
Significato statistico del test A/B: come e quando terminare un test
Pubblicato: 2020-05-22
Nella nostra recente analisi di 28.304 esperimenti eseguiti dai clienti di Convert, abbiamo riscontrato che solo il 20% degli esperimenti raggiunge il livello di significatività statistica del 95%. Econsultancy ha scoperto una tendenza simile nel suo rapporto di ottimizzazione del 2018. Due terzi degli intervistati vedono un "vincitore chiaro e statisticamente significativo" solo nel 30% o meno dei loro esperimenti.
Quindi la maggior parte degli esperimenti (70-80%) non sono conclusivi o sono stati interrotti in anticipo.
Di questi, quelli interrotti in anticipo costituiscono un caso curioso poiché gli ottimizzatori rispondono alla chiamata per terminare gli esperimenti quando lo ritengono opportuno. Lo fanno quando possono "vedere" un chiaro vincitore (o un perdente) o un test chiaramente insignificante. Di solito, hanno anche alcuni dati per giustificarlo.
Questo potrebbe non sembrare così sorprendente, dato che il 50% degli ottimizzatori non ha un "punto di arresto" standard per i propri esperimenti. Per la maggior parte, farlo è una necessità, grazie alla pressione di dover mantenere una certa velocità di test (XXX test/mese) e la corsa per dominare la concorrenza.
Poi c'è anche la possibilità che un esperimento negativo danneggi le entrate. La nostra stessa ricerca ha dimostrato che gli esperimenti non vincenti, in media, possono causare una diminuzione del 26% del tasso di conversione !
Detto questo, terminare gli esperimenti in anticipo è ancora rischioso...
... poiché lascia la probabilità che se l'esperimento avesse eseguito la sua lunghezza prevista, alimentato dalla giusta dimensione del campione, il suo risultato avrebbe potuto essere diverso.
Quindi, come fanno i team che terminano gli esperimenti in anticipo a sapere quando è il momento di terminarli? Per la maggior parte, la risposta sta nell'elaborare regole di arresto che accelerino il processo decisionale, senza comprometterne la qualità.
Allontanarsi dalle tradizionali regole di arresto
Per gli esperimenti web, un valore p di 0,05 funge da standard. Questa tolleranza di errore del 5% o il livello di significatività statistica del 95% aiuta gli ottimizzatori a mantenere l'integrità dei loro test. Possono garantire che i risultati siano risultati effettivi e non casuali.
Nei modelli statistici tradizionali per i test a orizzonte fisso, in cui i dati del test vengono valutati solo una volta in un momento prestabilito o a un numero specifico di utenti coinvolti, accetterai un risultato come significativo quando hai un p-value inferiore a 0,05. A questo punto, puoi rifiutare l'ipotesi nulla che il tuo controllo e il tuo trattamento siano gli stessi e che i risultati osservati non siano casuali.
A differenza dei modelli statistici che ti danno la possibilità di valutare i tuoi dati mentre vengono raccolti, tali modelli di test ti vietano di guardare i dati del tuo esperimento mentre è in esecuzione. Questa pratica, nota anche come peeking, è sconsigliata in tali modelli perché il valore p oscilla quasi quotidianamente. Vedrai che un esperimento sarà significativo un giorno e il giorno successivo il suo valore p aumenterà al punto in cui non è più significativo.
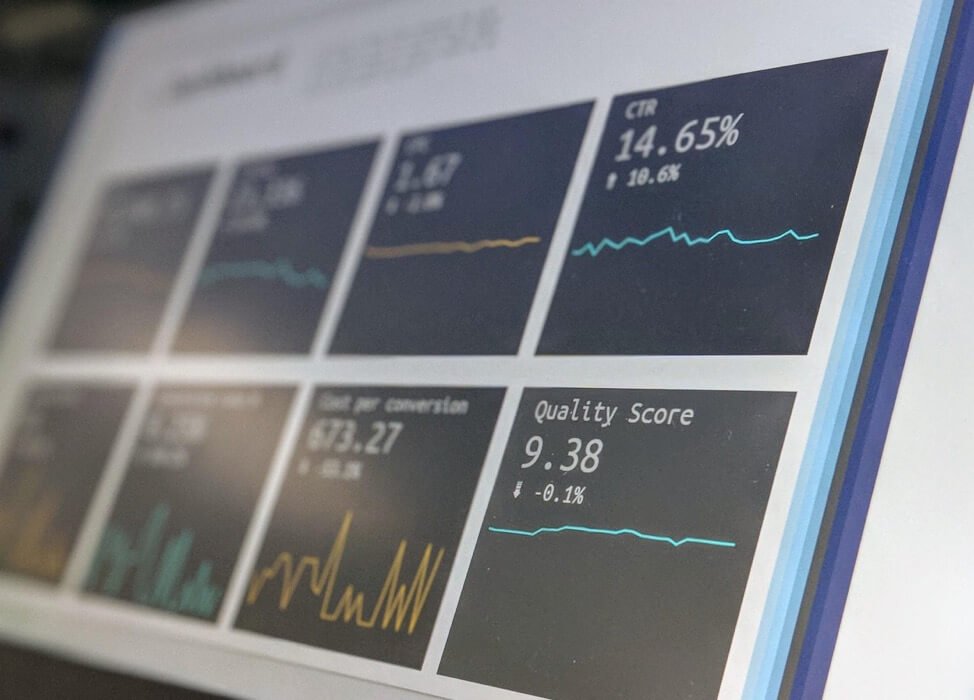
Simulazioni dei valori p tracciati per cento (20 giorni) esperimenti; solo 5 esperimenti finiscono per essere significativi al traguardo dei 20 giorni, mentre molti occasionalmente hanno raggiunto il limite di <0,05 nel frattempo.
