
Importanza della rete semantica per la SEO: creazione di reti di contenuti semantici con modelli di query e documenti - Case Study
Pubblicato: 2022-01-11Una rete semantica è connessa al concetto di una base di conoscenza che può rappresentare informazioni del mondo reale per cose che hanno connessioni relazionali. Una base di conoscenza può avere migliaia di tipi di relazione con miliardi di entità e trilioni di fatti. Una rete semantica può essere creata da qualsiasi esistenza nel mondo reale con caratteristiche reciproche come peso, dimensione, tipo, odore o colore. La relazione tra le Reti Semantiche e il Web Semantico è creata dai motori di ricerca semantica e dall'ottimizzazione.
Le reti semantiche sono utilizzate nell'analisi semantica, nella disambiguazione del senso delle parole, nella creazione di reti di parole, nella teoria dei grafi, nell'elaborazione del linguaggio naturale, nella comprensione e nella generazione. La prospettiva di una rete semantica può essere utilizzata all'interno dell'ottimizzazione semantica dei motori di ricerca fornendo una rete di contenuti semantici.
In questo caso di studio SEO, verranno spiegati due siti Web diversi con due metodi diversi con la stessa prospettiva in base ai modelli Query, Document, Intent e alle coppie entità-attributo dietro di essi.
Utilizzando la comprensione di come i motori di ricerca rappresentano la conoscenza e di come espandono la loro rappresentazione della conoscenza, sono in grado di sfruttarla per produrre risultati di ranking incredibili. Una volta compresi i concetti di base, spiegherò come li ho applicati ai due diversi siti Web, quindi descriverò in dettaglio i metodi che ho utilizzato.
In che modo le reti semantiche possono aiutare il posizionamento del tuo sito web?
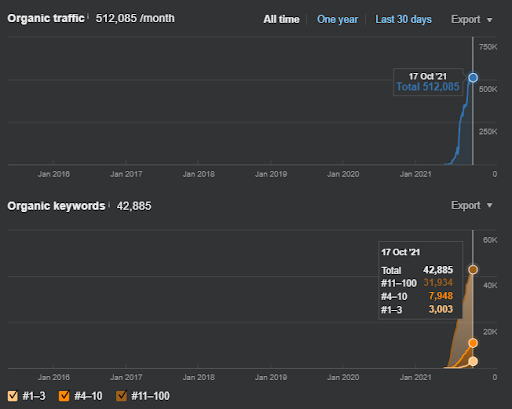
Di seguito, troverai i risultati grezzi complessivi per Project I.
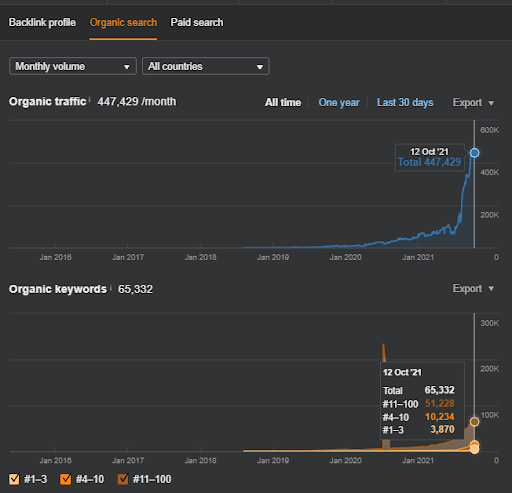
Risultati per il Progetto Uno che è IstanbulBogaziciEnstitu.com. Per dimostrare che le "Reti semantiche" possono essere utilizzate per la SEO con modelli di query e documenti, dimostrerò due diverse reti di contenuti da Project One. Project One avrà risultati molto migliori nel prossimo futuro grazie a Semantic Content Network Two. Il cliente sarà responsabile del roll-out di questa seconda rete, ma ne spiegherò anche la logica.
17 giorni dopo, ecco lo stato di avanzamento del Progetto I: 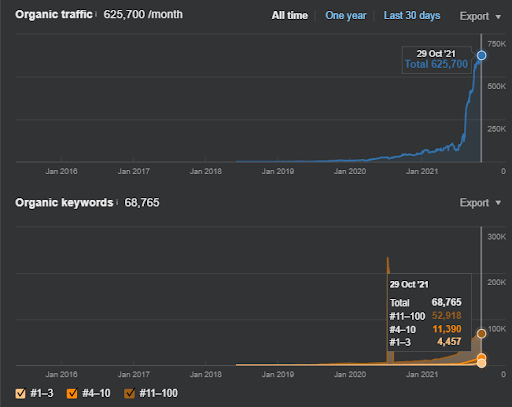
17 giorni dopo, il processo di riclassificazione di Semantic Content Network è più chiaro.
I concetti di Semantic Content Network ci aiutano a comprendere il valore di query, intenti di ricerca, comportamenti e modelli di documenti per entità dello stesso tipo. In questo case study SEO incentrato sulla rete semantica, il precedente case study sull'autorità topica e sulla SEO semantica verrà approfondito tramite i due nuovi siti Web che utilizzano reti di contenuti create semanticamente attorno agli stessi tipi di entità.
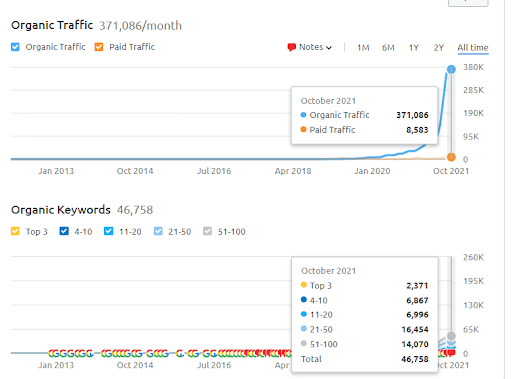
Questa è la grafica SEMRush del Primo Progetto. Devo anche ricordare che questo sito Web ha perso l'aggiornamento dell'algoritmo Broad Core di giugno, se non perdesse la sua "classificabilità", i risultati sarebbero migliori. Per il prossimo aggiornamento dell'algoritmo Broad Core, con una migliore autorità di attualità, copertura e dati storici, può recuperare facilmente la "classificabilità".
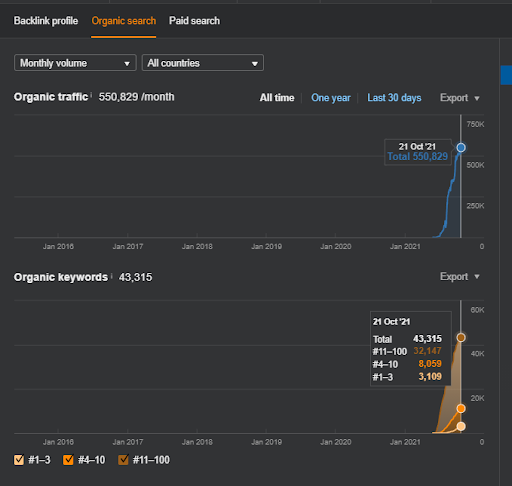
Il nome del Secondo Progetto è Vizem.net. A differenza di Project One, puoi vedere che Vizem.net ha un aumento più lento ma costante. È perché usano le reti di contenuti semantici con prospettive leggermente diverse. Di seguito, puoi vedere i risultati Ahrefs del Secondo Progetto.
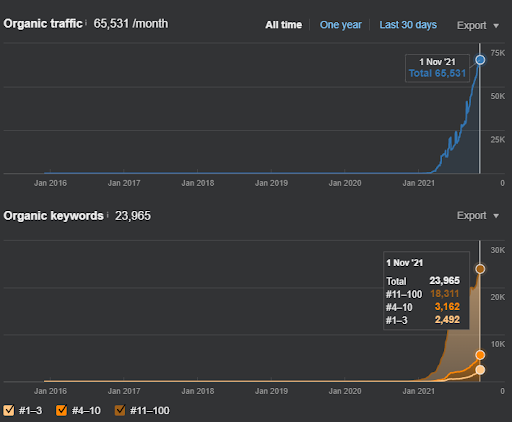
I risultati del Secondo Progetto rappresentano un “Processo di riclassificazione lento” attraverso il miglioramento graduale della Copertura e dell'Autorità d'attualità. I termini “Re-ranking” e “Initial Ranking” verranno spiegati dopo i concetti relativi alle Semantic Content Network. Se ti rendi conto della "stabilità" all'interno della grafica, è perché ho smesso di pubblicare nuovi contenuti nella fonte. Inoltre, influisce sul processo di riclassificazione, come ti rendi conto dai conteggi dei primi 3 conteggi di query. Le relazioni “Momentum”, e “Re-ranking” si trovano dopo le spiegazioni dei concetti fondamentali.
Di seguito, puoi trovare i risultati di SEMRush di Vizem.net.
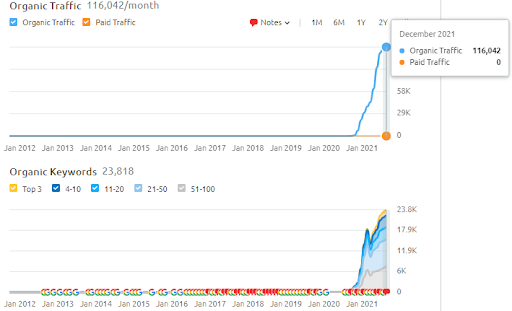
Il traffico effettivo di questo sito Web è 3 volte superiore al numero indicato nel SEMRush. Puoi realizzare la stessa "stabilità" e anche i concetti di "momentum" all'interno di questi grafici.
Mentre scrivevo il caso di studio SEO dell'autorità topica, ho ringraziato Bill Slawski per aver educato la mia prospettiva. Lo ripeto anche per il case study SEO di Semantic Content Network. Per comprendere i concetti di "riclassifica" e "classifica iniziale", è necessario leggere "Modalità in cui i motori di ricerca possono riclassificare i risultati di ricerca".
Il 18 marzo 2021, Oncrawl, RankSense e Holistic SEO & Digital hanno pubblicato un Webinar Python SEO e Data Science. Nel webinar è stata registrata la SERP per animare le differenze di risultato. Si può notare che il motore di ricerca modifica le classifiche di alcune fonti con altre con una frequenza simile.
Prima di continuare oltre, so che questo è un articolo lungo. Ma in realtà questa è una breve spiegazione di una metodologia SEO molto complessa. Le reti di contenuti semantici richiedono troppa riflessione durante la progettazione e mesi di formazione per clienti, autori e insieme all'onboarding. Pertanto, in questo articolo, voglio concentrarmi sulle definizioni dei concetti con i migliori brevi suggerimenti eseguibili possibili e importanti brevetti di Google e altri motori di ricerca, documenti di ricerca insieme ai propri concetti. Nella versione lunga (in pratica, un libro), mi sono concentrato sul “ranking iniziale” e sul “re-ranking” delle reti di contenuti semantici.
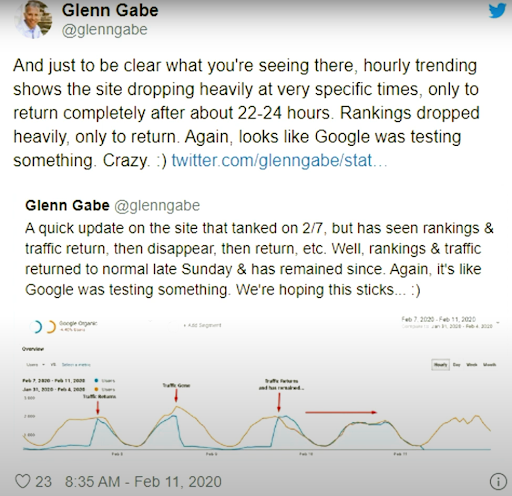
Dall'11 febbraio 2020, Glenn Gabe ha un buon esempio per la metodologia di riclassificazione e test dei motori di ricerca visivamente.
Se vuoi saperne di più, leggi "Importanza del ranking iniziale e re-ranking per SEO".
Per approfondire i dati del mondo reale per il case study SEO, i concetti per comprendere la rete di contenuti semantici dovrebbero essere elaborati con una prospettiva di comprensione e comunicazione dei motori di ricerca.
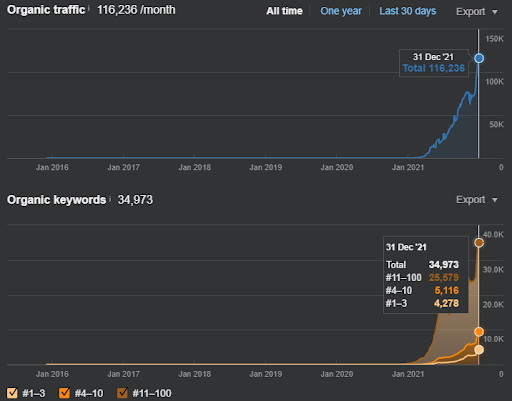
Come esempio di riclassificazione di Vizem.net, la situazione aggiornata può essere vista sopra. Nelle prossime sezioni del SEO Case Study, ci saranno ulteriori spiegazioni per gli algoritmi di re-ranking di Google per la SEO.
Cos'è una rete semantica?
Una rete semantica può essere utilizzata per connettere e analizzare l'Internet delle cose. Può essere utile per riconoscere i potenziali acquirenti nel mercato della tecnologia o semplicemente per l'analisi di parole chiave per la creazione di reti di parole chiave e il raggruppamento. Una rete semantica può essere utilizzata per supportare la navigazione e rivelare la struttura delle relazioni o l'importanza relativa di una cosa rispetto a un'altra cosa. Semantic Network ha i componenti seguenti:
- Semantica lessicale: capire quale parola e concetto sono legati a quali altri, con quali differenze.
