
Che cos'è una curva CTR e come calcolarla con Python?
Pubblicato: 2022-03-22La curva CTR, o in altre parole la percentuale di clic organica basata sulla posizione, è un dato che mostra quanti link blu su una SERP (Search Engine Result Page) ottengono il CTR in base alla loro posizione. Ad esempio, il più delle volte, il primo collegamento blu in SERP ottiene il maggior CTR.
Alla fine di questo tutorial, sarai in grado di calcolare la curva CTR del tuo sito in base alle sue directory o calcolare il CTR organico in base alle query CTR. L'output del mio codice Python è un grafico a barre e box approfondito che descrive la curva CTR del sito.
Se sei un principiante e non conosci la definizione CTR, la spiegherò meglio nella prossima sezione.
Che cos'è il CTR organico o la percentuale di clic organica?
Il CTR deriva dalla divisione dei clic organici in impressioni. Ad esempio, se 100 persone cercano "mela" e 30 fanno clic sul primo risultato, il CTR del primo risultato è 30 / 100 * 100 = 30%.
Ciò significa che da ogni 100 ricerche, ne ottieni il 30%. È importante ricordare che le impressioni in Google Search Console (GSC) non si basano sull'aspetto del link del tuo sito web nel viewport di ricerca. Se il risultato appare sulla SERP del ricercatore, ottieni un'impressione per ciascuna delle ricerche.
Quali sono gli usi della curva CTR?
Uno degli argomenti importanti nella SEO è la previsione del traffico organico. Per migliorare le classifiche in alcune serie di parole chiave, dobbiamo allocare migliaia e migliaia di dollari per ottenere più condivisioni. Ma la domanda a livello di marketing di un'azienda è spesso: "È conveniente per noi allocare questo budget?".
Inoltre, oltre al tema degli stanziamenti di budget per i progetti SEO, dobbiamo ottenere una stima del nostro aumento o diminuzione del nostro traffico organico in futuro. Ad esempio, se vediamo uno dei nostri concorrenti che si sforza di sostituirci nella nostra posizione in classifica SERP, quanto ci costerà?
In questa situazione o in molti altri scenari, abbiamo bisogno della curva CTR del nostro sito.
Perché non utilizziamo gli studi della curva CTR e non utilizziamo i nostri dati?
Semplicemente risposto, non c'è nessun altro sito Web che abbia le caratteristiche del tuo sito in SERP.
Ci sono molte ricerche per le curve CTR in diversi settori e diverse funzionalità SERP, ma quando hai i tuoi dati, perché i tuoi siti non calcolano il CTR invece di fare affidamento su fonti di terze parti?
Iniziamo a farlo.
Calcolo della curva CTR con Python: per iniziare
Prima di approfondire il processo di calcolo della percentuale di clic di Google in base alla posizione, è necessario conoscere la sintassi di base di Python e avere una conoscenza di base delle librerie Python comuni, come Pandas. Questo ti aiuterà a comprendere meglio il codice e personalizzarlo a tuo modo.
Inoltre, per questo processo, preferisco utilizzare un notebook Jupyter.
Per calcolare il CTR organico in base alla posizione, dobbiamo usare queste librerie Python:
- Panda
- Tramamente
- Caleido
Inoltre, utilizzeremo queste librerie standard Python:
- os
- json
Come ho detto, esploreremo due diversi modi di calcolare la curva CTR. Alcuni passaggi sono gli stessi in entrambi i metodi: importazione dei pacchetti Python, creazione di una cartella di output delle immagini di stampa e impostazione delle dimensioni della stampa di output.
# Importazione delle librerie necessarie per il nostro processo importare os importa json importa panda come pd importa plotly.express come px importa plotly.io come pio importa caleido
Qui creiamo una cartella di output per salvare le nostre immagini di stampa.
# Creazione della cartella di output delle immagini di stampa
se non os.path.exists('./output plot images'):
os.mkdir('./output plot images')
È possibile modificare l'altezza e la larghezza delle immagini del grafico di output di seguito.
# Impostazione della larghezza e dell'altezza delle immagini del tracciato di output pio.kaleido.scope.default_height = 800 pio.kaleido.scope.default_width = 2000
Iniziamo con il primo metodo che si basa sulle query CTR.