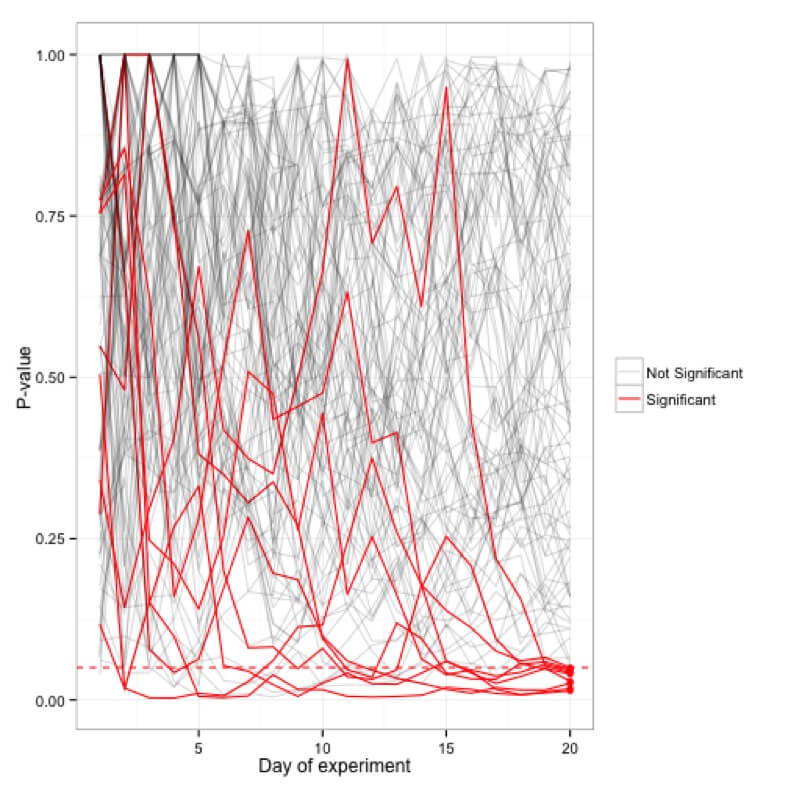
Dare un'occhiata ai tuoi esperimenti nel frattempo può mostrare risultati che non esistono. Ad esempio, di seguito hai un test A/A che utilizza un livello di significatività di 0,1. Poiché si tratta di un test A/A, non c'è differenza tra il controllo e il trattamento. Tuttavia, dopo 500 osservazioni durante l'esperimento in corso, c'è oltre il 50% di possibilità di concludere che sono diverse e che l'ipotesi nulla può essere rifiutata:
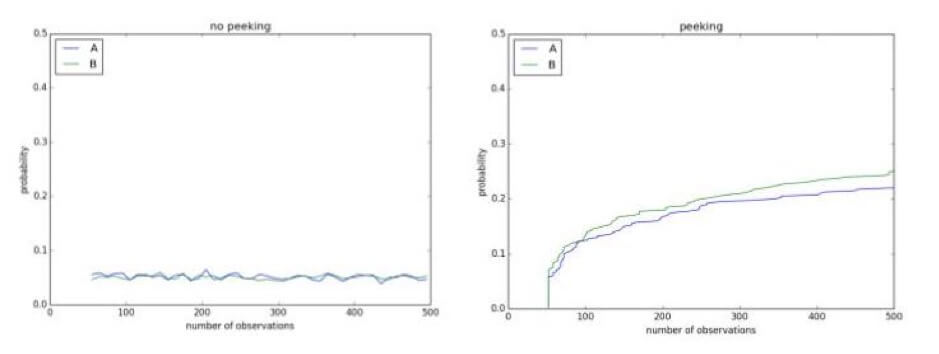
Ecco un altro test A/A di 30 giorni in cui il valore p scende più volte nella zona di significatività solo per essere finalmente molto più del cutoff:
Segnalare correttamente un valore p da un esperimento a orizzonte fisso significa che è necessario pre-impegnarsi per una dimensione del campione fissa o una durata del test. Alcuni team aggiungono anche un certo numero di conversioni a questo esperimento criteri di arresto e una durata prevista.