- Componente strutturale: capire quale nodo è connesso a quale bordo con quali informazioni.
- Componente semantica: Definizione dei fatti.
- Parte procedurale: aiuta a creare ulteriori connessioni tra i componenti.
Poiché le reti semantiche sono multiuso, gli algoritmi NLP possono essere utilizzati anche per scopi molto diversi, ad esempio per aiutare a identificare complicati problemi di salute. La stessa struttura di rete semantica può essere implementata in più altre aree purché queste altre aree abbiano una relazione semantica tra loro.
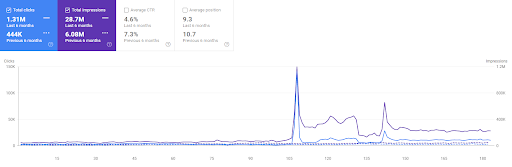
Confronto degli ultimi 6 mesi del Primo Progetto.
Che cos'è una base di conoscenza?
Una base di conoscenza è una libreria di informazioni con classificazione in un formato leggibile dalla macchina. Una base di conoscenza può essere utilizzata come un'enciclopedia che può essere ristretta e approfondita in base alla query. È possibile formare una base di conoscenza basata su proposte, estrazione di fatti ed estrazione di informazioni. La relazione tra una rete semantica e una base di conoscenza è che tutto ciò che è nella rete semantica verrà inserito nella base di conoscenza durante l'estrazione dei fatti.
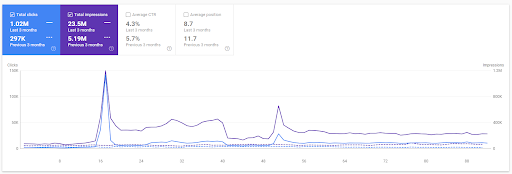
Confronto degli ultimi 3 mesi del Primo Progetto
Che cos'è una rete di contenuti semantici?
Semantic Content Network rappresenta una rete di contenuti che è stata preparata sulla base delle componenti e della comprensione della rete semantica. Una rete di contenuti semantici può includere più attributi di un'entità o entità dello stesso gruppo al fine di fornire una base di conoscenza più dettagliata.
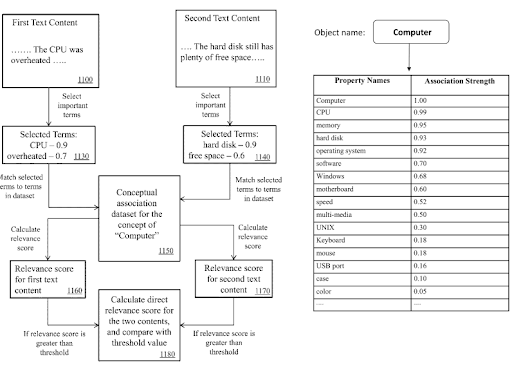
All'interno di una rete di contenuti semantici, i termini del dominio della conoscenza e le triple possono essere utilizzati per segnalare lo scopo principale di un documento e possibili contenuti di quartiere.
Un motore di ricerca può confrontare la propria base di conoscenza con la base di conoscenza che può essere generata dal contenuto di un sito web. Se il sito Web ha un elevato livello di accuratezza e completezza per diversi livelli contestuali, il motore di ricerca può migliorare la propria base di conoscenza dal contenuto del sito Web. Se un motore di ricerca migliora ed espande la propria base di conoscenze da un'altra fonte sul Web aperto, è un segnale di un alto livello di fiducia basata sulla conoscenza.
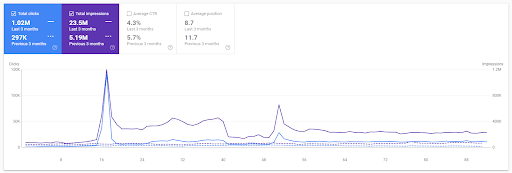
Confronto anno su anno per gli ultimi 3 mesi in base al primo progetto.
Che cos'è la fiducia basata sulla conoscenza?
La fiducia basata sulla conoscenza si concentra sul Web aperto basato sulla "accuratezza delle informazioni", non sul "PageRank". È un algoritmo simile al RankMerge. La fiducia basata sulla conoscenza implica triplette, estrazione dei fatti, controllo dell'accuratezza e comprensione del testo rimuovendo l'ambiguità del testo. La fiducia basata sulla conoscenza può essere acquisita fornendo reti di contenuto semantico che hanno le componenti fortemente connesse all'interno dell'articolo, basate su livelli contestuali diversi ma rilevanti.
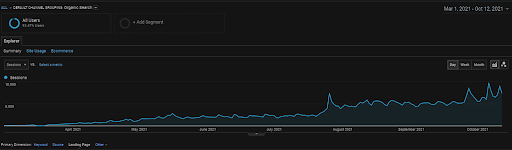
La sessione organica di Vizem.net di GA negli ultimi 6 mesi.
Di seguito, vedrai un esempio di una presentazione di Trust basata sulla conoscenza di Luna Dong. Mostra come un motore di ricerca può concentrarsi sui "fattori di ranking interni" anziché sui fattori di ranking esogeni. Spiega che un PageRank elevato non può rappresentare di per sé un'elevata qualità e accuratezza per il contenuto. Quindi, avere un KBT (Knowledge-based Trust) è importante.
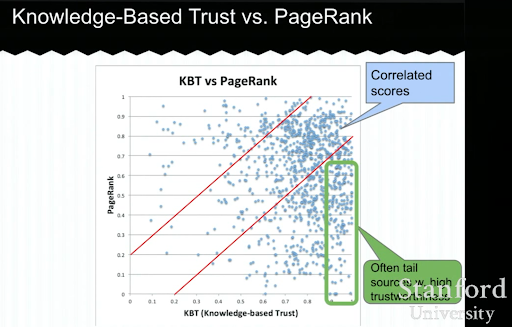
Mille grazie ad Arnout Hellemans che ha condiviso con me questa lezione educativa durante una chat SEO privata. Se vuoi saperne di più sulla fiducia basata sulla conoscenza: Stanford Seminar – Knowledge Vault e sulla fiducia basata sulla conoscenza
Che cos'è la copertura contestuale?
La copertura contestuale e la copertura tematica non sono la stessa cosa del dominio della conoscenza e il dominio contestuale non sono la stessa cosa. Una copertura contestuale rappresenta gli angoli di elaborazione di un concetto. Un concetto può essere elaborato in base ai suoi punti reciproci con le altre cose. Come se l'entità fosse un paese, la sua posizione sulla crisi ambientale può essere elaborata. Se altri paesi vengono elaborati dalla stessa angolazione, significa che stiamo coprendo un dominio contestuale.

Il motore di ricerca di Google costruisce i suoi documenti di ricerca e brevetti nel tempo. La citazione a destra della sezione sopra è un attributo ai "vettori di contesto" mentre la sezione a sinistra è un attributo alla "tassonomia delle frasi". La cosa interessante è che, anche l'esempio è lo stesso, che è “fotocamera digitale”.
I dettagli approfonditi e le sottoparti di queste combinazioni rappresentano gli strati contestuali all'interno di un dominio contestuale. Ogni entità, che sia denominata o meno, ha molti domini contestuali. Pertanto, Google estrae più domini contestuali e gli utenti cercano query più lunghe ogni anno. Quando vengono sviluppate l'elaborazione del linguaggio naturale e la comprensione del linguaggio naturale, le query ei documenti si espandono insieme in termini di dettagli e contesto.
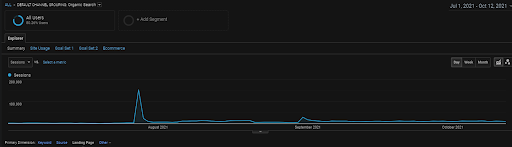
La grafica delle sessioni organiche di GA per gli ultimi 4 mesi del progetto BogaziciEnstitu. A causa della "fase di guadagno dei dati storici" del progetto, i dettagli aumentati non sono chiari per essere visti come lineari.
Una copertura contestuale può essere intesa dai "qualificatori di contesto". Un qualificatore di contesto può essere un aggettivo, avverbiale o qualsiasi altra preposizione come frasi che iniziano con "for, in, at, during, while". Le domande relative all'entità di seguito non sono le stesse in termini di dominio contestuale:
- Quali sono i frutti più utili per i bambini con insonnia?
- Quali sono i frutti più utili per i bambini con ansia?
Le domande relative all'entità di seguito non sono le stesse in termini di livello contestuale:
- Quali sono i frutti più utili per i bambini con grave insonnia di età superiore ai 6 anni?
- Quali sono i frutti più utili per i bambini con ansia di basso livello sotto i 6 anni?
Le domande relative all'entità di seguito non sono le stesse in termini di domini di conoscenza:
- Quali sono i libri più utili per i bambini con insonnia grave di età superiore ai 6 anni?
- Quali sono i giochi più utili per i bambini con ansia di basso livello sotto i 6 anni?
Ma tutte queste domande possono trovarsi nella stessa rete di contenuti semantici perché riguardano tutte lo stesso "concetto" e "area di interesse" con attività di ricerca simili e attività nel mondo reale correlate alla ricerca.
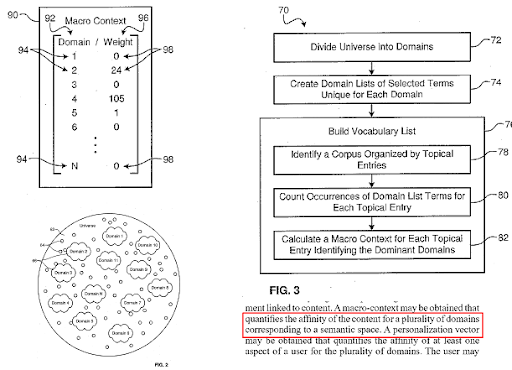
Un motore di ricerca divide il Web in diversi domini di conoscenza e calcola contemporaneamente i punteggi di macro e micro contesto per una fonte, una pagina Web e una sezione di una pagina Web.
So che ho molti nuovi concetti per te, e poiché questa è la versione breve di questo articolo, non sarò in grado di parlare di tutto qui, ma in un futuro corso Semantic SEO, elaborerò queste cose come la differenza tra "attività di ricerca" e "attività nel mondo reale correlata alla ricerca".
Continuiamo un po' con le cose più concrete.
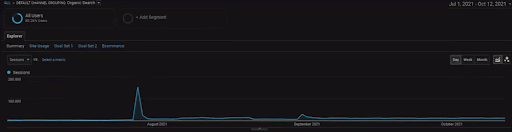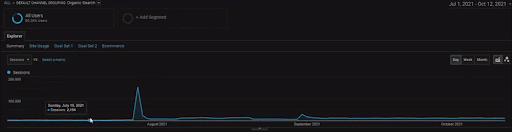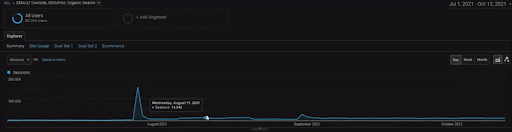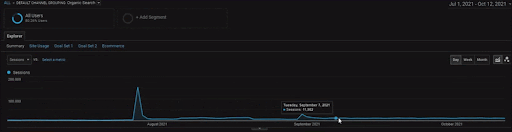
Per mostrare i dettagli del progetto BogaziciEnstitu, puoi controllare la versione dell'immagine interattiva. Il processo di test e riclassificazione dei motori di ricerca è più chiaro su questo progetto dopo l'evento storico dell'origine dati.
In che modo MuM è correlato alle reti di contenuti semantici?
L'apprendimento multitasking con un trasformatore unificato o il modello unificato multitasking addestra i modelli linguistici per valutare gli input visivi, oltre al testo. È in grado di generare testo insieme alla comprensione. Inoltre, MuM è indipendente dalla lingua, in altre parole, la SEO semantica dipende dall'abilità linguistica, ma non è limitata a una lingua. Poiché le entità non hanno un linguaggio e il significato è universale, MuM sfrutta le informazioni provenienti da più lingue e più contesti in un'unica base di conoscenza.
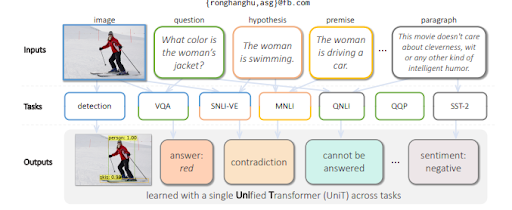
Per rispondere alle domande da una visuale, MuM genera domande basate sugli oggetti rilevati all'interno di un'immagine. Nel prossimo futuro potranno essere generate anche domande relative ad audio e video.
MuM utilizza diversi domini per il rilevamento di oggetti e la comprensione del linguaggio naturale con una struttura codificatore-decodificatore trasformatore. Ogni input proviene da una diversa area del web aperto mentre tutti vengono valutati da un unico decoder condiviso. Di seguito, potrai vedere un ulteriore esempio tratto dal documento di ricerca.
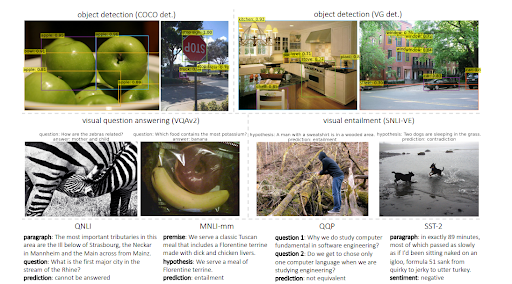
Come nota, MuM può essere 1000 volte più forte di BERT, ma BERT è ancora utilizzato all'interno del codificatore di testo di MuM. Il principale vantaggio di MuM è che può essere utilizzato direttamente per immagini e audio, motivo per cui può essere definito un modello "multitasking". Il secondo vantaggio è che rimuove direttamente tutte le barriere linguistiche. Il terzo vantaggio è che è in grado di collegare tutto a un'altra cosa senza bisogno di intermediari aggiuntivi. Il quarto vantaggio è che anche MuM può generare testo, a differenza di BERT.