Primo metodo: calcola la curva CTR per un intero sito Web o una specifica proprietà URL in base al CTR delle query
Prima di tutto, dobbiamo ottenere tutte le nostre query con il loro CTR, posizione media e impressione. Preferisco utilizzare un mese completo di dati del mese scorso.
Per fare ciò, ottengo i dati delle query dall'origine dati sulle impressioni del sito GSC in Google Data Studio. In alternativa, puoi acquisire questi dati nel modo che preferisci, ad esempio l'API GSC o il componente aggiuntivo Fogli Google "Search Analytics for Sheets". In questo modo, se il tuo blog o le pagine dei tuoi prodotti hanno una proprietà URL dedicata, puoi utilizzarli come origine dati in GDS.
1. Ottenere i dati delle query da Google Data Studio (GDS)
Per farlo:
- Crea un rapporto e aggiungi un grafico tabellare
- Aggiungi l'origine dati "Impressioni del sito" del tuo sito al rapporto
- Scegli "query" per la dimensione e "ctr", "posizione media" e "'impressione" per la metrica
- Filtra le query che contengono il nome del marchio creando un filtro (le query contenenti marchi avranno una percentuale di clic più elevata, il che ridurrà l'accuratezza dei nostri dati)
- Fare clic con il tasto destro sulla tabella e fare clic su Esporta
- Salva l'output come CSV
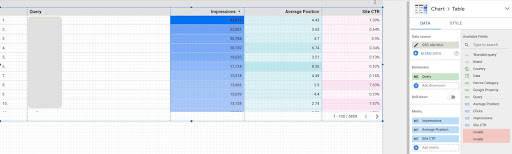
2. Caricamento dei nostri dati ed etichettatura delle query in base alla loro posizione
Per manipolare il CSV scaricato, utilizzeremo Panda.
La migliore pratica per la struttura delle cartelle del nostro progetto è avere una cartella "dati" in cui salviamo tutti i nostri dati.
Qui, per motivi di fluidità nel tutorial, non l'ho fatto.
query_df = pd.read_csv('./downloaded_data.csv')
Quindi etichettiamo le nostre query in base alla loro posizione. Ho creato un ciclo "for" per etichettare le posizioni da 1 a 10.
Ad esempio, se la posizione media di una query è 2,2 o 2,9, verrà etichettata come "2". Manipolando l'intervallo di posizione media, puoi ottenere la precisione che desideri.
per i nell'intervallo(1, 11):
query_df.loc[(query_df['Posizione media'] >= i) & (
query_df['Posizione media'] < i + 1), 'etichetta di posizione'] = i
Ora raggrupperemo le query in base alla loro posizione. Questo ci aiuta a manipolare i dati delle query di ogni posizione in un modo migliore nei passaggi successivi.
query_grouped_df = query_df.groupby(['etichetta di posizione'])
3. Filtraggio delle query in base ai loro dati per il calcolo della curva CTR
Il modo più semplice per calcolare la curva CTR è utilizzare tutti i dati delle query ed eseguire il calcolo. Tuttavia; non dimenticare di pensare a quelle query con un'impressione in posizione due nei tuoi dati.
Queste domande, in base alla mia esperienza, fanno molta differenza nel risultato finale. Ma il modo migliore è provarlo tu stesso. In base al set di dati, questo potrebbe cambiare.
Prima di iniziare questo passaggio, è necessario creare un elenco per l'output del grafico a barre e un DataFrame per archiviare le query manipolate.
# Creazione di un DataFrame per la memorizzazione dei dati manipolati 'query_df' modificato_df = pd.DataFrame() # Un elenco per salvare ogni posizione significa per il nostro grafico a barre lista_media_ctr = []
Quindi, eseguiamo il ciclo dei gruppi query_grouped_df e aggiungiamo il 20% delle query principali in base alle impressioni al DataFrame modified_df .
Se il calcolo del CTR solo in base al 20% superiore delle query con il maggior numero di impressioni non è il massimo per te, puoi modificarlo.
Per farlo, puoi aumentarlo o diminuirlo manipolando .quantile(q=your_optimal_number, interpolation='lower')] e your_optimal_number deve essere compreso tra 0 e 1.