Tuttavia, il problema qui è che avere abbastanza traffico di prova per alimentare ogni singolo esperimento per interrompere in modo ottimale l'utilizzo di questa pratica standard è difficile per la maggior parte dei siti web.
Ecco dove aiuta l'utilizzo di metodi di test sequenziali che supportano regole di arresto facoltative.
Passare a regole di arresto flessibili che consentano decisioni più rapide
I metodi di test sequenziali ti consentono di attingere ai dati dei tuoi esperimenti così come appaiono e di utilizzare i tuoi modelli di significatività statistica per individuare prima i vincitori, con regole di arresto flessibili.
I team di ottimizzazione ai massimi livelli di maturità CRO spesso escogitano le proprie metodologie statistiche per supportare tali test. Alcuni strumenti di test A/B hanno anche questo integrato e potrebbero suggerire se una versione sembra essere vincente. E alcuni ti danno il pieno controllo su come vuoi che venga calcolata la tua significatività statistica, con i tuoi valori personalizzati e altro ancora. Quindi puoi sbirciare e individuare un vincitore anche in un esperimento in corso.

Statistico, autore e istruttore del popolare corso CXL sulle statistiche dei test A/B, Georgi Georgiev è tutto per tali metodi di test sequenziali che consentono flessibilità nel numero e nei tempi delle analisi intermedie:
“ I test sequenziali consentono di massimizzare i profitti mediante l'implementazione anticipata di una variante vincente, nonché di interrompere i test che hanno poche probabilità di produrre un vincitore il prima possibile. Quest'ultimo riduce al minimo le perdite dovute a varianti inferiori e accelera i test quando è semplicemente improbabile che le varianti superino il controllo. Statisticamente il rigore è mantenuto in tutti i casi. "
Georgiev ha persino lavorato su una calcolatrice che aiuta i team a abbandonare i modelli di test di esempio fissi per uno in grado di rilevare un vincitore mentre un esperimento è ancora in corso. Il suo modello tiene conto di molte statistiche e ti aiuta a chiamare i test circa il 20-80% più velocemente rispetto ai calcoli di significatività statistica standard, senza sacrificare la qualità.
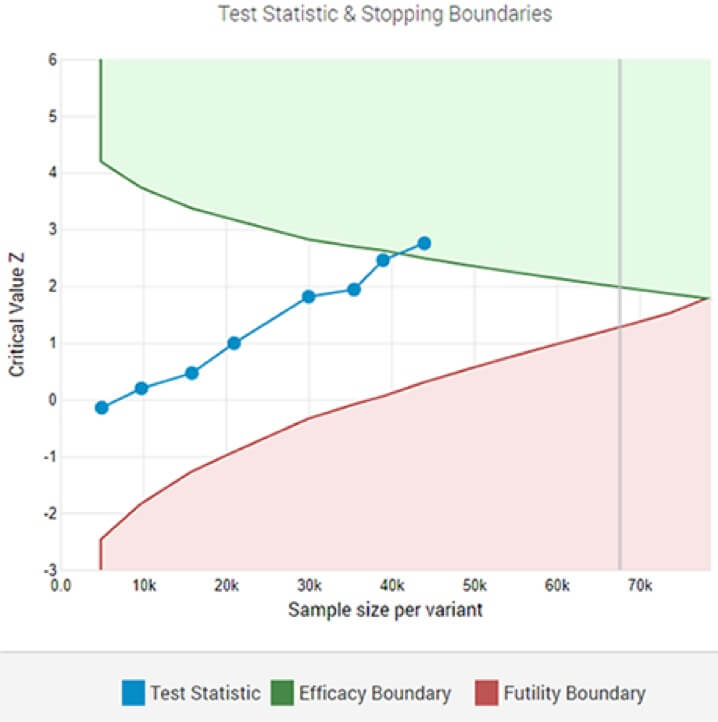
Un test A/B adattivo che mostra un vincitore statisticamente significativo alla soglia di significatività designata dopo l'ottava analisi ad interim.
Sebbene tali test possano accelerare il processo decisionale, c'è un aspetto importante che deve essere affrontato: l'impatto effettivo dell'esperimento . Terminare un esperimento nel frattempo può portarti a sopravvalutarlo.