La connessione tra MuM, Knowledge Base, Reti semantiche e Copertura contestuale è che il motore di ricerca è in grado di trovare domini molto più contestuali tramite qualificatori di contesto e le loro combinazioni con possibili domini di conoscenza. Pertanto, una rete di contenuti semantici ben strutturata, modellata con una mappa topica e un contesto di origine adeguati, può migliorare la fiducia della base di conoscenza, insieme all'autorità topica.
Qual è il contesto della sorgente?
Il contesto della sorgente rappresenta due cose. L'internet di ricerca centrale della fonte e l'attività di ricerca centrale che può essere eseguita con l'attività di ricerca correlata. Per un sito Web di e-commerce, il contesto di origine è l'acquisto di un prodotto specifico o di un tipo specifico di prodotto. Se si tratta di un sito Web di viaggi, il contesto della fonte sta andando da qualche parte da un altro posto per diversi tipi di cibo, paesaggi o semplicemente affari. In base al contesto della sorgente, il design della rete di contenuti semantici e la mappa tematica dovranno essere ulteriormente configurati. Ciò richiede la scelta delle sezioni centrali all'interno della mappa tematica e delle sezioni supplementari all'interno della mappa tematica.
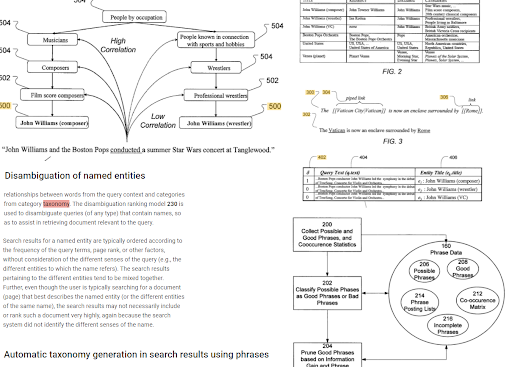
L'indicizzazione basata su frasi e la comprensione della ricerca orientata all'entità sono collegate tra loro in base alla semantica. Sopra, la "Disambiguazione dell'entità denominata" e la "Generazione automatica della tassonomia nei risultati di ricerca mediante frasi" possono essere viste insieme per determinare il "contesto". Le buone frasi e le informazioni uniche ma correlate per un argomento aiuteranno a migliorare l'iniziale e il riposizionamento.
Anche in questo caso, alcuni di questi concetti, la "configurazione della mappa topica", il "design della rete di contenuti semantici" non sono stati ancora definiti e questo non è il posto giusto per questo. Tuttavia, l'attività di ricerca correlata è stata spiegata insieme all'intento di ricerca canonico e alle frasi rappresentative di questi intenti di ricerca canonici.
Sfondo del caso di studio SEO focalizzato sulla rete semantica
Sulla base dei concetti di cui sopra, ho utilizzato le reti semantiche per creare un case study SEO. Esamineremo i due progetti di siti Web che ho menzionato all'inizio di questo articolo ed esamineremo i risultati e come ho implementato le reti semantiche per produrli.
Per darti un'idea di quanto possano essere potenti queste reti, i risultati relativi alla SEO per il case study SEO incentrato sulla rete semantica sono elencati di seguito.
- La comprensione della rete semantica è una necessità per creare una mappa tematica adeguata.
- Per entrambi i progetti, la SEO tecnica non viene utilizzata per isolare gli effetti della SEO semantica.
- L'ottimizzazione della velocità della pagina non viene utilizzata, per lo stesso motivo.
- Il design e l'ottimizzazione WUX (Website User Experience) non vengono utilizzati.
- I backlink (riferimenti esterni e flusso di PageRank) non vengono utilizzati.
- Entrambi i marchi non hanno dati storici. Vizem.net è completamente nuovo, BogaziciEnstitusu ha una storia più antica ma era inferiore alla società attuale.
- Non viene utilizzato il SEO OnPage o altri verticali del SEO.
- Entrambi i marchi hanno un server migliore rispetto al precedente esempio di case study di Topical Authority.
Questo case study SEO incentrato sulla rete semantica aiuterà le persone che desiderano migliorare la propria prospettiva SEO semantica con due diverse metodologie e concetti che si concentrano su due diversi siti Web.
Progetto due: Vizem.net si concentra sul processo di richiesta del visto. Prima di scrivere, pubblicare o persino lanciare questi progetti, ho mostrato entrambi questi siti Web molte volte ai miei altri clienti o partner. E Vizem.net ha recentemente iniziato il suo viaggio "Topical Authority".
Il SEO basato su Semantic Networks Case Study è stato scritto in due diverse versioni. Se vuoi leggere tutti i relativi brevetti, documenti di ricerca e approfondimenti approfonditi, interpretazioni dal punto di vista dei motori di ricerca mentre comprendi ulteriormente gli alberi decisionali dei motori di ricerca, puoi leggere l'importanza del posizionamento iniziale e del riposizionamento SEO Articolo di case study che supera le 30.000 parole. Se non hai abbastanza conoscenze teoriche per SEO e background storico, puoi continuare a leggere il riepilogo esecutivo.
Di seguito, puoi vedere la grafica del Secondo Progetto (Vizem.net) da SEMRush.
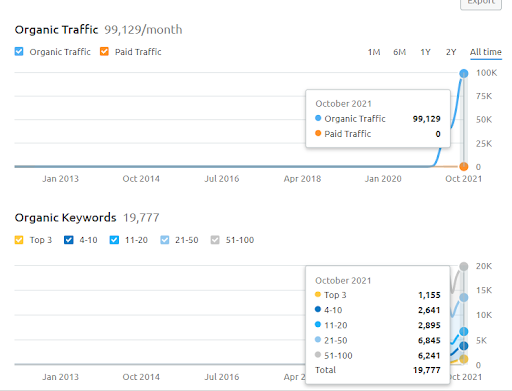
La grafica SEMRush del Secondo Sito. Vizem.net è una fonte completamente nuova che si rivolge a settori con un alto livello di concorrenti radicati come "Visa Application". Soprattutto, a causa degli ultimi eventi in Turchia, il livello di concorrenza del settore è in aumento. Pertanto, è utile utilizzare la prospettiva della rete semantica per creare una rete di contenuti.
Primo progetto: Istanbul Bogazici Enstitusu: aumento del 600% dei clic organici in 3 mesi – Dati storici con leva e classifica iniziale
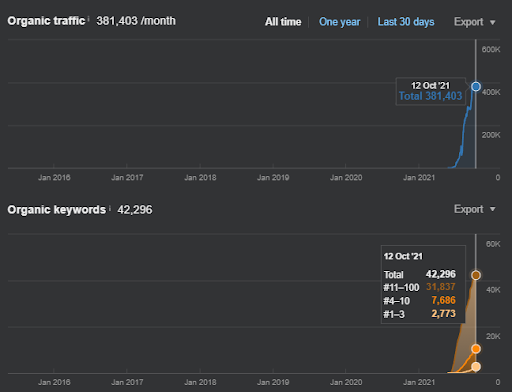
IstanbulBogazici Enstitusu è uno dei casi di studio SEO più difficili che ho eseguito, non a causa dei motori di ricerca, ma a causa delle persone e dei miei problemi di salute. Pertanto, ho lasciato il progetto e non ho pubblicato la terza rete di contenuti semantici progettata per completare le relazioni semantiche basate sul contesto della fonte. Anche se non ha termini del dominio della conoscenza e frasi contestuali implementate correttamente, è configurato con livelli sufficienti di connessioni semantiche e accuratezza, per consentire una performance di ricerca organica complessiva di oltre tre milioni di sessioni al mese se la terza rete di contenuti è pubblicato in futuro, tenendo conto anche dell'effetto crescente della seconda rete di contenuti semantici.
Di seguito, vedrai la grafica mutevole dell'IstanbulBogazici Enstitusu su GSC negli ultimi 12 mesi. Il progetto è stato avviato a maggio 2021 in modo corretto e si è concluso entro settembre 2021 pubblicando due Semantic Content Network.
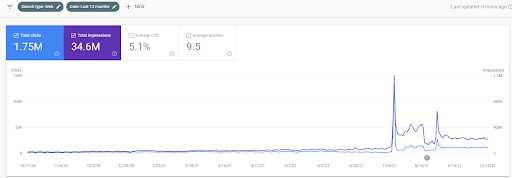
Di seguito puoi vedere la versione più dettagliata. Da 1400 clic giornalieri a 140000 clic, quindi è possibile visualizzare oltre 10.000 clic regolari al giorno nel rendimento della ricerca organica
Di seguito è possibile vedere l'aumento del traffico della prima rete di contenuti dopo il lancio.
Questa schermata mostra il 4° mese della prima rete di contenuti semantici.
Come si può vedere dal grafico, il traffico complessivo dell'intero sito è stato dominato e condizionato dalla First Semantic Content Network che si concentra sui “rami educativi”. La seconda rete di contenuti che ho lanciato con questo sito Web può essere vista di seguito da Google Search Console. Lo screenshot qui sotto è del 16° giorno della seconda rete di contenuti semantici.
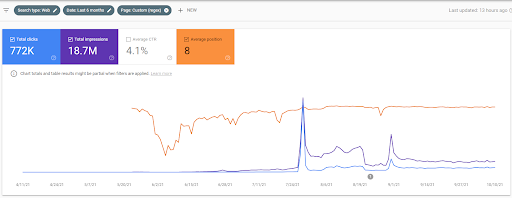
Il ranking iniziale e il re-ranking sono stati utilizzati all'interno dell'articolo perché definiscono le fasi degli algoritmi di ranking insieme ai loro tipi e scopi prima di testare una fonte e una pagina Web dalla fonte all'interno della SERP per query più importanti che hanno una popolarità .
Su cosa si concentra la prima rete di contenuti semantici del primo progetto?
"Semantic Content Network" utilizza una rete semantica da una base di conoscenza per spiegare le relazioni principali, secondarie e terziarie tra le cose all'interno della base di conoscenza. Pertanto, la creazione di una rete di contenuti semantici richiede la progettazione della successiva rete di contenuti semantici basata sul contesto della fonte, che è la funzione principale del sito Web. In questo contesto, la prima rete di contenuti semantici si è concentrata su "dipartimenti universitari, rami educativi e necessità per una formazione universitaria all'interno di un'organizzazione e di un ramo specifici".
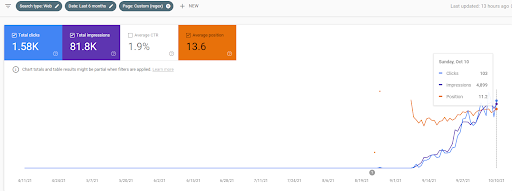
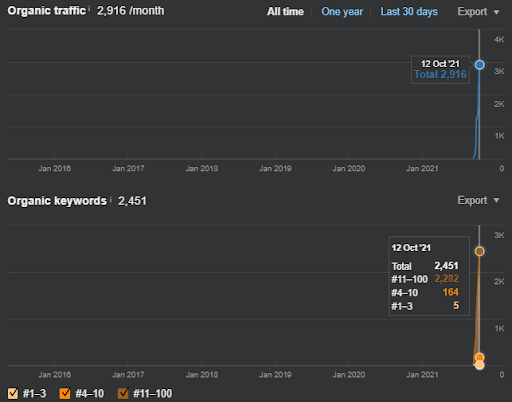
Di seguito, troverai la grafica Ahrefs della prima rete di contenuti semantici.
Questo è cinque giorni dopo rispetto allo screenshot precedente.
“Root: istanbulbogazicienstitu.com/bolum”, dopo la prima fase di classificazione iniziale, il processo di riclassificazione è più efficiente e produttivo.
Puoi vedere la versione successiva di quattro giorni come di seguito per supportare la natura del "riclassifica".
Su cosa si concentra la seconda rete di contenuti semantici del primo progetto?
La seconda rete di contenuti semantici si è concentrata sulle occupazioni, i lavori, le abilità e l'istruzione necessaria per queste abilità, o routine. Basata sulla prima rete di contenuti semantici, è stata supportata la seconda rete di contenuti semantici. E, secondo i "modelli di query-modelli di intenti", vengono create e posizionate altre due diverse reti di sottocontenuti semantici con le "connessioni relazionali" pur essendo collegate ai livelli gerarchici simili superiori.
So che queste sezioni sono complicate per te perché non hai ancora visto una definizione per le cose di seguito.
- Rete di contenuti semantici
- Contesto di origine
- Rete di sottocontenuti semantici
- base di conoscenza
- Connessioni relazionali
- Classifica iniziale
- Riclassifica
- Copertura contestuale
- Classifica di confronto
- Estrazione di fatti
Dopo aver spiegato il secondo sito web, sarà più facile comprendere questi concetti e queste frasi.
Vizem.net: da 0 a 9.000+ clic giornalieri al giorno in 6 mesi – Classifica comparativa sfruttata con copertura contestuale
Puoi vedere il grafico di Vizem.net per gli ultimi 12 mesi. Per questo progetto, a causa del Covid-19, abbiamo riscontrato molti problemi economici poiché l'investitore proviene dal settore delle palestre. Quindi, posso dire che i problemi economici hanno rallentato il progetto e hanno causato una certa latenza per i "processi di riclassificazione".