Ad esempio, se desideri ottenere il 30% superiore delle tue query, your_optimal_num è la differenza tra 1 e 0,3 (0,7).
per i nell'intervallo(1, 11):
# Un try-tranne per gestire quelle situazioni in cui una directory non ha dati per alcune posizioni
Tentativo:
tmp_df = query_grouped_df.get_group(i)[query_grouped_df.get_group(i)['impressions'] >= query_grouped_df.get_group(i)['impressions']
.quantile(q=0,8, interpolazione='inferiore')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modificato_df = modificato_df.append(tmp_df, ignore_index=True)
tranne KeyError:
mean_ctr_list.append(0)
# Eliminazione di DataFrame 'tmp_df' per ridurre l'utilizzo della memoria
del [tmp_df]
4. Disegnare un box plot
Questo passaggio è quello che stavamo aspettando. Per disegnare grafici, possiamo usare Matplotlib, seaborn come wrapper per Matplotlib, o Plotly.
Personalmente, penso che l'utilizzo di Plotly sia una delle soluzioni migliori per gli esperti di marketing che amano esplorare i dati.
Rispetto a Mathplotlib, Plotly è così facile da usare e con poche righe di codice, puoi disegnare una bella trama.
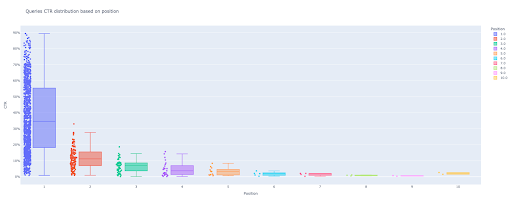
# 1. Il box plot
box_fig = px.box(df_modificato, x='etichetta posizione', y='CTR sito', title='Distribuzione CTR query basata sulla posizione',
punti='tutti', color='etichetta di posizione', etichette={'etichetta di posizione': 'Posizione', 'CTR sito': 'CTR'})
# Mostra tutti i dieci tick degli assi x
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Modifica del formato tick dell'asse y in percentuale
box_fig.update_yaxes(tickformat=".0%")
# Salvataggio del grafico nella directory 'output plot images'
box_fig.write_image('./output plot images/Query box plot CTR curve.png')
Con solo queste quattro righe, puoi ottenere un bellissimo box plot e iniziare a esplorare i tuoi dati.
Se vuoi interagire con questa colonna, in una nuova cella esegui:
box_fig.show()
Ora hai un attraente box plot in output che è interattivo.
Quando passi il mouse su un grafico interattivo nella cella di output, il numero importante che ti interessa è l'"uomo" di ogni posizione.
Questo mostra il CTR medio per ciascuna posizione. A causa dell'importanza media, come ricorderete, creiamo un elenco che contiene la media di ogni posizione. Successivamente, passeremo al passaggio successivo per disegnare un grafico a barre basato sulla media di ciascuna posizione.
5. Disegnare un grafico a barre
Come un box plot, disegnare la trama della barra è così facile. Puoi cambiare il title dei grafici modificando l'argomento title di px.bar() .
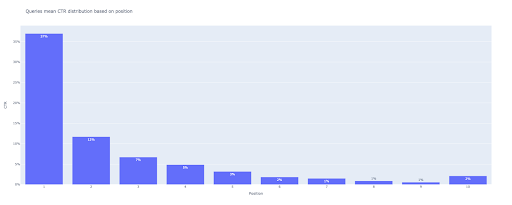
# 2. La trama della barra
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title='Le query indicano la distribuzione CTR in base alla posizione',
etichette={'x': 'Posizione', 'y': 'CTR'}, text_auto=True)
# Mostra tutti i dieci tick degli assi x
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Modifica del formato tick dell'asse y in percentuale
bar_fig.update_yaxes(tickformat='.0%')
# Salvataggio del grafico nella directory 'output plot images'
bar_fig.write_image('./output plot images/Query bar plot CTR curve.png')
In uscita, otteniamo questo grafico:
Come con il box plot, puoi interagire con questo plot eseguendo bar_fig.show() .
Questo è tutto! Con poche righe di codice, otteniamo la percentuale di clic organica basata sulla posizione con i dati delle nostre query.
Se disponi di una proprietà URL per ciascuno dei tuoi sottodomini o directory, puoi ottenere queste query sulle proprietà URL e calcolare la curva CTR per esse.
