngram = pd.DataFrame(sorted([(count_values[i],k) for k,i in vocab.items()], reverse=True)
).rename(columns={0: 'frequenza', 1:'bigramma/trigramma'})
df_ngram.head(20).style.background_gradient()
Prendiamo la colonna della query e contiamo la frequenza dei bigrammi per creare un dataframe che memorizza i bigrammi e il loro numero di occorrenze.
Questo passaggio è in realtà molto importante anche per analizzare i siti Web dei concorrenti. Puoi semplicemente raschiare il loro testo e controllare quali sono gli n-grammi più comuni, sintonizzando la n ogni volta per vedere se trovi schemi diversi nelle pagine di alto livello.
Se ci pensi per un secondo, ha molto più senso, poiché una singola parola chiave non ti dice nulla sul contesto.
Frutti bassi
Una delle cose più belle da fare è controllare i frutti bassi, quelle pagine che puoi migliorare facilmente per vedere buoni risultati il prima possibile. Questo è fondamentale nei primi passi di ogni progetto SEO per convincere i tuoi stakeholder. Pertanto, se c'è un'opportunità per sfruttare tali pagine, fallo e basta!
I nostri criteri per considerare una pagina come tale sono i quantili per le impressioni e il CTR. In altre parole, stiamo filtrando le righe che si trovano nell'80% più alto delle impressioni ma sono nel 20% che riceve il CTR più basso. Queste righe avranno un CTR peggiore dell'80% del resto.
top_impressions = df[df['impressions'] >= df['impressions'].quantile(0.8)]
(top_impressions[top_impressions['ctr'] <= top_impressions['ctr'].quantile(0.2)].sort_values('impressions', ascendente = Falso))
Ora hai un elenco con tutte le opportunità ordinate per Impressioni, in ordine decrescente.
Puoi pensare ad altri criteri per definire cosa sia un frutto basso, in base alle esigenze del tuo sito web e alle sue dimensioni.
Per i siti web più piccoli potresti considerare di cercare percentuali più alte, mentre nei siti web di grandi dimensioni dovresti già ottenere molte informazioni con i criteri che sto utilizzando.
[Ebook] SEO tecnico per pensatori non tecnici
 Leggi l'ebook
Leggi l'ebookPresentazione di querycat: classificazione e associazioni
Querycat è una libreria semplice ma potente che offre il mining di regole di associazione per il clustering di parole chiave e molto altro. Ti mostrerò solo le associazioni in quanto sono più preziose in questo tipo di analisi.
Puoi saperne di più su questa fantastica libreria dando un'occhiata al repository GitHub di querycat.
Breve introduzione sull'apprendimento delle regole di associazione
L'apprendimento delle regole di associazione è un metodo per trovare regole che definiscono le associazioni e le co-occorrenze tra insiemi di elementi. Questo è leggermente diverso da un altro metodo di apprendimento automatico non supervisionato, il cosiddetto clustering.
L'obiettivo finale è lo stesso, tuttavia, ottenere gruppi di parole chiave per capire come sta andando il nostro sito Web per alcuni argomenti.
Querycat ti dà la possibilità di scegliere tra due algoritmi: Apriori e FP-Growth. Sceglieremo il secondo per prestazioni migliori, quindi puoi ignorare il primo.
FP-Growth è una versione migliorata di Apriori per trovare schemi frequenti nei set di dati. L'apprendimento delle regole di associazione è molto utile anche per le transazioni di e-commerce, potresti essere interessato a capire cosa acquistano le persone insieme, ad esempio.
In questo caso il nostro focus è tutto sulle query, ma l'altra applicazione che ho citato può essere un'altra idea utile per i dati di Google Analytics.
Spiegare questi algoritmi dal punto di vista della struttura dei dati è piuttosto impegnativo e, a mio avviso, non è necessario per le tue attività SEO. Spiegherò solo alcuni concetti di base per capire cosa significano i parametri.
I 3 elementi principali dei 2 algoritmi sono:
- Supporto: esprime la popolarità di un articolo o di un set di articoli. In termini tecnici, è il numero di transazioni in cui la query X e la query Y vengono visualizzate insieme diviso per il numero totale di transazioni.
Inoltre, può essere utilizzato come soglia per rimuovere oggetti poco frequenti. Molto utile per aumentare la significatività statistica e le prestazioni. Impostare un buon supporto minimo è molto buono. - Fiducia: puoi pensarla come la probabilità di co-occorrenza per i termini.
- Lift – Il rapporto tra il supporto per (termine 1 e termine 2) e il supporto del termine 1. Possiamo esaminare il suo valore per ottenere informazioni sulla relazione tra i termini. Se maggiore di 1 i termini sono correlati; se inferiore a 1 è improbabile che i termini abbiano un'associazione: se lift è esattamente 1 (o vicino) non c'è relazione significativa.