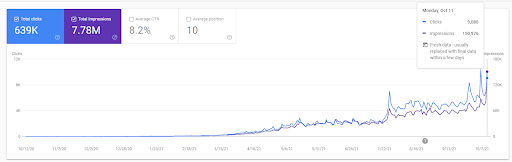
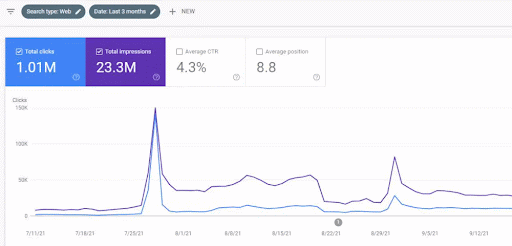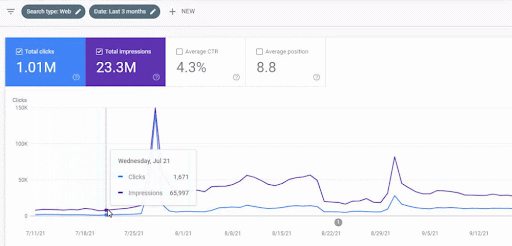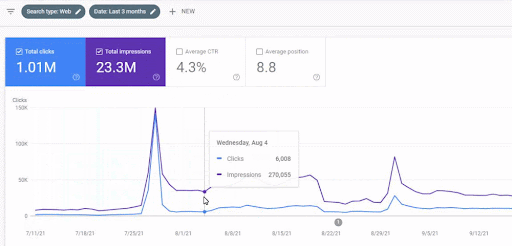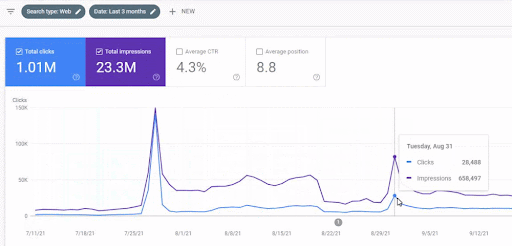
Per capire la classifica iniziale, e riclassificare un po' ulteriormente, puoi usare il grafico qui sotto.
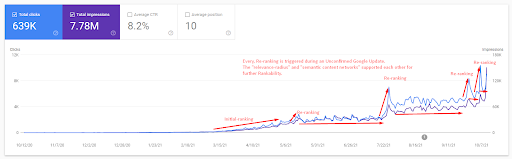
Alcune delle definizioni relative alla Classifica Iniziale e alla Riclassifica dal grafico sopra possono essere trovate di seguito.
- I grandi salti di classifica sono avvenuti durante gli aggiornamenti di Google non confermati. Alcuni test hanno fornito alcuni frammenti in primo piano e anche le persone hanno posto domande.
- Alcuni test di Google hanno rimosso i guadagni di FS e PAA.
- Ogni volta, la sequenza temporale tra due processi di riclassificazione era più breve.
- I processi di riclassificazione miglioravano ogni volta la classifica della fonte.
- La fonte ha sempre migliorato il raggio di pertinenza durante l'espansione dei cluster di query.
Come solo una nota, posso lasciare una frase qui sotto.
Se un motore di ricerca indicizza la tua pagina web, non significa che il motore di ricerca abbia capito la pagina web. L'indicizzazione avviene più velocemente della comprensione e, la maggior parte delle volte, un motore di ricerca classifica una pagina Web con previsioni, "inizialmente". Dopo l'intesa, avviene il "riclassifica". 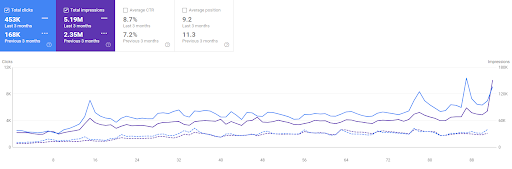
Confronto degli ultimi 3 mesi di Vizem.net
Com'è la rete di contenuti semantici di Vizem.net?
Ricordo che per molti dei miei clienti, amici o gruppi SEO segreti, durante gli incontri, ho dimostrato entrambi questi siti Web dicendo "esploderanno". E, mentre scrivo questo articolo, ti dico questo:
Guarda la rete di contenuti semantici "istanbulbogazicienstitu.com/meslek", perché esploderà. E puoi trovare un video che ho pubblicato prima di scrivere questo articolo mentre mostra i "Dati storici" di un evento stagionale e il suo effetto sui processi iniziali e di riclassificazione. Puoi vederlo sotto.
Sulla base di ciò, il Semantic Content Network di Vizem.net non è simile all'IstanbulBogazici Enstitusu, quindi, non ho utilizzato un "livello intenso di copertura topica e aumento dei dati storici", avevo bisogno di creare l'autorità relativa a determinati tipi di entità, i loro attributi e le possibili azioni dietro le query per queste coppie entità-attributo. Vizem.net non ha solo “filiali universitarie educative” o “occupazioni e corsi online” al suo interno. Ha "paesi per le domande di visto". Pertanto, la creazione di un livello sufficiente di autorità d'attualità richiede coerenza nel tempo con almeno 190 diverse reti di contenuti semantici.
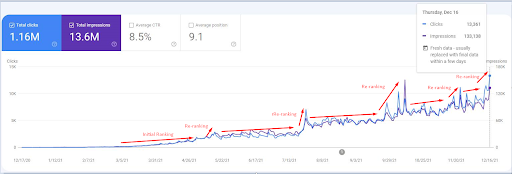
Uno screenshot del 18 dicembre 2021. Puoi vedere il continuo riposizionamento e aumento delle impressioni e dei clic. Questo è 4 settimane dopo rispetto allo screenshot precedente.
Per vedere gli eventi di riclassificazione, puoi confrontare la versione nuda del grafico delle prestazioni di ricerca organica che mostra l'effetto della SEO semantica. 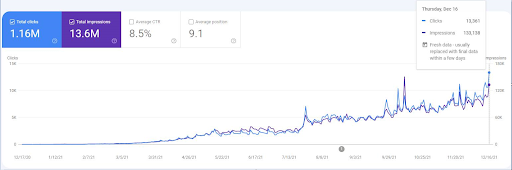
Queste 190 diverse reti di contenuti semantici sono modellate in base al "paese" stesso e i paesi sono messi al centro della mappa tematica con ogni possibile livello contestuale per migliorare la copertura dell'attività di ricerca.
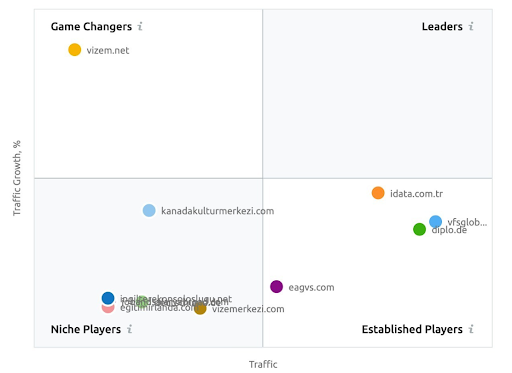
Uno screenshot di SEMRush che mostra la loro percezione per Vizem.net a differenza di altri attori del settore.
Ho anche pubblicato un altro video, solo per Vizem.net. In questo video, l'ultima situazione del sito non esiste, quindi, credo, fornisce anche un bel confronto tra oggi e quel giorno.
Infine, la pubblicazione di elementi irrilevanti all'interno di un articolo, un segmento di sito Web o una fonte irrilevanti può ridurre la rilevanza complessiva dell'entità Web per il dominio di conoscenza specifico. Vizem.net mostrerà il suo valore reale e la classifica in futuro sarà molto migliore.
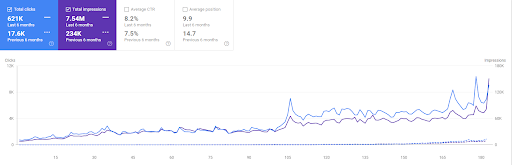
Confronto degli ultimi 6 mesi di Vizem.net.
Prima di continuare oltre, so che questo è un articolo lungo. Ma in realtà questa è una breve spiegazione di una metodologia SEO molto complessa. Le reti di contenuti semantici richiedono troppa riflessione durante la progettazione e mesi di formazione per clienti, autori e insieme all'onboarding. Pertanto, in questo articolo, voglio concentrarmi sulle definizioni dei concetti con i migliori brevi suggerimenti eseguibili possibili e importanti brevetti di Google e altri motori di ricerca, documenti di ricerca insieme ai propri concetti. Nella versione lunga (in pratica, un libro), mi sono concentrato sul “ranking iniziale” e sul “re-ranking” delle reti di contenuti semantici.
Se vuoi saperne di più, leggi "Importanza del ranking iniziale e re-ranking per SEO".
Fino ad ora, abbiamo elaborato le cose di seguito.
- Rete semantica
- base di conoscenza
- Rete di contenuti semantici
- Fiducia basata sulla conoscenza
- Copertura contestuale
- Dominio contestuale e livelli
- Rilevanza di MuM per le reti di contenuti semantici
- Contesto della fonte
Questi concetti servono a capire come funzionano le reti di contenuti semantici e come possono essere utilizzate con una mappa di attualità. Le prossime sezioni riguarderanno il modo in cui un motore di ricerca classifica le reti di contenuti semantici inizialmente e successivamente, Modifica. In questo contesto, verranno elaborate le cose di seguito.
- Classifica iniziale
- Riclassifica
- Modello di interrogazione
- Modello di documento
- Modello di intento di ricerca
- Cosa dovresti fare per sfruttare le reti di contenuti semantici
Che cos'è la classifica iniziale per SEO?
Questo è un nuovo termine e concetto per SEO, ma vecchio per i motori di ricerca. La versione lunga del "Case Study SEO focalizzato sulla rete semantica" si concentra sugli algoritmi di ranking basati su algoritmi dipendenti dalla query, dal documento, dalla fonte e da più brevetti. Gli algoritmi di Predictive Information Retrieval o di ranking predittivo cercano di ridurre il costo del calcolo. E, anche se l'indicizzazione avviene in un giorno, la comprensione di un documento può richiedere mesi o addirittura anni. Calcolare una classifica iniziale è quindi un modo per migliorare la Qualità SERP diminuendo il costo. Alcune attività relative ai motori di ricerca hanno una priorità maggiore rispetto ad altre per mantenere l'indice vivo, aggiornato e di qualità sufficientemente elevata.

Il termine ranking iniziale compare in decine di migliaia di diversi brevetti Google e documenti di ricerca perché è una prospettiva classica tra i costruttori di motori di ricerca. Quindi, sopra, puoi vedere diversi documenti di brevetto con continuazione degli stessi paragrafi e termini con piccole modifiche attorno al termine classifica iniziale.
La graduatoria iniziale rappresenta la graduatoria di un documento sulla SERP subito dopo essere stato indicizzato. La classifica iniziale di un documento rappresenta l'autorità generale e la pertinenza della fonte rispetto all'argomento specifico, al modello di query e all'intento di ricerca. Lo stesso contenuto può essere classificato in modo diverso in termini di ranking iniziale tra diverse fonti. La classifica iniziale è importante durante l'utilizzo delle reti di contenuti semantici per vedere la qualità complessiva e l'aumento dell'autorità della fonte. Ogni nuovo documento aumenta la sua posizione iniziale diminuendo il ritardo di indicizzazione se il design della rete di contenuti semantici è strutturato correttamente.
La classifica iniziale supporta il processo di riclassificazione e la sua efficienza per la fonte. E la "classificabilità di una fonte" dovrebbe essere elaborata con questi due termini, iniziale e riclassifica.
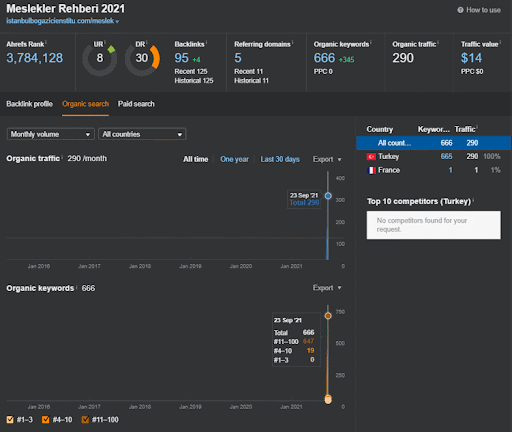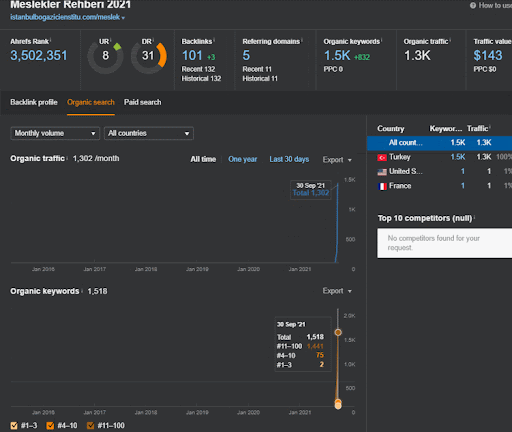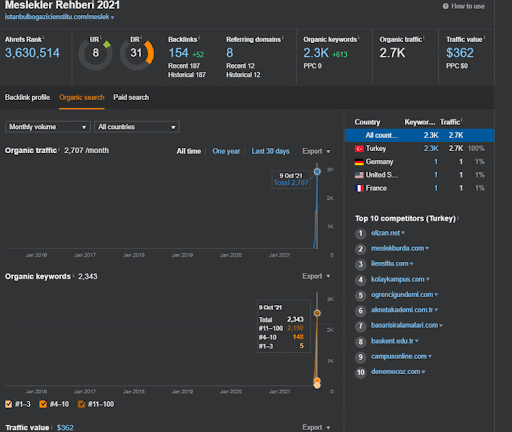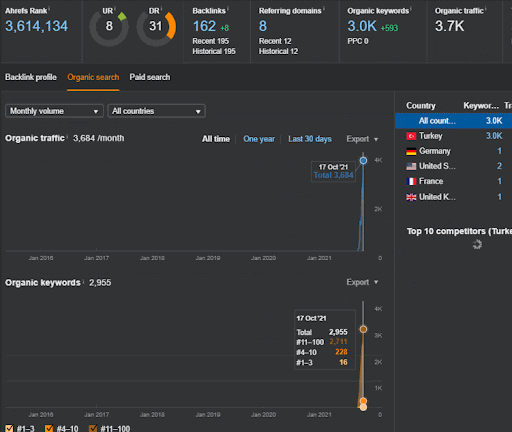
Puoi guardare i primi 20 giorni del cambiamento organico delle prestazioni della Second Content Network rispetto al Progetto I.