[Case Study] Migliorare le classifiche, le visite organiche e le vendite con l'analisi dei file di registro
 Leggi il caso di studio
Leggi il caso di studioSecondo metodo: calcolo della curva CTR in base agli URL delle pagine di destinazione per ciascuna directory
Nel primo metodo, abbiamo calcolato il nostro CTR organico in base al CTR delle query, ma con questo approccio otteniamo tutti i dati delle nostre pagine di destinazione e quindi calcoliamo la curva CTR per le nostre directory selezionate.

Amo in questo modo. Come sai, il CTR per le nostre pagine prodotto è molto diverso da quello dei nostri post sul blog o di altre pagine. Ogni directory ha il proprio CTR in base alla posizione.
In un modo più avanzato, puoi classificare ogni pagina della directory e ottenere la percentuale di clic organica di Google basata sulla posizione per un insieme di pagine.
1. Ottenere i dati delle pagine di destinazione
Proprio come il primo metodo, esistono diversi modi per ottenere i dati di Google Search Console (GSC). Con questo metodo, ho preferito ottenere i dati delle pagine di destinazione dall'esploratore dell'API di GSC all'indirizzo: https://developers.google.com/webmaster-tools/v1/searchanalytics/query.
Per ciò che è necessario in questo approccio, GDS non fornisce dati solidi sulla pagina di destinazione. Inoltre, puoi utilizzare il componente aggiuntivo Fogli Google "Cerca in Analytics per fogli".
Tieni presente che Google API Explorer è adatto a quei siti con meno di 25.000 pagine di dati. Per i siti più grandi, puoi ottenere parzialmente i dati delle pagine di destinazione e concatenarli insieme, scrivere uno script Python con un ciclo "for" per estrarre tutti i tuoi dati da GSC o utilizzare strumenti di terze parti.
Per ottenere dati da Google API Explorer:
- Vai alla pagina della documentazione dell'API GSC "Search Analytics: query": https://developers.google.com/webmaster-tools/v1/searchanalytics/query
- Utilizza API Explorer che si trova sul lato destro della pagina
- Nel campo "siteUrl", inserisci l'indirizzo della tua proprietà URL, ad esempio
https://www.example.com. Inoltre, puoi inserire la proprietà del tuo dominio come seguesc-domain:example.com - Nel campo "corpo della richiesta" aggiungi
startDateeendDate. Preferisco ottenere i dati del mese scorso. Il formato di questi valori èYYYY-MM-DD - Aggiungi
dimensione imposta i suoi valori apage - Crea un "dimensionFilterGroups" e filtra le query con i nomi delle varianti di marca (sostituendo
brand_variation_namescon i nomi dei tuoi marchi RegExp) - Aggiungi
rawLimite impostalo su 25000 - Al termine premere il pulsante 'ESEGUI'
Puoi anche copiare e incollare il corpo della richiesta qui sotto:
{
"startDate": "01-01-2022",
"endDate": "01-02-2022",
"dimensioni": [
"pagina"
],
"dimensionFilterGroups": [
{
"filtri": [
{
"dimensione": "QUERY",
"expression": "brand_variation_names",
"operatore": "EXCLUDING_REGEX"
}
]
}
],
"limite di riga": 25000
}
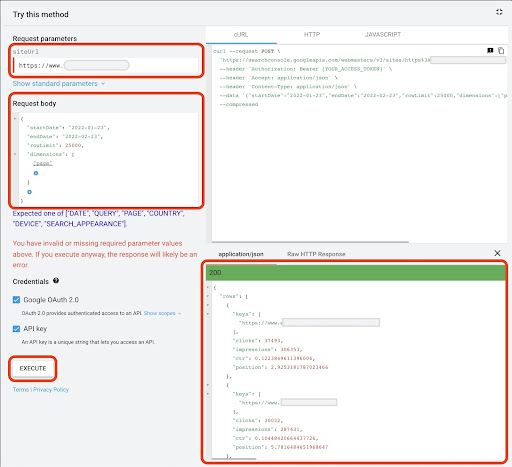
Dopo che la richiesta è stata eseguita, dobbiamo salvarla. A causa del formato della risposta, è necessario creare un file JSON, copiare tutte le risposte JSON e salvarlo con il nome file downloaded_data.json .
Se il tuo sito è piccolo, come un sito aziendale SASS, e i dati della tua pagina di destinazione sono inferiori a 1000 pagine, puoi facilmente impostare la tua data in GSC ed esportare i dati delle pagine di destinazione per la scheda "PAGINE" come file CSV.