Ulteriori dettagli sono forniti in questo articolo su querycat scritto dall'autore della libreria.
Ora siamo pronti per passare alla parte pratica.
importa querycat
query_cat = querycat.Categorize(df, 'query', min_support=10, alg='fpgrowth')
dfgrouped = df.groupby('category').agg(sumclicks = ('clicks', 'sum')).sort_values('sumclicks', ascending=False)
#crea gruppo per filtrare le categorie con meno di 15 clic (numero arbitrario)
filtergroup = dfgrouped[dfgrouped['sumclicks'] > 15]
gruppo di filtri
#applica il filtro
df = df.merge(filtergroup, on=['categoria','categoria'], how='interno')
Abbiamo filtrato le categorie meno frequenti nel processo, nel mio caso ho scelto 15 come benchmark. È solo un numero arbitrario, non c'è alcun criterio dietro.
Controlliamo le nostre categorie con il seguente snippet:
df['categoria'].value_counts()
E le 10 categorie più cliccate? Controlliamo quante query abbiamo per ciascuna di esse.
df.groupby('categoria').sum()['clic'].sort_values(ascending=False).head(10)
Il numero da scegliere è arbitrario, assicurati di sceglierne uno che filtri una buona percentuale di gruppi. Un'idea potenziale è ottenere la mediana delle impressioni e ridurre il 50% più basso, a condizione che tu voglia escludere piccoli gruppi.
Ottenere i cluster e cosa fare con l'output
Il mio consiglio è di esportare il tuo nuovo dataframe per evitare di eseguire nuovamente FP-Growth, per favore fallo per risparmiare tempo utile.
Non appena disponi di cluster, desideri conoscere i clic e le impressioni per ciascuno di essi per valutare quali aree necessitano di maggiori miglioramenti.
grouped_df = df.groupby('categoria')[['clic', 'impressioni']].agg('somma')
Con un po' di manipolazione dei dati siamo in grado di migliorare i nostri risultati di associazione e avere clic e impressioni per ogni cluster.
group_ex = df.groupby(['categoria'])['query'].apply(' | '.join).reset_index()
#rimuovi le query duplicate e poi ordinale in ordine alfabetico
group_ex['query'] = group_ex['query'].apply(lambda x: ' | '.join(sorted(list(set(x.split('|'))))))
df_final = group_ex.merge(grouped_df, on=['categoria', 'categoria'], how='interno')
df_final.head()
Ora hai un file CSV con tutti i tuoi cluster di parole chiave insieme a clic e impressioni.
#save CSV e scaricalo sul tuo computer locale. Se utilizzi Safari, considera di passare a Chrome per scaricare questi file poiché potrebbe non funzionare.
df_final.to_csv('clusters_queries.csv')
files.download('clusters_queries.csv')
In realtà, ci sono metodi migliori per il clustering, questo è solo un esempio su come utilizzare querycat per eseguire più attività per un uso immediato. L'obiettivo principale qui è ottenere quante più informazioni possibili, specialmente per i nuovi siti Web di cui non hai molte conoscenze.
In questo momento gli approcci migliori coinvolgono la semantica, quindi se vuoi concentrarti sul clustering ti suggerisco di considerare l'apprendimento di grafici o incorporamenti.
Tuttavia, questi sono argomenti avanzati se sei un principiante e puoi semplicemente provare alcune app Streamlit predefinite disponibili online.
Scansione dati³
 Scopri di più
Scopri di piùConclusione e cosa c'è dopo
Python può offrire un aiuto importante nell'analisi del tuo sito Web e può aiutarti a combinare pulizia, visualizzazione e analisi dei dati in un unico posto. L'estrazione dei dati dall'API GSC è sicuramente necessaria per attività più avanzate ed è un'introduzione "delicata" all'automazione dei dati.
Sebbene tu possa fare molti calcoli più avanzati con Python, la mia raccomandazione è di verificare cosa ha senso in termini di valore SEO.
Ad esempio, il conteggio delle query è molto più importante nel suo insieme a lungo termine, poiché desideri che il tuo sito Web venga considerato per più query.
L'uso dei taccuini è di grande aiuto per imballare il codice con i commenti e questo è il motivo principale per cui ti suggerisco di abituarti a Google Colab.
Questo è solo l'inizio di ciò che l'analisi dei dati può offrirti, poiché le migliori idee provengono dall'unione di diversi set di dati.
Google Search Console è di per sé uno strumento potente ed è totalmente gratuito, la quantità di informazioni pratiche che puoi ottenere da esso è quasi illimitata nelle buone mani.