In questo contesto, ogni volta che Vizem.net pubblica un nuovo documento, o ogni volta che IstanbulBogazici Enstitu pubblica una nuova rete di contenuti semantici, la classifica iniziale è migliore di prima mentre il contenuto viene indicizzato più velocemente.
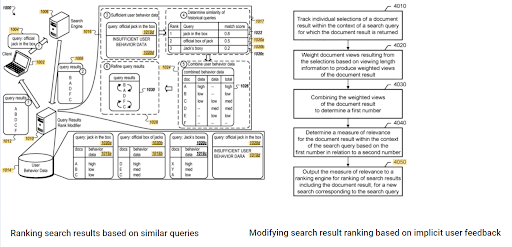
L'importanza della classifica iniziale e dei dati storici può essere vista tra questi due brevetti Google complementari. Uno è per i documenti iniziali e riclassificati in base al feedback implicito dell'utente. The other one is for doing the same if enough level of user data doesn't exist, based on the similar queries. The similar queries are also the point that relate the Semantics. Creating a Semantic Content Network will decrease the energy for reading the mind of the website owner from the search engine's point of view.
What is Re-ranking for SEO?
The re-ranking is the process of changing a document's ranking on the SERP based on the feedback of the users, or relevance, and quality evaluation algorithms. Re-ranking frequency can signal an algorithm update, or an update on the document, or a site-wide update for a source. Re-ranking is affected by the historical data which is explained in the previous SEO Case Study that focuses on the Topical Authority. Examining the re-ranking processes and the feedback from the search engines help for the configuration of the semantic content network design. Re-ranking timelines can be shortened with the help of the actual traffic, as well as with historical data if the contextual and topical coverage is improved.
The re-ranking processes are affected by the initial ranking and the quality of the neighborhood content. The neighborhood content will affect the ranking of any strongly connected components. Re-ranking processes can signal the weak spots, and the ability of the search engine to understand certain sections of the semantic content network. If the design is correctly created, the semantic content network will continue to rise and rise in terms of organic search performance over time, and any Google Updates will confirm these processes.
Below, you can see the comparison of the Semantic Content Network 1 and Semantic Content Network 2 of the IstanbulBogazici Enstitu in terms of the initial and re-ranking. 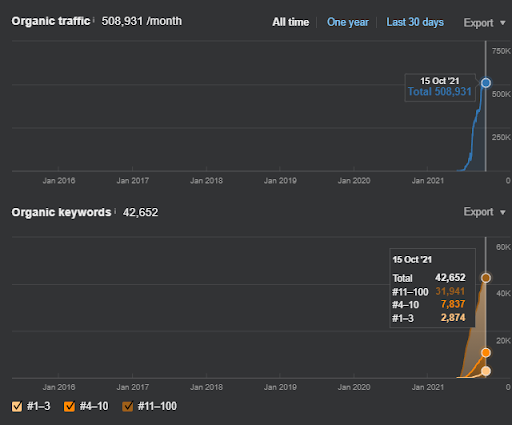
15 October 2021, performance of the first semantic content network of the IstanbulBogaziciEnstitusu which is the 124th day of the launch. 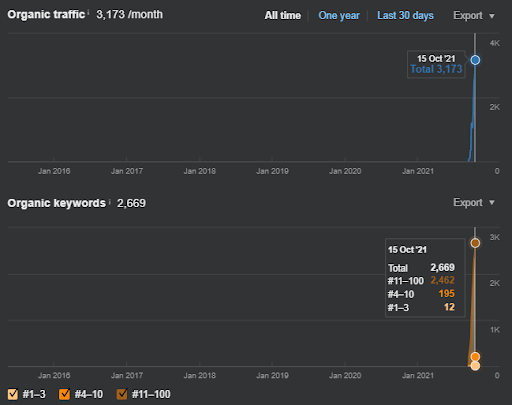
15 October 2021, performance of the Second Semantic Content Network of IstanbulBogazici Enstitu which is the 19th day of the launch. 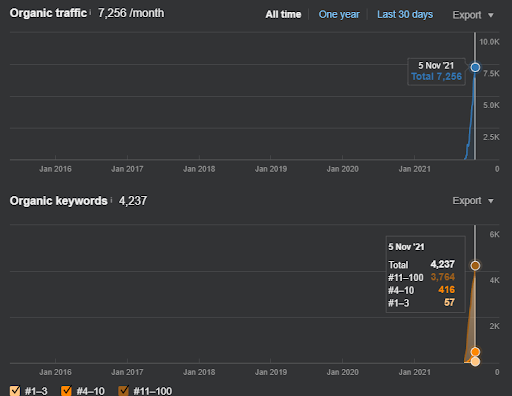
As you see, the second content network increases the organic query count and the rankings much faster than the first one. The Semantic Content Network 1 has the benefit of the “seasonal SEO” which gives enough level of historical data in a positive way. If there is a seasonal SEO event, the search engine will re-rank the pages, and assign the new relevance-radius and search activity coverage scores to the documents and the sources. Thus, I have chosen to use a “sudden launch” for the “university branches” first. It was the first step of the Topical Authority Building which is equal to the “historical data * topical coverage”. 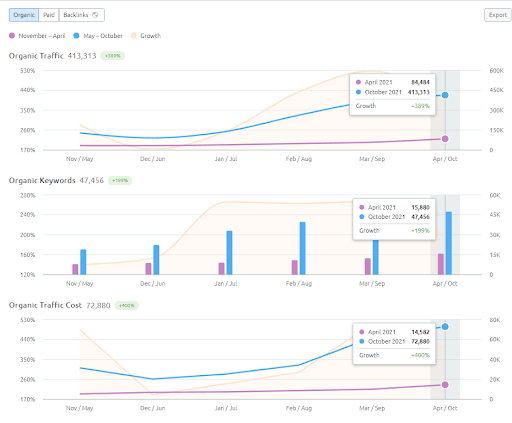
The 6 Months of Growth Comparison of the IstanbulBogazici Enstitu from SEMRush.
Note: To compensate for weaknesses in the execution, I designed a Semantic Content Network 3 to unite the first two using conceptual connections by providing the source's context. If I launched it, you would see that the source would acquire more than 1,2M organic traffic based on the Ahrefs graphic, in reality, it can be more than 2M. You can see my prediction's validity from the performance of the Second Content Network. Whenever you check it, you will see that it has thousands of new queries with higher rankings.
In the first Semantic Content Network, the first 3 ranking queries appeared after 2 months' for the second one, they appeared on the 15th day. You can imagine the increase in authority. Since the knowledge base of the website is left partially incomplete, after the source loses its momentum for semantic network completion, the search engine can prioritize other sources, and it can decrease the re-ranking positivity along with the relevance-radius and Rankability.
Implementing Semantic Networks on these sites makes use of a few concepts and “templates” used by search engines. Before I tell you about the method for setting up a Semantic Network, you should also understand what these templates are and how they work. This will help you understand how search patterns and document structure impact ranking, and therefore why the method I used in this case study is so effective.

The Initial Ranking, and Re-ranking are two different ranking algorithm types for a search engine based on timing. Search engines have other types of ranking algorithms such as query-dependent, query-independent, content-based, link-based, usage-based. To be able to understand the ranking systems, and clustering-associating technology of the search engines, the query-document-intent templates, and their relation to each other should be understood.
Scansione dati³
 Scopri di più
Scopri di piùWhat is a query template?
A query template represents a search pattern with ordered phrases that cover an entity for seeking factual information. A query template can have a question format, a proposition format, or an order of word types such as one adjective and one noun. A query template is useful for generating seed and synthetic queries from the point of view of a search engine. A seed query can help a search engine to choose centroids for the query clusters while helping the clustering web page documents, their types, and possible search activities for them. 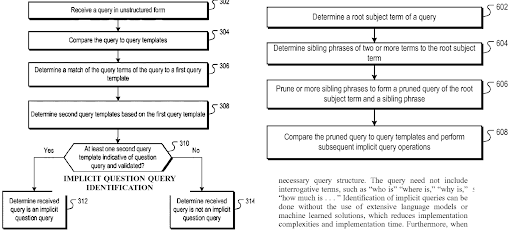
Another Google Patent about “Implicit Question Query Identification” which Nitin Gupta invented along with Steven Baker. “Implicit Question Query Identification” is also related to the question generation which is connected to the “K2Q System”.
In this context, a query template can be used for feeding the search engines' historical data for creating trust. Even if a search engine doesn't understand all aspects of a query, or a document for it, still some certain sources can be ranked earlier and better than others because of the document templates. If a source satisfies queries from a template, the search engine will rank the specific source for these types of queries from the same template better initially and during the re-ranking processes. Thus, on the web, we have sources that only focus on a single vertical with a single query template, like Wikihow, or GiftIdeas. 
“Query Suggestion Templates” is one of the documents that explains how a search engine can generate query templates based on query logs. Since, Nitin Gupta is one of the inventors of this patent, it has more value for me.
A query template can be used for creating a successful semantic content network, but in page contextual domains, and connections should be configured properly for connecting multiple semantic content networks for multiple query templates.
Note: The topic Query Templates, Intent Templates and the Document Templates are closely related, and another SEO Case Study will be published to demonstrate further details about it. 
A section from the Representation Learning for Information Extraction
from Form-like Documents of Google for extracting information from templatic content.
What is a document template?
A document template can signal the purpose of a web page based on the design elements, or even the request size, count and types. If a web page has too much JS, it can be a js-dependent website, or the interactivity needs can be higher than others. This can be confirmed easily by just checking the event-listeners on the web page, or input types, and API endpoints. When it comes to thinking like a search engine, remember that the web is a chaotic place. And, everything possible for understanding the users, especially if the users are Markovian , meaning that they are more influenced by the current page than their history of navigation. 
A section that explains how a search engine can use the document templates to see a user's interest area.
Did you know that Prabhakar Raghavan, the VP of Search on Google, also has a research that asks the same question? “Are Web Users Markovian?”. 
A section from the “Are web users Markovian?” research paper.
Sì. Il ranking probabilistico e il ranking di rilevanza degradata sono le colonne principali di un motore di ricerca semantico per comprendere gli utenti e creare la SERP della migliore qualità possibile preparata per gli stati di possibilità. 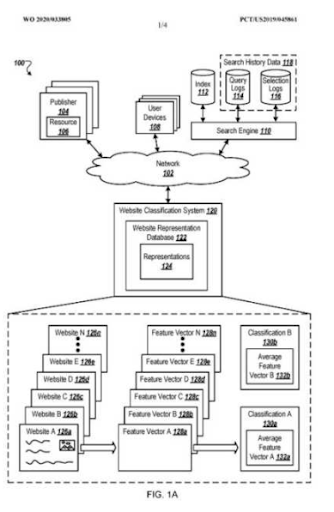
In precedenza, per rendere "il design del sito Web, l'aspetto o la tonalità" un argomento a favore dell'apprendimento della rappresentazione per i siti Web, Bill Slawski ha scritto i "Vettori di rappresentazione del sito Web".
Che cos'è un modello di intento di ricerca?
Un modello di intento di ricerca può essere rappresentato dalla necessità alla base del modello di query. Un modello di documento di query può essere unito in base a un modello di intento. Avere un modello di intento di ricerca con una possibile comprensione della "classifica di pertinenza degradata" e della "classifica probabilistica" aiuterà a creare la migliore attività di ricerca possibile e la copertura dell'intento di ricerca con l'ordine corretto. Durante la creazione di una rete di contenuti semantici, la cosa più importante è adattare il modello document-query-intent in base al contesto della fonte per completare una rete semantica basata su un dominio di conoscenza migliorando la copertura contestuale per migliorare la fiducia basata sulla conoscenza e l'autorità di attualità . 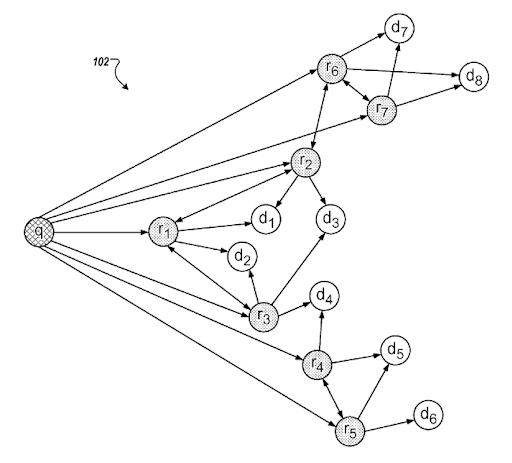
Una sezione di "Perfezionamenti delle query basati sull'intento dedotto" di Google. Funziona tramite cluster di query e modelli di intenti con connessioni semantiche. Puoi sperimentarlo su diversi livelli di tassonomia delle frasi.