2. Caricamento dei dati delle pagine di destinazione
Per il bene di questo tutorial, presumo che tu ottenga dati da Google API Explorer e li salvi in un file JSON. Per caricare questi dati dobbiamo eseguire il codice seguente:
# Creazione di un DataFrame per i dati scaricati
con open('./downloaded_data.json') come json_file:
landings_data = json.loads(json_file.read())['rows']
landings_df = pd.DataFrame(landings_data)
Inoltre, dobbiamo cambiare il nome di una colonna per darle più significato e applicare una funzione per ottenere gli URL della pagina di destinazione direttamente nella colonna "pagina di destinazione".
# Rinominare la colonna "chiavi" in colonna "pagina di destinazione" e convertire l'elenco "pagina di destinazione" in un URL
landings_df.rename(columns={'keys': 'landing page'}, inplace=True)
landings_df['pagina di destinazione'] = landings_df['pagina di destinazione'].apply(lambda x: x[0])
3. Ottenere tutte le directory principali delle pagine di destinazione
Prima di tutto, dobbiamo definire il nome del nostro sito.
# Definire il nome del tuo sito tra virgolette. Ad esempio, "https://www.example.com/" o "http://miodominio.com/" nome_sito = ''
Quindi eseguiamo una funzione sugli URL della pagina di destinazione per ottenere le loro directory principali e vederle in output per sceglierle.
# Ottenere ogni directory della pagina di destinazione (URL).
landings_df['directory'] = landings_df['pagina di destinazione'].str.extract(pat=f'((?<={site_name})[^/]+)')
# Per ottenere tutte le directory nell'output, dobbiamo manipolare le opzioni di Pandas
pd.set_option("display.max_rows", Nessuno)
# Directory del sito web
landings_df['directory'].value_counts()
Quindi, scegliamo per quali directory dobbiamo ottenere la loro curva CTR.
Inserisci le directory nella variabile important_directories .
Ad esempio, product,tag,product-category,mag . Separare i valori delle directory con una virgola.
directory_importanti = ''
directory_importanti = directory_importanti.split(',')
4. Etichettatura e raggruppamento delle pagine di destinazione
Come per le query, etichettiamo anche le pagine di destinazione in base alla loro posizione media.
# Etichettatura della posizione delle pagine di destinazione
per i nell'intervallo(1, 11):
landings_df.loc[(landings_df['position'] >= i) & (
landings_df['posizione'] < i + 1), 'etichetta di posizione'] = i
Quindi, raggruppiamo le pagine di destinazione in base alla loro "directory".
# Raggruppamento delle pagine di destinazione in base al loro valore di "directory". landings_grouped_df = landings_df.groupby(['directory'])
5. Generazione di grafici a scatole e barre per le nostre directory
Nel metodo precedente, non abbiamo utilizzato una funzione per generare i grafici. Tuttavia; per calcolare automaticamente la curva CTR per diverse landing page, dobbiamo definire una funzione.
# La funzione per creare e salvare i grafici di ogni directory
def each_dir_plot(dir_df, chiave):
# Raggruppamento delle pagine di destinazione della directory in base al valore dell'"etichetta di posizione".
dir_grouped_df = dir_df.groupby(['etichetta di posizione'])
# Creazione di un DataFrame per la memorizzazione dei dati manipolati 'dir_grouped_df'
modificato_df = pd.DataFrame()
# Un elenco per salvare ogni posizione significa per il nostro grafico a barre
lista_media_ctr = []
'''
Eseguire il ciclo sui gruppi "query_grouped_df" e aggiungere il 20% delle query principali in base alle impressioni al DataFrame "modified_df".
Se il calcolo del CTR solo in base al 20% superiore delle query con il maggior numero di impressioni non è il massimo per te, puoi modificarlo.
Per cambiarlo, puoi aumentarlo o diminuirlo manipolando '.quantile(q=your_optimal_number, interpolation='lower')]'.
'you_optimal_number' deve essere compreso tra 0 e 1.
Ad esempio, se desideri ottenere il 30% superiore delle tue query, 'your_optimal_num' è la differenza tra 1 e 0,3 (0,7).