Osservare le stime non corrette per la dimensione dell'effetto può essere pericoloso, avverte Georgiev. Per evitare ciò, il suo modello utilizza metodi per applicare aggiustamenti che tengano conto della distorsione sostenuta a causa del monitoraggio intermedio. Spiega come la loro analisi agile aggiusti le stime "a seconda della fase di arresto e del valore osservato della statistica (overshoot, se presente)." Di seguito, puoi vedere l'analisi per il test precedente: (nota come l'incremento stimato è inferiore a quello osservato e l'intervallo non è centrato attorno ad esso.)
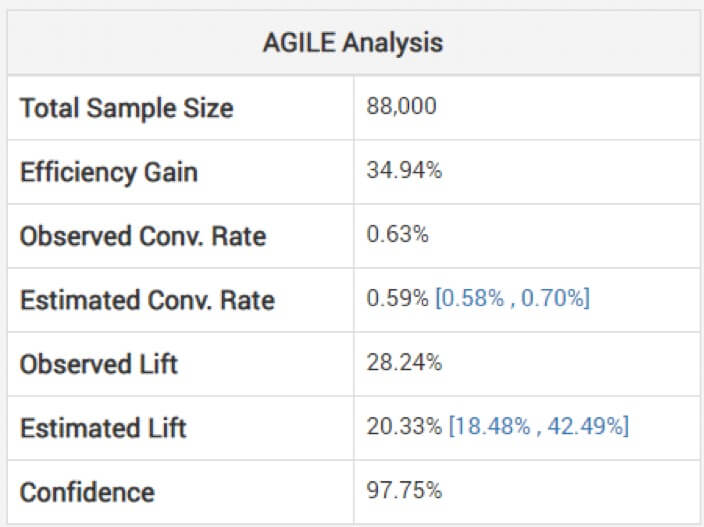
Quindi una vittoria potrebbe non essere così grande come sembra in base al tuo esperimento più breve del previsto.
Anche la perdita deve essere presa in considerazione, perché potresti comunque aver finito per chiamare erroneamente un vincitore troppo presto. Ma questo rischio esiste anche nei test a orizzonte fisso. La validità esterna, tuttavia, può essere una preoccupazione maggiore quando si chiamano gli esperimenti in anticipo rispetto a un test a orizzonte fisso di lunga durata. Ma questa è, come spiega Georgiev, “ una semplice conseguenza della minore dimensione del campione e quindi della durata del test. “
Alla fine... Non si tratta di vincitori o vinti...
… ma su decisioni aziendali migliori, come dice Chris Stucchio.
O come afferma Tom Redman (autore di Data Driven: Profiting from Your Most Important Business Asset) che negli affari: “ ci sono spesso criteri più importanti della significatività statistica. La domanda importante è: " Il risultato regge sul mercato, anche se solo per un breve periodo di tempo? ”'
E molto probabilmente lo farà, e non solo per un breve periodo, osserva Georgiev, " se è statisticamente significativo e le considerazioni sulla validità esterna sono state affrontate in modo soddisfacente in fase di progettazione".
L'intera essenza della sperimentazione è consentire ai team di prendere decisioni più informate. Quindi, se puoi trasmettere i risultati - a cui puntano i dati dei tuoi esperimenti - prima, allora perché no?
Potrebbe essere un piccolo esperimento dell'interfaccia utente a cui non puoi praticamente ottenere una dimensione del campione "sufficiente". Potrebbe anche essere un esperimento in cui il tuo sfidante schiaccia l'originale e potresti semplicemente accettare quella scommessa!
Come scrive Jeff Bezos nella sua lettera agli azionisti di Amazon, i grandi esperimenti pagano molto:
“ Data una possibilità del dieci percento di vincere 100 volte, dovresti accettare quella scommessa ogni volta. Ma sbaglierai comunque nove volte su dieci. Sappiamo tutti che se colpisci le recinzioni, colpirai molto, ma colpirai anche alcuni fuoricampo. La differenza tra baseball e affari, tuttavia, è che il baseball ha una distribuzione troncata dei risultati. Quando fai swing, non importa quanto bene ti colleghi con la palla, il numero massimo di punti che puoi ottenere è quattro. Negli affari, ogni tanto, quando sali sul piatto, puoi segnare 1.000 corse. Questa distribuzione dei rendimenti a coda lunga è il motivo per cui è importante essere audaci. I grandi vincitori pagano per tanti esperimenti. “
Chiamare gli esperimenti in anticipo, in larga misura, è come sbirciare ogni giorno i risultati e fermarsi in un punto che garantisce una buona scommessa.