Prima di passare ad alcuni esempi concreti e suggerimenti per aiutarti a creare una migliore rete di contenuti semantici, devo dirti che anche la versione semplice di questo Case Study SEO richiede un alto livello di comprensione dei motori di ricerca e capacità di comunicazione. Quindi, anche se sento di fornire informazioni di alto livello, so che il corso Semantic SEO che creerò ti mostrerà alcuni esempi concreti in più e meglio. 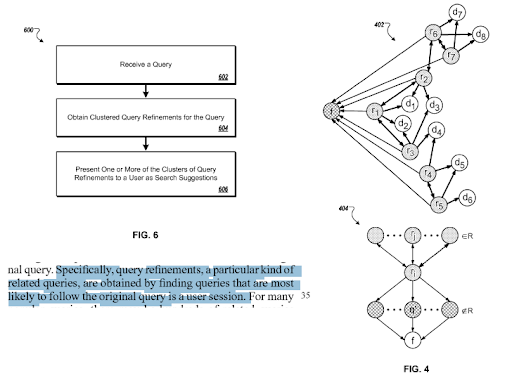
Lo stesso brevetto spiega le corrette connessioni tra diversi "percorsi di query" e "spostamenti di contesto".
Cosa dovresti sapere sull'utilizzo delle reti di contenuti semantici?
Per creare una rete di contenuti semantici, a volte anche un semplice riassunto del contenuto semantico e la progettazione possono richiedere un'ora, se si inseriscono tutti i dettagli rilevanti basati sulla semantica lessicale o sui tipi di relazione tra entità e frasi. Utilizzando più angolazioni contemporaneamente, come l'indicizzazione basata su frasi e i vettori di parole, o vettori di contesto per calcolare la rilevanza contestuale di un contenuto in generale rispetto a un dominio contestuale, o la sua rilevanza in base ai singoli tipi di contenuto secondario, richiede un alto livello di comprensione dei motori di ricerca semantica.
Quindi, l'uso di una metodologia generativa renderà tutto più semplice con i concetti che ti ho spiegato sopra, perché anche se prepari perfettamente ogni parte della rete di contenuti semantici, gli autori e gli scrittori non saranno in grado di scriverla, o i gestori dei contenuti non sarà in grado di seguire la tua visione. Pertanto, potrebbe stancarti per niente e farti lasciare un progetto come ho fatto per alcuni di questi progetti di case study SEO dopo aver dimostrato il concetto in un modo sufficientemente vivace e verificabile.
I suggerimenti di seguito saranno solo per semplici eseguibili e brevi passaggi che ti aiuteranno.
1. Non utilizzare collegamenti fissi nella barra laterale da tutte le reti di rete di contenuti semantici
Ogni collegamento dovrebbe avere una descrizione della connessione tra due documenti ipertestuali come ogni parola all'interno di una pagina web. L'utilizzo dell'HTML semantico può aiutare a specificare la posizione e la funzione di un documento su una pagina web, aiutando i motori di ricerca a ponderare le sezioni in modo diverso in termini di contesto.
Nell'esempio Vizem.net, non ho utilizzato lo stesso design della barra laterale. La barra laterale non mostrava gli ultimi post o quelli più critici. Le barre laterali mostrano solo gli attributi delle entità centrali e non sono fisse, sono dinamiche. In altre parole, in base alla gerarchia all'interno della mappa topica, le reti di rete di contenuti semantici cambiano anche se si trovano nella barra laterale. 
Pensare ai modelli Reasonable Surfer e Cautious Surfer può aiutare un SEO a creare una migliore rilevanza tra diversi documenti ipertestuali.
Inoltre, il collegamento scorre in termini di importanza e la popolarità dovrebbe seguire il contesto della fonte dalle migliori connessioni possibili. Di seguito, puoi vedere le sezioni della barra laterale con i codici HTML semantici modificati. 
In base alla gerarchia dell'articolo attivo nella sessione dell'utente, le schede, l'ordine delle schede, i collegamenti all'interno delle schede cambieranno. L'esempio sopra è tratto dalla gerarchia breadcrumb sottostante. ![]()
2. Supporta le reti di contenuti semantici con PageRank
Anche se il PageRank esterno non è d'obbligo dalle fonti esterne, se sei in grado di usarlo, ti renderai conto che la classifica iniziale e il re-ranking saranno migliori. Per entrambi questi progetti non li ho usati, ma questa volta non era lo scopo. Per Vizem.net, c'erano problemi economici e non volevo spendere il budget in PR digitali e sensibilizzazione. Per Istanbul BogaziciEnstitusu, ho organizzato un paio di "fonti interconnesse a livello locale" per supportare l'autenticità della fonte per l'argomento specifico, ma ancora una volta l'azienda non è stata in grado di implementarlo a causa di problemi di budget e di disciplina organizzativa. 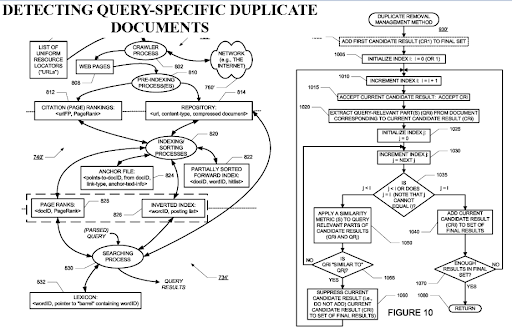
Il rilevamento di documenti duplicati specifici della query è una prospettiva importante dai motori di ricerca, perché il PageRank può aiutare un documento a essere filtrato come prezioso anche se è duplicato. Poiché le reti di contenuto semantico altamente organizzate possono essere simili tra loro, il flusso di PageRank e i dati storici sono utili.
Quando si tratta di scegliere il punto di flusso PageRank esterno per questi tipi di reti di contenuti semantici, utilizzare le fonti con i dati storici. Nel mio caso, avevo organizzato questi endpoint PageRank in precedenza, prima di lanciare e pubblicare la prima rete di contenuti semantici. In questo modo ho potuto prendere riferimenti esterni da concorrenti diretti, ma quando ho pubblicato la rete di contenuti semantici, i concorrenti hanno smesso di collegare la fonte perché hanno visto l'aumento di massa della fonte come concorrente.
Questa situazione ci porta al terzo suggerimento. Se potessimo utilizzare il flusso di PageRank da riferimenti esterni, il processo di riclassificazione sarebbe più veloce e la classifica iniziale sarebbe più alta.
3. Usa testi di ancoraggio diversi da piè di pagina, intestazione e contenuto principale per le parti di rete di contenuti semantici di spicco
I testi di ancoraggio o il “testo di collegamento” dal punto di vista del motore di ricerca segnalano la rilevanza di un documento ipertestuale per un altro. Secondo il documento originale del PageRank, il conteggio dei link è proporzionale al flusso del PageRank. Ma in seguito Google lo ha modificato per prevenire il "link stuffing" e ha limitato i collegamenti che possono effettivamente superare il PageRank. Sulla base di ciò, vengono sviluppati i modelli TrustRank, Cautious Surfer, Hilltop Algorithm o Reasonable Surfer. 
Questi sono due collegamenti alle due diverse reti di contenuti semantici per il BogaziciEnstitusu, ma dal momento che non ho implementato SEO tecnico o miglioramenti UX, puoi renderti conto della "economicità" dei design dei pulsanti.
Secondo Google, lo stesso link non può passare il PageRank una seconda volta a un'altra pagina web, mentre il PageRank verrà passato solo dal primo link. E, nella forma originale dell'algoritmo PageRank, un documento ipertestuale può collegarsi per migliorare il suo PageRank, oppure è possibile utilizzare reindirizzamenti 301 per prendere il PageRank del documento di destinazione del collegamento. Entrambe queste situazioni hanno creato vecchie tecniche di Black Hat come reindirizzare temporaneamente una pagina Web a un'altra solo per prendere il suo PageRank. Questo risale ai giorni in cui i SEO potevano vedere il PageRank di una pagina web da Google Search Console o dalla SERP. Successivamente, Google ha iniziato a smorzare il PageRank con ogni reindirizzamento mentre Danny Sullivan ha spiegato che 301 reindirizzamenti supereranno completamente il PageRank. Oltre a tutte queste modifiche, la cosa importante qui è che anche se il secondo link non supera il PageRank, passa comunque la rilevanza del testo del link. 
Sezioni di spicco della Semantic Content Network sono state collegate dalla HomePage sulla base dei "perfezionamenti delle query intermedie" che includono i "verbi, predicati" o "attività del ricercatore".
Pertanto, le sezioni prominenti della Semantic Content Network dovrebbero essere collegate dal menu di intestazione e piè di pagina con le sezioni di tassonomia superiore e i testi dei collegamenti dovrebbero essere diversi l'uno dall'altro. In questi esempi, ho utilizzato i collegamenti di intestazione con i testi dei collegamenti prominenti ma brevi mentre ho mantenuto gli esempi a piè di pagina più a lungo. 
Una sezione dell'"Indicizzazione dei tag di ancoraggio in un sistema web crawler", riassume l'importanza di un testo di ancoraggio e di un testo di annotazione per posizionare una pagina Web all'interno dei cluster di query e dei cluster di pagine Web.
Se la sezione Semantic Content Network è troppo prominente, per superare correttamente il PageRank e la priorità di scansione, ho collegato le sezioni più importanti con testi di collegamento appropriati e paragrafi esplicativi che includono gli attributi prominenti con diverse variazioni di N-Gram rilevanti. 
Questa è la seconda area collegata dalla homepage di Vizem.net, si trova dietro una fisarmonica, si concentra sui paesi all'interno delle query e collega la sezione centrale della rete di contenuti semantici.
Nota: Intorno ai testi di ancoraggio, è sempre stato utilizzato un "testo di annotazione" pianificato per migliorare la precisione dello scopo del collegamento.
4. Limitare la restrizione al conteggio dei collegamenti e far corrispondere i collegamenti desktop e mobili e il contenuto principale
Entrambi i progetti sono limitati ad avere meno di 150 collegamenti interni per pagina web. Con l'aiuto dell'HTML semantico, i luoghi dei collegamenti e le funzioni dei collegamenti vengono chiariti ai crawler. L'IstanbulBogazici Enstitusu aveva più di 450 collegamenti per pagina web, e alcuni di questi erano collegamenti automatici (un collegamento dalla stessa pagina alla stessa pagina). La parte peggiore è che metà di questi collegamenti non esisteva all'interno della versione mobile del contenuto. 
Punteggio mantenimento URL, Punteggio scansione e altri tipi di punteggi possono essere utilizzati per determinare l'importanza di un collegamento all'interno della mappa URL interna e i tag di identificazione del documento all'interno dei diversi livelli possono essere utilizzati per ordinare l'indice in base a punteggi di pertinenza indipendenti dalla query.
Poiché Google utilizza l'indicizzazione solo per dispositivi mobili, se il contenuto non esiste nella versione mobile, verrà ignorato e non utilizzato a fini di valutazione della pertinenza e posizionamento. Pertanto, il contenuto mobile e desktop è stato configurato per essere abbinato tra loro. Anche se Google tollera le discrepanze di contenuto tra le versioni desktop e mobile, rende comunque più difficile la comprensione e il posizionamento di una pagina Web per i motori di ricerca. 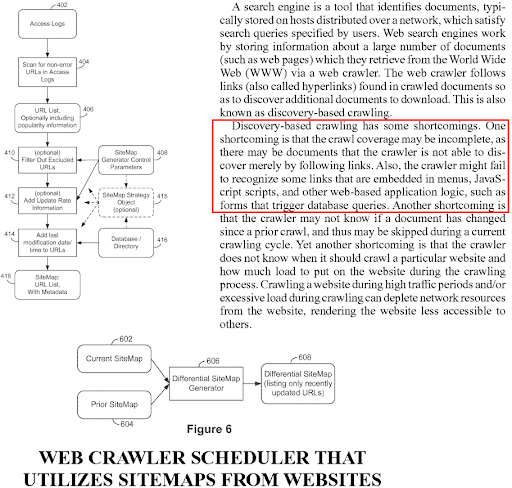
Un motore di ricerca può generare una mappa del sito per il sito Web e questa mappa del sito può essere rigenerata in un ciclo, se i collegamenti e i metadati dell'URL non corrispondono tra gli user-agent o le timeline. Pertanto, è importante mantenere il percorso di scansione breve, la coda di scansione breve e i collegamenti interni coerenti.
Insieme ai collegamenti tra le diverse pagine web, vengono utilizzati anche i collegamenti alle sottosezioni delle pagine web con la “tabella dei contenuti” e i “frammenti di URL”. Questi frammenti di URL prendono di mira una sottosezione specifica della pagina web nominandola correttamente e la sezione specifica è stata inserita in un tag di sezione con un h2. Con l'aiuto dei frammenti di URL con i "link di navigazione in-page", è stato più facile far arrivare un utente dalla SERP alla sezione specifica della pagina web, mentre le sezioni inferiori del contenuto sono state rese più prominenti per soddisfare l'esigenza alla base del interrogazione.
5. Avere una disciplina di livello militare per i tuoi progetti SEO
Questo è completamente un altro argomento e un altro articolo può essere scritto per definire cosa significa la disciplina a livello militare o perché è utile per un progetto SEO. Ma devo dirti che durante questi ultimi 2 mesi ho formato molti CEO e SEO di altre agenzie insieme ai loro team per vedere se il design del mio corso funzionerà bene o meno.