'''
per i nell'intervallo(1, 11):
# Un try-tranne per gestire quelle situazioni in cui una directory non ha dati per alcune posizioni
Tentativo:
tmp_df = dir_grouped_df.get_group(i)[dir_grouped_df.get_group(i)['impressions'] >= dir_grouped_df.get_group(i)['impressions']
.quantile(q=0,8, interpolazione='inferiore')]
mean_ctr_list.append(tmp_df['ctr'].mean())
modificato_df = modificato_df.append(tmp_df, ignore_index=True)
tranne KeyError:
mean_ctr_list.append(0)
# 1. Il box plot
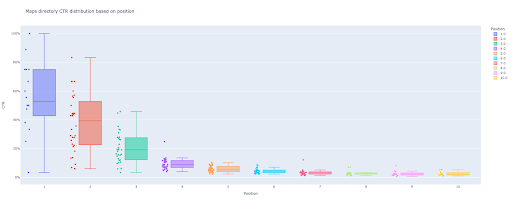
box_fig = px.box(modified_df, x='position label', y='ctr', title=f'{key} directory CTR distribuzione basata sulla posizione',
points='all', color='position label', labels={'position label': 'Position', 'ctr': 'CTR'})
# Mostra tutti i dieci tick degli assi x
box_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Modifica del formato tick dell'asse y in percentuale
box_fig.update_yaxes(tickformat=".0%")
# Salvataggio del grafico nella directory 'output plot images'
box_fig.write_image(f'./output plot images/{key} directory-Box plot CTR curve.png')
# 2. La trama della barra
bar_fig = px.bar(x=[pos for pos in range(1, 11)], y=mean_ctr_list, title=f'{key} directory distribuzione CTR media basata sulla posizione',
etichette={'x': 'Posizione', 'y': 'CTR'}, text_auto=True)
# Mostra tutti i dieci tick degli assi x
bar_fig.update_xaxes(tickvals=[i for i in range(1, 11)])
# Modifica del formato tick dell'asse y in percentuale
bar_fig.update_yaxes(tickformat='.0%')
# Salvataggio del grafico nella directory 'output plot images'
bar_fig.write_image(f'./output plot images/{key} directory-Bar plot CTR curve.png')
Dopo aver definito la funzione sopra, abbiamo bisogno di un ciclo "for" per scorrere i dati delle directory per i quali vogliamo ottenere la loro curva CTR.
# Eseguire il ciclo delle directory ed eseguire la funzione 'each_dir_plot'
per chiave, elemento in landings_grouped_df:
se chiave in directory_importanti:
each_dir_plot(elemento, chiave)
Nell'output, otteniamo i nostri grafici nella cartella delle output plot images del grafico di output.
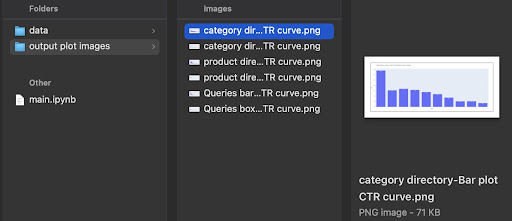
Consiglio avanzato!
Puoi anche calcolare le curve CTR delle diverse directory utilizzando la pagina di destinazione delle query. Con alcune modifiche alle funzioni, puoi raggruppare le query in base alle directory delle pagine di destinazione.
Puoi utilizzare il corpo della richiesta di seguito per effettuare una richiesta API in API Explorer (non dimenticare il limite di 25000 righe):
{
"startDate": "01-01-2022",
"endDate": "01-02-2022",
"dimensioni": [
"interrogazione",
"pagina"
],
"dimensionFilterGroups": [
{
"filtri": [
{
"dimensione": "QUERY",
"expression": "brand_variation_names",
"operatore": "EXCLUDING_REGEX"
}
]
}
],
"limite di riga": 25000
}
Suggerimenti per la personalizzazione del calcolo della curva CTR con Python
Per ottenere dati più accurati per il calcolo della curva CTR, dobbiamo utilizzare strumenti di terze parti.
Ad esempio, oltre a sapere quali query hanno uno snippet in primo piano, puoi esplorare più funzionalità SERP. Inoltre, se utilizzi strumenti di terze parti, puoi ottenere la coppia di query con il ranking della pagina di destinazione per quella query, in base alle funzionalità SERP.
Quindi, etichettare le pagine di destinazione con la loro directory principale (principale), raggruppare le query in base ai valori della directory, considerare le funzionalità SERP e infine raggruppare le query in base alla posizione. Per i dati CTR, puoi unire i valori CTR da GSC alle loro query peer.