Ogni volta che vedo il successo e un alto livello di attaccamento per le sessioni educative che svolgo, c'è una forte volontà e perseveranza. Il problema principale è che la SEO semantica è molto più difficile degli altri SEO verticali. La SEO tecnica è universale e ha persino scritto guide per ogni passaggio. Il SEO OnPage, o WUX e Layout Design può essere tracciato con misurazioni numeriche. Quando si parla di semantica, è la pratica di unire la prospettiva di una macchina che funziona sulla base di un complesso sistema adattivo con l'homo-sapiens che non capisce come funziona la macchina.
Questa distinzione richiede una base concreta che dovrebbe essere messa fin dal primo giorno del progetto. La maggior parte delle volte, utilizzo le regole seguenti.
- Il design dei contenuti e la rete di contenuti semantici non devono essere logici per un autore o uno scrittore.
- Il compito del gestore dei contenuti è verificare la compatibilità del contenuto con la progettazione del contenuto.
- Il compito dell'autore è scrivere il contenuto con le relative informazioni che includono un alto livello di accuratezza e dettaglio.
- I collegamenti, le definizioni, le prove, i confronti, le proposizioni, i riferimenti dovrebbero essere fatti con esempi concreti, non con lanugine.
- Ogni parola non necessaria è una diluizione per il contesto e il concetto.
Quando leggi, potrebbe sembrare facile da implementare, ma non è così facile. Quindi, posso dire che stavo persino per licenziare alcuni dei miei stessi dipendenti. Sono contento di non averlo fatto, almeno per ora. In condizioni normali, ci saranno molte domande che ti verranno poste, se il proprietario della domanda non è un SEO o proprietario dell'azienda, non rispondere. Risparmia energia nell'archiviazione dei dati del motore di ricerca che memorizzerà il tuo feedback positivo, non il feedback ridondante e irrilevante per le classifiche.
6. Espandere la sorgente con rilevanza contestuale
Questa sezione riguarda totalmente la comprensione della necessità di Google di creare il MuM. Quando si progetta una mappa tematica, includerà molte reti di contenuti semantici che forniranno una base di conoscenza migliore a livello di sito. Pertanto, durante la pubblicazione di queste sottosezioni, dovrebbero essere in grado di connettersi al contesto della fonte, oppure possono cambiare il modo in cui il motore di ricerca vede la fonte e il tema del sito Web può passare a un altro dominio di conoscenza. Ad esempio, collegare le cose attorno a concetti e aree di interesse con possibili azioni richiede la comprensione delle connessioni tra significati complicati. Rendere chiare queste connessioni a un utente, uno scrittore e anche una macchina allo stesso tempo è il processo di creazione della rete di contenuti semantici. 
A tal fine, ogni nuova sezione del sito web dovrebbe poter essere collegata alla sezione centrale della mappa tematica. Questi bridge contestuali possono essere visti dal design e dalla spiegazione di LaMDA di Google.
Incontro molte domande come "dovrei scrivere su un altro argomento", "se ho due nicchie diverse, mi danneggerà?". Se colleghi tutte queste sottosezioni, segmenti di siti Web come componenti fortemente connessi, queste reti di contenuti semantici si sosterranno a vicenda per un migliore posizionamento invece di dividere l'identità del marchio e l'autorità di attualità per due argomenti diversi e irrilevanti.
7. Crea traffico effettivo e verifica con la segmentazione personalizzata di Google Analytics
Il traffico effettivo è connesso al RankMerge nello stesso modo in cui il Trust basato sulla conoscenza è connesso al PageRank. Presto, sto pensando di scrivere un altro articolo dal titolo “Quando il PageRank mente…” per spiegare perché il motore di ricerca cerca di influenzare il PageRank con segnali laterali. In effetti, PageRank non è un segnale definitivo che mostri l'autorità, la competenza e l'affidabilità di una fonte. Può essere un segnale per la classifica e un fattore, ma non ci si può fidare da solo. RankMerge è il processo di unire il traffico del sito Web e il PageRank in modo che il sito Web possa avere un senso per il motore di ricerca. PageRank alto e basso traffico possono segnalare il "traffico impopolare" o la "manipolazione del PageRank".
Quindi, per migliorare i dati storici della fonte, ho utilizzato gli Eventi SEO stagionali, e ho aumentato le query “marchio + termine generico”. Il traffico diretto e le pagine Web contrassegnate da segnalibri aumentano con il traffico effettivo e autentico.
Questi tipi di dati aiutano un motore di ricerca a fidarsi di esso per posizionarlo sempre più in alto sulla SERP.
Per essere in grado di controllare questo traffico effettivo che proviene dalla rete di contenuti semantici, un SEO può creare un segmento personalizzato da Google Analytics per vedere come arriva come traffico diretto. Inoltre, è possibile creare obiettivi personalizzati come la creazione di un possibile viaggio di ricerca dalla prima rete di contenuti semantici alla seconda rete di contenuti. Questa è la prova del concetto che la rete semantica è costruita attorno agli interessi, ai concetti e alle possibili azioni relative alla ricerca.
Di seguito troverai solo un esempio per quello delle pagine web che vengono inserite all'interno del primo Semantic Content Network per dimostrare il traffico diretto acquisito tramite traffico organico. 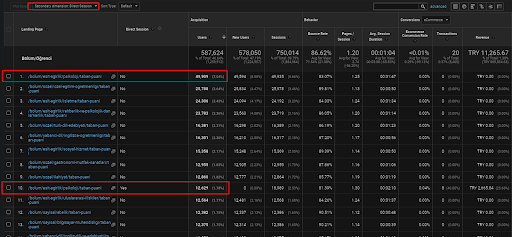
Negli ultimi 3 mesi solo una pagina web della prima rete di contenuti semantici è stata utilizzata dai 49.000 utenti organici. Inoltre, 12.900 utenti in più sono arrivati come traffico diretto acquisito per la prima volta dalla ricerca organica. Inoltre, le metriche di sessione/pagina e la durata media della sessione sono più elevate per questi segmenti di utenti.
Come detto prima, un motore di ricerca può raggruppare query, documenti, intenti, concetti, interessi, azioni, ma può anche raggruppare utenti. Se un gruppo di utenti lascia feedback positivi mentre crea un valore del marchio aggiungendo queste pagine Web ai segnalibri, digitando direttamente la barra degli indirizzi e cercando i termini generici insieme al nome del marchio, mostra che la fonte migliora la sua autorità e il motore di ricerca è in grado di riconoscere tutto dalla SERP, da Chrome e dai propri indirizzi DNS. 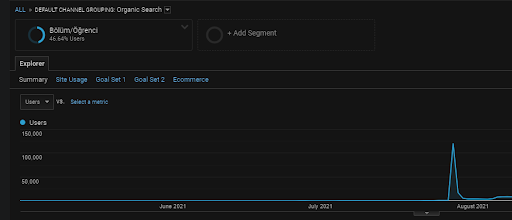
Sopra, puoi vedere il segmento utente della prima rete di contenuti. È possibile creare un segmento utente per ogni rete di contenuti semantici con obiettivi personalizzati e aggiungere segmenti di utenti secondari anche per le reti di contenuti secondari semantici.
8. Supporta le reti di contenuti semantici con sottosezioni basate sulle attività di ricerca
Questa sezione riguarda anche la risoluzione degli attributi dell'entità e l'analisi che è un altro argomento. Ma, in poche parole, alcuni attributi di queste entità basati su domini contestuali dovrebbero essere inseriti in una gerarchia inferiore, non nella gerarchia superiore. In questo caso, il “Vizem.net” può fare un esempio migliore, mentre per il Bogazici Enstitusu, lo si può dimostrare con “Salari delle Occupazioni” e “Punti Esame delle Università”. Questi due attributi importanti sono stati inseriti in base ai modelli di query e di documento nelle reti semantiche di sotto-contenuto. 
L'identificazione delle unità semantiche dall'interno di una query di ricerca è un altro brevetto di Google che divide le frasi in diverse categorie semantiche e aggrega la rilevanza di un documento in base alla sua vicinanza a tutte le variazioni della query.
In un precedente Case Study SEO non ho seguito questo tipo di struttura, ho creato un crawl path basato sulla “cronologia” e sui link interni strettamente limitati. In questi articoli l'importo del link interno inserito nel contenuto principale è maggiore del precedente.
9. Usa parole tematiche all'interno degli URL
Se Google incontra due URL diversi con lo stesso contenuto senza alcun segnale di canonizzazione, sceglie quello corto come quello canonico. Perché gli URL brevi sono più facili da analizzare, risolvere e richiedere. Quando hai trilioni di pagine web che aggiorni miliardi di volte ogni giorno, anche le lettere negli URL possono mostrare il "bilanciamento costo/qualità" di un sito web. Come ho detto prima, il "costo del recupero" dovrebbe essere inferiore al "costo del non recupero". Se vuoi essere compreso da un motore di ricerca, dovresti inserire i "segnali di contesto ordinati e complementari" a tutti i livelli, inclusi gli URL. 
Una sezione della classifica "basata sull'evidenza" tramite aggregazione di prove. Spiega come una risposta può essere abbinata a una domanda.
In questo contesto, la maggior parte delle volte, utilizzo una sola parola all'interno dell'URL. Questi possono riflettere la gerarchia e la struttura della rete di contenuti semantici. Alcuni pensano ancora che il "numero di livelli" all'interno dell'URL influisca sulla frequenza di scansione, prima del 2019 era vero. Ma, fintanto che il contenuto ha un senso e soddisfa gli utenti da un argomento popolare o importante, non sarà influenzato da una situazione del genere.
Per dimostrarlo, puoi seguire l'esempio seguente.
- Root-domain/semantic-content-network-1/type-1/sub-content-network-part-for-type-1
- Root-domain/semantic-content-network-2/type-2/sub-content-network-part-for-type-2
Queste due reti di contenuto semantico possono collegarsi a vicenda dalla stessa gerarchia e possono collegarsi anche in base alla rilevanza. Ci sono altre cose di cui possiamo parlare qui, come "Entity Grouper Contents - Hub Type Content", ma l'argomento di un altro giorno.
Nota: anche la terza rete di contenuti semantica pianificata può essere elaborata come una "rete di contenuti di raggruppamento concettuale". E, se viene pubblicato, con l'effetto della Second Semantic Content Network, il traffico organico complessivo può superare i 3 milioni di sessioni al mese.
10. Comprendi la differenza tra nidificazione e connessione
Come differenza metodologica pratica, la connessione è la connessione di cose simili tra loro sulla base di un dominio contestuale, mentre la nidificazione sta raggruppando il contenuto simile con lo stesso scopo insieme. Questo raggruppamento aiuterà un motore di ricerca a trovare contenuti simili tra loro più velocemente e creare un punteggio di qualità della fonte per questi gruppi, oppure questi contenuti nidificati basati su una rete semantica saranno più facili. 
Immagina che ci siano due diversi percorsi di scansione come di seguito.
- Percorso di scansione 1: incontra gli URL in modo casuale, senza modello, somiglianza e rilevanza contestuale.
- Percorso di scansione 2: incontra URL che hanno un senso anche dall'URL stesso, con un modello, un alto livello di somiglianza e pertinenza basato sul contesto.
Se anche dal percorso di scansione il contenuto ha un senso, il "ranking iniziale" e il "re-ranking" saranno migliori grazie all'"innesco del re-ranking basato sulla comprensione della copertura del motore di ricerca".
Nota: l'uso corretto dei collegamenti interni con la tassonomia delle frasi è importante per l'annidamento e la connessione.
Questo ci porta brevemente alle ultime due pratiche metodologie condivise. E questa sezione è ancora una volta correlata all'alto livello di disciplina e alla sufficienza organizzativa. 
Un brevetto di Trystan Upstill e Steven D. Baker per aver riconosciuto i termini che si verificano insieme negli elenchi HTML. L'importanza di questo brevetto è che mostra il valore di un singolo elenco HTML per determinare gli elenchi di termini coesistenti per un argomento o una parte della tassonomia delle frasi.
11. Capire quando pubblicare una rete di contenuti semantici con una frequenza adeguata
Questo è stato spiegato in precedenza, ma in uno di questi progetti di case study SEO, ho pubblicato quasi 400 contenuti in un giorno. Per quanto riguarda l'altro, ho iniziato a pubblicare solo 10-15 contenuti all'improvviso, poi ho aumentato la velocità nel tempo con una costanza fino all'inizio dei problemi economici legati al Covid.
Se una nuova fonte crea una nuova rete di contenuti semantici, pubblicarla il primo giorno potrebbe essere un po' più difficile di quanto pensi, controllare tutti i collegamenti interni, le grammatiche e le informazioni sulla pagina web non è così facile. Ma, se tutto il contenuto proviene solo da un singolo argomento e da un modello di query e se la fonte non ha alcuna cronologia su quell'argomento, la pubblicazione della maggior parte della rete di contenuti semantici presenta vantaggi come indicizzazione, comprensione e riclassificazione.
Nella mia situazione c'è stato anche un evento storico con stagionalità. Quindi, il mio scopo era avere un livello di posizione media sufficiente fino a quando non sarò in grado di essere testato dal motore di ricerca per le entità specifiche e le attività di ricerca rispetto alle fonti precedenti. Così, ho pubblicato il primo Semantic Content Network con un alto livello di preparazione prima dei 45 giorni dall'evento stagionale.
Quindi, puoi vedere come il motore di ricerca ha testato ripetutamente la fonte come di seguito. 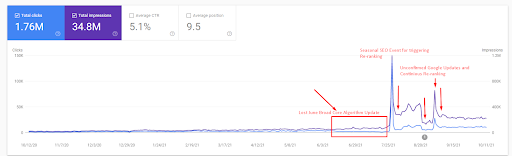
Una spiegazione più dettagliata può essere trovata di seguito. 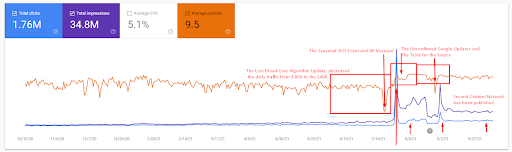
Di seguito è possibile trovare un rapido controllo dei fatti per la spiegazione dello screenshot sopra.
- L'aggiornamento dell'algoritmo Broad Core ha ridotto il traffico del sito Web di oltre il 200%.
- Il sito web ha anche perso più di 15.000 query.
- Ciò ha influito sull'indicizzazione complessiva della fonte per la nuova rete di contenuti semantici, poiché nel dettagliato articolo SEO Case Study è stato spiegato meglio.
- Grazie all'Evento SEO stagionale, il re-ranking è avvenuto prima, e dopo l'Evento SEO stagionale, il motore di ricerca ha normalizzato il ranking della sorgente in base al traffico effettivo durante gli aggiornamenti non confermati.
- Le query e le classifiche che si acquisiscono grazie al Primo Semantic Content Network e all'Evento Stagionale sono state protette e ulteriormente migliorate.
- Il primo Semantic Content Network supportava anche il nuovo e il secondo Semantic Content Network.
La perdita di query e la perdita media di ranking possono essere viste anche da Ahrefs come di seguito. Puoi controllare l'effetto di Google Broad Core Algorithm Update (GBCAU) di giugno 2021 insieme all'effetto dell'aggiornamento non confermato. 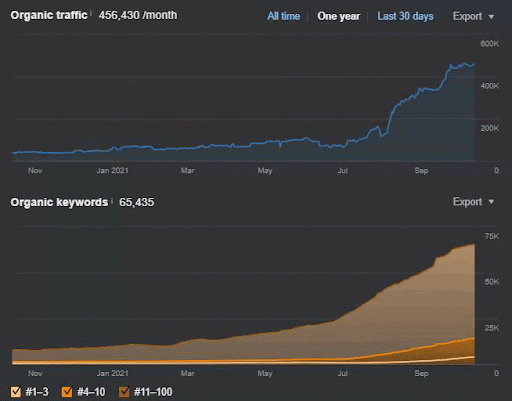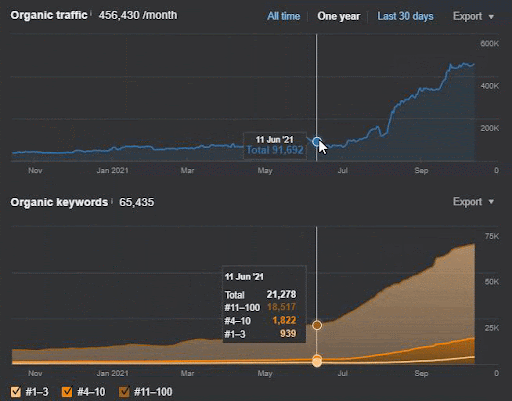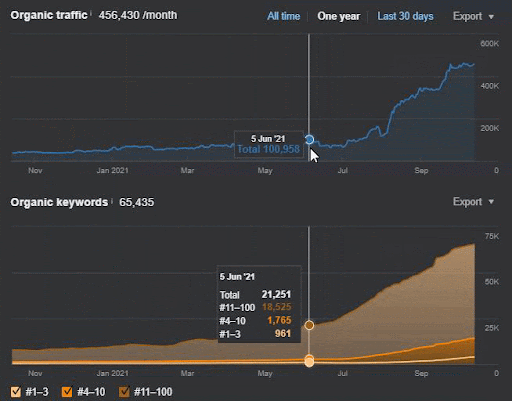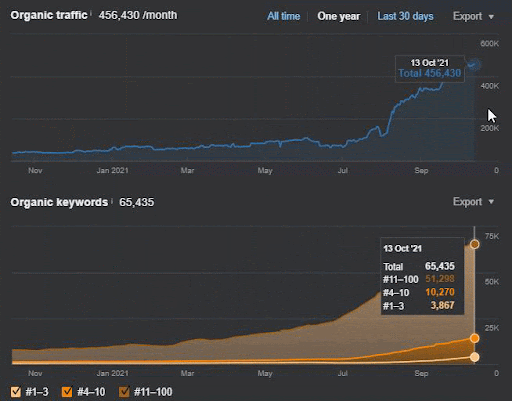
Pertanto, l'utilizzo di una rete di contenuti semantici con più strategie possibili è una necessità. Anche se il GCBAU è perso, comunque, grazie ad altri fattori legati al motore di ricerca natura può aiutare un SEO. Quindi, potresti immaginare perché spiegare queste cose a un autore o a un cliente sia più difficile della SEO tecnica. La SEO semantica non utilizza valori numerici, utilizza la conoscenza teorica che deriva dalla comprensione dei motori di ricerca tramite brevetti, documenti di ricerca, esperienza e annunci storici.
12. Usa l'ottimizzazione della frase in-page per una migliore struttura fattuale
Ad essere onesti, anche il decimo elenco è un argomento completamente nuovo e può richiedere anche la scrittura di 20.000 parole qui. Ma inizierò con un semplice esempio.
- X è Y.
- Y è X.
Per le frasi di esempio sopra, puoi capire le cose di seguito.
- Le frasi di cui sopra non sono contenuti duplicati.
- Le proposizioni di cui sopra sono duplicate.
- Le spiegazioni relazionali tra due frasi sono le stesse.
- Le etichette dei ruoli semantici sono diverse al 100%.
- L'output del riconoscimento dell'entità denominata è uguale al 100%.
L'ottimizzazione delle frasi in-page è correlata agli algoritmi di generazione delle domande e alle tecnologie di accoppiamento domanda-risposta. Un formato domanda richiede un certo tipo di frase. E a certi tipi di domande si dovrebbe rispondere con certi tipi di frasi. Il formato del contenuto, il NER e l'estrazione dei fatti saranno influenzati dall'ottimizzazione della struttura della frase. 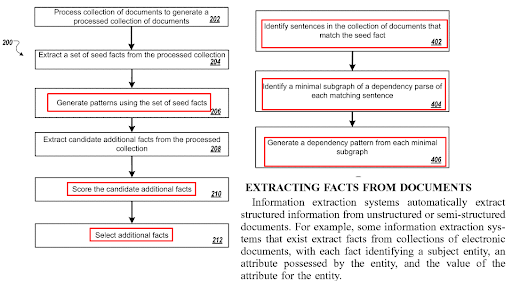
Le triplette (un oggetto, due soggetti) possono essere estratte e verificate in termini di precisione più velocemente. Due frasi simili non significano che sono duplicate, significa che sono vicine l'una all'altra in termini di struttura della frase. Finché la proposizione è diversa, l'uso di frasi simili tra modelli di documenti simili per coppie di intenti di query diverse è una necessità per la creazione di reti di contenuti semantici. 
Strutture di frasi chiare con uno schema appropriato sono utili per rendere i pezzi di testo più pertinenti l'uno all'altro mentre aiutano un motore di ricerca a riconoscere le entità con nome, i soggetti, gli attributi, insieme ai loro valori reciproci.
Aiuterà anche a vedere quale sezione di un articolo può essere migliorata, e in Topical Nets, dove i tuoi contenuti si classificano meglio per quali tipi di coppie di parole, vettori di parole e intenti. Perché, se alcuni tipi di strutture delle frasi per determinati tipi di domande possono essere osservati su più pagine Web, sarà utile per i test A/B SEO avanzati con quantità infinite di campioni di dati e campioni di test. Puoi creare più design di frasi in-page per verificare come un motore di ricerca estrae i fatti per confrontarli. 
Quando si tratta di fornire i fatti, è necessario ricordare il "Knowledge Vault" e il Luna Dong.
13. Fornisci informazioni sul mondo reale con precisione e coerenza, non opinioni con Fluff
La precisione qui significa poter essere confrontati con valori numerici, o relazioni concrete concettuali. La coerenza significa che proteggi la tua posizione per la proposta specifica. Ad esempio, non dire che "Il prodotto X è il migliore per Y" per ogni recensione di prodotto relativa alla Y. Non fornire proposte contraddittorie a livello di sito. E, se il prodotto è il migliore, quale ne è la prova? Materiale, dimensioni o colore e odore? Fluff all'interno del testo significa che usi parole ponte non necessarie o non dici cose che non è possibile provare o contraddicono la verità.
Nel contesto di queste istruzioni non definitive che sono supportate da alcuni degli esempi, puoi controllare uno dei modelli linguistici di Google che è KeALM.
Serve per generare testo da un database con i modelli data-to-text e per controllare l'accuratezza del contenuto. 
KELM è un esempio di Accuracy Audit per le proposte con metodi text-to-data.
Questo riguarda anche un po' la definizione di "Triplet" e "Open Information Extraction for Unknown Entities", ma come sai, questa è la versione breve e credo di aver detto abbastanza. Fondamentalmente, quando fornisci informazioni sbagliate sul tuo sito web, assicurati che Google sia in grado di capirle per diminuire la fiducia basata sulla conoscenza della fonte. Qui, potresti anche aver bisogno di sapere che, dal momento che sei in grado di espandere la Knowledge-base, un motore di ricerca può modificare la propria knowledge-base in base alle tue informazioni, se hai una fonte correlata con PageRank e Knowledge-base Trust con alta precisione e triplette uniche.
14. Comprendere l'albero delle dipendenze semantiche per le entità
Semantic Dependency Tree significa che gli attributi che segnalano le relazioni con altre entità hanno una dipendenza gerarchica tra di loro. L'albero delle dipendenze semantiche può essere osservato controllando più profili di entità e angoli come un paese può essere un membro di un'organizzazione e, come un'altra entità, questa organizzazione può avere alcuni altri attributi che possono essere attribuiti ai paesi collegati con relazioni dedotte.
Di seguito, potrai vedere un semplice esempio dal motore di ricerca, direttamente. 
REALM è un metodo che utilizza Semantic Dependency Trees per estrarre informazioni da testo ambiguo.
Sul Web aperto, l'estrazione di informazioni aperte può riconoscere nuove entità denominate ed estrarre queste stesse entità che si verificano insieme ad altre entità. Queste co-occorrenze e attributi reciproci all'interno dell'articolo possono assegnare un contesto e un tipo di relazione candidata tra entità. In base alle connessioni e al tipo dell'entità, è possibile creare l'albero delle dipendenze semantiche. La stessa logica vale anche per la semantica lessicale. La parola "ragazzo" ha alcuni possibili significati e alcuni esatti altri significati. Ad esempio, un ragazzo è un maschio e probabilmente un adolescente che non è sposato. Può essere utilizzato anche vicino allo studente. La parola "Regina" d'altra parte include altri significati collaterali ed esatti come "femmina" e "essere un governatore". Pertanto, avere qualcosa da governare è una gerarchia di alberi di dipendenza semantica naturale che può segnalare alcuni tipi di modelli di query come "Queen of..." o "For Quen". These contextual layers with context qualifiers should be united naturally with contextual domains and knowledge domains for improving the topical and contextual coverage together. 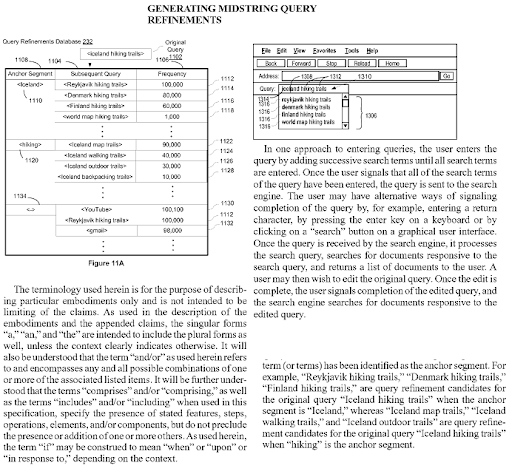
Generating Midstring Query Refinements is another Google Patent that shows the Semantic Content Network's connections to each other. Every midstring query refinement is a part of the topic's sub-topical net. A semantic content network that focuses on all these query refinement candidates with the correct semantic annotations will have the advantage of better re-ranking and initial ranking.
Last Thoughts on Semantic Content Network
I know that this content was highly technical in terms of Semantic SEO. And, before publishing my Semantic SEO Course, I still want to increase the knowledge, so that the first theoretical lessons can be digested by our minds faster than usual. The Semantic Content Networks can be defined as the sum of topical map, and individual content designs that include all of the headings, questions, heading levels, anchor texts, content hierarchy, and positions within the site-tree, or anything related to the content piece, including the featured images and in-page detailed images.
Here, besides the in-page sentence structure designs, or question-answer formats, or synonym sentence formats, we can also talk about the contextual vectors, contextual hierarchies, sequential sentences with bridged contexts, or evidence-based ranking by evidence aggregation. All these things would make this SEO Case Study and Guide more complicated but yet detailed. Thus, like in the previous, Importance of Topical Authority SEO Case Study and Guide, explaining Semantic Networks would make that article more complicated but yet detailed.
The future SEO Case Studies will include more and more details by supporting the previous ones. Lastly, I have gotten lots of screenshots and thank you messages from all of you that show the positive results that you have gotten thanks to Topical Authority understanding. I hope, Initial-ranking, and Re-ranking along with the Semantic Content Network understanding help you further.
See you in the next SEO Case Studies.
“The acquisition of knowledge is always of use to
the intellect, because it may thus drive out useless
things and retain the good. For nothing can be
loved or hated unless it is first known.”
– Leonardo da Vinci.